第03講:Flink 的編程模型與其他框架比較
Flink系列文章
第01講:Flink 的應用場景和架構模型
第02講:Flink 入門程式 WordCount 和 SQL 實現
第03講:Flink 的編程模型與其他框架比較
本課時我們主要介紹 Flink 的編程模型與其他框架比較。
本課時的內容主要介紹基於 Flink 的編程模型,包括 Flink 程式的基礎處理語義和基本構成模組,並且和 Spark、Storm 進行比較,Flink 作為最新的分散式大數據處理引擎具有哪些獨特的優勢呢?
Flink 的核心語義和架構模型
我們在講解 Flink 程式的編程模型之前,先來了解一下 Flink 中的 Streams、State、Time 等核心概念和基礎語義,以及 Flink 提供的不同層級的 API。
Flink 核心概念
- Streams(流),流分為有界流和無界流。有界流指的是有固定大小,不隨時間增加而增長的數據,比如我們保存在 Hive 中的一個表;而無界流指的是數據隨著時間增加而增長,計算狀態持續進行,比如我們消費 Kafka 中的消息,消息持續不斷,那麼計算也會持續進行不會結束。
- State(狀態),所謂的狀態指的是在進行流式計算過程中的資訊。一般用作容錯恢復和持久化,流式計算在本質上是增量計算,也就是說需要不斷地查詢過去的狀態。狀態在 Flink 中有十分重要的作用,例如為了確保 Exactly-once 語義需要將數據寫到狀態中;此外,狀態的持久化存儲也是集群出現 Fail-over 的情況下自動重啟的前提條件。
- Time(時間),Flink 支援了 Event time、Ingestion time、Processing time 等多種時間語義,時間是我們在進行 Flink 程式開發時判斷業務狀態是否滯後和延遲的重要依據。
- API:Flink 自身提供了不同級別的抽象來支援我們開發流式或者批量處理程式,由上而下可分為 SQL / Table API、DataStream API、ProcessFunction 三層,開發者可以根據需要選擇不同層級的 API 進行開發。
Flink 編程模型和流式處理
我們在第 01 課中提到過,Flink 程式的基礎構建模組是流(Streams)和轉換(Transformations),每一個數據流起始於一個或多個 Source,並終止於一個或多個 Sink。數據流類似於有向無環圖(DAG)。
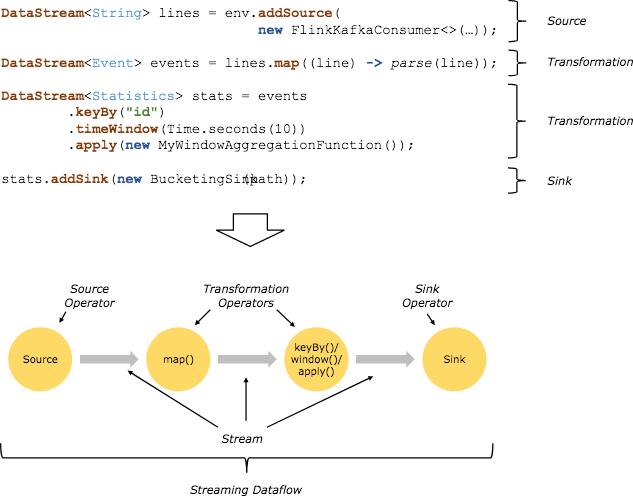
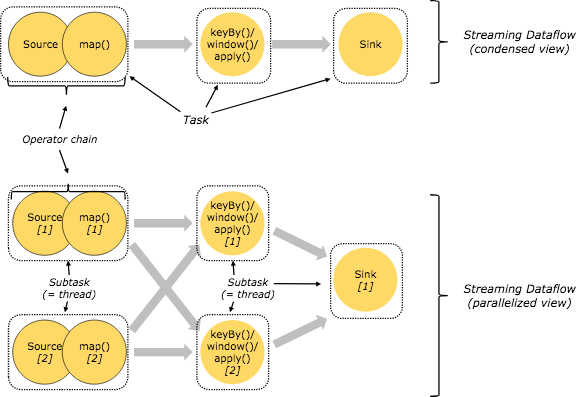
在分散式運行環境中,Flink 提出了運算元鏈的概念,Flink 將多個運算元放在一個任務中,由同一個執行緒執行,減少執行緒之間的切換、消息的序列化/反序列化、數據在緩衝區的交換,減少延遲的同時提高整體的吞吐量。
官網中給出的例子如下,在並行環境下,Flink 將多個 operator 的子任務鏈接在一起形成了一個task,每個 task 都有一個獨立的執行緒執行。
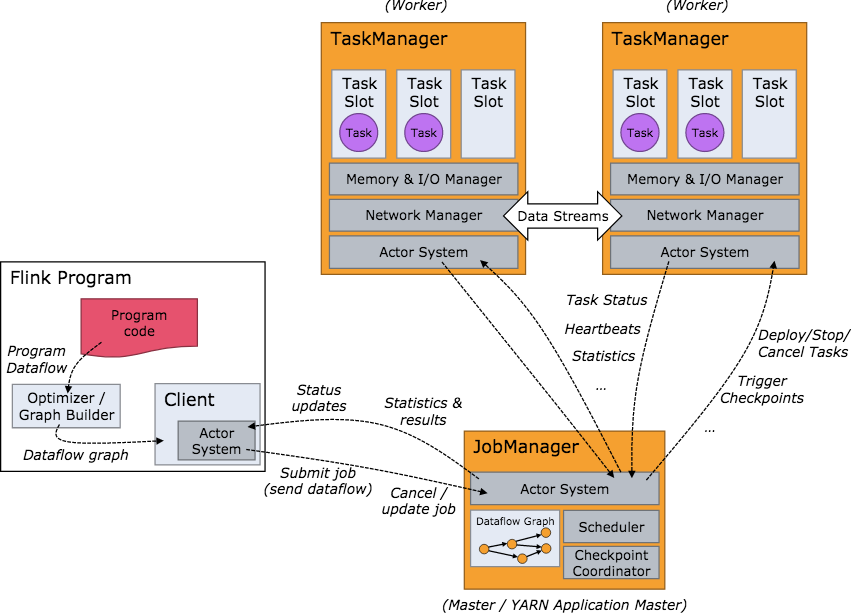
Flink 集群模型和角色
在實際生產中,Flink 都是以集群在運行,在運行的過程中包含了兩類進程。
- JobManager:它扮演的是集群管理者的角色,負責調度任務、協調 checkpoints、協調故障恢復、收集 Job 的狀態資訊,並管理 Flink 集群中的從節點 TaskManager。
- TaskManager:實際負責執行計算的 Worker,在其上執行 Flink Job 的一組 Task;TaskManager 還是所在節點的管理員,它負責把該節點上的伺服器資訊比如記憶體、磁碟、任務運行情況等向 JobManager 彙報。
- Client:用戶在提交編寫好的 Flink 工程時,會先創建一個客戶端再進行提交,這個客戶端就是 Client,Client 會根據用戶傳入的參數選擇使用 yarn per job 模式、stand-alone 模式還是 yarn-session 模式將 Flink 程式提交到集群。
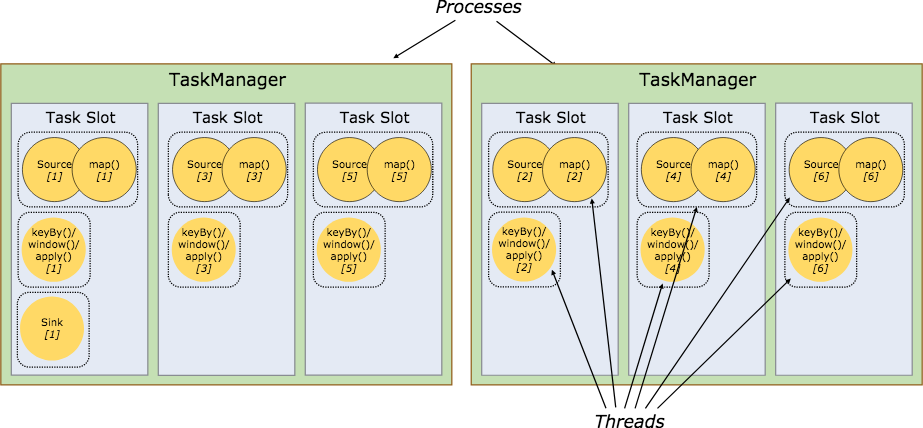
Flink 資源和資源組
在 Flink 集群中,一個 TaskManger 就是一個 JVM 進程,並且會用獨立的執行緒來執行 task,為了控制一個 TaskManger 能接受多少個 task,Flink 提出了 Task Slot 的概念。
我們可以簡單的把 Task Slot 理解為 TaskManager 的計算資源子集。假如一個 TaskManager 擁有 5 個 slot,那麼該 TaskManager 的計算資源會被平均分為 5 份,不同的 task 在不同的 slot 中執行,避免資源競爭。但是需要注意的是,slot 僅僅用來做記憶體的隔離,對 CPU 不起作用。那麼運行在同一個 JVM 的 task 可以共享 TCP 連接,減少網路傳輸,在一定程度上提高了程式的運行效率,降低了資源消耗。

與此同時,Flink 還允許將不能形成運算元鏈的兩個操作,比如下圖中的 flatmap 和 key&sink 放在一個 TaskSlot 里執行以達到資源共享的目的。
Flink 的優勢及與其他框架的區別
Flink 在誕生之初,就以它獨有的特點迅速風靡整個實時計算領域。在此之前,實時計算領域還有 Spark Streaming 和 Storm等框架,那麼為什麼 Flink 能夠脫穎而出?我們將分別在架構、容錯、語義處理等方面進行比較。
架構
Stom 的架構是經典的主從模式,並且強依賴 ZooKeeper;Spark Streaming 的架構是基於 Spark 的,它的本質是微批處理,每個 batch 都依賴 Driver,我們可以把 Spark Streaming 理解為時間維度上的 Spark DAG。
Flink 也採用了經典的主從模式,DataFlow Graph 與 Storm 形成的拓撲 Topology 結構類似,Flink 程式啟動後,會根據用戶的程式碼處理成 Stream Graph,然後優化成為 JobGraph,JobManager 會根據 JobGraph 生成 ExecutionGraph。ExecutionGraph 才是 Flink 真正能執行的數據結構,當很多個 ExecutionGraph 分布在集群中,就會形成一張網狀的拓撲結構。
容錯
Storm 在容錯方面只支援了 Record 級別的 ACK-FAIL,發送出去的每一條消息,都可以確定是被成功處理或失敗處理,因此 Storm 支援至少處理一次語義。
針對以前的 Spark Streaming 任務,我們可以配置對應的 checkpoint,也就是保存點。當任務出現 failover 的時候,會從 checkpoint 重新載入,使得數據不丟失。但是這個過程會導致原來的數據重複處理,不能做到「只處理一次」語義。
Flink 基於兩階段提交實現了精確的一次處理語義,我們將會在後面的課時中進行完整解析。
反壓(BackPressure)
反壓是分散式處理系統中經常遇到的問題,當消費者速度低於生產者的速度時,則需要消費者將資訊回饋給生產者使得生產者的速度能和消費者的速度進行匹配。
Stom 在處理背壓問題上簡單粗暴,當下游消費者速度跟不上生產者的速度時會直接通知生產者,生產者停止生產數據,這種方式的缺點是不能實現逐級反壓,且調優困難。設置的消費速率過小會導致集群吞吐量低下,速率過大會導致消費者 OOM。
Spark Streaming 為了實現反壓這個功能,在原來的架構基礎上構造了一個「速率控制器」,這個「速率控制器」會根據幾個屬性,如任務的結束時間、處理時長、處理消息的條數等計算一個速率。在實現控制數據的接收速率中用到了一個經典的演算法,即「PID 演算法」。
Flink 沒有使用任何複雜的機制來解決反壓問題,Flink 在數據傳輸過程中使用了分散式阻塞隊列。我們知道在一個阻塞隊列中,當隊列滿了以後發送者會被天然阻塞住,這種阻塞功能相當於給這個阻塞隊列提供了反壓的能力。
總結
本課時主要介紹了 Flink 的核心語義和架構模型,並且從架構、容錯、反壓等多方位比較了 Flink 和其他框架的區別,為後面我們學習 Flink 的高級特性和實戰打下了基礎。
以上就是本課時的內容。在下一課時中,我將介紹「Flink 常用的 DataSet 和 DataStream API」,下一課時見。
關注公眾號:
大數據技術派,回復資料,領取1024G資料。

