做音頻軟體開發10+年,包括語音通訊、語音識別、音樂播放等,大部分時間在做語音通訊。做語音通訊中又大部分時間在做VoIP語音處理。語音通訊是全雙工的,既要把自己的語音發送出去讓對方聽到,又要接收對方的語音讓自己聽到。發送又可叫做上行或者TX,接收又可叫做下行或者RX。之前寫了好多關於VoIP語音處理方面的文章,本文想結合框圖對相關知識做一個梳理。先綜述發送和接收方向的處理,再具體到每個知識點上。講到某個知識點,如曾經寫過相關的文章,就給出鏈接,如沒有寫過,等以後寫到時再補上鏈接。由於一些知識點在發送和接收兩個方向上是相關的,就放在一起講。
VoIP語音處理在發送和接收方向上的軟體框圖如下圖1和2:
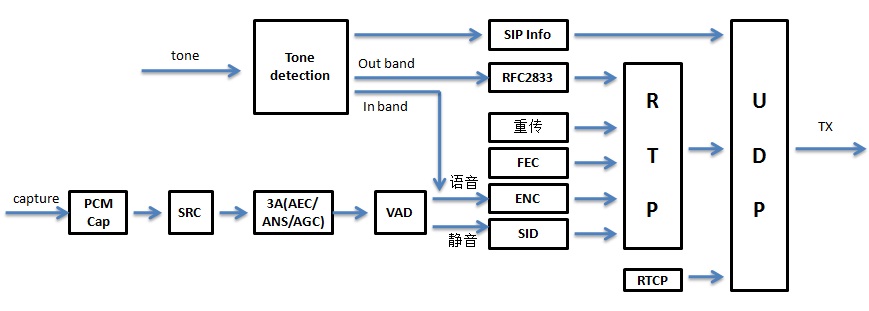
圖1:發送方向處理流程框圖

圖2:接收方向處理流程框圖
在發送方向,從codec晶片採集到語音PCM數據後如有需要首先做重取樣(SRC),然後做前處理(回聲消除/AEC,雜訊抑制/ANS,增益控制/AGC,俗稱3A演算法)。後面就是做靜音檢測(VAD),如是語音就編碼(ENC),得到碼流並通過RTP/UDP發送給對方。如是靜音,就生成靜音包(SID) 也通過RTP/UDP發送給對方。在弱網情況下為了提高語音品質,就需要前向糾錯(FEC)、重傳等手段把相應的包發給對方。一些場景下需要把tone音(比如 DTMF tone)發送給對方,先要做tone音檢測(tone detection),然後按照SIP協議協商好的方式把tone音發送給對方。在發送RTP包的同時,也需要發送RTCP包來監控RTP包的收發情況等。
在接收方向,先收到對方發來的RTP/RTCP包。對於RTP包,如是正常包或者重傳包,直接放進jitter buffer(後面簡稱JB),這些包有可能被JB收下,也有可能被JB丟棄(比如包來的太遲或者重複包等)。如是FEC包,先做FEC解碼,再把解碼後的RTP包放進JB。同樣也有可能被JB收下或者丟棄。從JB里取出的如是語音包,就需要做解碼(DEC),根據網路狀況還可能要做丟包補償(PLC)、加速、減速、融合等處理。如取出的是靜音包(SID),則需要產生舒適雜訊(CNG)。如取出的是RFC2833包,就要產生相應的tone音(tone generation)。處理好後還要經過雜訊抑制(ANS)/增益控制(AGC)等處理,有可能的話還需要做重取樣(SRC)。最後把PCM數據送給codec晶片播放出去。
下面看具體的知識點:
1,語音的採集和播放:主要是從codec晶片採集到語音得到PCM數據和把PCM數據發送給codec晶片播放出來,不同的OS下有不同的方法。曾經寫過相關的文章,具體見《音頻的採集和播放》。
2,重取樣(SRC):就是把PCM的取樣率從一種變成另一種。在音頻處理中經常遇到取樣率不一樣的情況,需要做重取樣。曾經寫過怎麼對開源的重取樣演算法做評估,從而覺定用哪個,具體見《音頻開源程式碼中重取樣演算法的評估與選擇》。也寫過基於sinc方法的重取樣的原理和實現,具體見《基於sinc的音頻重取樣(一):原理》和《基於sinc的音頻重取樣(二):實現》。
3,前後處理的3A演算法:包括AEC/ANS/AGC等,他們是保證音質的關鍵因素之一。AEC是回聲消除,曾寫過AEC的基本原理和調試經驗(算下來我前前後後共四次調試過AEC),具體見《音頻處理之回聲消除及調試經驗》。ANS是雜訊抑制,2021年我花了不少時間在ANS上,從學習原理到看懂程式碼以及自己寫演算法程式碼。也寫了三個演算法的系列,分別是webRTC里的ANS和基於MCRA-OMLSA的ANS以及基於混合模型的ANS,具體見《webRTC中語音降噪模組ANS細節詳解(一)》、《 webRTC中語音降噪模組ANS細節詳解(二)》 、《webRTC中語音降噪模組ANS細節詳解(三)》、《 webRTC中語音降噪模組ANS細節詳解(四) 和 《基於MCRA-OMLSA的語音降噪(一):原理 》 、《基於MCRA-OMLSA的語音降噪(二):實現》、《基於MCRA-OMLSA的語音降噪(三):實現(續)》 以及《語音降噪論文「A Hybrid Approach for Speech Enhancement Using MoG Model and Neural Network Phoneme Classifier」的研讀 》、《基於混合模型的語音降噪實踐 》、《基於混合模型的語音降噪效果提升 》。AGC是自動增益控制,是控制語音訊號的增益在預設的合理區間之內,避免忽大忽小。目前這一塊還沒有相關的文章。
4,靜音檢測(VAD)和舒適雜訊生成(CNG):VAD會根據預先設定的threshold判斷是語音還是靜音。如果是語音就要去做編碼,如果是靜音則不需要編碼,僅僅是周期性的(比如200毫秒)發送一個帶能量大小的SID包給對方,對方收到這個包後去做CNG產生舒適雜訊,讓通話者感覺更舒服些。用VAD/CNG主要有兩個好處:一是節省了頻寬,通常語音通話中一方只佔50%左右的講話時間,其餘時間處於靜音狀態。在靜音時發送SID包,SID包比正常語音包小不少,發的頻率也低好多,這樣就節省了頻寬。二是降功耗,在靜音期間不需要編解碼了,通常編解碼的運算load比VAD/CNG高,這樣就降低了功耗。目前還沒有這方面的文章。
5,編解碼(ENC/DEC):常用的codec有ITU-T的G系列(g.711/g.722/g.726/g.729等)、3GPP的AMR-WB/AMR-NB/EVS以及互聯網廠商提出的iLBC/OPUS等。曾在文章《音頻的編解碼及其優化方法和經驗 》中寫過基於reference code去優化CPU load。
6,前向糾錯(FEC)和重傳:在弱網情況下需要保證音質,就得有一些補救措施,FEC和重傳就是其中兩種。FEC是在發送端編碼生成冗餘包,在接收端解碼從而生成那些丟掉的包。重傳是把對方需要的包發給對方。曾在文章《語音通訊中提高音質的方法 》講過這兩種方法,當然也講了其他的提高音質的方法。
7,RTP/RTCP/UDP:這三個都是網路協議,RTP是網路傳輸協議,RTCP是網路傳輸控制協議,UDP是數據報協議。在文章《語音傳輸之RTP/RTCP/UDP及軟體實現關鍵點》里講了它們的軟體實現關鍵點。
8,tone音:一些場景下會用到tone音,比如DTMF tone,包括tone音檢測(tone detection)和tone音生成(tone generation)。文章《談談語音通訊中的各種tone 》詳細的講了tone音以及發送給對方的三種方式。
9,jitter buffer(JB):把從網路收到的RTP包放進JB里緩一下,同時把亂序的包排好序等,有利於播放的流暢。文章《音頻傳輸之Jitter Buffer設計與實現 》寫了我曾經設計過的一個JB。
10,netEQ:是webRTC里提出的概念,把JB、解碼和解碼後的PCM處理(加減速播放、丟包補償(PLC)等)放在一起形成一個模組。也就是接收方框圖中畫虛線的部分。我曾經寫過一個系列詳細介紹了netEQ,大家對這個系列的評價還是不錯的,具體見《webRTC中音頻相關的netEQ(一):概述 》 《webRTC中音頻相關的netEQ(二):數據結構 》 《webRTC中音頻相關的netEQ(三):存取包和延時計算 》《 webRTC中音頻相關的netEQ(四):控制命令決策 》和 《webRTC中音頻相關的netEQ(五):DSP處理 》。
以上就是VoIP語音處理中的主要知識點。需要說明的是一個VoIP語音處理解決方案中以上模組並不全是必須的,而是根據需求選用的。當然有些是必須的,比如編解碼。上面的框圖只是把涉及到的知識點列出來,框圖畫的可能不是十分的準確。有些模組(比如提高音質的一些方法)我沒用過,就沒畫出來。寫這篇文章的目的只有一個,就是讓大家知道VoIP語音處理的流程和其中有哪些知識點。


