Spark-寒假-實驗4
1.spark-shell 互動式編程
(1)該系總共有多少學生;
執行命令:
var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
var par=tests.map(row=>row.split(",")(0))
var distinct_par=par.distinct()
distinct_par.count

結果:

(2)該系共開設來多少門課程;
執行命令:
var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
var par=tests.map(row=>row.split(",")(1))
var distinct_par=par.distinct()
distinct_par.count
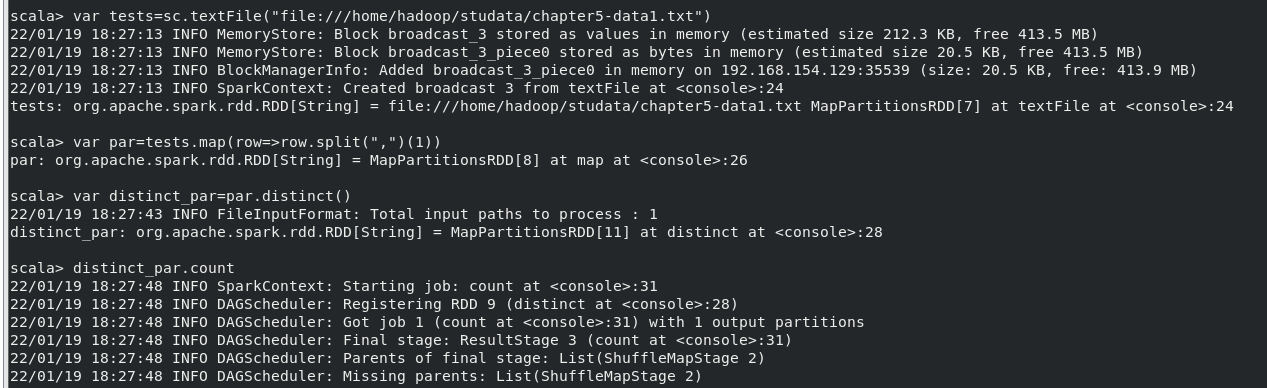
結果:

(3)Tom 同學的總成績平均分是多少;
執行命令:
var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
var pars=tests.filter(row=>row.split(",")(0)=="Tom")
pars.foreach(println)
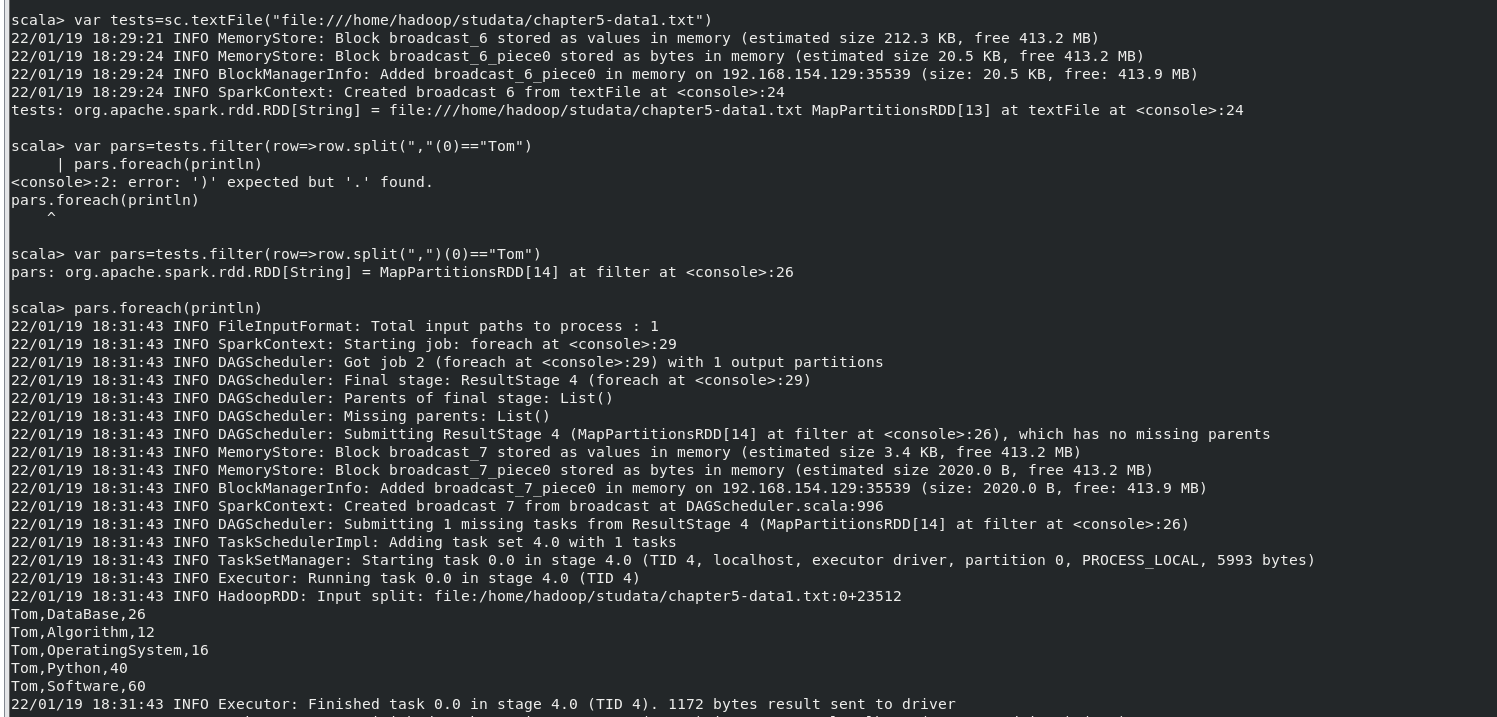
結果:

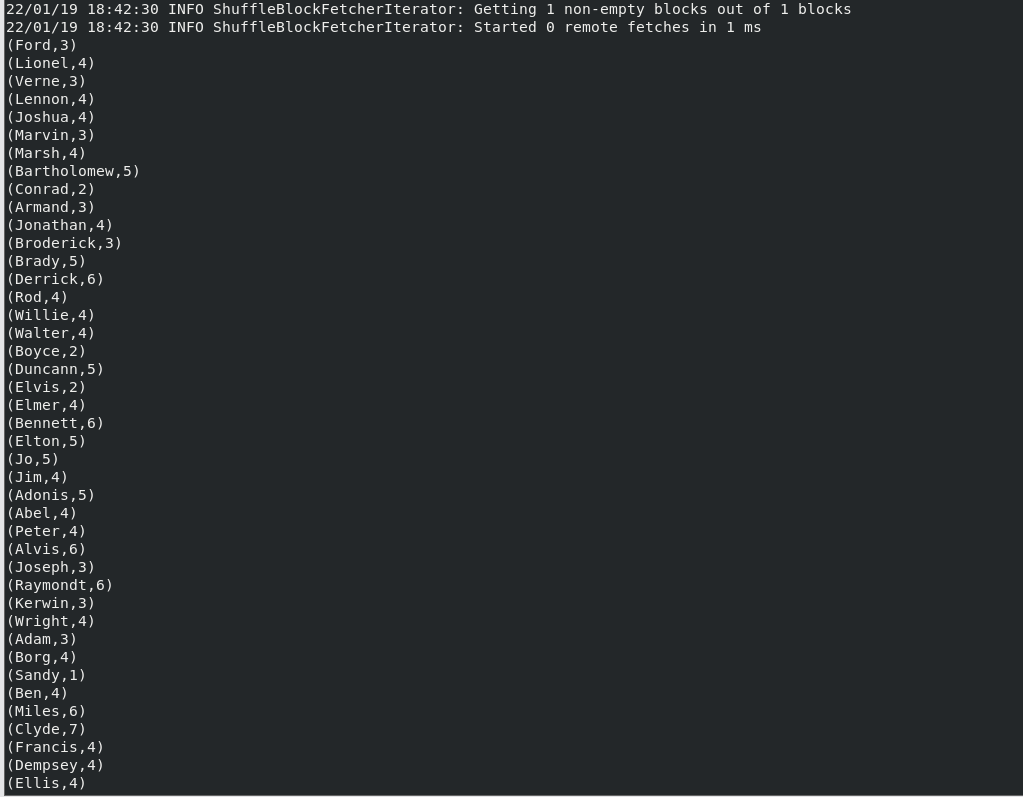
(4)求每名同學的選修的課程門數;
執行命令:
var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
var pars=tests.map(row=>(row.split(",")(0),row.split(",")(1)))
pars.mapValues(x=>(x,1)).reduceByKey((x,y)=>(" ",x._2+y._2)).mapValues(x=>x._2).foreach(println)
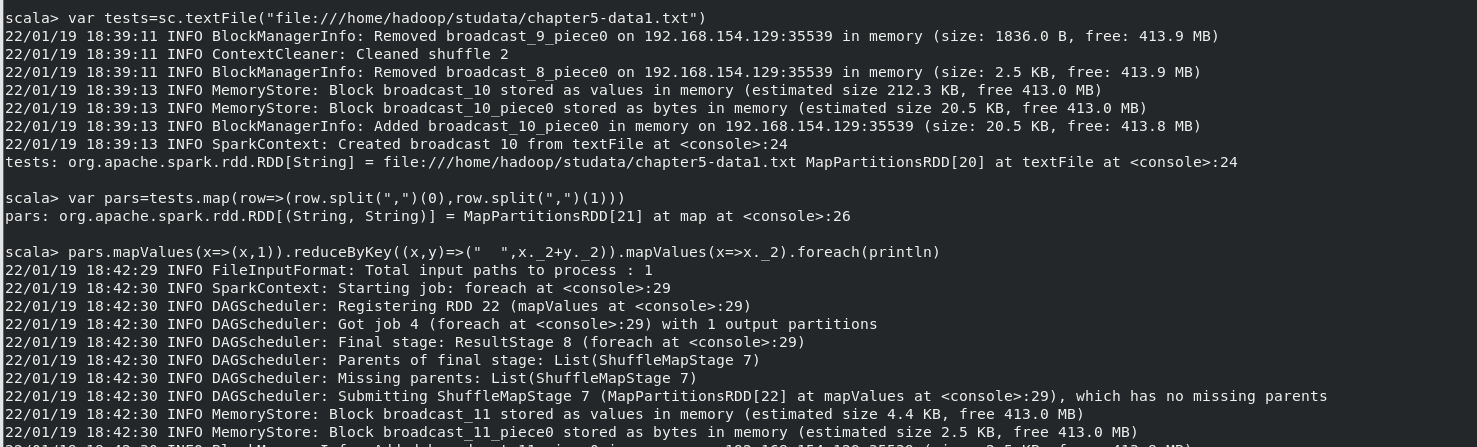
結果(此處僅為部分結果,結果共265項):
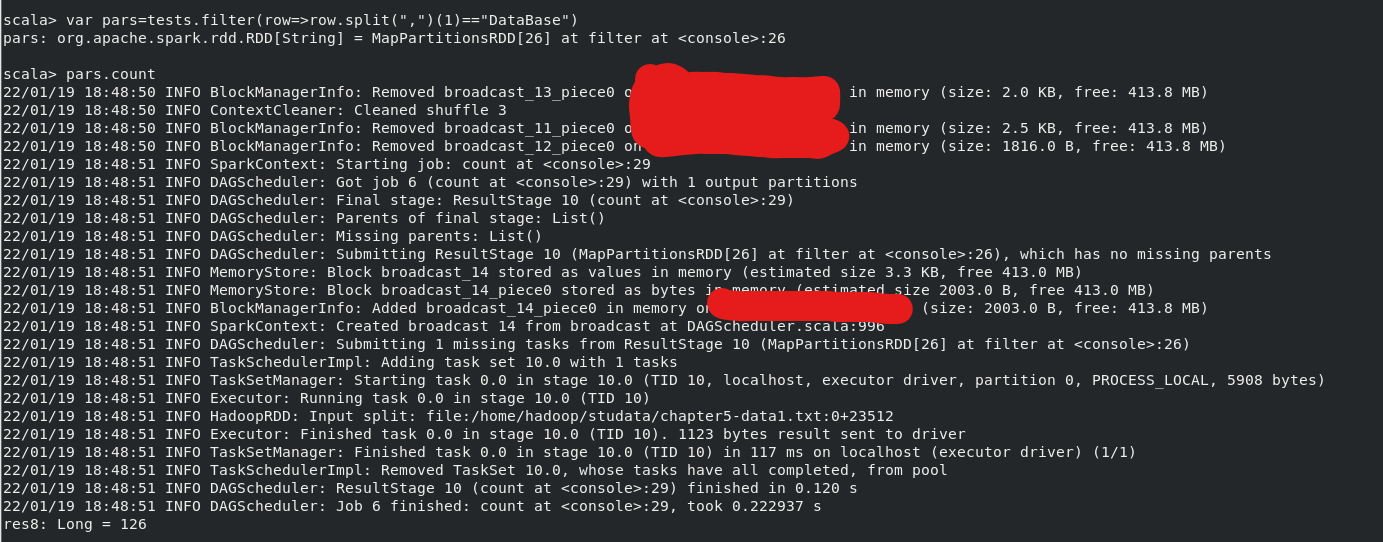
(5)該系 DataBase 課程共有多少人選修;
執行命令(結果最後一行):
var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
var pars=tests.filter(row=>(row.split(",")(1)=="Database"))
pars.count
(6)各門課程的平均分是多少;
執行命令:
var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
var pars=tests.map(row=>(row.split(",")(1),row.split(",")(2).toInt))
pars.mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).mapValues(x=>(x._1/x._2)).collect()

結果:

(7)使用累加器計算共有多少人選了 DataBase 這門課。
執行命令:
var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
var pars=tests.filter(row=>(row.split(",")(1)=="Database")).map(row=>(row.split(",")(1),1))
var account=sc.longAccumulator("My Accumulator")
pars.values.foreach(x=>account.add(x))
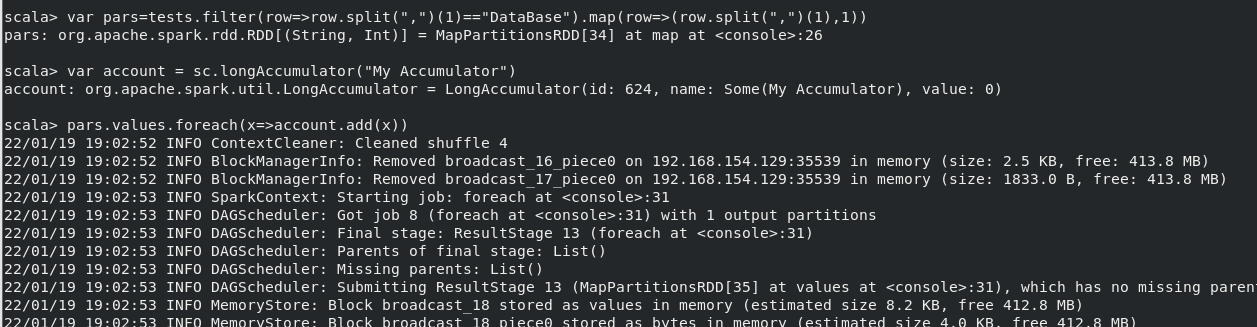
結果:

2.編寫獨立應用程式實現數據去重
對於兩個輸入文件 A 和 B,編寫 Spark 獨立應用程式,對兩個文件進行合併,並剔除其 中重複的內容,得到一個新文件 C。下面是輸入文件和輸出文件的一個樣例,供參考。 輸入文件 A 的樣例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
輸入文件 B 的樣例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根據輸入的文件 A 和 B 合併得到的輸出文件 C 的樣例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
創建項目:

remdup.scala
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf import org.apache.spark.HashPartitioner object RemDup { def main(args: Array[String]) { val conf = new SparkConf().setAppName("RemDup") val sc = new SparkContext(conf) val A = sc.textFile("file:///home/hadoop/studata/A.txt") val B = sc.textFile("file:///home/hadoop/studata/B.txt") val C = A.union(B).distinct().sortBy(x => x,true) C.foreach(println) sc.stop() } }
simple.sbt
name := "RemDup Project" version := "1.0" scalaVersion := "2.11.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
打包項目(sbt的安裝請看Spark-寒假-實驗3):
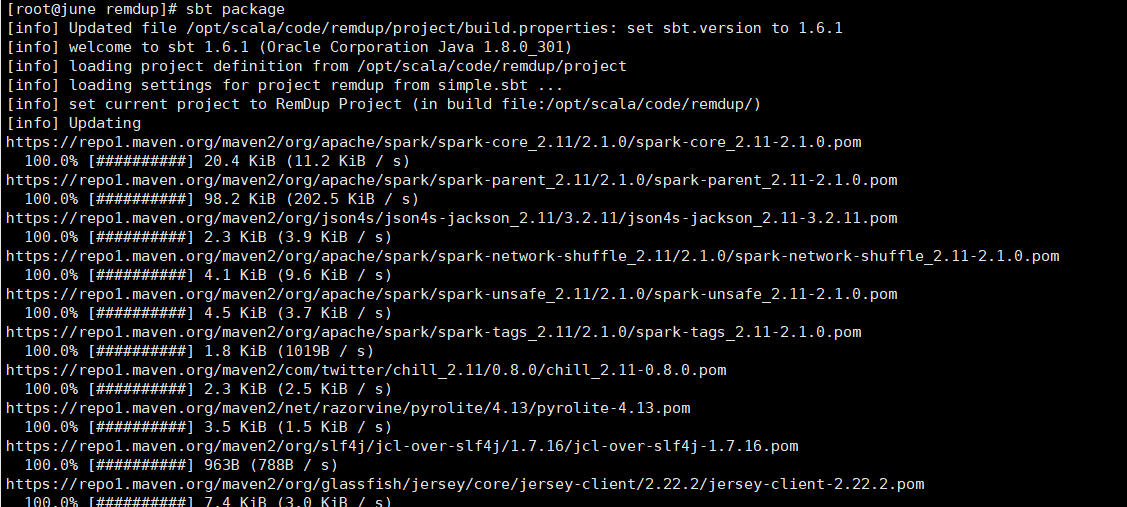
運行jar包:
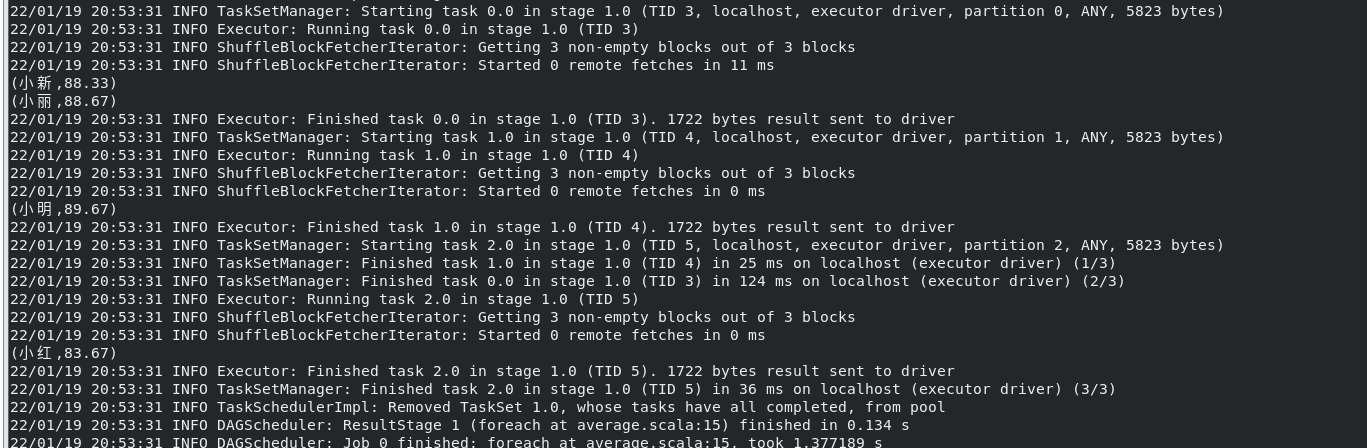
運行結果:

3.編寫獨立應用程式實現求平均值問題
創建項目流程同上:
程式程式碼如下:
average.scala
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf import org.apache.spark.HashPartitioner object Average { def main(args: Array[String]) { val conf = new SparkConf().setAppName("Average") val sc = new SparkContext(conf) val Algorimm = sc.textFile("file:///home/hadoop/studata/Algorimm.txt") val DataBase = sc.textFile("file:///home/hadoop/studata/DataBase.txt") val Python = sc.textFile("file:///home/hadoop/studata/Python.txt") val allGradeAverage = Algorimm.union(DataBase).union(Python) val stuArrayKeyValue = allGradeAverage.map(x=>(x.split(" ")(0),x.split(" ")(1).toDouble)).mapValues(x=>(x,1)) val totalGrade = stuArrayKeyValue.reduceByKey((x,y) => (x._1+y._1,x._2+y._2)) val averageGrade = totalGrade.mapValues(x=>(x._1.toDouble/x._2.toDouble).formatted("%.2f")).foreach(println) sc.stop() } }
simple.sbt
name := "Average Project" version := "1.0" scalaVersion := "2.11.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
打包項目:

運行jar包:
運行結果: