VAE變分自編碼器
我在學習VAE的時候遇到了很多問題,很多部落格寫的不太好理解,因此將很多內容重新進行了整合。
我自己的學習路線是先學EM演算法再看的變分推斷,最後學VAE,自我感覺這個線路比較好理解。
一.首先我們來宏觀了解一下VAE的作用:數據壓縮和數據生成。
1.1數據壓縮:
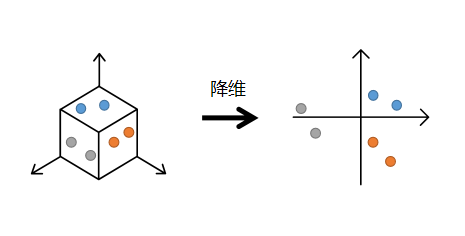
數據壓縮也可以成為數據降維,一般情況下數據的維度都是高維的,比如手寫數字(28*28=784維),如果數據維度的輸入,機器的處理量將會很大, 而數據經過降維以後,如果保留了原有數據的主要資訊,那麼我們就可以用降維的數據進行機器學習模型的訓練和預測,由於數據量大大縮減,訓練和預測的時間效率將大為提高。還有一種好處就是我們可以將數據降維至2D或3D以便於觀察分布情況。
平常最常用到的就是PCA(主成分分析法:將原來的三維空間投影到方差最大且線性無關的兩個方向或者說將原矩陣進行單位正交基變換以保留最大的資訊量)。
1.2數據生成:
近年來最火的生成模型莫過於GAN和VAE,這兩種模型在實踐中體現出極好的性能。
所謂數據的生成,就是經過樣本訓練後,人為輸入或隨機輸入數據,得到一個類似於樣本的結果。
比如樣本為很多個人臉,生成結果就是一些人臉,但這些人臉是從未出現過的全新的人臉。又或者輸入很多的手寫數字,得到的結果也是一些手寫數字。而給出的數據可能是一個或多個隨機數,或者一個分布。然後經過神經網路,將輸入的數據進行放大,得到結果。
1.3相互聯繫:
那麼可能有人有疑問:VAE中數據壓縮與數據生成有什麼關係呢?
我們剛剛講過,在數據生成過程中要輸入一些數進去,可是這些數字不能是隨隨便便的數字吧,至少得有一定的規律性才能讓神經網路進行學習(就像要去破譯密碼,總得知道那些個密碼符號表示的含義是什麼才可以吧)。
那如何獲得輸入數字(或者說密碼)的規律呢。這就是數據壓縮過程我們所要考慮的問題,我們想要獲得數據經過壓縮後滿足什麼規律,在VAE中,我們將這種規律用概率的形式表示。在經過一系列數學研究後:我們最終獲得了數據壓縮的分布規律,這樣我們就可以根據這個規律去抽取樣本進行生成,生成的結果一定是類似於樣本的數據。
關於為什麼將用概率來表示,我的理解是:變分自編碼器是編碼器的進化版本,但傳統編碼器魯棒性比較差,以分布的形式引入,加入雜訊的影響,使模型生成過程的魯棒性加強。
1.4舉個栗子:
對VAE有了宏觀認識後,我們進行下一步學習
(後面的講解我將以圖片為例進行介紹)
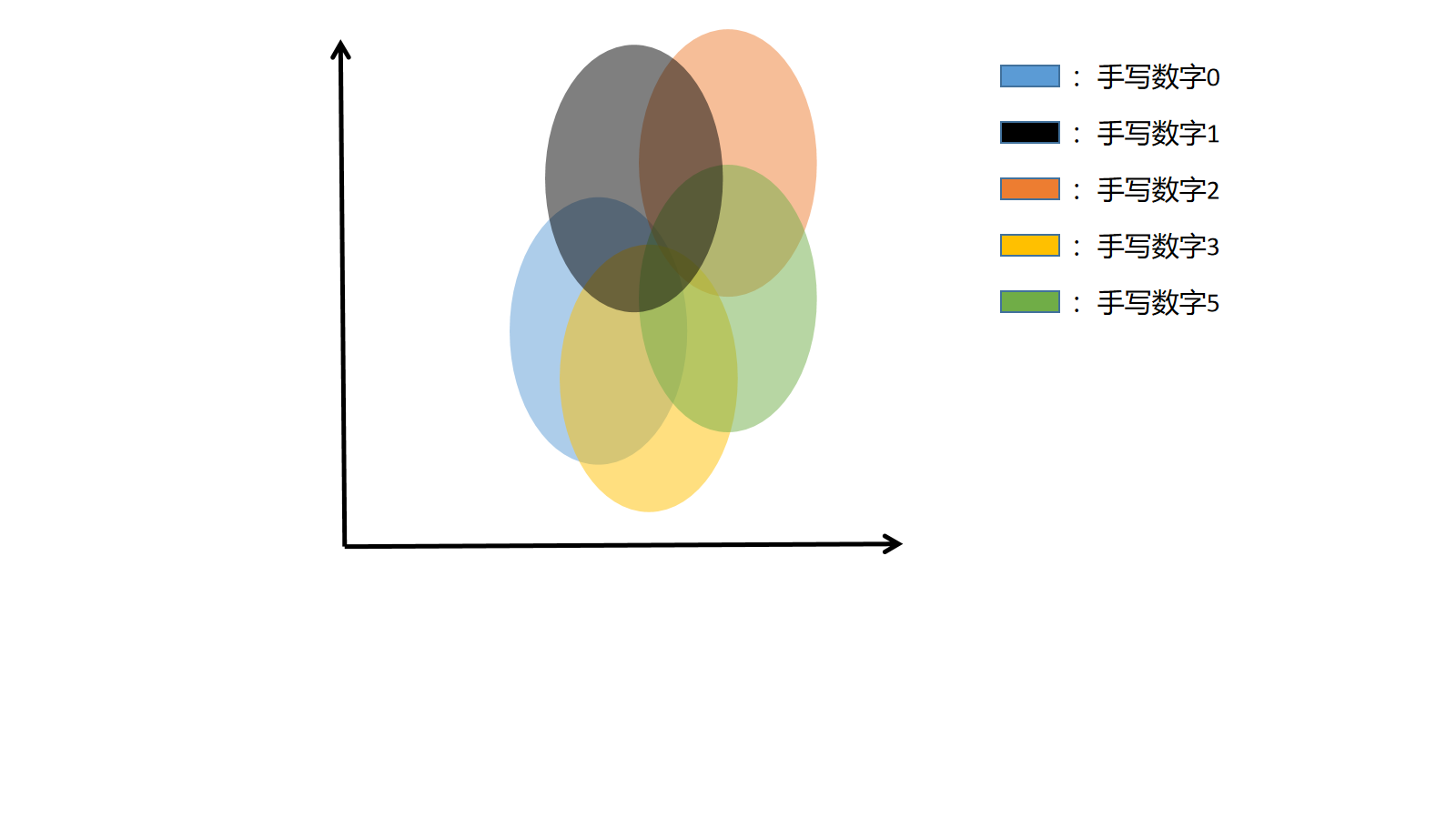
在前面講解過,將圖片進行某種編碼,我們將圖片編碼為2維的高斯分布(也可以不是2維,只是為了好可視化),二維平面的中心就是圖片的二維高斯分布的\(\mu\)(1)和\(\mu\)(2),表示橢圓的中心。
注意:這裡其實不是橢圓,我們只是把最較大概率的部分框出來。
假設一共有5個圖片(手寫數字0-4),則在隱空間中一共有5個二維正態分布(橢圓),如果生成過程中在坐標中取的點接近藍色區域,則說明,最後的生成結果接近數字0,如果在藍色和黑色交界處,則結果介於0和1之間。
1.5出現的問題:
此時出現了一個問題,如果每個橢圓離得特別遠會發生什麼,橢圓之間完全沒有交集。
假如隨機取數據的時候,取的數據不在任何橢圓里,最後的生成的結果將會非常離譜,根本不知道生成模型生成了什麼東西,我們稱這種現象為過擬合,因此,我們必須要讓這些個橢圓儘可能的推疊在一起,並且儘可能佔滿整個空間的位置,防止生成不屬於任何分類的圖片。後面我們會介紹如何將橢圓儘可能堆疊。
在解決上面那個問題後,我們就得到了一個較為標準的數據壓縮形態,這樣我們就可以放心取樣進行數據生成。
1.6VAE框架:
到現在為止,VAE框架已經形成:
•隱空間有規律可循,長的像的圖片離得近
•隱空間隨便拿個點解碼之後,得到的點有意義。
•隱空間中對應不同標籤的點不會離得很遠,但也不會離得太近(因為每個高斯的中心部分因為被取樣次數多必須特色鮮明,不能跟別的類別的高斯中心離得太近)(VAE做生成任務的基礎)
•隱空間對應相同標籤的點離得比較近,但又不會聚成超小的小簇,然而也不會有相聚甚遠的情況(VAE做分類任務的基礎)
二.理論推導VAE
我們接下來從理論的角度進行講解:
通過剛剛的講解,讀者一定有一個疑問,怎麼去求那麼複雜的高斯分布也就是隱空間呢,這個問題與變分推斷遇到的幾乎一樣。
2.1引入變分
在變分推斷中,我們想要通過樣本x來估計關於z的分布,也就是後驗,用概率的語言描述就是:p(z|x)。根據貝葉斯公式:
\]
我們不能直接求p(x)所以直接貝葉斯這個方法報廢,於是我們尋找新的方法。
這時我們想到了變分法,用另一個分布Q(z|x)來估計p(z|x,\(\theta\)),變分自編碼器的變分就來源於此。
用一個函數去近似另一個函數,可以看作從概率密度函數所在的函數空間到實數域R的一個函數f,自變數是Q的密度函數,因變數是Q與真實後驗密度函數的「距離」,而這一個f關於概率密度函數的「導數」就叫做「變分」,我們每次降低這個距離,讓Q接近真實的後驗,就是讓概率密度函數朝著「導數「的負方向進行函數空間的梯度下降。所以叫做變分推斷。
變分推斷和變分自編碼器的最終目標是相同的,都是將Q(z|x)盡量去近似p(z|x,\(\theta\)),我們知道有一種距離可以量化兩種分布的差異Kullback-Leibler divergence—KL散度,我們要盡量減小KL散度。
2.2KL散度
接下來我們進行公式的推導:
&KL[Q(z \mid x) \| p(z \mid x)]=E_{z \sim Q}[\log Q(z \mid x)-\log p(z \mid x)] \\
&=E_{z \sim Q}[\log Q(z \mid x)-\log p(x \mid z)-\log p(z)]+\log p(x)
\end{aligned}
\]
整理得:
&\log p(x)-KL[Q(z \mid x) \| p(z \mid x)]=E_{z \sim Q(z \mid x)}[\log p(x \mid z)]-KL[Q(z \mid x) \| p(z)]
\end{aligned}
\]
觀察這個複雜的式子:
(1)左邊第一個是樣本的對數似然,第二項是Q和p的KL散度。
(2)右邊第一項的意思是:給定的x,我們將其編碼為z,然後再重構x的似然函數值的期望。如果這個期望比較大,說明得到的z是x的一個比較好的表示,能夠抽取出x的足夠多的資訊以重構x。如果重構效果很好,說明Q(z|x)足夠擬合p(z|x)效果很好,生成效果好。
(3)右邊第二項看起來很奇怪,裡面出現里p(z)隱變數z的先驗分布。這裡算的是Q(z|x)與p(z)的距離。還記得前面我們說過存在一個過擬合問題嗎,就是Q(z|x)分布及其發散,會生成奇怪的數據,我們要將他們堆疊起來滿足一定規律性,然而自然界什麼分布最具有普遍性呢?當然是正態分布,因此我們假設z的先驗分布服從標準正態分布
\]
很關鍵的一點是我們一定要清楚每一個樣本x都對應一個正態分布Q (z|x)。每一個Q (z|x)都希望儘可能的去靠近正態分布。
這部分關於p(z)的分布與Q(z|x)的關係非常難理解,我的理解是,儘可能地將多個分布堆疊,盡量多的去覆蓋整個空間防止取到分布概率非常低的點造成生成奇怪的東西。
2.3ELBO
再次整理上式:
\]
變分推斷的目的是:最大化似然函數p(x),假設Q和p已經同分布了,等式左邊等於0,因此我們的目標就轉移為最大化ELBO。
這裡的分析與變分推斷完全一樣,不理解的話可以去看一下變分推斷的具體推導。
\]
接下來我們最大化ELBO:
L2,KL散度的簡化
\]
這裡面的Q(z|x)是一個樣本特有的分布,我們希望Q(z|x)去近似正態分布。而且Q (z|x)可以是一個多元的高斯分布。
將L2化簡(化簡步驟複雜,不要求理解)
\]
\]
這裡的 d 是隱變數 Z 的維度(或者說高斯分布的維度),而 μ(i) 和 σ(i) 分別代表一般正態分布的均值向量和方差向量的第 i 個分量。
L1,期望部分的簡化
假設p ( x ∣ z )服從伯努利分布:
原論文裡面寫出,encoder過程使用高斯分布P(z|X),decoder過程使用伯努利分布或者高斯分布p(x|z),在這裡我們使用伯努利分布進行分析。
\]
\]
再decoder過程中,我們將z輸入,通過MLP得到y,再將y帶入伯努利的概率分布公式中,從而得到
這裡面y是decoder的生成結果
\]
過程如下圖所示(圖中展示的是decoder過程的高斯分布):
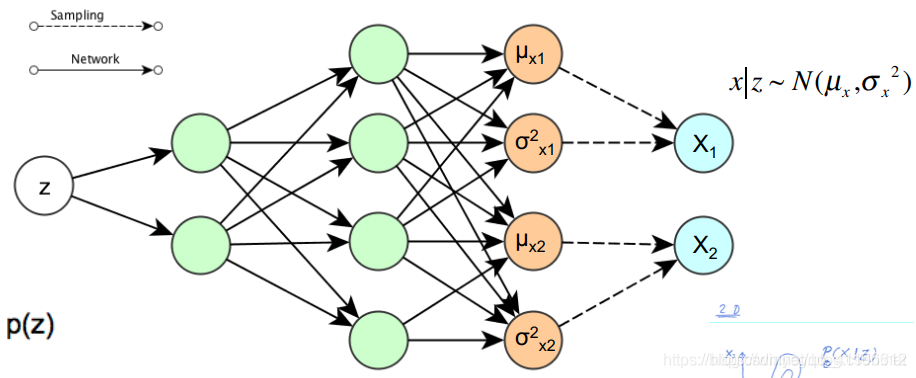
非常巧合的是,如果輸出是一個伯努利分布,滿足:
\]
BCE是原樣本x和生成結果y的BCE_Loss
觀察我們要求的L1部分,現在我們將 log p ( x ∣ z ) 進行化簡(BCE_loss),現在該求期望了。
但是對於對數似然期望的求解會是一個十分複雜的過程,所以採用MC演算法,將L1等價於:
\]
\]
\]
將上面求的 log( x | z )代入上式就的到最後結果。
2.4公式整合
將上面的L1和L2相加得到ELBO的計算式,最大化ELBO即可。
為了方便讀者理解和閱讀,在這裡,我把公式進行了歸納。
下面展示的是原始公式:
E L B O=E_{z \sim Q(z \mid x)}[\log p(x \mid z)]-K L[Q(z \mid x) \| p(z)] \\
K L\left[Q(z \mid x) \| p(z)=\frac{1}{2} \sum_{i=1}^{d}\left(\mu_{(i)}^{2}+\sigma_{(i)}^{2}-\log \sigma_{(i)}^{2}-1\right)\right. \\
\log p(X \mid z)=\sum_{i=1}^{D} x_{i} \log y_{i}+\left(1-x_{i}\right) \log \left(1-y_{i}\right)=B C E \\
\mathrm{E}_{Q(z \mid x)}(\log (p(x \mid z))) \approx \frac{1}{L} \sum_{l=1}^{L} \log p\left(x \mid z^{(l)}\right)
\end{array}\right.
\]
經過代入推導整理得:
E L B O=\frac{1}{L} \sum_{l=1}^{L} \sum_{i=1}^{D} x_{i} \log y_{i}+\left(1-x_{i}\right) \log \left(1-y_{i}\right)-\frac{1}{2} \sum_{i=1}^{d}\left(\mu_{(i)}^{2}+\sigma_{(i)}^{2}-\log \sigma_{(i)}^{2}-1\right) \\
\mathbf{y}=\operatorname{sigmoid}\left(\mathbf{W}_{2} \tanh \left(\mathbf{W}_{1} \mathbf{z}+\mathbf{b}_{1}\right)+\mathbf{b}_{2}\right)
\end{array}\right.
\]
w1,w2,b1,b2是decoder神經網路參數。
我們觀察這個ELBO,發現裡面的μ(i) 和 σ(i) 我們是不知道的。
也就是現在我們已經知道如何去算LOSS了,而且知道數學本質是什麼,但是最初的那個問題還沒有解決,也就是隱變數的分布Q(z|x)我們仍舊不清楚。
我們只知道用 Q ( z | x ) 去擬合 P( z | x )並且給出了一個數學公式判斷擬合效果。但是我們不會求Q(z|x)。
如果了解過變分推斷就知道,在變分推斷裡面用平均場理論直接硬推出了Q的迭代公式,但是如果z的變數數很多,平均場理論的就不太行了。
因此我們將眼光看向神經網路,神經網路時代,我們喜歡用一個網路去擬合各種數值,當然,我們也可以用網路去不斷迭代計算μ(i) 和 σ(i)。
接下來給出μ(i) 和 σ(i)的神經網路框架:
\log Q(\mathbf{z} \mid \mathbf{x}) &=\log \mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}, \boldsymbol{\sigma}^{2} \mathbf{I}\right) \\
\text { where } \boldsymbol{\mu} &=\mathbf{W}_{5} \mathbf{h}+\mathbf{b}_{5} \\
\log \boldsymbol{\sigma}^{2} &=\mathbf{W}_{4} \mathbf{h}+\mathbf{b}_{4} \\
\mathbf{h} &=\tanh \left(\mathbf{W}_{3} \mathbf{z}+\mathbf{b}_{3}\right)
\end{aligned}
\]
我們分別用兩個網路分別去算 μ 和 σ 。
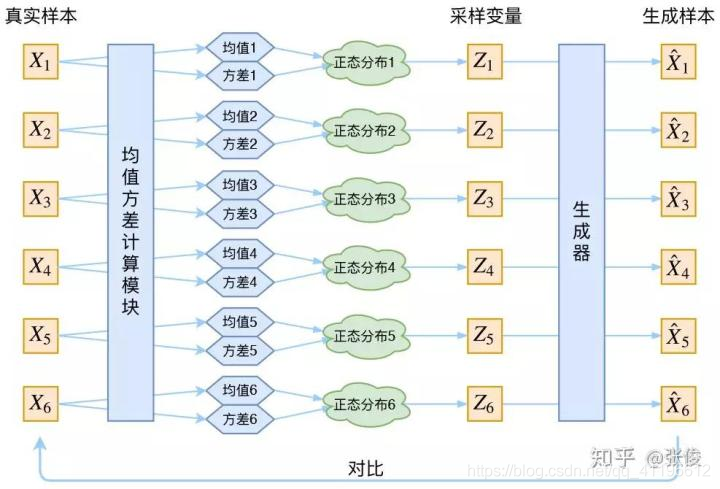
注意:這裡有一點非常關鍵,一個樣本或者說一個圖片對應一個正態分布,這樣才能在後面的生成過程找到對應的生成結果。
如下圖所以:
這張圖片來自知乎變分自編碼器VAE
2.5參數更新
ok,現在我們把整個ELBO都求出來了,下一步是什麼呢?
當然是進行參數更新,這裡我們採用隨機梯度下降進行參數更新。
但是在生成過程中,z是在分布中隨機進行取樣的,這樣會導致無法進行求導,進而前面求Q( z | x )的網路參數無法進行更新,那麼該如何解決這個問題呢?
因此我們需要用到一種新的技巧:重參數化
再次回顧我們為什麼要進行重參數,因為在訓練過程中,由於z的取樣,導致梯度斷裂,在BP的過程中,誤差需要穿過一個取樣層,該操作不連續且沒有梯度。SGD可以處理隨機輸入,但不能處理隨機操作!解決方法稱為 「重新參數化」,先取樣ϵ ∼ N ( 0 , I ) ,然後讓:
\]
所以「重參數化」的目的就是為了讓模型可以求導,進而可以用SGD求解。
三.對於VAE的一些理解
到目前為止,相比大家對VAE已經基本認識了,下面我從直觀的角度上進行一些講解(當然這些不是我自己想出來的,在經過大量閱讀文獻和大佬的部落格歸納出來的內容)
3.1 Question1
讀者肯定在思考一個問題(其實是我一直在思考的):為什麼需要p(z|x)儘可能的接近正態分布呢?
3.1.1解答:
我們先想一下什麼時候重構誤差最小呢(也就是前面的BCE_loss),當然是對z進行取樣的時候方差為0,直接取均值的時候誤差可以做到最小,這樣幾乎就是屏蔽了雜訊的影響,但是這樣的話變分自編碼器和編碼器將會沒有區別,將樣本編碼為概率分布將沒有意義,為了防止這個情況發生,或者說為了防止前面的encoder算σ(i)的時候全都計算成0,我們讓p(z|x)向標準正態看齊,也就是限制σ(i),讓他接近1。
3.1.2還有一種理解是:
VAE作為生成模型就是在潛變數的空間裡面,尋找訓練集投影集中的地方然後取樣就行了,只不過需要通過約束訓練集投影在集中在零向量附近,要不然因為高維空間的稀疏性,隨便選擇,模型重構結果肯定很差。
我的理解是會造成過擬合。
如果p(z|x)變成正態分布了,我們看看會發生什麼:
\]
很神奇,p(Z)滿足了標準正態分布,也就是我們進行生成的時候,保證了z的隨機性,或者說保證了生成能力。
所以前面我們可以最小化下面這個式子理解為保證模型的生成能力。
\]
3.2VAE的對抗性
我們的公式中的終極目標是最大化ELBO,既要最大化前面的期望,又要最小化後面的KL散度
\]
我們來分析一下這個過程,假如剛開始,期望很大,也就是模型的生成能力比較弱,我們就會適當降低雜訊(KL loss 增加),使得擬合起來容易一些(重構誤差開始下降)。
反之,如果生成模型訓練得還不錯時(重構誤差小於 KL loss),這時候雜訊就會增加(KL loss 減少),使得擬合更加困難了(重構誤差又開始增加),這時候生成模型就要想辦法提高它的生成能力了。
但是最終得到的Q(z|x)一定不是正態分布,因為模型剛開始訓練,loss集中在重構誤差上,只有到重構誤差比較小的時候,KL_loss才會有作用,可以將kl_loss理解為一個正則化項。
3.3 Question2
有個問題:既然隱含變數z的最終目標是往正態分布(0,1)走,那為什麼不一開始就按照正態分布取樣然後只訓練右邊似然估計的網路呢,為什麼還要設計並且計算左邊的呢?
解答:
我們並不能說標準正態分布是 z 的「最終」目標。
讓 z 往標準正態看齊,只是為了方便對 z 取樣。不妨這麼看,對於一個沒有訓練過的 encoder(左側網路),它會把每個 X 胡亂映射成不同的後驗分布 p(z|X) ,東邊一坨,西邊一坨的。整個訓練的過程就是把所有這些 p(z|X) 往 N(0, 1) 拉攏,但是呢,又不太可能可能完美「重合」,因為 decoder(右側網路)是要通過取樣 z 還原 X 的。
直覺地看,這也是一個競爭過程,我們可以把 p(z|X) 與 N(0,1) 的KL散度看作「吸引力」,而對重構的要求是「排斥力」。
3.4隱變數空間z到底是什麼東西?
在我看來,隱變數空間是提取了樣本的多個特徵,將特徵轉化為概率的分布,以概率的方式描述潛在空間觀察。
舉一個例子,假設我們在編碼維數為6的大型人臉數據集上訓練了一個自編碼器模型。理想的自編碼器將學習人臉的描述性屬性,如膚色、是否戴眼鏡等,以試圖用一些壓縮的表示來描述觀察。

我們可能更傾向於將每個潛在屬性表示為可能值的範圍。例如,如果輸入蒙娜麗莎的照片,你會為微笑屬性分配什麼樣的單值?使用變分自編碼器,我們可以用概率術語來描述潛在屬性。
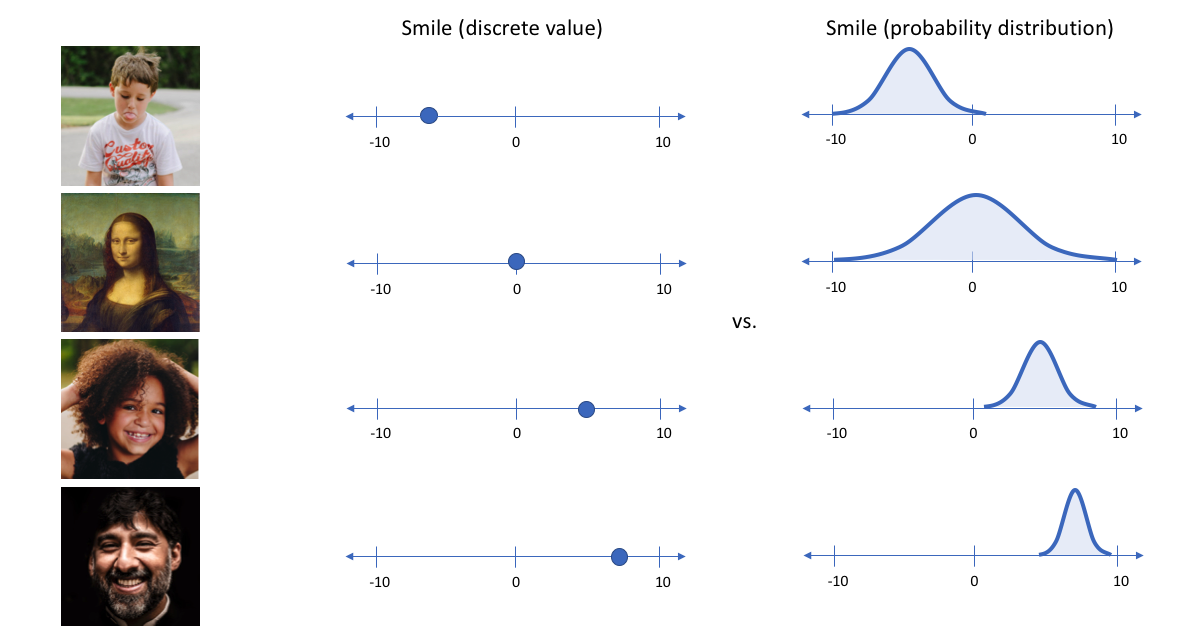
通過這種方法,我們現在將給定輸入的每個潛在屬性表示為概率分布。當從潛在狀態解碼時,我們將從每個潛在狀態分布中隨機取樣,生成一個向量作為解碼器模型的輸入。
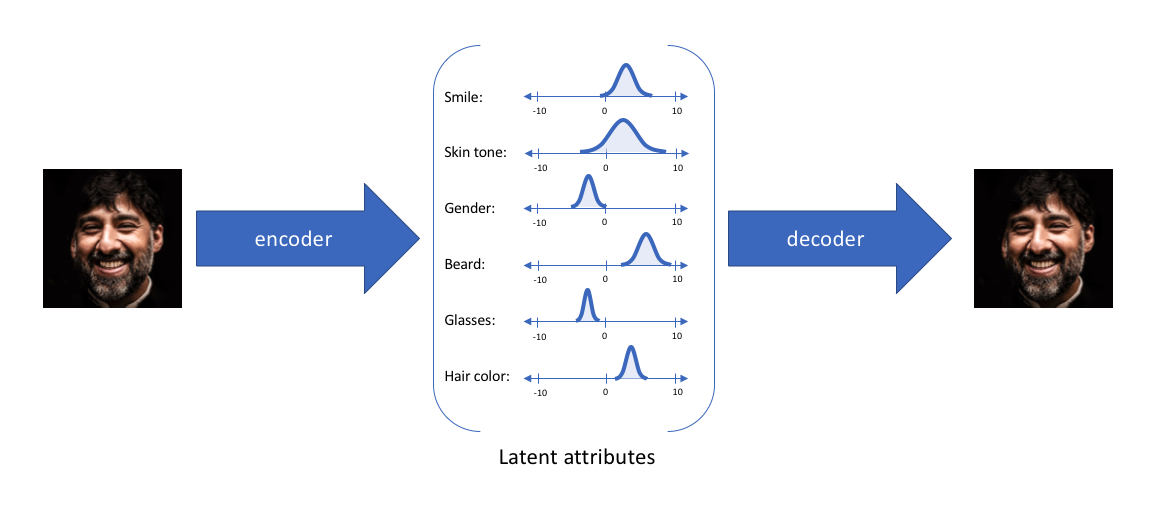
注意:對於變分自編碼器,編碼器模型有時被稱為識別模型(recognition model ),而解碼器模型有時被稱為生成模型。
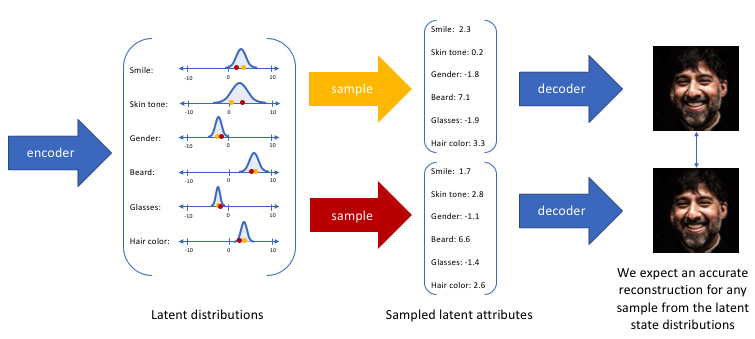
通過構造我們的編碼器模型來輸出可能值的範圍(統計分布),我們將隨機取樣這些值以供給我們的解碼器模型,我們實質上實施了連續,平滑的潛在空間表示。對於潛在分布的所有取樣,我們期望我們的解碼器模型能夠準確重構輸入。因此,在潛在空間中彼此相鄰的值應該與非常類似的重構相對應。
四.寫在最後
這篇文章是我進行學習時的一些想法和總結,當然裡面肯定還是存在不少問題,部落客目前大二,對於很多知識的理解都不太到位,如果有誤,盡請指出,希望不會對讀者進行誤導。
放一些文章供大家參考:
1.這個裡面有pytorch的程式碼
2.比較直觀的一種理解
3.重點關注對VAE的理解


