IEEE754浮點數表示法
- 2022 年 1 月 24 日
- 筆記
IEEE二進位浮點數算術標準(ANSI/IEEE Std 754-1985)是一套規定如何用二進位表示浮點數的標準。就像「補碼規則」建立了二進位位和正負數的一一對應關係一樣,IEEE754規則說明了一個從二進位狀態到實數集的一一映射的規則(當然事實上狀態有限而實數無限,叫做「單射」更為合適)。
IEEE754的初標準在1985年發布,也是現在廣為流傳的版本,被大多數語言所採用。事實上後來已經有了更新的標準了,不過兩者間沒有太大的區別。因此了解老標準就可以。
浮點數是如何存儲的
標準提供了四種最常見的規範:
- 單精度(single)浮點(32bit)
- 雙精度(double)浮點(64bit)
- 延伸單精度(extended single)浮點(43bit以上,很少用到)
- 延伸雙精度(extended double)浮點(79bit以上)。
沿用C/C++習慣,可以用float代指32位單精度浮點、double代表64位雙精度浮點。以下主要以較短的float進行說明。
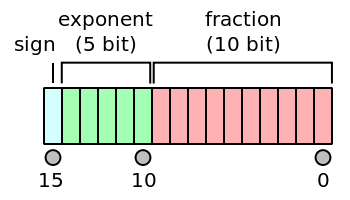
一個32位float型數用科學計數法表示,由符號位1位(sign)、指數位8位(exponent)和小數位23位(fraction)組成,在圖裡從左到右排列。

一個64位double型數由符號位1位、指數位11位和小數位52位組成,在圖裡從左到右排列。

- 符號位:1位,
0表示正數,1表示負數 - 指數位:8/11位表示指數。可以表示256/2048種狀態。
然而指數是可正可負的。在標準里,我們沒有選擇用”補碼規則”表示負數,而是選擇直接向左平移(又叫階碼)。8位範圍是\([0,255]\),我們將它向左平移一半(取127),就變成了\([-127,128]\),也就是說指數位減去127才是真實的指數(比如12(00001100)代表-125次方)。這裡減去的數叫偏移量(biase),對單精度來說是127,對雙精度來說是1023。 - 小數位:23/52位,表示底數。顯然底數的長度決定了類型的精度,決定了到底能存幾位有效數字,而指數位只是表示小數點的位置
二進位里的科學計數法
十進位和二進位的互化大家都很熟悉,但是一般僅限於整數,許多計算器軟體在二進位下甚至不能輸入小數點。
不過小數的轉化其實也是一個道理:對於整數位來說,第\(i\)位的1代表\(2^i\),而小數點後的第\(i\)位1則代表\(2^{-i}\)。比如\(110.101_{bit}=4+2+\frac 12 +\frac 18=6.625\)
將十進位數化為二進位數就反過來弄:小數部分大於0.5,則第一位為1,小數部分”模0.5″後大於0.25,則第二位為1。。。比如\(0.875=0.111_{bit}\)
在十進位中,如果用科學計數法表示數,最規範的表示就是讓底數的小數點之前僅有一位非零整數,便於用指數表示數量級。在二進位中,我們也這樣干,並且可以得到更特殊的性質:二進位中的”非零整數”只能是1。也就是任意一個不是太接近0的數都可以表示為\(1.xxxx \times 2^{exp}\)的形式。因此在表示小數位時,我們將這個首位1省略,只保存小數部分,顯然對於一個不是太接近0的數,這樣的表示都是益於節省空間提高精度的。
寫出一個數的浮點表示
-
實戰演練:將\(78.625\)轉化為浮點數形式。
\(78.625\)的二進位形式是\(1001110.101\),即\(1.001110101\times 2^6\),而指數位\(6+127=133=10000101_{bit}\),將底數的小數位後面補0到23位,得答案01000010100111010100000000000000 -
在C++中,浮點數是不能給二進位位賦值的。但是我們可以將32位整數賦值為對應的數,再用float指針來解析它,驗證結果(後文也會寫成16進位,節省空間)。

特殊的浮點位
IEEE754標準還提供了浮點數中一些特殊狀態的表示。
非規約數 & 正零和負零
上述規則描述的是常規範圍內的數如何表示,他們可以叫做規約數(normal number)。高位1的省略可以節省空間。這樣最接近0的數(即0x00000000)值為\(\pm 2^{-127}\)
但是如果一個數太小,他的第一位有效數字(當然指二進位)在127位以後呢?即使小數點右移127位,最高位仍然是0,不能表示更小的數了。
為了表示更小的數,在指數位全為0時,我們丟掉最高位為1的束縛,將最高位規定為0,將”全0指數位”規定為-126而不是本來的-127,用於表示絕對值小於\(2^{-126}\)的數。
比如00000000000101000000000000000000,其值為\(0.00101\times 2^{-126}=1.01*\times 2^{-129}\),表示出了更小的數。在這樣的規則下,最接近0的數(即0x00000001)值為\(\pm 2^{(-127-23)=-149}\),而全零位用來存儲0。
這樣的「全零位」,由於符號原因有兩種(0x00000000和0x80000000),他們用於表示正零和負零。高級應用層面對於正零和負零的判定各不相同。在C++,正零和負零是相等的,並且都對應布爾值false(儘管負零的符號位)。我們不關心,我們只需要知道IEEE支援兩種零的表示,並且在運算過程一個理論答案為零的結果既可能被計算為正零,也可能被計算為負零。
逐漸溢出
規格數的最小值為\(0(00000001)0..0_{bit}=2^{-126}\),非規格數的最大值為\(0(0..0)1..1_{bit}=(1-2^{-23})2^{-126}\),基本可以看做\(2^{-126}\)的開區間,從非規格數過渡到規格數時,相當於指數-126不變,底數進位到隱藏的高位。從而實現了平穩的值域過渡,剛好覆蓋了實數軸,這種特性叫做逐漸溢出(gradual overflow)
更有意思的是,當二進位碼從0x00000000不斷遞增時,他表示的浮點數值也是逐漸遞增的。對於非規約數到規約數來說表現為”逐漸溢出”;對於規約數來說,小數部分沒有全滿的情況顯然;而每當小數位全為1時,再下一個數應該是”逢二進一”(小數位清零,指數位加一),就好像小數位像指數位進位了一樣(比如0(0..01)11..11對應浮點數的下一個數是0(0..10)00..00,而0(0..01)11..11對應整數的下一個數也是0(0..10)00..00)!根據這個特性,我們也可以對浮點數進行基數排序(先劃分正負,同號的數將後31位任意切割為多個關鍵字後分別排序)。
無窮
為了表示狀態”無窮”,同樣只能從指數上動手腳。我們把指數全為1的狀態”挖掉”,用於表示無窮等狀態,如果一個數指數位全為1,小數位全為0,那麼這個數就表示無窮。
顯然無窮有兩種,\(0(1..1)0..0_{bit}\)對應正無窮0x7f800000,\(1(1..1)0..0_{bit}\)對應負無窮0xff800000。無窮支援一些數學意義上的運算:
- 同號無窮被認為相等,正無窮>所有規約數>負無窮
- 無窮與規約數進行四則運算仍是無窮
C++用1/0.0或者1e1000或者1e10000000賦值就可以得到一個無窮,他們都是一樣的無窮,本質上是表示”超過存儲範圍”。可以輸出無窮,表示為inf和-inf。
非數值
實數範圍里,有一些計算是沒有結果,無法進行的。在標準里同樣規定了一類數,用於保存這類結果,他們叫做非數值(not a number)。非數值與無窮一樣使用全為1的指數位表示,為了區分開來,小數位全為0時表示無窮,其他所有情況表示非數值情況。
顯然很多狀態都可以表示非數值,但是他們不被加以區分,也不分+NaN或者-NaN,同時也不能參與運算。
-
C++中,NaN與任何數的算數比較將返回
false。即使是自身之間(實際上NaN==NaN、NaN<NaN、NaN>NaN均為假,只有NaN!=NaN為真)。NaN自身轉化為bool值後為true -
任何NaN參加的運算,結果仍然是NaN
C++中用sqrt(-1)、0.0/0.0或者inf-inf都將得到NaN,可以將其輸出,表示為nan。

浮點數的範圍和精度

對於32位規約數來說,指數位包括\([-127,128]\),但是左右端點用來表示特殊數了,因此實際指數位\([-126,127]\)
首先是範圍,這個很好計算。不妨只考慮正數,前面已經計算過最小的規約數為\(2^{-126}\),而最大的規約數應該是\(0(11111110)1..1_{bit}\approx 2\times 2^{127}=2^{128}\),因此極限範圍就是\([2^{-126},2^{128})\),轉化為十進位就約是\([1.175\times 10^{-38},3.403\times 10^{38}]\)。如果算上非規約數0x00000001,下界可以達到\(2^{-149} \approx 1.401\times 10^{-45}\)。
而關於精度也不難計算,精度即底數有效數字的位數,底數有23位,那麼可以表示\(2^{23}\approx 10^{6.92}\)種有效數字,即兩個形如\(1.xxxxx\)的23位數大致可以和十進位下的7位小數一一對應,7位以後不同的數字只能對應到同一個二進位數上。
浮點數是離散不均勻儲存的
對於整數來說,32位二進位碼與\([0,2^{32})\)的數一一對應,是多少就是多少。\([0,2^{32})\)里的全體整數可以看作對應關係的”值域”(一張數表)。如果賦值int a=3.4呢,值域里沒有這個數!於是只能將它存為值域里最相鄰的兩個點之一(C++中浮點階段為整數的規則是向0取整(做圖時寫錯了應該是3),但是你也可以處理為向上取整,向下取整,或者四捨五入)。

而對於浮點數來說(仍以float為例),32位二進位碼最多只能對應\(2^{32}\)個數,但是實數是無窮無盡的!因此,按照上面規則,除去無窮和非數值,每個狀態計算出一個實數組成值域,float只能表示這些有限多的實數,對於不在”值域”內的數,只能選擇將他存儲為相鄰的兩個點之一(8388607.2在float範圍里,但float的數表裡沒有這個數)。

顯然,相鄰兩個數越近,誤差越小,精度越高,小數部分越長,越能支援更大精度。如果只考慮同一個類型,float的精度是多少呢?
我們從1開始計算,1的表示為\(1*2^0\),1的下一個數是\((1+2^{-23})*2^0\),再下一個數是\((1+2^{-22})*2^0\),由於實際指數為0,因此小數位每移動1,值就移動\(2^{-23}\approx 1.19\times 10^{-7}\)。
但是在2048附近呢?2048的表示為\(1*2^{11}\),下一個數\((1+2^{-23})*2^{11}\),再下一個數是\((1+2^{-22})*2^{11}\),誤差增大到了\(2^{-12}\approx 2.4\times 10^{-4}\)。
規律已經很顯然了,和整數完全不同,浮點數的間隔是變化的,離0越遠,間隔越大,並且每通過一個\(2^i\),指數位就增大1,間隔增大一倍。用剛剛有效數字來理解,有效數字只有大約7位,隨著整數部分越來越大,小數部分的位數會越來越短,在上圖,間隔已經達到0.5,只能儲存整數和”整數.5″。在數據達到\(2^{23}=8388608\)以後,間隔達到1,小數部分消失,小數都會舍入到整數。數據達到\(2^{24}=16777216\)以後.間隔變為2,已經不能精確存儲整數了。


這也可以說明為什麼float的範圍看起來如此誇張,因為這不算真的可用範圍,只是表示無窮以下的最大值而已。這個數可以表示為\(2^{60}\),卻不能表示\(2^{60}+1\),也不能表示\(2^{60}+1e9\),他的下一個數是\(2^{60}+2^{37}\),這是完全不可用的。
冷知識:《我的世界》中當水平坐標超過一千萬時,影像扭曲,載入異常,默認情況不能出現的5格跳,以及最終出現的邊境之地等都被認為是浮點誤差太大引起的

進位影響真實的儲存位數
為什麼0.1+0.2=0.300000000004?,一位有效數字也不能精確儲存了?這是因為0.1和0.2知識看上去的一位,實際上是無限小數。
我們知道任何\(\frac pq\)只有在分母的因子都能被進位整除才能寫成有限小數。比如10的因子只有2和5。所以\(\frac p{2^n5^m}\)無論分母多大也能除得盡。但\(\frac 13\)一個簡單的數卻只能寫成無限不循環。在之前的例子里,二進位有限小數化為十進位當然有限(顯然),但十進位有限在二進位下不一定有限,因為二進位無法把數五等分。
-
0.2,按照開篇的規則,應該對應\(0.0011\ 0011\ 0011…_{bit}\),在某一位後截斷在存儲,實際值不是0.2,是值域中最接近0.2的數。
-
0.99993896484375,儘管遠大於7位,但它可以在二進位下完全表示\(1-2^{-14}=0.11111111111111_{bit}\),因此完全儲存在了float中, 體現出了超乎尋常的精度。
所以之前提到的精度只是約值,而且其意義應該是相鄰兩數的間隔值,即”存儲值和實際值相減後大約第7位才有明顯誤差”。絕不是說”7位以下的數字能精確存儲,7位以上的就截斷到7位”。
其他類型的浮點數
以上說的都是32位,其實對於64位來說也是一樣的,更進一步來說,現在的標準還指定各種位數浮點數的存儲標準,一般來講,位數越長,小數位越多,有效數字越多;同時指數位也越多,最大範圍更大。雖然範圍不一樣,但他們的標準是一樣的。
-
半精度(Half)(16bit)
-
四精度(Quadruple)(128bit)

-
八精度(Half)(256bit)

-
延伸精度與上面的又不太一樣。(就好像32位整數相乘時,要取到64位一樣)延伸精度可以視為”精度運算的中間變數”。延伸雙精度定為79位以上,便於執行比雙精度更精確的計算。一些儲存標準中為擴展精度提供了專門的最高位。按照維基百科最高位的存在使延伸精度可以表示更多”額外狀態”,比如運算中的精度損失。C++里
long double可以實現延伸雙精度,長度為80/96/128位。





