mmap
開始之前,先看張圖。
Linux IO Stack
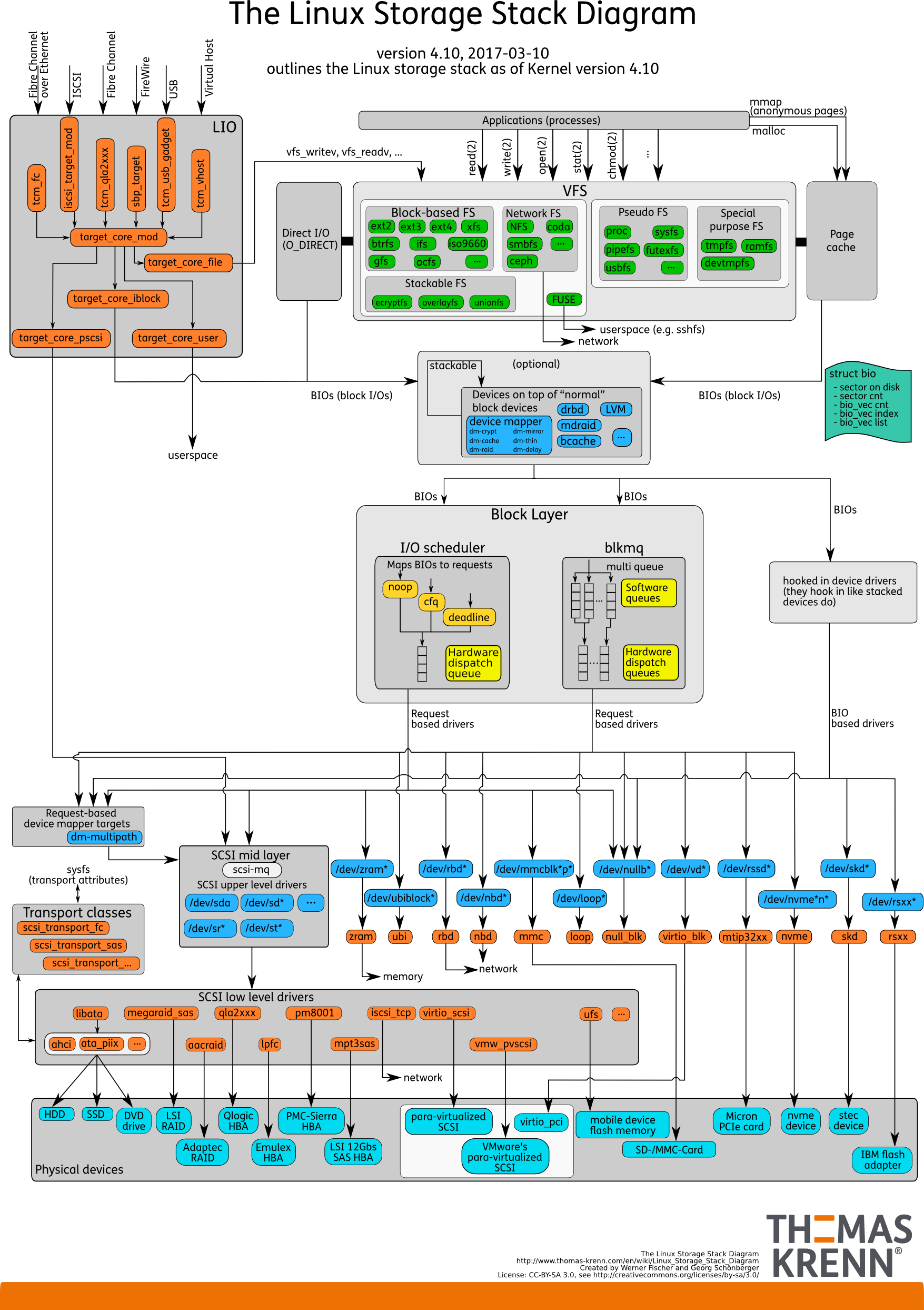
1.0 版本://www.ilinuxkernel.com/files/Linux.IO.stack_v1.0.pdf
常規做法
在大多數場景下,我們都是通過下面的方式進行 IO 訪問:
int fd = open(filename, flags, mode);
read(fd, buffer, size);
那麼其 function call stack 實際上是:
readsys_readvfs_read: 判斷是否命中 Page Cache,命中則直接返回,否則產生 PAGE FAULT,分配記憶體頁,讀入文件內容。- 內核向塊設備層 (Generic Block Layer) 發起 IO 請求,塊設備層的職責是屏蔽 SSD/HDD/U盤 等存儲設備的差異。
- IO 請求到達 IO Scheduler ,後面是真正的硬體 IO (在此先不關心硬體層面的 IO )。
那麼 IO 調度的意義是什麼呢?
在 SSD 之前,我們都用機械硬碟 HDD 作為存儲設備,HDD 有磁頭、磁軌、轉速等概念,磁軌上的每個扇區存放著數據,因此 IO Scheduler 一個淺顯的作用就是:產生一個比較好的 IO 請求序列,使得磁頭走過的路程是最短的。這一點也有助於減少進程的平均阻塞時間。
標記位 O_DIRECT
從上面的圖可以看出,在 Linux 中,把硬碟統一抽象為塊設備 (Block Device) 進行管理。
從用戶的角度來看,是直接面向 VFS 編程的,使用基本的 open/close/write/read 等 API 對文件進行讀寫操作,但在 VFS 中,會使用記憶體對文件進行快取,也就是說,我們在 write 調用的時候,寫入的只是 Cache 或者記憶體,而不是真正的文件,這是所謂的延遲寫 (Delayed Write)。
那是在什麼時候,我們寫入的內容會真正落在硬碟上呢?參考 fsync, fdatasync, sync .
在某些場景下(比如資料庫,新型存儲系統),我們希望儘可能減少數據的拷貝次數,譬如繞過 VFS 的 Page Cache ,這時候我們可以通過標記位 O_DIRECT 或者 mmap 來實現。
在 Linux I/O Stack 1.0 的版本當中,
O_DIRECT可繞過 VFS 維護的 Cache,直達文件系統,但文件系統本身也會快取,最理想的情況是通過mmap直達通用塊設備 IO 層 (Generic Block Device) 。
man 2 open 中對 O_DIRECT 的說明:
Try to minimize cache effects of the I/O to and from this file. In general this will degrade performance, but it is useful in special situations, such as when applications do their own caching. File I/O is done directly to/from user-space buffers. The O_DIRECT flag on its own makes an effort to transfer data synchronously, but does not give the guarantees of the O_SYNC flag that data and necessary metadata are transferred. To guarantee synchronous I/O, O_SYNC must be used in addition to O_DIRECT.
從上面的描述可以看出, O_DIRECT 並不保證數據可以直接寫到硬碟上,如果需要保證數據真正落盤,那麼需要結合 O_SYNC 使用。但這樣的話,IO 操作就會變成同步 IO ,如果 IO Scheduler 收到大量這樣的 IO 請求,那麼這樣的 IO 請求會被阻塞(這顯然不是一件好事情)。
Linus 本人似乎對 O_DIRECT 這一做法十分不屑:
“The thing that has always disturbed me about
O_DIRECTis that the whole interface is just stupid, and was probably designed by a deranged monkey on some serious mind-controlling substances.” –Linus
記憶體映射 mmap
mmap 即 memory mapping ,將一塊物理記憶體映射到某個文件上(通過文件描述符 fd 指定),一種典型的 zero-copy 機制,mmap 可以減少一次 kernel -> user space 的數據拷貝。

注意,此處的文件,指的是 VFS 概念下的文件,可以是 socket-fd, file-fd, shm-fd, pipe-fd 等,下同。
通過這個 API ,我們可以做到:
- 像訪問記憶體一樣,去讀/寫/複製文件的內容,並減少數據拷貝。
- 結合
shm_open使用,實現進程之間的共享記憶體。 - 如果文件很大,我們又想對文件進行隨機讀寫,那麼
mmap比使用常規文件讀寫要好。
API 定義:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
描述:
- 在調用
mmap的時候,並不會真正分配物理記憶體。 - 完成
mmap之後,如果我們訪問[addr, addr + length)這一區間的地址,那麼會產生缺頁中斷,這時候才會真正分配一塊物理記憶體,載入fd的內容。
參數說明:
-
addr如果是 NIL ,那麼內核會自動在進程的虛擬地址空間中選擇一塊地址空間去映射(想想進程空間中堆和棧之間是什麼區域?),因此一般我們默認填 NULL ;如果addr是用戶自定義的地址,並且位於有效的進程映射地址空間範圍內,那麼在addr頁對齊後的位置開始映射。 -
length需要映射的長度。 -
prot描述物理記憶體的屬性:PROT_EXEC Pages may be executed. PROT_READ Pages may be read. PROT_WRITE Pages may be written. PROT_NONE Pages may not be accessed. -
flags描述的是,對於[addr, addr + length)這一地址空間的修改是否是共享的,是否會把修改 flush 到文件上。The flags argument determines whether updates to the mapping are visible to other processes mapping the same region, and whether updates are carried through to the underlying file. This behavior is determined by including exactly one of the following values in flags: - MAP_SHARED Share this mapping. Updates to the mapping are visible to other processes mapping the same region, and (in the case of file-backed mappings) are carried through to the underlying file. (To precisely control when updates are carried through to the underlying file requires the use of msync(2).) - MAP_PRIVATE Create a private copy-on-write mapping. Updates to the mapping are not visible to other processes mapping the same file, and are not carried through to the underlying file. It is unspecified whether changes made to the file after the mmap() call are visible in the mapped region.更多
flags標記位的含義請查看man mmap。 -
fd是需要映射的文件描述符,offset表示文件內的偏移量,從該位置開始映射。
SHARED 和 PRIVATE
下面分別是 2 種 mmap 模式的行為示意圖。
- SHARED 表示所有對映射記憶體的修改都會 “同步” 在映射的對象上,典型的場景是進程之間共享記憶體。
- PRIVATE 採用的是 copy-on-write 的模式,如果沒有進程改動映射記憶體,那麼所有進程都共同讀取某一個物理頁;一旦有修改,會拷貝該頁面,新頁面會成為修改進程的 PRIVATE 頁面。
- 比較典型的場景是:
fork開啟一個子進程,如果子進程對數據是只讀的,在 OS 層面,子進程和父進程都共用數據段和程式碼段,如果修改了某一個buffer,那麼 OS 將會發生 copy-on-write ,這個buffer將會有 2 個實體,位於不同的物理記憶體頁。
- 比較典型的場景是:
| SHARED | PRIVATE |
|---|---|
 |
 |
假設我們有這麼一段程式碼:
#include <stdio.h>
int main()
{
puts("");
while (1);
}
通過 ./a.out & 在後台運行,並通過 cat /proc/$pid/maps 查看進程的地址空間映射:
...
5630be30c000-5630be32d000 rw-p 00000000 [heap]
7f05d579b000-7f05d57c0000 r--p 00000000 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f05d57c0000-7f05d5938000 r-xp 00025000 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f05d5938000-7f05d5982000 r--p 0019d000 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f05d5982000-7f05d5983000 ---p 001e7000 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f05d5983000-7f05d5986000 r--p 001e7000 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f05d5986000-7f05d5989000 rw-p 001ea000 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f05d5989000-7f05d598f000 rw-p 00000000
7f05d599f000-7f05d59a0000 r--p 00000000 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f05d59a0000-7f05d59c3000 r-xp 00001000 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f05d59c3000-7f05d59cb000 r--p 00024000 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f05d59cc000-7f05d59cd000 r--p 0002c000 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f05d59cd000-7f05d59ce000 rw-p 0002d000 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f05d59ce000-7f05d59cf000 rw-p 00000000
7ffc57b20000-7ffc57b41000 rw-p 00000000 [stack]
7ffc57b85000-7ffc57b89000 r--p 00000000 [vvar]
7ffc57b89000-7ffc57b8b000 r-xp 00000000 [vdso]
...
puts, printf 等函數的二進位程式碼都是位於 libc.so 這個動態鏈接庫當中(當然我們可以通過編譯參數指定靜態鏈接),當程式中使用了這些函數時,才會通過 mmap 建立映射。
我們再使用 strace 來追蹤 a.out 的系統調用棧。
execve("./a.out", ["./a.out"], 0x7fff9b085890 /* 33 vars */) = 0
brk(NULL) = 0x562755d26000
arch_prctl(0x3001 /* ARCH_??? */, 0x7ffd09c585d0) = -1 EINVAL (無效的參數)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (沒有那個文件或目錄)
# 首先載入了鏈接器的程式碼 ld.so
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=61731, ...}) = 0
mmap(NULL, 61731, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f1eeacca000
close(3) = 0
# 打開 libc.so 鏈接庫文件
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\360q\2\0\0\0\0\0"..., 832) = 832
pread64(3, "\6\0\0\0\4\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0"..., 784, 64) = 784
# ...
# 映射文件上的函數到虛擬地址空間
mmap(0x7f1eeaafb000, 1540096, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x25000) = 0x7f1eeaafb000
mmap(0x7f1eeac73000, 303104, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x19d000) = 0x7f1eeac73000
mmap(0x7f1eeacbe000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1e7000) = 0x7f1eeacbe000
mmap(0x7f1eeacc4000, 13528, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f1eeacc4000
close(3) = 0
# ...
# puts("")
write(1, "\n", 1) = 1
在 Shell 執行某個命令 cmd 的時候,其大概的執行邏輯是:
- fork 一個子進程。
- 在子進程中,通過
exec函數載入cmd的二進位文件並執行。
在上面的輸出中:
- 首先載入了鏈接器的程式碼
ld.so.
ld.so其實就是鏈接器的二進位程式碼。根據man ld.so的描繪:The programs ld.so and ld-linux.so* find and load the shared objects (shared libraries) needed by a program, prepare the program to run, and then run it.
- 然後打開共享鏈接庫的文件
libc.so。 - 最後是把
libc.so文件上的二進位程式碼(幾個函數的地址)映射到進程的虛擬地址空間,文件偏移量0x25000, 0x19d000等,可以與/proc/{pid}/maps的輸出對應。
注意到,上述的 mmap 是使用 MAP_PRIVATE|MAP_DENYWRITE 這 2 個標記的,為什麼 printf, puts 這些程式碼理應是只讀的,為什麼需要這樣做呢?
考慮 strtok 這個庫函數,內部實現使用了一個 static 變數來記錄上一次截斷的位置。因此,雖然 printf 是只讀的,但 libc 中的其他函數是有可能發生數據修改的。參考 Apple 的一個實現。
共享記憶體
首先看第一個進程 p1.c:
#include <fcntl.h> /* For O_* constants */
#include <sys/mman.h>
#include <sys/stat.h> /* For mode constants */
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const int len = 1024;
const char *name = "shm1";
int shmfd = shm_open(name, O_RDWR | O_CREAT, 0777);
if (shmfd == -1)
exit(EXIT_FAILURE);
// extend shared memory object as by default it's initialized with size 0
if (ftruncate(shmfd, len) == -1)
exit(EXIT_FAILURE);
void *addr = mmap(NULL, len, PROT_READ | PROT_WRITE, MAP_SHARED, shmfd, 0);
memcpy(addr, "hello", 6);
if (addr == MAP_FAILED)
exit(EXIT_FAILURE);
munmap(addr, len);
}
注意,這裡並沒有 shm_unlink 解除共享記憶體,也就是說這塊記憶體在 p1 結束後,依然存在於內核中。
編譯運行:
gcc p1.c -o p1 -lrt
./p1
然後:
$ cat /dev/shm/shm1
hello
第二個進程 p2.c:
#include <fcntl.h> /* For O_* constants */
#include <sys/mman.h>
#include <sys/stat.h> /* For mode constants */
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const int len = 1024;
const char *name = "shm1";
int shmfd = shm_open(name, O_RDWR | O_CREAT, 0777);
if (shmfd == -1)
exit(EXIT_FAILURE);
void *addr = mmap(NULL, len, PROT_READ | PROT_WRITE, MAP_SHARED, shmfd, 0);
puts(addr);
if (addr == MAP_FAILED)
exit(EXIT_FAILURE);
munmap(addr, len);
shm_unlink(name);
}
類似的方法編譯運行,puts(addr) 會輸出 hello 。當 ls /dev/shm 時,shm1 文件不存在,因為執行了 unlink 。
文件隨機訪問
首先使用 dd 命令創建一個 4G 的文件 empty.file 。
$ ls -lh empty.file
-rw-r--r-- 1 xxx xxx 4.0G Dec 16 18:22 empty.file
現在對這個文件進行隨機讀操作:
- 每次讀取 4096 位元組到棧上的一個
buffer - 隨機讀取
1e6次
如果使用 lseek, read 等操作進行隨機讀寫:
#include <fcntl.h> /* For O_* constants */
#include <sys/mman.h>
#include <sys/stat.h> /* For mode constants */
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdint.h>
#include <time.h>
int main()
{
srand(time(NULL));
uint64_t size = (uint64_t)4 * 1024 * 1024 * 1024;
uint64_t counter = (uint64_t)(1e6);
int fd = open("./empty.file", O_RDONLY);
char buf[4096];
for (uint64_t i = 0; i < counter; ++i)
{
off_t offset = (uint64_t)rand() % size;
lseek(fd, offset, SEEK_SET);
read(fd, buf, 4096);
}
close(fd);
}
如果使用 mmap 進行文件隨機讀寫:
#include <fcntl.h> /* For O_* constants */
#include <sys/mman.h>
#include <sys/stat.h> /* For mode constants */
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdint.h>
#include <time.h>
int main()
{
srand(time(NULL));
uint64_t size = (uint64_t)4 * 1024 * 1024 * 1024;
uint64_t counter = (uint64_t)(1e6);
int fd = open("./empty.file", O_RDONLY);
void *addr = mmap(NULL, size, PROT_READ, MAP_PRIVATE, fd, 0);
if (addr == MAP_FAILED)
{
puts("mmap failed");
exit(EXIT_FAILURE);
}
char buf[4096];
for (uint64_t i = 0; i < counter; ++i)
{
off_t offset = (uint64_t)rand() % size;
memcpy(buf, addr + offset, 4096);
}
munmap(addr, size);
close(fd);
}
執行時間對比
使用自帶的 time 命令去觀察執行時間:
# 常規用法隨機讀寫
$ time ./common
real 0m2.137s
user 0m0.111s
sys 0m2.024s
# mmap 隨機讀寫
$ time ./mmap
real 0m0.952s
user 0m0.818s
sys 0m0.134s
三個時間指標的含義:
參考 StackOverflow .
- Real is wall clock time – time from start to finish of the call. This is all elapsed time including time slices used by other processes and time the process spends blocked (for example if it is waiting for I/O to complete).
- User is the amount of CPU time spent in user-mode code (outside the kernel) within the process. This is only actual CPU time used in executing the process. Other processes and time the process spends blocked do not count towards this figure.
- Sys is the amount of CPU time spent in the kernel within the process. This means executing CPU time spent in system calls within the kernel, as opposed to library code, which is still running in user-space. Like ‘user’, this is only CPU time used by the process. See below for a brief description of kernel mode (also known as ‘supervisor’ mode) and the system call mechanism.
一個比較直觀的理解是:real 絕對值越小,user 佔比越高,說明程式的 IO 性能越好。
mmap 隨機讀寫比常規做法好在哪裡呢?
- 在常規讀寫中,第一次調用
read(fd, offset, buf)時會預讀取offset附近的若干頁到記憶體中(這麼設計的依據是局部性原理),但這裡的場景是隨機讀寫,因此局部性原理並不起效,相反還帶來了許多額外的開銷,預讀取了訪問概率較小的文件頁。此外,這種做法會引入 C 函數庫、內核等各個 IO 層次的快取,在用戶空間讀取的記憶體,實際上有多次的數據拷貝。 - 在
mmap中,每次訪問ptr = addr + offset這一地址,首先看ptr是否在記憶體中,不存在則產生缺頁中斷,讀取硬碟,每次僅讀取ptr所在的頁。並且是從memory <- block io的。
PAGE FAULT 對比
如果使用 perf 命令,還能看到缺頁中斷等資訊:
$ perf stat ./common
Performance counter stats for './common':
1891.44 msec task-clock:u # 0.999 CPUs utilized
0 context-switches:u # 0.000 K/sec
0 cpu-migrations:u # 0.000 K/sec
41 page-faults:u # 0.022 K/sec
161839663 cycles:u # 0.086 GHz
84068713 instructions:u # 0.52 insn per cycle
27018959 branches:u # 14.285 M/sec
48067 branch-misses:u # 0.18% of all branches
1.893381243 seconds time elapsed
0.113070000 seconds user
1.779353000 seconds sys
$ perf stat ./mmap
Performance counter stats for './mmap':
947.04 msec task-clock:u # 0.997 CPUs utilized
0 context-switches:u # 0.000 K/sec
0 cpu-migrations:u # 0.000 K/sec
32807 page-faults:u # 0.035 M/sec
2443079663 cycles:u # 2.580 GHz
67103101 instructions:u # 0.03 insn per cycle
16052590 branches:u # 16.950 M/sec
34696 branch-misses:u # 0.22% of all branches
0.949602420 seconds time elapsed
0.817763000 seconds user
0.130103000 seconds sys
從上面的輸出可以看出,常規操作的預讀機制使得其 PAGE FAULT 遠遠少於 mmap(要知道一次缺頁中斷的開銷是非常高的),但性能還是不如 mmap ,即使測試機器的記憶體是 8G 的,能夠快取整個文件到記憶體中。由於此處的場景是隨機讀寫,預讀並不能很好提高記憶體命中的概率,反而帶來了額外的讀取開銷。
Refs
- [1] read 文件一個位元組實際會發生多大的磁碟 IO ?
- [2] 淺談 Linux 內核 IO 體系之磁碟 IO
- [3] //www.thomas-krenn.com/en/wiki/Linux_Storage_Stack_Diagram
- [4] 圖片來源於 CSAPP – 3e


