基於MCRA-OMLSA的語音降噪(一):原理
前面的幾篇文章講了webRTC中的語音降噪。最近又用到了基於MCRA-OMLSA的語音降噪,就學習了原理並且軟體實現了它。MCRA主要用於雜訊估計,OMLSA是基於估計出來的雜訊去做降噪。類比於webRTC中的降噪方法,也有雜訊估計(分位數雜訊估計法)和基於估計出來的雜訊降噪(維納濾波),MCRA就相當於分位數雜訊估計法,OMLSA就相當於維納濾波。本文先講講怎麼用MCRA和OMLSA來做語音降噪的原理,後續會講怎麼來做軟體實現。
一, MCRA
MCRA的全稱是Minima Controlled Recursive Averaging(最小值控制的遞歸平均),是cohen提出的一種常用的雜訊估計方法,具體見論文《Noise Estimation by Minima Controlled Recursive Averaging for Robust Speech Enhancement》。 從名字就可看出這個方法主要包括兩部分,最小值控制和遞歸平均。 最小值控制用來算語音存在概率,遞歸平均用來做雜訊估計,即基於語音存在概率做雜訊估計。先定義一些名稱,然後分別看這兩部分。用l表示第l幀,k表示第k個頻點,Y(k, l)表示帶噪語音第l幀的第k個頻點的幅度譜,N(k, l)表示雜訊第l幀的第k個頻點的幅度譜,S(k, l)表示乾淨語音第l幀的第k個頻點的幅度譜,H0(k, l)表示第l幀的第k個頻點上只有雜訊,H1(k, l)表示第l幀的第k個頻點上有語音。P(H1(k, l) | Y(k, l)) 表示第l幀的第k個頻點上是語音的概率,P(H0(k, l) | Y(k, l)) 表示第l幀的第k個頻點上是雜訊的概率,顯然P(H0(k, l) | Y(k, l)) + P(H1(k, l) | Y(k, l)) = 1。
1, 用最小值控制來算語音存在概率
前面的文章( webRTC中語音降噪模組ANS細節詳解(四) )講過webRTC的ANS是基於似然比等來算語音存在概率。而這裡是用最小值控制來算語音存在概率,即基於當前帶噪語音的能量譜與指定長度幀內帶噪語音的能量譜的最小值的比值來計算,具體如下:
1) 對帶噪語音的能量譜做頻域平滑和時域平滑
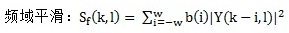
從上式可見,平滑窗的長度是奇數(2w + 1),係數是b(i)。
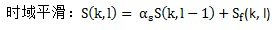
其中,αs (0 < αs < 1)是平滑因子。
2) 搜索能量譜最小值
定義Smin(k, l)和Stmp(k, l),並對它們初始化如下:

然後按頻點從第一幀開始逐幀比較:
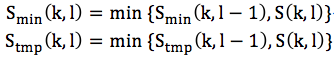
當到第L幀後:
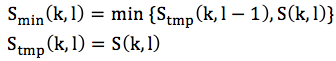
後面以L幀為一個周期,重複上面兩步,得到這個周期內的Smin(k, l)和Stmp(k, l)。搜索窗的幀長度L會影響到雜訊的跟蹤速度,一般按照經驗選0.5s~1.5s左右。
3) 計算語音存在概率
定義Sr(k, l)為當前幀相應頻點的能量譜與最小值的比值,即
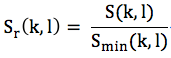
再定義二值I (k, l)如下:
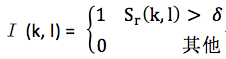
最終語音存在概率通過下式得到:
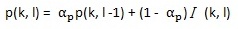
其中,αp (0 < αp < 1)是平滑因子。此處的p(k, l)就是P(H1(k, l) | Y(k, l))。為書寫方便,下文用p表示P(H1(k, l) | Y(k, l)),用1-p表示P(H0(k, l) | Y(k, l))。
2, 用遞歸平均來估計雜訊
通常認為雜訊都是加性雜訊,所以有下式:
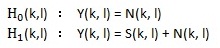
定義σ(k, l)表示第l幀的第k個頻點上的雜訊能量譜。這裡雜訊更新的思路如下:當語音不存在時更新雜訊的估計,當語言存在時用前一幀的雜訊估計值作為當前雜訊的估計值,表示如下式:
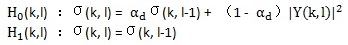
其中,αd (0 < αd < 1)是平滑因子。
所以雜訊能量譜的估計如下式(p = P(H1(k, l) | Y(k, l)),為語音存在概率):
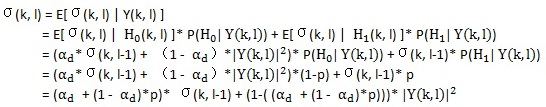
αd是tuning出來的,每個頻點上的語音存在概率是上面基於最小控制的方法算出來的,上一幀估計出來的雜訊能量譜σ(k, l-1)和當前幀的帶噪語音的能量譜均已知,這樣當前幀的估計出來的雜訊的能量譜就可求出了。
通常令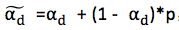 ,這樣上式就可寫成下式:
,這樣上式就可寫成下式:
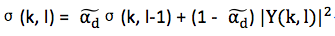
這就是雜訊估計的數學表達式。
二, OMLSA
雜訊估計出來後就要基於它做降噪了。這裡用的是OMLSA(Optimally Modified Log-Spectral Amplitude Estimator,最優修正的對數幅度譜估計),依舊是cohen提出來的,論文是《Optimal Speech Enhancement Under Signal Presence Uncertainty Using Log-Spectral Amplitude Estimator》。OMLSA是MMSE-LSA的改進演算法,目的是得到增益gain。演算法推導有些複雜,這裡只給出gain的表達式,如下:
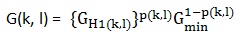
其中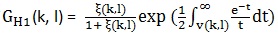 ,Gmin為預先設定的值,p(k, l)是語音存在概率。這裡
,Gmin為預先設定的值,p(k, l)是語音存在概率。這裡 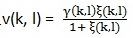 , ξ(k, l)是先驗性噪比,γ(k, l)是後驗性噪比。先驗性噪比和後驗性噪比在文章(webRTC中語音降噪模組ANS細節詳解(一) )中講過。後驗性噪比的計算基於上面用MCRA估計出來的雜訊,
, ξ(k, l)是先驗性噪比,γ(k, l)是後驗性噪比。先驗性噪比和後驗性噪比在文章(webRTC中語音降噪模組ANS細節詳解(一) )中講過。後驗性噪比的計算基於上面用MCRA估計出來的雜訊, , 先驗性噪比計算依舊用文章( webRTC中語音降噪模組ANS細節詳解(三) )中提到的DD方法,表達式如下:
, 先驗性噪比計算依舊用文章( webRTC中語音降噪模組ANS細節詳解(三) )中提到的DD方法,表達式如下:
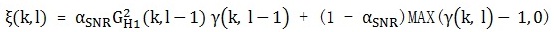
其中,αSNR (0 < αSNR < 1)是平滑因子。
G(k, l)得到後,降噪後乾淨語音的每個頻點的幅度譜可通過下式得到:
S(k, l) = G(K, l)Y(k, l)
以上就是基於MCRA-OMLSA的語音降噪原理。這裡需要指出的是雜訊估計和語音降噪相對獨立,有不同的組合方式來降噪,比如MCRA也可以和維納濾波結合來降噪。


