vivo資料庫與存儲平台的建設和探索
本文根據Xiao Bo老師在「2021 vivo開發者大會“現場演講內容整理而成。公眾號回復【2021VDC】獲取互聯網技術分會場議題相關資料。
一、資料庫與存儲平台建設背景

以史為鑒,可以知興替,做技術亦是如此,在介紹平台之前,我們首先來一起回顧下vivo互聯網業務近幾年的發展歷程。
我們將時間撥回到三年前來看看 vivo 互聯網產品近幾年的發展狀況,2018年11月,vivo移動互聯網累計總用戶突破2.2億;2019年應用商店、瀏覽器、影片、錢包等互聯網應用日活突破千萬大關;2020年瀏覽器日活突破1億,2021年在網總用戶(不含外銷)達到2.7億,數十款月活過億的應用,資料庫和存儲產品的也達到了4000+伺服器和5萬+資料庫實例的規模。
那三年前的資料庫和存儲平台是什麼樣呢?

2018年的資料庫服務現狀如果用一個詞形容,那我覺得「危如累卵」最適合不過了,主要表現為以下幾點;
-
資料庫線上環境的可用性由於低效的SQL、人為的誤操作,基礎架構的不合理,開源產品的健壯性等問題導致可用性經常受到影響。
-
變更不規範,變更和各種運維操作的效率低下,沒有平台支撐,使用命令行終端進行變更。
-
資料庫使用的成本極高,為了應對日益複雜的業務場景,增加了很多額外的成本。這些就是2018年當時vivo的資料庫現狀。
-
安全能力不夠健全,數據分類分級、密碼帳號許可權等缺乏規範。
我們再看看這些年vivo資料庫一些運營數據上的變化趨勢。
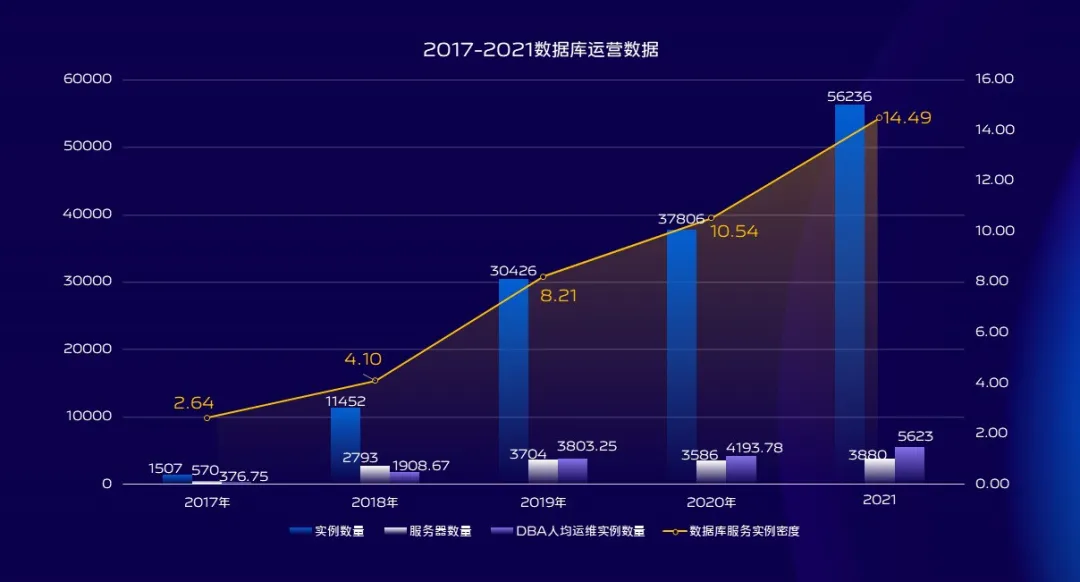
從17年底,18年初開始計算,這三年時間裡面資料庫實例的規模增加了接近5倍,所維護的資料庫伺服器規模增加了6.8倍,資料庫實例的單機部署密度增加了5倍以上,DBA人均運維的資料庫實例規模增加了14.9倍。
通過以上這些數字,我們發現近幾年vivo互聯網業務其實是處於高速發展的狀態,在高速發展的過程中無論是從用戶感受到的服務品質上來看還是從內部的成本效率來看,解決數據存儲的問題是迫在眉睫的事情,於是我們在2018年啟動了自研資料庫與存儲平台的計劃,通過幾年時間的建設,我們初步具備了一些能力,現在就這些能力給大家做下簡單的介紹。
二、資料庫與存儲平台能力建設

首先來整體對資料庫與存儲平台產品做下介紹,主要分為2層。
-
第一層我們的資料庫和存儲產品,包括關係型數據,非關係型資料庫,存儲服務三大塊。
-
第二層主要是工具產品,包括提供資料庫和存儲統一管控的研發和運維平台,數據傳輸服務,運維白屏化工具,還有一些SQL審核,SQL優化,數據備份等產品。
工具產品主要以自研為主,下面一層的資料庫和存儲產品我們會優先選用成熟的開源產品,同時也會在開源產品的基礎上或者純自研一些產品用來更好的滿足業務發展,下面就部分產品的能力做下簡單的介紹。

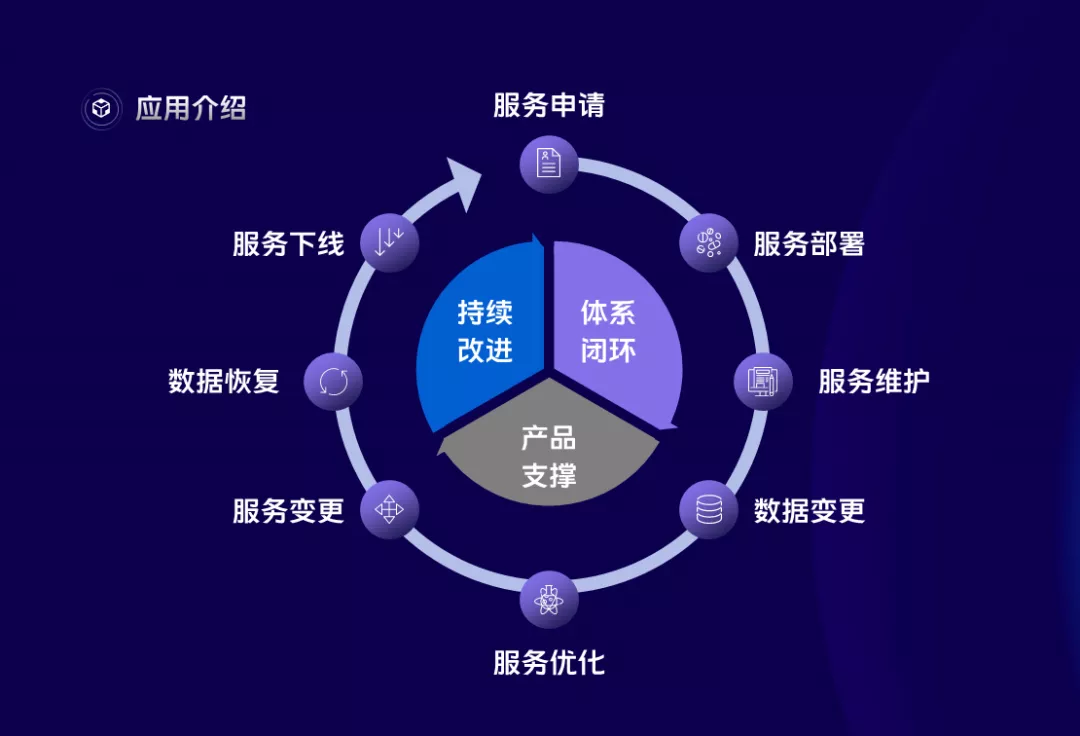
DaaS平台是Database as a Service的縮寫,該平台旨在提供高度自助化、高度智慧化、高可用、低成本的數據存儲使用和管理的平台,涵蓋了資料庫和存儲產品從服務申請、部署、維護直至下線的全生命周期,主要從四個方面為公司和用戶提供價值。
-
第一是提升資料庫產品的可用性,通過巡檢、監控、預案、故障跟蹤等對故障進行事前防範、事中及時處理、事後復盤總結進行全流程閉環。
-
第二是提升研發效能,研發自助使用資料庫,提供變更檢測、優化診斷等功能,減少人工溝通流程,項目變更規範流程清晰,提升研發效率。
-
第三是提升數據安全性,通過許可權管控、密碼管控、數據加密、數據脫敏、操作審計、備份加密等一系列手段全方位的保障數據安全性。
-
第四是降低資料庫和存儲產品的運營成本,首先通過自動化的流程減少DBA的重複工作,提高人效,其次通過服務編排和資源調度,提升資料庫和存儲服務的資源使用效率,持續降低運營成本。
通過幾年時間的建設,以上工作取得了一些進展,其中每月數以千計的需求工單,其中90%以上研發同學可以自助完成,服務可用性最近幾年都維持在4個9以上,平台對6種資料庫產品和存儲服務的平台化支援達到了85%以上,而且做到了同一能力的全資料庫場景覆蓋,比如數據變更,我們支援MySQL、ElastiSearch、MongoDB、TiDB的變更前語句審查,變更數據備份,變更操作一鍵回滾,變更記錄審計追蹤等。

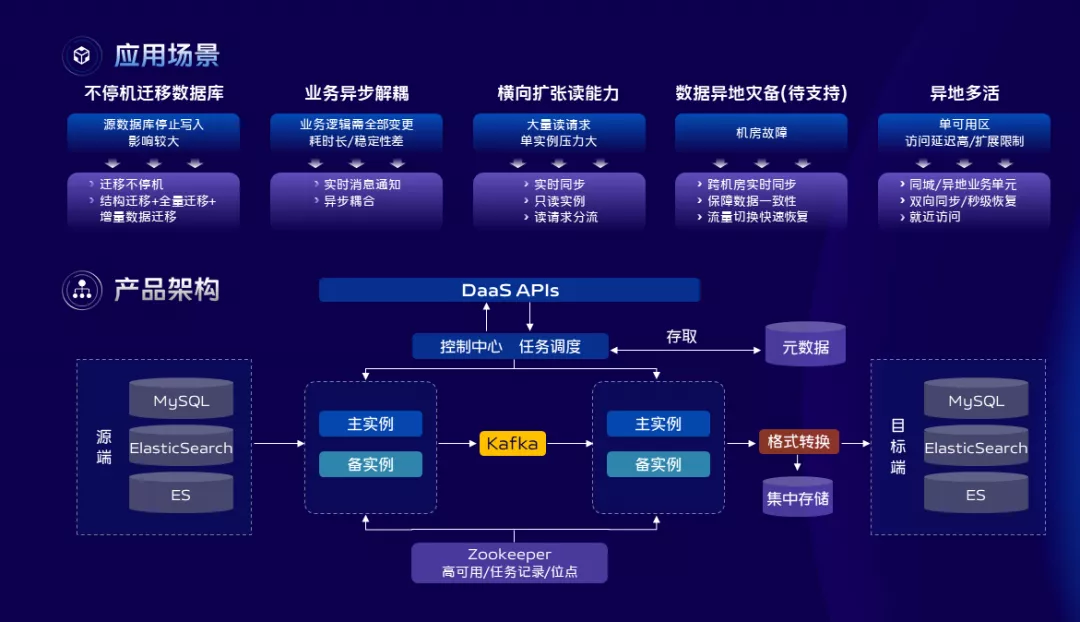
vivo的DTS服務是基於自身業務需求完全自研的數據傳輸服務,主要提供RDBMS、NoSQL、OLAP等數據源之間的數據交互。集數據遷移、訂閱、同步、備份的一體化服務,從功能上來看,主要有三個特性;
-
第一是同步鏈路的穩定性和數據可靠性保障,通過結合各個數據源產品的自身特性可以做到數據不重不丟,給業務提供99.99%的服務可用性保障。
-
第二是功能層面支援異構的多種資料庫類型,除了同步、遷移、訂閱等這些通用功能外,我們還支援變更數據的集中化存儲和檢索。
-
第三是故障容災層面,支援節點級別故障容災,可以做到同步鏈路秒級恢復,也支援斷點續傳,可以有效的解決因硬體、網路等異常導致的傳輸中斷問題。
下面我們再來看看我們在底層數據存儲層做的一些項目,首先來看看MySQL資料庫。

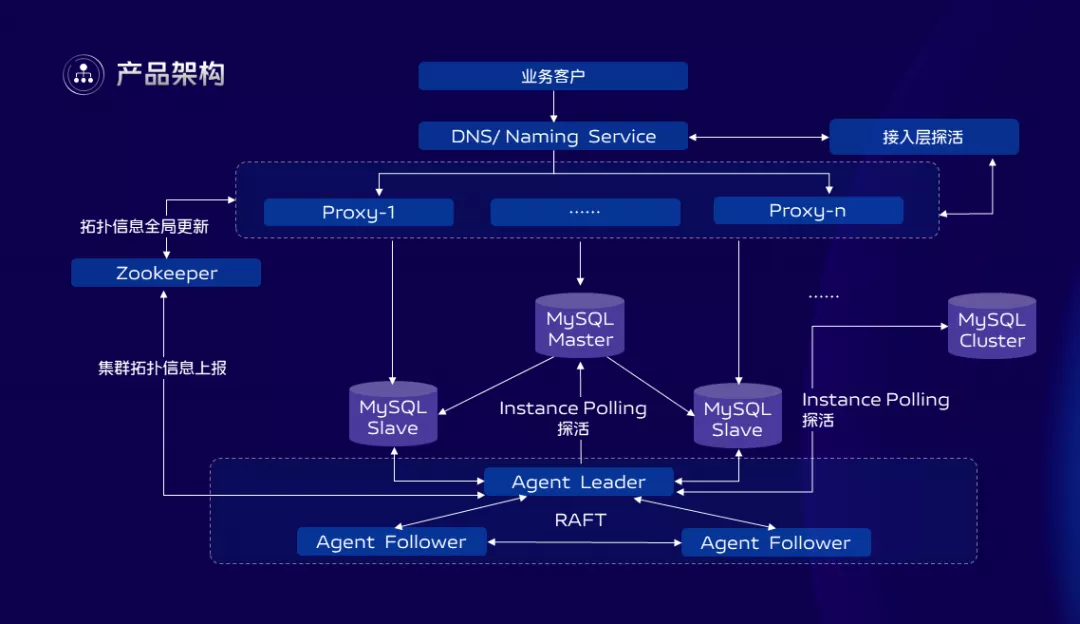
MySQL作為最流行的資料庫,在vivo同樣承擔了關係型資料庫服務的重任,上圖的MySQL2.0是我們內部的架構版本,在這幾年時間裡面,我們的架構演化了2版。
第一版為了快速解決當時面臨的可用性問題,基於MHA+自研組件做了1.0版本。
目前已經演化到了2.0版本,MHA等組件依賴已經沒有了,從架構上看,2.0版本的服務接入層我們支援業務使用DNS或者名字服務接入,中間加入了一層自研的代理層Proxy,這一層做到了100%與MySQL語法和協議兼容,在Proxy上面我們又實現了三級讀寫分離控制,流量管控,數據透明加密,SQL防火牆,日誌審計等功能。
Proxy層結合底層的高可用組件共同實現了MySQL集群的自動化、手動故障轉移,通過RAFT機制保障了高可用管控組件自身的可用性,當然MySQL用的還是主從架構,在同地域可以跨IDC部署,跨地域同步可以用前面提到的DTS產品解決,跨地域多活目前還未支援,這塊屬於規劃中的3.0架構。


Redis作為非常流行和優秀的KV存儲服務,在vivo得到了大量的應用,在vivo互聯網的發展歷程中,有使用過單機版的Redis,也有使用過主從版本的Redis。到目前為止,已經全部升級到集群模式,集群模式的自動故障轉移,彈性伸縮等特性幫我們解決了不少問題。
但當單集群規模擴大到TB級別和單集群節點數擴展到500+以後還是存在很多問題,基於解決這些問題的訴求,我們在Redis上面做了一些改造開發,主要包括三部份:
-
第一是Redis Cluster的多機房可用性問題,為此我們研發了基於Redis Cluster的多活版本Redis。
-
第二是對Redis的數據持久化做了加強,包括AOF日誌改造,AEP硬體的引入,包括正在規劃中的Forkless RDB等。
-
第三是Redis同步和集群模式的增強,包括非同步複製,文件快取,水位控制等,還有對Redis Cluster指令的時間複雜度優化,Redis Cluster指令的時間複雜度曾經給我們的運維帶來了很多的困擾,通過演算法的優化,時間複雜度降低了很多,這塊的程式碼目前已經同步給社區。
我們在Redis上做了這些優化後,發現僅僅有記憶體型的KV存儲是無法滿足業務需要,未來還有更大的存儲規模需求,必須有基於磁碟的KV存儲產品來進行數據分流,對數據進行分層存儲,為此我們研發了磁碟KV存儲產品。

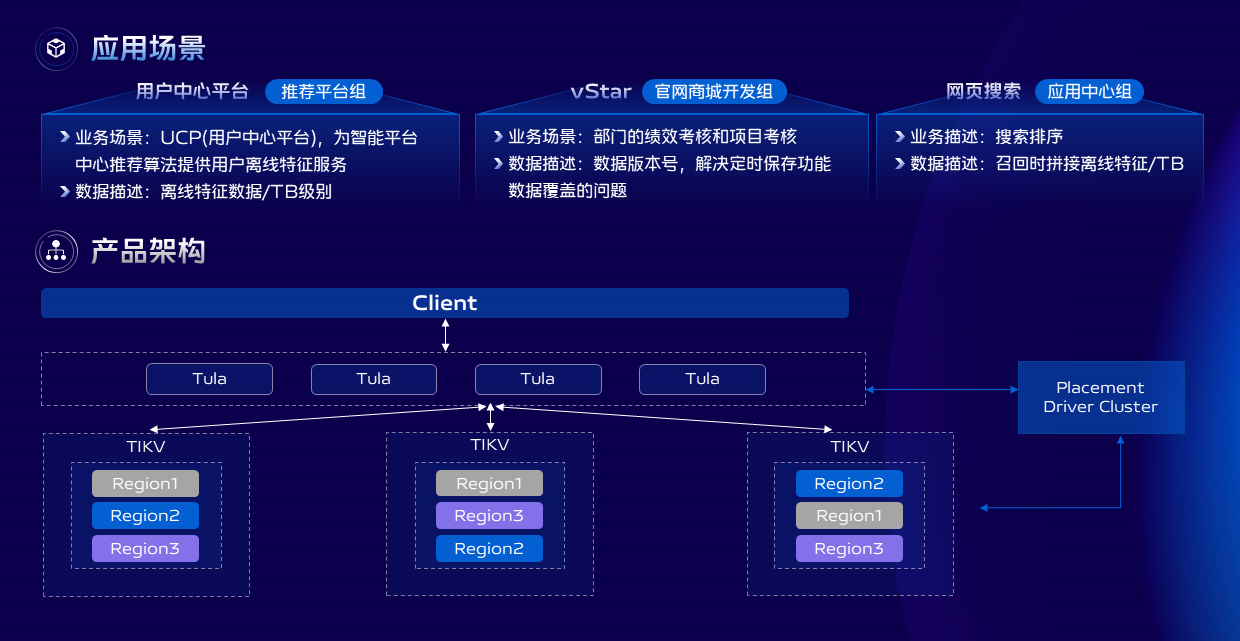
我們在啟動磁碟KV存儲服務研發項目時就明確了業務對存儲的基本訴求。
第一是是兼容Redis協議,可以很方便的從原來使用Redis服務的項目中切換過來。
第二是存儲成本要低,存儲空間要大,性能要高,結合運維的一些基本訴求比如故障自動轉移,能夠快速的擴縮容等。
最終我們選擇了以TIKV作為底層存儲引擎實現的磁碟KV存儲服務,我們在上層封裝了Redis指令和Redis協議。其中選擇TIKV還有一個原因是我們整體的存儲產品體系中有使用到TiDB產品,這樣可以降低運維人員學習成本,能夠快速上手。
我們還開發了一系列周邊工具,比如Bulk load批量導入工具,支援從大數據生態中導入數據到磁碟KV存儲,數據備份還原工具,Redis到磁碟KV同步工具等,這些工具大大的降低了業務的遷移成本,目前我們的磁碟KV存儲產品已經在內部廣泛使用,支撐了多個TB級別的存儲場景。

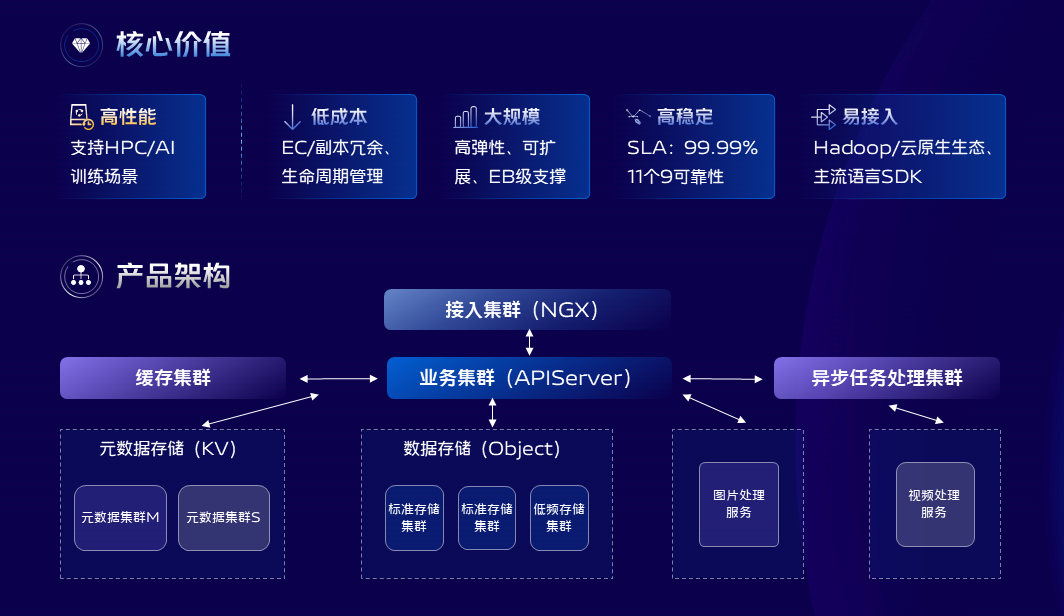
我們知道業務運行過程中除了需要對一些結構化或者半結構化的數據有存取需求之外,還有大量的非結構化數據存取需求。vivo的對象與文件存儲服務正是在這樣的背景下去建設的。
對象和文件存儲服務使用統一的存儲底座,存儲空間可以擴展到EB級別以上,上層對外暴露的有標準對象存儲協議和POSIX文件協議,業務可以使用對象存儲協議存取文件、圖片、影片、軟體包等,標準的POSIX文件協議可以使得業務像使用本地文件系統一樣擴展自己的存取需求,比如HPC和AI訓練場景,可以支撐百億級別小文件的GPU模型訓練。
針對圖片和影片文件,還擴展了一些常用的圖片和影片處理能力,比如水印,縮略圖、裁剪、截禎、轉碼等。前面簡單介紹了vivo資料庫與存儲平台的一些產品能力,那麼下面我們再來聊聊在平台建設過程中,我們對一些技術方向的探索和思考。
三、資料庫與存儲技術探索和思考


在平台建設方面,運維研發效率提升是老生常談的話題,在業內也有很多建設得不錯的平台和產品,但是關於數據存儲這塊怎麼提升運維研發效率講的比較少。
我們的理解是:
-
首先是資源的交付要足夠的敏捷,要屏蔽足夠多的底層技術細節,為此我們將IDC自建資料庫、雲資料庫、雲主機自建資料庫進行雲上雲下統一管理,提供統一的操作視圖,降低運維和研發的使用成本。
-
其次要提升效率就不能只關注生產環境,需要有有效的手段將研發、測試、預發、生產等多種環境統一管控起來,做到體驗統一,數據和許可權安全隔離。
-
最後是我們運用DevOps解決方案的思想,將整個平台邏輯上分為兩個域,一個是研發域,一個是運維域:
在研發域,我們需要思考如何解決研發同學關於資料庫和存儲產品的效率問題。交付一個資料庫實例和支援他們在平台上可以建庫建表是遠遠不夠的,很多操作是發生在編碼過程中的,比如構造測試數據,編寫增刪改查的邏輯程式碼等等。
我們希望在這些過程中就和我們的平台發生交互,最大程度的提升研發效率。
在運維域,我們認為目前有一個比較好的衡量指標就是日常運維過程中需要登錄伺服器操作的次數,將運維的動作全部標準化、自動化,並且未來有一些操作可以智慧化。在研發和運維交互的部分,我們的建設目標是減少交互,流程中參與的人越少效率就越高,讓系統來做決策,實現的方案是做自助化。下面我們在看看安全這塊的一些探索和思考。

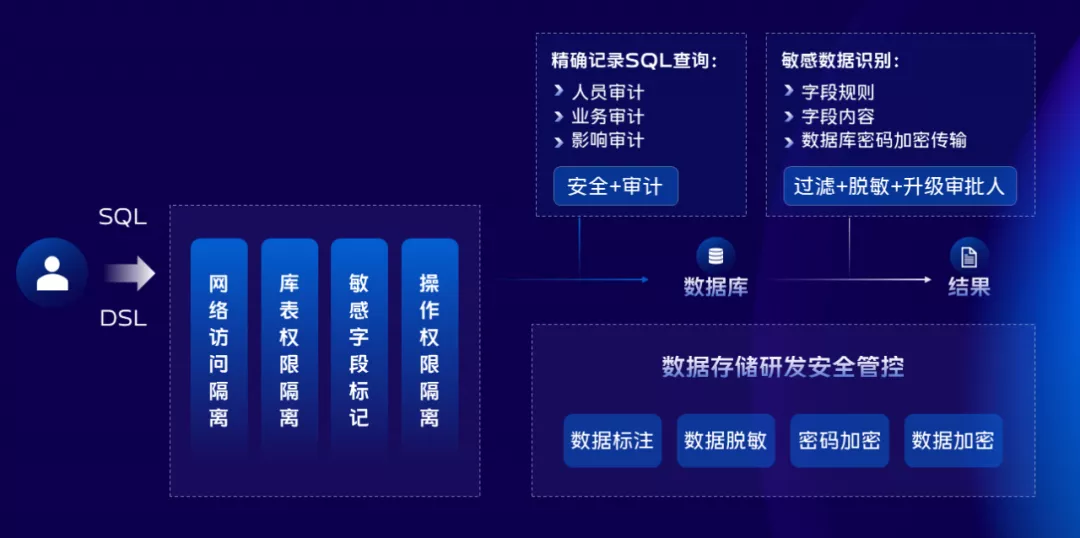
安全無小事,為此我們將資料庫安全和數據安全的部分單獨拿出來進行規劃和設計,基本的原則就是權責分明,資料庫體系涉及到帳號密碼等。
我們聯合SDK團隊共同研發了密碼加密傳輸使用方案,資料庫的密碼對研發、運維而言都是密文,在項目的配置文件中依然是密文,使用時對接公司的密鑰管理系統進行解密。
針對數據的部分,我們聯合安全團隊對敏感數據做了自動標註識別,分類分級,對敏感數據的查詢、導出、變更上做了嚴格的管控,比如許可權管控、許可權升級、通過數字水印技術進行使用追蹤,通過事後的審計可以追溯到誰在什麼時刻查看了什麼數據。針對敏感數據我們也做了透明加解密操作,落盤到存儲介質的數據是經過加密存儲的。
同理,備份的數據和日誌也做了加密存儲,這些是目前我們做的事情,未來安全這塊還有很多的能力需要建設。下面我們再來看看變更這塊。

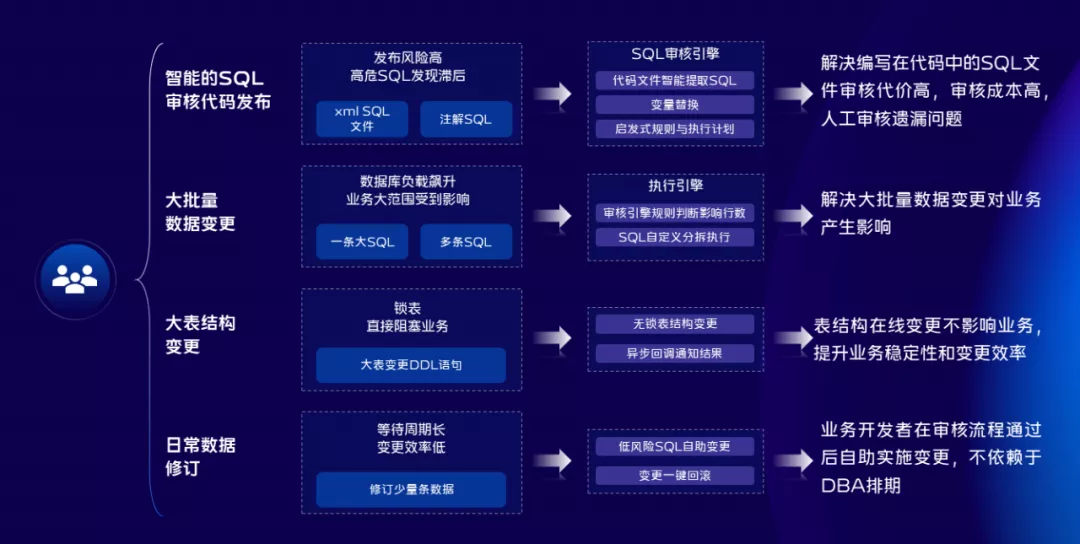
針對數據變更的場景,我們關注的主要有兩點;
-
第一是數據變更本身會不會影響已有的業務,為此我們建設了不鎖表結構、不鎖表數據的變更能力,針對上線前、上線中、上線後三個環節設置三道防線。杜絕一些不好的SQL或者Query流入到生產環境,針對變更過程中或者變更結束後如果想回滾,我們也做了一鍵回滾方案。
-
第二是變更效率問題,針對多個環境、多個集群我們提供了一鍵同步數據變更方案,同時為了更好的提升用戶體驗,我們也提供了GUI的庫表設計平台。有了這些基礎之後,我們將整個場景的能力全部開放給研發同學,現在研發同學可以24小時自助進行數據變更操作,極大的提升了變更效率。
四、探索和思考
接下來我們再介紹下成本這塊的一些思考。
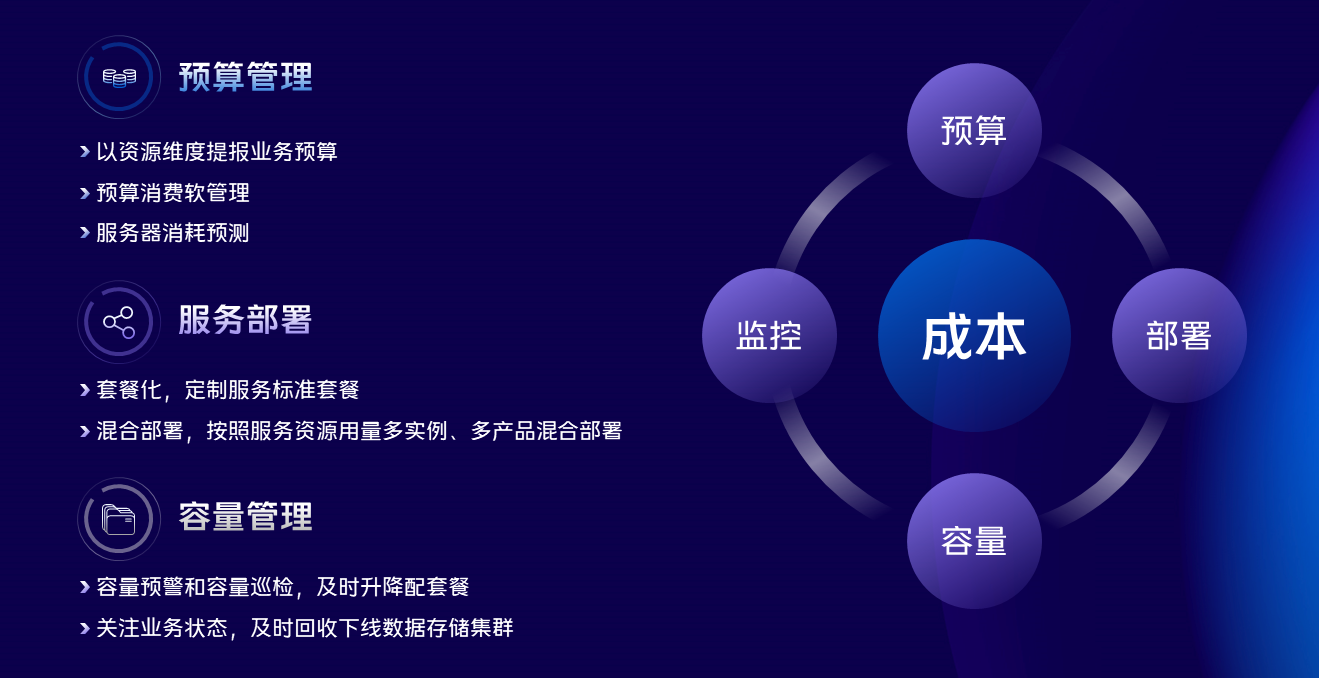
關於成本這塊我們主要從四個方面進行管理;
-
第一是預算的管控,資源去物理化,業務以資源為粒度進行預算提報,在預算管控層面對伺服器的消耗進行預測和不斷的修正,保證水位的健康。
-
第二是資料庫服務的部署,這塊我們經歷了幾個階段,最早期是單機單實例,浪費了很多資源,後面發展為標準化套餐部署,同一類型的存儲資源不同的套餐混合,通過演算法的優化不斷的提升資源的使用效率。
-
第三是我們做了一系列不同屬性資源的混合部署,比如資料庫的代理層和對象存儲的數據節點混合部署,這兩種資源一個是CPU型的,一個是存儲型的,正好可以互補,再往後發展的下一個階段應該是雲原生存儲計算分離,還在探索中。
-
第四是服務部署之後還需要不斷的關注運行中的狀況,對容量做巡檢和預警,對集群及時的做升降配操作,保障整個運行狀態有序。同時需要關注業務運行狀態,及時回收下線數據存儲集群,減少殭屍集群的存在。
成本這塊還有一點就是硬體資源的迭代,這塊也很關鍵,這裡就不做過多的介紹。然後我們再來看下存儲服務體系這塊。

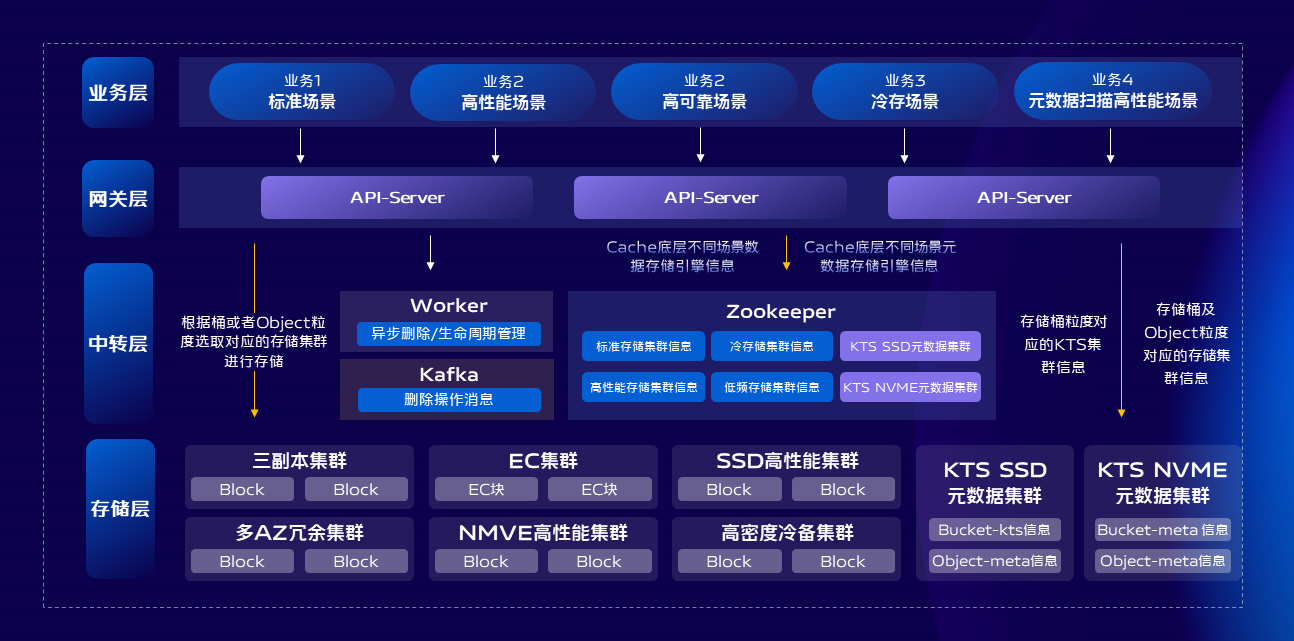
對象與文件存儲這塊我們主要關注的是兩個點;
-
第一個是成本,關於成本這塊我們在數據冗餘策略這塊使用了EC,並且做了跨IDC的EC,單個IDC全部故障也不會影響我們的數據可靠性。我們還引入了高密度大容量存儲伺服器,儘可能多的提升單機架存儲密度,需要注意的是伺服器採購之後的運行成本也不可忽視,依然有很大的優化空間。我們還提供了數據無損和透明壓縮的能力和生命周期管理的能力,及時清理過期數據和對冷數據進行歸檔。通過多種手段持續降低存儲成本。
-
第二是性能,關於性能這塊我們提供了桶&對象粒度底層存儲引擎IO隔離,通過引入一些開源組件如alluxio等提供了服務端+客戶端快取,提升熱點數據讀取性能,在底層存儲引擎這塊我們引入了opencas和IO_URING技術,進一步提升整機的磁碟IO吞吐。
以上就是我們目前在建設的能力的一些探索和思考,最後再來看下我們未來的規劃。
五、未來的規劃
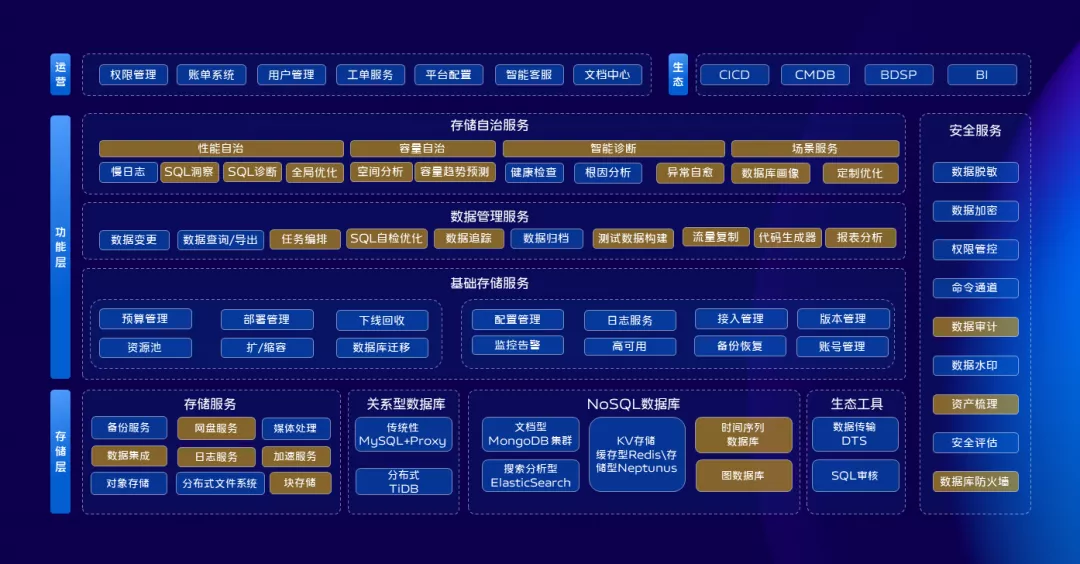
在整個存儲服務層,我們會不斷的完善存儲服務矩陣,打磨產品,提供更多元的存儲產品,更好的滿足業務發展訴求。同時在存儲服務層會基於現有存儲產品做一些SAAS服務來滿足更多的業務訴求。在功能層,我們拆解為4部分:
-
數據基礎服務,這部分提供存儲產品基本功能,包括部署、擴縮容、遷移、監控告警、備份恢復,下線回收等等。
-
數據服務,存儲產品本質上是存儲數據的載體,針對數據本身我們也有一些規範,最基本的比如數據的查詢變更性能優化,數據治理和如何深入到業務編碼過程中去。
-
存儲自治服務,初步劃分為性能自治、容量自治、智慧診斷、場景服務四大塊,通過自治服務一方面可以提升DBA工作的幸福感,一方面也可以大大的提升我們系統本身的健壯性和穩定性。
-
數據安全服務,目前雖然建設了一些能力,但是不夠體系,未來還需要加大投入。
未來整個存儲服務體系會融入到公司整體的混合雲架構中,給用戶提供一站式和標準化的體驗。以上就是分享的全部內容。
作者:vivo互聯網資料庫團隊-Xiao Bo

