python基礎之字元編碼
- 2020 年 1 月 19 日
- 筆記
了解字元編碼的知識儲備
一 電腦基礎知識

二 文本編輯器存取文件的原理(nodepad++,pycharm,word)
#1、打開編輯器就打開了啟動了一個進程,是在記憶體中的,所以,用編輯器編寫的內容也都是存放與記憶體中的,斷電後數據丟失 #2、要想永久保存,需要點擊保存按鈕:編輯器把記憶體的數據刷到了硬碟上。 #3、在我們編寫一個py文件(沒有執行),跟編寫其他文件沒有任何區別,都只是在編寫一堆字元而已。
三 python解釋器執行py文件的原理 ,例如python test.py

#第一階段:python解釋器啟動,此時就相當於啟動了一個文本編輯器 #第二階段:python解釋器相當於文本編輯器,去打開test.py文件,從硬碟上將test.py的文件內容讀入到記憶體中(小複習:pyhon的解釋性,決定了解釋器只關心文件內容,不關心文件後綴名) #第三階段:python解釋器解釋執行剛剛載入到記憶體中test.py的程式碼( ps:在該階段,即真正執行程式碼時,才會識別python的語法,執行文件內程式碼,當執行到name="egon"時,會開闢記憶體空間存放字元串"egon")
四 總結python解釋器與文件本編輯的異同
#1、相同點:python解釋器是解釋執行文件內容的,因而python解釋器具備讀py文件的功能,這一點與文本編輯器一樣 #2、不同點:文本編輯器將文件內容讀入記憶體後,是為了顯示或者編輯,根本不去理會python的語法,而python解釋器將文件內容讀入記憶體後,可不是為了給你瞅一眼python程式碼寫的啥,而是為了執行python程式碼、會識別python語法。
字元編碼介紹
一 什麼是字元編碼
電腦要想工作必須通電,即用『電』驅使電腦幹活,也就是說『電』的特性決定了電腦的特性。電的特性即高低電平(人類從邏輯上將二進位數1對應高電平,二進位數0對應低電平),關於磁碟的磁特性也是同樣的道理。結論:電腦只認識數字 很明顯,我們平時在使用電腦時,用的都是人類能讀懂的字元(用高級語言編程的結果也無非是在文件內寫了一堆字元),如何能讓電腦讀懂人類的字元? 必須經過一個過程: #字元--------(翻譯過程)------->數字 #這個過程實際就是一個字元如何對應一個特定數字的標準,這個標準稱之為字元編碼
二 以下兩個場景下涉及到字元編碼的問題:
#1、一個python文件中的內容是由一堆字元組成的,存取均涉及到字元編碼問題(python文件並未執行,前兩個階段均屬於該範疇) #2、python中的數據類型字元串是由一串字元組成的(python文件執行時,即第三個階段)
三 字元編碼的發展史與分類(了解)
電腦由美國人發明,最早的字元編碼為ASCII,只規定了英文字母數字和一些特殊字元與數字的對應關係。最多只能用 8 位來表示(一個位元組),即:2**8 = 256,所以,ASCII碼最多只能表示 256 個符號

當然我們程式語言都用英文沒問題,ASCII夠用,但是在處理數據時,不同的國家有不同的語言,日本人會在自己的程式中加入日文,中國人會加入中文。
而要表示中文,單拿一個位元組表表示一個漢子,是不可能表達完的(連小學生都認識兩千多個漢字),解決方法只有一個,就是一個位元組用>8位2進位代表,位數越多,代表的變化就多,這樣,就可以儘可能多的表達出不通的漢字
所以中國人規定了自己的標準gb2312編碼,規定了包含中文在內的字元->數字的對應關係。
日本人規定了自己的Shift_JIS編碼
韓國人規定了自己的Euc-kr編碼(另外,韓國人說,電腦是他們發明的,要求世界統一用韓國編碼,但世界人民沒有搭理他們)
這時候問題出現了,精通18國語言的小周同學謙虛的用8國語言寫了一篇文檔,那麼這篇文檔,按照哪國的標準,都會出現亂碼(因為此刻的各種標準都只是規定了自己國家的文字在內的字元跟數字的對應關係,如果單純採用一種國家的編碼格式,那麼其餘國家語言的文字在解析時就會出現亂碼)
所以迫切需要一個世界的標準(能包含全世界的語言)於是unicode應運而生(韓國人表示不服,然後沒有什麼卵用)
ascii用1個位元組(8位二進位)代表一個字元
unicode常用2個位元組(16位二進位)代表一個字元,生僻字需要用4個位元組
例:
字母x,用ascii表示是十進位的120,二進位0111 1000
漢字中已經超出了ASCII編碼的範圍,用Unicode編碼是十進位的20013,二進位的01001110 00101101。
字母x,用unicode表示二進位0000 0000 0111 1000,所以unicode兼容ascii,也兼容萬國,是世界的標準
這時候亂碼問題消失了,所有的文檔我們都使用但是新問題出現了,如果我們的文檔通篇都是英文,你用unicode會比ascii耗費多一倍的空間,在存儲和傳輸上十分的低效
本著節約的精神,又出現了把Unicode編碼轉化為「可變長編碼」的UTF-8編碼。UTF-8編碼把一個Unicode字元根據不同的數字大小編碼成1-6個位元組,常用的英文字母被編碼成1個位元組,漢字通常是3個位元組,只有很生僻的字元才會被編碼成4-6個位元組。如果你要傳輸的文本包含大量英文字元,用UTF-8編碼就能節省空間:
|
字元 |
ASCII |
Unicode |
UTF-8 |
|---|---|---|---|
|
A |
01000001 |
00000000 01000001 |
01000001 |
|
中 |
x |
01001110 00101101 |
11100100 10111000 10101101 |
從上面的表格還可以發現,UTF-8編碼有一個額外的好處,就是ASCII編碼實際上可以被看成是UTF-8編碼的一部分,所以,大量只支援ASCII編碼的歷史遺留軟體可以在UTF-8編碼下繼續工作。
四 總結字元編碼的發展可分為三個階段(重要)


#階段一:現代電腦起源於美國,最早誕生也是基於英文考慮的ASCII ASCII:一個Bytes代表一個字元(英文字元/鍵盤上的所有其他字元),1Bytes=8bit,8bit可以表示0-2**8-1種變化,即可以表示256個字元 ASCII最初只用了後七位,127個數字,已經完全能夠代表鍵盤上所有的字元了(英文字元/鍵盤的所有其他字元),後來為了將拉丁文也編碼進了ASCII表,將最高位也佔用了 #階段二:為了滿足中文和英文,中國人訂製了GBK GBK:2Bytes代表一個中文字元,1Bytes表示一個英文字元 為了滿足其他國家,各個國家紛紛訂製了自己的編碼 日本把日文編到Shift_JIS里,韓國把韓文編到Euc-kr里 #階段三:各國有各國的標準,就會不可避免地出現衝突,結果就是,在多語言混合的文本中,顯示出來會有亂碼。如何解決這個問題呢??? #!!!!!!!!!!!!非常重要!!!!!!!!!!!! 說白了亂碼問題的本質就是不統一,如果我們能統一全世界,規定全世界只能使用一種文字元號,然後統一使用一種編碼,那麼亂碼問題將不復存在, ps:就像當年秦始皇統一中國一樣,書同文車同軌,所有的麻煩事全部解決 很明顯,上述的假設是不可能成立的。很多地方或老的系統、應用軟體仍會採用各種各樣的編碼,這是歷史遺留問題。於是我們必須找出一種解決方案或者說編碼方案,需要同時滿足: #1、能夠兼容萬國字元 #2、與全世界所有的字元編碼都有映射關係,這樣就可以轉換成任意國家的字元編碼 這就是unicode(定長), 統一用2Bytes代表一個字元, 雖然2**16-1=65535,但unicode卻可以存放100w+個字元,因為unicode存放了與其他編碼的映射關係,準確地說unicode並不是一種嚴格意義上的字元編碼表,下載pdf來查看unicode的詳情: 鏈接:https://pan.baidu.com/s/1dEV3RYp 很明顯對於通篇都是英文的文本來說,unicode的式無疑是多了一倍的存儲空間(二進位最終都是以電或者磁的方式存儲到存儲介質中的) 於是產生了UTF-8(可變長,全稱Unicode Transformation Format),對英文字元只用1Bytes表示,對中文字元用3Bytes,對其他生僻字用更多的Bytes去存 #總結:記憶體中統一採用unicode,浪費空間來換取可以轉換成任意編碼(不亂碼),硬碟可以採用各種編碼,如utf-8,保證存放於硬碟或者基於網路傳輸的數據量很小,提高傳輸效率與穩定性。
!!!重點!!!

基於目前的現狀,記憶體中的編碼固定就是unicode,我們唯一可變的就是硬碟的上對應的字元編碼。 此時你可能會覺得,那如果我們以後開發軟時統一都用unicode編碼,那麼不就都統一了嗎,關於統一這一點你的思路是沒錯的,但我們不可會使用unicode編碼來編寫程式的文件,因為在通篇都是英文的情況下,耗費的空間幾乎會多出一倍,這樣在軟體讀入記憶體或寫入磁碟時,都會徒增IO次數,從而降低程式的執行效率。因而我們以後在編寫程式的文件時應該統一使用一個更為精準的字元編碼utf-8(用1Bytes存英文,3Bytes存中文),再次強調,記憶體中的編碼固定使用unicode。 1、在存入磁碟時,需要將unicode轉成一種更為精準的格式,utf-8:全稱Unicode Transformation Format,將數據量控制到最精簡
2、在讀入記憶體時,需要將utf-8轉成unicode 所以我們需要明確:記憶體中用unicode是為了兼容萬國軟體,即便是硬碟中有各國編碼編寫的軟體,unicode也有相對應的映射關係,但在現在的開發中,程式設計師普遍使用utf-8編碼了,估計在將來的某一天等所有老的軟體都淘汰掉了情況下,就可以變成:記憶體utf-8<->硬碟utf-8的形式了。
字元編碼應用之文件編輯器
3.1 文本編輯器之nodpad++

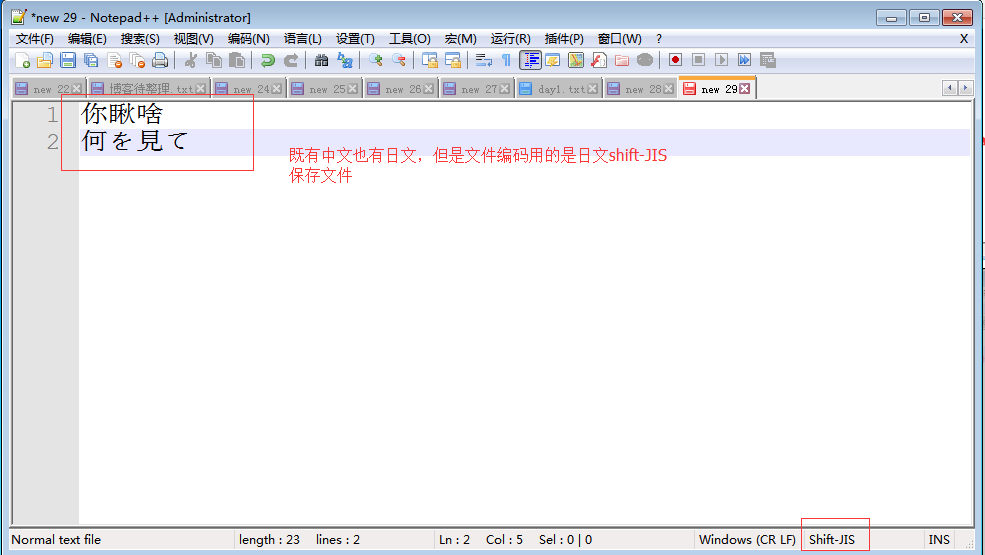


首先明確概念 #1、文件從記憶體刷到硬碟的操作簡稱存文件 #2、文件從硬碟讀到記憶體的操作簡稱讀文件 亂碼的兩種情況: #亂碼一:存文件時就已經亂碼 存文件時,由於文件內有各個國家的文字,我們單以shiftjis去存, 本質上其他國家的文字由於在shiftjis中沒有找到對應關係而導致存儲失敗 但當我們硬要存的時候,編輯並不會報錯(難道你的編碼錯誤,編輯器這個軟體就跟著崩潰了嗎???),但毫無疑問,不能存而硬存,肯定是亂存了,即存文件階段就已經發生亂碼 而當我們用shiftjis打開文件時,日文可以正常顯示,而中文則亂碼了 #用open模擬編輯器的過程 可以用open函數的write可以測試,f=open('a.txt','w',encodig='shift_jis' f.write('你瞅啥n何を見てn') #'你瞅啥'因為在shiftjis中沒有找到對應關係而無法保存成功,只存'何を見てn'可以成功 #以任何編碼打開文件a.txt都會出現其餘兩個無法正常顯示的問題 f=open('a.txt','wb') f.write('何を見てn'.encode('shift_jis')) f.write('你愁啥n'.encode('gbk')) f.write('你愁啥n'.encode('utf-8')) f.close() #亂碼二:存文件時不亂碼而讀文件時亂碼 存文件時用utf-8編碼,保證兼容萬國,不會亂碼,而讀文件時選擇了錯誤的解碼方式,比如gbk,則在讀階段發生亂碼,讀階段發生亂碼是可以解決的,選對正確的解碼方式就ok了,
!!!亂碼分析!!!
3.2 文本編輯器之pycharm

以utf-8格式打開(選擇reload)
#reload與convert的區別: pycharm非常強大,提供了自動幫我們convert轉換的功能,即將字元按照正確的格式轉換 要自己探究字元編碼的本質,還是不要用這個 我們選擇reload,即按照某種編碼重新載入文件
pycharm中:reload與convert的區別
3.3 文本編輯器之python解釋器
文件test.py以gbk格式保存,內容為: x='林' 無論是 python2 test.py 還是 python3 test.py 都會報錯(因為python2默認ascii,python3默認utf-8) 除非在文件開頭指定#coding:gbk
3.4 總結
!!!總結非常重要的兩點!!!
#1、保證不亂嗎的核心法則就是,字元按照什麼標準而編碼的,就要按照什麼標準解碼,此處的標準指的就是字元編碼 #2、在記憶體中寫的所有字元,一視同仁,都是unicode編碼,比如我們打開編輯器,輸入一個「你」,我們並不能說「你」就是一個漢字,此時它僅僅只是一個符號,該符號可能很多國家都在使用,根據我們使用的輸入法不同這個字的樣式可能也不太一樣。只有在我們往硬碟保存或者基於網路傳輸時,才能確定」你「到底是一個漢字,還是一個日本字,這就是unicode轉換成其他編碼格式的過程了
unicode—–>encode——–>utf-8
utf-8——–>decode———->unicode

#補充: 瀏覽網頁的時候,伺服器會把動態生成的Unicode內容轉換為UTF-8再傳輸到瀏覽器 如果服務端encode的編碼格式是utf-8, 客戶端記憶體中收到的也是utf-8編碼的結果。
字元編碼應用之python
4.1 執行python程式的三個階段
python test.py (我再強調一遍,執行test.py的第一步,一定是先將文件內容讀入到記憶體中)
test.py文件內容以gbk格式保存的,內容為:

階段一:啟動python解釋器
階段二:python解釋器此時就是一個文本編輯器,負責打開文件test.py,即從硬碟中讀取test.py的內容到記憶體中
此時,python解釋器會讀取test.py的第一行內容,#coding:utf-8,來決定以什麼編碼格式來讀入記憶體,這一行就是來設定python解釋器這個軟體的編碼使用的編碼格式這個編碼, 可以用sys.getdefaultencoding()查看,如果不在python文件指定頭資訊#-*-coding:utf-8-*-,那就使用默認的 python2中默認使用ascii,python3中默認使用utf-8

改正:在test.py指定文件頭,字元編碼一定要為gbk,
#coding:gbk 你好啊

階段三:讀取已經載入到記憶體的程式碼(unicode編碼格式),然後執行,執行過程中可能會開闢新的記憶體空間,比如x="egon"
記憶體的編碼使用unicode,不代表記憶體中全都是unicode, 在程式執行之前,記憶體中確實都是unicode,比如從文件中讀取了一行x="egon",其中的x,等號,引號,地位都一樣,都是普通字元而已,都是以unicode的格式存放於記憶體中的 但是程式在執行過程中,會申請記憶體(與程式程式碼所存在的記憶體是倆個空間)用來存放python的數據類型的值,而python的字元串類型又涉及到了字元的概念 比如x="egon",會被python解釋器識別為字元串,會申請記憶體空間來存放字元串類型的值,至於該字元串類型的值被識別成何種編碼存放,這就與python解釋器的有關了,而python2與python3的字元串類型又有所不同。
4.2 python2與python3字元串類型的區別
1)在python2中有兩種字元串類型str和unicode
str類型
當python解釋器執行到產生字元串的程式碼時(例如x='上'),會申請新的記憶體地址,然後將'上'編碼成文件開頭指定的編碼格式
要想看x在記憶體中的真實格式,可以將其放入列表中再列印,而不要直接列印,因為直接print()會自動轉換編碼,這一點我們稍後再說。
#coding:gbk x='上' y='下' print([x,y]) #['xc9xcf', 'xcfxc2'] #x代表16進位,此處是c9cf總共4位16進位數,一個16進位四4個比特位,4個16進位數則是16個比特位,即2個Bytes,這就證明了按照gbk編碼中文用2Bytes
print(type(x),type(y)) #(<type 'str'>, <type 'str'>)
理解字元編碼的關鍵!!!
記憶體中的數據通常用16進位表示,2位16進位數據代表一個位元組,如xc9,代表兩位16進位,一個位元組
gbk存中文需要2個bytes,而存英文則需要1個bytes,它是如何做到的???!!!
gbk會在每個bytes,即8位bit的第一個位作為標誌位,標誌位為1則表示是中文字元,如果標誌位為0則表示為英文字元
x=『你a好』 轉成gbk格式二進位位 8bit+8bit+8bit+8bit+8bit=(1+7bit)+(1+7bit)+(0+7bit)+(1+7bit)+(1+7bit)
這樣電腦按照從左往右的順序讀:
#連續讀到前兩個括弧內的首位標誌位均為1,則構成一個中午字元:你 #讀到第三個括弧的首位標誌為0,則該8bit代表一個英文字元:a #連續讀到後兩個括弧內的首位標誌位均為1,則構成一個中午字元:好
也就是說,每個Bytes留給我們用來存真正值的有效位數只有7位,而在unicode表中存放的只是這有效的7位,至於首位的標誌位與具體的編碼有關,即在unicode中表示gbk的方式為:
(7bit)+(7bit)+(7bit)+(7bit)+(7bit)

按照上圖翻譯的結果,我們可以去unicode關於漢字的對應關係中去查:鏈接:https://pan.baidu.com/s/1dEV3RYp
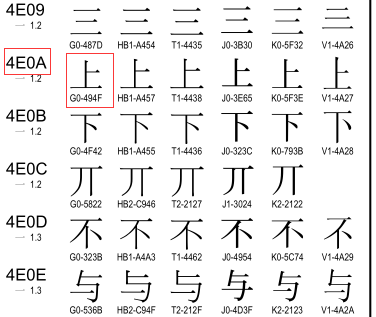
可以看到「」上「」對應的gbk(G0代表的是gbk)編碼就為494F,即我們得出的結果,而上對應的unicode編碼為4E0A,我們可以將gbk–>decode–>unicode
#coding:gbk x='上'.decode('gbk') y='下'.decode('gbk') print([x,y]) #[u'u4e0a', u'u4e0b']
unicode類型
當python解釋器執行到產生字元串的程式碼時(例如s=u'林'),會申請新的記憶體地址,然後將'林'以unicode的格式存放到新的記憶體空間中,所以s只能encode,不能decode
#coding:gbk x=u'上' #等同於 x='上'.decode('gbk') y=u'下' #等同於 y='下'.decode('gbk') print([x,y]) #[u'u4e0a', u'u4e0b']
print(type(x),type(y)) #(<type 'unicode'>, <type 'unicode'>)
列印到終端
對於print需要特別說明的是:
當程式執行時,比如
x='上' #gbk下,字元串存放為xc9xcf
print(x) #這一步是將x指向的那塊新的記憶體空間(非程式碼所在的記憶體空間)中的記憶體,列印到終端,按理說應該是存的什麼就列印什麼,但列印xc9xcf,對一些不熟知python編碼的程式設計師,立馬就懵逼了,所以龜叔自作主張,在print(x)時,使用終端的編碼格式,將記憶體中的xc9xcf轉成字元顯示,此時就需要終端編碼必須為gbk,否則無法正常顯示原內容:上


對於unicode格式的數據來說,無論怎麼列印,都不會亂碼
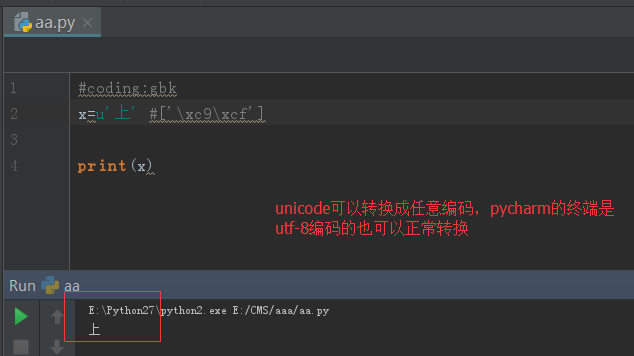

unicode這麼好,不會亂碼,那python2為何還那麼彆扭,搞一個str出來呢?python誕生之時,unicode並未像今天這樣普及,很明顯,好的東西你能看得見,龜叔早就看見了,龜叔在python3中將str直接存成unicode,我們定義一個str,無需加u前綴,就是一個unicode,屌不屌?
2)在python3 中也有兩種字元串類型str和bytes
str是unicode
#coding:gbk x='上' #當程式執行時,無需加u,'上'也會被以unicode形式保存新的記憶體空間中, print(type(x)) #<class 'str'> #x可以直接encode成任意編碼格式 print(x.encode('gbk')) #b'xc9xcf' print(type(x.encode('gbk'))) #<class 'bytes'>
很重要的一點是:看到python3中x.encode('gbk') 的結果xc9xcf正是python2中的str類型的值,而在python3是bytes類型,在python2中則是str類型
於是我有一個大膽的推測:python2中的str類型就是python3的bytes類型,於是我查看python2的str()源碼,發現


