Flink sql 之 兩階段聚合與 TwoStageOptimizedAggregateRule(源碼分析)
本文源碼基於flink1.14
上一篇文章分析了《flink的minibatch微批處理》的源碼
乘熱打鐵分析一下兩階段聚合的源碼,因為使用兩階段要先開啟minibatch,至於為什麼後面會分析到
兩階段聚合的原理,還是簡單提一下
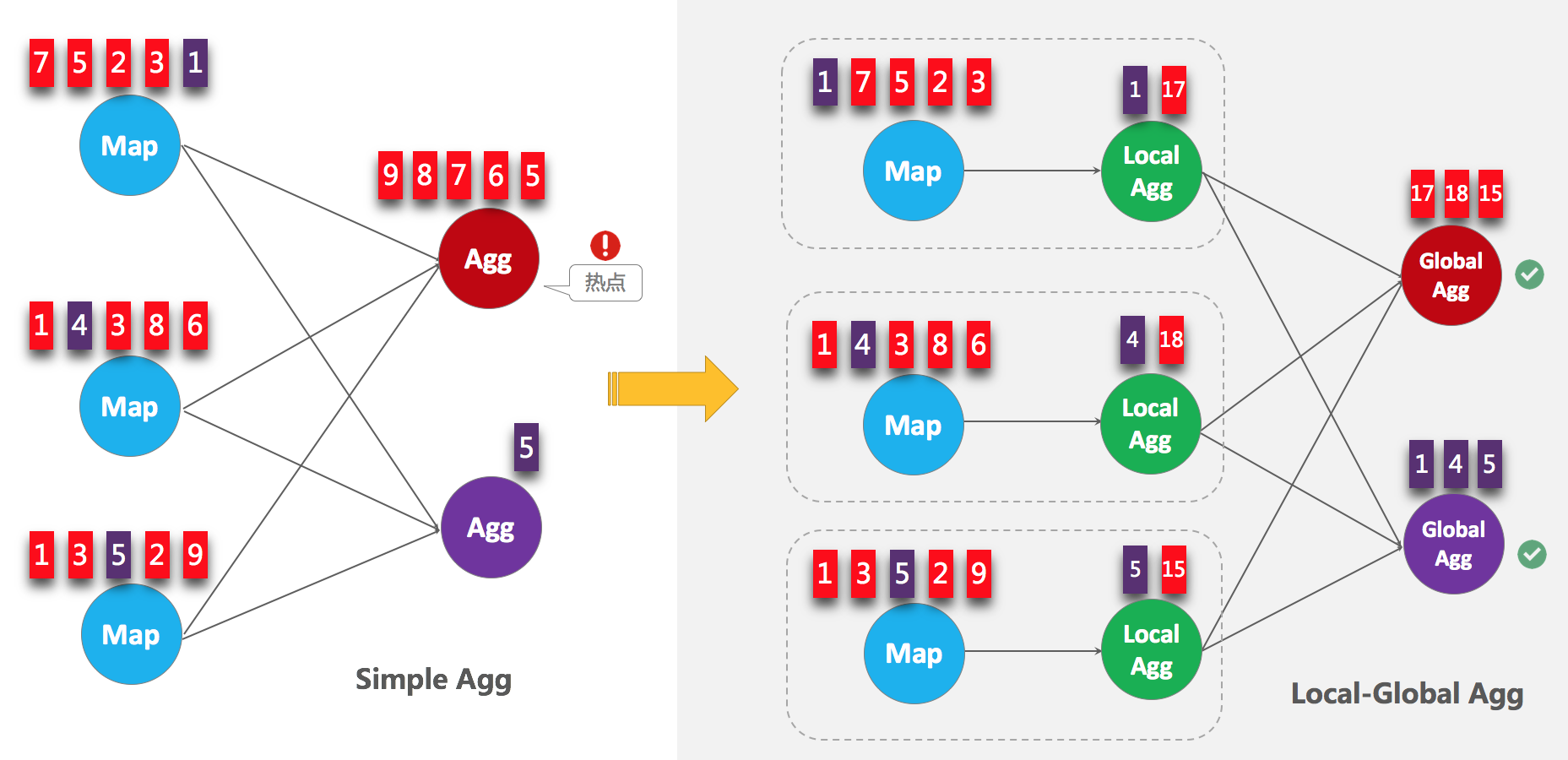
如下圖,當聚合發生熱點的時候,可以在聚合前,先進行一個本地的聚合,先減小數據量,後接正常的數據交換以後聚合,來達到一個解熱點的目的,
先來看下兩階段聚合的Calcite優化rule

看下什麼情況會匹配上

並且在onmatch方法中會判斷開啟了minibatch,以及二階段聚合的時候會調用
來看下具體邏輯match方法
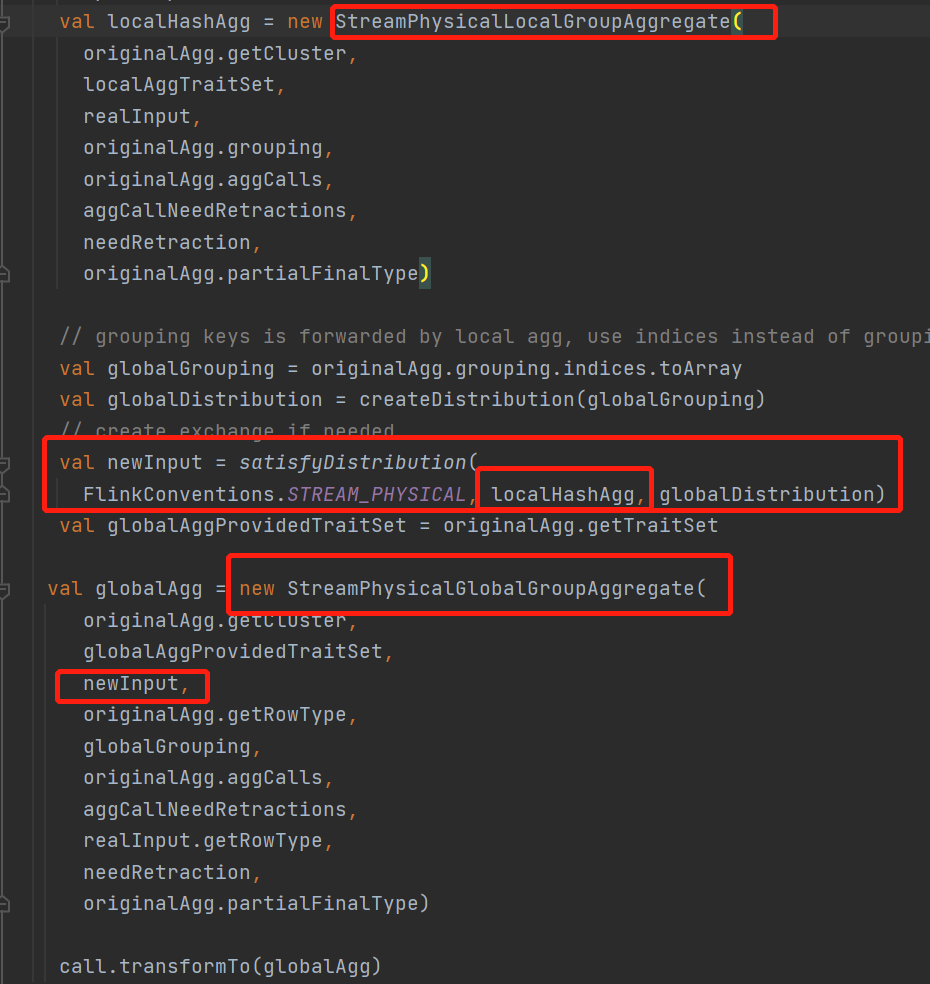
整個兩階段聚合會將原來的一個StreamPhysicalGroupAggregate物理節點,轉換成一個
StreamPhysicalLocalGroupAggregate本地聚合節點 + StreamPhysicalGlobalGroupAggregate聚合節點
來看下這個新添加的StreamPhysicalLocalGroupAggregate本地聚合運算元的計算邏輯是什麼樣子的
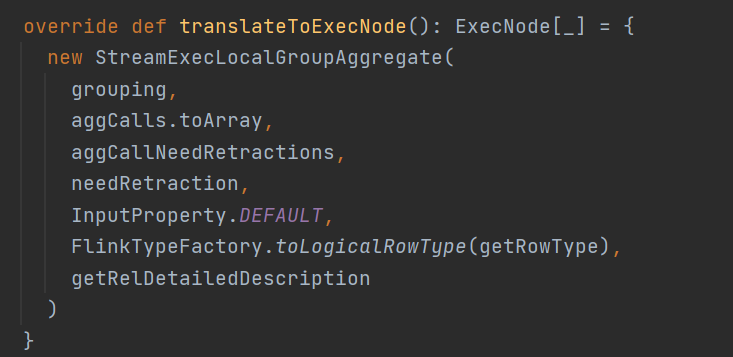
StreamExecLocalGroupAggragate就是StreamPhysicalLocalGroupAggregate本地聚合具體的ExecNode節點了
來看下具體的operator
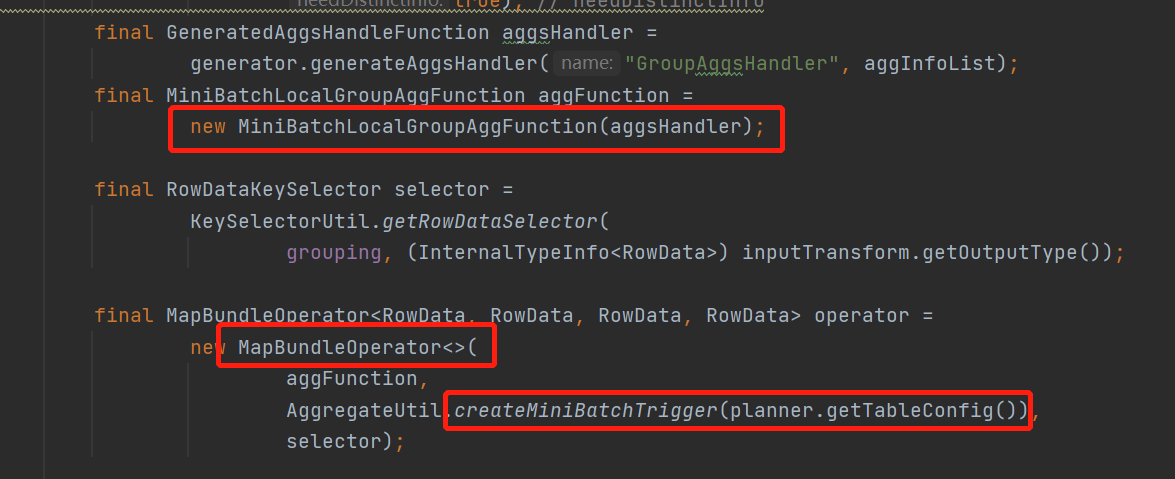
看到這裡是不是看到了熟悉的 MapBundleOperator ,如果看過上一篇minibatch優化的就知道,兩階段提交也是使用的這個有界operator作為抽象
在了解一下這個MapBundleOperator
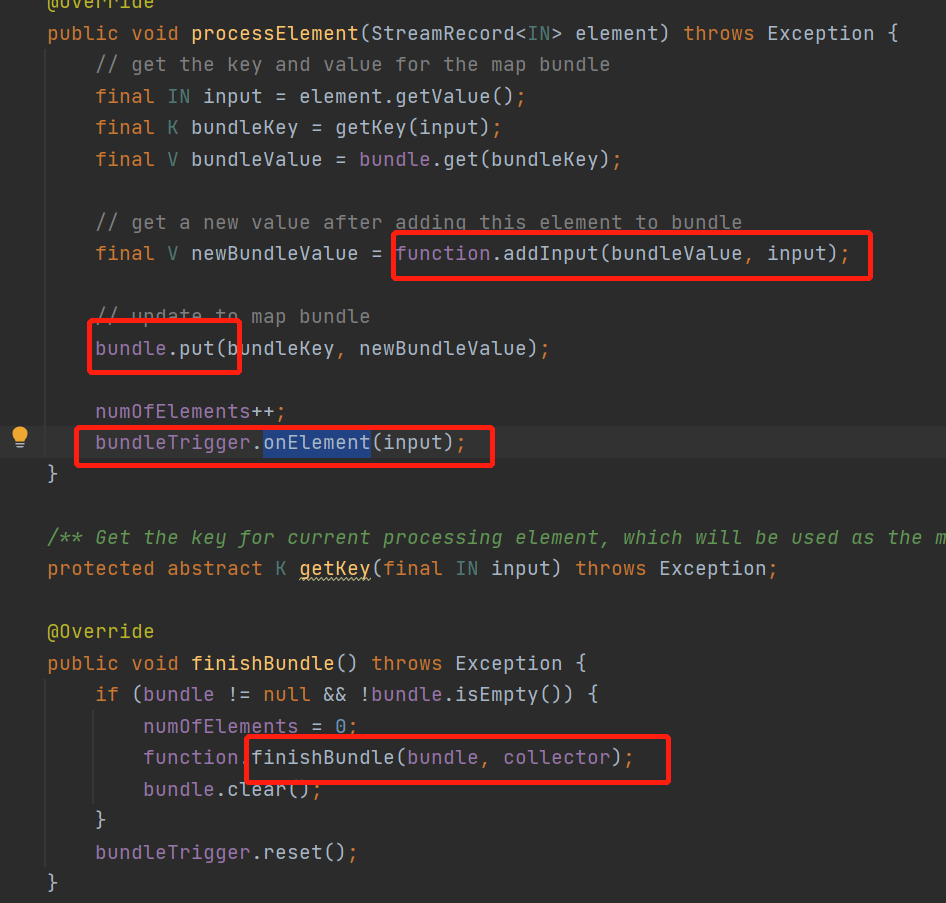
就是每來一條數據,都會調用傳入的fun的addInput方法
然後把每個key的結果put保存在一個本地變數,就是個map<Rowdata,Rowdata>裡面
然後調用自己的trigger觸發器,當這條數據可以觸發觸發器就會調用finishBundle
這裡說到觸發器,回到初始化mapBundle的時候通過createMiniBatchTrigger創建的一個minibatch的觸發器,看看具體邏輯
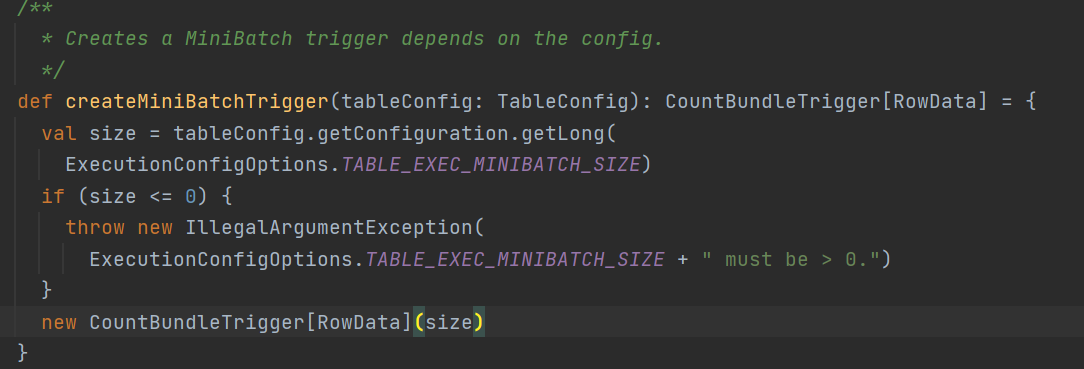
其實就是一個普通的count觸發器,觸發條件就是直接使用的minibatch配置的size參數, 所以這裡知道了為什麼兩階段提交要先開minibatch了
先看下每來一條數據會觸發的addInput方法,在來看看攢一個批次後觸發的finishBundle
minibatch會包裝成一個MiniBatchLocalGroupAggFunction這個funtion的addInput來看看
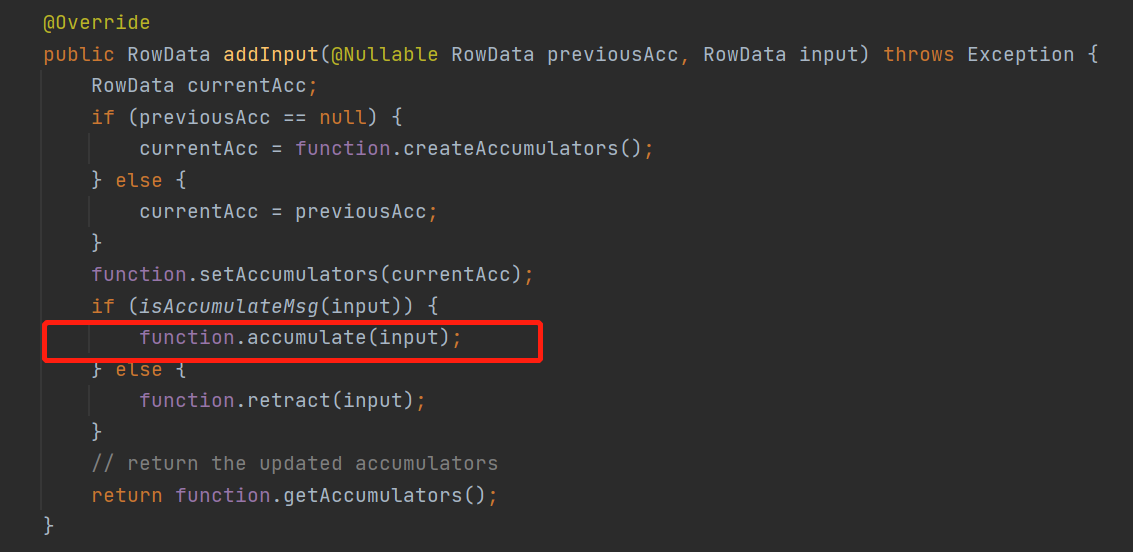
就是來一條數據直接調用聚合函數的accumulate直接計算結果了,雖然計算結果但是還沒有往下游發送
來看下當攢一批後,集體是怎麼往下游發送的 finishBundle 方法
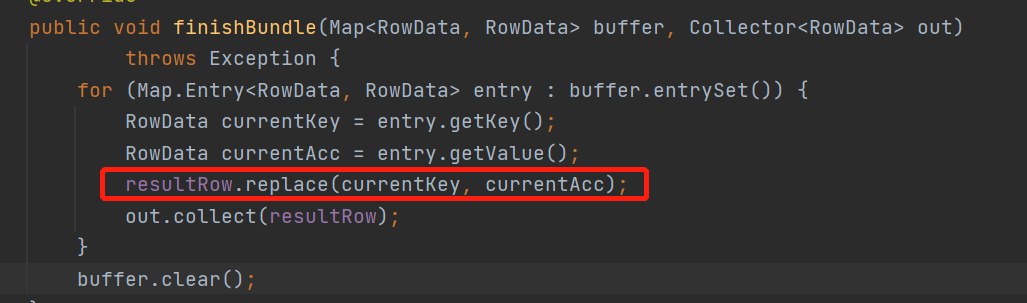
結果都已經計算好了,攢一個批次還能幹嘛,就是把當前的計算結果往下游發送唄
那整個二次聚合的優化就講完了
總結一下
sql會將agg拆成 localminiagg + agg
先在本地聚合localConbine一遍,再往下游發送
下游就正常聚合,優化了熱點的問題

