TCP長連接實踐與挑戰

👉 點這裡立即申請

本文介紹了tcp長連接在實際工程中的實踐過程,並總結了tcp連接保活遇到的挑戰以及對應的解決方案。
作者:字節跳動終端技術 ——— 陳聖坤
概述
眾所周知,作為傳輸層通訊協議,TCP是面向連接設計的,所有請求之前需要先通過三次握手建立一個連接,請求結束後通過四次揮手關閉連接。通常我們使用TCP連接或者基於TCP連接之上的應用層協議例如HTTP 1.0等,都會為每次請求建立一次連接,請求結束即關閉連接。這樣的好處是實現簡單,不用維護連接狀態。但對於大量請求的場景下,頻繁創建、關閉連接可能會帶來大量的開銷。因此這種場景通常的做法是保持長連接,一次請求後連接不關閉,下次再對該端點發起的請求直接復用該連接,例如HTTP 1.1及HTTP 2.0都是這麼做的。然而在工程實踐中會發現,實現TCP長連接並不像想像的那麼簡單,本文總結了實現TCP長連接時遇到的挑戰和解決方案。
事實上TCP協議本身並沒有規定請求完成時要關閉連接,也就是說TCP本身就是長連接的,直到有一方主動關閉連接為止。實現TCP連接遇到的挑戰主要有兩個:連接池和連接保活。
連接池
長連接意味著連接是復用的,每次請求完連接不關閉,下次請求繼續使用該連接。如果請求是串列的,那完全沒有問題。但在並發場景下,所有請求都需要使用該連接,為了保證連接的狀態正確,加鎖不可避免,如果連接只有一個,就意味著所有請求都需要排隊等待。因此長連接通常意味著連接池的存在:連接池中將保留一定數量的連接不關閉,有請求時從池中取出可用的連接,請求結束將連接返回池中。
用go實現一個簡單的連接池(參考《Go語言實戰》):
import (
"errors"
"io"
"sync"
)
type Pool struct {
m sync.Mutex
resources chan io.Closer
closed bool
}
func (p *Pool) Acquire() (io.Closer, error) {
r, ok := <-p.resources
if !ok {
return nil, errors.New("pool has been closed")
}
return r, nil
}
func (p *Pool) Release(r io.Closer) {
p.m.Lock()
defer p.m.Unlock()
if p.closed {
r.Close()
return
}
select {
case p.resources <- r:
default:
// pool is full , just close
r.Close()
}
}
func (p *Pool) Close() error {
p.m.Lock()
defer p.m.Unlock()
if p.closed {
return nil
}
p.closed = true
close(p.resources)
for r := range p.resources {
if err := r.Close(); err != nil {
return err
}
}
return nil
}
func New(fn func() (io.Closer, error), size uint) (*Pool, error) {
if size <= 0 {
return nil, errors.New("size too small")
}
res := make(chan io.Closer, size)
for i := 0; i < int(size); i++ {
c, err := fn()
if err != nil {
return nil, err
}
res <- c
}
return &Pool{
resources: res,
}, nil
}
池的對象只需實現io.Closer介面即可,利用go緩衝通道的特性可以輕鬆地實現連接池:獲取連接時從通道中接收一個對象,釋放連接時將該對象發送到連接池中。由於go的通道本身就是goroutine安全的,因此不需要額外加鎖。Pool使用的鎖是為了保證Release操作和Close操作的並發安全,防止連接池在關閉的同時再釋放連接,造成預期外的錯誤。
連接池經常遇到的一個問題就是池大小的控制:過大的連接池會帶來資源的浪費,同時對服務端也會帶來連接壓力;過小的連接池在高並發場景下會限制並發性能。通常的解決辦法是延遲創建和設置空閑時間,延遲創建是指連接只在請求到來時才創建,空閑時間是指連接在一定時間內未被使用則將被主動關閉。這樣日常情況下連接池控制在較小的尺度,當並發請求量較大時會為新的請求創建新的連接,這些連接在請求完畢後返還連接池,其中的大部分會在閑置一定時間後被主動關閉,這樣就做到了並發性能和IO資源之間較好的平衡。
連接保活
長連接的第二個問題就是連接保活的問題。雖然TCP協議並沒有限制一個連接可以保持多久,理論上只要不關閉連接,連接就一直存在。但事實上由於NAT等網路設備的存在,一個連接即使沒有主動關閉,它也不會一直存活。
NAT
NAT(Network Address Translation)是一種被廣泛應用的網路設備,直觀地解釋就是進行網路地址轉換,通過一定策略對tcp包的源ip、源埠、目的ip和目的埠進行替換。可以說,NAT有效緩解了ipv4地址緊缺的問題,雖然理論上ipv4早已耗盡,但正由於NAT設備的存在,ipv4的壽命超出了所預計的時間。公司內部的網路也是通過NAT構建起來的。
雖然NAT有如此的優點,但它也帶來了一些新的問題,對TCP長連接的影響就是其中之一。我們將一個通過NAT連接的網路簡化成下面的模型: 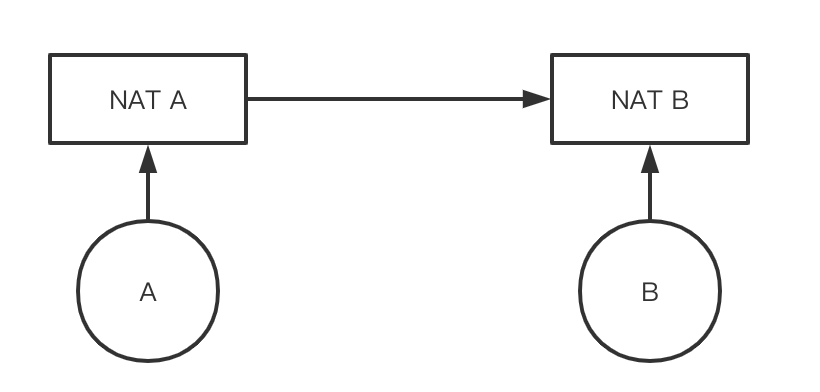
A如果想保持對B的長連接,它實際並不與B直接建立連接,而是與NAT A建立長連接,而NAT A又與NAT B、NAT B與B建立長連接。如果NAT設備任由下面的機器保持連接不關閉,那它很容易就耗盡所能支援的連接數,因此NAT設備會定時關閉一定時間內沒有數據包的連接,並且它不會通知網路的雙方。這就是為什麼我們有時候會遇到這種錯誤:
error: read tcp4 1.1.1.1:8888->2.2.2.2:9999: i/o timeout
按照TCP的設計,連接有一方要關閉連接時會有「四次揮手」的過程,通過一個關閉的連接發送數據時會拋出Broken pipe的錯誤。但NAT關閉連接時並不通知連接雙方,發送方不知道連接已關閉,會繼續通過該連接發送數據,並且不會拋出Broken pipe的錯誤,而接收方也不知道連接已關閉,還會持續監聽該連接。這樣發送方請求能成功發送,但接收方無法接收到該請求,因此發送方自然也等不到接收方的響應,就會阻塞至介面超時。經過實踐發現公司的NAT超時是一個小時,也就是保持連接不關閉並閑置一個小時後,再通過該連接發送請求時,就會出現上述timeout的錯誤。
我們上面提到連接池大小的控制問題,其實看起來有點類似NAT的超時控制,那既然我們允許連接池關閉超時的閑置連接,為什麼不能接受NAT設備關閉呢?答案就是上面提到的,NAT設備關閉連接時並未通知連接雙方,因此客戶端使用連接請求時並不知道該連接實際上是否可用,而如果是由連接池主動關閉連接,那它自然知道連接是否是可用的。
Keepalive
通過上面的描述我們就知道怎麼解決了,既然NAT會關閉一定時間內沒有數據包的連接,那我們只需要讓這個連接定時自動發送一個小數據包,就能保證連接不會被NAT自動關閉。
實際上TCP協議中就包含了一個keepalive機制:如果keepalive開關被打開,在一段時間(保活時間:tcp_keepalive_time) 內此連接不活躍,開啟保活功能的一端會向對端發送一個保活探測報文。只要我們保證這個tcp_keepalive_time小於NAT的超時時間,這個探測報文的存在就能保證NAT設備不會關閉我們的連接。
unix系統為TCP開發封裝的socket介面通常都有keepalive的相關設置,以go語言為例:
conn, _ := net.DialTCP("tcp4", nil, tcpAddr)
_ = conn.SetKeepAlive(true)
_ = conn.SetKeepAlivePeriod(5 * time.Minute)
另一個常見的保活機制是HTTP協議的keep-alive,不同於TCP協議,HTTP 1.0設計上默認是不支援長連接的,伺服器響應完立即斷開連接,通過請求頭中的設置「connection: keep-alive」保持TCP連接不斷開(HTTP 1.1以後默認開啟)。
流水線控制
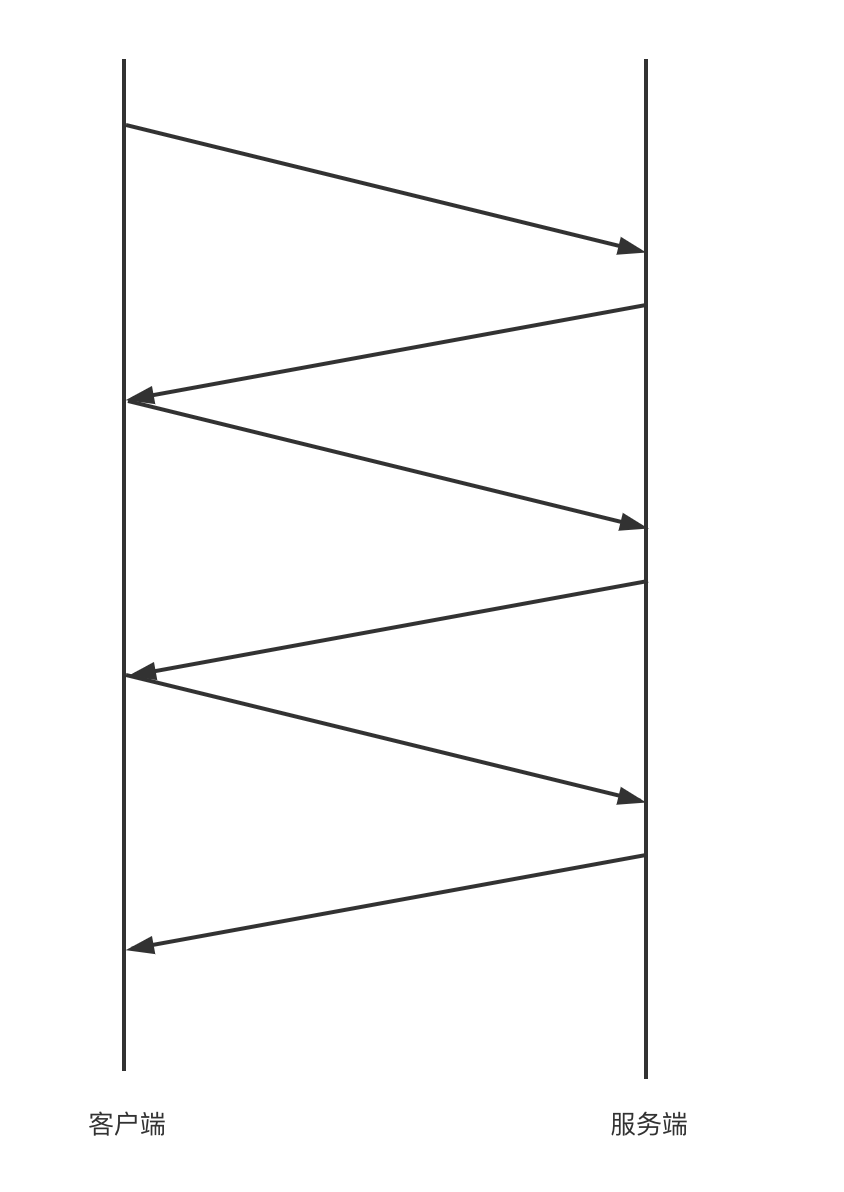
儘管使用連接池一定程度上能平衡好並發性能和io資源,但在高並發下性能還是不夠理想,這是因為可能有上百個請求都在等同一個連接,每個請求都需要等待上一個請求返回後才能發出:
: 
這樣無疑是低效的,我們不妨參考HTTP協議的流水線設計,也就是請求不必等待上一個請求返回才能發出,一個TCP長連接會按順序連續發出一系列請求,等到請求發送成功後再統一按順序接收所有的返回結果:
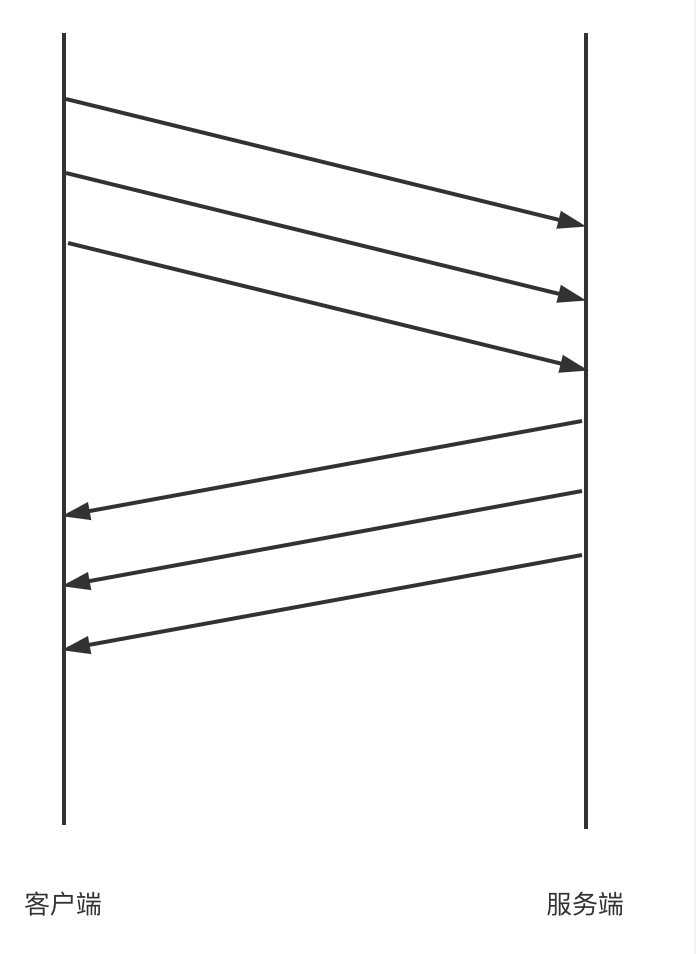
這樣無疑能大大減少網路的等待時間,提高並發性能。隨之而來的一個顯而易見的問題是如何保證響應和請求的正確對應關係?通常有兩種策略:
- 如果服務端是單執行緒/進程地處理每個連接,那服務端天然就是以請求的順序依次響應的,客戶端接收到的響應順序和請求順序是一致的,不需要特殊處理;
- 如果服務端是並發地處理每個連接上的所有請求(例如將請求入隊列,然後並發地消費隊列,經典的如redis),那就無法保證響應的順序與請求順序一致,這時就需要修改客戶端與服務端的通訊協議,在請求與響應的數據結構中帶上獨一無二的序號,通過匹配這個序號來確定響應和請求之間的映射關係;
HTTP 2.0實現了一個多路復用的機制,其實可以看成是這種流水線的優化,它的響應與請求的映射關係就是通過流ID來保證的。
總結
以上就是對TCP長連接實踐中遇到的挑戰和解決思路的總結,結合筆者在公司內部的實踐經驗分別探討了連接池、連接保活和流水線控制等問題,梳理了實現TCP長連接經常遇到的問題,並提出了解決思路,在降低頻繁創建連接的開銷的同時儘可能地保證高並發下的性能。
參考
🔥 火山引擎 APMPlus 應用性能監控是火山引擎應用開發套件 MARS 下的性能監控產品。我們通過先進的數據採集與監控技術,為企業提供全鏈路的應用性能監控服務,助力企業提升異常問題排查與解決的效率。目前我們面向中小企業特別推出「APMPlus 應用性能監控企業助力行動」,為中小企業提供應用性能監控免費資源包。現在申請,有機會獲得60天免費性能監控服務,最高可享6000萬*條事件量。
👉 點擊這裡,立即申請

