Python實訓day07pm【Selenium操作網頁、爬取數據-下載歌曲】
練習1-爬取歌曲列表
任務:通過兩個案例,練習使用Selenium操作網頁、爬取數據。
使用無頭模式,爬取網易雲的內容。

'''
任務:通過兩個案例,練習使用Selenium操作網頁、爬取數據。
使用無頭模式,爬取網易雲的內容。
'''
from selenium import webdriver
# 無頭模式:隱身地啟動瀏覽器,但是並沒有窗口展現
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.add_argument('--headless')
opts.add_argument('--disable-gpu')
bw = webdriver.Chrome(options=opts);
# bw = webdriver.Chrome();
url = '//music.163.com/#/discover/toplist?id=3779629'
bw.get(url);
bw.switch_to.frame('g_iframe')
# 如果頁面中有iframe,說明有內嵌頁面
# 要爬取元素時,先切換到對應的內嵌頁面中,然後再爬
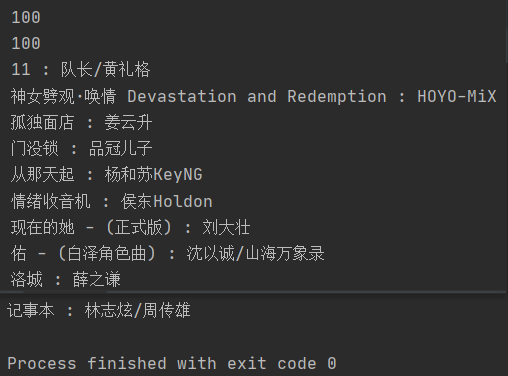
ss = bw.find_elements_by_css_selector('.m-table-rank tbody tr .txt a b');
print(len(ss)) # 100
authors = bw.find_elements_by_css_selector('.m-table-rank tbody tr .text');
print(len(authors)) # 100
for i, s in enumerate(ss):
print(s.get_attribute('title'), ':', authors[i].get_attribute('title'));
bw.close();練習2-爬取歌曲文件mp3
網易云:能不能爬取音樂???可以!能不能爬歌詞???可以!
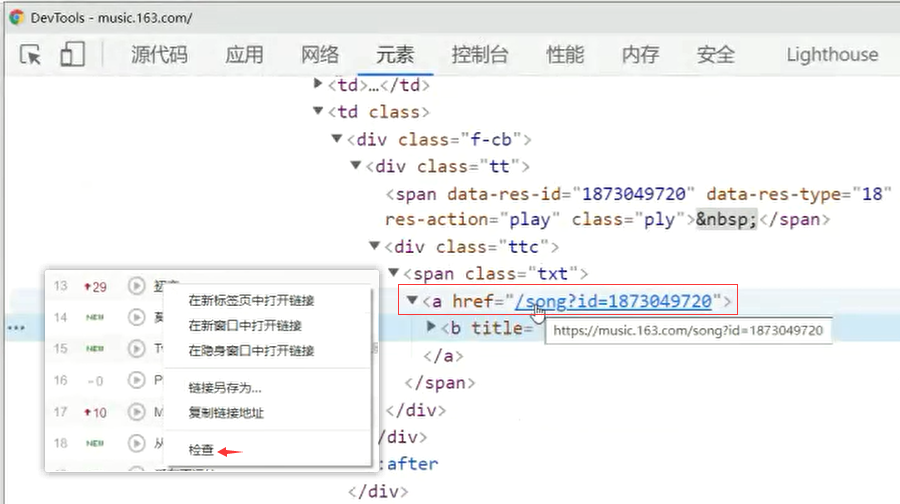
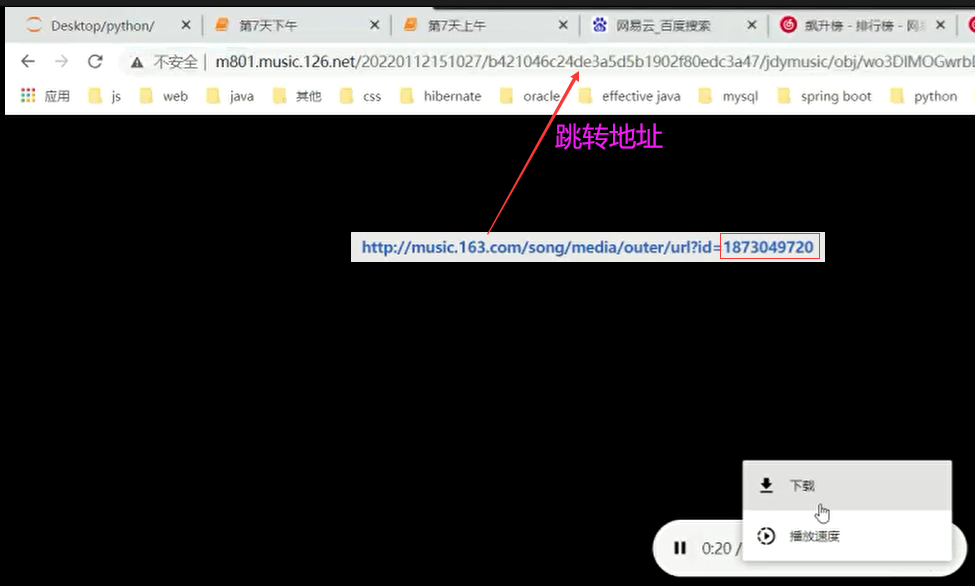
網易雲音樂,歌曲通用下載地址://music.163.com/song/media/outer/url?id= [ id後面拼接歌曲編號 ]



'''
嘗試下載,requests訪問,得到二進位數據,保存到本地即可
爬取網易雲音樂的歌曲mp3文件(單個歌曲下載)
《初戀》歌曲id: 1873049720
《清醒》歌曲id:1909660296
《星辰大海》歌曲id:1811921555
'''
import requests as req
# hds:偽裝成瀏覽器
hds = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
common_url = '//music.163.com/song/media/outer/url?id={}'; # 通用下載路徑
resp = req.get(common_url.format('1909660296'), headers=hds);
ct = resp.content; # 響應內容
print(len(ct)) # 響應內容長度
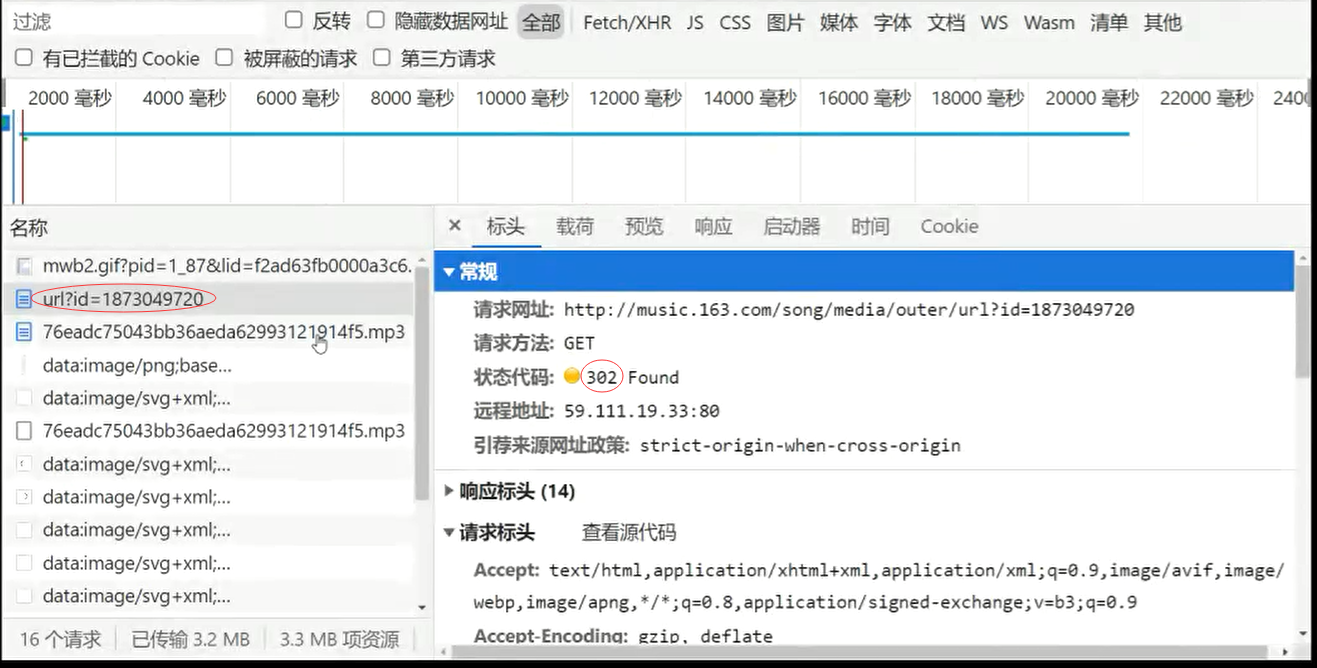
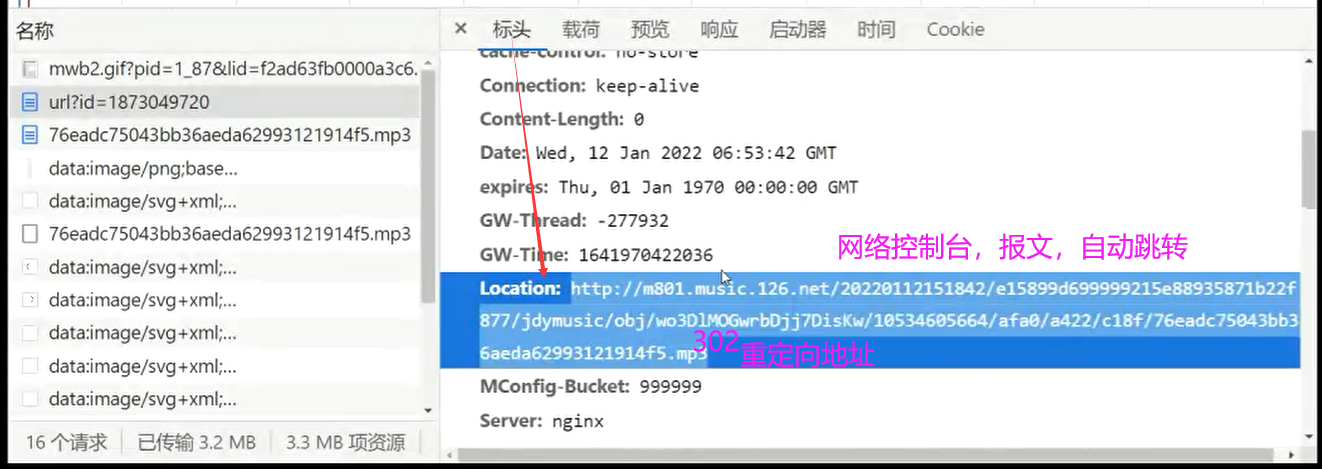
print(resp.status_code); # 200正常;302重定向,需要繼續獲取重定向後的路徑
# print(resp.headers)
# u2 = resp.headers['Location'];
# print(u2) # 繼續爬取u2路徑,來下載音樂
if resp.status_code == 200:
with open(r'C:\Users\lwx\Desktop\網易雲\清醒.mp3', 'wb') as f: # as f取別名,簡寫
f.write(ct);
# 上述兩行程式碼(簡寫),在效果上等於下面三行程式碼。
# f = open(r'C:\Users\lwx\Desktop\網易雲\清醒.mp3', 'wb')
# f.write(ct)
# f.close()
print('over!')練習3-下載飆升榜中的歌曲
結合上午的程式碼和剛才下載音樂的辦法,請嘗試:將飆升榜中的前20首歌曲下載(嘗試下載)。
//music.163.com/#/discover/toplist 15分鐘時間
import requests as req
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
hds = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
def wydown(songname, songid):
common_url = '//music.163.com/song/media/outer/url?id={}';
resp = req.get(common_url.format(songid), headers=hds);
ct = resp.content;
# print(len(ct))
# print(resp.status_code); #200正常 302重定向,需要繼續獲取重定向後的路徑
if resp.status_code == 200:
f = open(r'C:\Users\qx\Desktop\網易雲\{}.mp3'.format(songname), 'wb')
f.write(ct);
f.close();
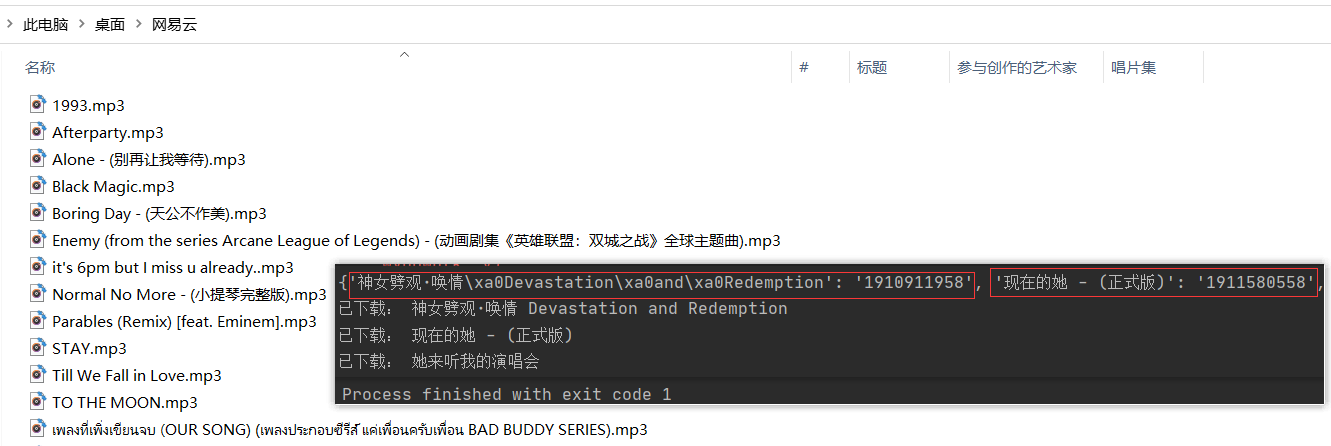
print('已下載:', songname);
# 無頭模式 : 隱身的啟動瀏覽器,但是並沒有窗口展現
opts = Options()
opts.add_argument('--headless')
opts.add_argument('--disable-gpu')
bw = webdriver.Chrome(options=opts);
url = '//music.163.com/#/discover/toplist'
bw.get(url);
bw.switch_to.frame('g_iframe');
ss = bw.find_elements_by_css_selector('.m-table-rank tbody tr .txt a b');
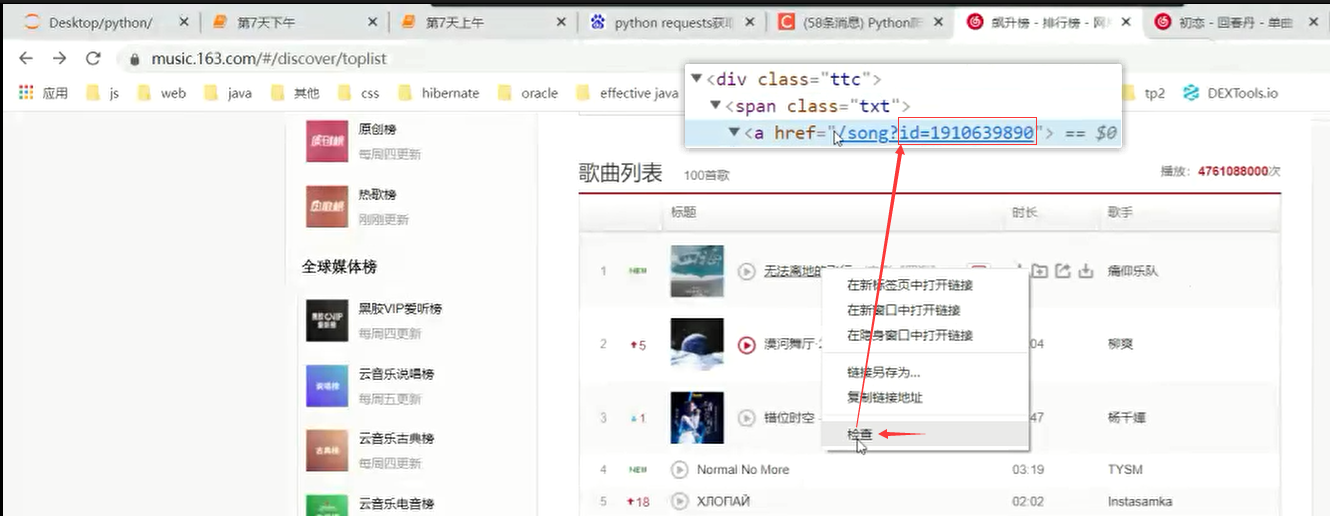
ids = bw.find_elements_by_css_selector('.m-table-rank tbody tr .txt a');
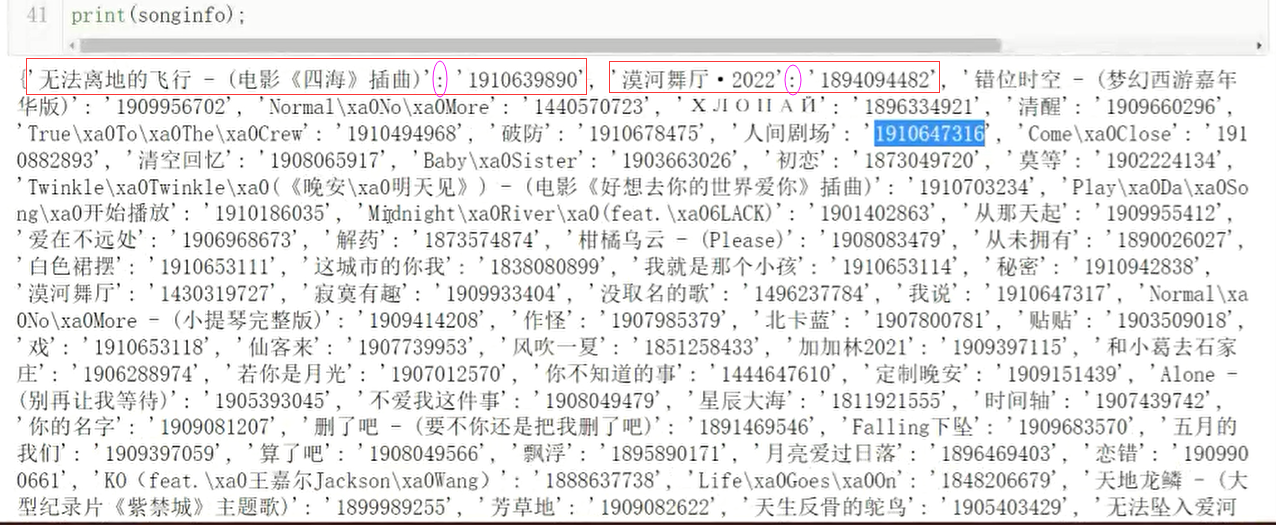
songinfo = {}; # 歌曲名:歌曲id
for i, s in enumerate(ss):
songinfo[s.get_attribute('title')] = ids[i].get_attribute('href').split("=")[1];
bw.close();
# print(songinfo);
# 遍歷字典,下載所有歌曲
for k, v in songinfo.items():
wydown(k, v);

