【計理01組03號】Java基礎知識
- 2022 年 1 月 2 日
- 筆記
- 【計理01組】Java語言
簡單數據類型的取值範圍
byte:8 位,1 位元組,最大數據存儲量是 255,數值範圍是 −128 ~ 127。short:16 位,2 位元組,最大數據存儲量是 65536,數值範圍是 −32768 ~ 32767。int:32 位,4 位元組,最大數據存儲容量是 2^32 – 1,數值範圍是 −2^31 ~ 2^31 – 1。long:64 位,8 位元組,最大數據存儲容量是 2^64 – 1 數值範圍是 −2^63 ~ 2^63 – 1。float:32 位,4 位元組,數值範圍是 3.4e−45 ~ 1.4e38,直接賦值時必須在數字後加上f或F。double:64 位,8 位元組,數值範圍在 4.9e−324 ~ 1.8e308,賦值時可以加 d 或 D,也可以不加。boolean:只有true和false兩個取值。char:16 位,2 位元組,存儲 Unicode 碼,用單引號'賦值。
字元型
關係運算符和邏輯運算符
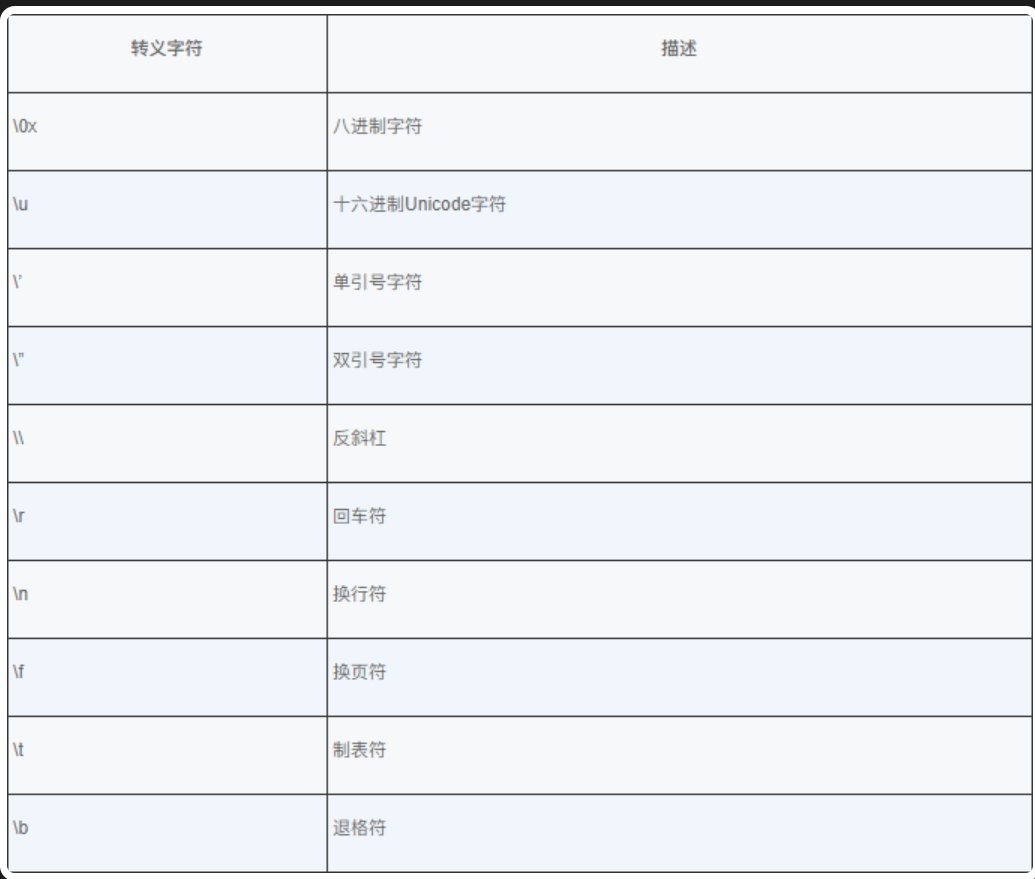
在 Java 程式設計中,關係運算符(Relational Operator)和邏輯運算符(Logical Operator)顯得十分重要。關係運算符定義值與值之間的相互關係,邏輯(logical)運算符定義可以用真值和假值連接在一起的方法。
關係運算符
在數學運算中有大於、小於、等於、不等於關係,在程式中可以使用關係運算符來表示上述關係。下圖中列出了 Java 中的關係運算符,通過這些關係運算符會產生一個結果,這個結果是一個布爾值,即 true 或 false。在 Java 中,任何類型的數據,都可以用 == 比較是不是相等,用 != 比較是否不相等,只有數字才能比較大小,關係運算的結果可以直接賦予布爾變數。
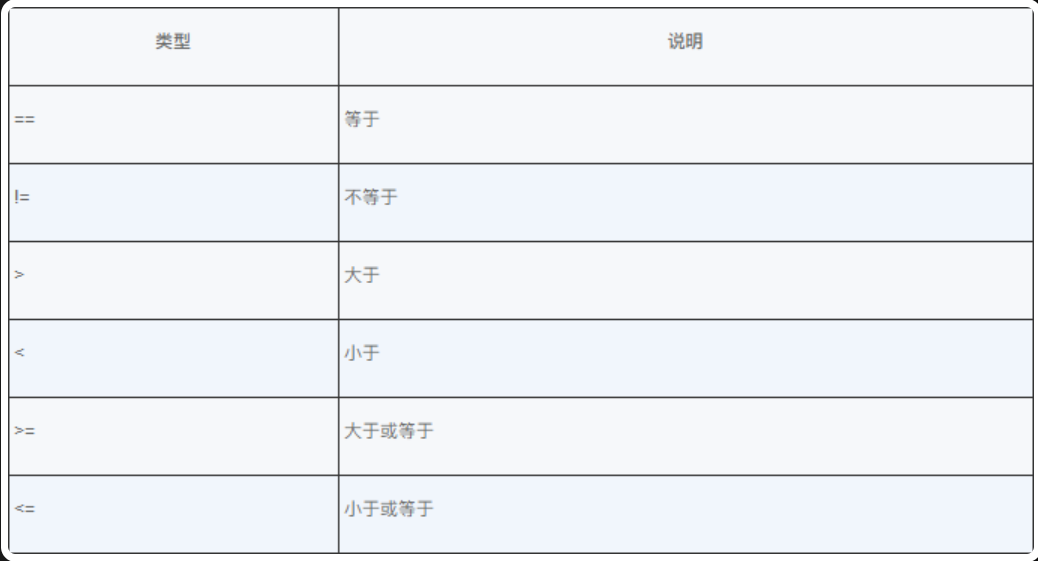
邏輯運算符
布爾邏輯運算符是最常見的邏輯運算符,用於對布爾型操作數進行布爾邏輯運算,Java 中的布爾邏輯運算符如下圖示。

邏輯運算符與關係運算符運算後得到的結果一樣,都是布爾類型的值。在 Java 程式設計中,&& 和 || 布爾邏輯運算符不總是對運算符右邊的表達式求值,如果使用邏輯與 & 和邏輯或 |,則表達式的結果可以由運算符左邊的操作數單獨決定。通過下表,同學們可以了解常用邏輯運算符 &&、||、! 運算後的結果。

位邏輯運算符
在 Java 程式設計中,使用位邏輯運算符來操作二進位數據。讀者必須注意,位邏輯運算符只能操作二進位數據。如果用在其他進位的數據中,需要先將其他進位的數據轉換成二進位數據。位邏輯運算符(Bitwise Operator)可以直接操作整數類型的位,這些整數類型包括 long、int、short、char 和 byte。Java 語言中位邏輯運算符的具體說明如下表所示。

因為位邏輯運算符能夠在整數範圍內對位操作,所以這樣的操作對一個值產生什麼效果是很重要的。具體來說,了解 Java 如何存儲整數值並且如何表示負數是非常有用的。下表中演示了操作數 A 和操作數 B 按位邏輯運算的結果。

移位運算符把數字的位向右或向左移動,產生一個新的數字。Java 的右移運算符有兩個,分別是 >> 和 >>>。
>>運算符:把第一個操作數的二進位碼右移指定位數後,將左邊空出來的位以原來的符號位填充。即,如果第一個操作數原來是正數,則左邊補 0;如果第一個操作數是負數,則左邊補 1。>>>:把第一個操作數的二進位碼右移指定位數後,將左邊空出來的位以 0 填充。
條件運算符
條件運算符是一種特殊的運算符,也被稱為三目運算符。它與前面所講的運算符有很大不同,Java 中提供了一個三目運算符,其實這跟後面講解的 if 語句有相似之處。條件運算符的目的是決定把哪個值賦給前面的變數。在 Java 語言中使用條件運算符的語法格式如下所示。
變數 = (布爾表達式) ? 為 true 時賦予的值 : 為 false 時賦予的值;賦值運算符
注意:在 Java 中可以對賦值運算符進行擴展,其中最為常用的有如下擴展操作。
另外,在後面的學習中我們會接觸到
equals()方法,此方法和賦值運算符==的功能類似。要想理解兩者之間的區別,我們需要從變數說起。Java 中的變數分為兩類,一類是值類型,它存儲的是變數真正的值,比如基礎數據類型,值類型的變數存儲在記憶體的棧中;另一類是引用類型,它存儲的是對象的地址,與該地址對應的記憶體空間中存儲的才是我們需要的內容,比如字元串和對象等,引用類型的變數存儲在記憶體中的堆中。賦值運算符==比較的是值類型的變數,如果比較兩個引用類型的變數,比較的就是它們的引用地址。equals()方法只能用來比較引用類型的變數,也就是比較引用的內容。
==運算符比較的是左右兩邊的變數是否來自同一個記憶體地址。如果比較的是值類型(基礎數據類型,如int和char之類)的變數,由於值類型的變數存儲在棧裡面,當兩個變數有同一個值時,其實它們只用到同一個記憶體空間,所以比較的結果是true。
eqluals()方法是 Object 類的基本方法之一,所以每個類都有自己的equals()方法,功能是比較兩個對象是否是同一個,通俗的理解就是比較這兩個對象的內容是否一樣。
賦值運算符是等號 =,Java 中的賦值運算與其他電腦語言中的賦值運算一樣,起到賦值的作用。在 Java 中使用賦值運算符的格式如下所示。
+=:對於x+=y,等效於x=x+y。-=:對於x-=y,等效於x=x−y。*=:對於x*=y,等效於x=x*y。/=:對於x/=y,等效於x=x/y。%=:對於x%=y,等效於x=x%y。&=:對於x&=y,等效於x=x&y。|=:對於x|=y,等效於x=x|y。^=:對於x^=y,等效於x=x^y。<<=:對於x<<=y,等效於x=x<<y。>>=:對於x>>=y,等效於x=x>>y。>>>=:對於x>>>=y,等效於x=x>>>y。
其中,變數 var 的類型必須與表達式 expression 的類型一致。 賦值運算符有一個有趣的屬性,它允許我們對一連串變數進行賦值。請看下面的程式碼。 在上述程式碼中,使用一條賦值語句將變數 x、y、z 都賦值為 100。這是由於 = 運算符表示右邊表達式的值,因此 z = 100 的值是 100,然後該值被賦給 y,並依次被賦給 x。使用字元串賦值是給一組變數賦予同一個值的簡單辦法。在賦值時類型必須匹配,否則將會出現編譯錯誤。
運算符的優先順序
數學中的運算都是從左向右運算的,在 Java 中除了單目運算符、賦值運算符和三目運算符外,大部分運算符也是從左向右結合的。單目運算符、賦值運算符和三目運算符是從右向左結合的,也就是說,它們是從右向左運算的。乘法和加法是兩個可結合的運算,也就是說,這兩個運算符左右兩邊的操作符可以互換位置而不會影響結果。
運算符有不同的優先順序,所謂優先順序,就是在表達式運算中的運算順序。下表中列出了包括分隔符在內的所有運算符的優先順序,上一行中的運算符總是優先於下一行的。
字元串的初始化
在 Java 程式中,使用關鍵字 new 來創建 String 實例,具體格式如下所示。
String a = new String();
上面這行程式碼創建了一個名為 a 的 String 類的實例,並把它賦給變數,但它此時是一個空的字元串。接下來就為這個字元串複製,賦值程式碼如下所示。
a = "I am a person.";
在 Java 程式中,我們將上述兩句程式碼合併,就可以產生一種簡單的字元串表示方法。
String s = new String("I am a person.");
除了上面的表示方法,還有表示字元串的如下一種形式。
String s = ("I am a person.");String 類
在 Java 程式中可以使用 String 類來操作字元串,在該類中有許多方法可以供程式設計師使用。
索引
在 Java 程式中,通過索引函數 charAt() 可以返回字元串中指定索引的位置。讀者需要注意的是,這裡的索引數字從零開始,使用格式如下所示。
public char charAt(int index)
追加字元串
追加字元串函數 concat() 的功能是在字元串的末尾添加字元串,追加字元串是一種比較常用的操作,具體語法格式如下所示。
public String concat(String s)StringBuffer 類
StringBuffer 類是 Java 中另一個重要的操作字元串的類,當需要對字元串進行大量的修改時,使用 StringBuffer 類是最佳選擇。接下來將詳細講解 StringBuffer 類中的常用方法。
追加字元
在 StringBuffer 類中實現追加字元功能的方法的語法格式如下所示。
public synchronized StringBuffer append(char b)
插入字元
前面的字元追加方法總是在字元串的末尾添加內容,倘若需要在字元串中添加內容,就需要使用方法 insert(),語法格式如下所示。
public synchronized StringBuffer insert(int offset, String s)
上述語法格式的含義是:將第 2 個參數的內容添加到第 1 個參數指定的位置,換句話說,第 1 個參數表示要插入的起始位置,第 2 個參數是需要插入的內容,可以是包括 String 在內的任何數據類型。
顛倒字元
字元顛倒方法能夠將字元顛倒,例如 “我是誰”,顛倒過來就變成 “誰是我”,很多時候需要顛倒字元。字元顛倒方法 reverse() 的語法格式如下所示。
public synchronized StringBuffer reverse()自動類型轉換
如果系統支援把某種基本類型的值直接賦給另一種基本類型的變數,這種方式被稱為自動類型轉換。當把一個取值範圍小的數值或變數直接賦給另一個取值範圍大的變數時,系統可以進行自動類型轉換。
Java 中所有數值型變數之間可以進行類型轉換,取值範圍小的可以向取值範圍大的進行自動類型轉換。就好比有兩瓶水,當把小瓶里的水倒入大瓶時不會有任何問題。Java 支援自動類型轉換的類型如下圖所示。

在上圖所示的類型轉換圖中,箭頭左邊的數值可以轉換為箭頭右邊的數值。當對任何基本類型的值和字元串進行連接運算時,基本類型的值將自動轉換為字元串類型,儘管字元串類型不再是基本類型,而是引用類型。因此,如果希望把基本類型的值轉換為對應的字元串,可以對基本類型的值和一個空字元串進行連接。
Java 11 新特性:新增的 String 函數
在新發布的 JDK 11 中,新增了 6 個字元串函數。下面介紹各個字元串函數。
-
String.repeat(int)函數
String.repeat(int)的功能是根據 int 參數的值重複 String。 -
String.lines()函數
String.lines()的功能是返回從該字元串中提取的行,由行終止符分隔。行要麼是零個或多個字元的序列,後面跟著一個行結束符;要麼是一個或多個字元的序列,後面是字元串的結尾。一行不包括行終止符。在 Java 程式中,使用函數String.lines()返回的流包含該字元串中出現的行的順序。 -
String.strip()函數
String.strip()的功能是返回一個字元串,該字元串的值為該字元串,其中所有前導和尾部空白均被刪除。如果該 String 對象表示空字元串,或者如果該字元串中的所有程式碼點是空白的,則返回一個空字元串。否則,返回該字元串的子字元串,該字元串從第一個不是空白的程式碼點開始,直到最後一個不是空白的程式碼點,並包括最後一個不是空白的程式碼點。在 Java 程式中,開發者可以使用此函數去除字元串開頭和結尾的空白。 -
String.stripLeading()函數
String.stripLeading()的功能是返回一個字元串,其值為該字元串,並且刪除字元串前面的所有空白。如果該 String 對象表示空字元串,或者如果該字元串中的所有程式碼點是空白的,則返回空字元串。 -
String.stripTrailing()函數
String.stripTrailing()的功能是返回一個字元串,其值為該字元串,並且刪除字元串後面的所有空白。如果該 String 對象表示空字元串,或者如果該字元串中的所有程式碼點是空白的,則返回空字元串。 -
String.isBlank()函數
String.isBlank()的功能是判斷字元串是否為空或僅包含空格。如果字元串為空或僅包含空格則返回true;否則,返回false。
定義常量時的注意事項
在 Java 語言中,主要利用 final 關鍵字(在 Java 類中靈活使用 static 關鍵字)來進行 Java 常量的定義。當常量被設定後,一般情況下就不允許再進行更改。在定義常量時,需要注意如下 3 點。
- 在定義 Java 常量的時候,就需要對常量進行初始化。也就是說,必須在聲明常量時就對它進行初始化。跟局部變數或類成員變數不同,在定義一個常量的時候,進行初始化之後,在應用程式中就無法再次對這個常量進行賦值。如果強行賦值的話,編譯器會彈出錯誤資訊,並拒絕接受這一新值。
- 需要注意
final關鍵字的使用範圍。final關鍵字不僅可以用來修飾基本數據類型的常量,還可以用來修飾對象的引用或方法,比如數組就是對象引用。為此,可以使用final關鍵字定義一個常量的數組。這是 Java 語言中的一大特色。一個數組對象一旦被final關鍵字設置為常量數組之後,它就只能恆定地指向一個數組對象,無法將其指向另一個對象,也無法更改數組中的值。 - 需要注意常量的命名規則。在定義變數或常量時,不同的語言,都有自己的一套編碼規則。這主要是為了提高程式碼的共享程度與易讀性。在 Java 中定義常量時,也有自己的一套規則。比如在給常量取名時,一般都用大寫字母。在 Java 語言中,區分大小寫字母。之所以採用大寫字母,主要是為了跟變數進行區分。雖然說給常量取名時採用小寫字母,也不會有語法上的錯誤,但是為了在編寫程式碼時能夠一目了然地判斷變數與常量,最好還是能夠將常量設置為大寫字母。另外,在常量中,往往通過下劃線來分隔不同的字元,而不像對象名或類名那樣,通過首字母大寫的方式來進行分隔。這些規則雖然不是強制性的,但是為了提高程式碼的友好性,方便開發團隊中的其他成員閱讀,這些規則還是需要遵守的。 總之,Java 開發人員需要注意,被定義為
final的常量需要採用大寫字母命名,並且中間最好使用下劃線作為分隔符來連接多個單詞。定義為final的數據不論是常量、對象引用還是數組,在主函數中都不可以改變,否則會被編輯器拒絕並提示錯誤資訊。
char 類型中單引號的意義
char 類型使用單引號括起來,而字元串使用雙引號括起來。關於 String 類的具體用法以及對應的各個方法,讀者可以參考查閱 API 文檔中的資訊。其實 Java 語言中的單引號、雙引號和反斜線都有特殊的用途,如果在一個字元串中包含這些特殊字元,應該使用轉義字元。
例如希望在 Java 程式中表示絕對路徑 c:\daima,但這種寫法得不到我們期望的結果,因為 Java 會把反斜線當成轉義字元,所以應該寫成 c:\\daima 的形式。只有同時寫兩個反斜線,Java 才會把第一個反斜線當成轉義字元,與後一個反斜線組成真正的反斜線。
正無窮和負無窮的問題
Java 還提供了 3 個特殊的浮點數值——正無窮大、負無窮大和非數,用於表示溢出和出錯。
例如,使用一個正浮點數除以 0 將得到正無窮大,使用一個負浮點數除以 0 將得到負無窮大,用 0.0 除以 0.0 或對一個負數開方將得到一個非數。
正無窮大通過 Double 或 Float 的 POSITIVE_INFINITY 表示,負無窮大通過 Double 或 Float 的 NEGATIVE_INFINITY 表示,非數通過 Double 或 Float 的 NaN 表示。
請注意,只有用浮點數除以 0 才可以得到正無窮大或負無窮大,因為 Java 語言會自動把和浮點數運算的 0(整數)當成 0.0(浮點數)來處理。如果用一個整數除以 0,則會拋出 「ArithmeticException:/by zero」(除以 0 異常)。
移位運算符的限制
Java 移位運算符只能用於整型,不能用於浮點型。也就是說,>>、>>>和<<這 3 個移位運算符並不適合所有的數值類型,它們只適合對 byte、short、char、int 和 long 等整型數進行運算。除此之外,進行移位運算時還有如下規則:
- 對於低於
int類型(如byte、short和char)的操作數來說,總是先自動類型轉換為int類型後再移位。 - 對於
int類型的整數移位,例如a >> b,當b > 32時,系統先用b對 32 求余(因為int類型只有 32 位),得到的結果才是真正移位的位數。例如,a >> 33和a >> l的結果完全一樣,而a >> 32的結果和a相同。 - 對
long類型的整數移位時,例如a >> b,當b > 64時,總是先用b對 64 求余(因為long類型是 64 位),得到的結果才是真正移位的位數。 當進行位移運算時,只要被移位的二進位碼沒有發生有效位的數字丟失現象(對於正數而言,通常指被移出的位全部都是 0),不難發現左移 n 位就相當於乘以 2n,右移則相當於除以 2n。這裡存在一個問題:左移時,左邊捨棄的位通常是無效的,但右移時,右邊捨棄的位常常是有效的,因此通過左移和右移更容易看出這種運行結果,並且位移運算不會改變操作數本身,只是得到一個新的運算結果,原來的操作數本身是不會改變的。
if 語句
if 語句由保留字 if、條件語句和位於後面的語句組成。條件語句通常是一個布爾表達式,結果為 true 和 false。如果條件為 true,則執行語句並繼續處理其後的下一條語句;如果條件為 false,則跳過語句並繼續處理緊跟整個 if 語句的下一條語句。例如在下圖中,當條件(condition)為 true 時,執行 statement1 語句;當條件為 false 時,執行 statement2 語句。
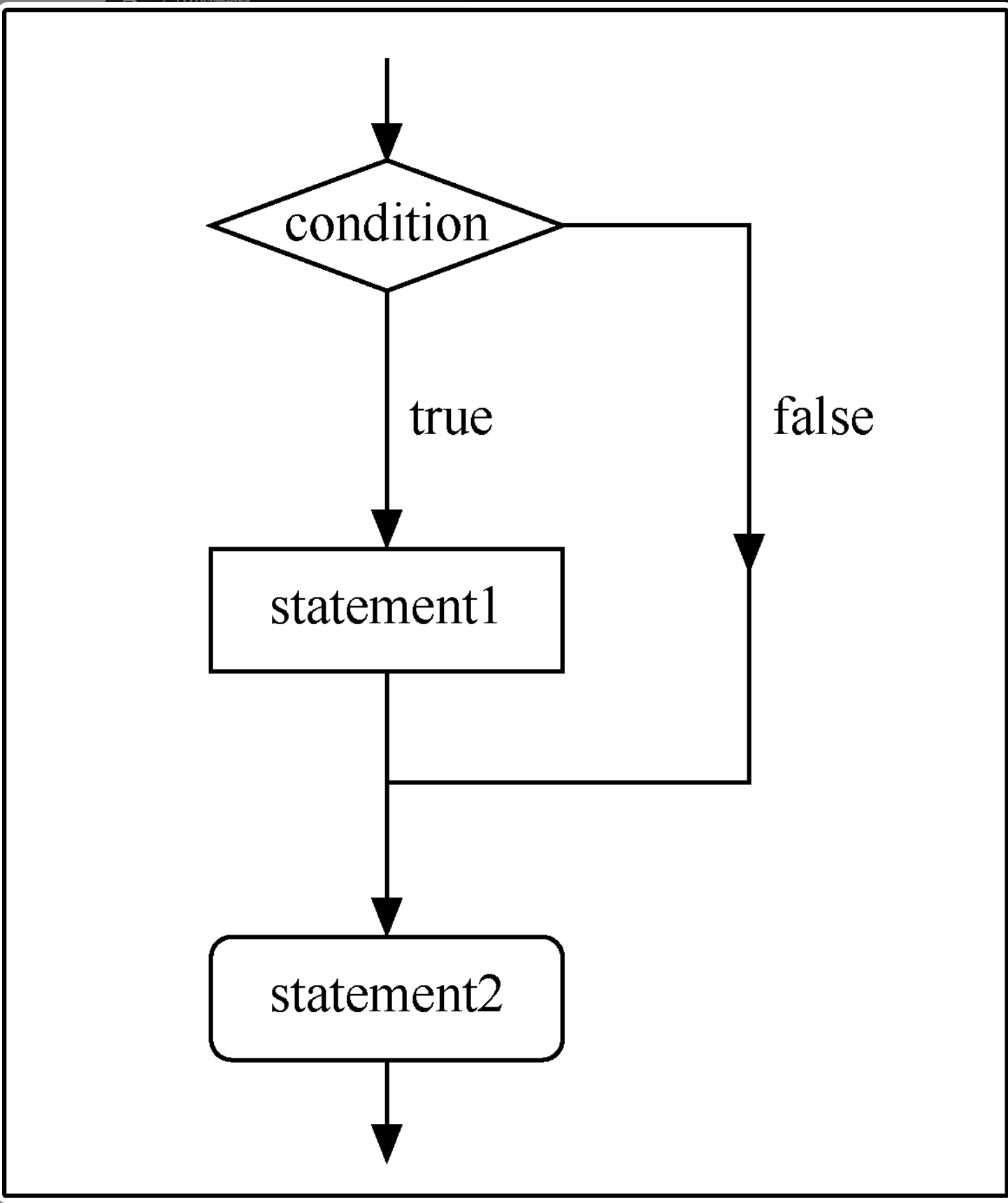
if 語句的語法格式如下所示。
if (條件表達式)
語法說明:if 是該語句中的關鍵字,後續緊跟一對小括弧,這對小括弧任何時候都不能省略。小括弧的內部是具體的條件,語法上要求條件表達式的結果為 boolean 類型。後續為功能程式碼,也就是當條件成立時執行的程式碼。在書寫程式時,一般為了直觀地表達包含關係,功能程式碼需要縮進。
例如下面的演示程式碼。
int a = 10; //定義 int 型變數 a 的初始值是 10
if (a >= 0)
System.out.println("a 是正數"); //a 大於或等於 0 時的輸出內容
if ( a % 2 == 0)
System.out.println("a 是偶數"); //a 能夠整除 2 時的輸出內容
在上述演示程式碼中,第一個條件判斷變數 a 的值是否大於或等於零,如果該條件成立,輸出 “a 是正數”;第二個條件判斷變數 a 是否為偶數,如果成立,也輸出 “a 是偶數”。
再看下面的程式碼的執行流程。
int m = 20; //定義 int 型變數 m 的初始值是 20
if ( m > 20) //如果變數 m 的值大於 20
m += 20; //將 m 的值加上 20
System.out.println(m); //輸出 m 的值
按照前面的語法格式說明,只有 m += 20 這行程式碼屬於功能程式碼,而後續的輸出語句和前面的條件形成順序結構,所以該程式執行以後輸出的結果為 20。當條件成立時,如果需要執行的語句有多句,可以使用語句塊來進行表述,具體語法格式如下所示。
if (條件表達式) {
功能程式碼塊;
}
這種語法格式中,使用功能程式碼塊來代替前面的功能程式碼,這樣可以在程式碼塊內部書寫任意多行程式碼,而且也使整個程式的邏輯比較清楚,所以在實際的程式碼編寫中推薦使用這種方式。
if語句的延伸
在第一種 if 語句中,大家可以看到,並不對條件不符合的內容進行處理。因為這是不允許的,所以 Java 引入了另外一種條件語句 if…else,基本語法格式如下所示。
if (condition) // 設置條件 condition
statement1; // 如果條件 condition 成立,執行 statement1 這一行程式碼
else // 如果條件 condition 不成立
statement2; // 執行 statement2 這一行程式碼
if…else 語句的執行流程如下圖所示。

有多個條件判斷的 if 語句
if 語句實際上是一種功能十分強大的條件語句,可以對多種情況進行判斷。可以判斷多個條件的語句是 if-else-if,語法格式如下所示。
if (condition1)
statement1;
else if (condition2)
statement2;
else
statement3;
上述語法格式的執行流程如下。
- 判斷第一個條件 condition1,當為
true時執行 statement1,並且程式運行結束。當 condition1 為false時,繼續執行後面的程式碼。 - 當 condition1 為
false時,接下來先判斷 condition2 的值,當 condition2 為true時執行 statement2,並且程式運行結束。當 condition2 為false時,執行後面的 statement3。也就是說,當前面的兩個條件 condition1 和 condition2 都不成立(為false)時,才會執行 statement3。
if-else-if 的執行流程如下圖所示。

在 Java 語句中,if…else 可以嵌套無限次。可以說,只要遇到值為 true 的條件,就會執行對應的語句,然後結束整個程式的運行。
switch 語句的形式
switch 語句能夠對條件進行多次判斷,具體語法格式如下所示。
switch(整數選擇因子) {
case 整數值 1 : 語句; break;
case 整數值 2 : 語句; break;
case 整數值 3 : 語句; break;
case 整數值 4 : 語句; break;
case 整數值 5 : 語句; break;
//..
case 整數值 n : 語句; break;
default: 語句;
}
其中,整數選擇因子 必須是 byte、short、int 和 char 類型,每個整數必須是與 整數選擇因子 類型兼容的一個常量,而且不能重複。整數選擇因子 是一個特殊的表達式,能產生整數。switch 能將整數選擇因子的結果與每個整數做比較。發現相符的,就執行對應的語句(簡單或複合語句)。沒有發現相符的,就執行 default 語句。
在上面的定義中,大家會注意到每個 case 均以一個 break 結尾。這樣可使執行流程跳轉至 switch 主體的末尾。這是構建 switch 語句的一種傳統方式,但 break 是可選的。若省略 break,將會繼續執行後面的 case 語句的程式碼,直到遇到 break 為止。儘管通常不想出現這種情況,但對有經驗的程式設計師來說,也許能夠善加利用。注意,最後的 default 語句沒有 break,因為執行流程已到達 break 的跳轉目的地。當然,如果考慮到編程風格方面的原因,完全可以在 default 語句的末尾放置一個 break,儘管它並沒有任何實際用處。
switch 語句的執行流程如下圖所示。
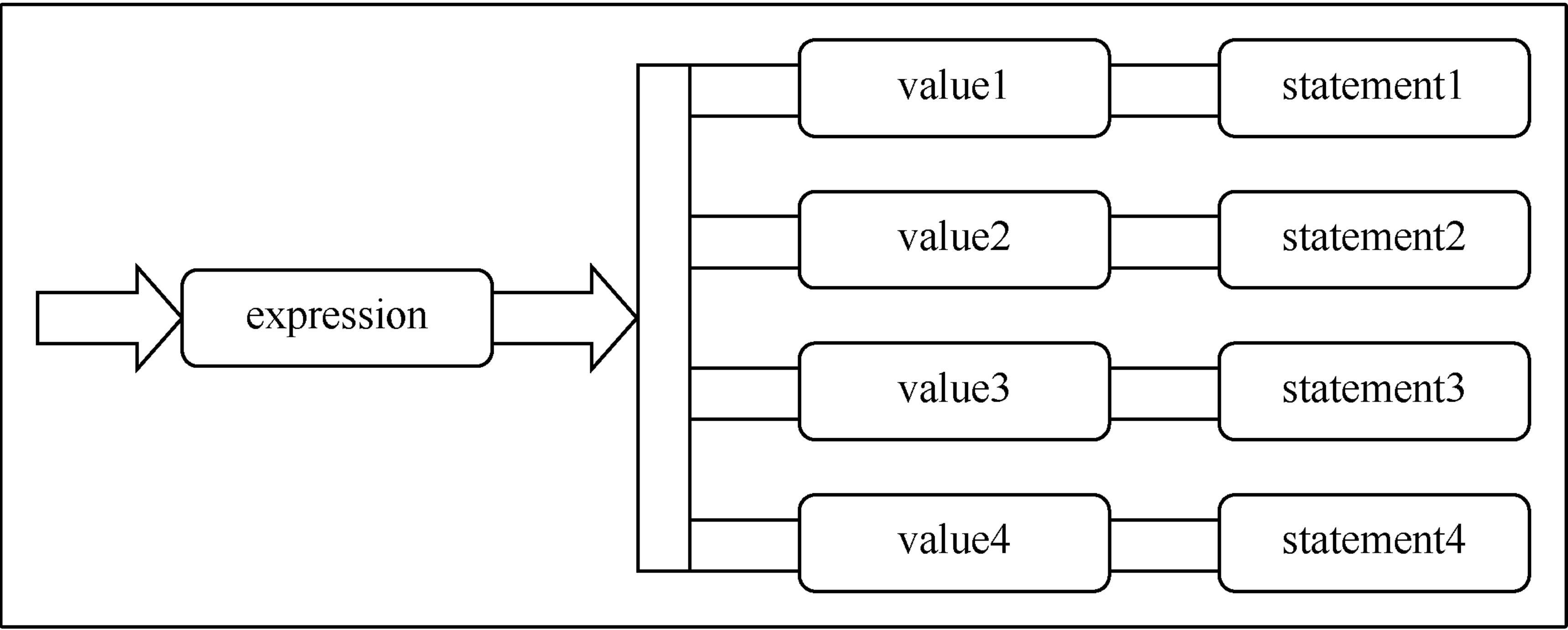
無 break 的情況
多次出現了 break 語句,其實在 switch 語句中可以沒有 break 這個關鍵字。一般來說,當 switch 遇到一些 break 關鍵字時,程式會自動結束 switch 語句。如果把 switch 語句中的 break 關鍵字去掉了,程式將繼續向下執行,直到整個 switch 語句結束。
case 語句後沒有執行語句
當 case 語句後沒有執行語句時,即使條件為 true,也會忽略掉不執行。
default 可以不在結尾
通過前面的學習,很多初學者可能會誤認為 default 一定位於 switch 的結尾。其實不然,它可以位於 switch 中的任意位置
for 循環
在 Java 程式中,for 語句是最為常見的一種循環語句,for 循環是一種功能強大且形式靈活的結構,下面對它進行講解。
書寫格式
for 語句是一種十分常見的循環語句,語法格式如下所示。
for(initialization;condition;iteration){
statements;
}
從上面的語法格式可以看出,for 循環語句由如下 4 部分組成。
initialization:初始化操作,通常用於初始化循環變數。condition:循環條件,是一個布爾表達式,用於判斷循環是否持續。iteration:循環迭代器,用於迭代循環變數。statements:要循環執行的語句(可以有多條語句)。
上述每一部分間都用分號分隔,如果只有一條語句需要重複執行,大括弧就沒有必要有了。
在 Java 程式中,for 循環的執行過程如下。
- 當循環啟動時,先執行初始化操作,通常這裡會設置一個用於主導循環的循環變數。重要的是要理解初始化表達式僅被執行一次。
- 計算循環條件。
condition必須是一個布爾表達式,它通常會對循環變數與目標值做比較。如果這個布爾表達式為真,則繼續執行循環體statements;如果為假,則循環終止。 - 執行循環迭代器,這部分通常是用於遞增或遞減循環變數的一個表達式,以便接下來重新計算循環條件,判斷是否繼續循環。
在 Java 程式里,除了 for 語句以外,while 語句也是十分常見的循環語句,其特點和 for 語句十分類似。while 循環語句的最大特點,就是不知道循環多少次。在 Java 程式中,當不知道某個語句塊或語句需要重複運行多少次時,通過使用 while 語句可以實現這樣的循環功能。當循環條件為真時,while 語句重複執行一條語句或某個語句塊。while 語句的基本使用格式如下所示。
while (condition) // condition 表達式是循環條件,其結果是一個布爾值
{
statements;
}
while 語句的執行流程如下圖所示。
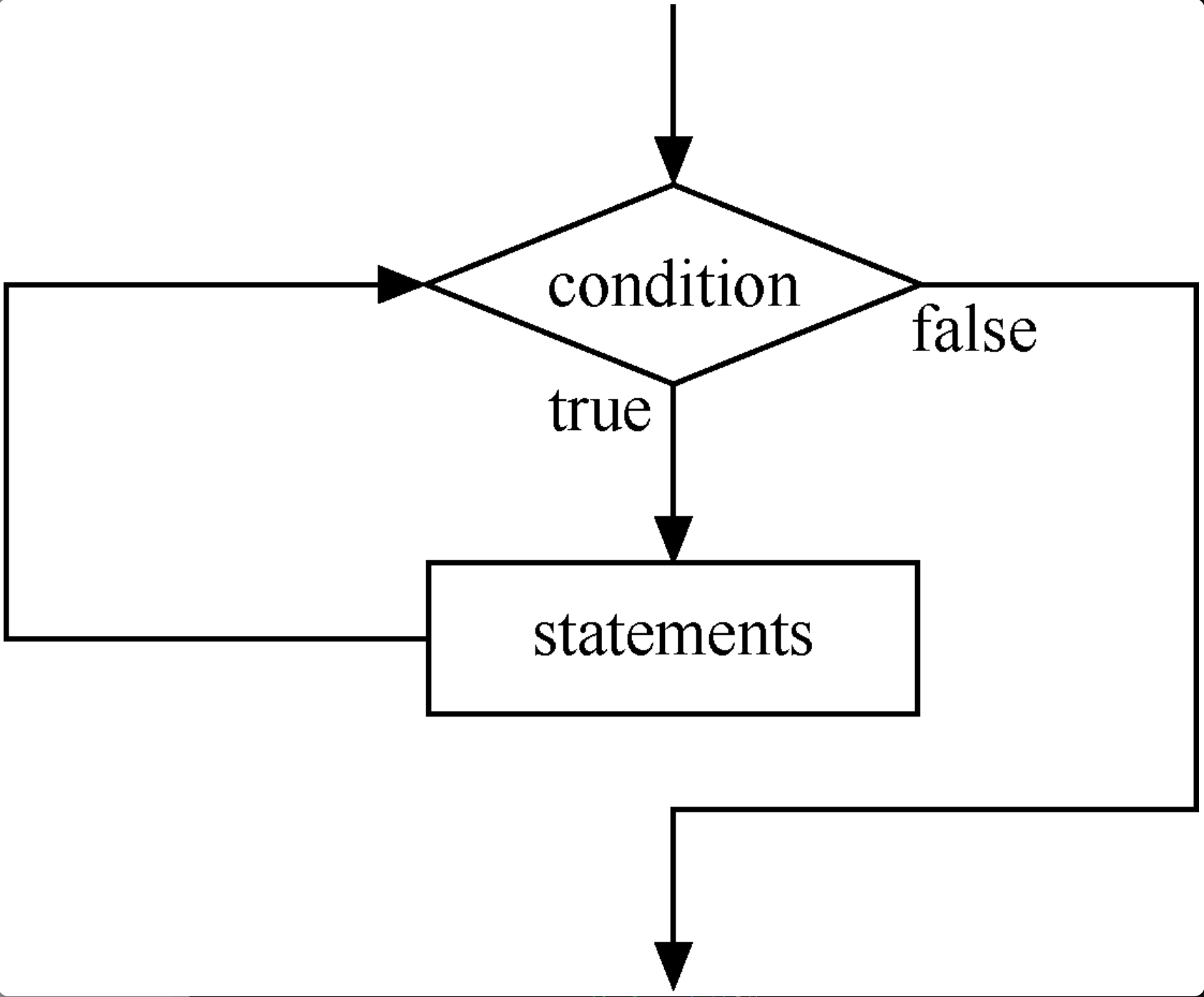
許多軟體程式中會存在這種情況:當條件為假時也需要執行語句一次。初學者可以這麼理解,在執行一次循環後才測試循環的條件表達式。在 Java 語言中,我們可以使用 do…while 語句實現上述循環。
書寫格式
在 Java 語言中,do…while 循環語句的特點是至少會執行一次循環體,因為條件表達式在循環的最後。do…while 循環語句的使用格式如下所示。
do{
statements;
}
while (condition) // condition 表示循環條件,是一個布爾值
在上述格式中,do…while 語句先執行 statement 一次,然後判斷循環條件。如果結果為真,循環繼續;如果為假,循環結束。
do…while 循環語句的執行流程如下圖所示。
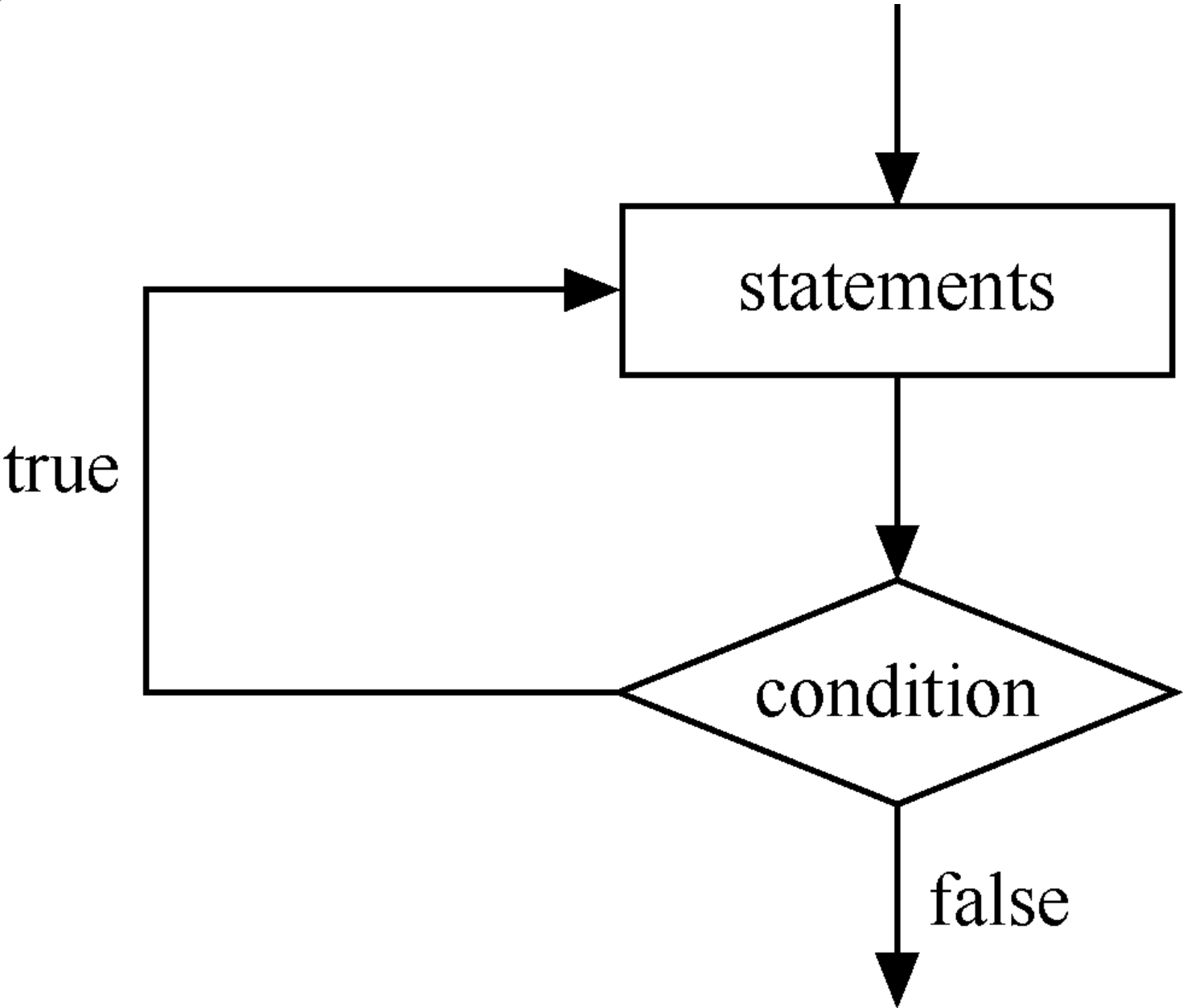
break 語句的應用
在本小節前面的內容中,我們事實上已經接觸過 break 語句,了解到它在 switch 語句里可以終止一條語句。其實除這個功能外,break 還能實現其他功能,例如退出循環。break 語句根據用戶使用的不同,可以分為無標號退出循環和有標號退出循環兩種。
無標號退出循環是指直接退出循環,當在循環語句中遇到 break 語句時,循環會立即終止,循環體外面的語句也將會重新開始執行。
return 語句的使用
在 Java 程式中,使用 return 語句可以返回一個方法的值,並把控制權交給調用它的語句。return 語句的語法格式如下所示。
return [expression];
expression 表示表達式,是可選參數,表示要返回的值,它的數據類型必須同方法聲明中返回值的類型一致,這可以通過強制類型轉換實現。
在編寫 Java 程式時,return 語句如果被放在方法的最後,它將用於退出當前的程式,並返回一個值。如果把單獨的 return 語句放在一個方法的中間,會出現編譯錯誤。如果非要把 return 語句放在方法的中間,可以使用條件語句 if,然後將 return 語句放在這個方法的中間,用於實現將程式中未執行的全部語句退出。
continue 語句
在 Java 語言中,continue 語句不如前面幾種跳轉語句應用得多,其作用是強制當前這輪迭代提前返回,也就是讓循環繼續執行,但不執行當前迭代中 continue 語句生效之後的語句。
使用 for 循環的技巧
控制 for 循環的變數經常只用於該循環,而不用在程式的其他地方。在這種情況下,可以在循環的初始化部分聲明變數。當我們在 for 循環內聲明變數時,必須記住重要的一點:該變數的作用域在 for 循環執行後就結束了(因此,該變數的作用域僅限於 for 循環內)。由於循環控制變數不會在程式的其他地方使用,因此大多數程式設計師都在 for 循環中聲明它。
另外,初學者經常以為,只要在 for 後面的括弧中控制了循環迭代語句,就萬無一失了,其實不是這樣的。請看下面的程式碼。
public class TestForError {
public static void main(String[] args) {
// 循環的初始化條件、循環條件、循環迭代語句都在下面一行
for (int count = 0; count < 10; count++) {
System.out.println(count);
// 再次修改了循環變數
count *= 0.1;
}
System.out.println("循環結束!");
}
}
在上述程式碼中,我們在循環體內修改了 count 變數的值,並且把這個變數的值乘以 0.1,這會導致 count 的值永遠都不超過 10,所以上述程式是一個死循環。
其實在使用 for 循環時,還可以把初始化條件定義在循環體之外,把循環迭代語句放在循環體內。把 for 循環的初始化語句放在循環之前定義還有一個好處,那就是可以擴大初始化語句中定義的變數的作用域。在 for 循環里定義的變數,其作用域僅在該循環內有效。for 循環終止以後,這些變數將不可被訪問。
跳轉語句的選擇技巧
由此可見,continue 的功能和 break 有點類似,區別在於 continue 只是中止當前迭代,接著開始下一次迭代;而 break 則完全終止循環。我們可以將 continue 的作用理解為:略過當前迭代中剩下的語句,重新開始新一輪的迭代。
聲明一維數組
數組本質上就是某類元素的集合,每個元素在數組中都擁有對應的索引值,只需要指定索引值就可以取出對應的數據。在 Java 中聲明一維數組的格式如下所示。
int[] arrar;
也可以用下面的格式。
int array[];
雖然這兩種格式的形式不同,但含義是一樣的,各個參數的具體說明如下。
int:數組類型。array:數組名稱。[]:一維數組的內容通過這個符號括起來。
除上面聲明的整型數組外,還可以聲明多種數據類型的數組,例如下面的程式碼。
boolean[] array; // 聲明布爾型數組
float[] array; // 聲明浮點型數組
double[] array; // 聲明雙精度型數組創建一維數組
創建數組實質上就是為數組申請相應的存儲空間,數組的創建需要用大括弧 {} 括起來,然後將一組相同類型的數據放在存儲空間里,Java 編譯器負責管理存儲空間的分配。創建一維數組的方法十分簡單,具體格式如下所示。
int[] a = {1,2,3,5,8,9,15};
上述程式碼創建了一個名為 a 的整型數組,但是為了訪問數組中的特定元素,應指定數組元素的位置序號,也就是索引(又稱下標),一維數組的內部結構如下圖所示。

上面這個數組的名稱是 a,方括弧的數值表示數組元素的索引,這個序號通常也被稱為下標。這樣就可以很清楚地表示每一個數組元素,數組 a 的第一個值就用 a[0] 表示,第 2 個值就用 a[1] 表示,以此類推。
初始化一維數組
在 Java 程式里,一定要將數組看作一個對象,它的數據類型和前面的基本數據類型相同。很多時候我們需要對數組進行初始化處理,在初始化的時候需要規定數組的大小。當然,也可以初始化數組中的每一個元素。下面的程式碼演示了 3 種初始化一維數組的方法。
int[] a = new int[8]; // 使用 new 關鍵字創建一個含有 8 個元素的 int 類型的數組 a
int[] a = new int{1,2,3,4,5,6,7,8}; // 初始化並設置數組 a 中的 8 個數組元素
int[] a = {1,2,3,4}; // 初始化並設置數組 a 中的 4 個數組元素
對上面程式碼的具體說明如下所示。
int:數組類型。a:數組名稱。new:對象初始化語句。
在初始化數組的時候,當使用關鍵字 new 創建數組後,一定要明白它只是一個引用,直到將值賦給引用,開始進行初始化操作後才算真正結束。在上面 3 種初始化數組的方法中,同學們可以根據自己的習慣選擇一種初始化方法。
聲明二維數組
在前面已經學習了聲明一維數組的知識,聲明二維數組也十分簡單,因為它與聲明一維數組的方法十分相似。很多程式設計師習慣將二維數組看作一種特殊的一維數組,其中的每個元素又是一個數組。聲明二維數組的語法格式如下所示。
float A[][]; //float 類型的二維數組 A
char B[][]; //char 類型的二維數組 B
int C[][]; //int 類型的二維數組 C
上述程式碼中各個參數的具體說明如下所示。
float、char和int:表示數組和類型。A、B和C:表示數組的名稱。[][]:二維數組的內容通過這個符號括起來。
創建二維數組的過程,實際上就是在電腦上申請一塊存儲空間的過程,例如下面是創建二維數組的程式碼。
int A[][]={
{1,2,3,4},
{5,6,7,8},
{9,10,11,12},
};
上述程式碼創建了一個二維數組,A 是數組名,實質上這個二維數組相當於一個 3 行 4 列的矩陣。當需要獲取二維數組中的值時,可以使用索引來顯示,具體格式如下所示。
array[i - 1][j - 1];
上述程式碼中各個參數的具體說明如下所示。
i:數組的行數。j:數組的列數。
下面以一個二維數組為例,看一下 3 行 4 列的數組的內部結構,如下圖所示。

初始化二維數組
初始化二維數組的方法非常簡單,可以看作是由多個一維數組構成,也是使用下面的語法格式實現的。
array = new int[][]{
{第一個數組第一個元素的值,第一個數組第二個元素的值,第一個數組第三個元素的值},
{第二個數組第一個元素的值,第二個數組第二個元素的值,第二個數組第三個元素的值},
};
或者使用 new 關鍵字。
array = new int[3][4]; // 創建一個 3 行 4 列的數組。
使用 new 關鍵字初始化的數組,其所有元素的值都默認為該數組的類型的默認值。這裡是 int 類型數組,則默認值為 0.
上述程式碼中各個參數的具體說明如下所示。
array:數組名稱。new:對象實例化語句。int:數組類型。
聲明三維數組
聲明三維數組的方法十分簡單,與聲明一維、二維數組的方法相似,具體格式如下所示。
float a[][][];
char b[][][];
上述程式碼中各個參數的具體說明如下所示。
float和char:數組類型。a和b:數組名稱。
創建三維數組的方法
在 Java 程式中,創建三維數組的方法也十分簡單,例如下面的程式碼。
int [][][] a = new int[2][2][3];初始化三維數組
初始化三維數組的方法十分簡單,例如可以用下面的程式碼初始化一個三維數組。
int[][][]a={
//初始化三維數組
{{1,2,3}, {4,5,6}}
{{7,8,9},{10,11,12}}
}
通過上述程式碼,可以定義並且初始化三維數組中元素的值。
複製數組
複製數組是指複製數組中的數值,在 Java 中可以使用 System 的方法 arraycopy() 實現數組複製功能。方法 arraycopy() 有兩種語法格式,其中第一種語法格式如下所示。
System.arraycopy(arrayA,indexA,arrayB,indexB,a.length);
arrayA:來源數組名稱。indexA:來源數組的起始位置。arryaB:目的數組名稱。indexB:要從來源數組複製的元素個數。
上述數組複製方法 arraycopy() 有一定局限,可以考慮使用方法 arraycopy() 的第二種格式,使用第二種格式可以複製數組內的任何元素。第二種語法格式如下所示。
System.arraycopy(arrayA,2,arrayB,3,3);
arrayA:來源數組名稱。2:來源數組從起始位置開始的第2個元素。arrayB:目的數組名稱。3:目的數組從其實位置開始的第3個元素。3:從來源數組的第 2 個元素開始複製3個元素。
比較數組
比較數組就是檢查兩個數組是否相等。如果相等,則返回布爾值 true;如果不相等,則返回布爾值 false。在 Java 中可以使用方法 equals() 比較數組是否相等,具體格式如下所示。
Arrays.equals(arrayA,arrayB);
arrayA:待比較數組的名稱。arrayB:待比較數組的名稱。
如果兩個數組相等,就會返回 true;否則返回 false。
排序數組
排序數組是指對數組內的元素進行排序,在 Java 中可以使用方法 sort() 實現排序功能,並且排序規則是默認的。方法 sort() 的語法格式如下所示。
Arrays.sort(array);
參數 array 是待排序數組的名稱。
搜索數組中的元素
在 Java 中可以使用方法 binarySearch() 搜索數組中的某個元素,語法格式如下所示。
int i = binarySearch(a,"abcde");
a:要搜索的數組名稱。abcde:需要在數組中查找的內容。
填充數組
在 Java 程式設計里,可以使用 fill() 方法向數組中填充元素。fill() 方法的功能十分有限,只能使用同一個數值進行填充。使用 fill() 方法的語法格式如下所示。
int a[] = new int[10];
Arrays.fill(array,11);
其中,參數 a 是將要填充的數組的名稱,上述格式的含義是將數值 11 填充到數組 a 中。
遍曆數組
在 Java 語言中,foreach 語句是從 Java 1.5 開始出現的新特徵之一,在遍曆數組和遍歷集合方面,foreach 為開發人員提供極大的方便。從實質上說,foreach 語句是 for 語句的特殊簡化版本,雖然 foreach 語句並不能完全取代 for 語句,但是任何 foreach 語句都可以改寫為 for 語句版本。
foreach 並不是一個關鍵字,習慣上將這種特殊的 for 語句稱為 foreach 語句。從英文字面意思理解,foreach 就是「為每一個」的意思。foreach 語句的語法格式如下所示。
for(type 變數 x : 遍歷對象 obj){
引用了 x 的 Java 語句;
}
其中,type 是數組元素或集合元素的類型,變數 x 是一個形參,foreach 循環自動將數組元素、集合元素依次賦給變數 x。
動態初始化數組的規則
在執行動態初始化時,程式設計師只需要指定數組的長度即可,即為每個數組元素指定所需的記憶體空間,系統將負責為這些數組元素分配初始值。在指定初始值時,系統按如下規則分配初始值。
- 數組元素的類型是基本類型中的整數類型(
byte、short、int和long),數組元素的值是 0。 - 數組元素的類型是基本類型中的浮點類型(
float、double),數組元素的值是 0.0。 - 數組元素的類型是基本類型中的字元類型(
char),數組元素的值是 ‘\u0000’。 - 數組元素的類型是基本類型中的布爾類型(
boolean),數組元素的值是false。 - 數組元素的類型是引用類型(類、介面和數組),數組元素的值是
null。
引用類型
如果記憶體中的一個對象沒有任何引用的話,就說明這個對象已經不再被使用了,從而可以被垃圾回收。不過由於垃圾回收器的運行時間不確定,可被垃圾回收的對象實際被回收的時間是不確定的。對於一個對象來說,只要有引用存在,它就會一直存在於記憶體中。如果這樣的對象越來越多,超出 JVM 中的記憶體總數,JVM 就會拋出 OutOfMemory 錯誤。雖然垃圾回收器的具體運行是由 JVM 控制的,但是開發人員仍然可以在一定程度上與垃圾回收器進行交互,目的在於更好地幫助垃圾回收器管理好應用的記憶體。這種交互方式就是從 JDK 1.2 開始引入的 java.lang.ref 包。
強引用
在一般的 Java 程式中,見到最多的就是強引用(strong reference)。例如 Date date = new Date(),其中的 date 就是一個對象的強引用。對象的強引用可以在程式中到處傳遞。很多情況下,會同時有多個引用指向同一個對象。強引用的存在限制了對象在記憶體中的存活時間。假如對象 A 中包含對象 B 的一個強引用,那麼一般情況下,對象 B 的存活時間就不會短於對象 A。如果對象 A 沒有顯式地把對象 B 的引用設為 null 的話,那麼只有當對象 A 被垃圾回收之後,對象 B 才不再有引用指向它,才可能獲得被垃圾回收的機會。 除了強引用之外,java.lang.ref包還提供了對一個對象的另一種不同的引用方式。JVM 的垃圾回收器對於不同類型的引用有不同的處理方式。
軟引用
軟引用(soft reference)在強度上弱於強引用,通過類 SoftReference 來表示。它的作用是告訴垃圾回收器,程式中的哪些對象不那麼重要,當記憶體不足的時候是可以被暫時回收的。當 JVM 中的記憶體不足時,垃圾回收器會釋放那些只被軟引用指向的對象。如果全部釋放完這些對象之後,記憶體仍不足,則會拋出 OutOfMemory 錯誤。軟引用非常適合於創建快取。當系統記憶體不足時候,快取中的內容是可以被釋放的。比如考慮一個影像編輯器的程式。該程式會把影像文件的全部內容讀取到記憶體中,以方便進行處理。用戶也可以同時打開多個文件。當同時打開的文件過多時,就可能造成記憶體不足。如果使用軟引用來指向影像文件的內容,垃圾回收器就可以在必要的時候回收這些記憶體。
數組的初始化
在 Java 中不存在只分配記憶體空間而不賦初始值的情況。因為一旦為數組的每個數組元素分配記憶體空間,記憶體空間里存儲的內容就是數組元素的值,即使記憶體空間存儲的內容為空,「空」也是值,用 null 表示。不管以哪一種方式初始化數組,只要為數組元素分配了記憶體空間,數組元素就有了初始值。獲取初始值的方式有兩種:一種由系統自動分配;另一種由程式設計師指定。
Java 面向對象的幾個核心概念
類
只要是一門面向對象的程式語言(例如 C++、C#等),那麼就一定有類這個概念。類是指將相同屬性的東西放在一起,類是一個模板,能夠描述一類對象的行為和狀態。請看下面兩個例子。
- 在現實生活中,可以將人看成一個類,這類稱為人類。
- 如果某個男孩想找一個對象(女朋友),那麼所有的女孩都可能是這個男孩的女朋友,所有的女孩就是一「類」。
Java 中的每一個源程式至少都會有一個類,在本書前面介紹的實例中,用關鍵字 class 定義的都是類。Java 是面向對象的程式設計語言,類是面向對象的重要內容,我們可以把類當成一種自定義數據類型,可以使用類來定義變數,這種類型的變數統稱為引用型變數。也就是說,所有類都引用數據類型。
對象
對象是實際存在某個類中的每一個個體,因而也稱為實例(instance)。對象的抽象是類,類的具體化就是對象,也可以說類的實例是對象。類用來描述一系列對象,類會概述每個對象包括的數據和行為特徵。因此,我們可以把類理解成某種概念、定義,它規定了某類對象所共同具有的數據和行為特徵。
接著前面的兩個例子。
- 人這個「類」的範圍實在是太籠統了,人類裡面的秦始皇是一個具體的人,是一個客觀存在的人,我們就將秦始皇稱為一個對象。
- 想找對象(女朋友)的男孩已經找到目標了,他的女朋友名叫「大美女」。注意,假設叫這個名字的女孩人類中僅有這一個,此時名叫「大美女」的這個女孩就是一個對象。
在面向對象的程式中,首先要將一個對象看作一個類,假定人是對象,任何一個人都是一個對象,類只是一個大概念而已,而類中的對象是具體的,它們具有自己的屬性(例如漂亮、身材好)和方法(例如會作詩、會編程)。
Java 中的對象
通過上面的講解可知,我們的身邊有很多對象,例如車、狗、人等。所有這些對象都有自己的狀態和行為。拿一條狗來說,它的狀態有名字、品種、顏色;行為有叫、搖尾巴和跑。
現實對象和軟體對象之間十分相似。軟體對象也有狀態和行為,軟體對象的狀態就是屬性,行為通過方法來體現。在軟體開發過程中,方法操作對象內部狀態的改變,對象的相互調用也是通過方法來完成的。
注意:類和對象有以下區別。
類描述客觀世界裡某一類事物的共同特徵,而對象則是類的具體化,Java 程式使用類的構造器來創建該類的對象。
類是創建對象的模板和藍圖,是一組類似對象的共同抽象定義。類是一個抽象的概念,不是一個具體的事物。
對象是類的實例化結果,是真實的存在,代表現實世界的某一事物。
屬性
屬性有時也稱為欄位,用於定義該類或該類的實例所包含的數據。在 Java 程式中,屬性通常用來描述某個對象的具體特徵,是靜態的。例如姚明(對象)的身高為 2.6m,小白(對象)的毛髮是棕色的,二郎神(對象)額頭上有隻眼睛等,都是屬性。
方法
方法用於定義該類或該類實例的行為特徵或功能實現。 每個對象都有自己的行為或者使用它們的方法,比如說一隻狗(對象)會跑會叫等。我們把這些行為稱為方法,它是動態的,可以使用這些方法來操作一個對象。
類的成員
屬性和方法都被稱為所在類的成員,因為它們是構成一個類的主要部分,如果沒有這兩樣東西,那麼類的定義也就沒有內容了。
定義類
在 Java 語言中,定義類的語法格式如下所示。
[修飾符] class 類名
{
零到多個構造器的定義…
零到多個屬性…
零到多個方法…
}
在上面定義類的語法格式中,修飾符可以是 public、final 或 static,也可以完全省略它們,類名只要是一個合法的標識符即可,但這僅滿足了 Java 的語法要求;如果從程式的可讀性方面來看,那麼 Java 類名必須由一個或多個有意義的單詞構成,其中每個單詞的首字母大寫,其他字母全部小寫,單詞與單詞之間不要使用任何分隔符。
在定義一個類時,它可以包含 3 個最常見的成員,它們分別是構造器、屬性和方法。這 3 個成員可以定義零個或多個。如果 3 個成員都只定義了零個,則說明定義了一個空類,這沒有太大的實際意義。類中各個成員之間的定義順序沒有任何影響,各個成員之間可以相互調用。需要注意的是,一個類的 static 方法需要通過實例化其所在類來訪問該類的非 static 成員。
下面的程式碼定義一個名為 person 的類,這是具有一定特性(人類)的一類事物,而 Tom 則是類的一個對象實例,其程式碼如下所示。
class person {
int age; //人具有 age 屬性
String name; //人具有 name 屬性
void speak(){ //人具有 speak 方法
System.out.println("My name is"+name);
}
}
public static void main(String args[]){
//類及類屬性和方法的使用
person Tom=new person(); //創建一個對象
Tom.age=27; //對象的 age 屬性是 27
Tom.name="TOM"; //對象的 name 屬性是 TOM
Tom.speak(); //對象的方法是 speak
}
一個類需要具備對應的屬性和方法,其中屬性用於描述對象,而方法可讓對象實現某個具體功能。例如在上述實例程式碼中,類、對象、屬性和方法的具體說明如下所示。
- 類:程式碼中的
person就是一個類,它代表人類。 - 對象:程式碼中的 Tom(注意,不是 TOM)就是一個對象,它代表一個具體的人。
- 屬性:程式碼中有兩個屬性:
age和name,其中屬性 age 表示對象 Tom 這個人的年齡是 27,屬性 name 表示對象 Tom 這個人的名字是 TOM。 - 方法:程式碼中的
speak()是一個方法,它表示對象 Tom 這個人具有說話這一技能。
定義屬性
在 Java 中定義屬性的語法格式如下所示。
[修飾符] 屬性類型 屬性名 [=默認值];
上述格式的具體說明如下所示。
- 修飾符:修飾符可以省略,也可以是
public、protected、private、static、final,其中public、protected、private最多只能出現一個,它可以與static、final組合起來修飾屬性。 - 屬性類型:屬性類型可以是 Java 語言允許的任何數據類型,它包括基本類型和現在介紹的複合類型。
- 屬性名:屬性名只要是一個合法的標識符即可,但這只是從語法角度來說的。如果從程式可讀性角度來看,那麼作者建議屬性名應該由一個或多個有意義的單詞構成,第一個單詞的首字母小寫,後面每個單詞的首字母大寫,其他字母全部小寫,單詞與單詞之間不需使用任何分隔符。
- 默認值:在定義屬性時可以定義一個由用戶指定的默認值,如果用戶沒有指定默認值,則該屬性的默認值就是其所屬類型的默認值。
定義方法
在 Java 中定義方法的語法格式如下所示。
[修飾符] 方法返回值類型 方法名 ([形參列表。..]){
由零條或多條可執行語句組成的方法體;
}
-
修飾符:它可以省略,也可以是
public、protected、private、static、final、abstract,其中public、protected、private這 3 個最多只能出現一個;abstract和final最多只能出現一個,它們可以與static組合起來共同修飾方法。 -
方法返回值類型:返回值類型可以是 Java 語言允許的任何數據類型,這包括基本類型、複合類型與 _
void類型_。如果聲明了方法的返回值類型,則方法體內就必須有一個有效的return語句,該語句可以是一個變數或一個表達式,這個變數或者表達式的類型必須與該方法聲明的返回值類型相匹配。當然,如果一個方法中沒有返回值,那麼我們也可以將返回值聲明成void類型。 -
方法名:方法名的命名規則與屬性的命名規則基本相同,我們建議方法名以英文的動詞開頭。
形參列表:形參列表用於定義該方法可以接受的參數,形參列表由零到多組「參數類型形參名」組合而成,多組參數之間以英文逗號(,)隔開,形參類型和形參名之間以英文空格隔開。一旦在定義方法時指定了形參列表,則在調用該方法時必須傳入對應的參數值——誰調用方法,誰負責為形參賦值。
在方法體中的多條可執行性語句之間有著嚴格的執行順序,在方法體前面的語句總是先執行,在方法體後面的語句總是後執行。
同學們實際上在前面的章節中已經多次接觸過方法,例如 public static void main(String args[]){...} 這段程式碼中就使用了方法 main(),在下面的程式碼中也定義了幾個方法。
public class test_class {
//定義一個無返回值的方法
public void cheng(){ //方法名是 cheng
System.out.println("我已經長大了"); //方法 cheng 的功能是輸出文本"我已經長大了"
//…
}
//定義一個有返回值的方法
public int Da(){ //方法名是 Da
int a=100; //定義變數 a,設置初始值是 100
return a; //方法 Da 的功能返回變數 a 的值
}定義構造器
構造器是一個創建對象時自動調用的特殊方法,目的是執行初始化操作。構造器的名稱應該與類的名稱一致。當 Java 程式在創建一個對象時,系統會默認初始化該對象的屬性,基本類型的屬性值為 0(數值類型)、false(布爾類型),把所有的引用類型設置為 null。構造器是類創建對象的根本途徑,如果一個類沒有構造器,那麼這個類通常將無法創建實例。為此 Java 語言提供構造器機制,系統會為該類提供一個默認的構造器。一旦為類提供了構造器,那麼系統將不再為該類提供構造器。
定義構造器的語法格式與定義方法的語法格式非常相似,在調用時,我們可以通過關鍵字 new 來調用構造器,從而返回該類的實例。下面,我們先來看一下定義構造器的語法格式。
[修飾符] 構造器名 ([形參列表。..]);
{
由零條或多條可執行語句組成的構造器執行體;
}
上述格式的具體說明如下所示。
-
修飾符:修飾符可以省略,也可以是
public、protected、private其中之一。 -
構造器名:構造器名必須和類名相同。
-
形參列表:這和定義方法中的形參列表的格式完全相同。
與一般方法不同的是,構造器不能定義返回值的類型,也不能使用 void 定義構造器沒有返回值。如果為構造器定義了返回值的類型,或使用 void 定義構造器沒有返回值,那麼在編譯時就不會出錯,但 Java 會把它當成一般方法來處理。下面的程式碼演示了使用構造器的過程。
public class Person { //定義類 Person
public String name; //定義屬性 name
public int age; //定義屬性 age
public Person(String name, int age) { //構造器函數 Person()
this.name = name; //開始自定義構造器,添加 name 屬性
this.age = age; //繼續自定義構造器,添加 age 屬性
}
public static void main(String[] args) {
// 使用自定義的構造器創建對象(構造器是創建對象的重要途徑)
Person p = new Person("小明", 12); //創建對象 p,名字是「小明」,年齡是 12
System.out.println(p.age); //輸出對象 p 的年齡
System.out.println(p.name); //輸出對象 p 的名字
}
}public 修飾符
在 Java 程式中,如果將屬性和方法定義為 public 類型,那麼此屬性和方法所在的類和及其子類、同一個包中的類、不同包中的類都可以訪問這些屬性和方法。
private 修飾符
在 Java 程式里,如果將屬性和方法定義為 private 類型,那麼該屬性和方法只能在自己的類中訪問,在其他類中不能訪問。
protected 修飾符
在編寫 Java 應用程式時,如果使用修飾符 protected 修飾屬性和方法,那麼該屬性和方法只能在自己的子類和類中訪問。
其他修飾符
前面幾節講解的修飾符是在 Java 中最常用的修飾符。除了這幾個修飾符外,在 Java 程式中還有許多其他的修飾符,具體說明如下所示。
- 默認修飾符:如果沒有指定訪問控制修飾符,則表示使用默認修飾符,這時變數和方法只能在自己的類及同一個包下的類中訪問。
static:由static修飾的變數稱為靜態變數,由static修飾的方法稱為靜態方法。final:由final修飾的變數在程式執行過程中最多賦值一次,所以經常定義它為常量。transient:它只能修飾非靜態變數,當序列化對象時,由transient修飾的變數不會序列化到目標文件。當對象從序列化文件中重構對象時(反序列化過程),不會恢復由transient欄位修飾的變數。volatile:和transient一樣,它只能修飾變數。這個關鍵字的作用就是告訴編譯器,只要是被此關鍵字修飾的變數都是易變、不穩定的。abstract:由abstract修飾的成員稱為抽象方法,用abstract修飾的類可以擴展(增加子類),且不能直接實例化。用abstract修飾的方法不能在聲明它的類中實現,且必須在某個子類中重寫。synchronized:該修飾符只能應用於方法,不能修飾類和變數。此關鍵字用於在多執行緒訪問程式中共享資源時實現順序同步訪問資源。
方法與函數的關係
不論是從定義方法的語法上來看,還是從方法的功能上來看,都不難發現方法和函數之間的相似性。儘管實際上方法是由傳統函數發展而來的,但方法與傳統的函數有著顯著不同。在結構化程式語言里,函數是老大,整個軟體由許多的函數組成。在面向對象的程式語言里,類才是老大,整個系統由許多的類組成。因此在 Java 語言里,方法不能獨立存在,方法必須屬於類或對象。在 Java 中如果需要定義一個方法,則只能在類體內定義,不能獨立定義一個方法。一旦將一個方法定義在某個類體內,並且這個方法使用 static 來修飾,則這個方法屬於這個類;否則,這個方法屬於這個類的對象。
在 Java 語言中,類型是靜態的,即我們當定義一個類之後,只要不再重新編譯這個類文件,那麼該類和該類對象所擁有的方法是固定的,且永遠都不會改變。因為 Java 中的方法不能獨立存在,它必須屬於一個類或者一個對象,所以方法也不能像函數那樣獨立執行。在執行方法時必須使用類或對象作為調用者,即所有方法都必須使用 類。方法 或 對象。方法 的格式來調用。此處可能會產生一個問題,當同一個類的不同方法之間相互調用時,不可以直接調用嗎?在此需要明確一個原則:當在同一個類的一個方法中調用另外一個方法時,如果被調方法是普通方法,則默認使用 this 作為調用者;如果被調方法是靜態方法,則默認使用類作為調用者。儘管從表面上看起來某些方法可以獨立執行,但實際上它還是使用 this 或者類來作為調用者。
永遠不要把方法當成獨立存在的實體,正如現實世界由類和對象組成,而方法只能作為類和對象的附屬,Java 語言里的方法也是一樣。講到此處,可以總結 Java 里的方法有如下主要屬性。
- 方法不能獨立定義,只能在類體里定義。
- 從邏輯意義上來看,方法要麼屬於該類本身,要麼屬於該類的一個對象。
- 永遠不能獨立執行方法,執行方法必須使用類或對象作為調用者。
長度可變的方法
自 JDK 1.5 之後,在 Java 中可以定義形參長度可變的參數,從而允許為方法指定數量不確定的形參。如果在定義方法時,在最後一個形參類型後增加 3 點 ...,則表明該形參可以接受多個參數值,它們當成數組傳入。在下面的實例程式碼中定義了一個形參長度可變的方法。
不使用 void 關鍵字構造方法名
前面小節節已經講解了構造器的知識,在此提醒同學們,構造方法沒有返回類型,不用 void 修飾,只有一個 public 之類的修飾符而已。
遞歸方法
如果一個方法在其方法體內調用自身,那麼這稱為方法遞歸。方法遞歸包含一種隱式的循環,它會重複執行某段程式碼,但這種重複執行無須循環控制。
使用 this
在講解變數時,曾經將變數分為局部變數和全局變數兩種。當局部變數和全局變數的數據類型和名稱都相同時,全局變數將會被隱藏,不能使用。為了解決這個問題,Java 規定可以使用關鍵字 this 去訪問全局變數。使用 this 的語法格式如下所示。
this. 成員變數名
this. 成員方法名()創建和使用對象
在 Java 程式中,一般通過關鍵字 new 來創建對象,電腦會自動為對象分配空間,然後訪問變數和方法。對於不同的對象,變數也是不同的,方法由對象調用。
使用靜態變數和靜態方法
在前面已經講過,只要使用修飾符 static 關鍵字在變數和方法前面,那麼這個變數和方法就稱作靜態變數和靜態方法。靜態變數和靜態方法的訪問只需要類名,通過運算 . 即可以實現對變數的訪問和對方法的調用。
抽象類和抽象方法的基礎
抽象方法和抽象類必須使用 abstract 修飾符來定義,有抽象方法的類只能定義成抽象類,類里可以沒有抽象方法。所謂抽象類是指只聲明方法的存在而不去實現它的類,抽象類不能實例化,也就是不能創建對象。在定義抽象類時,要在關鍵字 class 前面加上關鍵字 abstract,其具體格式如下所示。
abstract class 類名{
類體
}
- 抽象類必須使用
abstract修飾符來修飾,抽象方法也必須使用abstract修飾符來修飾,方法不能有方法體。 - 抽象類不能實例化,無法使用關鍵字 new 來調用抽象類的構造器創建抽象類的實例。
- 抽象類里不能包含抽象方法,這個抽象類也不能創建實例。
- 抽象類可以包含屬性、方法(普通方法和抽象方法都可以)、構造器、初始化塊、內部類、枚舉類 6 種。抽象類的構造器不能創建實例,主要用於被其子類調用。
- 含有抽象方法的類(包括直接定義一個抽象方法;繼承一個抽象父類,但沒有完全實現父類包含的抽象方法;實現一個介面,但沒有完全實現介面包含的抽象方法)只能定義成抽象類。
由此可見,抽象類同樣能包含與普通類相同的成員。只是抽象類不能創建實例,普通類不能包含抽象方法,而抽象類可以包含抽象方法。
抽象方法和空方法體的方法不是同一個概念。例如 public abstract void test() 是一個抽象方法,它根本沒有方法體,即方法定義後沒有一對花括弧。然而,但 public void test(){} 是一個普通方法,它已經定義了方法體,只是這個方法體為空而已,即它的方法體什麼也不做,因此這個方法不能使用 abstract 來修飾。
抽象類必須有一個抽象方法
創建抽象類最大的要求是必須有一個抽象方法
抽象類的作用
抽象類不能創建實例,它只能當成父類來繼承。從語義的角度看,抽象類是從多個具體類中抽象出來的父類,它具有更高層次的抽象。從多個具有相同特徵的類中抽象出一個抽象類,以這個抽象類作為其子類的模板,從而避免子類設計的隨意性。
抽象類體現的是一種模板模式的設計,抽象類為多個子類的通用模板,子類在抽象類的基礎上進行擴展、改造,但總體上子類會大致保留抽象類的行為方式。如果編寫一個抽象父類,父類提供了多個子類的通用方法,並把一個或多個方法留給其子類實現,那麼這就是一種模板模式,模板模式也是最常見、最簡單的設計模式之一。接下來看一個模板模式的實例程式碼,在它演示的抽象父類中,父類的普通方法依賴於一個抽象方法,而抽象方法則推遲到子類中實現。
軟體包的定義
定義軟體包的方法十分簡單,只需要在 Java 源程式的第一句中添加一段程式碼即可。在 Java 中定義包的格式如下所示。
package 包名;
package 聲明了多程式中的類屬於哪個包,在一個包中可以包含多個程式,在 Java 程式中還可以創建多層次的包,具體格式如下所示。
package 包名1[.包名2[.包名3]];
新建 UseFirst.java 文件,編寫以下程式碼。
package China.CQ; //載入一個包,其中父目錄函數「China」的子目錄是"CQ"
public class UseFirst { //定義類
public static void main(String[] args){
System.out.println("這個程式定義了一個包");
}
}
執行上述程式碼後將會創建一個多層次的包。由此可見,定義軟體包的過程實際上就是新建一個文件夾,將編譯後的文件放在新建文件夾中。定義軟體包實際上完成的就是這個事情。
在程式里插入軟體包
在 Java 程式中插入軟體包的方法十分簡單,只需使用 import 語句插入所需的類即可。在上一節實驗中,已經對插入軟體包這個概念進行了初次的接觸。在 Java 程式中插入軟體包的格式如下所示。
import 包名1.[包名2[.包名3]].(類名1*);
上述格式中,各個參數的具體說明如下所示。
- 包名 1:一級包。
- 包名 2:二級包。
- 類名:是需要導入的類名。也可以使用
*號,表示將導入這個包中的所有類。
掌握 this 的好處
關鍵字 this 最大的作用就讓類中的一個方法訪問該類的另一個方法或屬性。其實 this 關鍵字是很容易理解的,接下來作者舉兩個例子進行對比,相信大家看後對 this 的知識就完全掌握了。
第一段程式碼演示了沒有使用 this 的情況,具體程式碼如下所示。
class A {
private int aa, bb; // 聲明兩個 int 類型變數
public int returnData(int x, int y) { // 一個返回整數的方法
aa = x;
bb = y;
return aa + bb;
}
}
在第二段程式碼中使用 this,具體程式碼如下所示。
在下面的程式碼中需要重點注意在 MyDate newDay=new MyDate(this); 語句中 this 的作用。
class MyDate {
private int day;
private int month;
private int year; // 定義 3 個成員變數
public MyDate(int day, int month, int year) {
this.day = day;
this.month = month;
this.year = year;
} // 構造方法
public MyDate(MyDate date) {
this.day = date.day;
this.month = date.month;
this.year = date.year; // 將參數 Date 類中的成員變數賦給 MyDate 類
} // 構造方法
public int getDay() {
return day;
}// 方法
public void setDay(int day) {
this.day = day; // 參數 day 賦給此類中的 ddy
}
public MyDate addDays(int moreDay) {
MyDate newDay = new MyDate(this);
newDay.day = newDay.day + moreDay;
return newDay; // 返回整個類
}
public void print() {
System.out.println("My Date: " + year + "-" + month + "-" + day);
}
}
public class TestMyDate {
public static void main(String args[]) {
MyDate myBirth = new MyDate(19, 11, 1987); // 利用構造函數初始化
MyDate next = myBirth.addDays(7);
// addDays() 的返回值是類,將其返回值賦給變數 next
next.print();
}
}
事實上,前兩個類從本質說是相同的,而為什麼在第二個類中使用 this 關鍵字呢?注意,第二個類中的方法 returnData (int aa,int bb) 的形式參數分別為 aa 和 bb,這剛好和 private int aa,bb; 里的變數名是一樣的。現在問題來了:究竟如何在 returnData 的方法體中區別形式參數 aa 和全局變數 aa 呢?兩個 bb 也是如此嗎?這就是引入 this 關鍵字的用處所在了。this.aa 表示的是全局變數 aa,而沒有加 this 的 aa 表示形式參數 aa,bb 也是如此。
在此建議,在編程中不能過多使用 this 關鍵字。這從上面的程式碼中也可以看出,當相同的變數名加上 this 關鍵字過多時,有時會讓人分不清。這時可以按照第三段程式碼進行修改,避免使用 this 關鍵字。
class A {
private int aa, bb; // 聲明兩個 int 類型變數
public int returnData(int aa1, int bb1) {
aa = aa1; // 在 aa 後面加上數字 1 加以區分,其他以此類推
bb = bb1;
return aa + bb;
}
}
由此可以看出,儘管上面的第一段程式碼、第二段程式碼、第三段程式碼都是一樣的,但是第三段程式碼既避免了使用 this 關鍵字,又避免了第一段程式碼中參數意思不明確的缺點,所以建議使用與第三段程式碼一樣的方法。
推出抽象方法的原因
當編寫一個類時,常常會為該類定義一些方法,這些方法用以描述該類的行為方式,這時這些方法都有具體的方法體。在某些情況下,某個父類只是知道其子類應該包含什麼樣的方法,但卻無法準確知道這些子類如何實現這些方法,例如定義一個 Shape 類,這個類應該提供一個計算周長的方法 scalPerimeter(),不同 Shape 子類對周長的計算方法是不一樣的,也就是說 Shape 類無法準確知道其子類計算周長的方法。
很多人以為,既然 Shape 不知道如何實現 scalPerimeter() 方法,那麼就乾脆不要管它了。其實這是不正確的作法,假設有一個 Shape 引用變數,該變數實際上會引用到 Shape 子類的實例,那麼這個 Shape 變數就無法調用 scalPerimeter() 方法,必須將其強制類型轉換為其子類類型才可調用 scalPerimeter() 方法,這就降低了 Shape 的靈活性。 究竟如何既能在 Shape 類中包含 scalPerimeter() 方法,又無須提供其方法實現呢?Java 中的做法是使用抽象方法滿足該要求。抽象方法是只有方法簽名,並沒有方法實現的方法。
static 修飾的作用
使用 static 修飾的方法屬於這個類,或者說屬於該類的所有實例所共有。使用 static 修飾的方法不但可以使用類作為調用者來調用,也可以使用對象作為調用者來調用。值得指出的是,因為使用 static 修飾的方法還是屬於這個類的,所以使用該類的任何對象來調用這個方法都將會得到相同的執行結果,這與使用類作為調用者的執行結果完全相同。
不使用 static 修飾的方法則屬於該類的對象,它不屬於這個類。因此不使用 static 修飾的方法只能用對象作為調用者來調用,不能使用類作為調用者來調用。使用不同對象作為調用者來調用同一個普通方法,可能會得到不同的結果。
數組內是同一類型的數據
Java 是一門是面向對象的程式語言,能很好地支援類與類之間的繼承關係,這樣可能產生一個數組裡可以存放多種數據類型的假象。例如有一個水果數組,要求每個數組元素都是水果,實際上數組元素既可以是蘋果,也可以是香蕉,但這個數組中的數組元素類型還是唯一的,只能是水果類型。
另外,由於數組是一種引用類型的變數,因此使用它定義一個變數時,僅表示定義了一個引用變數(也就是定義了一個指針),這個引用變數還未指向任何有效的記憶體,因此定義數組時不能指定數組的長度。由於定義數組僅是定義了一個引用變數,並未指向任何有效的記憶體空間,所以還沒有記憶體空間來存儲數組元素,這時這個數組也不能使用,只有數組初始化後才可以使用。
繼承的定義
類的繼承是指從已經定義的類中派生出一個新類,是指我們在定義一個新類時,可以基於另外一個已存在的類,從已存在的類中繼承有用的功能(例如屬性和方法)。這時已存在的類便被稱為父類,而這個新類則稱為子類。在繼承關係中,父類一般具有所有子類的共性特徵,而子類則會為自己增加一些更具個性的方法。類的繼承具有傳遞性,即子類還可以繼續派生子類,因此,位於上層的類在概念上就更抽象,而位於下層的類在概念上就更具體。
父類和子類
繼承是面向對象的機制,利用繼承可以創建一個公共類,這個類具有多個項目的共同屬性。我們可再用一些具體的類來繼承該類,同時加上自己特有的屬性。在 Java 中實現繼承的方法十分簡單,具體格式如下所示。
<修飾符> class <子類名> extends <父類名> {
[<成員變數定義>]…
[<方法定義>]…
}
我們通常所說的子類一般指的是某父類的直接子類,而父類也可稱為該子類的直接超類。如果存在多層繼承關係,比如,類 A 繼承的是類 B,則它們之間的關係就必須符合下面的要求。
- 若存在另外一個類 C,類 C 是類 B 的子類,類 A 是類 C 的子類,那麼可以判斷出類 A 是類 B 的子類。
- 在 Java 程式中,一個類只能有一個父類,也就是說在 extends 關鍵字前只能有一個類,它不支援多重繼承。
調用父類的構造方法
構造方法是 Java 類中比較重要的方法,一個子類可以訪問構造方法,這在前面已經使用過多次。Java 語言調用父類構造方法的具體格式如下所示。
super(參數);訪問父類的屬性和方法
在 Java 程式中,一個類的子類可以訪問父類的屬性和方法,具體語法格式如下所示。
super.[方法和全局變數];


