扒一扒@Retryable註解,很優雅,有點意思!
- 2022 年 1 月 17 日
- 筆記
你好呀,我是歪歪。
前幾天我 Review 程式碼的時候發現項目裡面有一坨邏輯寫的非常的不好,一眼望去簡直就是醜陋之極。
我都不知道為什麼會有這樣的程式碼存在項目裡面,於是我看了一眼提交記錄準備叫對應的同事問問,為什麼會寫出這樣的程式碼。
然後…
那一坨程式碼是我 2019 年的時候提交的。
我細細的思考了一下,當時好像由於對項目不熟悉,然後其他的項目裡面又有一個類似的功能,我就直接 CV 大法搞過來了,裡面的邏輯也沒細看。
嗯,原來是歷史原因,可以理解,可以理解。

程式碼裡面主要就是一大坨重試的邏輯,各種硬編碼,各種辣眼睛的修補程式。
特別是針對重試的邏輯,到處都有。所以我決定用一個重試組件優化一波。
今天就帶大家卷一下 Spring-retry 這個組件。

醜陋的程式碼
先簡單的說一下醜陋的程式碼大概長什麼樣子吧。
給你一個場景,假設你負責支付服務,需要對接外部的一個渠道,調用他們的訂單查詢介面。
他們給你說:由於網路問題,如果我們之間交互超時了,你沒有收到我的任何響應,那麼按照約定你可以對這個介面發起三次重試,三次之後還是沒有響應,那就應該是有問題了,你們按照異常流程處理就行。
假設你不知道 Spring-retry 這個組件,那麼你大概率會寫出這樣的程式碼:
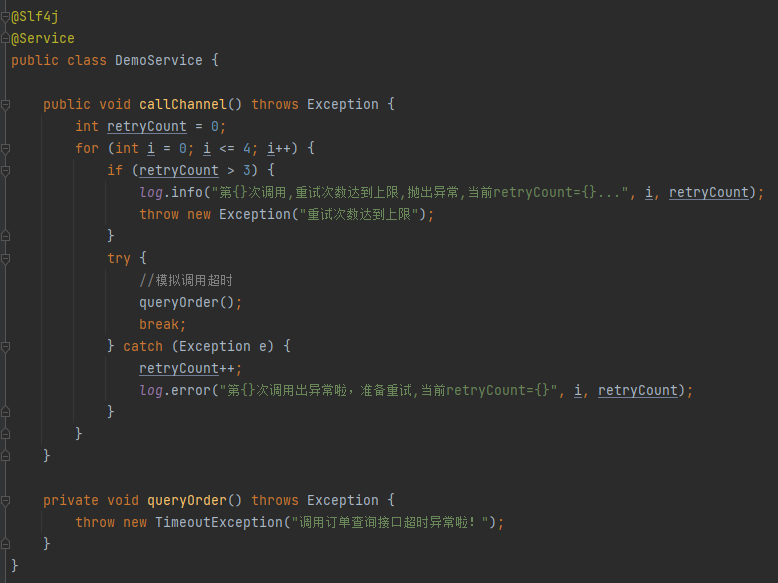
邏輯很簡單嘛,就是搞個 for 循環,然後異常了就發起重試,並對重試次數進行檢查。
然後搞個介面來調用一下:
發起調用之後,日誌的輸出是這樣的,一目了然,非常清晰:
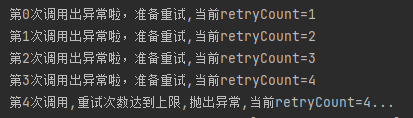
正常調用一次,重試三次,一共可以調用 4 次。在第五次調用的時候拋出異常。
完全符合需求,自測也完成了,可以直接提交程式碼,交給測試同學了。
非常完美,但是你有沒有想過,這樣的程式碼其實非常的不優雅。
你想,如果再來幾個類似的「超時之後可以發起幾次重試」需求。
那你這個 for 循環是不是得到處的搬來搬去。就像是這樣似的,醜陋不堪:
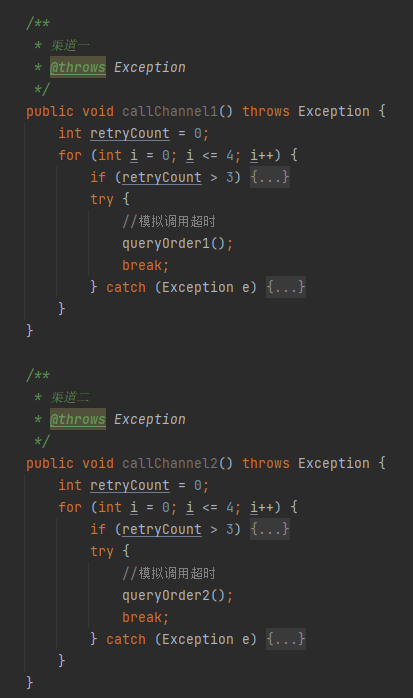
實話實說,我以前也寫過這樣的丑程式碼。

但是我現在是一個有程式碼潔癖的人,這樣的程式碼肯定是不能忍的。
重試應該是一個工具類一樣的通用方法,是可以抽離出來的,剝離到業務程式碼之外,開發的時候我們只需要關注業務程式碼寫的巴巴適適就行了。
那麼怎麼抽離呢?
你說巧不巧,我今天給你分享這個的東西,就把重試功能抽離的非常的好:
//github.com/spring-projects/spring-retry

用上 spring-retry 之後,我們上面的程式碼就變成了這樣:

只是加上了一個 @Retryable 註解,這玩意簡直簡單到令人髮指。
一眼望去,非常的優雅!

所以,我決定帶大家扒一扒這個註解。看看別人是怎麼把「重試」這個功能抽離成一個組件的,這比寫業務程式碼有意思。
我這篇文章不會教大家怎麼去使用 spring-retry,它的功能非常的豐富,寫用法的文章已經非常多了。我想寫的是,當我會使用它之後,我是怎麼通過源碼的方式去了解它的。
怎麼把它從一個只會用的東西,變成簡歷上的那一句:翻閱過相關源碼。

但是你要壓根都不會用,都沒聽過這個組件怎麼辦呢?
沒關係,我了解一個技術點的第一步,一定是先搭建出一個非常簡單的 Demo。
沒有跑過 Demo 的一律當做一無所知處理。
先搭 Demo
我最開始也是對這個註解一無所知的。
所以,對於這種情況,廢話少說,先搞個 Demo 跑起來才是王道。
但是你記住搭建 Demo 也是有技巧的:直接去官網或者 github 上找就行了,那裡面有最權威的、最簡潔的 Demo。
比如 spring-retry 的 github 上的 Quick Start 就非常簡潔易懂。

它分別提供了註解式開發和編程式開發的示例。
我們這裡主要看它的註解式開發案例:
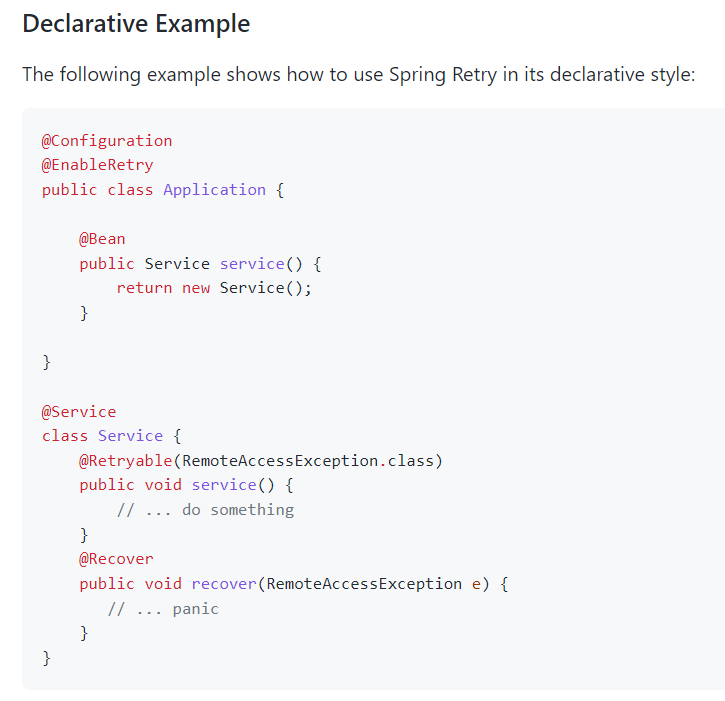
裡面涉及到三個註解:
-
@EnableRetry:加在啟動類上,表示支援重試功能。 -
@Retryable:加在方法上,就會給這個方法賦能,讓它有用重試的功能。 -
@Recover:重試完成後還是不成功的情況下,會執行被這個註解修飾的方法。
看完 git 上的 Quick Start 之後,我很快就搭了一個 Demo 出來。
如果你之前不了解這個組件的使用方法的話,我強烈建議你也搭一個,非常的簡單。
首先是引入 maven 依賴:
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
<version>1.3.1</version>
</dependency>
由於該組件是依賴於 AOP 給你的,所以還需要引入這個依賴:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
<version>2.6.1</version>
</dependency>
然後是程式碼,就這麼一點,就夠夠的了:
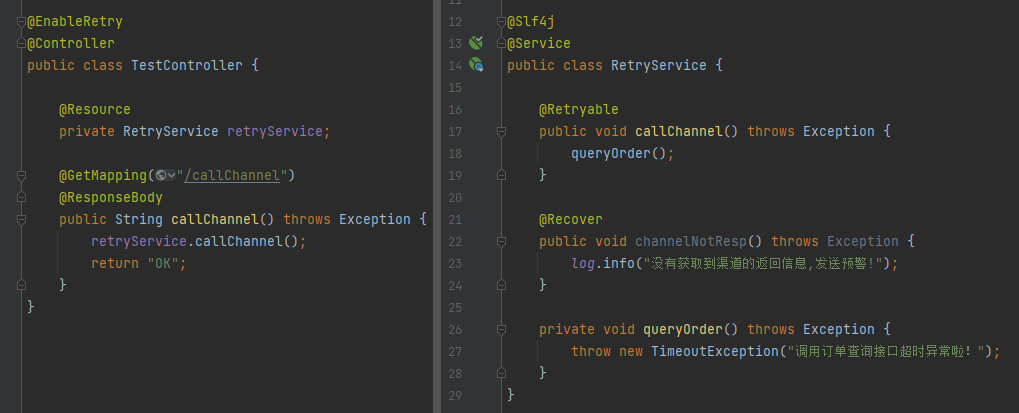
最後把項目跑起來,調用一筆,確實是生效了,執行了 @Recover 修飾的方法:
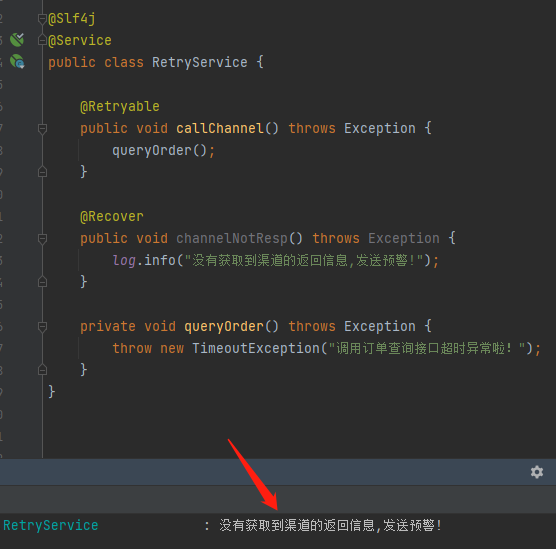
但是日誌就只有一行,也沒有看到重試的操作,未免有點太簡陋了吧?
我以前覺得無所謂,迫不及待的衝到源碼裡面去一頓狂翻,左看右看。

我是怎麼去狂翻源碼做呢?
就是直接看這個註解被調用的地方,就像是這樣:
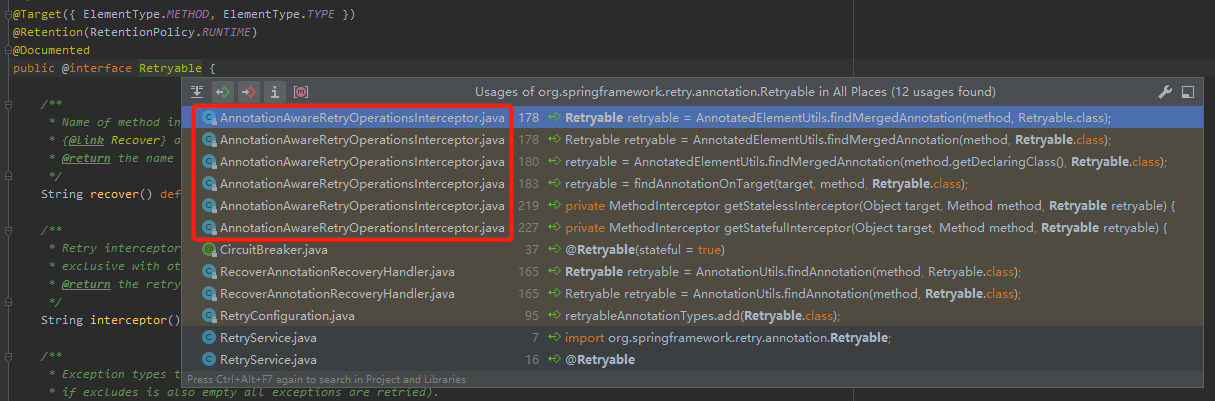
調用的地方不多,確實也很容易就定位到下面這個關鍵的類:
org.springframework.retry.annotation.AnnotationAwareRetryOperationsInterceptor
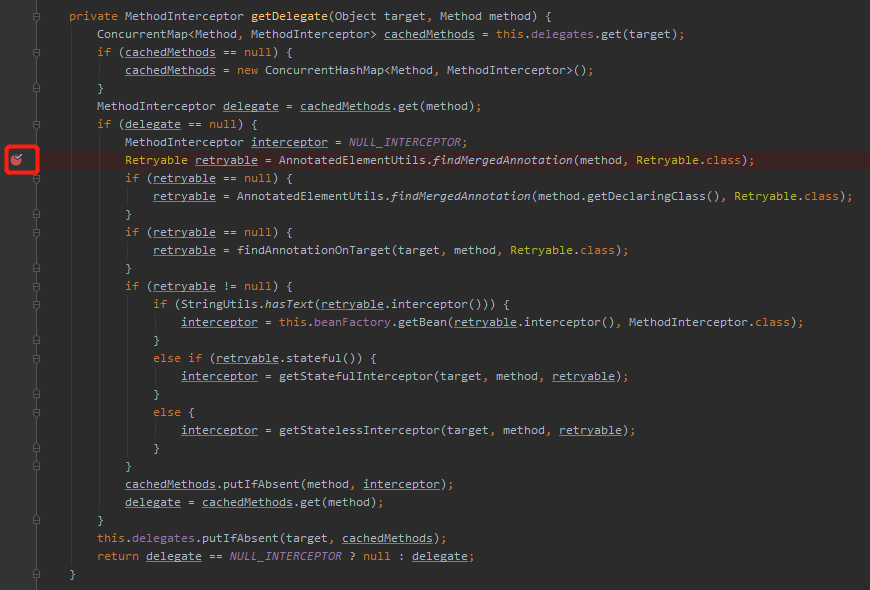
然後在相應的位置打上斷點,開始跑程式,進行 debug:
但是我現在不會這麼猴急了,作為一個老程式設計師,現在就成熟了很多,不會先急著去卷源碼,會先多從日誌裡面挖掘一點東西出來。
我現在遇到這個問題的第一反應就是調整日誌級別到 debug:
logging.level.root=debug
修改日誌級別重啟並再次調用之後,就能看到很多有價值的日誌了:
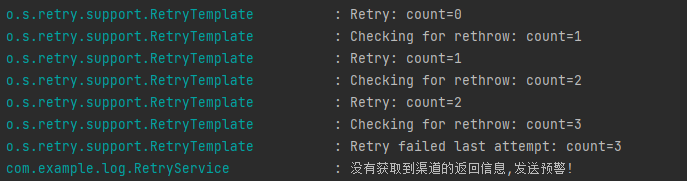
基於日誌,可以直接找到這個地方:
org.springframework.retry.support.RetryTemplate#doExecute
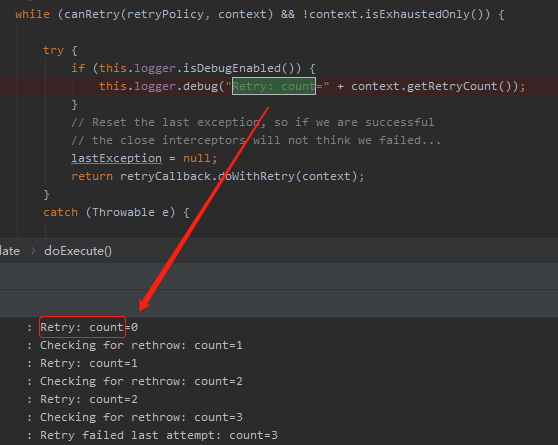
在這裡打上斷點進行調試,才是最合適的地方。
這也算是一個調試小技巧吧。以前我經常忽略日誌裡面的輸出,感覺一大坨難得去看,其實仔細去分析日誌之後你會發現這裡面有非常多的有價值的東西,比你一頭扎到源碼裡面有效多了。
你要是不信,你可以去試著看一下 Spring 事務相關的 debug 日誌,我覺得那是一個非常好的案例,列印的那叫一個清晰。
從日誌就能推動你不同隔離級別下的 debug 的過程,還能保持清晰的鏈路,不會有雜亂無序的感覺。
好了,不扯遠了。
我們再看看這個日誌,這個輸出你不覺得很熟悉嗎?
這不和剛剛我們前面出現的一張圖片神似嗎?
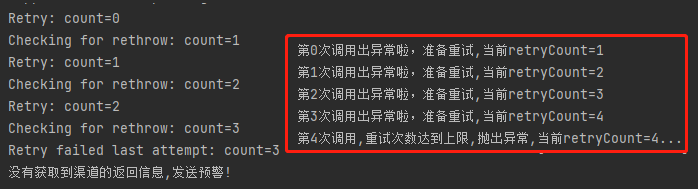
看到這裡一絲笑容浮現在我的嘴角:小樣,我盲猜你源碼裡面肯定也寫了一個 for 循環。如果循環裡面拋出異常,那麼就檢測是否滿足重試條件,如果滿足則繼續重試。不滿足,則執行 @Recover 的邏輯。
要是猜錯了,我直接把電腦螢幕給吃了。
好,flag 先立在這裡了,接下來我們去擼源碼。
等等,先停一下。
如果說我們前面找到了 Debug 第一個斷點打的位置,那麼真正進入源碼調試之前,還有一個非常關鍵的操作,那就是我之前一再強調的,一定要帶著比較具體的問題去翻源碼。
而我前面立下的 flag 其實就是我的問題:我先給出一個猜想,再去找它是不是這樣實現的,具體到程式碼上是怎麼實現。
所以再梳理了一下我的問題:
-
1.找到它的 for 循環在哪裡。 -
2.它是怎麼判斷應該要重試的? -
3.它是怎麼執行到 @Recover 邏輯的?
現在可以開始發車了。
翻源碼
源碼之下無秘密。
首先我們看一下前面找到的 Debug 入口:
org.springframework.retry.support.RetryTemplate#doExecute
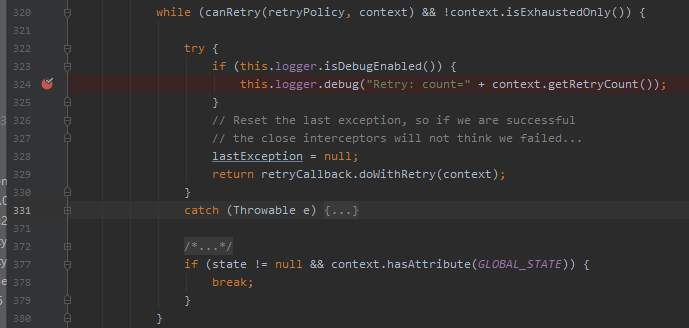
從日誌裡面可以直觀的看出,這個方法裡面肯定就包含我要找的 for 循環。
但是…
很遺憾,並不是 for 循環,而是一個 while 循環。問題不大,意思差不多:
打上斷點,然後把項目跑起來,跑到斷點的地方我最關心的是下面的調用堆棧:
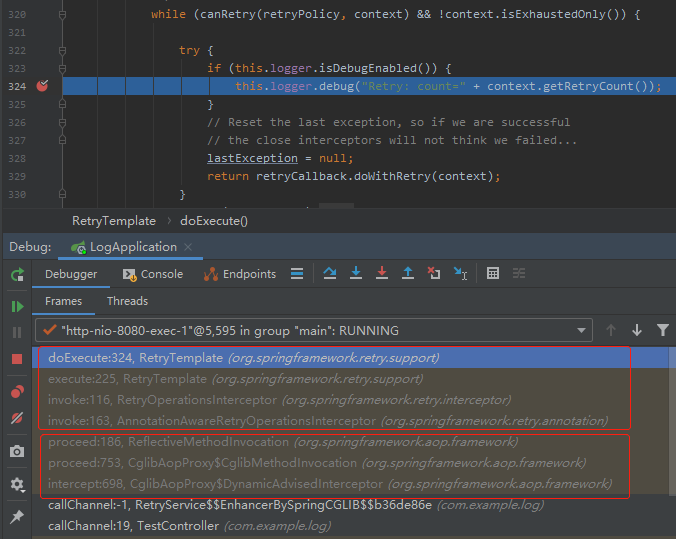
被框起來了兩部分,一部分是 spring-aop 包裡面的內容,一部分是 spring-retry。
然後我們看到 spring-retry 相關的第一個方法:
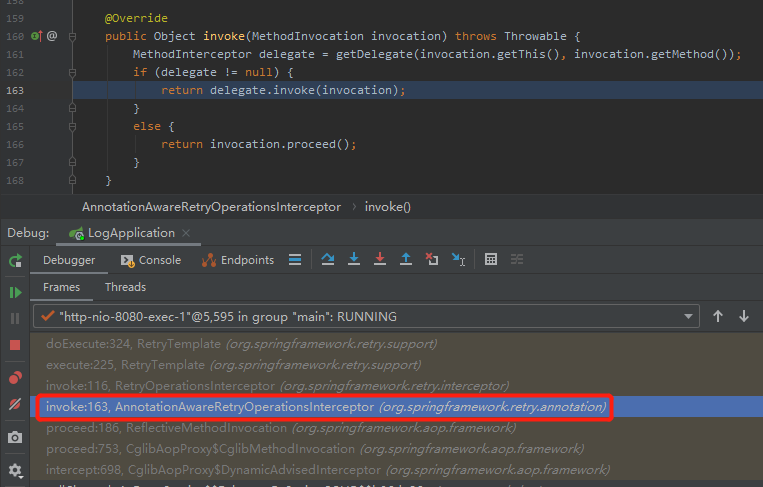
恭喜你,如果說前面通過日誌找到了第一個打斷點的位置,那麼通過第一個斷點的調用堆棧,我們找到了整個 retry 最開始的入口處,另外一個斷點就應該打在下面這個方法的入口處:
org.springframework.retry.annotation.AnnotationAwareRetryOperationsInterceptor#invoke
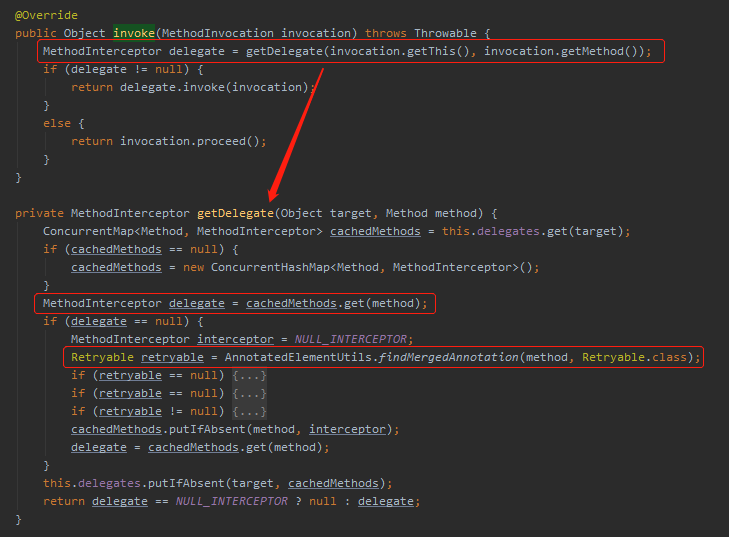
說真的,觀察日誌加調用棧這個最簡單的組合拳用好了,調試絕大部分源碼的過程中都不會感覺特別的亂。
找到了入口了,我們就從介面處接著看源碼。
這個 invoke 方法一進來首先是試著從快取中獲取該方法是否之前被成功解析過,如果快取中沒有則解析當前調用的方法上是否有 @Retryable 註解。
如果是被 @Retryable 修飾的,返回的 delegate 對象則不會是 null。所以會走到 retry 包的程式碼邏輯中去。
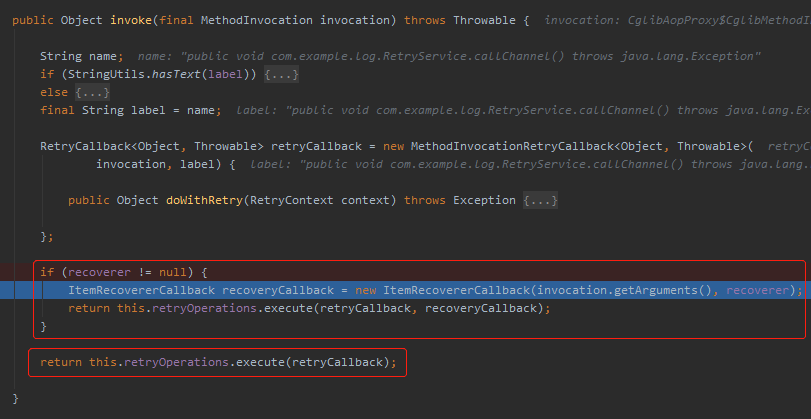
然後在 invoke 這裡有個小細節,如果 recoverer 對象不為空,則執行帶回調的。如果為空則執行沒有 recoverCallback 對象方法。
我看到這幾行程式碼的時候就大膽猜測: @Recover 註解並不是必須的。
於是我興奮的把這個方法註解掉並再次運行項目,發現還真是,有點不一樣了:
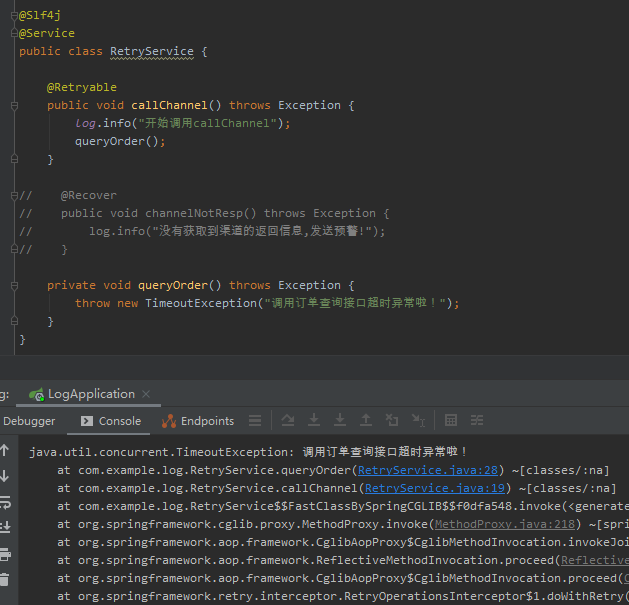
在我沒有看其他文章、沒有看官方介紹,僅通過一個簡單的示例就發掘到他的一個用法之後,這屬於意外收穫,也是看源碼的一點小樂趣。
其實源碼並沒有那麼可怕的。

但是看到這裡的時候另外一個問題就隨之而來了:
這個 recoverer 對象看起來就是我寫的 channelNotResp 方法,但是它是在什麼時候解析到的呢?
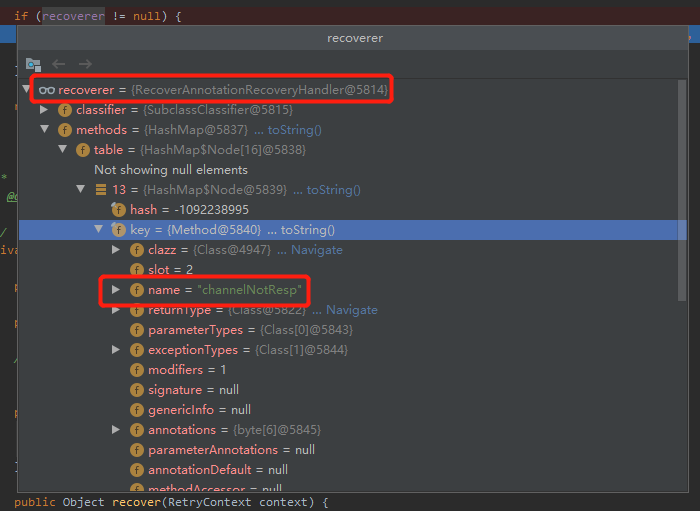
按下不表,後面再說,當務之急是找到重試的地方。
在當前的這個方法中再往下走幾步,很快就能到我前面說的 while 循環中來:
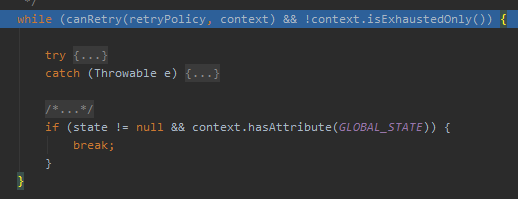
主要關注這個 canRetry 方法:
org.springframework.retry.RetryPolicy#canRetry
點進去之後,發現是一個介面,擁有多個實現:
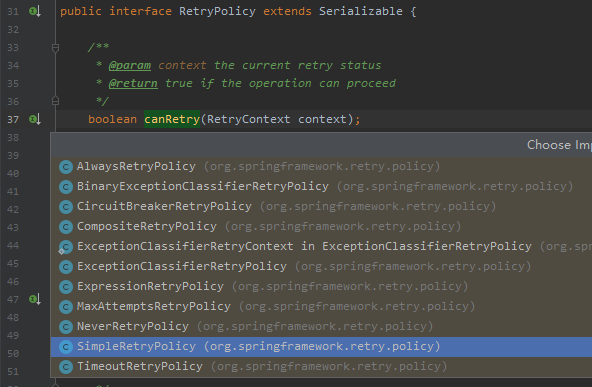
簡單的介紹一下其中的幾種含義是啥:
-
AlwaysRetryPolicy:允許無限重試,直到成功,此方式邏輯不當會導致死循環 -
NeverRetryPolicy:只允許調用RetryCallback一次,不允許重試 -
SimpleRetryPolicy:固定次數重試策略,默認重試最大次數為3次,RetryTemplate默認使用的策略 -
TimeoutRetryPolicy:超時時間重試策略,默認超時時間為1秒,在指定的超時時間內允許重試 -
ExceptionClassifierRetryPolicy:設置不同異常的重試策略,類似組合重試策略,區別在於這裡只區分不同異常的重試 -
CircuitBreakerRetryPolicy:有熔斷功能的重試策略,需設置3個參數openTimeout、resetTimeout和delegate -
CompositeRetryPolicy:組合重試策略,有兩種組合方式,樂觀組合重試策略是指只要有一個策略允許即可以重試,悲觀組合重試策略是指只要有一個策略不允許即不可以重試,但不管哪種組合方式,組合中的每一個策略都會執行
那麼這裡問題又來了,我們調試源碼的時候這麼有多實現,我怎麼知道應該進入哪個方法呢?
記住了,介面的方法上也是可以打斷點的。你不知道會用哪個實現,但是 idea 知道:
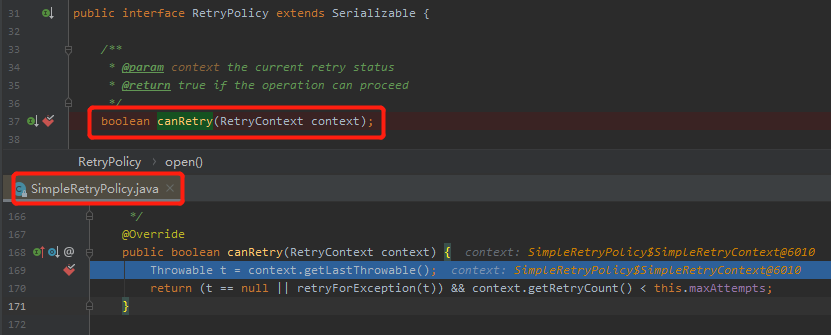
這裡就是用的 SimpleRetryPolicy 策略,即這個策略是 Spring-retry 的默認重試策略。
t == null || retryForException(t)) && context.getRetryCount() < this.maxAttempts
這個策略的邏輯也非常簡單:
-
1.如果有異常,則執行 retryForException 方法,判斷該異常是否可以進行重試。 -
2.判斷當前已重試次數是否超過最大次數。
在這裡,我們找到了控制重試邏輯的地方。
上面的第二點很好理解,第一點說明這個註解和事務註解 @Transaction 一樣,是可以對指定異常進行處理的,可以看一眼它支援的選項:
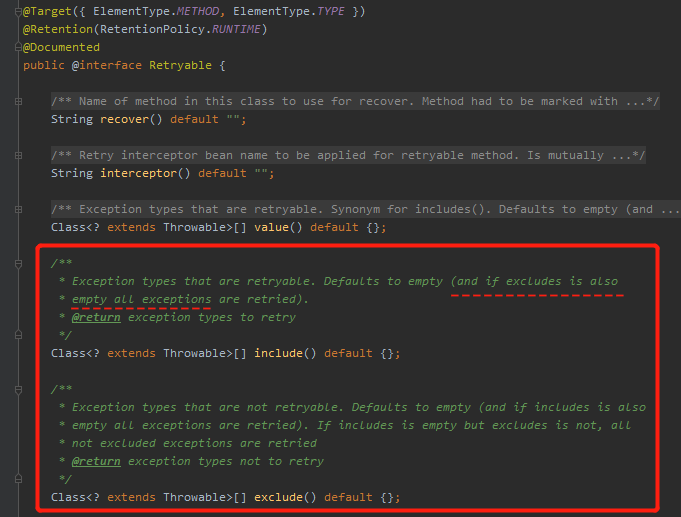
注意 include 裡面有句話我標註了起來,意思是說,這個值默認為空。且當 exclude 也為空時,默認是所有異常。
所以 Demo 裡面雖然什麼都沒配,但是拋出 TimeoutException 也會觸發重試邏輯。
又是一個通過翻源碼挖掘到的知識點,這玩意就像是探索彩蛋似的,舒服。
看完判斷是否能進行重試調用的邏輯之後,我們接著看一下真正執行業務方法的地方:
org.springframework.retry.RetryCallback#doWithRetry
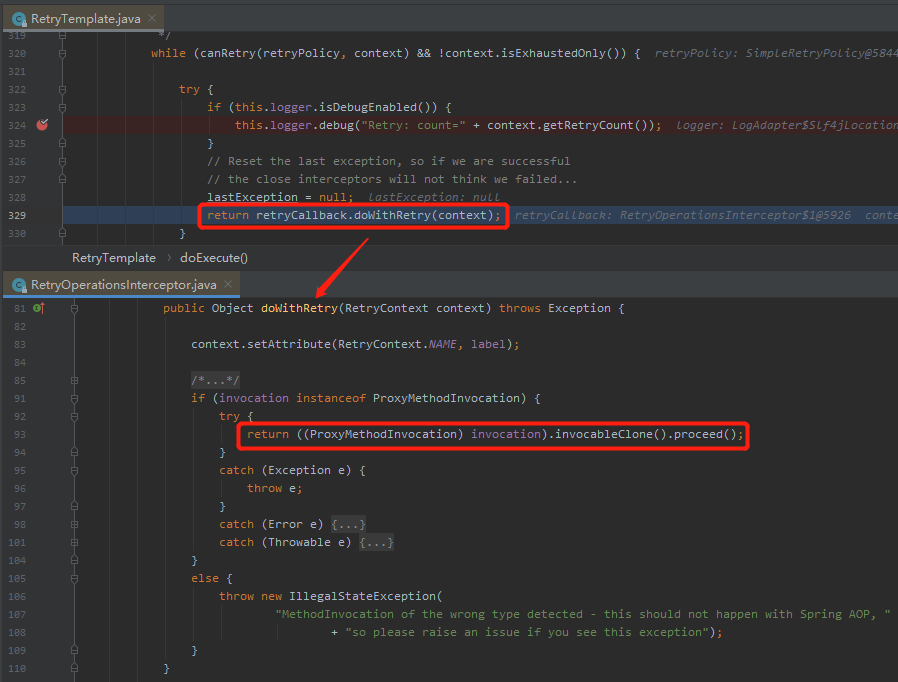
一眼就能看出來了,這裡面就是應該非常熟悉的動態代理機制,這裡的 invocation 就是我們的 callChannel 方法:
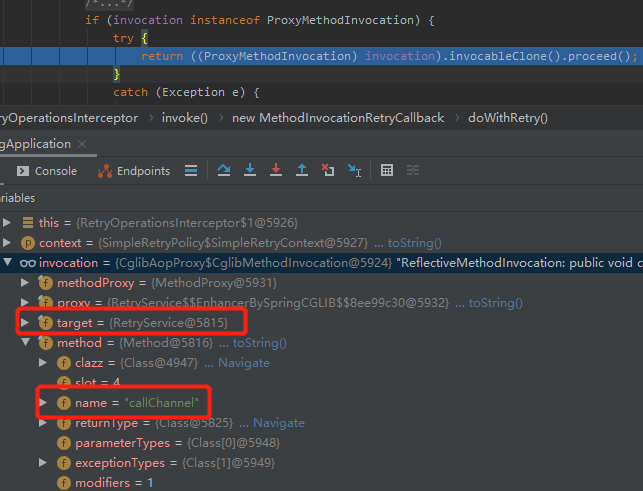
從程式碼我們知道,callChannel 方法拋出的異常,在 doWithRetry 方法裡面會進行捕獲,然後直接扔出去:
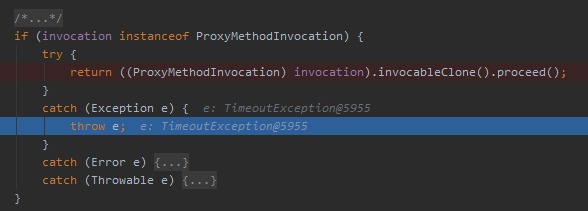
這裡其實也很好理解的,因為需要拋出異常來觸發下一次的重試。
但是這裡也暴露了一個 Spring-retry 的弊端,就是必須要通過拋出異常的方式來觸發相關業務。
聽著好像也是沒有毛病,但是你想想一下,假設渠道方說如果我給你返回一個 500 的 ErrorCode,那麼你也可以進行重試。
這樣的業務場景應該也是比較多的。
如果你要用 Spring-retry 會怎麼做?
是不是得寫出這樣的程式碼:
if(errorCode==500){
throw new Exception("手動拋出異常");
}
意思就是通過拋出異常的方式來觸發重試邏輯,算是一個不是特別優雅的設計吧。
其實根據返回對象中的某個屬性來判斷是否需要重試對於這個框架來說擴展起來也不算很難的事情。
你想,它這裡本來就能拿到返回。只需要提供一個配置的入口,讓我們告訴它當哪個對象的哪個欄位為某個值的時候也應該進行重試。
當然了,大佬肯定有自己的想法,我這裡都是一些不成熟的拙見而已。其實另外的一個重試框架 Guava-Retry,它就支援根據返回值進行重試。
不是本文重點就不擴展了。
接著往下看 while 循環中捕獲異常的部分。
裡面的邏輯也不複雜,但是下面框起來的部分可以注意一下:
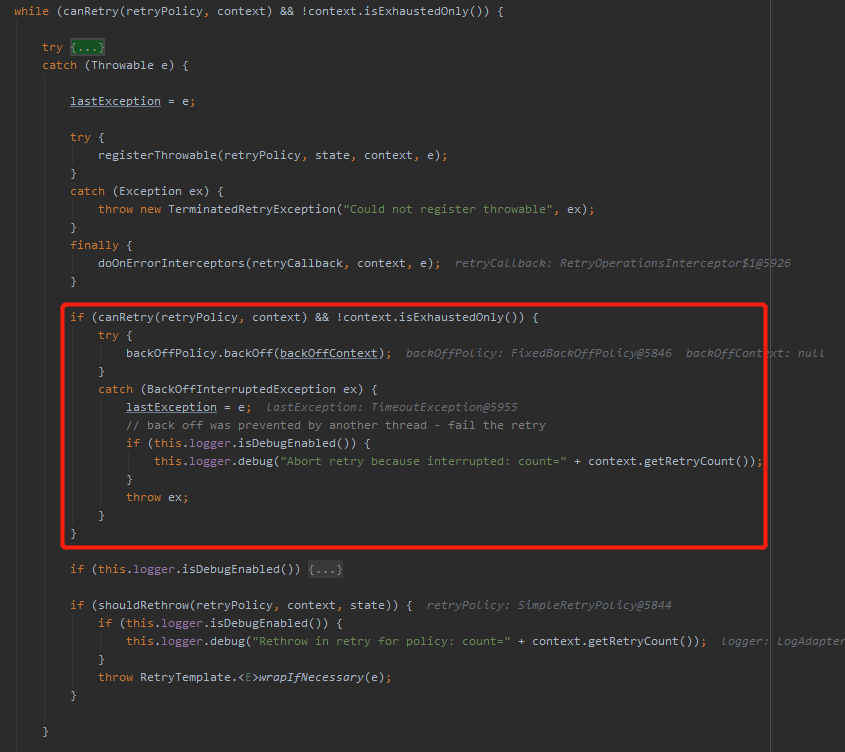
這裡又判斷了一次是否可以重試,是幹啥呢?
是為了執行這行程式碼:
backOffPolicy.backOff(backOffContext);
它是幹啥的?
我也不知道,debug 看一眼,最後會走到這個地方:
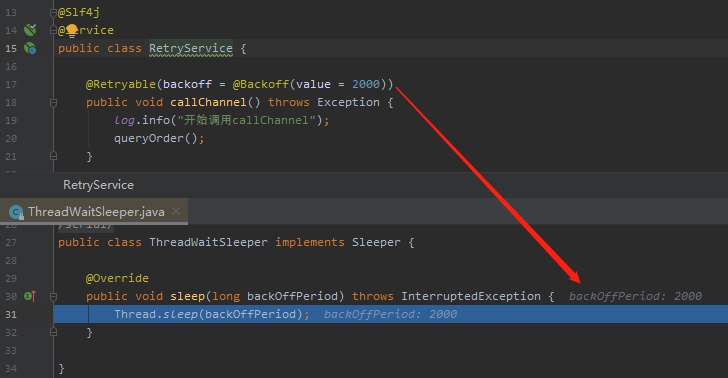
org.springframework.retry.backoff.ThreadWaitSleeper#sleep
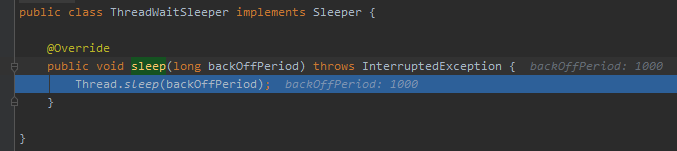
在這裡執行睡眠 1000ms 的操作。
我一下就懂了,這玩意在這裡給你留了個抓手,你可以設置重試間隔時間的抓手。然後默認給你賦能 1000ms 後重試的功能。

然後我在 @Retryable 註解裡面找到了這個東西:
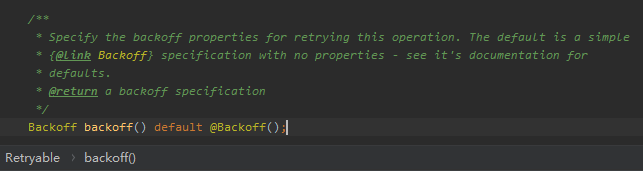
這玩意一眼看不懂是怎麼配置的,但是它上面的註解叫我看看 Backoff 這個玩意。
它長這樣:
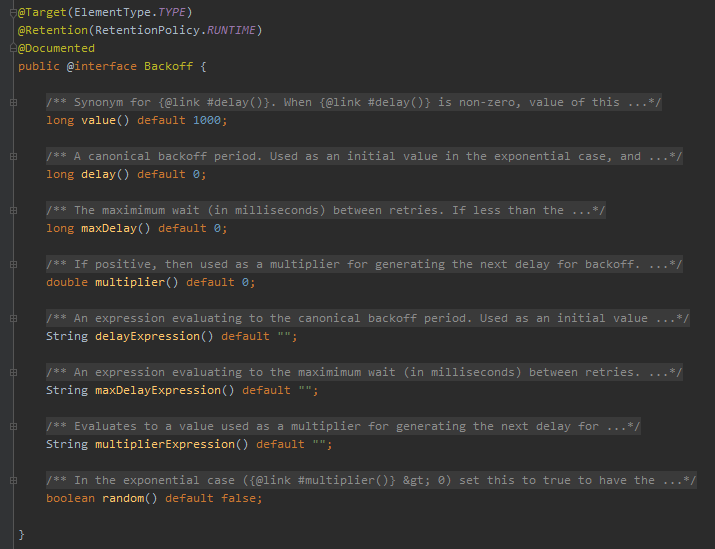
這東西看起來就好理解多了,先不管其他的參數吧,至少我看到了 value 的默認值是 1000。
我懷疑就是這個參數控制的指定重試間隔,所以我試了一下:
果然是你小子,又讓我挖到一個彩蛋。
在 @Backoff 裡面,除了 value 參數,還有很多其他的參數,他們的含義分別是這樣的:
-
delay:重試之間的等待時間(以毫秒為單位) -
maxDelay:重試之間的最大等待時間(以毫秒為單位) -
multiplier:指定延遲的倍數 -
delayExpression:重試之間的等待時間表達式 -
maxDelayExpression:重試之間的最大等待時間表達式 -
multiplierExpression:指定延遲的倍數表達式 -
random:隨機指定延遲時間
就不一一給你演示了,有興趣自己玩去吧。
因為豐富的重試時間配置策略,所以也根據不同的策略寫了不同的實現:
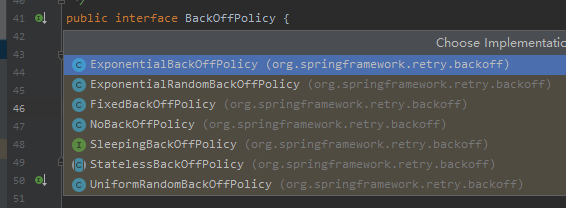
通過 Debug 我知道了默認的實現是 FixedBackOffPolicy。
其他的實現就不去細研究了,我主要是抓主要鏈路,先把整個流程打通,之後自己玩的時候再去看這些枝幹的部分。
在 Demo 的場景下,等待一秒鐘之後再次發起重試,就又會再次走一遍 while 循環,重試的主鏈路就這樣梳理清楚了。
其實我把程式碼摺疊一下,你可以看到就是在 while 循環裡面套了一個 try-catch 程式碼塊而已:
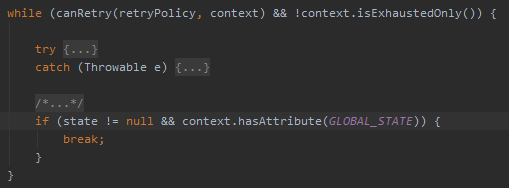
這和我們之前寫的丑程式碼的骨架是一樣的,只是 Spring-retry 把這部分程式碼進行擴充並且藏起來了,只給你提供一個註解。
當你只拿到這個註解的時候,你把它當做一個黑盒用的時候會驚呼:這玩意真牛啊。
但是現在當你抽絲剝繭的翻一下源碼之後,你就會說:就這?不過如此,我覺得也能寫出來啊。

到這裡前面拋出的問題中的前兩個已經比較清晰了:
問題一:找到它的 for 循環在哪裡。
沒有 for 循環,但是有個 while 循環,其中有一個 try-catch。
問題二:它是怎麼判斷應該要重試的?
判斷要觸發重試機制的邏輯還是非常簡單的,就是通過拋出異常的方式觸發。
但是真的要不要執行重試,才是一個需要仔細分析的重點。
Spring-retry 有非常多的重試策略,默認是 SimpleRetryPolicy,重試次數為 3 次。
但是需要特別注意的是它這個「3次」是總調用次數為三次。而不是第一次調用失敗後再調用三次,這樣就共計 4 次了。關於到底調用幾次的問題,還是得分清楚才行。
而且也不一定是拋出了異常就肯定會重試,因為 Spring-retry 是支援對指定異常進行處理或者不處理的。
可配置化,這是一個組件應該具備的基礎能力。
還是剩下最後一個問題:它是怎麼執行到 @Recover 邏輯的?
接著懟源碼吧。
Recover邏輯
首先要說明的是 @Recover 註解並不是一個必須要有的東西,前面我們也分析了,就不再贅述。
但是這個功能用起來確實是不錯的,絕大部分異常都應該有對應的兜底措施。
這個東西,就是來執行兜底的動作的。
它的源碼也非常容易找到,就緊跟在重試邏輯之後:
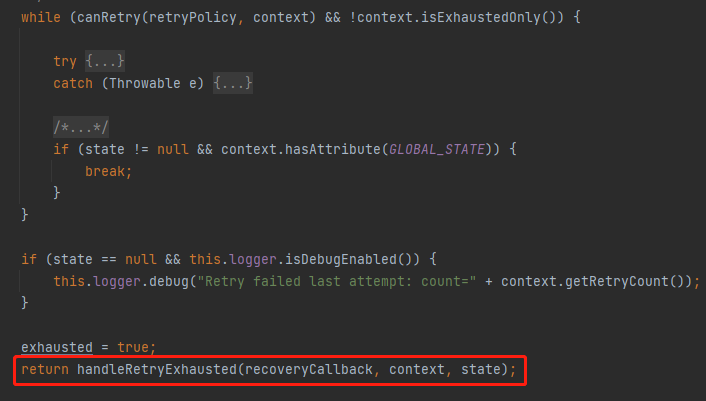
往下 Debug 幾步你就會走到這個地方來:
org.springframework.retry.annotation.RecoverAnnotationRecoveryHandler#recover
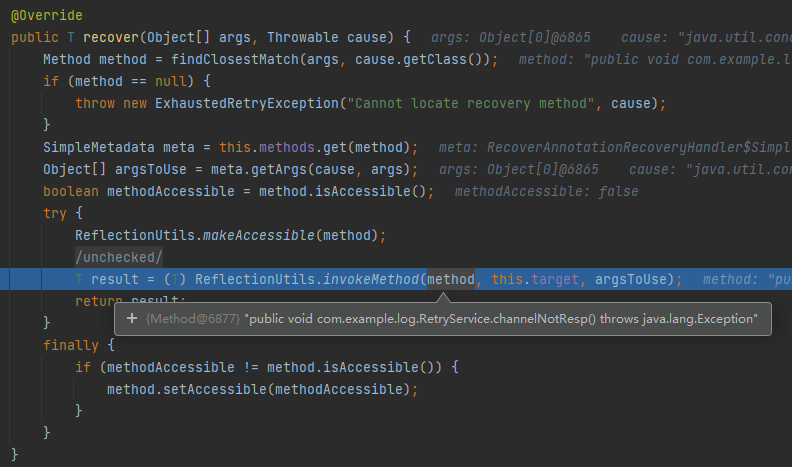
又是一個反射調用,這裡的 method 已經是 channelNotResp 方法了。
那麼問題就來了:Spring-retry 是怎麼知道我的重試方法就是 channelNotResp 的呢?
仔細看上面的截圖中的 method 對象,不難發現它是方法的第一行程式碼產生的:
Method method = findClosestMatch(args, cause.getClass());
這個方法從名字和返回值上看叫做找一個最相近的方法。但是具體不太明白啥意思。
跟進去看一眼它在幹啥:
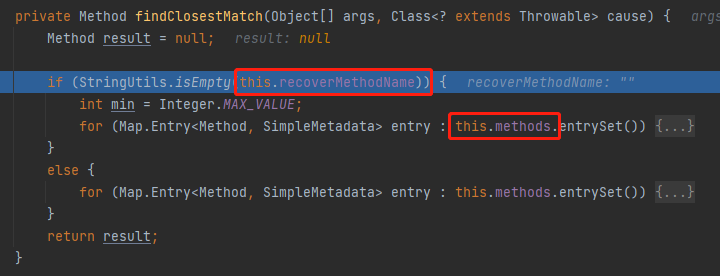
這個裡面有兩個關鍵的資訊,一個叫做 recoverMethodName,當這個值為空和不為空的時候走的是兩個不同的分支。
還有一個參數是 methods,這是一個 HashMap:
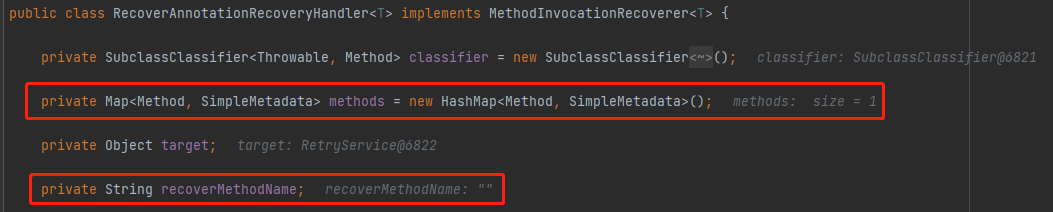
這個 Map 裡面放的就是我們的兜底方法 channelNotResp:

而這個 Map 不論是走哪個分支都是需要進行遍歷的。
這個 Map 裡面的 channelNotResp 是什麼時候放進去的呢?
很簡單,看一下這個 Map 的 put 方法調用的地方就完事了:
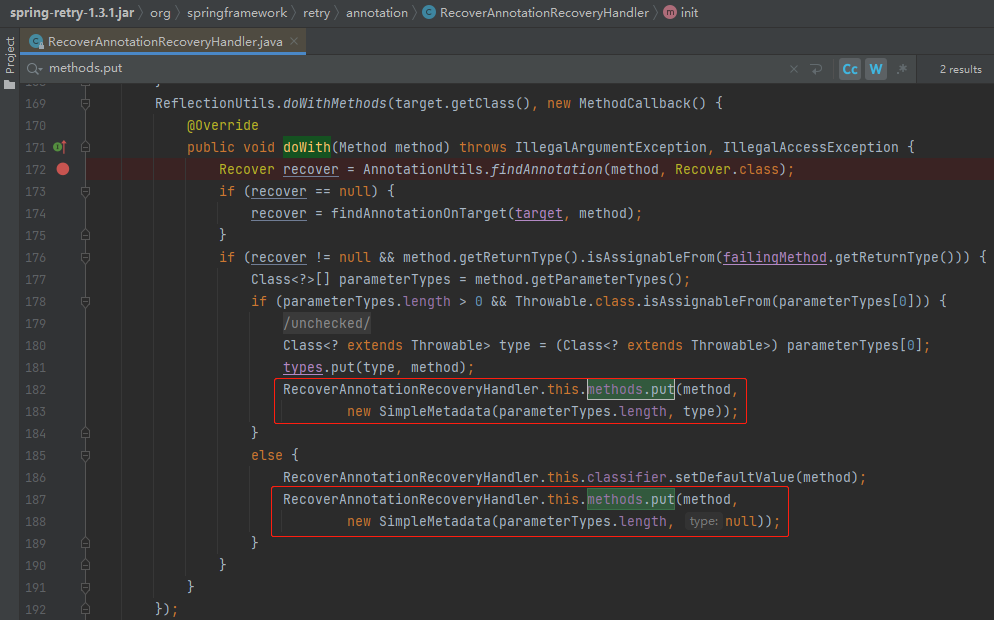
就這兩個 put 的地方,源碼位於下面這個方法中:
org.springframework.retry.annotation.RecoverAnnotationRecoveryHandler#init
從截圖中可以看出,這裡是在找 class 裡面有沒有被 @Recover 註解修飾的方法。
我在第 172 行打上斷點,調試一下看一下具體的資訊,你就知道這裡是在幹什麼了。
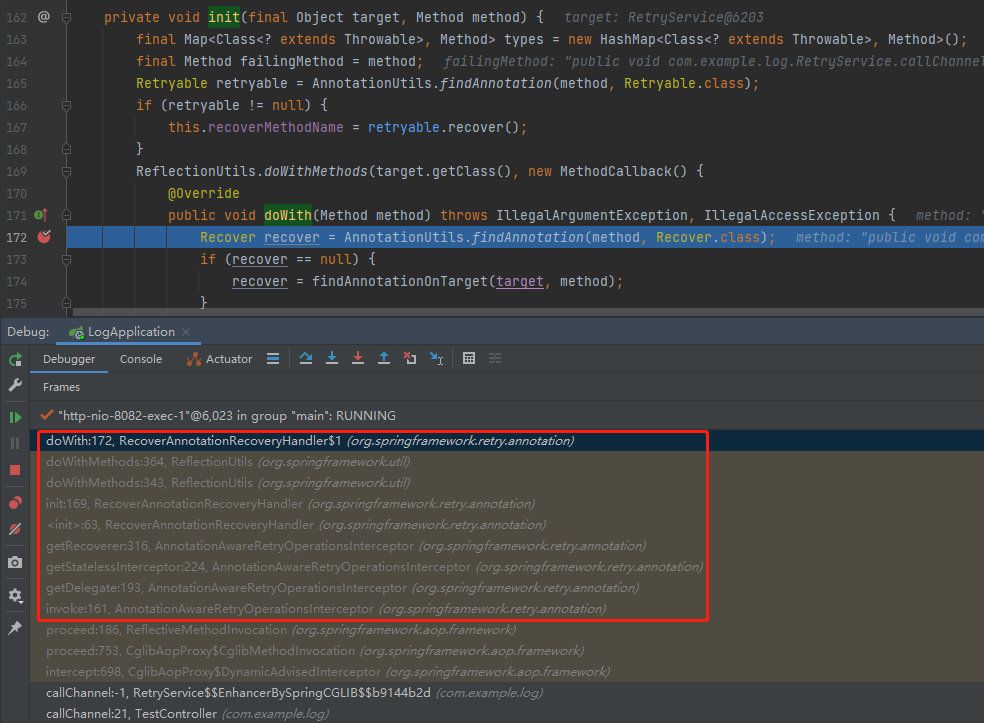
在你發起調用之後,程式會在斷點處停下,至於是怎麼走到這裡的,前面說過,看調用堆棧,就不再贅述了。
關於這個 doWith 方法,我們把調用堆棧往上看一步,就知道這裡是在解析我們的 RetryService 類裡面的所有方法:
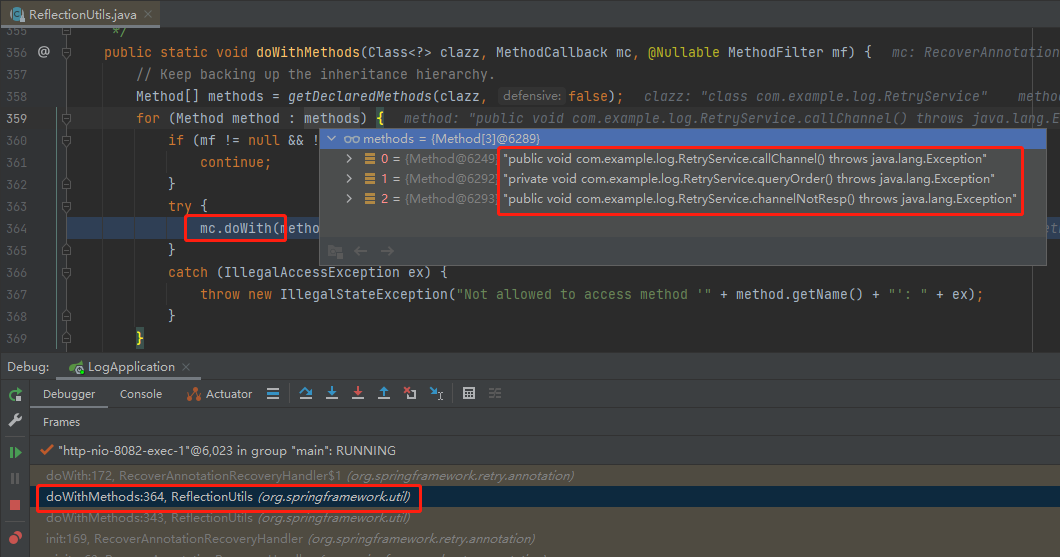
當解析到 channelNotResp 方法的時候,會識別出該方法上標註了 @Recover 註解。
但從源碼上看,要進行進一步解析,要滿足 if 條件。而 if 條件除了要有 Recover 之外,還需要滿足這個東西:
method.getReturnType().isAssignableFrom(failingMethod.getReturnType())
isAssignableFrom 方法是判斷是否為某個類的父類。
就是的 method 和 failingMethod 分別如下:
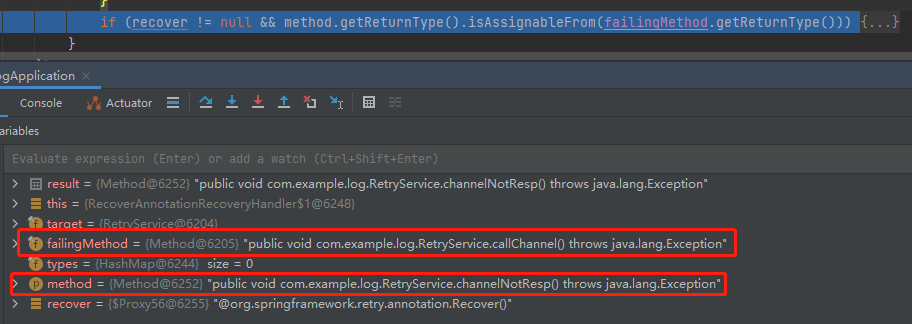
這是在檢查被 @Retryable 標註的方法和被 @Recover 標註的方法的返回值是否匹配,只有返回值匹配才說明這是一對,應該進行解析。
比如,我把源碼改成這樣:

當它解析到 channelNotRespStr 方法的時候,會發現雖然被 @Recover 註解修飾了,但是返回值並不一致,從而知道它並不是目標方法 callChannel 的兜底方法。
源碼裡面的常規套路罷了。
再加入一個 callChannelSrt 方法,在上面的源碼中 Spring-retry 就能幫你解析出誰和誰是一對:
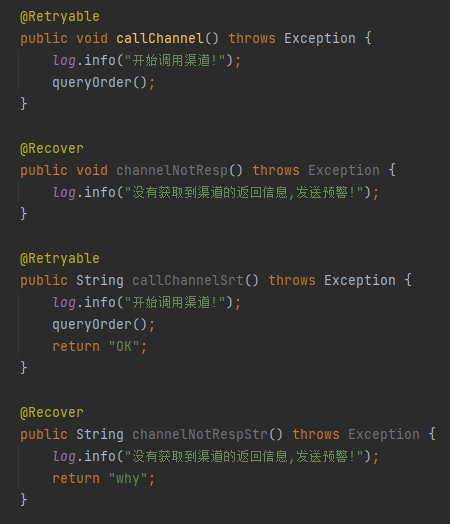
接著看一下如果滿足條件,匹配上了,if 裡面在幹啥呢?
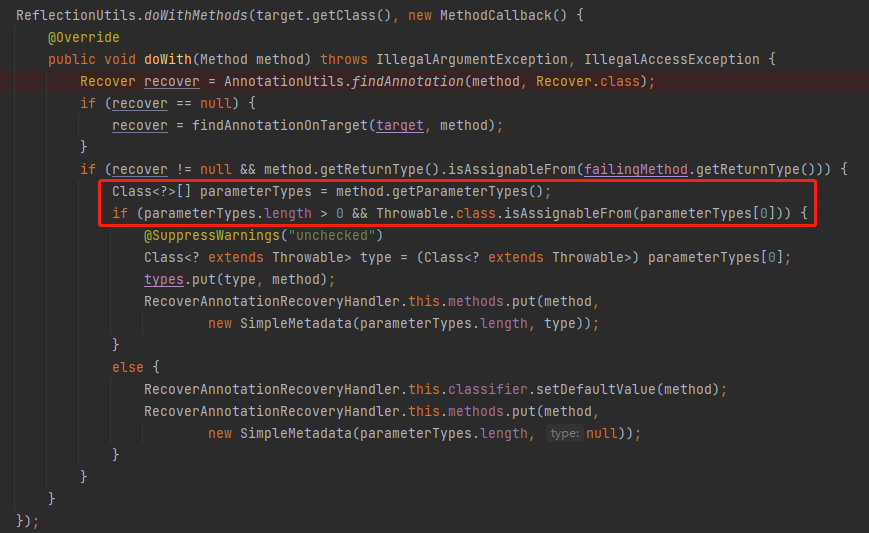
這是在獲取方法上的入參呀,但是仔細一看,也只是為了獲取第一個參數,且這個參數要滿足一個條件:
Throwable.class.isAssignableFrom(parameterTypes[0])
必須是 Throwable 的子類,也就說說它必須是一個異常。用 type 欄位來承接,然後下面會把它給存起來。
第一次看的時候肯定沒看懂這是在幹啥,沒關係,我看了幾次看明白了,給你分享一下,這裡是為了這一小節最開始出現的這個方法服務的:
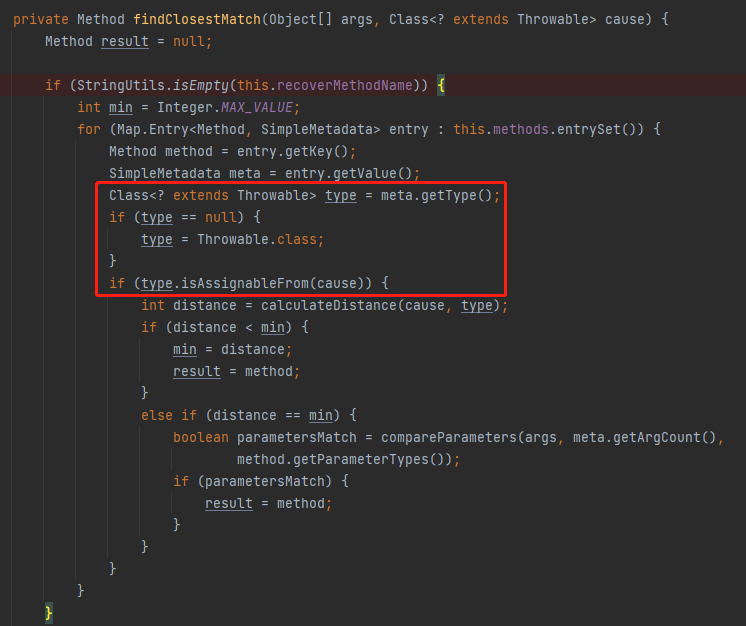
在這裡面獲取了這個 type,判斷如果 type 為 null 則默認為 Throwable.class。
如果有值,就判斷這裡的 type 是不是當前程式拋出的這個 cause 的同類或者父類。
再強調一遍,從這個方法從名字和返回值上看,我們知道是要找一個最相近的方法,前面我說具體不太明白啥意思都是為了給你鋪墊了一大堆 methods 這個 Map 是怎麼來的。
其實我心裡明鏡兒似的,早就想扯下它的面紗了。

來,跟著我的思路馬上就能看到葫蘆里到底賣的是什麼酒了。
你想,findClosestMatch,這個 Closest 是 Close 的最高級,表示最接近的意思。
既然有最接近,那麼肯定是有幾個東西放在一起,這裡面只有一個是最符合要求的。
在源碼中,這個要求就是「cause」,就是當前拋出的異常。
而「幾個東西」指的就是這個 methods 裝的東西裡面的 type 屬性。
還是有點暈,對不對,別慌,下面這張圖片一出來,馬上就不暈了:
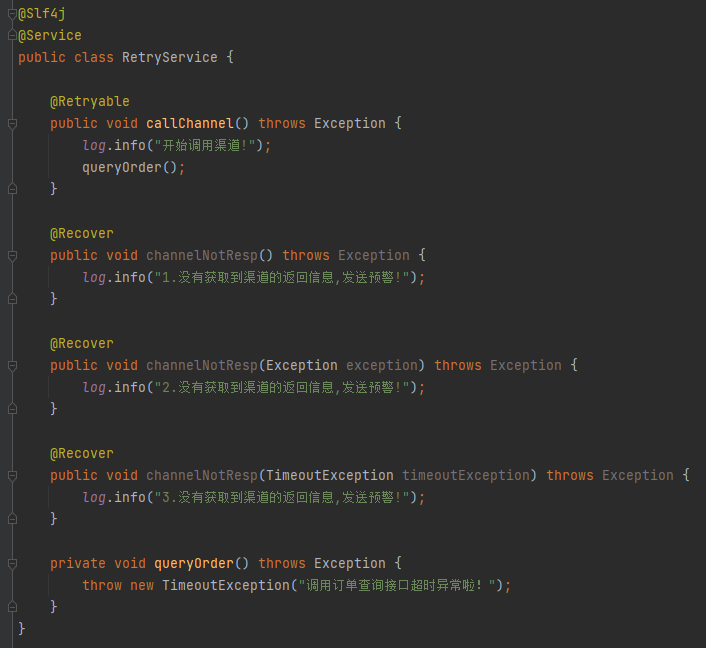
拿這個程式碼去套「Closest」這個玩意。
首先,cause 就是拋出的 TimeoutException。
而 methods 這個 Map 裡面裝的就是三個被 @Recover 註解修飾的方法。
為什麼有三個?
好問題,說明我前面寫的很爛,導致你看的不太明白。沒事,我再給你看看往 methods 裡面 put 東西的部分的程式碼:
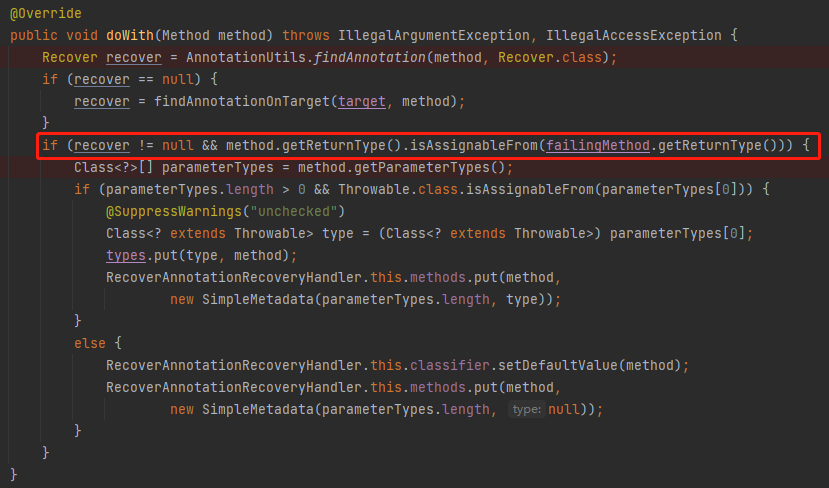
這三個方法都滿足被 @Recover 註解的條件,且同時也滿足返回值和目標方法 callChannel 的返回值一致的條件。那就都得往 methods 裡面 put,所以是三個。
這裡也解釋了為什麼兜底方法是用一個 Map 裝著呢?
我最開始覺得這是「兜底方法」的兜底策略,因為永遠要把用戶當做那啥,你不知道它會寫出什麼神奇的程式碼。
比如我上面的例子,其實最後生效的一定是這個方法:
@Recover
public void channelNotResp(TimeoutException timeoutException) throws Exception {
log.info("3.沒有獲取到渠道的返回資訊,發送預警!");
}
因為它是 Closest。
給你截個圖,表示我沒有亂說:

但是,校稿的時候我發現這個地方不對,並不是用戶那啥,而是真的有可能會出現一個 @Retryable 修飾的方法,針對不同的異常有不同的兜底方法的。
比如下面這樣:
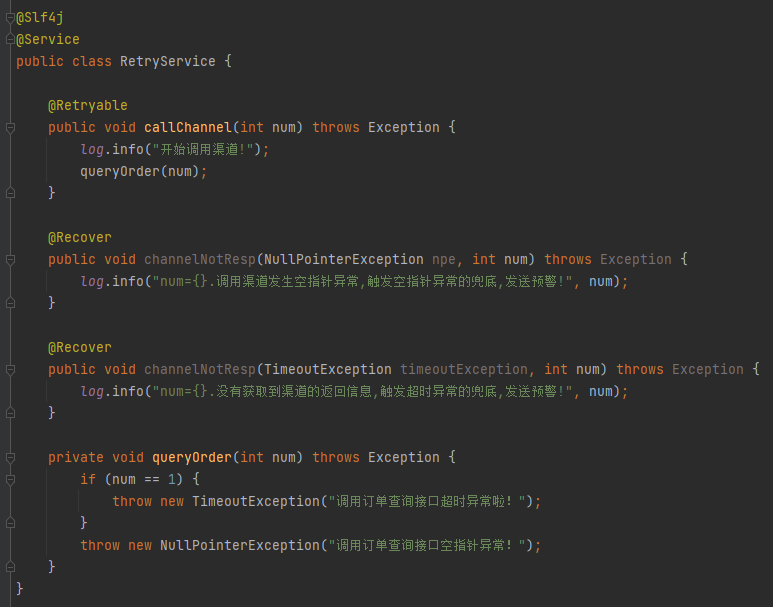
當 num=1 的時候,觸發的是超時兜底策略,日誌是這樣的:
//localhost:8080/callChannel?num=1
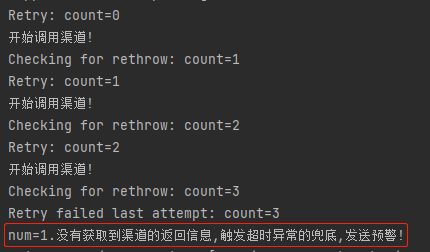
當 num>1 的時候,觸發的是空指針兜底策略,日誌是這樣的:
妙啊,真的是妙不可言啊。
看到這裡我覺得對於 Spring-retry 這個組件算是入門了,有了一個基本的掌握,對於主幹流程是摸的個七七八八,簡歷上可以用「掌握」了。
後續只需要把大的枝幹處和細節處都摸一摸,就可以把「掌握」修改為「熟悉」了。

有點瑕疵
最後,再補充一個有點瑕疵的東西。
再看一下它處理 @Recover 的方法這裡,只是對方法的返回值進行了處理:
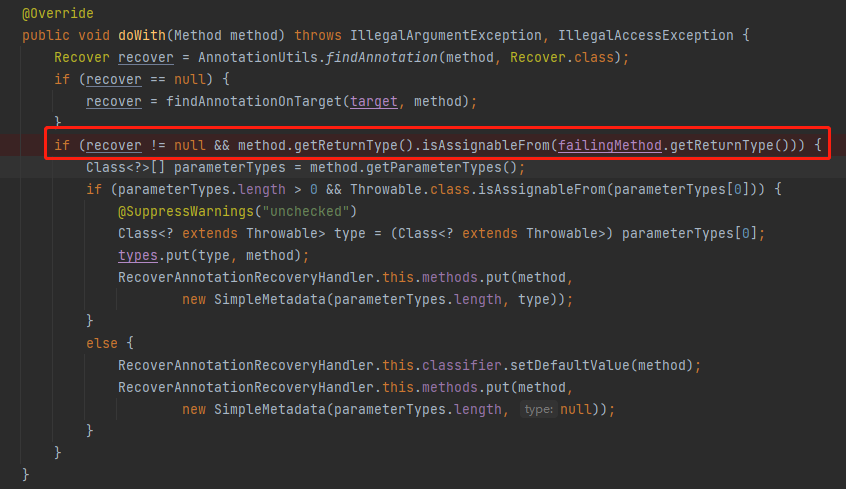
我當時看到這裡的第一眼的時候就覺不對勁,少了對一種情況的判斷,那就是:泛型。
比如我搞個這玩意:
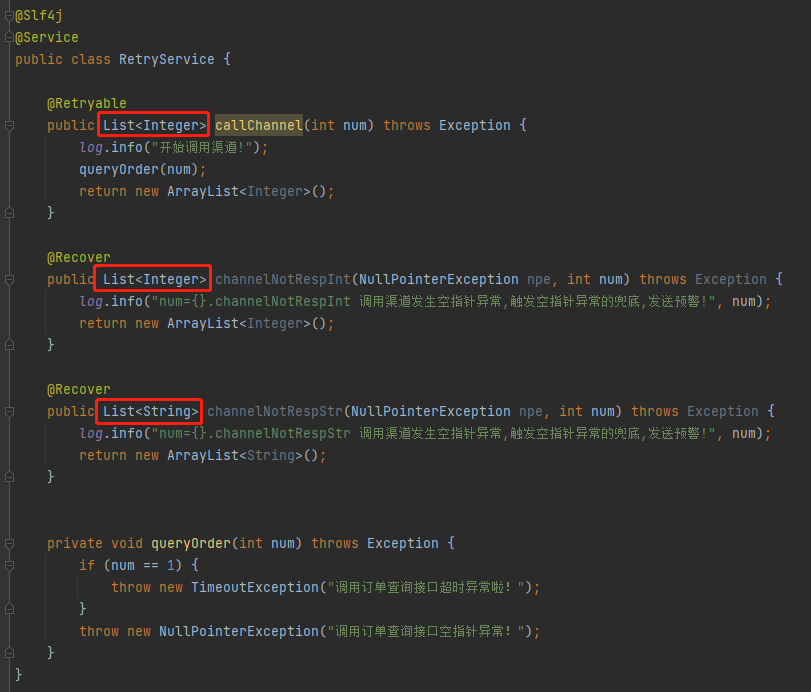
按理來說我希望的兜底策略是 channelNotRespInt 方法。
但是執行之後你就會發現,是有一定幾率選到 channelNotRespStr 方法的:
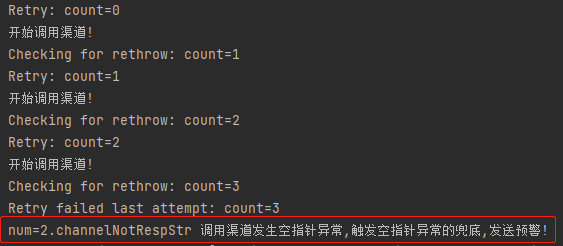
這玩意不對啊,我明明想要的是 channelNotRespInt 方法來兜底呀,為什麼沒有選正確呢?
因為泛型資訊已經沒啦,老鐵:
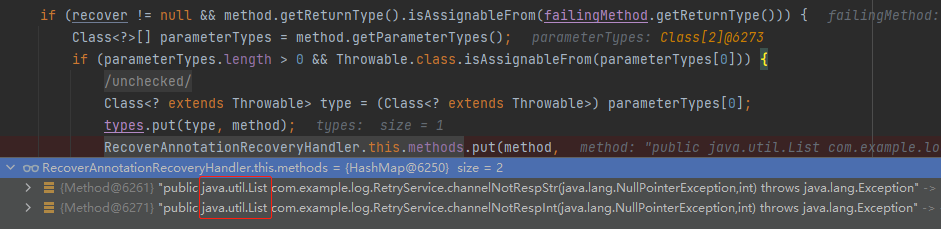
假設我們要支援泛型呢?
從 github 上的描述來看,目前作者已經開始著力於這個方法的研究了:
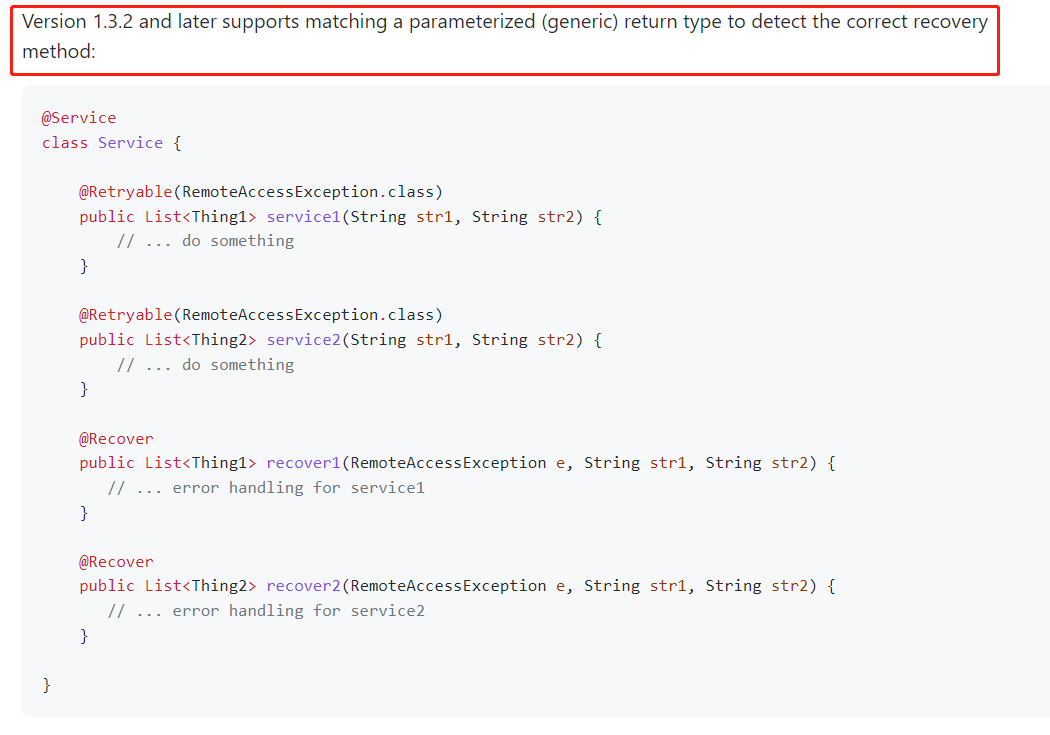
從 1.3.2 版本之後會支援泛型的。
但是目前 maven 倉庫裡面最高的版本還是在 1.3.1:
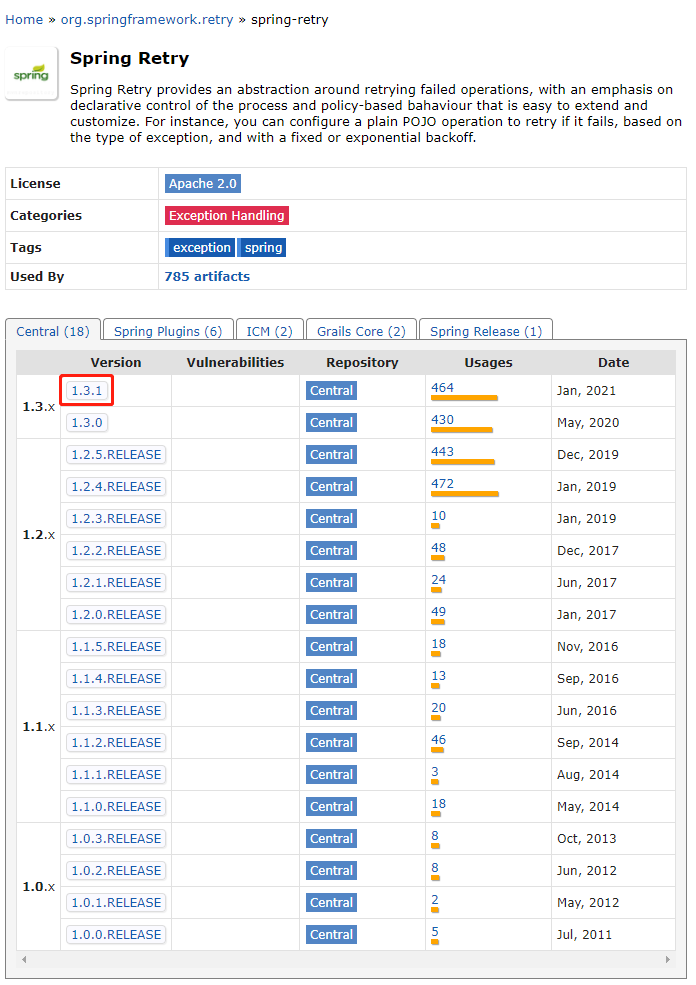
想看程式碼怎麼辦?
只有把源碼拉下來看一眼了。
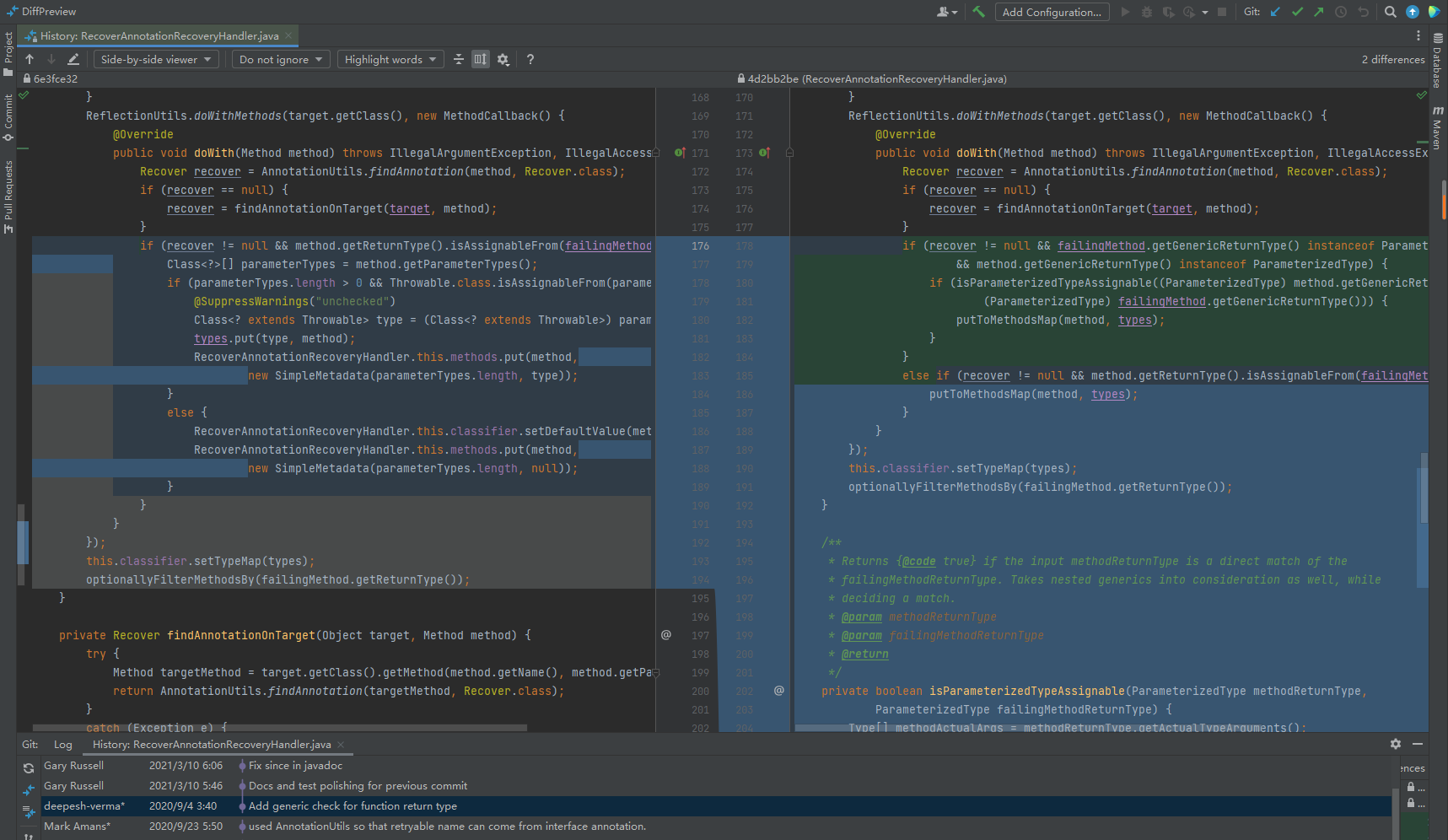
直接看這個類的提交記錄:
org.springframework.retry.annotation.RecoverAnnotationRecoveryHandler
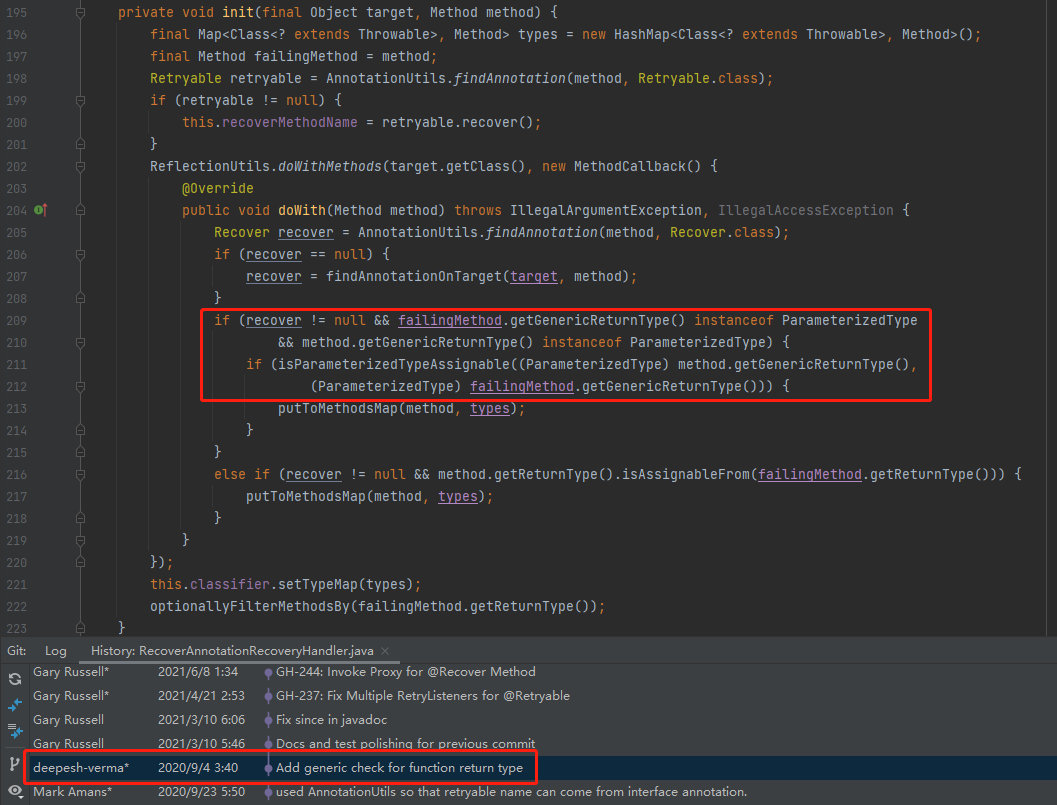
可以看到判斷條件發生了變化,增加了對於泛型的處理。
我這裡就是指個路,你要是有興趣去研究就把源碼拉下來看一下。具體是怎麼實現的我就不寫了,寫的太長了也沒人看,先留個坑在這裡吧。
主要是寫到這裡的時候女朋友催著我去打乒乓球了。她屬於是人菜癮大的那種,昨天才把她給教會,今天居然揚言要打我個 11-0,看我不好好的削她一頓,殺她個片甲不留。

本文已收錄至個人部落格,裡面全是優質原創,歡迎大家來瞅瞅:
//www.whywhy.vip/