我與消息隊列的八年情緣

談起消息隊列,內心還是會有些波瀾。
消息隊列,快取,分庫分表是高並發解決方案三劍客,而消息隊列是我最喜歡,也是思考最多的技術。
我想按照下面的四個階段分享我與消息隊列的故事,同時也是對我技術成長經歷的回顧。
- 初識:ActiveMQ
- 進階:Redis&RabbitMQ
- 升華:MetaQ
- 鍾情:RocketMQ
1 初識ActiveMQ
1.1 非同步&解耦
2011年初,我在一家互聯網彩票公司做研發。
我負責的是用戶中心系統,提供用戶註冊,查詢,修改等基礎功能。用戶註冊成功之後,需要給用戶發送簡訊。
因為原來都是面向過程編程,我就把新增用戶模組和發送簡訊模組都揉在一起了。

起初都還好,但問題慢慢的顯現出來。
- 簡訊渠道不夠穩定,發送簡訊會達到5秒左右,這樣用戶註冊介面耗時很大,影響前端用戶體驗;
- 簡訊渠道介面發生變化,用戶中心程式碼就必須修改了。但用戶中心是核心系統。每次上線都必要謹小慎微。這種感覺很彆扭,非核心功能影響到核心系統了。
第一個問題,我可以採取執行緒池的方法來做,主要是非同步化。但第二個問題卻讓我束手無措。
於是我向技術經理請教,他告訴我引入消息隊列去解決這個問題。
- 將發送簡訊功能單獨拆成獨立的Job服務;
- 用戶中心用戶註冊成功後,發送一條消息到消息隊列,Job服務收到消息調用簡訊服務發送簡訊即可。

這時,我才明白: 消息隊列最核心的功能就是非同步和解耦。
1.2 調度中心
彩票系統的業務是比較複雜的。在彩票訂單的生命周期里,經過創建,拆分子訂單,出票,算獎等諸多環節。
每一個環節都需要不同的服務處理,每個系統都有自己獨立的表,業務功能也相對獨立。假如每個應用都去修改訂單主表的資訊,那就會相當混亂了。
公司的架構師設計了調度中心的服務,調度中心的職責是維護訂單核心狀態機,訂單返獎流程,彩票核心數據生成。

調度中心通過消息隊列和出票網關,算獎服務等系統傳遞和交換資訊。
這種設計在那個時候青澀的我的眼裡,簡直就是水滴vs人類艦隊,降維打擊。
隨著我對業務理解的不斷深入,我隱約覺得:「好的架構是簡潔的,也是應該易於維護的」。
當彩票業務日均千萬交易額的時候,調度中心的研發維護人員也只有兩個人。調度中心的源碼里業務邏輯,日誌,程式碼規範都是極好的。
在我日後的程式人生里,我也會下意識模仿調度中心的編碼方式,「不玩奇技淫巧,程式碼是給人閱讀的」。
1.3 重啟大法
隨著彩票業務的爆炸增長,每天的消息量從30萬激增到150~200萬左右,一切看起來似乎很平穩。
某一天雙色球投注截止,調度中心無法從消息隊列中消費數據。消息匯流排處於只能發,不能收的狀態下。 整個技術團隊都處於極度的焦慮狀態,「要是出不了票,那可是幾百萬的損失呀,要是用戶中了兩個雙色球?那可是千萬呀」。大家急得像熱鍋上的螞蟻。
這也是整個技術團隊第一次遇到消費堆積的情況,大家都沒有經驗。
首先想到的是多部署幾台調度中心服務,部署完成之後,調度中心消費了幾千條消息後還是Hang住了。 這時,架構師只能採用重啟的策略。你沒有看錯,就是重啟大法。說起來真的很慚愧,但當時真的只能採用這種方式。
調度中心重啟後,消費了一兩萬後又Hang住了。只能又重啟一次。來來回回持續20多次,像擠牙膏一樣。而且隨著出票截止時間的臨近,這種思想上的緊張和恐懼感更加強烈。終於,通過1小時的手工不斷重啟,消息終於消費完了。
我當時正好在讀畢玄老師的《分散式java應用基礎與實踐》,猜想是不是執行緒阻塞了,於是我用Jstack命令查看堆棧情況。 果然不出所料,執行緒都阻塞在提交數據的方法上。

我們馬上和DBA溝通,發現oracle資料庫執行了非常多的大事務,每次大的事務執行都需要30分鐘以上,導致調度中心的調度出票執行緒阻塞了。
技術部後來採取了如下的方案規避堆積問題:
- 生產者發送消息的時候,將超大的消息拆分成多批次的消息,減少調度中心執行大事務的幾率;
- 數據源配置參數,假如事務執行超過一定時長,自動拋異常,回滾。
1.4 復盤
Spring封裝的ActiveMQ的API非常簡潔易用,使用過程中真的非常舒服。
受限於當時彩票技術團隊的技術水平和視野,我們在使用ActiveMQ中遇到了一些問題。
- 高吞吐下,堆積到一定消息量易Hang住;
技術團隊發現在吞吐量特別高的場景下,假如消息堆積越大,ActiveMQ有較小几率會Hang住的。
出票網關的消息量特別大,有的消息並不需要馬上消費,但是為了規避消息隊列Hang住的問題,出票網關消費數據的時候,先將消息先持久化到本地磁碟,生成本地XML文件,然後非同步定時執行消息。通過這種方式,我們大幅度提升了出票網關的消費速度,基本杜絕了出票網關隊列的堆積。
但這種方式感覺也挺怪的,消費消息的時候,還要本地再存儲一份數據,消息存儲在本地,假如磁碟壞了,也有丟消息的風險。
- 高可用機制待完善
我們採用的master/slave部署模式,一主一從,伺服器配置是4核8G 。
這種部署方式可以同時運行兩個ActiveMQ, 只允許一個slave連接到Master上面,也就是說只能有2台MQ做集群,這兩個服務之間有一個數據備份通道,利用這個通道Master向Slave單向地數據備份。 這個方案在實際生產線上不方便, 因為當Master掛了之後, Slave並不能自動地接收Client發來的請來,需要手動干預,且要停止Slave再重啟Master才能恢復負載集群。
還有一些很詭異丟消息的事件,生產者發送消息成功,但master控制台查詢不到,但slave控制台竟然能查詢到該消息。
但消費者沒有辦法消費slave上的消息,還得通過人工介入的方式去處理。
2 進階Redis&RabbitMQ
2014年,我在藝龍網從事紅包系統和優惠券系統優化相關工作。
2.1 Redis可以做消息隊列嗎
酒店優惠券計算服務使用的是初代流式計算框架Storm。Storm這裡就不詳細介紹,可以參看下面的邏輯圖:
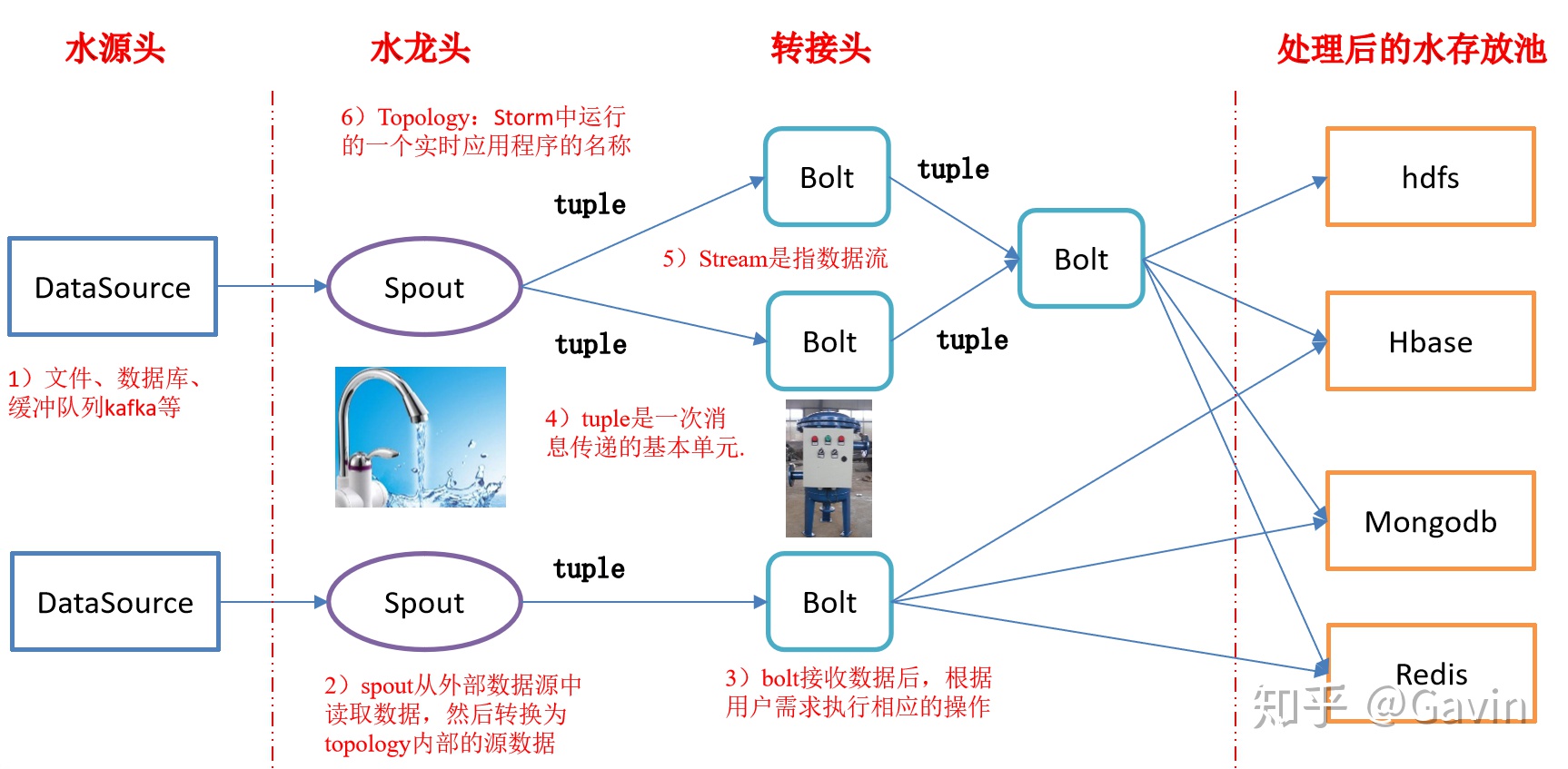
這裡我們的Storm集群的水源頭(數據源)是redis集群,使用list數據結構實現了消息隊列的push/pop功能。

流式計算的整體流程:
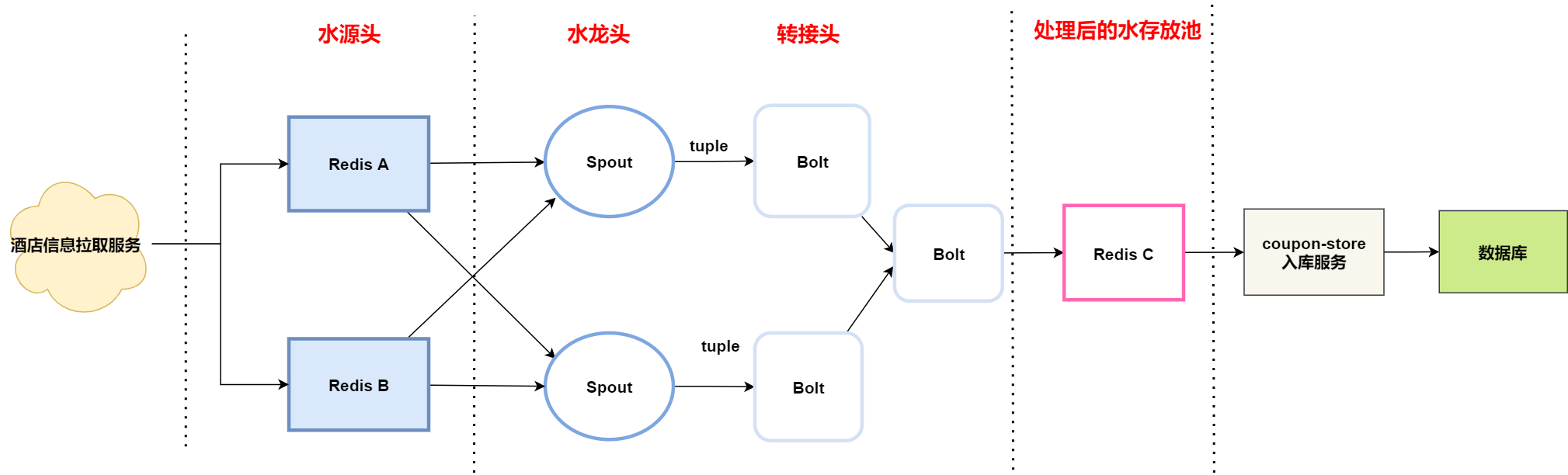
- 酒店資訊服務發送酒店資訊到Redis集群A/B;
- Storm的spout組件從Redis集群A/B獲取數據, 獲取成功後,發送tuple消息給Bolt組件;
- Bolt組件收到消息後,通過運營配置的規則對數據進行清洗;
- 最後Storm把處理好的數據發送到Redis集群C;
- 入庫服務從Redis集群C獲取數據,存儲數據到資料庫;
- 搜索團隊掃描資料庫表,生成索引。
這套流式計算服務每天處理千萬條數據,處理得還算順利。
但方案在團隊內部還是有不同聲音:
- storm的拓撲升級時候,或者優惠券服務重啟的時候,偶爾出現丟消息的情況。但消息的丟失,對業務來講沒有那麼敏感,而且我們也提供了手工刷新的功能,也在業務的容忍範圍內;
- 團隊需要經常關注Redis的快取使用量,擔心Redis隊列堆積, 導致out of memory;
- 架構師認為搜索團隊直接掃描資料庫不夠解耦,建議將Redis集群C替換成Kafka,搜索團隊從kafka直接消費消息,生成索引;
我認為使用Redis做消息隊列應該滿足如下條件:
- 容忍小概率消息丟失,通過定時任務/手工觸發達到最終一致的業務場景;
- 消息堆積概率低,有相關的報警監控;
- 消費者的消費模型要足夠簡單。
2.2 RabbitMQ是管子不是池子
RabbitMQ是用erlang語言編寫的。RabbitMQ滿足了我的兩點需求:
- 高可用機制。藝龍內部是使用的鏡像高可用模式,而且這種模式在藝龍已經使用了較長時間了,穩定性也得到了一定的驗證。
- 我負責的紅包系統里,RabbitMQ每天的吞吐也在百萬條消息左右,消息的發送和消費都還挺完美。
優惠券服務原使用SqlServer,由於數據量太大,技術團隊決定使用分庫分表的策略,使用公司自主研發的分散式資料庫DDA。

因為是第一次使用分散式資料庫,為了測試DDA的穩定性,我們模擬發送1000萬條消息到RabbitMQ,然後優惠券重構服務消費消息後,按照用戶編號hash到不同的mysql庫。
RabbitMQ集群模式是鏡像高可用,3台伺服器,每台配置是4核8G 。
我們以每小時300萬條消息的速度發送消息,最開始1個小時生產者和消費者表現都很好,但由於消費者的速度跟不上生產者的速度,導致消息隊列有積壓情況產生。第三個小時,消息隊列已堆積了500多萬條消息了, 生產者發送消息的速度由最開始的2毫秒激增到500毫秒左右。RabbitMQ的控制台已血濺當場,標紅報警。
這是一次無意中的測試,從測試的情況來看,RabbitMQ很優秀,但RabbitMQ對消息堆積的支援並不好,當大量消息積壓的時候,會導致 RabbitMQ 的性能急劇下降。
有的朋友對我講:「RabbitMQ明明是管子,你非得把他當池子?」
隨著整個互聯網數據量的激增, 很多業務場景下是允許適當堆積的,只要保證消費者可以平穩消費,整個業務沒有大的波動即可。
我心裏面越來越相信:消息隊列既可以做管子,也可以當做池子。

3 升華MetaQ
Metamorphosis的起源是我從對linkedin的開源MQ–現在轉移到apache的kafka的學習開始的,這是一個設計很獨特的MQ系統,它採用pull機制,而 不是一般MQ的push模型,它大量利用了zookeeper做服務發現和offset存儲,它的設計理念我非常欣賞並贊同,強烈建議你閱讀一下它的設計文檔,總體上說metamorphosis的設計跟它是完全一致的。— MetaQ的作者庄曉丹
3.1 驚艷消費者模型
2015年,我主要從事神州專車訂單研發工作。
MetaQ滿足了我對於消息隊列的幻想:「分散式,高吞吐,高堆積」。
MetaQ支援兩種消費模型: 集群消費和廣播消費 ,因為以前使用過的消費者模型都是用隊列模型,當我第一次接觸到這種發布訂閱模型的時候還是被驚艷到了。
▍ 集群消費

訂單創建成功後,發送一條消息給MetaQ。這條消息可以被派單服務消費,也可以被BI服務消費。
▍ 廣播消費
派單服務在講訂單指派給司機的時候,會給司機發送一個推送消息。推送就是用廣播消費的模式實現的。

大體流程是:
- 司機端推送服務是一個TCP服務,啟動後,採用的是廣播模式消費MetaQ的PushTopic;
- 司機端會定時發送TCP請求到推送服務,鑒權成功後,推送服務會保存司機編號和channel的引用;
- 派單服務發送推送消息到MetaQ;
- 推送服務的每一台機器都會收到該消息,然後判斷記憶體中是否存在該司機的channel引用,若存在,則推送消息。
這是非常經典的廣播消費的案例。我曾經研讀京麥TCP網關的設計,它的推送也是採用類似的方式。
3.2 激進的消峰
2015年是打車大戰硝煙瀰漫的一年。
對神州專車來講,隨著訂單量的不斷增長,欣喜的同時,性能的壓力與日俱增。早晚高峰期,用戶打車的時候,經常點擊下單經常無響應。
在系統層面來看,專車api網關發現大規模超時,訂單服務的性能急劇下降。資料庫層面壓力更大,高峰期一條記錄插入竟然需要8秒的時間。
整個技術團隊需要儘快提升專車系統的性能,此前已經按照模組領域做了資料庫的拆分。但系統的瓶頸依然很明顯。
我們設計了現在看來有點激進的方案:
- 設計訂單快取。快取方案大家要有興趣,我們可以以後再聊,裡面有很多可以詳聊的點;
- 在訂單的載客生命周期里,訂單的修改操作先修改快取,然後發送消息到MetaQ,訂單落盤服務消費消息,並判斷訂單資訊是否正常(比如有無亂序),若訂單數據無誤,則存儲到資料庫中。

這裡有兩個細節:
-
消費者消費的時候需要順序消費,實現的方式是按照訂單號路由到不同的partition,同一個訂單號的消息,每次都發到同一個partition;
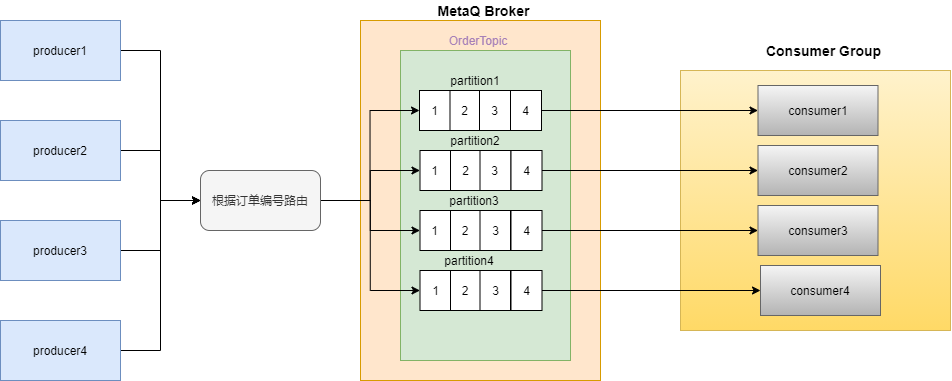
-
一個守護任務,定時輪詢當前正在進行的訂單,當快取與數據不一致時候,修複數據,並發送報警。

這次優化大大提升訂單服務的整體性能,也為後來訂單服務庫分庫分表以及異構打下了堅實的基礎,根據我們的統計數據,基本沒有發生過快取和資料庫最後不一致的場景。 但這種方案對快取高可用有較高的要求,還是有點小激進吧。
3.3 消息SDK封裝
做過基礎架構的同學可能都有經驗:「三方組件會封裝一層」,神州架構團隊也是將metaq-client封裝了一層。
在我的思維裡面,封裝一層可以減少研發人員使用第三方組件的心智投入,統一技術棧,也就如此了。
直到發生一次意外,我的思維升級了。那是一天下午,整個專車服務崩潰較長時間。技術團隊發現:”專車使用zookeeper做服務發現。zk集群的leader機器掛掉了,一直在選主。”
臨時解決後,我們發現MetaQ和服務發現都使用同一套zk集群,而且consumer的offset提交,以及負載均衡都會對zk集群進行大量的寫操作。
為了減少MetaQ對zk集群的影響,我們的目標是:「MetaQ使用獨立的zk集群」。
- 需要部署新的zk集群;
- MetaQ的zk數據需要同步到新的集群;
- 保證切換到新的集群,應用服務基本無感知。
我很好奇向架構部同學請教,他說新的集群已經部署好了,但需要同步zk數據到新的集群。他在客戶端里添加了雙寫的操作。也就是說:我們除了會寫原有的zk集群一份數據,同時也會在新的zk集群寫一份。
過了幾周後,MetaQ使用獨立的zk集群這個任務已經完成了。

這一次的經歷帶給我很大的感慨:「還可以這麼玩?」 ,也讓我思考著:三方組件封裝沒有想像中那麼簡單。
我們可以看下快手消息的SDK封裝策略:
- 對外只提供最基本的 API,所有訪問必須經過SDK提供的介面。簡潔的 API 就像冰山的一個角,除了對外的簡單介面,下面所有的東西都可以升級更換,而不會破壞兼容性 ;
- 業務開發起來也很簡單,只要需要提供 Topic(全局唯一)和 Group 就可以生產和消費,不用提供環境、NameServer 地址等。SDK 內部會根據 Topic 解析出集群 NameServer 的地址,然後連接相應的集群。生產環境和測試環境環境會解析出不同的地址,從而實現了隔離;
- 上圖分為 3 層,第二層是通用的,第三層才對應具體的 MQ 實現,因此,理論上可以更換為其它消息中間件,而客戶端程式不需要修改;
- SDK 內部集成了熱變更機制,可以在不重啟 Client 的情況下做動態配置,比如下發路由策略(更換集群 NameServer 的地址,或者連接到別的集群去),Client 的執行緒數、超時時間等。通過 Maven 強制更新機制,可以保證業務使用的 SDK 基本上是最新的。

3.4 重構MetaQ , 自成體系
我有一個習慣 : “經常找運維,DBA,架構師了解當前系統是否有什麼問題,以及他們解決問題的思路。這樣,我就有另外一個視角來審視公司的系統運行情況”。
MetaQ也有他的缺點。
- MetaQ的基層通訊框架是gecko,MetaQ偶爾會出現rpc無響應,應用假死的情況,不太好定位問題;
- MetaQ的運維能力薄弱,只有簡單的Dashboard介面,無法實現自動化主題申請,消息追蹤等功能。
有一天,我發現測試環境的一台消費者伺服器啟動後,不斷報鏈接異常的問題,而且cpu佔用很高。我用netstat命令馬上查一下,發現已經創建了幾百個鏈接。出於好奇心,我打開了源碼,發現網路通訊框架gecko已經被替換成了netty。我們馬上和架構部的同學聯繫。
我這才明白:他們已經開始重構MetaQ了。我從來沒有想過重構一個開源軟體,因為距離我太遠了。或者那個時候,我覺得自己的能力還達不到。
後來,神州自研的消息隊列自成體系了,已經在生產環境運行的挺好。
時至今天,我還是很欣賞神州架構團隊。他們自研了消息隊列,DataLink(數據異構中間件),分庫分表中間件等。他們願意去創新,有勇氣去做一個更好的技術產品。
我從他們身上學到很多。
也許在看到他們重構MetaQ的那一刻,我的心裡埋下了種子。

4 鍾情RocketMQ
4.1 開源的盛宴
2014年,我搜羅了很多的淘寶的消息隊列的資料,我知道MetaQ的版本已經升級MetaQ 3.0,只是開源版本還沒有放出來。
大約秋天的樣子,我加入了RocketMQ技術群。誓嘉(RocketMQ創始人)在群里說:「最近要開源了,放出來後,大家趕緊fork呀」。他的這句話發在群里之後,群里都炸開了鍋。我更是歡喜雀躍,期待著能早日見到阿里自己內部的消息中間件。

終於,RocketMQ終於開源了。我迫不及待想一窺他的風采。
因為我想學網路編程,而RocketMQ的通訊模組remoting底層也是Netty寫的。所以,RocketMQ的通訊層是我學習切入的點。
我模仿RocketMQ的remoting寫了一個玩具的rpc,這更大大提高我的自信心。正好,藝龍舉辦技術創新活動。我想想,要不嘗試一下用Netty改寫下Cobar的通訊模組。於是參考Cobar的源碼花了兩周寫了個netty版的proxy,其實非常粗糙,很多功能不完善。後來,這次活動頒給我一個鼓勵獎,現在想想都很好玩。
因為在神州優車使用MetaQ的關係,我學習RocketMQ也比較得心應手。為了真正去理解源碼,我時常會參考RocketMQ的源碼,寫一些輪子來驗證我的學習效果。
雖然自己做了一些練習,但一直沒有在業務環境使用過。2018年是我真正使用RocketMQ的一年,也是有所得的一年。
▍ 簡訊服務
簡訊服務應用很廣泛,比如用戶註冊登錄驗證碼,營銷簡訊,下單成功簡訊通知等等。
最開始設計簡訊服務的時候,我想學習業界是怎麼做的。於是把目標鎖定在騰訊雲的簡訊服務上。
騰訊雲的簡訊服務有如下特點:
- 統一的SDK,後端入口是http/https服務 , 分配appId/appSecret鑒權;
- 簡潔的API設計:單發,群發,營銷單發,營銷群發,模板單發,模板群發。
於是,我參考了這種設計思路。
- 模仿騰訊雲的SDK設計,提供簡單易用的簡訊介面;
- 設計簡訊服務API端,接收發簡訊請求,發送簡訊資訊到消息隊列;
- worker服務消費消息,按照負載均衡的演算法,調用不同渠道商的簡訊介面;
- Dashboard可以查看簡訊發送記錄,配置渠道商資訊。
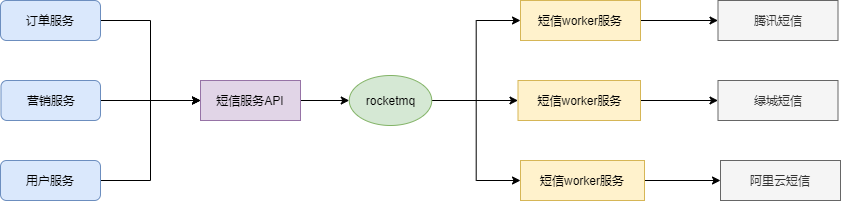

簡訊服務是我真正意義第一次生產環境使用RocketMQ,當簡訊一條條發出來的時候,還是蠻有成就感的。
▍ MQ控制台

使用過RocketMQ的朋友,肯定對上圖的控制台很熟悉。當時團隊有多個RocketMQ集群,每組集群都需要單獨部署一套控制台。於是我想著:能不能稍微把控制台改造一番,能滿足支援多組集群。
於是,擼起袖子幹了起來。大概花了20天的時間,我們基於開源的版本改造了能支援多組集群的版本。做完之後,雖然能滿足我最初的想法,但是做的很粗糙。而且搜狐開源了他們自己的MQCloud ,我看了他們的設計之後, 覺得離一個消息治理平台還很遠。
後來我讀了《網易雲音樂的消息隊列改造之路》,《今日頭條在消息服務平台和容災體系建設方面的實踐與思考》這兩篇文章,越是心癢難耐,蠻想去做的是一個真正意義上的消息治理平台。一直沒有什麼場景和機會,還是有點可惜。
最近看了哈羅單車架構專家梁勇的一篇文章《哈啰在分散式消息治理和微服務治理中的實踐》,推薦大家一讀。
▍ 一扇窗子,開始自研組件
後來,我嘗試進一步深入使用RocketMQ。
- 仿ONS風格封裝消息SDK;
- 運維側平滑擴容消息隊列;
- 生產環境DefaultMQPullConsumer消費模式嘗試
這些做完之後,我們又自研了註冊中心、配置中心,任務調度系統。設計這些系統的時候,從RocketMQ源碼里汲取了很多的營養,雖然現在看來有很多設計不完善的地方,程式碼品質也有待提高,但做完這些系統後,還是大大提升我的自信心。
RocketMQ給我打開了一扇窗子,讓我能看到更廣闊的Java世界。 對我而言,這就是開源的盛宴。
4.2 Kafka: 大數據生態的不可或缺的部分
Kafka是一個擁有高吞吐、可持久化、可水平擴展,支援流式數據處理等多種特性的分散式消息流處理中間件,採用分散式消息發布與訂閱機制,在日誌收集、流式數據傳輸、在線/離線系統分析、實時監控等領域有廣泛的應用。
▍ 日誌同步
在大型業務系統設計中,為了快速定位問題,全鏈路追蹤日誌,以及故障及時預警監控,通常需要將各系統應用的日誌集中分析處理。
Kafka設計初衷就是為了應對大量日誌傳輸場景,應用通過可靠非同步方式將日誌消息同步到消息服務,再通過其他組件對日誌做實時或離線分析,也可用於關鍵日誌資訊收集進行應用監控。
日誌同步主要有三個關鍵部分:日誌採集客戶端,Kafka消息隊列以及後端的日誌處理應用。
- 日誌採集客戶端,負責用戶各類應用服務的日誌數據採集,以消息方式將日誌「批量」「非同步」發送Kafka客戶端。
Kafka客戶端批量提交和壓縮消息,對應用服務的性能影響非常小。 - Kafka將日誌存儲在消息文件中,提供持久化。
- 日誌處理應用,如Logstash,訂閱並消費Kafka中的日誌消息,最終供文件搜索服務檢索日誌,或者由Kafka將消息傳遞給Hadoop等其他大數據應用系統化存儲與分析。
日誌同步示意圖:

▍流計算處理
在很多領域,如股市走向分析、氣象數據測控、網站用戶行為分析,由於數據產生快、實時性強且量大,您很難統一採集這些數據並將其入庫存儲後再做處理,這便導致傳統的數據處理架構不能滿足需求。Kafka以及Storm、Samza、Spark等流計算引擎的出現,就是為了更好地解決這類數據在處理過程中遇到的問題,流計算模型能實現在數據流動的過程中對數據進行實時地捕捉和處理,並根據業務需求進行計算分析,最終把結果保存或者分發給需要的組件。
▍ 數據中轉樞紐
近10多年來,諸如KV存儲(HBase)、搜索(ElasticSearch)、流式處理(Storm、Spark、Samza)、時序資料庫(OpenTSDB)等專用系統應運而生。這些系統是為單一的目標而產生的,因其簡單性使得在商業硬體上構建分散式系統變得更加容易且性價比更高。通常,同一份數據集需要被注入到多個專用系統內。例如,當應用日誌用於離線日誌分析時,搜索單個日誌記錄同樣不可或缺,而構建各自獨立的工作流來採集每種類型的數據再導入到各自的專用系統顯然不切實際,利用消息隊列Kafka版作為數據中轉樞紐,同份數據可以被導入到不同專用系統中。
下圖是美團 MySQL 數據實時同步到 Hive 的架構圖,也是一個非常經典的案例。

4.3 如何技術選型
2018年去哪兒QMQ開源了,2019年騰訊TubeMQ開源了,2020年Pulsar如火如荼。
消息隊列的生態是如此的繁榮,那我們如何選型呢?
我想我們不必局限於消息隊列,可以再擴大一下。簡單談一談我的看法。
Databases are specializing – the 「one size fits all」 approach no longer applies —– MongoDB設計哲學
第一點:先有場景,然後再有適配這種場景的技術。什麼樣的場景選擇什麼樣的技術。
第二點:現實往往很複雜,當我們真正做技術選型,並需要落地的時候,技術儲備和成本是兩個我們需要重點考量的因素。
▍ 技術儲備
- 技術團隊有無使用這門技術的經驗,是否踩過生產環境的坑,以及針對這些坑有沒有完備的解決方案;
- 架構團隊是否有成熟的SDK,工具鏈,甚至是技術產品。
▍ 成本
- 研發,測試,運維投入人力成本;
- 伺服器資源成本;
- 招聘成本等。
最後一點是人的因素,特別是管理者的因素。每一次大的技術選型考驗技術管理者的視野,格局,以及管理智慧。
5 寫到最後
我覺得這個世界上沒有什麼毫無道理的橫空出世,真的,如果沒有大量的積累大量的思考是不會把事情做好的。。。
總之,在經歷了這部電影以後,我覺得我要學的太多了,這世界上有太多的能人,你以為的極限,弄不好,只是別人的起點。所以只有不停地進取,才能不丟人。那,人可以不上學,但一定要學習,真的。
—— 韓寒《後會無期》演講
我學習消息隊列的過程是不斷思考,不斷實踐的過程,雖然我以為的極限,弄不好,只是別人的起點,但至少現在,當我面對這門技術的時候,我的內心充滿了好奇心,同時也是無所畏懼的。
我始終相信:每天學習一點點,比昨天進步一點點就好。
如果我的文章對你有所幫助,還請幫忙點贊、在看、轉發一下,你的支援會激勵我輸出更高品質的文章,非常感謝!



