.NET C#教程初級篇 1-1 基本數據類型及其存儲方式
- 2022 年 1 月 7 日
- 筆記
- .NET, .NET Core C#, Asp.Net Core, c#, 編程
.NET C# 教程初級篇 1-1 基本數據類型及其存儲方式
全文目錄
本節內容是對於C#基礎類型的存儲方式以及C#基礎類型的理論介紹
基礎數據類型介紹
例如以下這句話:「張三是一名程式設計師,今年15歲重50.3kg,他的代號是『A』,他家的經緯度是(N30,E134)。」,這句話就是一個字元串,使用雙引號括起來。而15則表示是一個 整數類型,50.3就是小數類型,不過我們在C# 中通常稱為 浮點類型,最後一個經緯度,我們通常定位地點的時候都是成對出現,所以我們認為這二者是一個密不可分的結構,這種類型我們稱為 結構體類型(struct)。
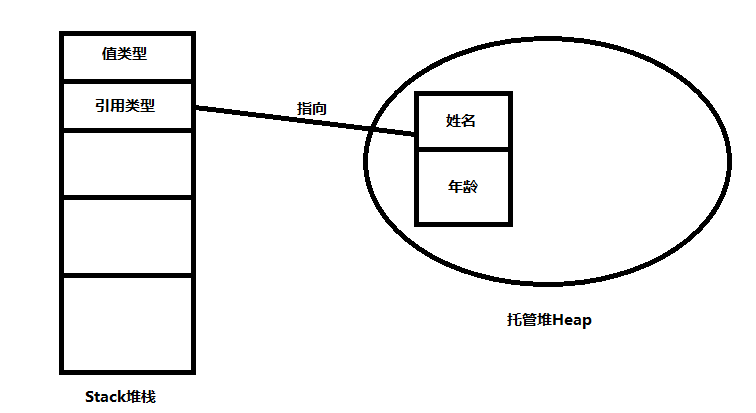
以上我所說的數據類型都是一個所含有資訊量一定的數值,我們稱為值類型;而張三這個人,他所含有的數據大小是不固定的,比如我又了解到了張三是一個富二代,那麼他就會增加一個屬性是富二代,我們需要更多的空間去存儲他,張三這個變數我們通常就稱為引用類型,而張三這個名字,我們就稱為引用,如果你對C或者C++熟悉的話,張三這個名字就是指向張三這個人(對象)的一個指針。
C# 中兩種數據存儲方式
在C# 中,數據在記憶體中的存儲方式主要分為在堆中存儲和棧中存儲。我們之前提到的值類型就是存儲在棧中,引用類型的數據是存儲在堆中,而數據是在棧中。
值類型:存儲在棧(Stack,一段連續的記憶體塊)中,存儲遵循先進後出,有嚴格的順序讀取訪問速度快,可通過地址推算訪問同一個棧的其餘變數。
引用類型:引用(本質上和C++中的指針一致)存儲在棧中,內含的數據存儲在堆中(一大塊記憶體地址,內部變數存儲不一定連續存儲)。
事實上,值類型和引用類型有一個很明顯的區別就是值類型應當都是有值的,而引用類型是可以為空值的。在C#中,記憶體管理相比於C/C++是更加安全的,在C/C++中我們可以自由的申請和釋放記憶體空間,C#採用堆棧和託管堆進行記憶體管理。也就是絕大部分的記憶體管理都交給了CLR。通常來說棧負責保存我們的程式碼執行(或調用)路徑(也就是直接指向的數據的記憶體地址),而堆則負責保存對象(或者說數據,接下來將談到很多關於堆的問題)的路徑。
考慮到實際難度,在這裡我們不做太多深入的研究,具體的分析內容讀者可以查看本教程的番外補充篇進行學習。
堆棧
堆棧一般用於存儲數據引用(指針)或是一些值類型,它的空間並不大,通常只有幾M大小,它的讀取速度是快於存儲在堆中的數據的。
託管堆
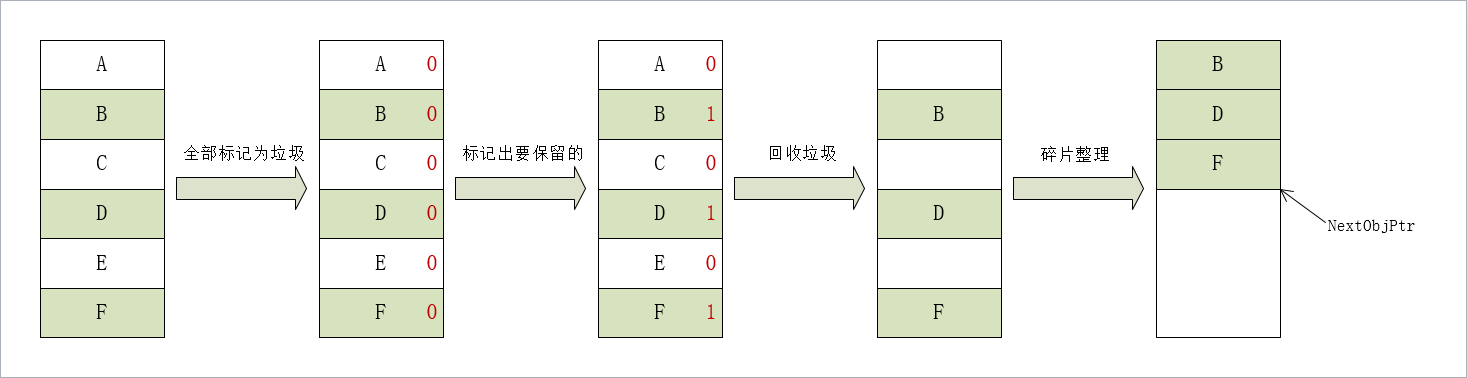
在C#中微軟使用了託管堆進行記憶體的管理,引用類型的實例是記憶體釋放都交給了GC(垃圾回收器)進行自動的處理。這樣保證了記憶體的安全性。下圖是垃圾回收的機制:
常見的幾種數據類型
- 字元類型:char字元類型,代表無符號的16位整數,對應的可能值是ASCⅡ碼,你可以上網搜索ASCⅡ碼的內容
- 整數類型:常用的一般有:byte,short,int,long。各代表8位、16位、32位、64位整型。佔用記憶體分別為(位數/8)位元組。範圍則是 +-(位數)個1組成的二進位的十進位數/2。例如byte的範圍則是11111111轉十進位後除以2取反,即-127~128。範圍絕對值之和為256。
- 浮點類型:float, double, decimal:浮點類型,分別代表32位、64位、128位浮點類型。通常默認類型是double,如果需要指定float類型,需要1.3f,decimal類型則指定1.3m。浮點型存在的問題是精度的損失,並不一定安全。
- 布爾類型:bool類型是一個二進位中的0和1,各代表了false和true。只存在兩個值。
- 字元串類型:string本質是一種語法糖,作為字元類型的數組引用(指針)存在,也是String類的簡寫
- 委託類型:delegate用於綁定函數,為引用類型的一種,將函數參數化為變數。本質上就是C++中的函數指針。
- 數組:繼承自Array類,屬於任意類型的一種集合,但不同於集合,大小必須被初始化。在記憶體中是一段連續的記憶體空間,但是不是值類型。
數據的存儲方式
對於大部分學習者而言,數據的存儲方式是一個相對陌生的概念,但是為了全面理解和學習,還是有必要進行一個簡單的學習的。這裡不會講述過難的組成原理知識,只是讓讀者明白一些有關電腦科學的原理和常識。
進位
首先我們學習一下在電腦常用的一些進位,這裡以二進位、八進位和十六進位進行展開。在進行講解之前,提出一個問題,為什麼我們的電腦都是以二進位為基礎進行算數的運算呢?
其實答案很簡單,因為電腦是採用數字電路進行邏輯運算最終實現我們的功能的,而對於一條電路而言,它的電位只有高低兩種電平,或者理解為只分為有電流和無電流通過。因此使用0和1作為標識是非常實用的。同時採用二進位也有利於我們電路邏輯的設計。
二進位的運算非常的簡單,從低到高位分別賦予權重\(2^{n-1}\),n為位數,而一串二進位的十進位表示的計算公式為
\]
其中\(K_i\)稱為位權,取值是0或1,更一般的,一個r進位數的的位權取值是一個大於0小於r-1的數,r進位數轉換為10進位的計算公式如下:
\]
在C#中,表示一個二進位通常用Ob開頭,8進位則是以0開頭,16進位以0x開頭,例如
int a = 0b101011;//二進位
int b = 035167;//八進位
int a = 0xD2F3;//十六進位
講完了二進位數,接下來我們講講八進位和十六進位。既然二進位如此美妙好用,為什麼各位電腦學家還是要在電腦大量的使用八進位和十六進位呢?一個很明顯的例子就是變數在記憶體中往往都是以8或16進位進行存儲,不知道你有沒有看過時常彈出來的錯誤窗口中會提示記憶體0xfffff錯誤,這裡就是使用了我們的十六進位。原因是因為一段過長的二進位值是可讀性非常差的,而選擇八進位和十六進位正是縮短了過長的二進位,因為八進位逢8進1,也就是2的3次方,十六進位則是2的4次方,十六進位超過9以後的數以字母A~F表示。例如101011011011這串二進位程式碼,如果換算成八進位則是05333,轉換成為十六進位則是0xACB,很明顯大大縮小了我們的閱讀難度,同時因為其是2的整數次方,轉換也十分的簡單迅速。
二進位轉八進位的訣竅是,從低到高位,每三位一組(\(2^3\)),最後不足三位的前面添0,以每一組二進位的值為位權,最終就是我們的八進位數。十六進位也一樣,只不過改成以4個為一組(\(2^4\))。如果將16或8進位轉換成為2進位,則將十六或八進位中從每一位按4或3位展開即可。例如
1011011011轉八進位的過程,先添0補足長度為3的倍數,001011011011,分組001|011|011|011,則表示為1333,十六進位和N進位轉2進位希望讀者自己嘗試解決。
如果帶小數點,則依次類推,只不過我們指數冪就換成負數即可,這裡不再展開贅述。
在C#中也提供了相關的函數方便我們迅速進行進位間的轉換
// value為需轉換的R進位數,以字元串表示,fromBase為需轉換的進位
Convert.ToInt32(string value, int fromBase):
// value為需轉換的十進位數,toBase為需轉換的進位
Convert.ToString(int value, int toBase);
值得補充的一點是,數據在記憶體中的存儲大小本身是由數據的 位(bit) 決定的,我們常說的一位元組在現在的電腦中指有8個比特空間大小,一個比特位可以存儲一位二進位程式碼,而我們常見的int類型默認是Int32,也就是32位整形,因此你知道為什麼int是4個位元組了吧?
正負數存儲形式及四種碼
在電腦中,數據往往並不是直接以數值本身的二進位碼(機器數)進行存儲和計算的,我們往往需要對數值的二進位碼進行一些變換。同時你是否想過,正數我們可以直接寫出它的二進位碼,那麼碰到負數我們又應該如何做呢?也許聰明的你已經想要脫口而出:既然因為電位只有兩種狀態我們用0和1進行表示,正負也只有兩種表示方法!因此我們在二進位碼的頭部增加一位符號位進行有符號數的正負標識,這裡我們用1表示負號,0表示正號。這裡似乎又解決了我們一個很頭大的問題:為什麼int、long這種有符號數表示的範圍是要比它所佔的位數少一位,因為最高位用於標識它的符號了。
這裡我們引入下一個概念 「原碼」:原碼是最簡單、直觀的機器數表示方法了,也就是用機器數的最高位標識它的符號,其餘為數據位是數的絕對值。例如-8這個十進位數用二進位原碼錶示就是1100。值得一提的是,0在原碼錶示法中有兩種表示,+0和-0。
反碼 :反碼的概念非常的簡單,通常反碼在電腦中只起到原碼到補碼轉換的過渡過程。在這直接拋出計算方法而不做贅述。對於正數,反碼就是其本身,對於負數,反碼則是將原碼中除符號位外每一位數字進行邏輯取反,因此它的性質和原碼其實是一致的。 例如+8的二進位為0,100,反碼就是0,100,對於-8的二進位1,100,反碼則為1,011
接下來介紹的是電腦中真正的數據存儲方式,補碼:首先,補碼正如其名,和原碼是一對互補的數字。它的和原碼之間的關係是:對於正數,補碼就是其本身,對於負數,原碼的反碼+1=補碼。
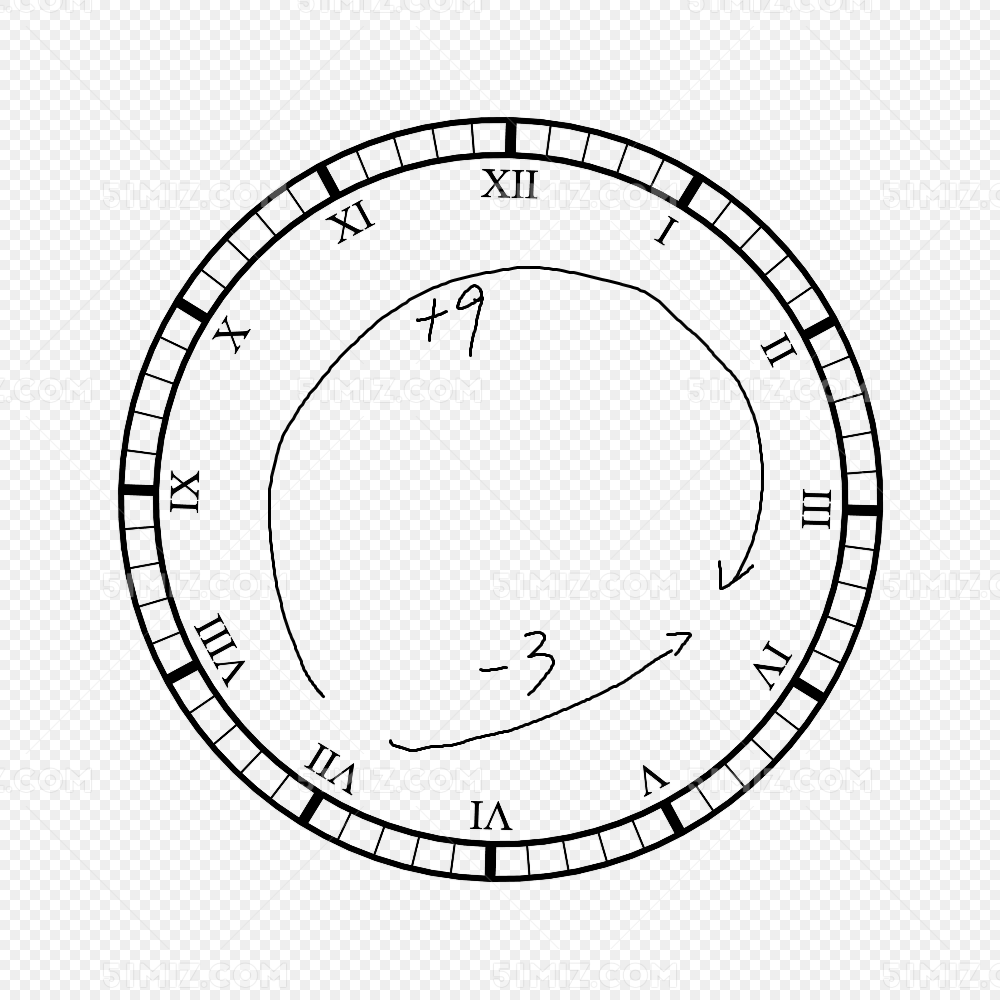
我們引入一個生活中的小例子,我們在看鐘表的時候,如果以0(12)作為基準,如果現在指針指向3,我們正常會以順時針從0(12)開始數到3,得知現在是3點,如果是指向9,我們則會從0(12)開始逆時針開始數。或者說,你看到15點會不自覺的知道指針指向3,因為15-12=3,這裡其實就已經用到了補碼的概念。事實上,在電腦的結構中,加法是可以直接進行運算的,但是並沒有針對減法設計數字電路,因為減法的數字電路並不容易設計,同時也出於節約成本的考慮,如果只設計加法電路的情況,如何去得到我們的減法?這裡先需要知道一個運算求余——%,例如7%3=1,即除法後的餘數。我們就以7-3為例子,試著將一個減法運算成加法。
答案非常的顯而易見,7-3不就是7+(-3)嗎?你可以假設一個鐘錶,它的最大值是12,現在指向7,我們定義順時針為正,逆時針為負。現在鐘錶指向了7,我們逆時針往迴轉3個小時,指針指向了4。那麼問題來了,我們是不是也可以順時針轉9格也得到4呢?按著我們的定義7+9=16並不等於4,但我們的鐘錶最大也只有12呀,因此我們需要將溢出位丟棄,也就是取余操作(7+9) mod 12=4。這樣我們就成功的將一個減法運算設計成了加法運算了。
因此回到我們補碼的概念,那麼7-3實際上是7和-3進行相加,加法是可以直接運算的,而從補碼和反碼的定義我們知道負數的反碼是數值位進行取反而符號位不變,因此負數的\([反碼+原碼+1]_原=最大值+1\)也就是\([補碼+原碼]_原=最大值+1\),這也就體現了補碼的名稱了。因此對於減法\(x-y(x>0,y>0)\),可以化為\((x+[y]_補)\%(max+1)\),其實證明並不難,如下
y_補=max-y_原+1\\
x+y_補 = x-y_原+max+1\\
因此很顯然x-y = x+y_補=(x-y_原+max+1)\%(max+1)得證
\\\]
更一般的,若數據表示的最大原碼為M-1,對於定點類型數(整數、定點小數),有
\\
\\
[A-B]_補 = (A_補+[-B]_補)mod M
\]
講到這裡,其實也就解釋通了為什麼在電腦中,數據都是以補碼的形式進行存儲和運算了,因為可以講任意的加減法(乘除法實際上也就是循環型的加減)都按著加法進行運算,有利於節省成本和降低設計難度。
移碼是我們四碼裡面的最後一種碼,它通常用於表示浮點數的階碼,具體的運用在下文會詳細的進行介紹,這裡不再展開。移碼的定義非常簡單,就是在真值X上加上偏置量,通常是以2的n次方為偏置量,就相當於X在數軸之上偏移了若干個單位。移碼的求解方法非常簡單,將補碼的符號位取反就是移碼。例如真值1,進行移位\(2^4\)得到了17,轉換成為補碼形式就是10001。
定點數與浮點數存儲方式
定點數和浮點數統稱實型,點指代小數點,定點數無需解釋,我們只要事先規定好整數位和小數位的數量即可表示。對於浮點數,
*數據的存儲方式(選看)
數據的存儲方式主要分為大端存儲和小端存儲、邊界對齊存儲(詳情請看結構體的內容)兩種。對於現代的電腦,數據的存儲通常以位元組編址,也就是一個地址編號對應的記憶體單元存儲1個位元組。那麼對於一個大的數據,我們可能會存儲在連續的多個記憶體單元之中。
大端小端沒有誰優誰劣,各自優勢便是對方劣勢,我們不太需要關注哪一種存儲方式,只需要大體了解一下即可。
- 小端存儲就是低位位元組排放在記憶體的低地址端,高位位元組排放在記憶體的高地址端。
- 大端存儲就是高位位元組排放在記憶體的低地址端,低位位元組排放在記憶體的高地址端。
例如數字0x12345678進行存儲時,存儲記憶體結構如下圖。
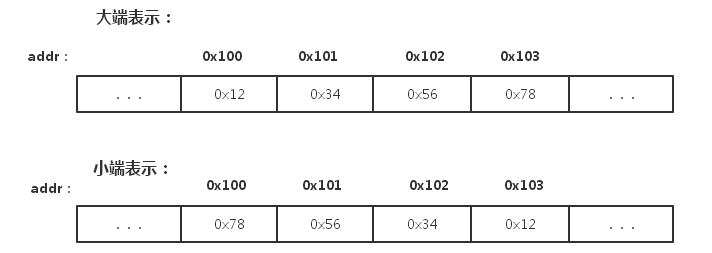
小端模存儲中強制轉換數據不需要調整位元組內容,1、2、4位元組的存儲方式一樣。而在大端存儲中符號位的判定固定為第一個位元組,容易判斷正負。
為什麼要學這個奇怪的知識呢?因為在跨語言或平台的通訊之中,不了解這個知識總是會有一些奇奇怪怪的錯誤出現,例如Java網路通訊中,數據流是按大端位元組序,和網路位元組序一致的方法進行傳輸,而C#在Windows平台上是小端位元組序進行數據存儲。那麼如果一個Java程式往一個C#程式發送網路數據包的時候,由於數據存儲順序的不同就會導致數據讀取結果的不同。
大家可以閱讀這兩篇博文進行一個理解:
值與引用類型的存儲方式
在前文中我們其實已經講過許多有關值類型和引用類型的存儲,大體上我們值類型、指令、指針等是直接存儲在棧中,而引用類型、委託等指針指向的類型則存儲在託管堆中。具體請看文章開頭處對數據類型的簡介。
C#中定義變數的方式及數據轉換的方法
在C#中定義變數的方式和其他的主流語言沒有太大的區別,以下是幾種定義方式:
int number = 5;//定義一個32位整數類型
bool b = true;//定義
//注意看以下兩條,string定義的字元串必須為雙引號,而char使用單引號並且只允許輸入一個字元
string str = "test";
char a = 'a';
//記得後綴
float f = 1.3f;
decimal d = 1.5m;
數據類型的轉換分為隱式轉換和顯式轉換,看下面幾個例子:
string a = "15";
int b = int.Parse(a);//顯式轉換
b = (int)a;//強制轉換
b = Convert.ToInt32(a);//顯式轉換,較常用
double d = 1.5;
b = d;//隱式轉換
如果我們定義的數據大小超過了數據類型本身的大小,那麼位於高位的數據會被首先捨棄。
這裡還有一種相對特殊的類型——無符號類型,通過前文的介紹,我們大體已經知道了有符號數字的定義以及存儲方式,而對於無符號數,補碼原碼反碼都是其本身,也就是將首位的符號位替換成了數據位。當有符號數向無符號數進行轉換時,我們需要計算出有符號數的補碼,然後直接按公式進行計算。例如:
int a = -3;//補碼為100
uint b = a;//b=8
數組
數組指一個類型(任意)的集合,例如你定義一個變數為a=5,很輕鬆,假設你需要100個呢?因此我們使用數組來存儲。
數組的定義以及使用如下:
//偽程式碼,T為類型,n為大小
T [] t = new T[n];
//定義一個整型數組
int [] a = new int [5];
//你也可以選擇初始化的方式定義
int [] b = new int [] {1,2,3,4,5};
//或
int [] c = new int [5]{1,2,3,4,5};
//數組的訪問,從0開始索引
Console.WriteLine(b[0]);
有時候我們也許會想用一個表格進行數據的存儲,例如我們存儲一個矩陣就需要二維的空間,這裡給出二維數組的定義:
//偽程式碼,T為類型,m,n為大小
T [,] t = new T[m,n];
本質上二維數組的概念就是數組的數組,一個組成元素為一維數組的數組就是我們的二維數組。一般而言,我們需要指定二維數組的行列寬,當然我們也可以不指定行數直接初始化,但我們必須指定列數,因為記憶體是按行進行分配。
運算符及規則重載
基礎的運算符
- +-*/:對應數學中的加減乘除。
- %: 求余運算,a%b指a除以b的餘數。
- & | ~ ^ :分別為按位與、按位或、按位取反、按位異或
- <<、>>:左右移位運算符,例如0010 –> 0100
- ?:三元判斷運算符
^是異或,result=1110,就是說異是不同返回1,相同是0,或就是只要有1就返回1。
&是與, result=0001,也就是相同返回1,不同為0
|是或, result=1111,除了兩個都為0,否則返回1
~稱為按位取反,我們表示符號是用四個0表示,運算規則就是正數的反碼,補碼都是其本身的源碼,
負數的反碼是符號位不變,本身的0變1,1變0,補碼就是反碼+1,
最後進行補碼取反時連同符號位一起變得到的反碼就是結果
流程如下:0000 0111 –> 0000 1000 –> 0000 1001 –> 1111 0110 = -8
>>稱為右移,右移一位流程如下 0000 1001 –> 0000 0100 = 4
<< 稱為左移,左移一位流程如下 0000 1001 –> 0000 10010 = 18
移位運算需要注意的一點是,由於我們電腦保存數據的方式是採取補碼存儲,因此,當我們對一個負數進行移位時,在添加的並不是0而是1。
運算符的重載
我們在大部分時候,語言自身提供的運算符運算規則已經足夠我們使用,但往往我們會涉及到一些奇怪的場景,例如我需要知道某兩個節日的日期相距多少天而我並不想藉助DateTime類的方法,我想用date1-date2進行計算,那麼我們就需要使用運算符重載去改寫減號的規則。
事實上我們仔細思考不難得出結論,一切的運算符本質上都是一種函數的對應關係,那麼我們使用operator關鍵字進行某類中運算符的重載,例如:
// T是修改類型的返回值
public static T operator +(D d1,D d2)
{
return something;
}
通過運算符重載,我們可以更有效的書寫高品質的程式碼,同時可讀性也可以大大提升。
具體的操作我會在我在BiliBili上發布的 .Net Core 教程上進行詳細的講述。
*結構體(選看)
結構體是一種比較特殊的數據類型,它很像我們後面講述到的類,但是他並不是一個類,他本質還是值類型,結構體的使用是很重要的,如果結構體使用得當,可以有效的提升程式的效率。
結構體你可以理解為將將若干個類型拼接在一起,但是存在一個很重要的內容——記憶體對齊。例如下面兩個結構體:
struct S
{
int a;
long b;
int c;
}
struct SS
{
int a;
int b;
long c;
}
乍一看你會覺得這兩個結構體完全一致,絲毫沒有任何的差別。但事實上,在大多數程式語言裡面,對於結構體這種大小並不是定值的值類型,都存在一個最小分配單元用於結構體內單個變數的大小分配。在記憶體中,他們兩個的存儲方式有很大的不同。
對於上面兩個結構體,他們在記憶體中的單元分配是:
- S:a(4 byte + 4 free) –> b(8 byte) –> c(4 byte + 4 free),共計24位元組
- SS:a(4 byte)b(4 byte) –> c(8 byte),共計16位元組
在C#中,如果你不指定最小分配單元,那麼編譯器將會把結構體中佔用記憶體最大的作為最小分配單元。不過尤其需要注意一件事,就是引用類型在結構體中。鑒於我們現在尚未講解面向對象的類,我們用string作為成員寫一個結構體。如下面這個例子:
struct S
{
char a;
long b;
string c;
}
//函數中創建
S s = new S();
s.a = 'a';
s.b = 15;
s.c = "I Love .NET Core And Microsoft"
很顯然s.c的大小超過了結構體中其餘兩個,但是記憶體分配的時候就是以最大的c作為標準嗎?
顯然不是,我們要知道struct是在棧中分配記憶體,string的內容是在堆中的,所以在結構體中存儲的string只是一個引用,並不會包含其他的東西,只佔用4個位元組。並且特別的,引用類型在記憶體中的位置位於大於四位元組的欄位前,小於四位元組欄位後。
上面記憶體分配應當是這樣:
a(8) –> c(8) –> b(8)。
如果需要深入了解這一方面內容,建議去閱讀《CLR Via C#》這本書,以及學習SOS調試相關內容。
練習題
理論分析題
- 計算出int和long的數值範圍
- 為什麼在大部分提供科學計算或程式語言會存在精度問題?例如浮點數2.5在任何一種採用二進位計算的程式語言中也不是一個精確值?或者說如果我們展開浮點數的所有精確位,最後的幾位小數並不是0?(較難)
- 為什麼引用類型即使不存儲內容也需要記憶體空間?
- 試說明引用類型和值類型的優缺點
- 數組為什麼需要初始化大小?如果是多維數組,不指定列寬可以嗎?
計算題
- 求123.6875的二進位、八進位、十六進位表達式。
- 求\((11011.101)_2\)二進位小數轉換為十進位。
- a=5,b=8,試手算a&b,a|b,a^b,a<<1, b>>1
- 若a=12,試手算~a
- 若a為8位二進位,試著寫出將a的高四位取反,第四位不變的運算表達式
- int a = 15,試求a+int.MaxValue的值
編程題
- 請學習指針內容以及C#unsafe調試,試著不使用索引進行數組的讀取。
- 將字元串」15」轉成整數?
- 使用運算符重載,計算向量的加減和點乘(內積)
Reference
《C# in Depth》—— Jon Skeet
《電腦組成原理》——唐朔飛
About Me
作 者:WarrenRyan
出 處://www.cnblogs.com/WarrenRyan/
本文對應影片:BiliBili(待重錄)
關於作者:熱愛數學、熱愛機器學習,喜歡彈鋼琴的不知名小菜雞。
版權聲明:本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文鏈接。若需商用,則必須聯繫作者獲得授權。
特此聲明:所有評論和私信都會在第一時間回復。也歡迎園子的大大們指正錯誤,共同進步。或者直接私信我
聲援部落客:如果您覺得文章對您有幫助,可以點擊文章右下角【推薦】一下。您的鼓勵是作者堅持原創和持續寫作的最大動力!
部落客一些其他平台:
微信公眾號:寤言不寐
BiBili——小陳的學習記錄
Github——StevenEco
BiBili——記錄學習的小陳(電腦考研紀實)
掘金——小陳的學習記錄
知乎——小陳的學習記錄
聯繫方式
社交媒體聯繫二維碼:



