第59篇-編譯策略
- 2022 年 1 月 22 日
- 筆記
在執行OSR或方法編譯時,調用AdvancedThresholdPolicy::common()函數決定編譯策略,這樣才能在SimpleThresholdPolicy::submit_compile()函數提交編譯任務。common()函數的實現如下:
CompLevel AdvancedThresholdPolicy::common(
Predicate p,
Method* method,
CompLevel cur_level,
// 當為OSR編譯時,如下參數為true,方法編譯時,為false
bool disable_feedback
) {
CompLevel next_level = cur_level;
int i = method->invocation_count();
int b = method->backedge_count();
// 當一個方法足夠簡單時,使用C1編譯器就能達到C2的效果
if (is_trivial(method)) {
next_level = CompLevel_simple;
} else {
switch(cur_level) {
case CompLevel_none:
// 當前的編譯級次為ComLevel_none,可能會直接到CompLevel_full_optimization級別,如果Metod::_method_data
// 不為NULL並且已經採集了足夠資訊的話
if (common(p, method, CompLevel_full_profile, disable_feedback) == CompLevel_full_optimization) {
next_level = CompLevel_full_optimization;
}
// 調用AdvancedThresholdPolicy::call_predicate()或AdvancedThresholdPolicy::loop_predicate()函數,
// 函數如果返回true,表示已經充分收集了profile資訊,可直接採用第3層的CompLevel_full_profile編譯
else if ((this->*p)(i, b, cur_level)) {
// 在 C2 忙碌的情況下,方法會被CompLevel_limited_profile的C1編譯,然後再被
// CompLevel_full_profile的C1編譯,目的是減少方法在CompLevel_full_profile的執行時間
// Tier3DelayOn的英文解釋為:If C2 queue size grows over this amount per compiler thread
// stop compiling at tier 3 and start compiling at tier 2
if (!disable_feedback && CompileBroker::queue_size(CompLevel_full_optimization) >
Tier3DelayOn * compiler_count(CompLevel_full_optimization)) {
next_level = CompLevel_limited_profile;
} else { // C2如果不忙碌,直接使用CompLevel_full_profile的C1編譯即可
next_level = CompLevel_full_profile;
}
}
break;
case CompLevel_limited_profile:
if (is_method_profiled(method)) {
// 特殊情況下,可能解釋執行過程中已經採集了足夠的運行時資訊,直接採用CompLevel_full_optimization的C2編譯
next_level = CompLevel_full_optimization;
} else {
MethodData* mdo = method->method_data();
if (mdo != NULL) {
if (mdo->would_profile()) {
// 如果C2的負載不高時,採用CompLevel_full_profile進行資訊的採集
// Tier3DelayOff的英文解釋為:If C2 queue size is less than this amount per compiler thread
// allow methods compiled at tier 2 transition to tier 3
if (disable_feedback || (CompileBroker::queue_size(CompLevel_full_optimization) <=
Tier3DelayOff * compiler_count(CompLevel_full_optimization) &&
(this->*p)(i, b, cur_level))) {
next_level = CompLevel_full_profile;
}
} else {
next_level = CompLevel_full_optimization;
}
}
}
break;
case CompLevel_full_profile:
{
MethodData* mdo = method->method_data();
if (mdo != NULL) {
if (mdo->would_profile()) {
int mdo_i = mdo->invocation_count_delta();
int mdo_b = mdo->backedge_count_delta();
if ((this->*p)(mdo_i, mdo_b, cur_level)) {
next_level = CompLevel_full_optimization;
}
} else {
next_level = CompLevel_full_optimization;
}
}
}
break;
}
}
return MIN2(next_level, (CompLevel)TieredStopAtLevel);
}
通過如上函數,我們能夠看到HotSpot VM對OSR和方法的編譯策略,編譯層級從一個層級轉換到另外一個層級參考的主要指標有:方法統計的運行時資訊和編譯器執行緒的負載情況。下面我們詳細介紹一下編譯策略,首先介紹一下編譯層級。AdvancedThresholdPolicy支援5個級別的編譯,這5個級別通過CompLevel枚舉類定義,如下:
源程式碼位置:openjdk/hotspot/src/share/vm/utilites/globalDefinitions.hpp
enum CompLevel {
CompLevel_any = -1,
CompLevel_all = -1,
// level 0:解釋執行
CompLevel_none = 0,
// level 1:執行不帶profiling的C1程式碼
CompLevel_simple = 1,
// level 2:執行僅帶方法調用次數以及循環回邊執行次數profiling的C1程式碼
CompLevel_limited_profile = 2,
// level 3:執行帶所有profiling的C1程式碼
CompLevel_full_profile = 3,
// level 4:執行C2程式碼
CompLevel_full_optimization = 4,
// 在分層編譯的情況下僅使用C2進行編譯,值為4,也就是level 4
CompLevel_highest_tier = CompLevel_full_optimization,
CompLevel_initial_compile = CompLevel_full_profile
};
方法和OSR執行的編譯策略路徑如下圖所示。
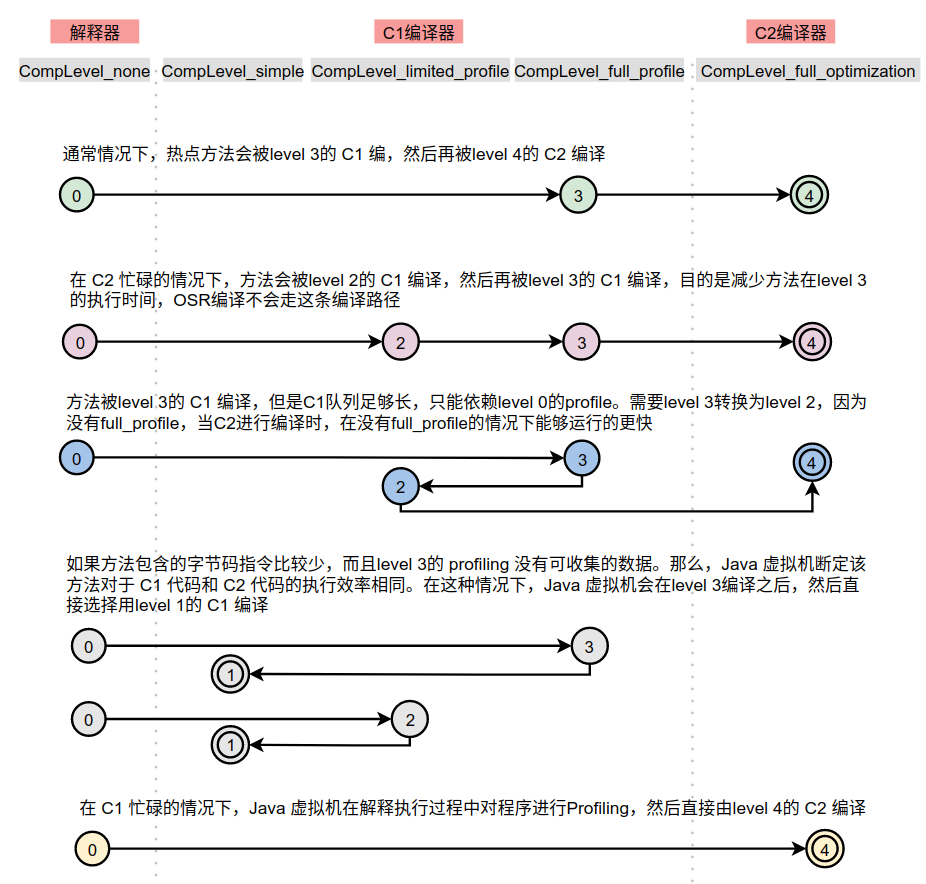
其中0、2、3這三個層級下都會周期性的通知AdvancedThresholdPolicy某個函數的方法調用計數(invocation counters)和循環調用計數(backedge counters),不同級別下通知的頻率不同。這些通知用來決定如何調整編譯層級,所以最終會形成不同的編譯路徑。
在 5 個層次的執行狀態中,CompLevel_simple和CompLevel_full_optimization為終止狀態。當一個方法被終止狀態編譯後,如果編譯後的程式碼沒有失效,那麼Java虛擬機是不會再次發出對該方法的編譯請求的。
下面我們從另外一個角度解讀上圖中的編譯路徑。
1、在CompLevel_none下不執行任何編譯,仍然是解釋執行
當某個方法剛開始執行時,通常會解釋執行。
當C1和C2的編譯任務隊列的長度足夠短,也可在CompLevel_none下開啟profile資訊收集。編譯隊列通過優先順序隊列實現,每個添加到編譯任務隊列的方法都會周期的計算其在單位時間內增加的調用次數,每次從編譯隊列中獲取任務時,都選擇單位時間內調用次數最大的一個。基於此,我們也可以將那些編譯完成後不再使用,調用次數不再增加的方法從編譯任務隊列中移除。
如果當前的編譯層級為CompLevel_none,可能會變為CompLevel_limited_profile、CompLevel_full_profile、CompLevel_full_optimization編譯層級。
2、CompLevel_none調整為CompLevel_limited_profile或CompLevel_full_profile
AdvancedThresholdPolicy會綜合如下兩個因素和調用計數將編譯級別調整為CompLevel_limited_profile或CompLevel_full_profile:
- C2編譯任務隊列的長度決定了下一個編譯級別。據觀察,CompLevel_limited_profile級別下的編譯比CompLevel_full_profile級別下的編譯快30%,因此我們應該在只有已經收集了充分的profile資訊後才採用CompLevel_full_profile編譯,從而儘可能縮短CompLevel_full_profile級別下編譯的耗時。當C2的編譯任務隊列太長的時候,如果選擇CompLevel_full_profile則編譯會被卡住直到C2將之前的編譯任務處理完成,這時如果選擇CompLevel_limited_profile編譯則很快完成編譯。當C2的編譯壓力逐步減小,就可以重新在CompLevel_full_profile下編譯並且開始收集profile資訊;
- 根據C1編譯任務隊列的長度動態的調整閾值,在編譯器過載時,將打算編譯但是不再被調用的方法從編譯隊列中移除。
3、CompLevel_full_profile調整為CompLevel_limited_profile、CompLevel_simple、CompLevel_full_optimization
當CompLevel_full_profile下profile資訊收集完成後就會轉換成CompLevel_full_optimization了,可以根據C2編譯任務隊列的長度來動態調整轉換的閾值。當經過C1編譯完成後,基於方法的程式碼塊的數量,循環的數量等資訊可以判斷一個方法是否是瑣碎(trivial)的,這類方法在C2編譯下會產生和C1編譯一樣的程式碼,因此這時會用CompLevel_simple的編譯代替CompLevel_full_optimization的編譯。
4、CompLevel_full_profile調整為CompLevel_full_optimization
注意CompLevel_full_profile並不是終態,一般到了這個層次的編譯任務最終都需要C2編譯器承擔CompLevel_full_optimization層級的編譯任務,所以我們才會看到,當編譯層級由其它的調整為CompLevel_full_profile時,通常會判斷C2的負載能力。
前面介紹過, 編譯層級從一個層級轉換到另外一個層級參考的主要指標還需要參考運行時收集的資訊,OSR編譯主要是調用AdvancedThresholdPolicy::loop_predicate()函數,如下:
bool AdvancedThresholdPolicy::loop_predicate(int i, int b, CompLevel cur_level) {
switch(cur_level) {
case CompLevel_none:
case CompLevel_limited_profile: {
// Tier3LoadFeedback的值默認為5,Tier 3 thresholds will increase twofold
// when C1 queue size reaches this amount per compiler thread
double k = threshold_scale(CompLevel_full_profile, Tier3LoadFeedback);
return loop_predicate_helper<CompLevel_none>(i, b, k);
}
case CompLevel_full_profile: {
// Tier4LoadFeedback的值默認為3,
double k = threshold_scale(CompLevel_full_optimization, Tier4LoadFeedback);
return loop_predicate_helper<CompLevel_full_profile>(i, b, k);
}
default:
return true;
}
}
調用的threshold_scale()函數的實現如下:
double AdvancedThresholdPolicy::threshold_scale(CompLevel level, int feedback_k) {
double queue_size = CompileBroker::queue_size(level); // 編譯隊列中編譯任務的數量
int comp_count = compiler_count(level); // 編譯器執行緒數量
double k = queue_size / (feedback_k * comp_count) + 1;
// 獲取CodeCache的剩餘可用空間,如果不足,則增加C1編譯的閾值,從而為C2編譯保留足夠的空間
if ((TieredStopAtLevel == CompLevel_full_optimization) && (level != CompLevel_full_optimization)) {
double current_reverse_free_ratio = CodeCache::reverse_free_ratio();
if (current_reverse_free_ratio > _increase_threshold_at_ratio) {
k *= exp(current_reverse_free_ratio - _increase_threshold_at_ratio);
}
}
return k;
}
當隊列的任務越多時,scale的值越大;當編譯的執行緒數量越多時,值越小。
調用的loop_predicate_helper()函數的實現如下:
template<CompLevel level>
bool SimpleThresholdPolicy::loop_predicate_helper(int i, int b, double scale) {
switch(level) {
case CompLevel_none:
case CompLevel_limited_profile:
// 回邊計數>60000*2
return b > Tier3BackEdgeThreshold * scale;
case CompLevel_full_profile:
// 回邊計數>40000*2
return b > Tier4BackEdgeThreshold * scale;
}
return true;
}
scale越小時,滿足如上函數的判斷條件需要的回邊計數值就越小,如上函數在返回true後,通常在編譯策略中會將編譯層次調整為更高的級別。scale的值是通過調用threshold_scale()函數決定的,也就是隊列中任務越多時,如上函數返回false的機率越大,編譯執行緒數量越多時,如上函數返回true的機率越大。這樣就能很好的控制編譯任務的數量。
編譯方法時,調用的是call_predicate()函數,此函數的實現如下:
bool AdvancedThresholdPolicy::call_predicate(int i, int b, CompLevel cur_level) {
switch(cur_level) {
case CompLevel_none:
case CompLevel_limited_profile: {
double k = threshold_scale(CompLevel_full_profile, Tier3LoadFeedback);
return call_predicate_helper<CompLevel_none>(i, b, k);
}
case CompLevel_full_profile: {
double k = threshold_scale(CompLevel_full_optimization, Tier4LoadFeedback);
return call_predicate_helper<CompLevel_full_profile>(i, b, k);
}
default:
return true;
}
}
template<CompLevel level>
bool SimpleThresholdPolicy::call_predicate_helper(int i, int b, double scale) {
switch(level) {
case CompLevel_none:
case CompLevel_limited_profile:
return
// 方法調用>200 * 2
(i > Tier3InvocationThreshold * scale) ||
// ( 方法調用>100*2 && (方法調用+回邊計數)>2000*2 )
(i > Tier3MinInvocationThreshold * scale && i + b > Tier3CompileThreshold * scale);
case CompLevel_full_profile:
return
// 方法調用>5000*2
(i > Tier4InvocationThreshold * scale) ||
// ( 方法調用>600*2 && (方法調用+回邊計數)>15000*2 )
(i > Tier4MinInvocationThreshold * scale && i + b > Tier4CompileThreshold * scale);
}
return true;
}
實現的邏輯與回邊的判斷差不多,只不過方法編譯時,還會考慮到回邊計數。
公眾號 深入剖析Java虛擬機HotSpot 已經更新虛擬機源程式碼剖析相關文章到60+,歡迎關注,如果有任何問題,可加作者微信mazhimazh,拉你入虛擬機群交流


