【論文筆記】用反事實推斷方法緩解標題黨內容對推薦系統的影響 Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue
Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue
Authors: 王文傑,馮福利,何向南,張含望,蔡達成
SIGIR’21 新加坡國立大學,中國科學技術大學,南洋理工大學
論文鏈接://dl.acm.org/doi/pdf/10.1145/3404835.3462962
本文鏈接://www.cnblogs.com/zihaojun/p/15713705.html
0. 總結
這篇文章在不引入用戶回饋資訊的情況下,利用物品的外觀特徵(exposure feature)和內容特徵(content feature),用反事實推斷的方法,去除物品外觀特徵對推薦結果的直接影響,解決推薦系統中「標題黨」的問題。
1. 問題背景
在推薦系統的訓練數據中,通常將用戶點擊過的物品作為正樣本進行訓練。但是,用戶點擊一個物品不一定是因為用戶喜歡這個物品,也可能是因為物品的外觀很吸引人,但是內容很差。這種現象稱為Clickbait Issue——引誘點擊問題。
- 例如,在影片推薦場景下,用戶點擊一個影片,可能只是因為影片的封面和標題做的很好,但點進去可能並不喜歡看。
- 在文章/新聞推薦場景下也是如此,很多標題黨文章可以獲得很多點擊,但用戶對這種文章是深惡痛絕的。
Clickbait Issue會導致用戶對推薦系統的信任度下降,也會導致低品質的標題黨資訊在系統中泛濫,產生劣幣驅逐良幣的效果和馬太效應。
因此,設計和訓練推薦模型時,不能只追求點擊率優化,而應該追求更高的用戶滿意度,避免陷入「推薦標題黨內容-標題黨獲得更多點擊-推薦更多標題黨內容」的惡性循環中。
2. 研究目標
利用物品的外觀資訊和內容資訊,區分用戶的點擊是因為被標題/封面吸引,還是真的喜歡物品的內涵。
3. 方法
3.1 符號和概念
數據集包含歷史點擊數據\(\bar{\mathcal{D}}=\left\{\left(u, i, \bar{Y}_{u, i}\right) \mid u \in \mathcal{U}, i \in \mathcal{I}\right\}\),其中\(\bar{Y}_{u, i} \in \{0,1\}\),分別表示沒有/有點擊交互。物品特徵包括暴露資訊(Exposure features)和內容資訊(Content features),\(i = (e,t)\),暴露資訊(e)在用戶點擊之前就能看到,比如標題和封面圖;內容資訊(t)在點擊之後才能看到,例如文章內容、影片內容或物品詳情等。
推薦模型預測結果\(Y_{u,i} = s_{\theta}(u,i) \in [0,1]\),優化目標為:
\bar{\theta}=\underset{\theta}{\arg \min } \sum_{\left(u, i, \bar{Y}_{u, i}\right) \in \overline{\mathcal{D}}} l\left(s_{\theta}(u, i), \bar{Y}_{u, i}\right)
\end{align}
\]
Clickbait Issue:如果推薦系統給出的推薦列表中,把標題很吸引人,但是內容很差的物品\(i\)排在標題不太吸引人,但是內容比較好的物品\(j\)之前,則認為發生了Clickbait Issue。
s_{\bar{\theta}}\left(u, i=\left(e_{i}, t_{i}\right)\right)>s_{\bar{\theta}}\left(u, j=\left(e_{j}, t_{j}\right)\right)
\end{align}
\]
Causal effect:因果效應分解,參見【因果推斷】中介因果效應分解 匯總與理解(為了讀懂這個分解方法,花了很多時間來研究,才寫成此文)
- 總體因果效應:包含直接路徑和間接路徑的因果效應。
- 直接因果效應:通過直接路徑產生的因果效應。
- 間接因果效應:通過中介節點產生的因果效應。
3.2 因果推薦模型
如圖3(a),在傳統的基於特徵的推薦模型中,會將物品特徵(E, T)都作為輸入,通過MLP等模型,得到item的表示(I)。
但是用戶可能只是被標題等資訊吸引而點擊一個物品,因此,本文提出,建模曝光特徵(E)對點擊(Y)的直接因果效應,如圖3(b)。
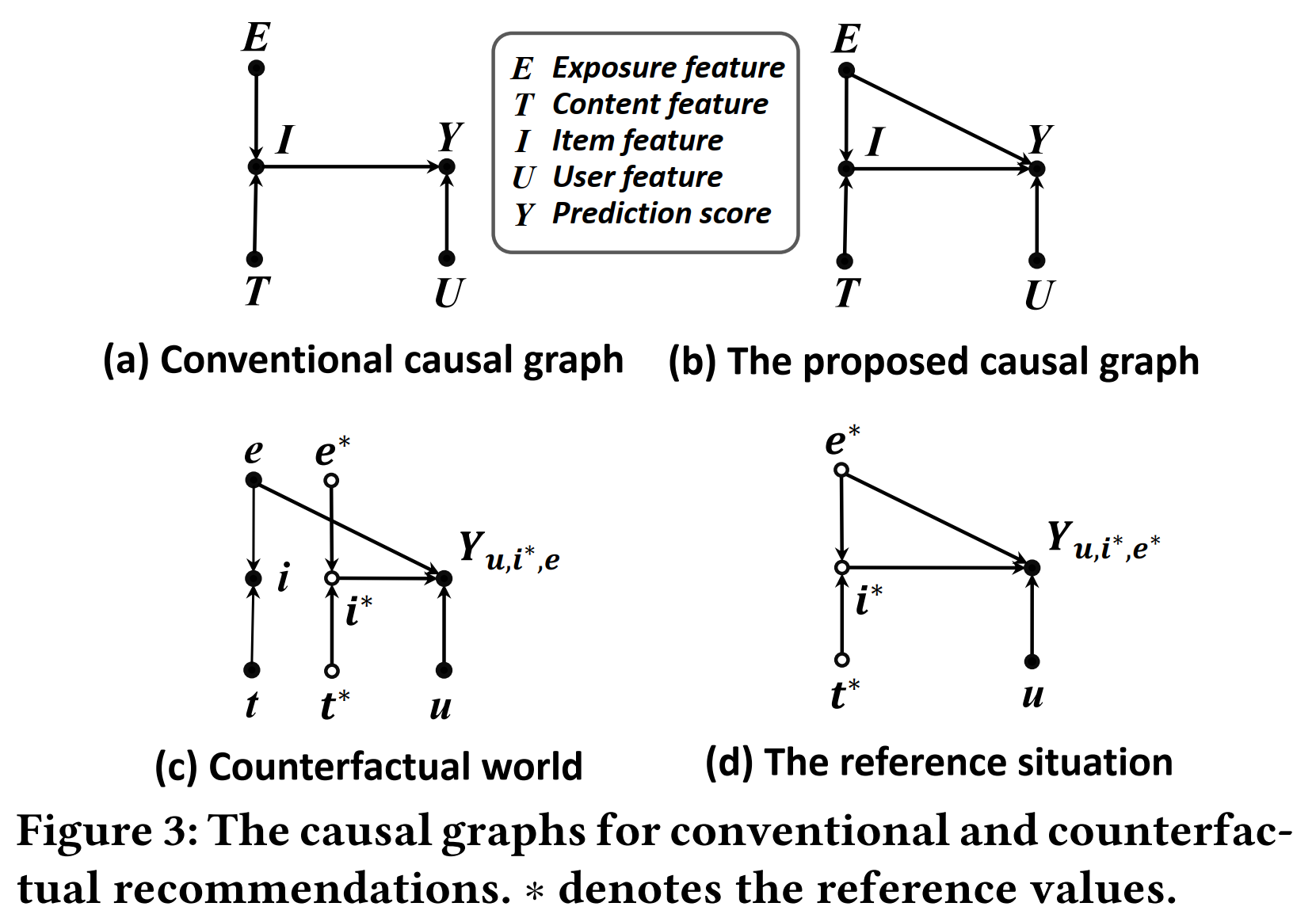
Mitigating Clickbait Issue
- 為了解決推薦結果的Clickbait Issue,需要將\(E\rightarrow Y\)這條路徑的影響去掉。我們希望去除的是E對Y自然直接效應,保留E對Y的自然間接效應和交互效應,即保留總體間接效應TIE,因此,不能直接對這條路徑做干預,否則就會去除掉總體直接效應,只剩自然間接效應NIE:
Y_{u,i,e^*} – Y_{u,i^*,e^*} = NIE
\end{align}
\]
本文希望得到的總體間接效應:
TIE = Y_{u,i,e}-Y_{u,i^*,e}
\end{align}
\]
- 具體請參考博文【論文筆記】Direct and Indirect Effects、【因果推斷】中介因果效應分解 匯總與理解
- 從因果圖的角度來理解,\(Y_{u, i, e}\)和\(Y_{u, i^*, e}\)的因果圖中,\(E \rightarrow Y\)這條邊是一樣的(都是e),因此\(E \rightarrow Y\)的直接影響可以被減掉,還剩下\(I \rightarrow Y\)的影響。
- 直觀理解,如果一個物品是靠標題黨來吸引流量的,則這個物品在反事實世界中的點擊率(\(Y_{u, i^*, e}\))會很高,從而在反事實推薦模型中被排到後面去。
3.3 模型設計
在因果圖中,影響點擊概率Y的變數有三個(e,u,i),本文分別建立了u-e模型和u-i模型,分別捕捉物品曝光特徵和總體特徵對用戶點擊概率的影響:
Y_{u, i, e}=f_{Y}(U=u, I=i, E=e)=f\left(Y_{u, i}, Y_{u, e}\right)=Y_{u, i} * \sigma\left(Y_{u, e}\right)
\end{align}
\]
模型訓練:
\mathcal{L}=\sum_{\left(u, i, \bar{Y}_{u, i}\right) \in \overline{\mathcal{D}}} l\left(Y_{u, i, e}, \bar{Y}_{u, i}\right)+\alpha * l\left(Y_{u, e}, \bar{Y}_{u, i}\right)
\end{align}
\]
模型預測:
Y_{C R}=Y_{u, i, e}-Y_{u, i^{*}, e}=Y_{u, i, e}-f\left(c_{u}, Y_{u, e}\right)=Y_{u, i, e}-c_{u} * \sigma\left(Y_{u, e}\right)
\end{align}
\]
\(c_u\)是用戶u對所有物品特徵的平均興趣:
c_{u}=E\left(Y_{u, I}\right)=\frac{1}{|\mathcal{I}|} \sum_{i \in I} Y_{u, i}
\end{align}
\]
4. 實驗
4.1 實驗結果
使用了兩個有物品特徵和用戶回饋的數據集,統計資訊見下表:
&\text { Table 1: Statistics of two datasets. }\\
&\begin{array}{l|c|c|c|c}
\hline \text { Dataset } & \text { #Users } & \text { #Items } & \text { #Clicks } & \text { #Likes } \\
\hline \text { Tiktok } & 18,855 & 34,756 & 1,493,532 & 589,008 \\
\hline \text { Adressa } & 31,123 & 4,895 & 1,437,540 & 998,612 \\
\hline
\end{array}
\end{aligned}
\]
對於每個用戶,將正樣本按8:1:1的比例隨機劃分訓練集、驗證集和測試集,其中測試集中只包含用戶給出正回饋的物品。
baseline:
- NT:(Normal Training)使用正常的訓練數據,即使用曝光特徵+內容特徵作為模型輸入,使用點擊數據(而不是只使用正回饋數據)作為正樣本參與訓練。
- CFT:(Content Feature Training)只使用內容特徵來訓練模型,同樣使用點擊數據作為正樣本參與訓練。
- IPW:訓練階段使用Inverse Propensity Score的方法來做debias[27,28]。
以下三個baseline是利用了用戶回饋數據的:
- CT:(Clean Training)只使用正回饋數據作為正樣本來訓練。
- NR:(Negative feedback Re-weighting)將點擊但不喜歡的樣本,與未點擊的樣本一起作為負樣本進行訓練。
- RR:(Re-Rank)在NT的基礎上,對每個用戶前20的推薦物品,結合物品的點贊率進行重排序。
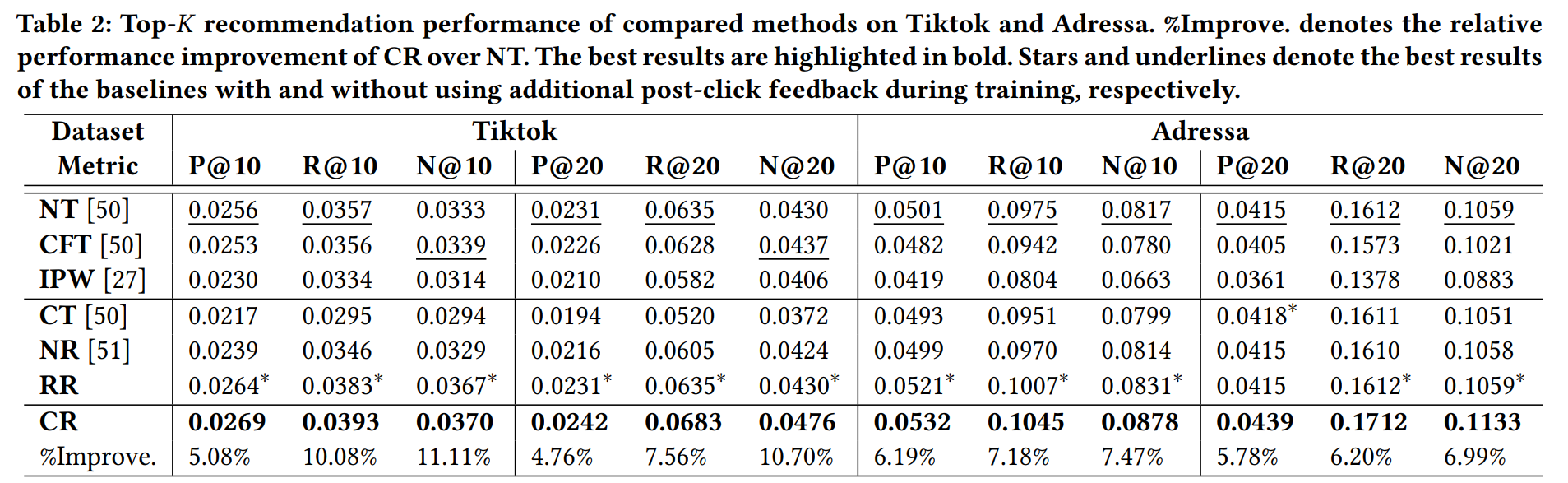
實驗表明,本文提出的方法CR(Counterfactual Recommendation)的性能高於所有baseline。
4.2 性能比較
- CFT性能比NT要差,說明簡單地去除曝光特徵是不行的。IPW性能也很差,這可能與本文的設定下,propensity score很難估計有關。
- CR的性能高於NT,說明利用用戶回饋數據的有效性,更能捕捉用戶對內容的興趣。但CT和NR的性能比較差,這可能是因為直接拋棄用戶點擊但未給出正回饋的那些數據,會使得數據量大大減少。
一些想法
- 有些物品可能難以收集或者定義曝光特徵,此時就無法應用此方法
- 本文的模型設計是比較反直覺的,不是直接在預測時把包含e的項去掉,而是減去一項\(c_{u} * \sigma\left(Y_{u, e}\right)\)。這也是因果推斷理論的作用——給出不怎麼符合直覺但是更合理更有效的模型設計方法。
- 這是2021年的最後一個晚上發表的今年最後一篇隨筆,2021年我發生了很大的變化,希望在即將到來的2022年,能儘快達到自己滿意的學術水平,順利開啟博士生涯,抓緊在校園的時光,努力學本領。希望明年能發表100篇以上的部落格,讀500篇以上的論文,加油加油!
進一步閱讀
[45] Tyler J VanderWeele. 2013. A three-way decomposition of a total effect into direct, indirect, and interactive effects. Epidemiology (Cambridge, Mass.) 24, 2 (2013), 224
[30] Dugang Liu, Pengxiang Cheng, Zhenhua Dong, Xiuqiang He, Weike Pan, and Zhong Ming. 2020. A General Knowledge Distillation Framework for Counterfactual Recommendation via Uniform Data. In SIGIR. ACM, 831–840
[35] Yulei Niu, Kaihua Tang, Hanwang Zhang, Zhiwu Lu, Xian-Sheng Hua, and JiRong Wen. 2020. Counterfactual VQA: A Cause-Effect Look at Language Bias. In arXiv:2006.04315
[37] Judea Pearl. 2001. Direct and indirect effects. In UAI. Morgan Kaufmann Publishers Inc, 411–420.
[43] Kaihua Tang, Jianqiang Huang, and Hanwang Zhang. 2020. Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect. In NeurIPS.
[44] Kaihua Tang, Yulei Niu, Jianqiang Huang, Jiaxin Shi, and Hanwang Zhang. 2020. Unbiased scene graph generation from biased training. In arXiv:2002.11949
[27] Dawen Liang, Laurent Charlin, and David M Blei. 2016. Causal inference for recommendation. In UAI. AUAI.
[28] Dawen Liang, Laurent Charlin, James McInerney, and David M Blei. 2016. Modeling user exposure in recommendation. In WWW. ACM, 951–961
[32] Hongyu Lu, Min Zhang, and Shaoping Ma. 2018. Between Clicks and Satisfaction: Study on Multi-Phase User Preferences and Satisfaction for Online News Reading. In SIGIR. ACM, 435–444.
[52] Hong Wen, Jing Zhang, Yuan Wang, Fuyu Lv, Wentian Bao, Quan Lin, and Keping Yang. 2020. Entire space multi-task modeling via post-click behavior decomposition for conversion rate prediction. In SIGIR. ACM, 2377–2386


