GAN 簡介
GAN
原理:
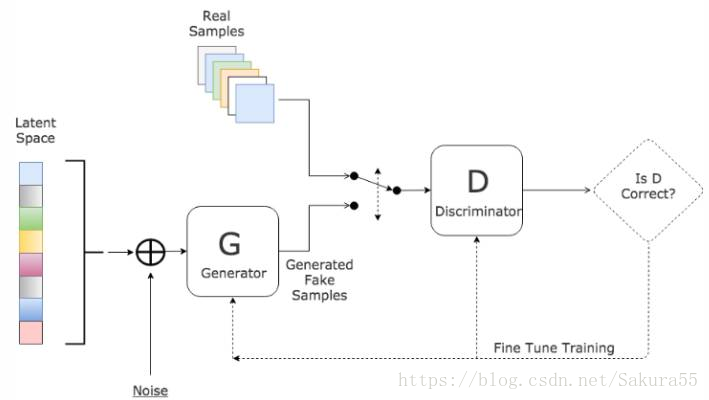
GAN 的主要靈感來源於博弈論中零和博弈的思想,應用到深度學習神經網路上來說,就是通過生成網路 G(Generator)和判別網路 D(Discriminator)不斷博弈,進而使 G 學習到數據的分布,如果用到圖片生成上,則訓練完成後,G 可以從一段隨機數中生成逼真的影像。
- G 是一個生成網路,其輸入為一個隨機噪音,在訓練中捕獲真實數據的分布,從而生成儘可能真實的數據並讓 D 犯錯
- D 是一個判別網路,判別生成的數據是不是「真實的」。它的輸入參數是 x,輸出 D(x) 代表 x 為真實數據的概率,如果為 1,就代表 100% 是真實的數據,而輸出為 0,就代表不可能是真實的數據
為了從數據 x 中學習到生成器的分布 \(p_g\),我們定義一個輸入噪音變數 \(p_z(z)\),然後將其映射到數據空間得到 \(G(z;\theta_g)\)。\(D(x; \theta_d)\) 輸出是一個數,代表 \(x\) 來自真實數據而不是 \(p_g\) 的概率。
&\min_G \max_D V(D,G) = E_{x∼p_{data}(x)}[log(D(x))]+E_{z∼p_{z}(z)}[log(1−D(G(z)))] \qquad ①\\
&訓練 D 來最大化辨別能力:\quad \max_D V(D,G)=E_{x∼p_{data}(x)}[log(D(x))]+E_{z∼p_z(z)}[log(1−D(G(z)))]\qquad② \\
&訓練 G 來最小化log(1−D(G(z))):\quad \min_G V(D,G)=E_{z∼p_z(z)}[log(1−D(G(z)))]\qquad③ \\
\end{aligned}
\]
注:\(\max_D\) 表示令 \(D(x)\) 儘可能大以便找出真實數據,而令 \(D(G(z))\) 儘可能小以便區分出偽造數據,最後導致 ② 式儘可能大;\(\min_G\) 表示令 \(D(G(z))\) 儘可能大從而混淆判別器,最後導致 ③ 式儘可能小。訓練早期,G 的擬合程度很低,D 可以被訓練得很好,導致 log(1-D(G(z))) 趨於 0,進而使回傳梯度很小,導致訓練效果不行。因此,比起 minimize log(1-D(G(z))),maximize log(D(G(z))) 會更好。
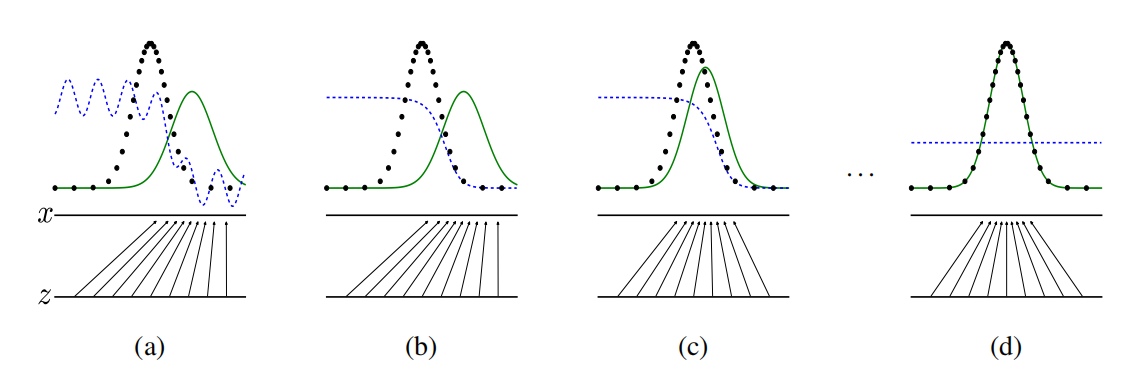
註:將隨機噪音 z 映射到 x 上(x = G(z)),使 x 儘可能擬合真實數據 data 的分布。綠色實線為生成的數據 p_g,黑色點為真實數據 p_data,藍色虛線為判別器 D。每次訓練 G 都使 p_g 儘可能擬合 p_data,而判別器 D 則會調整從而儘可能將 p_g 和 p_data 區分開。當 D(x) = 0.5 時,判別器將無法區分真假。
演算法:

小結:
命題1:當 G 被固定住時,最優的辨別器 D 如下
\]
證明:
&E_{x∼p}f(x) = \int_xp(x)f(x)dx \qquad x = g(z) \\
&V(G, D) = \int_x p_{data}(x)\log{(D(x))}dx + \int_zp_z(z)\log{(1-D(g(z)))}dz = \int_x p_{data}(x)\log{(D(x))} + p_g(x)\log{(1-D(x))}dx\\
&記:V(G, D) = \int_x a \cdot \log(y) + b \cdot \log{(1-y)} dx\qquad \\
&則函數 \quad y \rightarrow a \cdot \log(y) + b \cdot \log{(1-y)} 在 [0, 1]里最大值為:\quad \frac{a}{a+b} = \frac{p_{data}(x)}{p_{data}(x)+p_g(x)}
\end{aligned}
\]
定理1:當且僅當 \(p_g\) = \(p_{data}\) 時, C(G) 取得全局最小值,為 -log4
C(G) &= \max_DV(G, D) = E_{x∼p_{data}}[log(D_G^*(x))]+E_{z∼p_z}[log(1−D_G^*(G(z)))]\\
&= E_{x∼p_{data}}[log(D_G^*(x))]+E_{x∼p_g}[log(1−D_G^*(x)] = E_{x∼p_{data}}[log\frac{p_{data}(x)}{p_{data}(x)+ p_g(x)}]+E_{x∼p_g}[log\frac{p_g(x)}{p_{data}(x)+ p_g(x)}]\\
\end{aligned}
\]
KL 散度:KL(p||q) = \(E_{x∼p}\log{\frac{p(x)}{q(x)}}\)
證明:
&E_{x∼p_{data}}[-\log2] + E_{x∼p_g}[-\log2] = -\log4,則 \\
&C(G) = -\log(4) + KL(p_{data} || \frac{p_{data} + p_g}{2}) + KL(p_g || \frac{p_{data} + p_g}{2})
= -\log(4) + 2 \cdot JSD(p_{data} || p_g) \\
&由於 JSD 非負,且僅當其兩個參數相等時才為 0,故,當 p_{data} = p_g 時 C(G) 取最小值為 -\log(4)
\end{aligned}
\]
命題2:當 G 和 D 有足夠容量,且演算法 1 中我們允許每一步 D 是可以達到他的最優解。那麼如果我們對 G 的優化是去迭代下面這一步驟,則 p_g 會收斂到 p_{data}
\]
優缺點:
特點:
- 相比較傳統的模型,GAN 存在兩個不同的網路,而不是單一的網路,並且訓練方式採用的是對抗訓練方式
- GAN 中 G 的梯度更新資訊來自判別器 D,而不是來自數據樣本
優點:
- GAN 是一種生成式模型,相比較其他生成模型(玻爾茲曼機和GSNs)只用到了反向傳播,而不需要複雜的馬爾科夫鏈
- 相比其他所有模型, GAN 可以產生更加清晰、真實的樣本
對 f 期望的求導等價於對 f 自己求導 => 通過誤差的反向傳遞對 GAN 進行求解:\(\lim_{\sigma\rightarrow0}\nabla_xE_{\epsilon∼N(0, \sigma^2I)}f(x+\epsilon) = \nabla_xf(x)\)
- GAN 採用的是一種無監督學習方式訓練,可以被廣泛用在無監督學習和半監督學習領域。但卻用一個有監督學習的損失函數來做無監督學習,在訓練上會高效很多
- 相比於變分自編碼器(VAE),GANs 沒有引入任何決定性偏置( deterministic bias),變分方法引入決定性偏置。因為他們優化對數似然的下界,而不是似然度本身,這導致了 VAEs 生成的實例比 GANs 更模糊
- 相比 VAE,GANs 沒有變分下界,如果鑒別器訓練良好,那麼生成器可以完美的學習到訓練樣本的分布。換句話說,GANs 是漸進一致的,而 VAE 是有偏差的
 由於 GAN 的無監督,在生成過程中,G 就會按照自己的意思天馬行空生成一些「詭異」的圖片,可怕的是 D 還可能給一個很高的分數。這就是無監督目的性不強所導致的,所以在同年的NIPS大會上,有一篇論文 conditional GAN 就加入了監督性進去,將可控性增強,表現效果也好很多
由於 GAN 的無監督,在生成過程中,G 就會按照自己的意思天馬行空生成一些「詭異」的圖片,可怕的是 D 還可能給一個很高的分數。這就是無監督目的性不強所導致的,所以在同年的NIPS大會上,有一篇論文 conditional GAN 就加入了監督性進去,將可控性增強,表現效果也好很多
缺點:
- 訓練GAN需要達到納什均衡,有時候可以用梯度下降法做到,但有時候做不到。我們還沒有找到很好的達到納什均衡的方法,所以訓練 GAN 相比 VAE 或者 PixelRNN 是不穩定的,但我認為在實踐中它還是比訓練玻爾茲曼機穩定的多
- GAN 不適合處理離散形式的數據,比如文本
- GAN 存在訓練不穩定、梯度消失、模式崩潰的問題(目前已解決)
 GAN 的目的是在高維非凸的參數空間中找到納什均衡點,GAN 的納什均衡點是一個鞍點,但是 SGD 只會找到局部極小值,因為 SGD 解決的是一個尋找最小值的問題,GAN 是一個博弈問題。同時,SGD容易震蕩,容易使GAN訓練不穩定。因此,GAN 中的優化器不常用 SGD
GAN 的目的是在高維非凸的參數空間中找到納什均衡點,GAN 的納什均衡點是一個鞍點,但是 SGD 只會找到局部極小值,因為 SGD 解決的是一個尋找最小值的問題,GAN 是一個博弈問題。同時,SGD容易震蕩,容易使GAN訓練不穩定。因此,GAN 中的優化器不常用 SGD
補充:Generative Adversarial Net、GAN(生成對抗神經網路)原理解析、簡單理解與實驗生成對抗網路GAN、blogs from CSDN


