進程池與執行緒池基本使用、協程理論與實操、IO模型、前端、BS架構、HTTP協議與HTML前戲
昨日內容回顧
1.在python解釋器中 才有GIL的存在(只與解釋器有關)
2.GIL本質上其實也是一把互斥鎖(並發變串列 犧牲效率保證安全)
3.GIL的存在 是由於Cpython解釋器中的記憶體管理不是執行緒安全的
記憶體管理》》》垃圾回收機制
4.在python中 同一個進程下的多個執行緒無法實現並行的(可以並發)
1.python程式碼要想被運行 必須先獲取到解釋器 但是解釋器的獲取需要搶奪和釋放GIL全局解釋器鎖
剝奪CPU許可權的兩種情況:
01 執行時間過長
02 進入IO操作
2.互斥鎖最好不要多次使用 尤其是存在多把鎖的情況下
3.驗證python多執行緒無法利用多核優勢的情況下是否還有用
01 要先區分 任務類型是 計算密集型還是IO密集型
02 如果是計算密集型 那麼開設多進程有優勢
03 如果是IO密集型 那麼開設多執行緒有優勢
04 可以多進程多執行緒結合使用(效率更高)
1.池:
為了保證電腦硬體安全的情況下 提升程式的運行效率(硬體的發展遠遠跟不上軟體的發展速度)
2.進程池:
提前開設好一堆進程 只需要朝池子中提交任務 任務會自動分配給空閑的進程處理 並且池子中的進程創建好了之後就不會更替
3.執行緒池:
提前開設好一堆執行緒 只需要朝池子中提交任務 任務會自動分配給空閑的執行緒處理 並且池子中的執行緒創建好了之後就不會更替
'''進程池執行緒池封裝程度更高 不需要我們自己編寫複雜的程式碼'''
今日內容概要
- 進程池與執行緒池的基本使用
- 協程理論與實操
- IO模型
- 前端介紹
內容詳細
1、進程池與執行緒池基本使用
01 向進程池提交任務 非同步獲取結果
import time
import os
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
# 創建進程池
pool = ProcessPoolExecutor(5) # 可以自定義進程數 也可以採用默認的策略
# 定義一個任務
def task(n):
print(n, os.getpid())
time.sleep(2)
return '>>%s'% n**2
# 往進程池提交任務
l = []
if __name__ == '__main__':
for i in range(20):
res = pool.submit(task, i) # pool.submit(task, i) 屬於非同步提交任務
l.append(res)
# 等待進程池中所有任務執行完畢之後 再獲取各自任務的結果
pool.shutdown()
for i in l:
print(i.result()) # 獲取任務執行結果 同步
02 向執行緒池提交任務 非同步獲取結果
import time
import os
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
# 創建執行緒池
pool = ThreadPoolExecutor(5) # 可以自定義執行緒數 也可以採用默認的策略
# 定義一個任務
def task(n):
print(n, os.getpid())
time.sleep(2)
return '>>%s'% n**2
# 往執行緒池提交任務
l = []
for i in range(20):
res = pool.submit(task, i) # pool.submit(task, i) 屬於非同步提交任務
l.append(res)
# 等待進程池中所有任務執行完畢之後 再獲取各自任務的結果
pool.shutdown()
for i in l:
print(i.result()) # 獲取任務執行結果 同步
03 非同步回調機制
import time
import os
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
# 創建進程池與執行緒池
# pool = ThreadPoolExecutor(5) # 可以自定義執行緒數 也可以採用默認的策略
pool = ProcessPoolExecutor(5) # 可以自定義進程數 也可以採用默認的策略
# 定義一個任務
def task(n):
print(n, os.getpid())
time.sleep(2)
return '>>%s'% n**2
# 定義一個回調函數:非同步提交完之後有結果自動調用該函數
def call_back(a):
print('非同步回調函數 %s'% a.result()) # a task任務的返回值
if __name__ == '__main__':
for i in range(20):
res = pool.submit(task, i).add_done_callback(call_back) # pool.submit(task, i) 屬於非同步提交任務
"""
同步:提交完任務之後原地等待任務的返回結果 期間不做任何事
非同步:提交完任務之後不願地等待任務的返回結果 結果由非同步回調機制自動回饋
在windows電腦中 如果是進程池的使用 需要在__main__方法下面
"""
2、協程理論與實操
# 1.進程
資源單位
# 2.執行緒
工作單位
# 3.協程
是程式設計師單方面意淫出來的名詞>>>:單執行緒下實現並發
# 4.CPU被剝奪的條件
1.程式長時間佔用
2.程式進入IO操作
# 5.並發
切換+保存狀態
'''以往學習的是:多個任務(進程、執行緒)來回切換'''
# 6.欺騙CPU的行為
單執行緒下我們如果能夠自己檢測IO操作並且自己實現程式碼層面的切換
那麼對於CPU而言我們這個程式就沒有IO操作,CPU會儘可能的被佔用
# 7.從程式碼層面實現 協程
第三方gevent模組:能夠自主監測IO行為並切換
'''01 普通執行程式碼所需時間'''
from gevent import monkey;monkey.patch_all() # 固定程式碼格式加上之後才能檢測所有的IO行為
import time
def play(name):
print('%s play 1' % name)
time.sleep(5)
print('%s play 2' % name)
def eat(name):
print('%s eat 1' % name)
time.sleep(3)
print('%s eat 2' % name)
start = time.time()
play('jason') # 正常的同步調用
eat('jason') # 正常的同步調用
print('主', time.time() - start) # 單執行緒下實現並發,提升效率
結果:
jason play 1
jason play 2
jason eat 1
jason eat 2
主 8.0690336227417
"""02 實現協程效果:單執行緒下實現並發"""
from gevent import monkey;monkey.patch_all() # 固定程式碼格式加上之後才能檢測所有的IO行為
from gevent import spawn
import time
def play(name):
print('%s play 1' % name)
time.sleep(5)
print('%s play 2' % name)
def eat(name):
print('%s eat 1' % name)
time.sleep(3)
print('%s eat 2' % name)
start = time.time()
g1 = spawn(play, 'jason') # 非同步提交 不加 .join() 主進程不會等待子進程結束
g2 = spawn(eat, 'jason') # 非同步提交 不加 .join() 主進程不會等待子進程結束
g1.join() # 等待被監測的任務運行完畢
g2.join() # 等待被監測的任務運行完畢
print('主', time.time() - start) # 單執行緒下實現並發,提升效率
結果: # 並沒有開設多執行緒或者多進程
jason play 1
jason eat 1
jason eat 2
jason play 2
主 5.033665418624878
3、協程實現TCP服務端並發的效果
# 客戶端開設幾百個執行緒發消息即可
import socket
from threading import Thread, current_thread
from socket import *
def client():
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
n = 0
while True:
msg = '%s say hello %s' % (current_thread().name, n)
n += 1
client.send(msg.encode('utf8'))
data = client.recv(1024)
print(data.decode('utf8'))
# if __name__ == '__main__': 要不要都可以
for i in range(500):
t = Thread(target=client)
t.start()
# 服務端
import socket
from gevent import spawn
from gevent import monkey;monkey.patch_all()
def talk(sock):
while True:
try:
data = sock.recv(1024)
print(data)
sock.send(data + b'hello big baby')
except ConnectionError as e:
print(e)
sock.close()
break
def servers():
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen()
while True:
sock, addr = server.accept()
spawn(talk, sock)
g1 = spawn(servers)
g1.join()
"""
最牛逼的情況:多進程下開設多執行緒 多執行緒下開設協程
我們以後可能自己動手寫的不多 一般都是使用別人封裝好的模組或框架
"""
4、IO模型
"""理論為主 程式碼實現大部分為偽程式碼(沒有實際含義 僅為驗證參考)"""
# 1.基本關鍵字
同步(synchronous) 大部分情況下會採用縮寫的形式 sync
非同步(asynchronous) async
阻塞(blocking)
非阻塞(non-blocking)
# 2.研究的方向
Stevens在文章中一共比較了五種IO Model:
* blocking IO 阻塞IO
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路復用
* signal driven IO 訊號驅動IO
* asynchronous IO 非同步IO
由於signal driven IO(訊號驅動IO)在實際中並不常用,所以主要介紹其餘四種 IO Model
4.1、四種IO模型簡介
1.阻塞IO
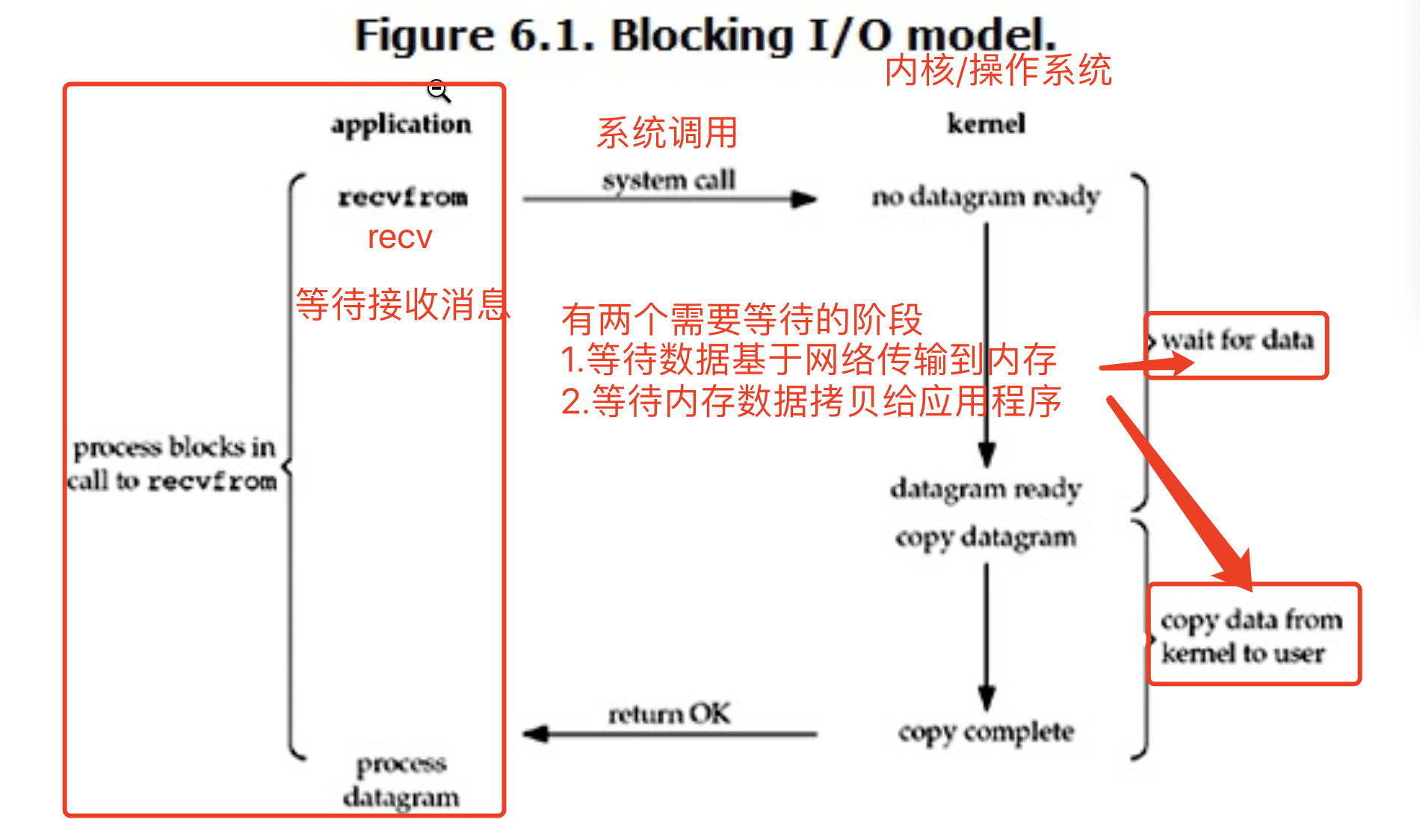
在linux中,默認情況下所有的socket都是blocking,一個典型的讀操作流程大概是下圖:6.1
當用戶進程調用了recvfrom這個系統調用,kernel就開始了IO的第一個階段:準備數據。對於network io來說,很多時候數據在一開始還沒有到達(比如,還沒有收到一個完整的UDP包),這個時候kernel就要等待足夠的數據到來。
而在用戶進程這邊,整個進程會被阻塞。當kernel一直等到數據準備好了,它就會將數據從kernel中拷貝到用戶記憶體,然後kernel返回結果,用戶進程才解除block的狀態,重新運行起來。
所以,blocking IO的特點就是在IO執行的兩個階段(等待數據和拷貝數據兩個階段)都被block了。
'''
最為常見的一種IO模型 有兩個等待的階段(wait for data、copy data)
'''
2.非阻塞IO
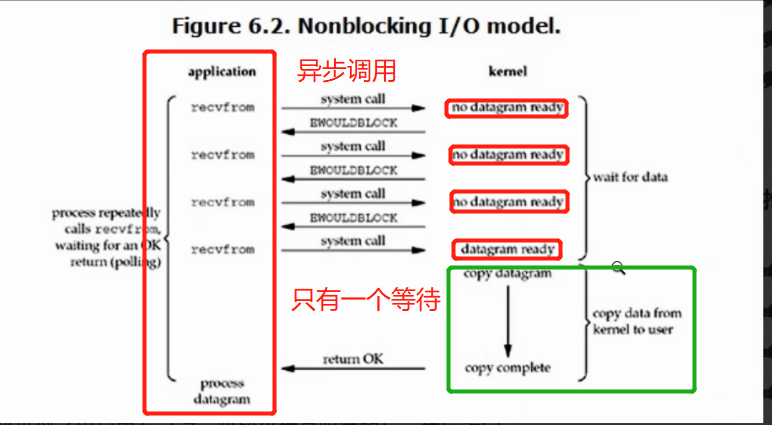
Linux下,可以通過設置socket使其變為non-blocking。當對一個non-blocking socket執行讀操作時,流程是下圖:6.2
從圖中可以看出,當用戶進程發出read操作時,如果kernel中的數據還沒有準備好,那麼它並不會block用戶進程,而是立刻返回一個error。從用戶進程角度講 ,它發起一個read操作後,並不需要等待,而是馬上就得到了一個結果。用戶進程判斷結果是一個error時,它就知道數據還沒有準備好,於是用戶就可以在本次到下次再發起read詢問的時間間隔內做其他事情,或者直接再次發送read操作。一旦kernel中的數據準備好了,並且又再次收到了用戶進程的system call,那麼它馬上就將數據拷貝到了用戶記憶體(這一階段仍然是阻塞的),然後返回。
也就是說非阻塞的recvform系統調用調用之後,進程並沒有被阻塞,內核馬上返回給進程,如果數據還沒準備好,此時會返回一個error。進程在返回之後,可以干點別的事情,然後再發起recvform系統調用。重複上面的過程,循環往複的進行recvform系統調用。這個過程通常被稱之為輪詢。輪詢檢查內核數據,直到數據準備好,再拷貝數據到進程,進行數據處理。需要注意,拷貝數據整個過程,進程仍然是屬於阻塞的狀態。
所以,在非阻塞式IO中,用戶進程其實是需要不斷的主動詢問kernel數據準備好了沒有。
'''
系統調用階段變為了非阻塞(輪詢) 有一個等待的階段(copy data)
輪詢的階段是比較消耗資源的
'''
3.多路復用IO
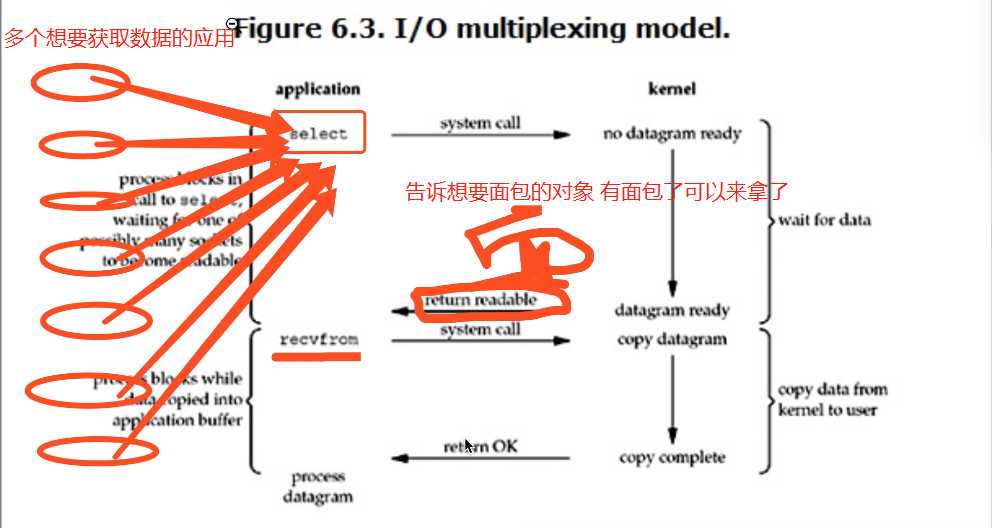
IO multiplexing這個詞可能有點陌生,但是如果我說select/epoll,大概就都能明白了。有些地方也稱這種IO方式為事件驅動IO(event driven IO)。我們都知道,select/epoll的好處就在於單個process就可以同時處理多個網路連接的IO。它的基本原理就是select/epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有數據到達了,就通知用戶進程。它的流程如圖:6.3
當用戶進程調用了select,那麼整個進程會被block,而同時,kernel會「監視」所有select負責的socket,當任何一個socket中的數據準備好了,select就會返回。這個時候用戶進程再調用read操作,將數據從kernel拷貝到用戶進程。
這個圖和blocking IO的圖其實並沒有太大的不同,事實上還更差一些。因為這裡需要使用兩個系統調用(select和recvfrom),而blocking IO只調用了一個系統調用(recvfrom)。但是,用select的優勢在於它可以同時處理多個connection。
# 強調:
1. 如果處理的連接數不是很高的話,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延遲還更大。select/epoll的優勢並不是對於單個連接能處理得更快,而是在於能處理更多的連接。
2. 在多路復用模型中,對於每一個socket,一般都設置成為non-blocking,但是,如上圖所示,整個用戶的process其實是一直被block的。只不過process是被select這個函數block,而不是被socket IO給block。
結論: select的優勢在於可以處理多個連接,不適用於單個連接
'''
利用select或者epoll來監管多個程式 一旦某個程式需要的數據存在於記憶體中了 那麼立刻通知該程式去取即可
'''
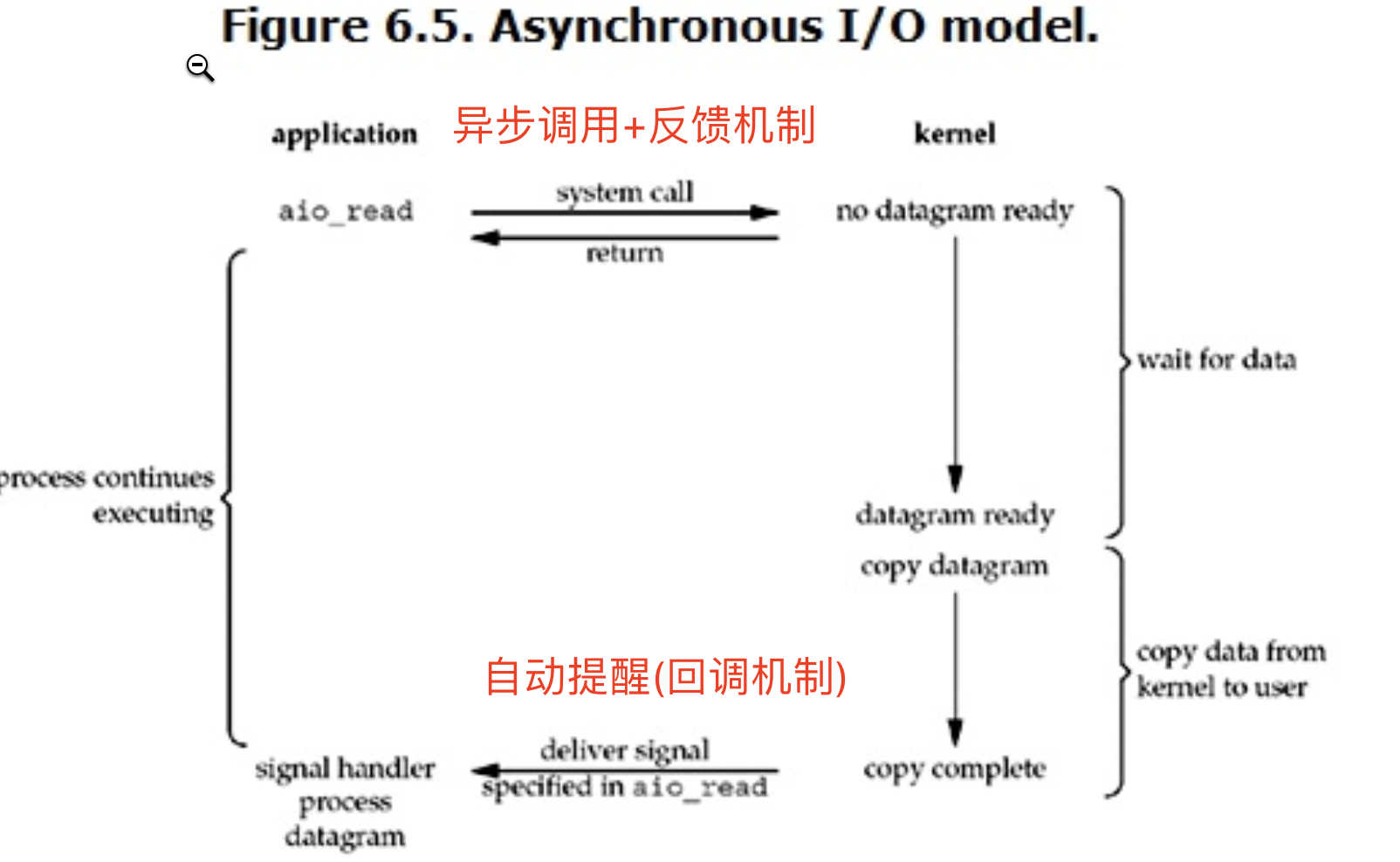
4.非同步IO
Linux下的asynchronous IO其實用得不多,從內核2.6版本才開始引入。流程如下圖:6.5
用戶進程發起read操作之後,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之後,首先它會立刻返回,所以不會對用戶進程產生任何block。然後,kernel會等待數據準備完成,然後將數據拷貝到用戶記憶體,當這一切都完成之後,kernel會給用戶進程發送一個signal,告訴它read操作完成了。
'''
只需要發起一次系統調用 之後無需頻繁發送 有結果並準備好之後會通過非同步回調機制回饋給調用者
'''
5、前端
# 1.什麼是前端:
任何與作業系統打交道的介面都可以稱之為"前端"
手機介面(app) 電腦介面(軟體) 平板介面(軟體)
# 2.什麼是後端:
不直接與用戶打交道,而是控制核心邏輯的運行
各種程式語言編寫的程式碼(python程式碼、java程式碼、c++程式碼)
# 3.前端的學習思路
聲明:前端也是一門獨立的學科 市面上也有前端工程師崗位,所以前端完整的課程內容也有解決六個半月,我們不可能全部學習,只學習最為核心最為基礎的部門
程度:掌握基本前端頁面搭建 掌握前端後續內容的學習思路 看得懂前端工程師所編寫的程式碼
# 4.前端的學習流程
前端三劍客:
HTML 網頁的骨架(沒有樣式很醜)
CSS 網頁的樣式(給骨架美化)
JS 網頁的動態效果(豐富用戶體驗)


5.1、BS架構
'''
我們在編寫TCP服務端的時候 針對客戶端的選擇可以是自己寫的客戶端程式碼也可以是瀏覽器充當客戶端(bs架構本質也是cs架構)
'''
# 本地自己搭建一個簡易服務端
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
sock, addr = server.accept()
while True:
data = sock.recv(1024)
print(data)
sock.send(b'big baby')
# 讓瀏覽器充當客戶端訪問
127.0.0.1:8080
無法識別
原因是:
我們自己編寫的服務端發送的數據瀏覽器不識別 原因在於
每個人服務端數據的格式千差萬別 瀏覽器無法自動識別 沒有按照瀏覽器固定的格式發送
"""
瀏覽器可以訪問很多服務端 如何做到無障礙的與這麼多不同程式設計師開發的軟體 實現數據的交互?
1.瀏覽器自身功能強大 自動識別並切換(太過消耗資源)
2.大家統一一個與瀏覽器交互的數據方式(統一思想)
"""
![image-20220118212038298]()
5.2、HTTP協議(重點)
'''
協議:大家商量好的一個共同認可的結果
HTTP協議:
規定了瀏覽器與服務端之間數據交互的方式及其他事項 如果我們開發的時候不遵循該協議 那麼瀏覽器就無法識別我們的網站 網站就需要自己編寫一個客戶端(可以不遵循)
'''
# 1.四大特性
01 基於請求響應
服務端永遠不會主動給客戶端發消息 必須是客戶端先發請求
如果想讓服務端主動給客戶端發送消息可以採用其他網路協議
02 基於TCP、IP作用於應用層之上的協議
應用層(HTTP)、傳輸層、網路層、數據鏈路層、物理鏈接層
03 無狀態
不保存客戶端的狀態資訊(早期的網站不需要用戶註冊 所有人訪問的網頁數據都是一樣的)
"""雞哥語錄:縱使見她千百遍 我都當她如初見"""
04 無連接/短連接
兩者請求響應之後立刻斷絕關係
# 2.數據格式
01 請求格式
請求首行(網路請求的方法)
請求頭(一堆K:V鍵值對)
(換行符 不能省略)
請求體(並不是所有的請求方法都有)
02 響應格式
響應首行(相應狀態碼)
響應頭(一堆K:V鍵值對)
(換行符 不能省略)
響應體(即將交給瀏覽器的數據)
# 3.響應體程式碼
用數字來表示一串中文意思
1XX:服務端已經接受到了數據正在處理 你可以繼續發送數據也可以等待
2XX:200 OK 請求成功 服務端返回了相應的數據
3XX:重定向(原本想訪問A頁面 但是自動跳轉到了B頁面)
4XX:403沒有許可權訪問 404請求資源不存在
5XX:伺服器內部錯誤
"""
公司還會自定義狀態碼 一般以10000開頭
參考:聚合數據
"""
5.3、HTML前戲
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
"""
請求首行
b'GET / HTTP/1.1\r\n
請求頭
Host: 127.0.0.1:8080\r\n
Connection: keep-alive\r\n
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"\r\n
sec-ch-ua-mobile: ?0\r\n
sec-ch-ua-platform: "macOS"\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\r\n
Sec-Fetch-Site: none\r\n
Sec-Fetch-Mode: navigate\r\n
Sec-Fetch-User: ?1\r\n
Sec-Fetch-Dest: document\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9\r\n
\r\n
請求體(當前為空)
'
"""
while True:
sock, addr = server.accept()
while True:
data = sock.recv(1024)
if len(data) == 0: break
print(data)
sock.send(b'HTTP/1.1 200 OK\r\n\r\n')
# 遵循HTTP響應格式
sock.send(b'<h1>hello big baby<h1>')
sock.send(b'<a href="//www.jd.com">good see<a>')
sock.send(b'<img src="//imgcps.jd.com/ling4/100013209930/54iG5qy-55u06ZmN/6YOo5YiG5q-P5ruhMTk55YePMTAw/p-5bd8253082acdd181d02fa06/a677079b/cr/s/q.jpg"/>')
# 直接相應
# sock.send(b'hello big baby')
# 用文本內容相應
# with open(r'a.txt', 'rb') as f:
# data = f.read()
# sock.send(data)









