聊聊同步、非同步、阻塞、非阻塞以及IO模型
- 2022 年 1 月 10 日
- 筆記
- Learn Java
前言
在使用Netty改造手寫RPC框架的時候,需要給大家介紹一些相關的知識,這樣很多東西大家就可以看明白了,手寫RPC是一個支線任務,後續重點仍然是Kubernetes相關內容。
阻塞與非阻塞 同步與非同步
阻塞與非阻塞
阻塞和非阻塞是進程在訪問數據的時候,數據是否準備就緒的一種處理方式。當數據沒有準備的時候,阻塞需要等待調用結果返回之前,進程會被掛起,函數只有在得到結果之後才會返回。非阻塞和阻塞的概念相對,指在不能立刻得到結果之前,該函數不會阻塞當前執行緒,而會立刻返回。
同步與非同步
同步指的是在發出一個功能調用時,在沒有得到結果之前,該調用就不返回。也就是必須一件一件事做,等前一件做完了才能做下一件事。非同步的概念和同步相對,當一個非同步過程調用發出後,調用者不能立刻得到結果。實際處理這個調用的部件在完成後,通過狀態、通知和回調來通知調用者。
舉個例子來說,對於我們經常使用B/S架構來說,同步和非同步指的是從客戶端發起訪問數據的請求,阻塞和非阻塞指的是服務端進程訪問數據,進程是否需要等待。這兩者存在本質的區別,它們的修飾對象是不同的。
阻塞和非阻塞是指進程訪問的數據如果尚未就緒,進程是否需要等待,簡單說這相當於函數內部的實現區別,也就是未就緒時是直接返回還是等待就緒。
同步和非同步是指訪問數據的機制,同步一般指主動請求並等待I/O操作完畢的方式,當數據就緒後在讀寫的時候必須阻塞,非同步則指主動請求數據後便可以繼續處理其它任務,隨後等待I/O,操作完畢的通知,這可以使進程在數據讀寫時也不阻塞。
舉個例子
媽媽讓我去廚房燒一鍋水,準備下餃子。
阻塞:水只要沒燒開,我就乾瞪眼看著這個鍋,滄海桑田,日新月異,我自巋然不動,廚房就是我的家,燒水是我的宿命;
非阻塞:我先去我屋子裡打把王者,但是每過一分鐘,我都要去廚房瞅一眼,生怕時間長了,水燒乾了就壞了,這樣導致我遊戲也心思打,果不然,又掉段了;
同步:不管是每分鐘過來看一眼鍋,還是寸步不離的一直看著鍋,只要我不去看,我就不知道水燒好沒有,浪費時間啊,一寸光陰一寸金;
非同步:我在淘寶買了一個電水壺,只要水開了,它就發出響聲,嗨呀,可以安心打王者嘍,打完可以吃餃子嘍;
總結:
阻塞/非阻塞:我在等你幹活的時候我在幹啥?
阻塞:啥也不幹,死等;
非阻塞:可以干別的,但也要時不時問問你的進度;
同步/非同步:你幹完了,怎麼讓我知道呢?
同步:我只要不問,你就不告訴我;
非同步:你幹完了,直接喊我過來就行;
IO模型
網路IO的本質是Socket的讀取,Socket在Linux系統被抽象為流,IO可以理解為對流的操作。Linux標準文件訪問方式如下:

當發起一個read操作的時候,會經歷2個階段:
-
等待數據準備; -
將數據從內核拷貝到進程中;
對於socket流也會經歷兩個階段:
-
將磁碟或者其他設備到達以後的資訊,拷貝到內核的快取區中; -
將內核的快取區的數據複製到應用進程快取中;
網路應用需要處理的無非就是兩大類問題,網路IO,數據計算。相對於後者,網路IO的延遲,給應用帶來的性能瓶頸大於後者,接下來我們介紹下IO模型:
同步阻塞IO(blocking IO)
同步阻塞 IO 模型是最常用的一個模型,也是最簡單的模型。在Linux中,默認情況下所有的socket都是blocking。阻塞就是進程休息, CPU處理其它進程去了。
用戶空間的應用程式執行一個系統調用(recvform),這會導致應用程式阻塞,直到數據準備好,並且將數據從內核複製到用戶進程,最後進程再處理數據,在等待數據到處理數據的兩個階段,整個進程都被阻塞。不能處理別的網路IO。調用應用程式處於一種不再消費 CPU 而只是簡單等待響應的狀態,因此從處理的角度來看,這是非常有效的。在調用recv()/recvfrom()函數時,發生在內核中等待數據和複製數據的過程,大致如下圖:

-
應用進程向內核發起recfrom讀取數據;
-
準備數據報(應用進程阻塞);
-
將數據從內核負責到應用空間;
-
複製完成後,返回成功提示;
特點
同步阻塞 IO 整個過程都是阻塞的,對於用戶可以及時返回數據,無延遲,對於開發者來說簡單省事,對於系統來說無法應對高並發訪問,以及用戶在等待期間也無法進行其他任何操作。
同步非阻塞IO(nonblocking IO)
同步非阻塞就是採用輪詢的方式,定時去查看數據是否準備完成。在這種模型中,進程是以非阻塞的形式打開的。IO 操作不會立即完成,如果該緩衝區沒有數據的話,就會直接返回一個EWOULDBLOCK錯誤,不會讓應用一直等待中。
非阻塞IO也會進行recvform系統調用,檢查數據是否準備好,與阻塞IO不一樣,非阻塞將大的整片時間的阻塞分成N多的小的阻塞, 所以進程不斷地有機會被CPU訪問。也就是說非阻塞的recvform系統調用調用之後,進程並沒有被阻塞,內核馬上返回給進程,如果數據還沒準備好,此時會返回一個error。

-
應用進程向內核發起recvfrom讀取數據;
-
沒有數據報準備好,即刻返回EWOULDBLOCK錯誤碼;
-
應用進程向內核發起recvfrom讀取數據;
-
已有數據包準備好就進行一下步驟,否則還是返回錯誤碼;
-
將數據從內核拷貝到用戶空間;
-
完成後,返回成功提示;
特點
同步非阻塞方式相比同步阻塞方式,在等待任務期間進程可以處理其他事情,缺點的話就是因為採用定時輪詢的方式,導致系統整體的吞吐量降低。
IO多路復用( IO multiplexing)
同步非阻塞方式需要不斷主動輪詢,輪詢佔據了很大一部分過程,輪詢會消耗大量的CPU時間,當並發情況下伺服器很可能一瞬間會收到幾十上百萬的請求,這種情況下同步非阻塞IO需要創建幾十上百萬的執行緒去讀取數據,同時又因為應用執行緒是不知道什麼時候會有數據讀取,為了保證消息能及時讀取到,那麼這些執行緒自己必須不斷的向內核發送recvfrom 請求來讀取數據。這麼多的執行緒不斷調用recvfrom 請求數據,明細是對執行緒資源的浪費。
於是有人就想到了由一個執行緒循環查詢多個任務的完成狀態(fd文件描述符),只要有任何一個任務完成,就去處理它。這樣就可以只需要一個或幾個執行緒就可以完成數據狀態詢問的操作,當有數據準備就緒之後再分配對應的執行緒去讀取數據,這麼做就可以節省出大量的執行緒資源出來,這個就是IO多路復用。

-
應用進程向內核發起select調用;
-
kernel會監聽所有select負責的socket;
-
任何一個socket中的數據準備好了,select就會返回;
-
應用進程再調用recvfrom操作,將數據從內核拷貝到用戶空間;
-
完成後,返回成功提示;
特點
IO多路復用與同步非阻塞相比,應用執行緒通過調select/poll之後,阻塞住,進入到內核態後由內核執行緒來輪詢這個應用執行緒所關注的所有文件描述符對應的緩衝區是否有數據準備就緒,只要有一個緩衝區數據準備就緒,就可以進行數據拷貝然後返回給用戶執行緒,這種方式就減少了用戶執行緒的不斷輪詢以及避免在每次輪詢時所產生的兩次上下文切換過程。
此外就是IO多路復用模型可以同時阻塞多個I/O操作。而且可以同時對多個讀操作,多個寫操作的I/O函數進行檢測,直到有數據可讀或可寫時(這裡並不是全部數據可讀或可寫),才真正調用I/O操作函數。
此外還需要注意的是,IO多路復用既然可以處理多個IO,也就帶來了新的問題,多個IO之間的順序變得不確定了。
訊號驅動IO(signal-driven IO)
IO多路復用解決了一個執行緒或者多個執行緒可以監控多個文件描述符的問題,但是select是採用輪詢的方式來監控多個文件描述符的,通過不斷的輪詢文件描述符的可讀狀態來知道是否有可讀的數據,這樣無腦的輪詢就顯得有點浪費,因為大部分情況下的輪詢都是無效的,於是乎有人就想,能不能不要總是去輪詢數據是否準備就緒,能不能發出請求後,等數據準備好了在通知我,所以這樣就出現了訊號驅動IO。
訊號驅動IO不是用循環請求詢問的方式去監控數據就緒狀態,而是在調用sigaction時候建立一個SIGIO的訊號聯繫,當內核數據準備好之後再通過SIGIO訊號,通知執行緒數據準備好後的可讀狀態,當執行緒收到可讀狀態的訊號後,此時再向內核發起recvfrom讀取數據的請求。因為訊號驅動IO的模型下,應用執行緒在發出訊號監控後即可返回,不會阻塞,所以這樣的方式下,一個應用執行緒也可以同時監控多個文件描述符。
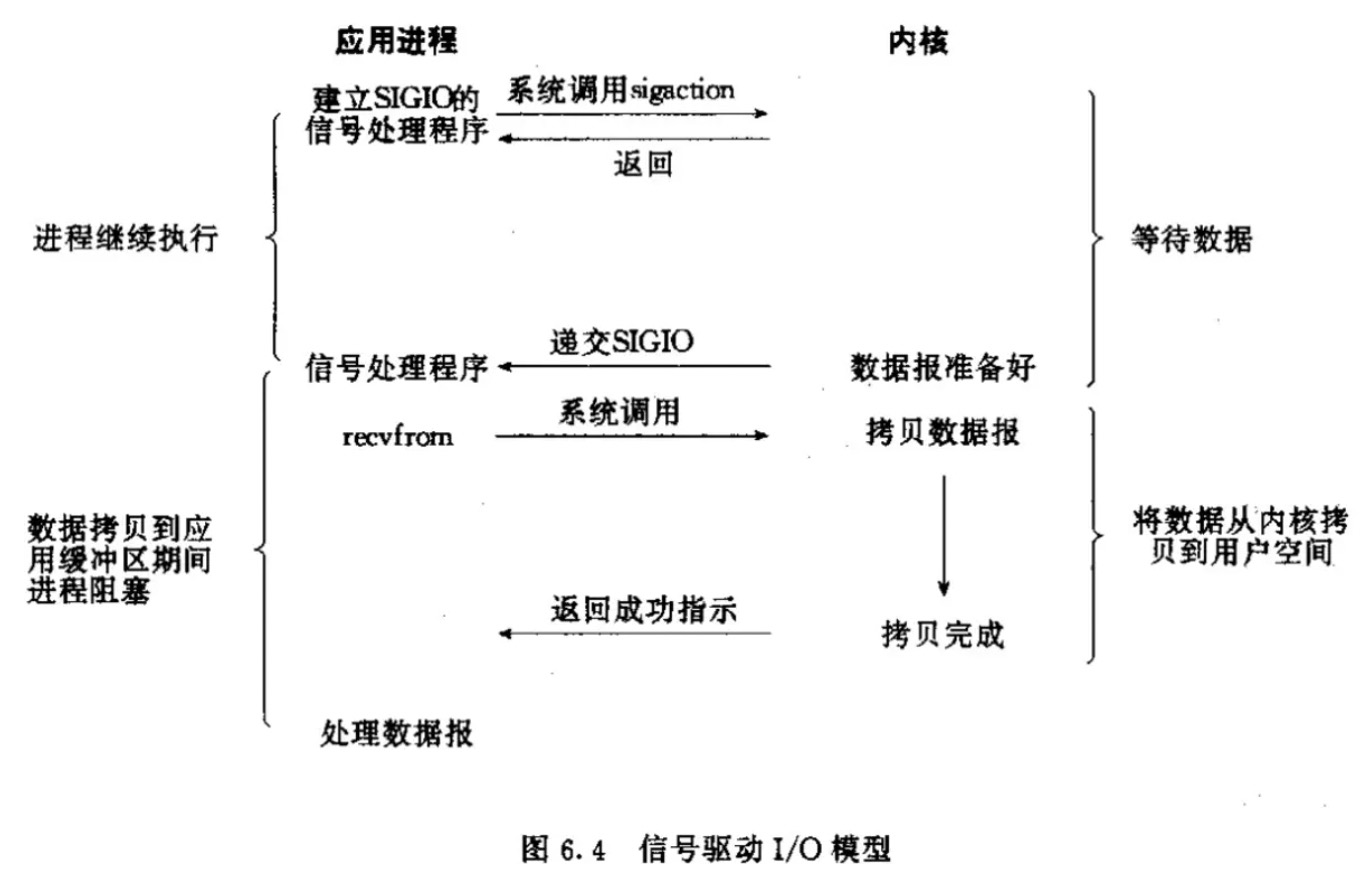
-
應用進程開啟套介面訊號驅動IO功能,通過系統調用sigaction執行一個訊號處理函數,請求即刻返回;
-
當數據準備就緒時,就生成對應進程的SIGIO訊號,通過訊號回調通知應用進程;
-
應用進程再調用recvfrom操作,將數據從內核拷貝到用戶空間;
-
完成後,返回成功提示;
特點
訊號驅動IO相比於IO多路復用,在通過這種建立訊號關聯的方式,實現了發出請求後只需要等待數據就緒的通知即可,這樣就可以避免大量無效的數據狀態輪詢操作。
非同步非阻塞 IO(asynchronous IO)
不管是IO多路復用還是訊號驅動,我們要讀取數據的時候,總是要發起兩階段的請求,第一次發送select請求,詢問數據狀態是否準備好,第二次發送recevform請求讀取數據。這個時候我們會有一個疑問,為什麼在讀數據之前總要有個數據就緒的狀態,可不可以應用進程只需要向內核發送一個read 請求,告訴內核要讀取數據後,就立即返回。當內核數據準備就緒,內核會主動把數據從內核複製到用戶空間,等所有操作都完成之後,內核會發起一個通知告訴應用,所以這樣就出現了非同步非阻塞 IO模型。
非同步非阻塞IO模型應用進程發起aio_read操作之後,立刻就可以開始去做其它的事。後續的操作有內核接管,當內核收到一個asynchronous read之後,它會立刻返回,不會對用戶進程產生任何block。然後,內核會等待數據準備完成,然後將數據拷貝到用戶記憶體,當這一切都完成以後,內核會給用戶進程發送一個signal或執行一個基於執行緒的回調函數來完成這次 IO 處理過程。
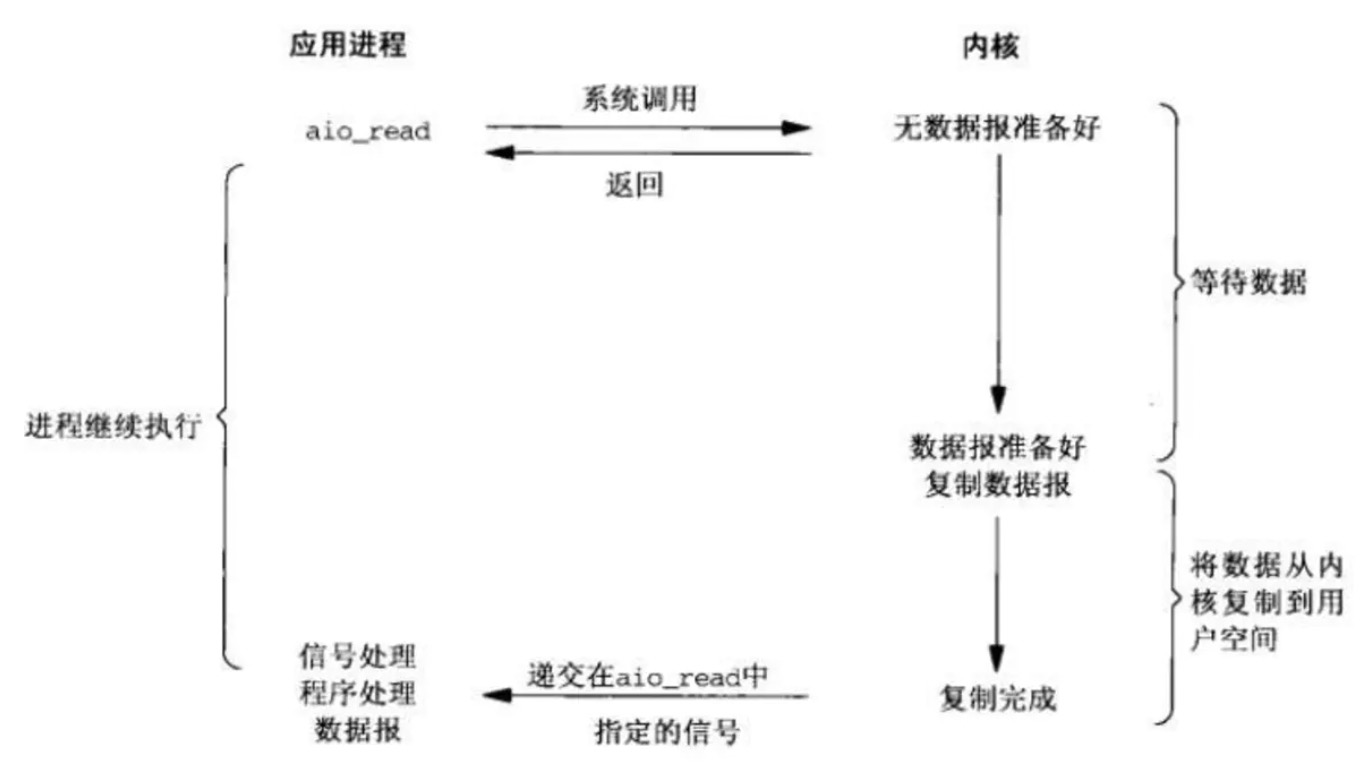
-
應用進程發起aio_read操作,立即返回;
-
內核等待數據準備完成,然後將數據拷貝到用戶記憶體;
-
內核會給用戶進程發送一個signal訊號;
-
收到訊號,返回成功提示;
特點
非同步非阻塞 IO相比於訊號驅動IO,訊號驅動IO模型只是由內核通知我們可以開始下一個IO操作,而非同步非阻塞 IO模型是由內核通知我們操作什麼時候完成。
五種IO模型總結
阻塞IO和非阻塞IO區別
調用阻塞IO會一直阻塞住對應的進程直到操作完成,而非阻塞IO在內核還準備數據的情況下會立刻返回。
同步IO和非同步IO區別
兩者的區別就在於同步IO做IO操作的時候會將進程阻塞,也就是應用進程調用recvfrom操作,recvfrom會將數據從內核拷貝到用戶記憶體中,在這段時間內,進程是被阻塞的。

舉個例子
小王去買火車票,三天後買到一張退票。參演人員(老李,黃牛,售票員,快遞員),往返車站耗費1小時。
同步阻塞 IO
小王去火車站買票,排隊三天買到一張退票。整個三天小王無法做其他事情,只能做買票的一件事情。
同步非阻塞 IO
小王去火車站買票,隔一天去火車站問有沒有退票,三天後買到一張票。整個過程中小王需要往返3次,往返消耗3小時,這個期間小王可以做其他事情。
IO多路復用
select/poll
小王去火車站買票,委託黃牛購買,然後每隔12小時打電話詢問黃牛,黃牛三天買到票,然後小王去火車站交錢領票。整個小王需要往返2次,往返消耗2小時,黃牛需要手續費100,打電話6次,這裡的黃牛就是select/poll,多路指的就是一個黃牛可以服務多個人。
epoll
小王去火車站買票,委託黃牛購買,黃牛買到後即通知小王去領,然後小王去火車站交錢領票。整個過程小王需要往返2次,往返消耗2小時,黃牛需要手續費100,無需打電話。
訊號驅動IO
小王去火車站買票,售票員留下電話,有票後,售票員電話通知小王,然後小王去火車站交錢領票。整個過程小王需要往返2次,往返消耗2小時,無手續費,無需打電話。
非同步非阻塞 IO
小王去火車站買票,給售票員留下電話,有票後,售票員電話通知小王並快遞送票上門。整個過程小王需要往返1次,往返消耗1小時,無手續費,無需打電話。
參考
結束
歡迎大家點點關注,點點贊!



