JAX-MD在近鄰表的計算中,使用了什麼奇技淫巧?(一)
- 2022 年 1 月 4 日
- 筆記
- Molecular Dynamics
技術背景
JAX-MD是一款基於JAX的純Python高性能分子動力學模擬軟體,應該說在純Python的軟體中很難超越其性能。當然,比一部分直接基於CUDA的分子動力學模擬軟體性能還是有些差距。而在計算過程中,近鄰表的計算是佔了較大時間和空間比重的模組,我們通過源碼分析,看看JAX-MD中使用了哪些的奇技淫巧,感興趣的童鞋可以直接參考JAX-MD下的partition模組。
Verlet List和Cell List的使用
關於Verlet List,其實更多的是使用在動力學模擬的過程中,而Cell List則更常用於近鄰表的計算優化,也就是我們通俗所說的打格點演算法。可以參考下圖的一個示例,將一個體系中的多個原子,劃分到一個空間中均勻分布的格子裡面:
如此一來,我們只需要設定好這些格子的長度,比如長度直接定為判斷近鄰的cutoff數值,這樣我們在計算的過程中,就只需要對當前原子所在格子的周邊的格子進行檢索即可,大大縮減了計算複雜度。原本不加格子的近鄰表計算複雜度為\(O(N^2)\),而加了格子之後近鄰表計算的複雜度為\(O(Nlog N)\),其中\(N\)為體系的原子數目。在前面的一篇部落格中,我們大致的使用Python中的Numba寫了一個簡單的打格點演算法程式碼(不包含近鄰表的檢索),感興趣的童鞋可以參考一下。
當然,這些都是比較高層次的演算法,我們可以閱讀JAX-MD中的程式碼實現,來看看他是怎麼一步一步去實現這個演算法的。
計算格點長度
在JAX-MD中,周期性盒子的大小是給定的,但是格點大小不是一個固定值,而是先給定一個格點大小的下界,然後計算格點數量並取了一個floor的操作,再根據格點的數量計算得到每個格點的最終大小:
cells_per_side = onp.floor(box_size / minimum_cell_size)
cell_size = box_size / cells_per_side
cells_per_side = onp.array(cells_per_side, dtype=i32)
cell_count = reduce(mul, flat_cells_per_side, 1)
這裡使用的floor操作確保了最終的cell_size一定是大於給定的minimum_cell_size的。這裡還有一行程式碼用於計算總的格點數,這裡用了一個非常優雅的實現,是functools中的reduce方法,其實實現的內容就將數組中的元素按照給定的函數逐兩個的疊加計算,可以參考詳細說明:
def reduce(function, sequence, initial=_initial_missing):
"""
reduce(function, sequence[, initial]) -> value
Apply a function of two arguments cumulatively to the items of a sequence,
from left to right, so as to reduce the sequence to a single value.
For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates
((((1+2)+3)+4)+5). If initial is present, it is placed before the items
of the sequence in the calculation, and serves as a default when the
sequence is empty.
"""
或者用一個更加貼合演算法中示例的程式碼來說明下更簡單些:
In [1]: from operator import mul
In [2]: from functools import reduce
In [3]: reduce(mul,[4,5,6],1)
Out[3]: 120
In [4]: reduce(mul,[4,5,6],2)
Out[4]: 240
最後一個輸入給定的initial值是一個基礎值。
哈希乘子
在JAX-MD的源碼中稱之為哈希常量,我們可以先簡單的描述下這個乘子的作用場景:在前面介紹的打格點演算法中,每一個原子會獲得1個格點的編號,如果是在三維空間,這個編號中會包含3個元素,分別對應\((x,y,z)\)三個軸方向的格點編號。但是如果我們需要確認「2個不同的原子是否在同一個格子中?目標原子在具體哪一個格子中?指定的格子中有幾個原子?」這些問題的話,我們最好是將一個三維的格點轉換成一維的格點排列。比如一個\(10\times10\times10\)的網格,其中\((0,0,0)\)號網格就會被編碼成第0個網格,第\((0,1,0)\)號網格會被編碼成第10個網格,第\((0,0,1)\)號網格會被編碼成第100個網格。換句話說,要實現這個三維到一維的轉化,每一個維度都會帶有不同大小的權重,這個權重值,就是我們所謂的哈希乘子:
one = jnp.array([[1]], dtype=i32)
cells_per_side = jnp.concatenate((one, cells_per_side[:, :-1]), axis=1)
hash_constant = jnp.array(jnp.cumprod(cells_per_side), dtype=i32)
也可以用一個更加淺顯的示例來展示下這個計算的過程:
In [5]: import numpy as np
In [6]: one = np.array([[1]],dtype=np.int32)
In [7]: cells_per_side = np.array([[10,20,30]])
In [8]: cells_per_side = np.concatenate((one,cells_per_side[:,:-1]),axis=1)
In [9]: cells_per_side
Out[9]: array([[ 1, 10, 20]])
In [10]: np.cumprod(cells_per_side)
Out[10]: array([ 1, 10, 200])
先是完成了一個維度替換,再是累計做乘法,最後再放到具體編號列表中一點乘,不同的原子如果在同一個格點中,就會得到相同的計算結果。還有一點說明是,在將3維的格點轉化成1維格點之後,如果需要再轉化回3維的格點,只需要一個reshape即可。
格點原子數統計
獲得每個原子對應的格點編號是容易的,通過廣播機制直接一步就可以計算出來。而上一步中我們提到了哈希乘子,在這裡就要派上用場,得到每個原子所在的格點編號,然後做一個段求和的操作,就可以得到每個格點中對應的原子數目:
particle_index = jnp.array(position / cell_size, dtype=i32)
particle_hash = jnp.sum(particle_index * hash_multipliers, axis=1)
filling = ops.segment_sum(jnp.ones_like(particle_hash),
particle_hash,
cell_count)
關於這裡面使用到的段求和操作,可以參考如下圖片(圖片來自於參考鏈接2)所表示的演算法過程:
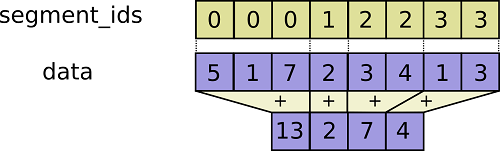
在得到每個格點中的原子數之後,還有一個很重要的意義是我們可以以其中最大的原子數作為計算近鄰表的一個padding長度的基準。我們很難在python之中去高效的處理循環,儘可能是直接使用numpy和jax所集成的操作,而這些操作的對象都要求維度上的統一,因此我們需要一個padding的操作,保障每一個原子的近鄰表size一致。當然,這裡面多出來的位置可以用非合法值進行填充,常用的有-1等。
獲取近鄰格點編號
因為在近鄰檢索過程中,我們只檢索當前原子的近鄰格點中的原子。對於一維的體系,只需要檢索2個周邊格點即可,對於2維的體系,需要檢索周邊的8個格點,而對於3維的體系,需要檢索周邊的26個格點。在JAX-MD中使用了ndindex的迭代器來生成近鄰格點的id:
for dindex in onp.ndindex(*([3] * dimension)):
yield onp.array(dindex, dtype=i32) - 1
其實實現的效果與itertools.product是一致的:
In [11]: from itertools import product
In [12]: product(range(3),repeat=3)
Out[12]: <itertools.product at 0x7f79a3035fc0>
In [13]: list(product(range(3),repeat=3))
Out[13]:
[(0, 0, 0),
(0, 0, 1),
(0, 0, 2),
(0, 1, 0),
(0, 1, 1),
(0, 1, 2),
(0, 2, 0),
(0, 2, 1),
(0, 2, 2),
(1, 0, 0),
(1, 0, 1),
(1, 0, 2),
(1, 1, 0),
(1, 1, 1),
(1, 1, 2),
(1, 2, 0),
(1, 2, 1),
(1, 2, 2),
(2, 0, 0),
(2, 0, 1),
(2, 0, 2),
(2, 1, 0),
(2, 1, 1),
(2, 1, 2),
(2, 2, 0),
(2, 2, 1),
(2, 2, 2)]
當然,這個得到的id列表還需要進一步的操作,比如全部-1,就可以將中心的格點id變成\((0,0,0)\),考慮近鄰元素時,需要忽略自身跟自身的近鄰,再有就是,轉化成一維之後的格點id,還需要多乘一個上面提到過的哈希乘子。
GPU的循環鏈表
因為GPU上的計算模式的特殊性,加上JAX的封裝,我們很難去構造一些真實意義的數據結構,比如鏈表、棧和隊列等等。那麼當我們需要類似的功能的時候,就只能用矩陣移位的方法:
def _shift_array(arr: Array, dindex: Array) -> Array:
if len(dindex) == 2:
dx, dy = dindex
dz = 0
elif len(dindex) == 3:
dx, dy, dz = dindex
if dx < 0:
arr = jnp.concatenate((arr[1:], arr[:1]))
elif dx > 0:
arr = jnp.concatenate((arr[-1:], arr[:-1]))
if dy < 0:
arr = jnp.concatenate((arr[:, 1:], arr[:, :1]), axis=1)
elif dy > 0:
arr = jnp.concatenate((arr[:, -1:], arr[:, :-1]), axis=1)
if dz < 0:
arr = jnp.concatenate((arr[:, :, 1:], arr[:, :, :1]), axis=2)
elif dz > 0:
arr = jnp.concatenate((arr[:, :, -1:], arr[:, :, :-1]), axis=2)
return arr
比如正常的一個循環鏈表,應該是有一個指針來讀取下一個元素的,只是最後一個元素又指向了第一個元素,因此形成了一個如下圖(圖片來自於參考鏈接3)所示的循環鏈表:

那麼在JAX中去實現循環鏈表時,我們只能將頭部元素轉接到尾部去,也就是這裡JAX-MD所使用的方法。
排序
由於在前面的計算中,3維的格點編號被轉換成了1維,因此我們就可以根據格點編號對坐標等參量同步進行排序:
indices = jnp.array(position / cell_size, dtype=i32)
hashes = jnp.sum(indices * hash_multipliers, axis=1)
sort_map = jnp.argsort(hashes)
sorted_position = position[sort_map]
sorted_hash = hashes[sort_map]
sorted_id = particle_id[sort_map]
這裡JAX-MD是直接用了argsort的功能,排序後只返回對應排序的一個映射id,這樣就可以把排序關係同步到其他的參數如坐標中。再獲得到排序之後,再初始化一個格點數*格點容量的cell_position和cell_id,再逐一將排序之後的position和id填進去,得到一個可能為稀疏的cell_list:
sorted_cell_id = jnp.mod(lax.iota(i32, N), cell_capacity)
sorted_cell_id = sorted_hash * cell_capacity + sorted_cell_id
cell_position = cell_position.at[sorted_cell_id].set(sorted_position)
cell_id = cell_id.at[sorted_cell_id].set(sorted_id)
在Jax中是不支援原位操作的,需要使用Jax的object.at[id].set(value)這樣的功能模組來實現。而在JAX-MD中大量的使用了一個叫lax.iota的操作,其實這個操作就相當於numpy.arange,但是不清楚為什麼非得用這個函數,於是測試了下幾個方案的速度:
In [1]: from jax import lax
In [2]: from jax import numpy as jnp
In [3]: import numpy as np
In [4]: %timeit np.arange(1000000,dtype=np.int32)
377 µs ± 2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [5]: %timeit jnp.arange(1000000,dtype=jnp.int32)
118 µs ± 53.9 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [6]: %timeit lax.iota(jnp.int32,1000000)
52.6 µs ± 402 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
結果我們發現lax.iota這個操作的速度確實是快於使用jnp.arange的,只是看起來還不太習慣。
構建Neighbor List
在上一步完成了格點近鄰表的構建之後,開始正式搜索每個原子的近鄰表。那麼在定義原子的近鄰原子時,我們就需要給定一個cutoff值,當原子距離小於這個值時,我們就認為這一對原子是近鄰原子。但是這裡就有一個關聯性的問題,我們通過打格點的方法來搜索近鄰表,那麼格點大小的選取,是否要與cutoff的值相關呢?在JAX-MD中,直接選取了cutoff的值作為格點大小(實際上是cutoff加上一個鬆弛小量dr_threshold,在鬆弛範圍內不改變近鄰關係,所以不影響這部分的演算法複雜性推斷):
cell_size = cutoff
關於Cell Size選取的思考
至於為什麼這樣選取,我們可以做一個簡單的思考。如果\(cutoff<cell\_size\),那麼就意味著,我們同樣需要在3維空間搜索27個格子中的近鄰原子,只是每個格子中的平均原子數更多了,但是這其實相當於做了更多的無用功,所以我們選擇cell_size時最好不要超過cutoff的值。而如果是\(cutoff>cell\_size\)的情況,相對而言就比較複雜,比如當\(cutoff=2cell\_size\)時,相當於要在空間中搜索125個盒子,當然,每個盒子中的平均原子數也隨之下降了,這就看具體的取捨了。在演算法中我們知道,對於一個有序的數組的搜索複雜性是\(O(log\ n)\)的。那麼一個比較粗糙的估計下的結果就是(如下圖所示),格點長度取半長的cutoff可以達到一個相對更低的複雜性,不過一般還是得具體情況具體分析,至少我們現在已經知道,JAX-MD是直接取了cutoff的長度作為格點長度。

上圖用於估計複雜度的程式碼如下所示:
import matplotlib.pyplot as plt
import numpy as np
N = 300
l = 1.
c = 0.3
s = np.arange(0.1,1,0.1)*c
y = N*np.log2((np.ceil(c/s)*2+1)**3*N*s**3/l**3)
plt.figure()
plt.title('Estimation of complexity')
plt.xlabel('cell_size/cutoff')
plt.ylabel('complexity')
plt.plot(s/c,y,'o',color='black')
plt.plot(s/c,y,color='red')
plt.show()
Neighbor List的初始化
在JAX-MD的源碼中又學到了一個擴維的小技巧,可以使用array[None,:]的形式來替代numpy.expand_dims,輸出是完全一樣的,關鍵是速度要快上10倍:
In [1]: import numpy as np
In [2]: a=np.arange(10)
In [3]: a[None,:]
Out[3]: array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
In [4]: np.expand_dims(a,axis=0)
Out[4]: array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
In [5]: %timeit b=a[None,:]
164 ns ± 0.774 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
In [6]: %timeit b=np.expand_dims(a,axis=0)
2.43 µs ± 9.05 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
一般機器學習框架中都會經常用到擴維這個函數,目前並不確定這個運算元加速是否適用於所有的框架,至少在numpy和jax裡面我們發現應該是適用的。
總結概要
本文是第一篇關於JAX-MD的源碼學習的文章,主要關注點在於JAX-MD中對於近鄰表的檢索和優化。本文的主要內容是其中構建CellList的部分,通過打格點的方法可以大大降低近鄰表搜索演算法的複雜度,在GPU計算的過程中更是可以極大的降低顯示記憶體的佔用,從而允許我們去運行更大規模的體系。
版權聲明
本文首發鏈接為://www.cnblogs.com/dechinphy/p/jaxnb1.html
作者ID:DechinPhy
更多原著文章請參考://www.cnblogs.com/dechinphy/
打賞專用鏈接://www.cnblogs.com/dechinphy/gallery/image/379634.html
騰訊雲專欄同步://cloud.tencent.com/developer/column/91958
參考鏈接
- //github.com/google/jax-md
- //www.w3cschool.cn/tensorflow_python/tensorflow_python-ua7w2jip.html
- //data.biancheng.net/view/7.html


