第53篇-編譯執行緒的初始化
- 2022 年 1 月 13 日
- 筆記
即時編譯(Just In Time,JIT)的運行模式有兩種:client模式(C1編譯器)和server模式(C2編譯器)。這兩種模式採用的編譯器是不一樣的,client模式採用的是代號為C1的輕量級編譯器,特點是啟動快,但是編譯不夠徹底;而server模式採用的是代號為C2的編譯器,特點是啟動比較慢,但是編譯比較徹底,所以一旦服務起來後,性能更高。
用戶可以使用 -client 和 -server 參數強制指定虛擬機運行在 Client 模式或者 Server 模式。這種配合使用的方式稱為「混合模式」(Mixed Mode),用戶可以使用參數 -Xint 強制虛擬機運行於 「解釋模式」(Interpreted Mode),這時候編譯器完全不介入工作。另外,使用 -Xcomp 強制虛擬機運行於 「編譯模式」(Compiled Mode),這時候將優先採用編譯方式執行,但是解釋器仍然要在編譯無法進行的情況下接入執行過程。JDK8默認開啟了分層編譯。不管是開啟還是關閉分層編譯,原本用來選擇即時編譯器的參數 -client 和 -server 都是無效的。當關閉分層編譯的情況下(指定-XX:-TieredCompilation),Java 虛擬機將直接採用 C2編譯器編譯。如果只想用 C1,可以在打開分層編譯的情況下使用參數 -XX:TieredStopAtLevel=1。在這種情況下,Java 虛擬機會在解釋執行之後直接由 1 層的 C1 進行編譯。
Oracle JDK6u25之後引入了分層編譯(對應參數 -XX:+TieredCompilation)的概念,綜合了 C1 的啟動性能優勢和 C2 的峰值性能優勢。JDK8版本默認開啟了分層編譯。不管是開啟還是關閉分層編譯,原本用來選擇即時編譯器的參數 -client 和 -server 都是無效的。當關閉分層編譯的情況下(指定-XX:-TieredCompilation),Java 虛擬機將直接採用 C2編譯器編譯。如果只想用 C1,可以在打開分層編譯的情況下使用參數 -XX:TieredStopAtLevel=1。在這種情況下,Java 虛擬機會在解釋執行之後直接由 1 層的 C1 進行編譯。
下面介紹一下HotSpot VM的編譯策略。編譯策略通常由CompilationPolicy來表示,CompilationPolicy是選擇哪個方法要用什麼程度優化的抽象層。此類的繼承體系如下:
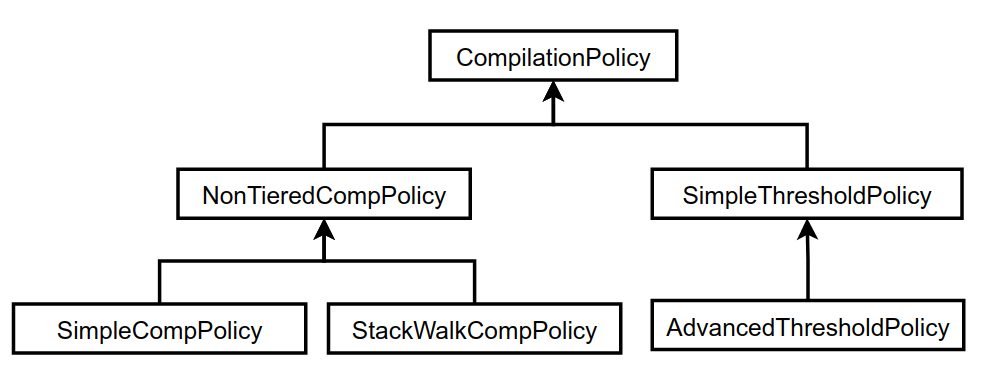
在實現分層編譯之前,編譯策略主要有兩種實現,一種是SimpleCompPolicy,表示哪個方法觸發編譯就編譯哪個方法;另一種是StackWalkCompPolicy,在觸發編譯的時候會遍歷調用棧,看看是不是向上幾層找個caller來編譯的受益更大,找最大受益的caller來編譯。
在實現多層編譯之後,CompilationPolicy的任務還加上了為當前要編譯的方法選擇一個合適的編譯路徑去編譯。
CompilationPolicy類的實現如下:
源程式碼位置:openjdk/hotspot/src/share/vm/runtime/compilationPolicy.hpp
class CompilationPolicy : public CHeapObj<mtCompiler> {
// 運行時使用的CompilationPolicy
static CompilationPolicy* _policy;
// 用於編譯耗時統計
static elapsedTimer _accumulated_time;
public:
// ...
// 方法必須被編譯執行
static bool must_be_compiled(methodHandle m, int comp_level = CompLevel_all);
// 方法被允許編譯(在未編譯完成時可能會解釋執行)
static bool can_be_compiled(methodHandle m, int comp_level = CompLevel_all);
// 方法被允許OSR編譯
static bool can_be_osr_compiled(methodHandle m, int comp_level = CompLevel_all);
// ...
}
通過compilationPolicy_init()函數完成CompilationPolicy的初始化,調用棧如下:
Threads::create_vm() thread.cpp init_globals() init.cpp compilationPolicy_init() compilationPolicy.cpp
在創建虛擬機時會調用compilationPolicy_init()函數,此函數的實現如下:
// 根據命令行參數選擇編譯策略,默認情況下選擇AdvancedThresholdPolicy
void compilationPolicy_init() {
switch(CompilationPolicyChoice) {
case 0:
CompilationPolicy::set_policy(new SimpleCompPolicy());
break;
case 1: // 需要在C2編譯器可用情況下才能選擇此選項
CompilationPolicy::set_policy(new StackWalkCompPolicy());
break;
case 2: // 需要在支援分層編譯情況下才能選擇此選項
CompilationPolicy::set_policy(new SimpleThresholdPolicy());
break;
case 3: // 需要在支援分層編譯情況下才能選擇此選項
CompilationPolicy::set_policy(new AdvancedThresholdPolicy());
break;
default:
fatal("CompilationPolicyChoice must be in the range: [0-3]");
}
CompilationPolicy::policy()->initialize();
}
CompilationPolicyChoice是虛擬機配置命令,表示具體的編譯策略,server模式下默認是3,也就是採用AdvancedThresholdPolicy策略。
AdvancedThresholdPolicy繼承自SimpleThresholdPolicy,SimpleThresholdPolicy在CompilationPolicy的基礎上添加了兩個屬性_c1_count和_c2_count,表示C1和C2編譯執行緒的數量。AdvancedThresholdPolicy添加了_start_time和_increase_threshold_at_ratio兩個屬性,前者表示啟動時間,後者表示當CodeCache已使用了指定比例時提升C1編譯的閾值。
在compilationPolicy_init()函數中會調用AdvancedThresholdPolicy::initialize()函數初始化編譯策略。AdvancedThresholdPolicy::initialize()函數的實現如下:
void AdvancedThresholdPolicy::initialize() {
// CICompilerCountPerCPU默認值為false,表示是否每個CPU對應1個後台編譯執行緒,
// CICompilerCount表示後台編譯執行緒的數量,默認值3
// 當這兩個選項配置都是默認值時,將CICompilerCountPerCPU設置為true
if (FLAG_IS_DEFAULT(CICompilerCountPerCPU) && FLAG_IS_DEFAULT(CICompilerCount)) {
FLAG_SET_DEFAULT(CICompilerCountPerCPU, true);
}
int count = CICompilerCount;
if (CICompilerCountPerCPU) {
//考慮機器的CPU數量,計算總的後台編譯執行緒數
int log_cpu = log2_int(os::active_processor_count());
int loglog_cpu = log2_int(MAX2(log_cpu, 1));
count = MAX2(log_cpu * loglog_cpu, 1) * 3 / 2;
}
// 計算C1,C2編譯執行緒的數量,按照1:2的比例進行分配
set_c1_count(MAX2(count / 3, 1));
set_c2_count(MAX2(count - c1_count(), 1));
// 重置CICompilerCount
FLAG_SET_ERGO(intx, CICompilerCount, c1_count() + c2_count());
// InlineSmallCode表示只有當方法程式碼的大小小於該值時才會使用內聯編譯的方式,x86下默認是1000
// 這裡是將其調整為2000
if (FLAG_IS_DEFAULT(InlineSmallCode)) {
FLAG_SET_DEFAULT(InlineSmallCode, 2000);
}
// 當CodeCache已使用了指定比例時提升C1編譯的閾值
set_increase_threshold_at_ratio();
}
// IncreaseFirstTierCompileThresholdAt默認是50%,當CodeCache的
// 已使用量大於50%時就會開始提高觸發C1編譯的閾值
void set_increase_threshold_at_ratio() {
_increase_threshold_at_ratio = 100 / (100 - (double)IncreaseFirstTierCompileThresholdAt);
}
在64位JVM中,有2種情況來計算總的編譯執行緒數,如下:
- -XX:+CICompilerCountPerCPU=true, 默認情況下,編譯執行緒的總數根據處理器數量來調整;
- -XX:+CICompilerCountPerCPU=false且-XX:+CICompilerCount=N,強制設定總編譯執行緒數。
無論以上哪種情況,HotSpot VM都會將這些編譯執行緒按照1:2的比例分配給C1和C2(至少1個),舉個例子,對於一個四核機器來說,總的編譯執行緒數目為 3,其中包含一個 C1 編譯執行緒和兩個 C2 編譯執行緒。
設置完成編譯器執行緒數量後,會在創建虛擬機實例時調用compilation_init()函數初始化編譯相關組件,包括編譯器實現,編譯執行緒,計數器等。調用棧如下:
Threads::create_vm() thread.cpp CompileBroker::compilation_init() compileBroker.cpp
compilation_init()函數的實現如下:
void CompileBroker::compilation_init() {
if (!UseCompiler) { // 不使用編譯器就不需要初始化
return;
}
// 返回前面計算出的編譯器執行緒數量
int c1_count = CompilationPolicy::policy()->compiler_count(CompLevel_simple);
int c2_count = CompilationPolicy::policy()->compiler_count(CompLevel_full_optimization);
if (c1_count > 0) {
_compilers[0] = new Compiler(); // C1編譯器為Compiler
}
if (c2_count > 0) {
_compilers[1] = new C2Compiler(); // C2編譯器為C2Compiler
}
// 啟動編譯執行緒
init_compiler_threads(c1_count, c2_count);
// ...
}
調用init_compiler_threads()函數的實現如下:
void CompileBroker::init_compiler_threads(int c1_compiler_count, int c2_compiler_count) {
// 初始化編譯執行緒任務隊列
if (c2_compiler_count > 0) {
_c2_method_queue = new CompileQueue("C2MethodQueue", MethodCompileQueue_lock);
_compilers[1]->set_num_compiler_threads(c2_compiler_count);
}
if (c1_compiler_count > 0) {
_c1_method_queue = new CompileQueue("C1MethodQueue", MethodCompileQueue_lock);
_compilers[0]->set_num_compiler_threads(c1_compiler_count);
}
int compiler_count = c1_compiler_count + c2_compiler_count;
_compiler_threads = new (ResourceObj::C_HEAP, mtCompiler) GrowableArray<CompilerThread*>(compiler_count, true);
char name_buffer[256];
// 創建C2編譯器執行緒
for (int i = 0; i < c2_compiler_count; i++) {
CompilerCounters* counters = new CompilerCounters("compilerThread", i, CHECK);
CompilerThread* new_thread = make_compiler_thread(name_buffer, _c2_method_queue, counters, _compilers[1], CHECK);
_compiler_threads->append(new_thread);
}
// 創建C1編譯器執行緒
for (int i = c2_compiler_count; i < compiler_count; i++) {
CompilerCounters* counters = new CompilerCounters("compilerThread", i, CHECK);
CompilerThread* new_thread = make_compiler_thread(name_buffer, _c1_method_queue, counters, _compilers[0], CHECK);
_compiler_threads->append(new_thread);
}
}
分別創建C1和C2編譯的CompileQueu隊列,所有的編譯任務都需要入到隊列中,然後由創建出來的編譯執行緒從隊列中獲取到編譯任務進行編譯,這在後面的文章中會詳細介紹,這裡不再介紹。
公眾號 深入剖析Java虛擬機HotSpot 已經更新虛擬機源程式碼剖析相關文章到60+,歡迎關注,如果有任何問題,可加作者微信mazhimazh,拉你入虛擬機群交流


