# 中文NER的那些事兒6. NER新範式!你問我答之MRC
就像Transformer帶火了”XX is all you need”的論文起名大法,最近也看到了好多”Unified XX Framework for XX”的paper,畢竟誰不喜歡寫好一套框架然後哪裡需要哪裡搬凸–凸。這一章讓我們來看下如何把NER的序列標註任務轉換成閱讀理解任務。論文本身把重點放在新的框架可以更好解決嵌套實體問題,但是實際應用中我碰到Nested NER的情況很少,不過在此之外MRC對小樣本場景,以及細粒,層次化實體的識別任務也有一些啟發意義,程式碼詳見ChineseNER/mrc
Paper: A Unified MRC Framework for Named Entity Recognition
下面我們把MRC的模型框架分開成兩部分來看。第一部分是閱讀理解任務主要處理模型的輸入,第二部分是entity Span抽取任務針對模型的輸出。因為他們其實是針對不同問題的改良,可以在不同的場景下分開使用
閱讀理解:Tag -> Q&A
樣本生成
在之前的NER任務中,對不同的實體類型的處理就是在label中使用不同的tag,地點就是LOC,人物就是PER,機構就是ORG。這種標註方式的問題在於
- label本身沒有任何先驗資訊(這裡的先驗資訊既包括label本身的含義,也包括label之間關聯性)
- 以及output層的複雜度會隨著實體類別的增加呈線性增長
- label和文本的交互只發生在輸出層
MRC的改良方式是把label資訊用Query進行編碼,然後用Query和文本間的交互提取對應的實體資訊。針對MSRA數據集中LOC,ORG,PER三類實體,作者分別用了如下的Query作為三類實體的先驗資訊
Tag2Query = {
'LOC': '按照地理位置劃分的國家,城市,鄉鎮,大洲',
'PER': '人名和虛構的人物形象',
'ORG': '組織包括公司,政府黨派,學校,政府,新聞機構'
}
Bert模型的輸入和QA任務相同是\([CLS]query[SEP]text\), 以PER為例,每個樣本都被構建為以下形式。
[CLS]人名和虛構的人物形象[SEP]這是中國領導人首次在哈佛大學發表演講
如果NER任務有N個實體,訓練樣本有M個,按以上QA樣本的構建方式會得到N*M個樣本。
Query構建
因為這裡Query是對label先驗資訊的刻畫,所以如何構建query對最終的模型效果有很大的影響,作者在paper中對比了不同的Query生成方式,已ORG為例,作者嘗試了
- position: tag的數值編碼1/2/3
- keyword: 組織
- Rule-based template filling: 文中提到了哪些結構?
- wikipedia:組織的百科描述
- synonyms: 組織的同義詞
- keyword+synonyms: 組織+組織的同義詞
- Annotation guide: 組織包括公司,政府黨派,學校,政府,新聞機構

對比結果如上,position因為沒啥資訊所以效果最差,keyword+synonyms顯著優於只使用關鍵詞/同義詞,所以編碼資訊其實是越全面越好。wiki因為包含一些無效資訊所以效果不如Annotation。在實際應用時,其實可以進一步在query中引入結構化資訊,幫助更細粒度的實體標註,例如[綜藝節目]音樂綜藝,[綜藝節目]搞笑綜藝,對同一領域的實體加上領域資訊,幫助模型學習實體間的關聯關係
總結
QA模型結構的優點
- 加入了label的先驗資訊,會在few-shot/zero-shot場景中有更好的效果,對於新實體的冷起會是個不錯的選擇
- Query里可以加入label之間的關聯資訊,例如同一領域內的細分實體,對細粒度實體識別可能會有幫助
- QA的模型結構增加了實體類型和文本的交互
- 增加新的實體類型,只會增加對應的訓練樣本,不會增加模型複雜度
哈哈天上從來不會掉餡餅,有優點肯定有缺點滴~這個paper中沒有提,不過在使用中感覺有幾點需要填坑
- QA的樣本構建方式加劇了Data Imbalance,原先有實體/無實體的比例如果是1:10,3類實體的QA樣本可能就是1:30,會出現大量無實體的sample
- QA的構建方式導致一次推理只能提取1種實體類型,會增加線上推理耗時。當然你可以加機器加並發。在github上看到有另一種操作是把query拼在一起\([cls1]q1[cls2]q2[cls3]q3[seq]text\),不過這個需要同時修改訓練方式,有試過效果的小夥伴歡迎comment下效果~
- Query的構建有時候會需要多次嘗試,因為如果先驗資訊有錯或者不完整,反而會影響到模型效果。
Span抽取
span抽取部分paper中寫的很簡單,真的是讀完覺得簡單明了!結果噼里啪啦一同寫,跑起來發現模型span F1不收斂。。。於是默默去讀了MRC的源碼,感覺paper中省略了幾個對模型效果會有影響的細節,下面來聊聊踩過的坑~
Start/End Index
為了同時抽取nested Entitty,作者使用了start index+end index的方式來標記實體位置。舉個例子,樣本如下
樣本:{"title": "我 會 邀 請 許 惠 佑 一 同 來 訪 ",
"label": [{"span": "許惠佑", "tag": "PER", "start_pos": 4, "end_pos": 6}]}
start index:[0,0,0,0,1,0,0,0,0,0,0]
end index:[0,0,0,0,0,0,1,0,0,0,0]
span index: [11,11] matrix,[(4,6)]=1
start index標記實體開始的位置,end index標記實體結束的位置。這裡和序列標註的方式相同,會在Bert模型輸出後面接一個classifier,預測每個位置是否start/end=1
p_{start} = softmax(W_{start} \cdot Bert_{output})\\
p_{end} = softmax(W_{end} \cdot Bert_{output})\\
\hat{I}_{start} = \{i|argmax(p_{start}^i)==1, i=1,2,…n\}\\
\hat{I}_{end} = \{i|argmax(p_{end}^i)==1, i=1,2,…n\}
\end{align}
\]
Span Index
因為是nested entity,所以開始位置和結束位置可能會存在交叉,並不能唯一確定實體位置,所以需要一個span index。span index第i行第j列如果是1,就意味著i->j之間存在一個實體。
下面是paper中的公式,看公式我以為是把start end的logits進行了拼接,然後做一層線性變換,從start/end logits裡面判斷哪些是正確的組合。
\]
結果看到下面的源碼發現是直接對Bert的embedding輸出copy了兩份進行拼接後,又加了一層非線性變換。。。這公式寫的有些抽象。。。所以span logits的計算空間複雜度比較高,因為span本身是seq_len * seq_len二維的,所以embedding空間是O(seq_len * seq_len * emb_size)。
span_embedding = MultiNonLinearClassifier(config.hidden_size * 2, 1, config.mrc_dropout, intermediate_hidden_size=config.classifier_intermediate_hidden_size)
sequence_heatmap = bert_outputs[0] # [batch, seq_len, hidden]
# [batch, seq_len, seq_len, hidden]
start_extend = sequence_heatmap.unsqueeze(2).expand(-1, -1, seq_len, -1)
end_extend = sequence_heatmap.unsqueeze(1).expand(-1, seq_len, -1, -1)
# [batch, seq_len, seq_len, hidden*2]
span_matrix = torch.cat([start_extend, end_extend], 3)
# [batch, seq_len, seq_len]
span_logits = span_embedding(span_matrix).squeeze(-1)
計算Span Loss的時候,作者先做了個一個下半矩陣的MASK,這一步只是把所有start_index>end_index的位置直接MASK掉。但只有這一個MASK並不夠,因為span logits存在很嚴重的Data-Imbalance的問題,就像上面在Query構造時就提到過的,QA的樣本會成倍的提高正負樣本比,這裡的Span Loss也是同樣的問題。1個實體在start index中的正負比是1vsSeq_len,在span index中就是1vs(Seq_len * Seq_len)。
考慮到Span Index只是為了對Start/End Index的輸出結果進一步篩選,所以作者在計算Span Loss的時候加了Candidate Mask。Mask有幾種構建方式,最終作者選擇的主要是『pred_and_gold』 MASK,也就是只針對Span Label=1 or Start/End預測=1的位置計算Span Loss。。。(*≧ω≦)
Loss & Inference
最終的模型loss是start loss, end loss, span loss的加權求和。看作者的參數設定span的權重一般是0.1,start&end的權重是1。感覺這裡的trick可能在於差異化梯度更新,因為span的loss計算依賴上面提到的使用start/end的預測結果作為MASK。所以需要start/end先行更快的收斂,再來幫助span進行收斂。直接差異化learning rate可能也闊以??
L_{start} = CE(P_{start}, Y_{start})\\
L_{end} = CE(P_{end}, Y_{end})\\
L_{span} = CE(P_{span}, Y_{span})\\
L = \alpha L_{start} + \beta L_{end} + \gamma L_{span} \\
\end{align}
\]
模型的預測結果,需要分別對start,end, span index進行預測,然後取三個Index的交集作為實體預測的結果。
評估
實際應用中到我還沒碰到必須使用嵌套實體的場景,所以還是更傾向於適配Flat NER的解決方案,所以在使用MRC的時候,我只使用了前半部分的Query構建,後面的start/end/span的抽取方式直接替換成了BIO的序列標註方式。
在MSRA上進行實驗,因為這裡沒加CRF層,所以直接和第一章時提到的Bert+CrossEntropy的模型結構進行對比。(這裡用的是google Bert Base,測試過和WWM Bert Base沒啥差別,作者paper中用的是WWM Bert Large,然我並跑不動。。。所以結果沒法比)上面是MRC的結果下面是Bert-CE的結果。會發現PER的預測結果兩個模型差不多,但是ORG/LOC的結果中,MRC反而要略差一些,指標主要差在召回率都是顯著低於Bert-CE的
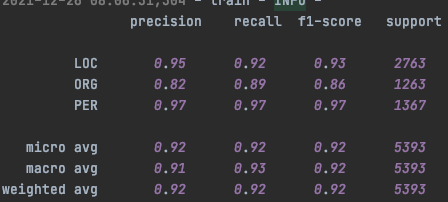
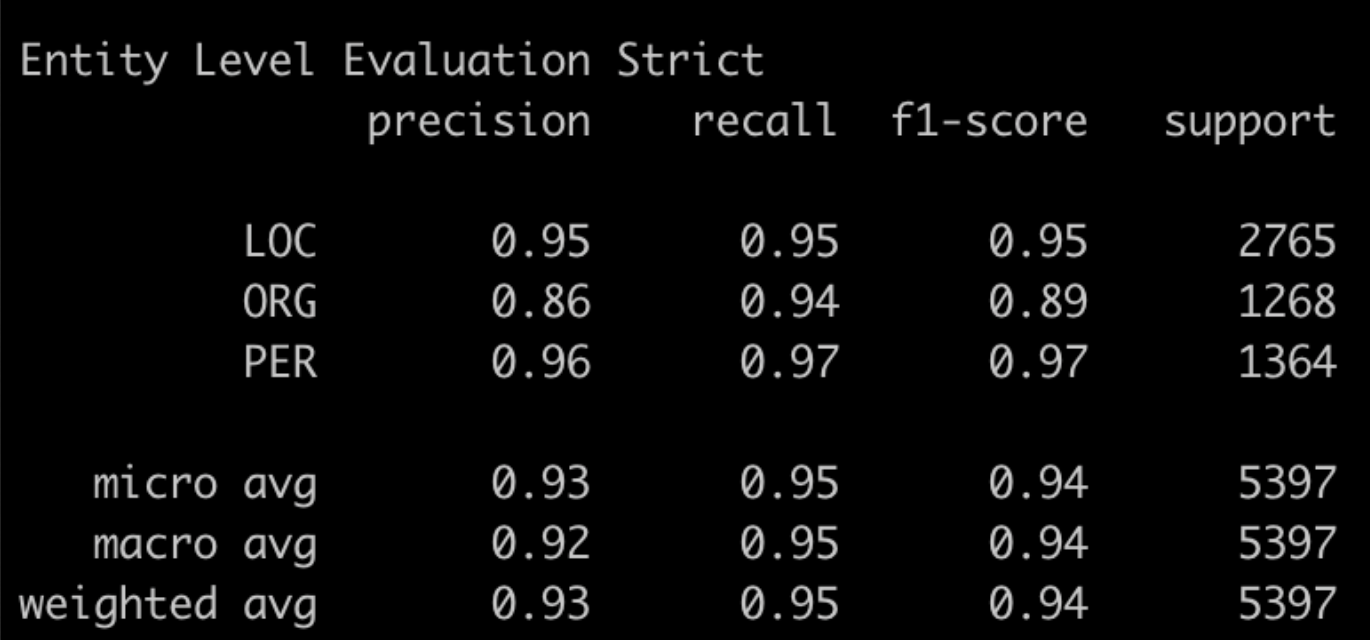
摟了一眼MRC的召回結果,發現個比較有意思的點就是不太符合Query定義的存在一些爭議的case,一般都沒被召回。不確定這是否是由於query引入了較強的先驗資訊帶來的效果~
- ORG中會議類的多數都沒有召回,會議類是否屬於ORG其實有一些模糊,但至少是不包含在ORG的Query定義里的
{"text": "致公黨第十一次全國代表大會是致公黨歷史上一次重要的會議。", "tag": "ORG",
"pred_entity_list": ["致公黨", "致公黨"],
"true_entity_list": ["致公黨第十一次全國代表大會", "致公黨"]}
{"text": "不久前,召開了舉世矚目的第十五次全國代表大會。", "tag": "ORG",
"pred_entity_list": [],
"true_entity_list": [ "第十五次全國代表大會"]}
{"text": "不久前成功召開的第十五次全國代表大會最重要的歷史貢獻是。。。", "tag": "ORG",
"pred_entity_list": [],
"true_entity_list": [第十五次全國代表大會"]}
- 同樣LOC中存在爭議的case,例如月亮,太陽啥的是不是LOC(; ̄ェ ̄),MRC同樣沒有召回
{'text': '東方月正圓紹武圓,可是個絕妙好詞!', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '窗檯前花圃的那叢玫瑰正痴情地吻著如水的月輝,搖曳著美麗的花影。', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '此刻,我不知道彭丹是否也在月下徘徊,是否也在做著自己飛翔的夢?', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '「人有悲歡離合,月有陰晴圓缺,此事古難全!', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '」沒什麼,月亮碎了,心並沒有碎!', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月亮']}
{'text': '從圓明園破碎那天起,鍊石補月的工程,就啟動了。', 'tag': 'LOC',
'pred_entity_list': ['圓明園'],
'true_entity_list': ['圓明園', '月']}
{'text': '月碎了有什麼?', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '月碎了,只能造就出一批又一批、一代又一代的補月能手罷了!', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月', '月']}
{'text': '二十一世紀的月亮,正從東方升起來,圓不圓?', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月亮']}
{'text': '讓人類撕碎撒謊者遮羞的破布,讓歷史記住戰爭的創傷,讓孩子和鴿群一起起飛,在藍天托起和平的太陽。', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['太陽']}
除了Query先驗資訊的影響之外,不確定這裡Data Imbalance的影響有多少,下一章我們試下調整Loss Function看看會不會有進一步的提升~
Reference