分散式NoSQL資料庫MongoDB初體驗-v5.0.5
概述
定義
MongoDB官網 //www.mongodb.com/ 社區版最新版本5.0,其中5.2版本很快也要面世了
MongoDB GitHub源碼 //github.com/mongodb
MongoDB文檔地址 //docs.mongodb.com/manual/
MongoDB是一個流行的開源分散式文檔型資料庫,由 C++ 語言編寫,旨在處理大規模額數據,為 WEB 應用提供可擴展、高性能的數據存儲解決方案。
MongoDB介於關係資料庫和非關係資料庫之間的產品,是非關係資料庫當中功能最豐富,最像關係資料庫的。前面我們學習了MySQL和Elasticsearch,我們本篇後續章節也會學習和聊聊MongoDB與這兩者的故事。
特性
- 面向文檔存儲,MongoDB從存儲結構上使用類似json的bjson格式,這就比關係型資料庫MySQL存儲更靈活些,不需要先定義表結構也讓DDL管理更加簡單,文檔式結構也更容易理解;動態 DDL能力,沒有強Schema約束也讓DDL管理更加簡單,支援更快速迭代。
- 完全分散式、高可用,高性能計算,提供基於記憶體的快速數據查詢。
- 容易擴展,利用數據分片可以支援海量數據存儲,實現自動分片和水平擴展。
- 豐富的功能集,支援二級索引、強大的聚合管道功能、事務、join,為開發者量身定做的功能,如數據自動老化、固定集合等等。MongoDB是NoSQL中最像SQL的資料庫。
- 跨平台版本、支援多語言SDK。
bson和json的區別
bson是一種二進位形式的存儲格式,採用了相似於C 語言結構體的名稱、對表示方法,支援內嵌的文檔對象和數組對象,具備輕量性、可遍歷性、高效性的特色,能夠有效描述非結構化數據和結構化數據,有點相似於Google的Protocol Buffer。
- 更快的遍歷速度:對json格式來講,太大的json結構會導致數據遍歷變慢;在json中要跳過一個文檔進行數據讀取,須要對此文檔進行掃描匹配比如括弧的匹配,而bson將每個元素的長度存在元素的頭部,這樣就可快速讀到指定位置。
- 操做更簡易:對json來講數據存儲是無類型的,比如你要修改值9為10這樣就從一個字元變成了兩個字元,也即是後面的內容都要後移一位因此增加開銷。而使用bson可以指定這個列為數字類型,那麼數字從9改為10甚至是10000,這樣都只是在存儲數字上修改,不會致使數據總長度變化。當時在MongoDB中若是數字從整形增大到長整型那仍是會致使數據總長度變大的。
- 增加額外的數據類型:json是一個很方便的數據交換格式,可是其類型比較有限;bson在其基礎上增長了「byte array」數據類型,這使得二進位的存儲再也不需要先base64轉換後再存成json,大大減小了計算開銷和數據大小。下圖為bson支援數據類型

數據模型與關係型資料庫對比
- database-資料庫,與關係型資料庫(database)概念相同,一個資料庫包含多個集合(表)。
- collection-集合,相當於關係型資料庫中的表(table),一個集合可以存放多個文檔(行)。不同之處就在於集合的結構(schema)是動態的,不需要預先聲明一個嚴格的表結構。更重要的是默認情況下MongoDB 並不會對寫入的數據做任何schema的校驗。
- document-文檔,相當於關係型資料庫中的行(row),一個文檔由多個欄位(列)組成,並採用bson(json)格式表示。
- field-欄位,相當於關係型資料庫中的列(column),相比普通column的差別在於field的類型可以更加靈活比如支援嵌套的文檔、數組,區分大小寫。
- 其他說明
- id-主鍵,MongoDB 默認生成id 欄位來保證文檔的唯一性。
- reference-引用,勉強可以對應於外鍵(foreign key) 的概念,但reference 並沒有實現任何外鍵約束,只是由客戶端(driver)自動進行關聯查詢、轉換的一個特殊類型。
- view-視圖,MongoDB 3.4 開始支援視圖,這個和關係型資料庫的視圖沒有什麼差異,視圖是基於集合之上進行動態查詢的一層對象,可以是虛擬的,也可以是物理的(物化視圖)。
- index-索引,與關係型資料庫的索引相同。
- $lookup-聚合操作符,可以用於實現類似關係型資料庫-join連接的功能。
- transaction-事務,從 MongoDB 4.0 版本開始,提供了對於事務的支援。
- aggregation-聚合,MongoDB 提供了強大的聚合計算框架,group by是其中的一類聚合操作。
Elasticsearch與MongoDB對比
- 相同點
- 存儲格式:MongoDB和Elasticsearch都屬於json格式NoSQL大家族、文檔型數據存儲。
- 可用性和容錯:MongoDB和ElasticSearch作為天生分散式的代表產品都支援數據分片、和副本、複製,兩者都通過分片支援水平擴展, 同時都通過副本來支援高可用
- 分片:一個數據集的數據分為多份, 同時分布在多個節點上存儲和管理, 主流分片有hash分片和range分片這兩種方式,各有優勢, 適合不同的場景。ElasticSearch是hash,Mongo是range和hash。
- 副本:一份數據集同時有一個或者多個複製品(或者叫主從), 每份複製品都一模一樣, 但是為了保證數據的一致性, 往往多個副本中只有一個作為Primary副本(通過選主演算法從多個副本中選出Primary), 提供寫服務, 其他副本只提供讀, 或者只提供備份服務。ElasticSearch和MongoDB都可以通過副本增強讀能力, 而前面我們學習的kafka的副本是只有備份功能。
- 都支援CRUD操作、聚合、簡單版join操作和處理超大規模的數據。MongoDB和ElasticSearch也都支援全文索引, 但是MongoDB的全文索引效果完全無法跟專業的搜索引擎產品ElasticSearch相比,被吊打也是可以理解的。
- 不同點
- 定位:MongoDB是文檔型資料庫, 提供 數據存儲和管理服務,Elasticsearch 是搜索服務, 提供 數據檢索服務;MongoDB作為一個資料庫產品,是擁有源數據管理能力的,Elasticsearch作為一個搜索引擎, 定位是提供數據檢索服務。
- 讀寫能力:Elasticsearch 可以從其他數據源同步數據過來提供查詢, 但是不適合對數據進行存儲和管理,Elasticsearch修改Mapping的代價非常高, 所以我們一般都是把新數據重新寫一份新索引,然後直接切換新索引庫,Elasticsearch更側重數據的查詢, 各種複雜的花式查詢支援的很好。
- 存儲引擎:MongoDB支援的存儲引擎有WiredTiger和In-Memory;WiredTiger按照b-tree的形式來組織並進行擴展,支援兩種基礎文件格式:行存儲和列存儲,其中兩者都是鍵/值存儲的B+ tree實現,還支援日誌結構的合併樹實現也為B+樹;In-Memory將數據只存儲在記憶體中。Elasticsearch底層使用lucene全文檢索引擎作為核心引擎。
- 部署與資源佔用:集群化分片+副本的部署方式, Elasticsearch部署起來比MongoDB方便很多;MongoDB可以支援存儲文件類型的數據, 作為資料庫也有數據壓縮能力, Elasticsearch則因為大量的索引存在需要佔用大量的磁碟和記憶體空間,資源開銷較大。
- 分散式方案:MongoDB是以節點為單位劃分角色, 一旦一個節點被指定為副本, 其上面的數據都是副本;Elasticsearch是以分片為單位劃分角色, 一個節點上即可以擁有某分片的主分片和可以同時擁有另一個分片的副本分片, 同時Elasticsearch還支援自動的副本負載均衡, 如果一個新節點上面什麼數據都沒有, 系統會自動分配分片數據過來。
- MongoDB支援事務,Elasticsearch不支援事務。
- Elasticsearch是Java編寫,通過RESTFul介面操作數據。MongoDB是C++編寫,通過driver操作數據。
- Elasticsearch是天生分散式,主副分片自動分配和複製,開箱即用,而MongoDB的要手動配置,且部署分片集群和配置較為麻煩。
- Elasticsearch偏向於檢索、查詢和數據分析,適用於OLAP(on-line Analytical Processing)系統,MongoDB偏向於大數據下的CRUD,適用於OLTP(on-line Transaction Processing)系統。
- 從時效性上看,Elasticsearch非實時,有丟數據的風險,而MongoDB是實時,理論上無丟數據的風險。
Elasticsearch和MongoDB適合使用場景
- MongoDB
- 對服務可用性和一致性有高要求,MongoDB對傳統RDBMS造成強有力的競爭威脅。
- 無schema的數據存儲+需要索引數據。
- 高讀寫性能要求, 數據使用場景簡單的海量數據場景。
- 有熱點數據, 有數據分片需求的數據存儲。
- 日誌、html、爬蟲數據等半結構化或圖片,影片等非結構化數據的存儲。
- Elasticsearch
- 起初就是以檢索查詢為主要應用場景出道,與RDBMS做相互協助。
- 已經有其他系統負責數據管理。
- 對複雜場景下的查詢需求,對查詢性能有要求, 對寫入及時性要求不高的場景。
- 監控資訊/日誌資訊檢索。
- 小團隊但是有多語言服務,es擁有restful介面,用起來最方便。
分散式集群部署
集群架構
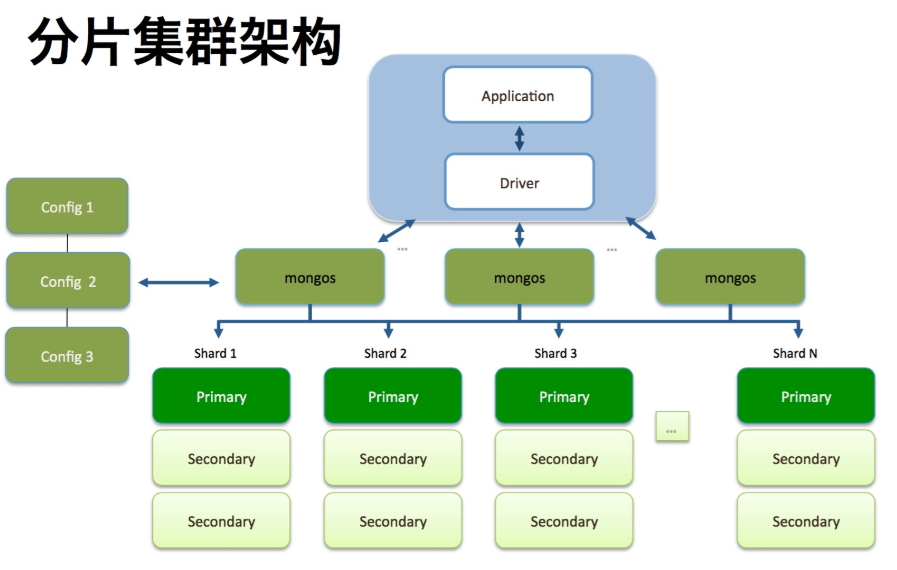
- Shard:分片伺服器:用於存儲實際的數據塊,實際生產環境中一個Shard Server角色可由幾台機器組成一個replica set副本集承擔,防止主機單點故障。
- 分片(sharding)是指將資料庫拆分,將其分散在不同的機器上的過程。將數據分散到不同的機器上,不需要功能強大的伺服器就可以存儲更多的數據和處理更大的負載。基本思想就是將集合切成小塊,這些塊分散到若干片里,每個片只負責總數據的一部分,最後通過一個均衡器來對各個分片進行均衡(數據遷移)。通過一個名為mongos的路由進程進行操作,mongos知道數據和片的對應關係(通過配置伺服器)。大部分使用場景都是解決磁碟空間的問題,對於寫入有可能會變差,查詢則盡量避免跨分片查詢。
- 使用分片的時機
- 機器的磁碟不夠用了。使用分片解決磁碟空間的問題。
- 單個mongod已經不能滿足寫數據的性能要求。通過分片讓寫壓力分散到各個分片上面,使用分片伺服器自身的資源。
- 把大量數據放到記憶體里提高性能,通過分片可以使用到分片伺服器自身的資源。
- Config Server:配置伺服器:mongod實例,存儲了整個 分片群集的配置資訊,其中包括 chunk資訊。
- Mongos:前端路由,客戶端由此接入,且讓整個集群看上去像單一資料庫,前端應用透明化。
部署規劃
前面我們學習了Docker,本篇我們就利用docker-compose來編排部署MongoDB分片集群,那我們就開始練手了
部署一個兩個副本集(每個副本集3個節點)、配置伺服器集群(3個節點)、一個路由節點
一鍵部署腳本
當前目錄下創建scripts文件夾,創建setup.sh、setup-cnf.sh、init-shard.sh和docker-compose.yml文件。
setup.sh內容如下:
#!/bin/bash
mongodb1=`getent hosts ${MONGO1} | awk '{ print $1 }'`
mongodb2=`getent hosts ${MONGO2} | awk '{ print $1 }'`
mongodb3=`getent hosts ${MONGO3} | awk '{ print $1 }'`
port=${PORT:-27017}
echo "Waiting for startup.."
until mongo --host ${mongodb1}:${port} --eval 'quit(db.runCommand({ ping: 1 }).ok ? 0 : 2)' &>/dev/null; do
printf '.'
sleep 1
done
echo "Started.."
echo setup.sh time now: `date +"%T" `
mongo --host ${mongodb1}:${port} <<EOF
var cfg = {
"_id": "${RS}",
"protocolVersion": 1,
"members": [
{
"_id": 0,
"host": "${mongodb1}:${port}"
},
{
"_id": 1,
"host": "${mongodb2}:${port}"
},
{
"_id": 2,
"host": "${mongodb3}:${port}"
}
]
};
rs.initiate(cfg, { force: true });
rs.reconfig(cfg, { force: true });
EOF
setup-cnf.sh內容如下:
#!/bin/bash
mongodb1=`getent hosts ${MONGO1} | awk '{ print $1 }'`
mongodb2=`getent hosts ${MONGO2} | awk '{ print $1 }'`
mongodb3=`getent hosts ${MONGO3} | awk '{ print $1 }'`
port=${PORT:-27017}
echo "Waiting for startup.."
until mongo --host ${mongodb1}:${port} --eval 'quit(db.runCommand({ ping: 1 }).ok ? 0 : 2)' &>/dev/null; do
printf '.'
sleep 1
done
echo "Started.."
echo setup-cnf.sh time now: `date +"%T" `
mongo --host ${mongodb1}:${port} <<EOF
var cfg = {
"_id": "${RS}",
"configsvr": true,
"protocolVersion": 1,
"members": [
{
"_id": 100,
"host": "${mongodb1}:${port}"
},
{
"_id": 101,
"host": "${mongodb2}:${port}"
},
{
"_id": 102,
"host": "${mongodb3}:${port}"
}
]
};
rs.initiate(cfg, { force: true });
rs.reconfig(cfg, { force: true });
EOF
init-shard.sh內容如下:
#!/bin/bash
mongodb1=`getent hosts ${MONGOS} | awk '{ print $1 }'`
mongodb11=`getent hosts ${MONGO11} | awk '{ print $1 }'`
mongodb12=`getent hosts ${MONGO12} | awk '{ print $1 }'`
mongodb13=`getent hosts ${MONGO13} | awk '{ print $1 }'`
mongodb21=`getent hosts ${MONGO21} | awk '{ print $1 }'`
mongodb22=`getent hosts ${MONGO22} | awk '{ print $1 }'`
mongodb23=`getent hosts ${MONGO23} | awk '{ print $1 }'`
mongodb31=`getent hosts ${MONGO31} | awk '{ print $1 }'`
mongodb32=`getent hosts ${MONGO32} | awk '{ print $1 }'`
mongodb33=`getent hosts ${MONGO33} | awk '{ print $1 }'`
port=${PORT:-27017}
echo "Waiting for startup.."
until mongo --host ${mongodb1}:${port} --eval 'quit(db.runCommand({ ping: 1 }).ok ? 0 : 2)' &>/dev/null; do
printf '.'
sleep 1
done
echo "Started.."
echo init-shard.sh time now: `date +"%T" `
mongo --host ${mongodb1}:${port} <<EOF
sh.addShard( "${RS1}/${mongodb11}:${PORT1},${mongodb12}:${PORT2},${mongodb13}:${PORT3}" );
sh.addShard( "${RS2}/${mongodb21}:${PORT1},${mongodb22}:${PORT2},${mongodb23}:${PORT3}" );
sh.status();
EOF
docker-compose.yml內容如下:
version: '3.9'
services:
mongo-1-2:
container_name: "mongo-1-2"
image: mongo:5.0.5
ports:
- "30012:27017"
command: mongod --replSet rs1 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-1-3:
container_name: "mongo-1-3"
image: mongo:5.0.5
ports:
- "30013:27017"
command: mongod --replSet rs1 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-1-1:
container_name: "mongo-1-1"
image: mongo:5.0.5
ports:
- "30011:27017"
command: mongod --replSet rs1 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-rs1-setup:
container_name: "mongo-rs1-setup"
image: mongo:5.0.5
depends_on:
- "mongo-1-1"
- "mongo-1-2"
- "mongo-1-3"
volumes:
- ./scripts:/scripts
environment:
- MONGO1=mongo-1-1
- MONGO2=mongo-1-2
- MONGO3=mongo-1-3
- RS=rs1
entrypoint: [ "/scripts/setup.sh" ]
networks:
- mongo
mongo-2-2:
container_name: "mongo-2-2"
image: mongo:5.0.5
ports:
- "30022:27017"
command: mongod --replSet rs2 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-2-3:
container_name: "mongo-2-3"
image: mongo:5.0.5
ports:
- "30023:27017"
command: mongod --replSet rs2 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-2-1:
container_name: "mongo-2-1"
image: mongo:5.0.5
ports:
- "30021:27017"
command: mongod --replSet rs2 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-rs2-setup:
container_name: "mongo-rs2-setup"
image: mongo:5.0.5
depends_on:
- "mongo-2-1"
- "mongo-2-2"
- "mongo-2-3"
volumes:
- ./scripts:/scripts
environment:
- MONGO1=mongo-2-1
- MONGO2=mongo-2-2
- MONGO3=mongo-2-3
- RS=rs2
entrypoint: [ "/scripts/setup.sh" ]
networks:
- mongo
mongo-cnf-2:
container_name: "mongo-cnf-2"
image: mongo:5.0.5
ports:
- "30102:27017"
command: mongod --replSet cnf-serv --configsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-cnf-3:
container_name: "mongo-cnf-3"
image: mongo:5.0.5
ports:
- "30103:27017"
command: mongod --replSet cnf-serv --configsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-cnf-1:
container_name: "mongo-cnf-1"
image: mongo:5.0.5
ports:
- "30101:27017"
command: mongod --replSet cnf-serv --configsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-cnf-setup:
container_name: "mongo-cnf-setup"
image: mongo:5.0.5
depends_on:
- "mongo-cnf-1"
- "mongo-cnf-2"
- "mongo-cnf-3"
volumes:
- ./scripts:/scripts
environment:
- MONGO1=mongo-cnf-1
- MONGO2=mongo-cnf-2
- MONGO3=mongo-cnf-3
- RS=cnf-serv
- PORT=27017
entrypoint: [ "/scripts/setup-cnf.sh" ]
networks:
- mongo
mongo-router:
container_name: "mongo-router"
image: mongo:5.0.5
ports:
- "30001:27017"
depends_on:
- "mongo-rs1-setup"
- "mongo-rs2-setup"
- "mongo-cnf-setup"
command: mongos --configdb cnf-serv/mongo-cnf-1:27017,mongo-cnf-2:27017,mongo-cnf-3:27017 --port 27017 --bind_ip 0.0.0.0
restart: always
networks:
- mongo
mongo-shard-setup:
container_name: "mongo-shard-setup"
image: mongo:5.0.5
depends_on:
- "mongo-router"
volumes:
- ./scripts:/scripts
environment:
- MONGOS=mongo-router
- MONGO11=mongo-1-1
- MONGO12=mongo-1-2
- MONGO13=mongo-1-3
- MONGO21=mongo-2-1
- MONGO22=mongo-2-2
- MONGO23=mongo-2-3
- RS1=rs1
- RS2=rs2
- PORT=27017
- PORT1=27017
- PORT2=27017
- PORT3=27017
entrypoint: [ "/scripts/init-shard.sh" ]
restart: on-failure:20
networks:
- mongo
networks:
mongo:
driver: bridge
ipam:
config:
- subnet: 10.200.1.10/24
部署
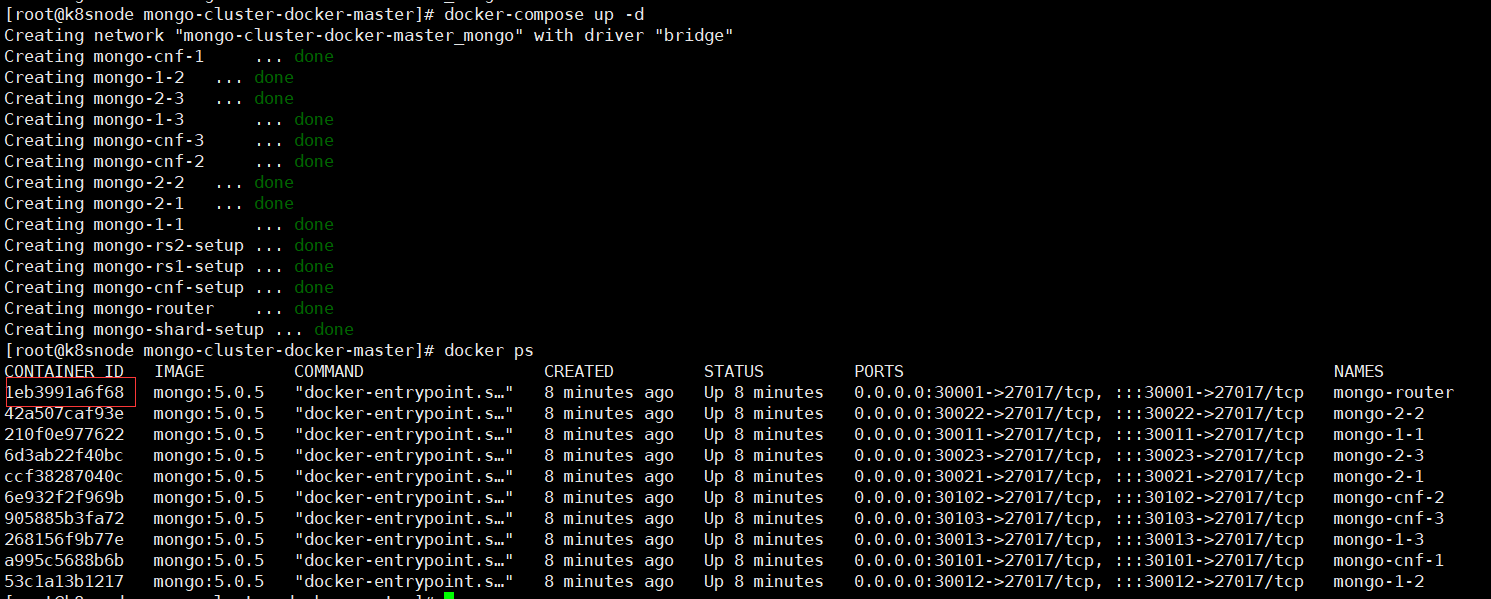
#docker-compose.yml當前目錄下一鍵運行docker-compose,也可以使用-f docker-compose.yml指定文件
docker-compose up -d
#查看運行日誌,至此分片集群啟動和配置完成
docker-compose logs
#查看進程資訊或者docker ps
docker-compose ps
##進入路由節點
docker exec -it 1eb3991a6f68 /bin/bash
## 執行mongo客戶端
mongo
#查看集群分片資訊,目前數據節點由rs1和rs2兩個副本集組成
db.stats()
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-L6lsTfrK-1640346822317)(image-20211224172209608.png)]
#進入一個副本集節點裡
docker exec -it 210f0e977622 /bin/bash
## 執行mongo客戶端
mongo
#查看當前所在副本集的集群節點資訊
rs.status()
實戰
基礎命令
MongoDB基於文檔的管理,官方提供詳細說明,包括插入數據、修改數據、刪除數據、基礎查詢。
spring-boot整合
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
yaml文件配置
spring:
data:
mongodb:
uri: mongodb://192.168.50.95:30001/test
import cn.aotain.entity.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Sort;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import java.util.*;
@SpringBootTest
class GitTestApplicationTests {
@Autowired
private MongoTemplate mongoTemplate;
@Test
//批量插入
void batInsertUser() {
List<User> users = new ArrayList<>();
for (long i = 1; i <= 1000; i++) {
users.add(new User(i,"user"+i, new Random().nextInt(100), UUID.randomUUID().toString(),new Date()));
}
mongoTemplate.insert(users,"user_info");
}
@Test
//查詢全部
public void findAllUser() throws Exception {
List<User> users = mongoTemplate.findAll(User.class,"user_info");
System.out.println("查詢結果:" + users.toString());
}
@Test
//查詢條件
public void findUserByConditionAndSort() {
Query query = new Query(Criteria.where("age").is(62)).with(Sort.by("createTime"));
List<User> users = mongoTemplate.find(query, User.class,"user_info");
users.forEach(System.out::println);
}
@Test
//查詢一個
public void findOneUser(){
Query query = new Query(Criteria.where("userId").is(233L));
User user = mongoTemplate.findOne(query, User.class,"user_info");
System.out.printf(user.toString());
}
}
分片鍵類型
對MongoDB集合進行分片時需要選擇一個片鍵 , 片鍵是每條記錄都必須包含的欄位,且為建立了索引的單個欄位或複合欄位,MongoDB資料庫按照片鍵將數據劃分到不同的數據塊中,並將數據塊均衡地分布到所有分片中。為了按照片鍵劃分數據塊,MongoDB使用基於範圍的分片方式或者基於哈希的分片方式。但需要注意的是一旦集合設置分片並插入文檔之後每個文檔的分片的鍵和值都是不可更改的。如果需要修改文檔的分片鍵,必須要先刪除文檔,再修改分片鍵,然後重新插入文檔。分片鍵也不支援數組索引,文本索引和地理空間索引。
- 基於範圍的分片鍵
- 定義:基於範圍的分片鍵是根據分片鍵值把數據分成一個個鄰接的範圍,如果沒有指定特定的分片類型,則基於範圍的分片鍵是默認的分片類型。
- 特點:基於範圍的分片鍵對於範圍類型的查詢比較高效,給定一個片鍵的範圍,分發路由可以很簡單地確定哪個數據塊存儲了請求需要的數據,並將請求轉發到相應的分片中。
- 使用場景:建議在分片鍵基數較大,頻率較低,並且分片鍵值不是單調變化的情況下使用基於範圍的分片鍵。
- 基於哈希的分片鍵
- 定義:基於哈希的分片鍵是指MongoDB資料庫計算一個欄位的哈希值,並用這個哈希值來創建數據塊。
- 特點:保證了集群中數據的均衡。哈希值的隨機性使數據隨機分布在每個數據塊中,因此也隨機分布在不同分片中。
- 使用場景:如果分片鍵值的基數較大,擁有大量不一樣的值,或者分片鍵值是單調變化的,則建議使用基於哈希的分片鍵。
分片配置
- 基於範圍的分片鍵設置
#基於範圍的分片鍵設置,使用如下命令,開啟資料庫分片開關,參數database表示要開啟分片集合的資料庫
sh.enableSharding(database)
#設置分片鍵,參數namespace表示需要進行分片的目標集合的完整命名空間<database>.<collections>,key表示要設置分片鍵的索引,如果需要進行分片的目標集合是空集合,可以不創建索引直接進行下一步的分片設置,該操作會自動創建索引,如果需要進行分片的目標集合是非空集合,則需要先創建索引key。然後使用如下命令設置分片鍵。
sh.shardCollection(namespace, key)
- 哈希的分片鍵設置
然後再使用如下命令創建基於哈希的分片鍵#基於範圍的分片鍵設置,使用如下命令,開啟資料庫分片開關,參數database表示要開啟分片集合的資料庫
sh.enableSharding(database)
#設置基於哈希的分片鍵,其中numInitialChunks值的估算方法是:db.collection.stats().size / 10*1024*1024*1024。
sh.shardCollection("<database>.<collection>", { <shard key> : "hashed" }* , false, {numInitialChunks: 預置的chunk個數})
#如果集合已經包含數據,則需要先使用如下命令對需要創建的基於哈希的分片鍵先創建哈希索引
db.collection.createIndex()
#然後再使用如下命令創建基於哈希的分片鍵
sh.shardCollection()
分片實驗
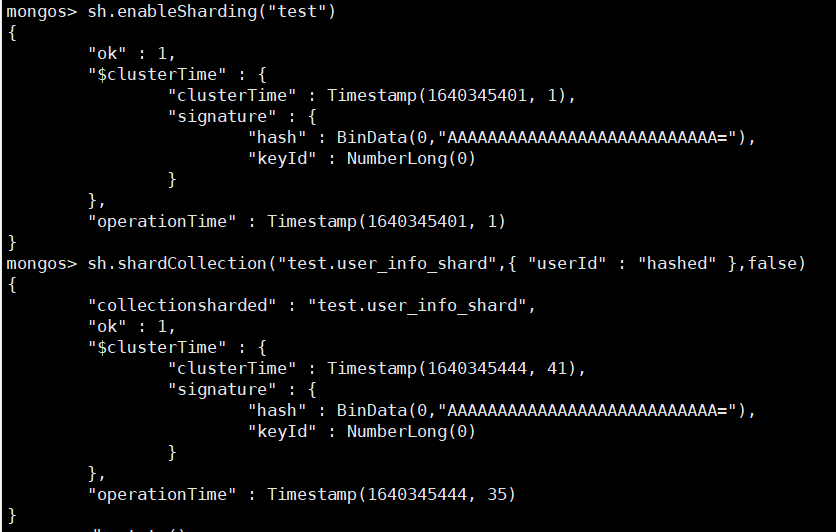
#基於Hash分片
sh.enableSharding("test")
sh.shardCollection("test.user_info_shard",{ "userId" : "hashed" },false)
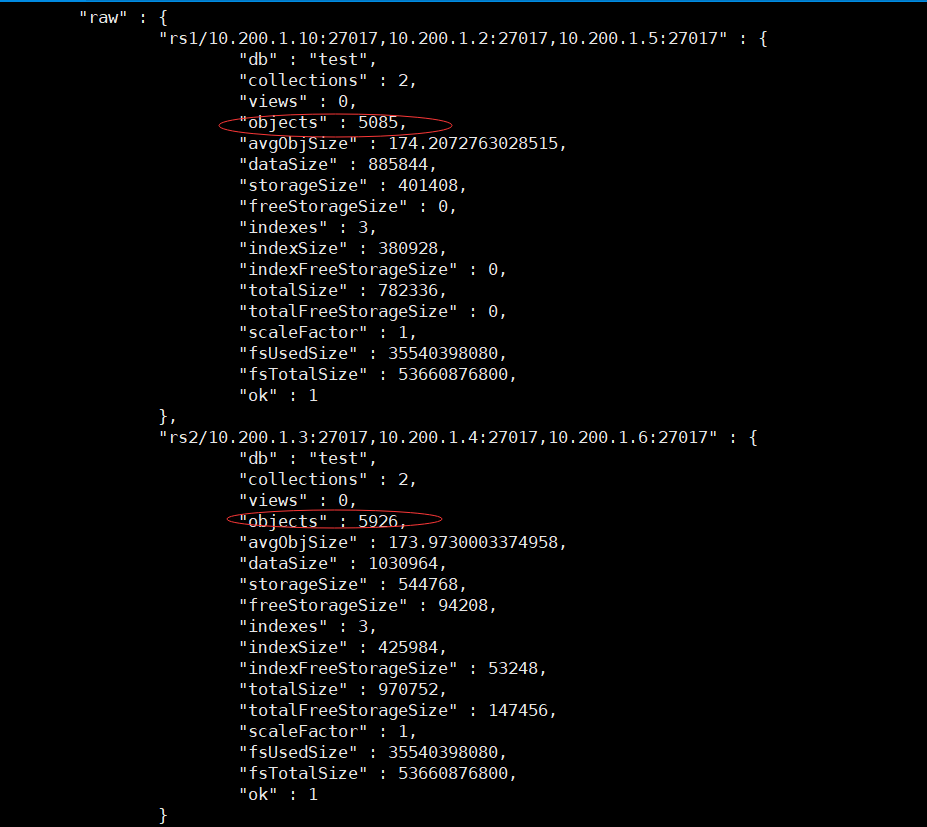
我們往test.user_info_shard集合中插入10000條數據,查看兩個rs中的文檔數可以看到數據已經分散到兩個副本集集群中了。
**本人部落格網站 **IT小神 www.itxiaoshen.com


