Pytorch入門上 —— Dataset、Tensorboard、Transforms、Dataloader
本節內容參照小土堆的pytorch入門影片教程。學習時建議多讀源碼,通過源碼中的注釋可以快速弄清楚類或函數的作用以及輸入輸出類型。
Dataset
借用Dataset可以快速訪問深度學習需要的數據,例如我們需要訪問如下訓練數據:
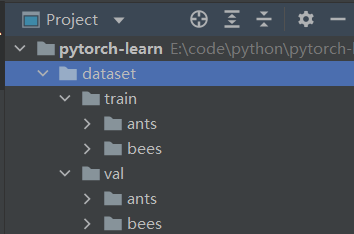
其中,train中存放的是訓練數據集,ants和bees既是文件夾名稱也是其包含的圖片數據的標籤,val中存放的是驗證數據集。
假如我們希望自己的Dataset類可以實現如下數據訪問形式:
dataset = MyDataset("root_dir", "label_dir")
img, label = dataset[0] # 通過下標訪問
我們只需要繼承Dataset類並覆蓋其中的__getitem__()(必須)和__len__()(建議)方法。詳情可在交互模式中執行如下語句查看:
from torch.utils.data import Dataset
help(Dataset)
# 或執行 Dataset??
# 或在pycharm中按住ctrl並點擊Dataset直接查看源碼
部分輸出如下:
An abstract class representing a :class:`Dataset`.
All datasets that represent a map from keys to data samples should subclass it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a data sample for a given key. Subclasses could also optionally overwrite :meth:`__len__`, which is expected to return the size of the dataset by many :class:`~torch.utils.data.Sampler` implementations and the default options of :class:`~torch.utils.data.DataLoader`.
定義MyDataset類:
import os
from torch.utils.data import Dataset
from torch.utils.data.dataset import T_co
from PIL import Image
class MyDataset(Dataset):
def __init__(self, root_dir, label_dir):
"""根據路徑獲取到所有的 image 文件名
:param root_dir: data路徑
:param label_dir: label
"""
self.root_dir = root_dir
self.label_dir = label_dir
self.data_dir = os.path.join(self.root_dir, self.label_dir)
self.img_names = os.listdir(self.data_dir)
def __getitem__(self, index) -> T_co:
"""overwrite 後才可以通過下標訪問 dataset
:param index: 下標
:return: img(PIL), label
"""
img_name = self.img_names[index]
img_path = os.path.join(self.data_dir, img_name)
img = Image.open(img_path)
label = self.label_dir
return img, label # 放回什麼數據由自己定義
def __len__(self):
return len(self.img_names)
使用MyDataset類
在交互模式中導入MyDataset並執行如下語句:
ants_dataset = MyDataset("dataset/train", "ants") # 創建dataset
bees_dataset = MyDataset("dataset/train", "bees")
img, label = ants_dataset[47] # 通過下標訪問數據
len(bees_dataset) # 獲取dataset長度
img.show() # 顯示圖片
dataset = ants_dataset + bees_dataset # 將dataset相加
Tensorboard
使用tensorboard可以按照日誌的形式記錄訓練模型時產生的一些數據(標量、圖片等),同時也可以對記錄的數據進行可視化,方便我們對現有模型進行分析。例如,藉助tensorboard記錄loss 函數隨著訓練訓練周期的下降過程並可視化。
使用Tensorboard首先要在conda環境中通過如下命令進行安裝:
conda install tensorboard
記錄標量(scalar)
記錄標量需要用到torch.utils.tensorboard中的SummaryWriter類的add_scalar方法。
創建如下python腳本並執行:
from torch.utils.tensorboard import SummaryWriter
# 參數:log_dir,日誌存放的路徑名稱
writer = SummaryWriter("logs")
# 記錄曲線 y = x^2
# 參數一:tag,數據標識符
# 參數二:scalar_value,標量值,y軸數據
# 參數三:global_step,步驟,x軸數據
for i in range(100):
writer.add_scalar("y = x^2", i ** 2, i)
# 調用close() 確保數據刷入磁碟
writer.close()
腳本執行成功後會在腳本文件所在當前路徑下創建logs文件夾並生成日誌文件。日誌生成成功後在conda環境中執行以下命令來啟動tensorboard可視化服務:
# 指明log存放的位置以及服務啟動時使用的埠,默認埠為6006
# 多人使用同一台伺服器時應該避免以下兩個參數值相同
tensorboard --logdir=second/logs --port=6008
該命令執行成功後會給出如下圖中的提示:

在瀏覽器中打開以上鏈接即可查看可視化情況:
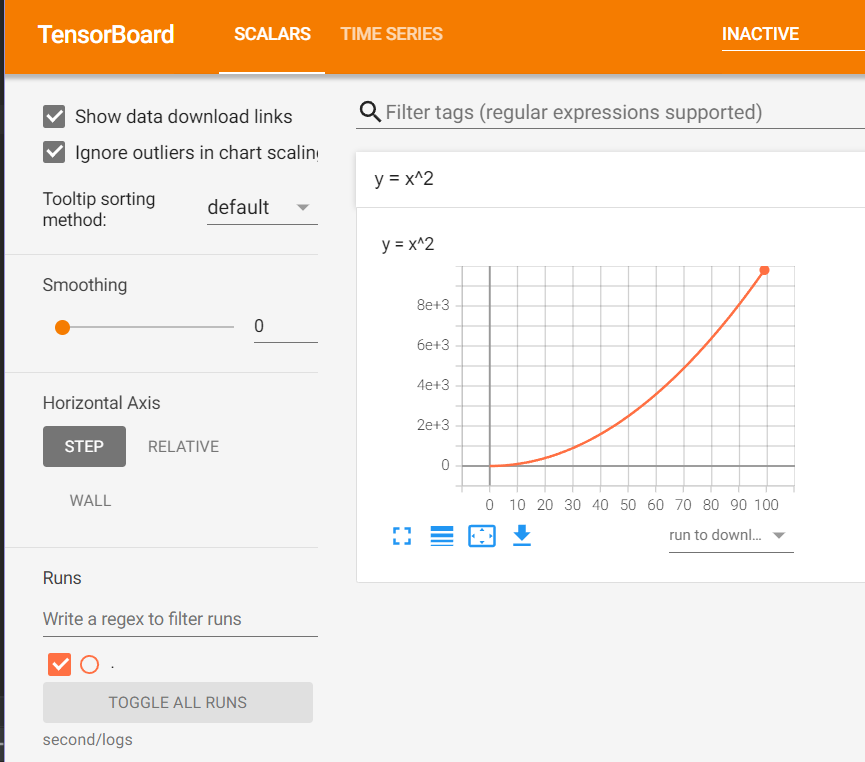
注意:Tensorboard是根據不同的tag來進行可視化的,如果多次寫入的日誌有相同tag,可能會導致可視化時出問題。只需刪除日誌並重新生成,然後重啟可視化服務即可解決。
記錄影像(image)
記錄影像可以使用torch.utils.tensorboard中的SummaryWriter類的add_image方法。
該方法定義如下:
def add_image(self, tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
# tag(string) 同上
# img_tensor (torch.Tensor, numpy.array, or string/blobname): 影像數據
# global_step (int): 步驟
# dataformats (string):影像數據格式,不為CHW則需要指明
創建如下python腳本並執行:
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("logs")
img_path = "E:\\code\\python\\pytorch-learn\\dataset\\train\\ants\\0013035.jpg"
# img 為 PIL.JpegImagePlugin.JpegImageFile 類型
img = Image.open(img_path)
img_array = np.array(img)
writer.add_image("ants", img_array, 0, dataformats="HWC")
writer.close()
腳本執行成功後按之前同樣的方式啟動可視化服務即可。
如果日誌中同一個tag標識的數據有多個global_step則可以如下圖所示:拖動軸來查看global_step之間的影像變化。
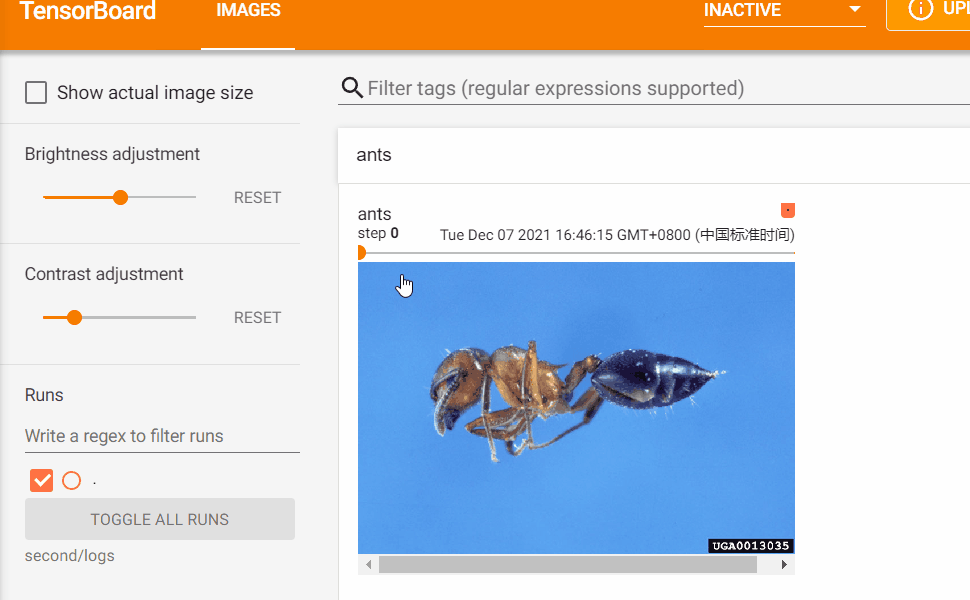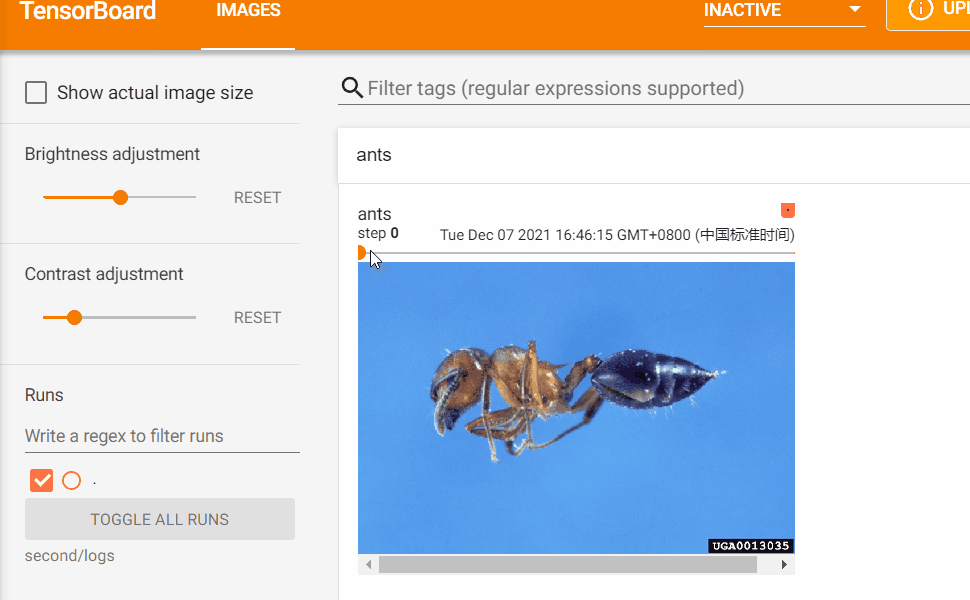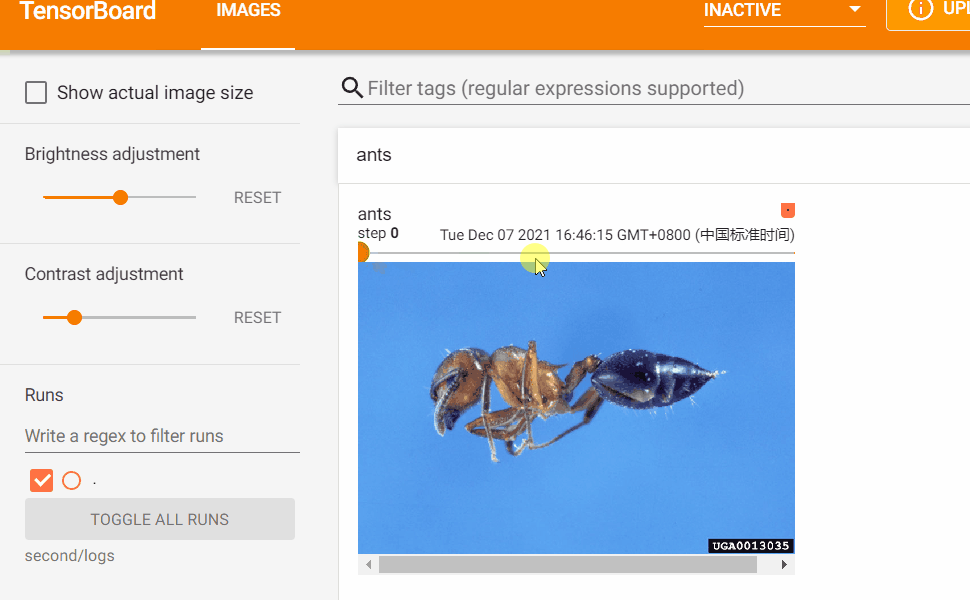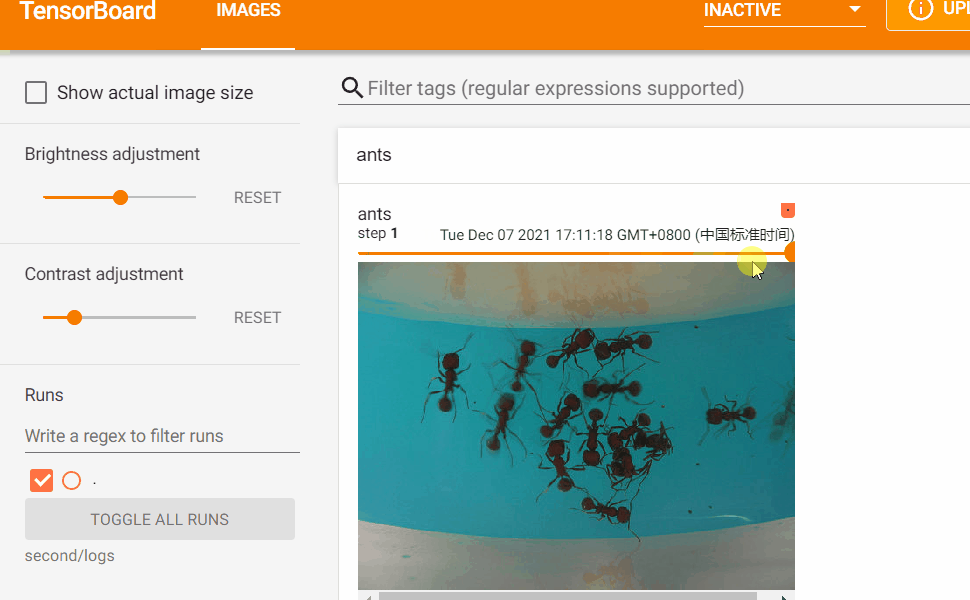
Transforms
transforms是位於torchvision包中的一個模組,模組中有多個類可以對將要輸入神經網路的數據進行轉換以適應網路的需要。
ToTensor
該類可以將 PIL Image or numpy.ndarray 轉換為張量,以方便影像輸入到神經網路中,如下程式碼做了簡單示例:將PIL Image 轉換為張量後藉助tensorboard直接寫入日誌文件:
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
# 創建 transforms 模組中的 ToTensor 類
trans_to_tensor = transforms.ToTensor()
# 獲取 PIL 影像
img_path = "E:/code/python/pytorch-learn/dataset/train/ants" \
"/6743948_2b8c096dda.jpg "
img = Image.open(img_path)
# 將 PIL 影像轉化為 tensor 類型
# 1. 將輸入的數據shape W,H,C ——> C,W,H
# 2. 將所有數除以255,將數據歸一化到[0,1]
# 實例像方法一樣調用,這裡實際調用的是ToTensor類中的__call__方法,
# 更多://zhuanlan.zhihu.com/p/370234492
img_tensor = trans_to_tensor(img)
# 使用 tensorboard 將 tensor 影像寫入日誌
writer = SummaryWriter("logs")
writer.add_image("img_tensor", img_tensor, 1)
writer.close()
啟動tensorbard可視化服務並在瀏覽器中訪問:
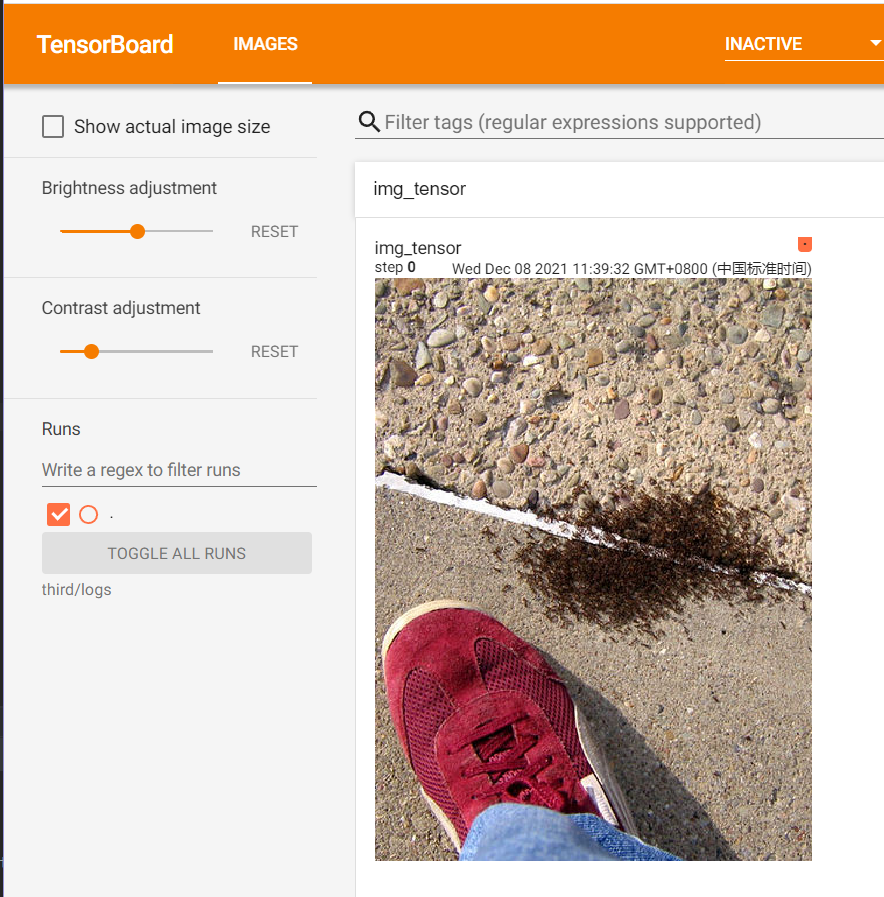
Normalize
normalize類可以利用均值和標準差對tensor影像進行歸一化。該類構造函數定義如下:
# mean (sequence): 代表影像每個通道均值的序列
# std (sequence): 代表影像每個通道標準差的序列
# inplace(bool,optional): 是否原地修改tensor
def __init__(self, mean, std, inplace=False):
該類的具體歸一化操作如下:
output[channel] = (input[channel] - mean[channel]) / std[channel]
拿任意通道來說,如果原值 value 為 [0, 1],傳入的 mean 為 0.5,std 為 0.5 那麼歸一化操作即為:(value - 0.5) / 0.5 = 2*value - 1,帶入value範圍後計算得到value的新範圍為[-1, 1]。
創建如下腳本並執行:
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
# 創建 transforms 模組中的 ToTensor 類
trans_to_tensor = transforms.ToTensor()
# 創建 transforms 模組中的 Normalize 類,三個通道的mean和std都為0.5
trans_normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# 獲取 PIL 影像
img_path = "E:/code/python/pytorch-learn/dataset/train/ants" \
"/6743948_2b8c096dda.jpg "
img = Image.open(img_path)
# 將 PIL 影像轉化為 tensor 類型
# 1. 將輸入的數據shape W,H,C ——> C,W,H
# 2. 將所有數除以255,將數據歸一化到[0,1]
img_tensor = trans_to_tensor(img)
# 將 tensor 進行歸一化
img_normalize = trans_normalize(img_tensor)
print(type(img_normalize))
# <class 'torch.tensor'="">
# 使用 tensorboard 將 tensor 影像寫入日誌
writer = SummaryWriter("logs")
writer.add_image("img_normalize", img_normalize, 1)
writer.close()
啟動tensorbard可視化服務並在瀏覽器中訪問:
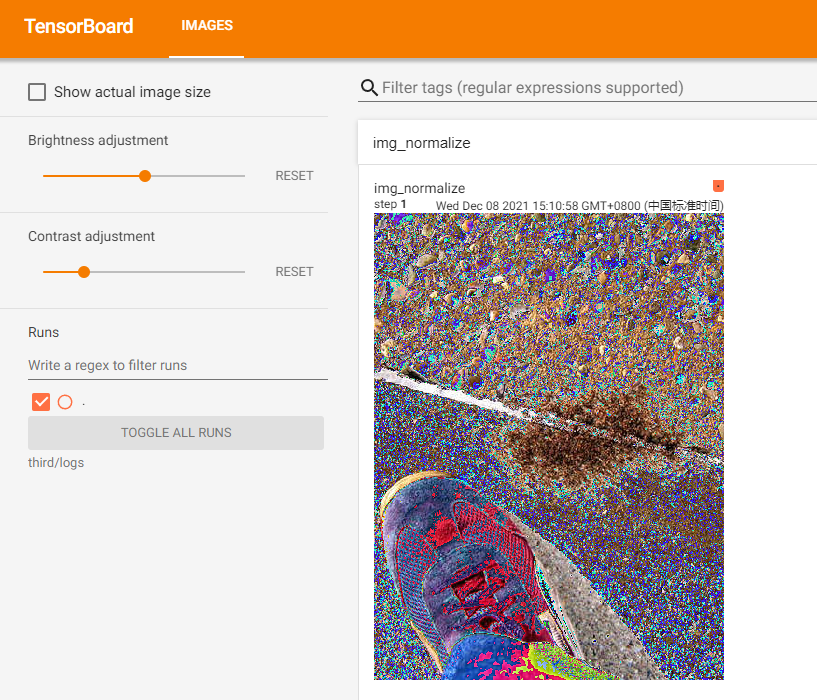
Resize
Resize類可對tensor或PIL影像進行縮放,構造函數定義如下:
# size (sequence or int): 所需的輸出大小
# 如果size是形如(h, w)的高和寬的序列,輸出時就按此匹配;
# 如果size是一個int,則選擇小的邊來進行等比例縮放,如果 height > width,
# 則縮放後為(size * height / width, size)
def __init__(self, size, interpolation=InterpolationMode.BILINEAR, max_size=None, antialias=None):
創建如下腳本並執行:
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
# 創建到 transforms 模組中的 ToTensor 類
trans_to_tensor = transforms.ToTensor()
# 創建 transforms 模組中的 Normalize 類
trans_normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# 創建 transforms 模組中的 Resize 類
trans_resize_52x52 = transforms.Resize((80, 40))
trans_resize_52 = transforms.Resize(200)
# 獲取 PIL 影像
img_path = "E:/code/python/pytorch-learn/dataset/train/ants" \
"/6743948_2b8c096dda.jpg "
img = Image.open(img_path)
# 使用 tensorboard 記錄多個處理步驟的影像
writer = SummaryWriter("logs")
# 將 PIL 影像轉化為 tensor 類型
# 1. 將輸入的數據shape W,H,C ——> C,W,H
# 2. 將所有數除以255,將數據歸一化到[0,1]
img_tensor = trans_to_tensor(img)
# 步驟0:記錄tensor影像
writer.add_image("img-tensor-normalize-resize_52x52_resize_52", img_tensor, 0)
# 將 tensor 進行歸一化
img_normalize = trans_normalize(img_tensor)
# 步驟1:記錄normalize後的影像
writer.add_image("img-tensor-normalize-resize_52x52_resize_52",
img_normalize, 1)
# 對normalize後的tensor進行(52, 52)的resize
img_resize_52x52 = trans_resize_52x52(img_normalize)
# 步驟2:記錄(52, 52)resize後的影像
writer.add_image("img-tensor-normalize-resize_52x52_resize_52",
img_resize_52x52, 2)
# 對(52, 52)resize後的tensor再次進行(52)的resize
img_resize_52 = trans_resize_52(img_resize_52x52)
# 步驟3:記錄(52)resize後的影像
writer.add_image("img-tensor-normalize-resize_52x52_resize_52",
img_resize_52, 3)
writer.close()
啟動tensorbard可視化服務並在瀏覽器中訪問:
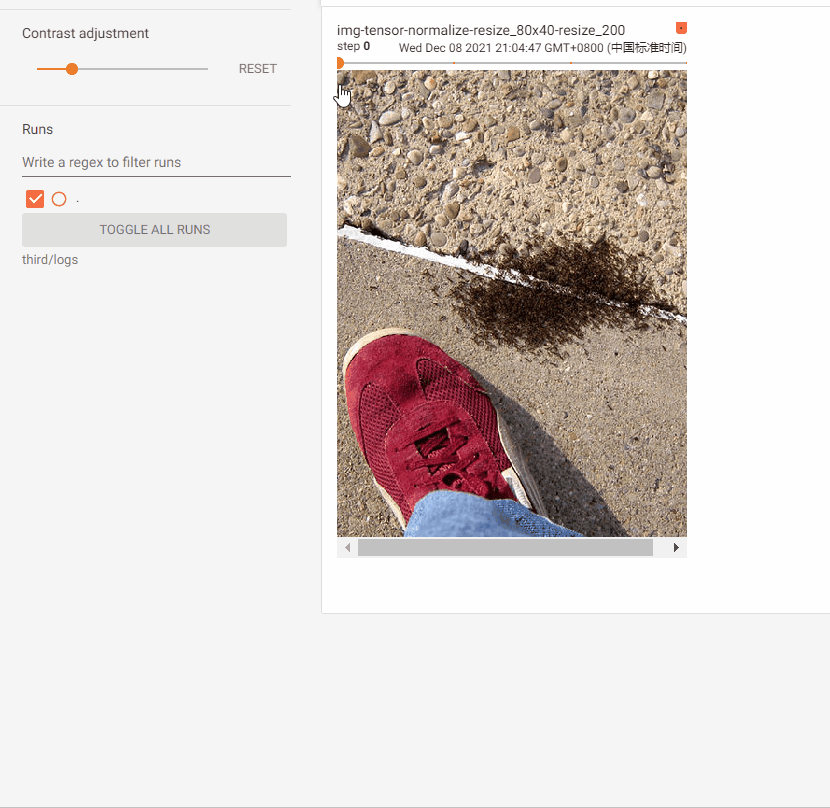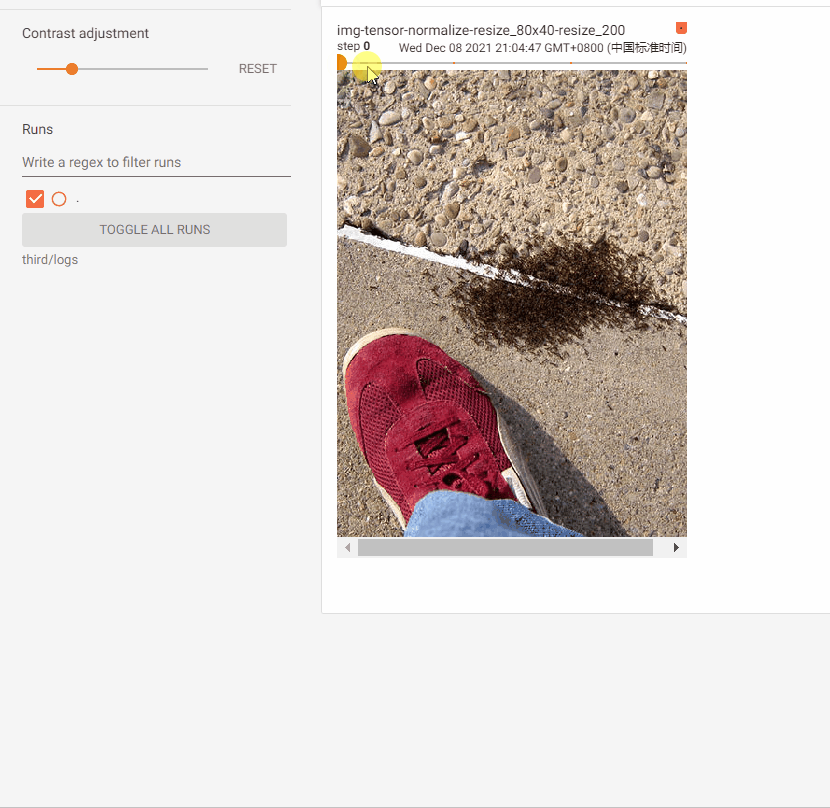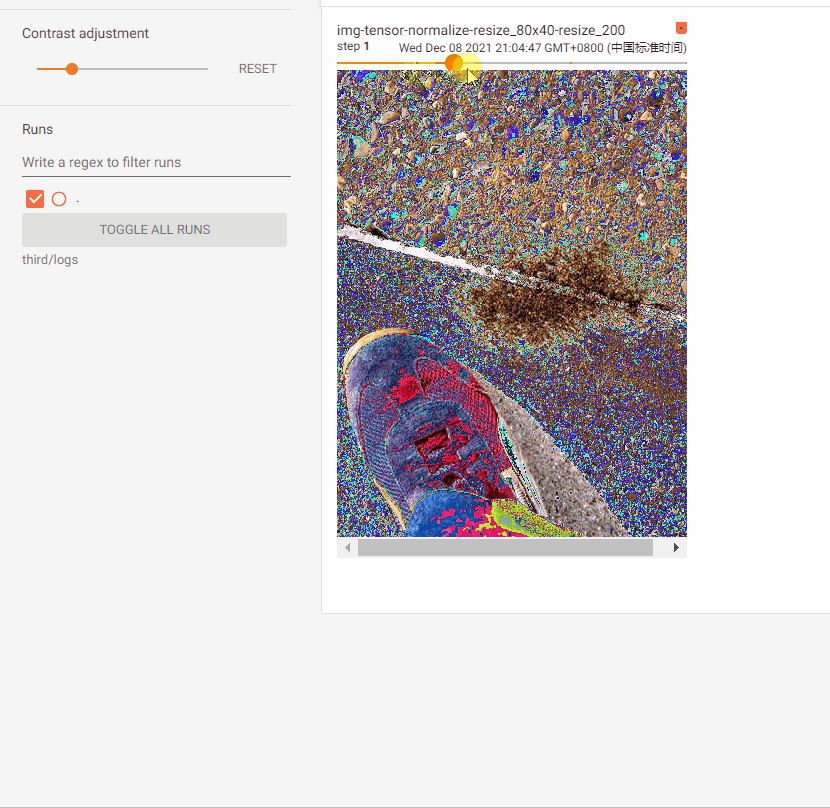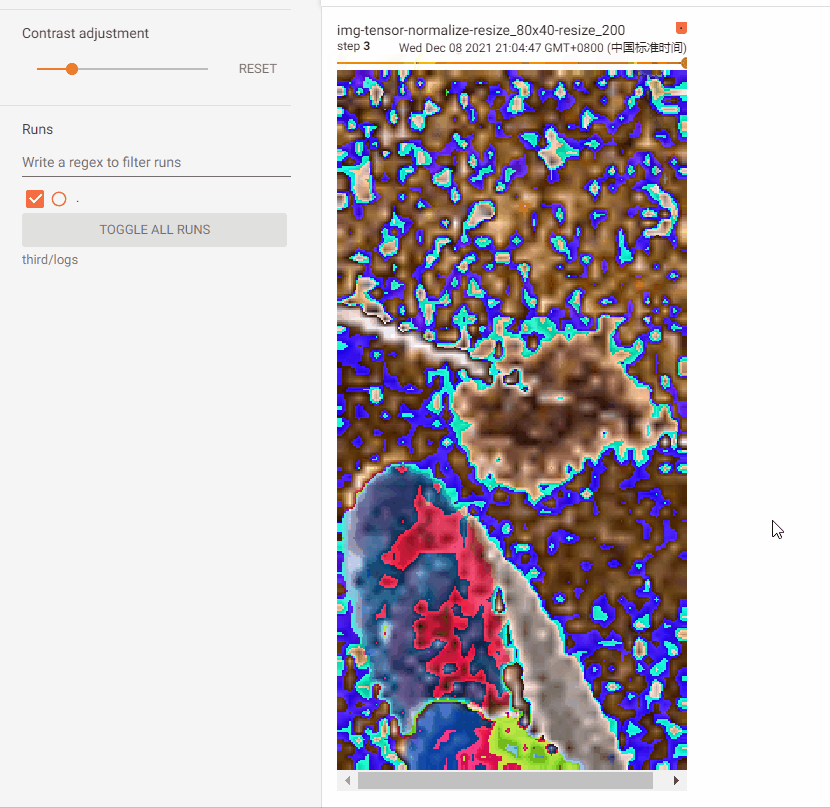
Compose
在上一節的示例中,我們對影像的處理是基於一系列transform,為了記錄每個transform執行後的影像,我們在每兩個transform之間插入了記錄影像操作。如果我們不需要記錄每個transform執行後的影像,那麼我們可以通過Compose來順序執行一系列transform。
Compose類的構造函數定義如下:
# transforms (list of Transform objects):
# 需要順序執行的transfrom對象組成的list
def __init__(self, transforms):
該類的核心思想位於__call__函數中:
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img
有了compose後,為了得到上一節最後的結果,我們可以對上一節的腳本做如下簡化:
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
# 創建到 transforms 模組中的 ToTensor 類
trans_to_tensor = transforms.ToTensor()
# 創建 transforms 模組中的 Normalize 類
trans_normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# 創建 transforms 模組中的 Resize 類
trans_resize_80x40 = transforms.Resize((80, 40))
trans_resize_200 = transforms.Resize(200)
# 創建 transforms 模組中的 Compose 類
trans_compose = transforms.Compose([trans_to_tensor, trans_normalize,
trans_resize_80x40, trans_resize_200])
# 獲取 PIL 影像
img_path = "E:/code/python/pytorch-learn/dataset/train/ants" \
"/6743948_2b8c096dda.jpg "
img = Image.open(img_path)
# 執行 Compose
img_compose = trans_compose(img)
# 記錄compose後的影像
writer = SummaryWriter("logs")
writer.add_image("img-tensor-normalize-resize_80x40-resize_200-compose",
img_compose, 0)
writer.close()
啟動tensorbard可視化服務並在瀏覽器中訪問:
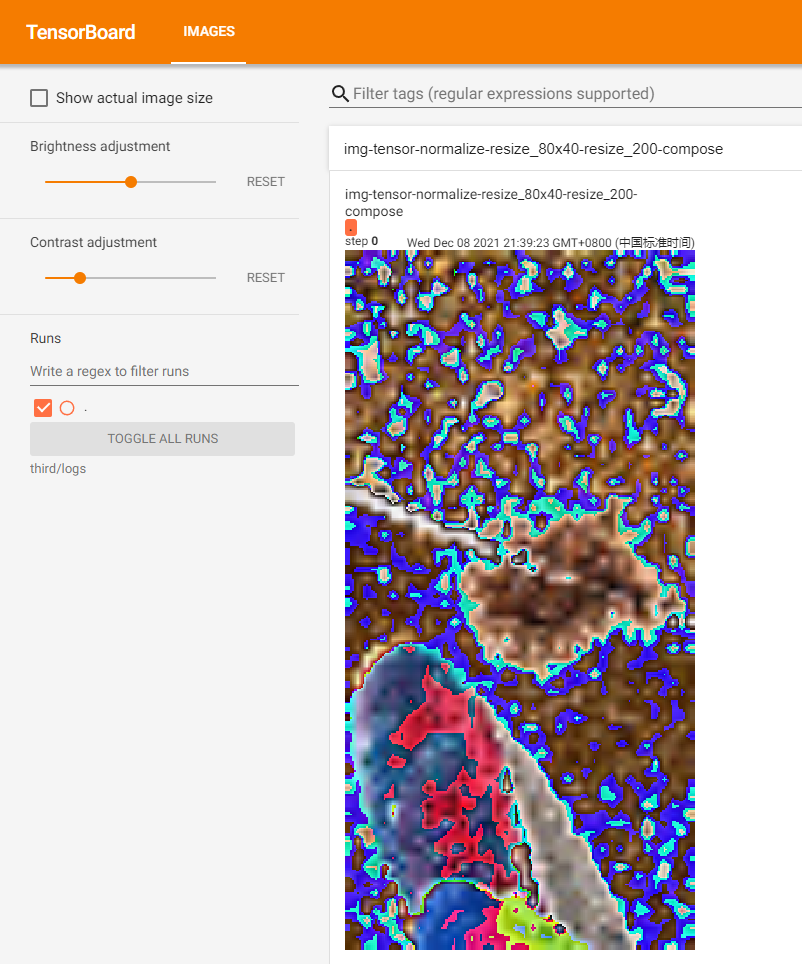
transforms模組中還有很多其他的transform類,這些類在需要時查詢文檔即可。查詢文檔時,重點要弄清楚類或函數的作用以及輸入輸出類型。
Dataset 和 Transforms結合使用
在pytorch官網首頁,按不同模組分別提供了文檔,包括:核心模組,音頻模組,文本模組,視覺模組等:
在torchvision.datasets中,提供了對常用數據集的支援,它可以幫助我們下載、解壓並快速使用數據集:
以CIFAR10數據集為例,根據如下文檔使用即可:
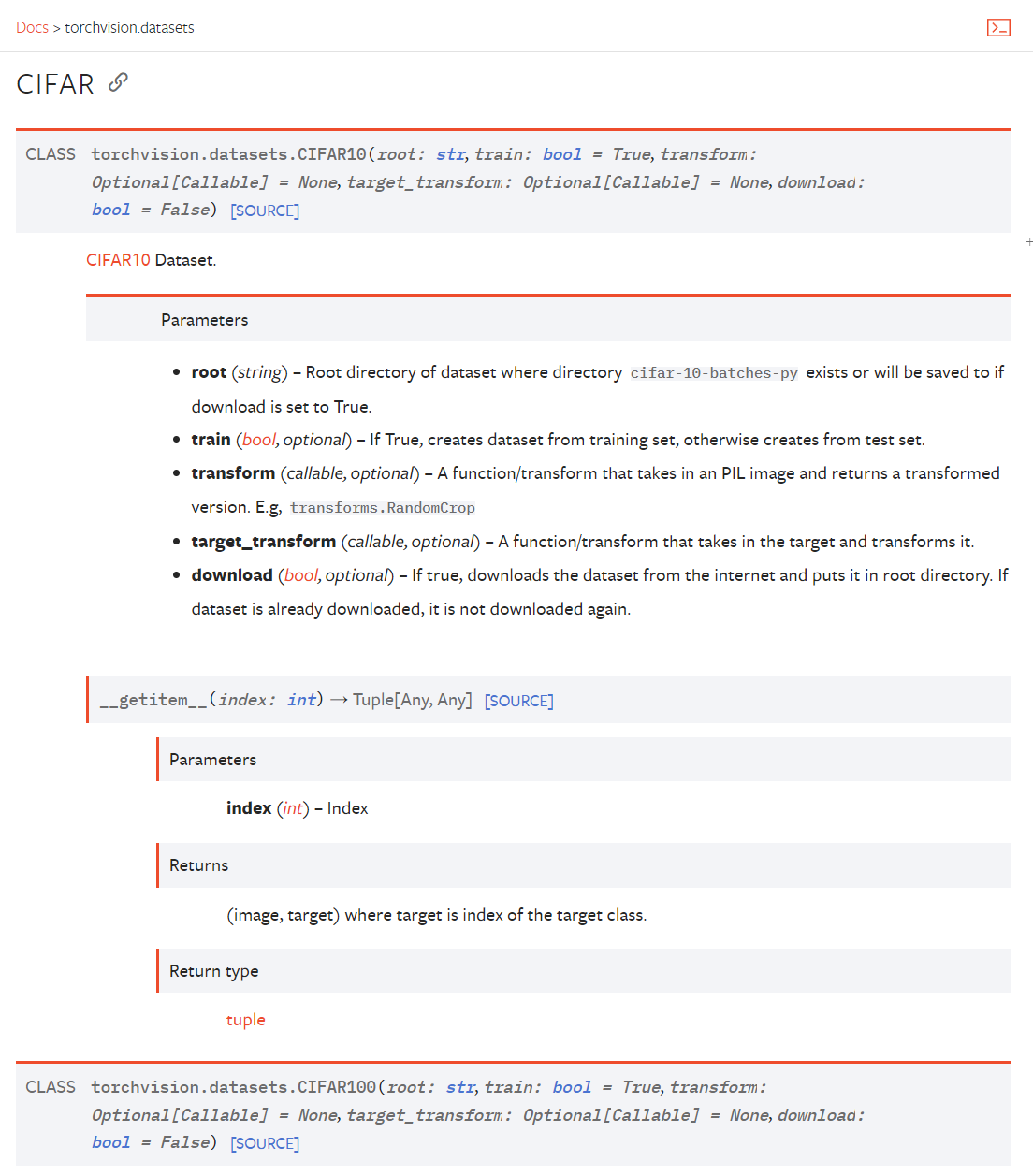
根據文檔可以知道,要使用CIFAR10數據集則使用torchvision.datasets.CIFAR10類,該類的構造函數要求傳入如下參數:
# root (string):數據集所在目錄
# train (bool, optional):為True,創建訓練集;為false,創建測試集
# transform (callable, optional):處理 PIL image 的function/transform
# target_transform (callable, optional):處理 target(影像類別)的function/transform
# download (bool, optional):為true則下載數據集到root目錄中,如果已經存在則不會下載
def __init__(
self,
root: str,
train: bool = True,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
download: bool = False,
) -> None:
根據文檔中的__getitem__函數我們知道,通過下標訪問Dataset時會返回(image, target),即影像和影像的種類。
創建如下腳本並執行(使用訓練集):
import torchvision
# 創建transform,將 PIL Image 轉換為 tensor
data_trans = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# 建議download始終為True,即使你自己提前下載好了數據集
# 下載慢的話可以拷貝控制台輸出的下載地址,然後到迅雷下載好後再將壓縮包拷貝至root下即可
# 下載地址也可以在torchvision.datasets.CIFAR10類的源碼中查看
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True,
transform=data_trans, download=True)
img, target = train_set[0]
print(type(img)) # <class 'torch.tensor'="">
print(target) # 6
# ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print(train_set.classes)
print(train_set.classes[target]) # frog
創建如下腳本並執行(使用測試集):
import torchvision
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False,
download=True)
img, target = test_set[0]
img.show()
print(type(img)) # <class 'pil.image.image'="">
print(target) # 3
print(test_set.classes[target]) # cat
DataLoader
借用DataLoader可以將數據輸入神經網路,查看官方文檔:
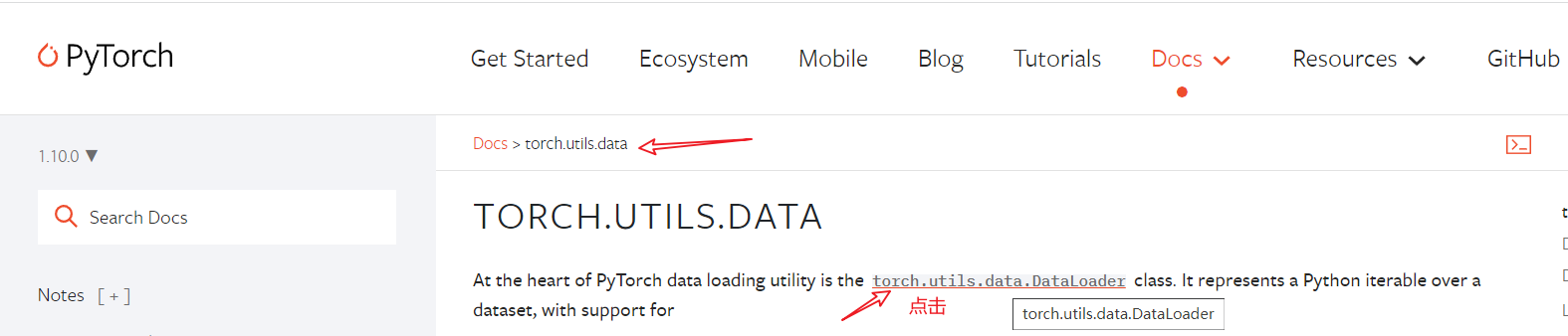
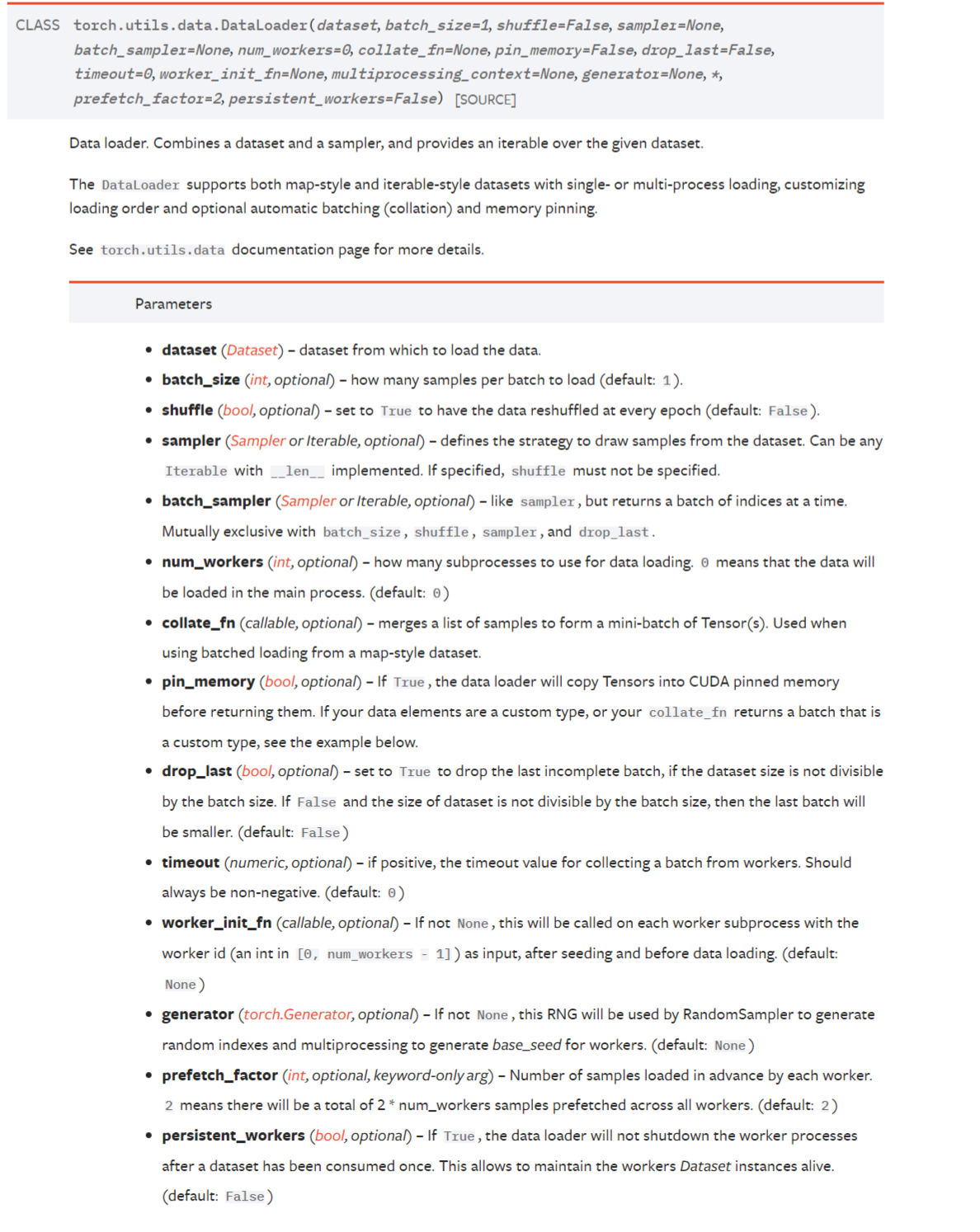
根據官方文檔我們知道,在創建DataLoader時需要的主要的參數如下:
# dataset (Dataset): Dataset類型數據集
# batch_size (int, optional): 批大小,default: 1
# shuffle (bool, optional): 每個 epoch 後是否打亂數據,default: False
# num_workers (int, optional): 載入數據時使用的子進程數量,為0表示使用主進程載入,default: 0。可設置為你的cpu核心數
# drop_last (bool, optional): 當數據個數不能被batch_size整除時,為True表示丟棄最後一批,為False表示不丟棄,default: False
def __init__(self, dataset: Dataset[T_co], batch_size: Optional[int] = 1,
shuffle: bool = False, sampler: Optional[Sampler] = None,
batch_sampler: Optional[Sampler[Sequence]] = None,
num_workers: int = 0, collate_fn: Optional[_collate_fn_t] = None,
pin_memory: bool = False, drop_last: bool = False,
timeout: float = 0, worker_init_fn: Optional[_worker_init_fn_t] = None,
multiprocessing_context=None, generator=None,
*, prefetch_factor: int = 2,
persistent_workers: bool = False):
創建如下腳本並執行:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
def train():
trans_to_tensor = torchvision.transforms.ToTensor()
train_dataset = torchvision.datasets.CIFAR10(root="./dataset",
transform=trans_to_tensor,
download=True)
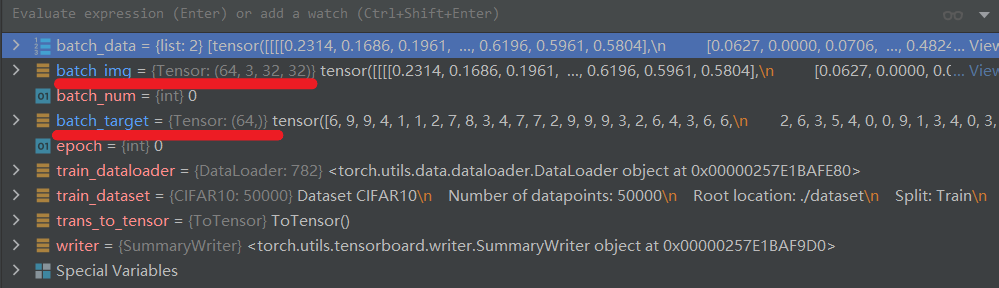
# dataloader 按照batch_size打包img和target,如圖所示
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64,
shuffle=False, num_workers=16,
drop_last=False)
writer = SummaryWriter("logs")
for epoch in range(2):
for batch_num, batch_data in enumerate(train_dataloader):
# print(epoch, " : ", batch_num)
batch_img, batch_target = batch_data
writer.add_images(
"CIFAR10-batch64-no_shuffle-no_drop_last_epoch{}".format(epoch)
, batch_img, batch_num)
writer.close()
if __name__ == "__main__":
train()
在windows中如果num_workers > 1報錯,解決方法如下:
1.修改程式碼為如下格式:
def train():
# Here was inserted the whole code that train the network ...
if __name__ == '__main__':
train()
2.如果程式碼修改後仍然報錯:OSError: [WinError 1455] 頁面文件太小,無法完成操作。則還需要調整你的python環境所在盤的虛擬記憶體大小:
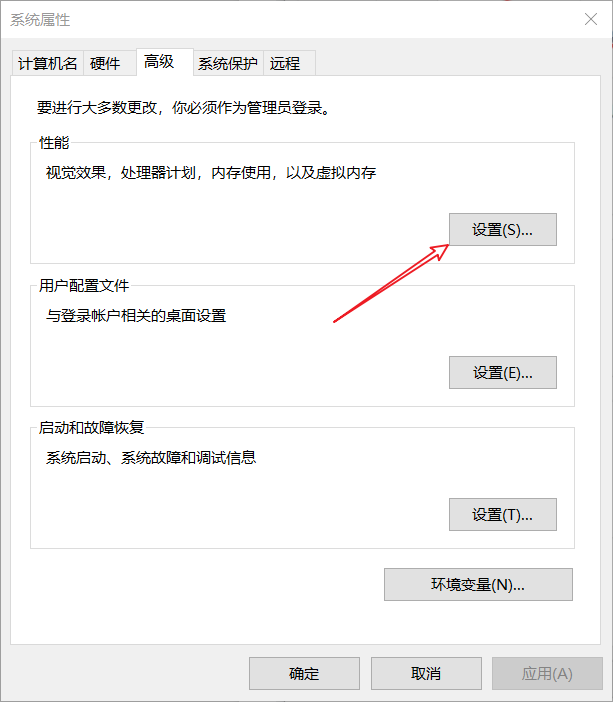
進入高級系統設置:
點擊:高級 -> 性能 -> 設置:
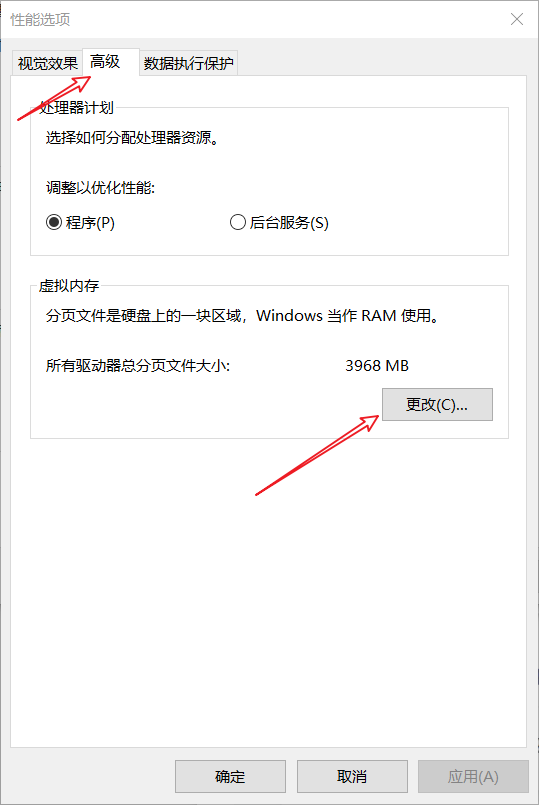
點擊:高級 -> 更改:
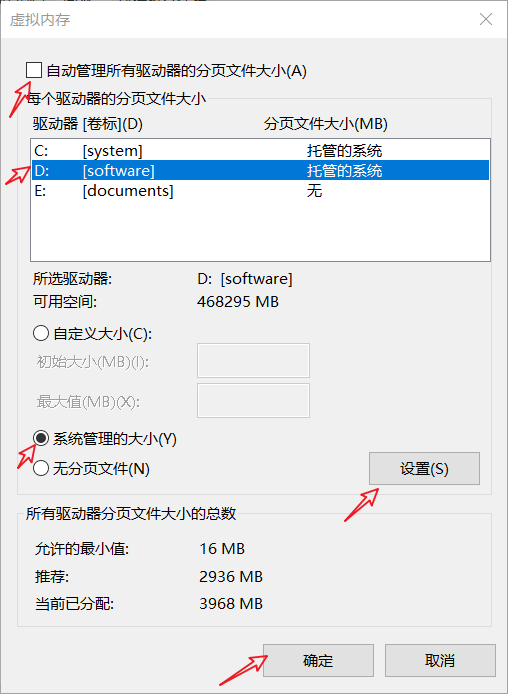
按照下圖,將D盤的虛擬記憶體調整為系統管理的大小(重啟後生效)。任然報錯就自定義大小為一個很大的值,如:10GB-100GB。
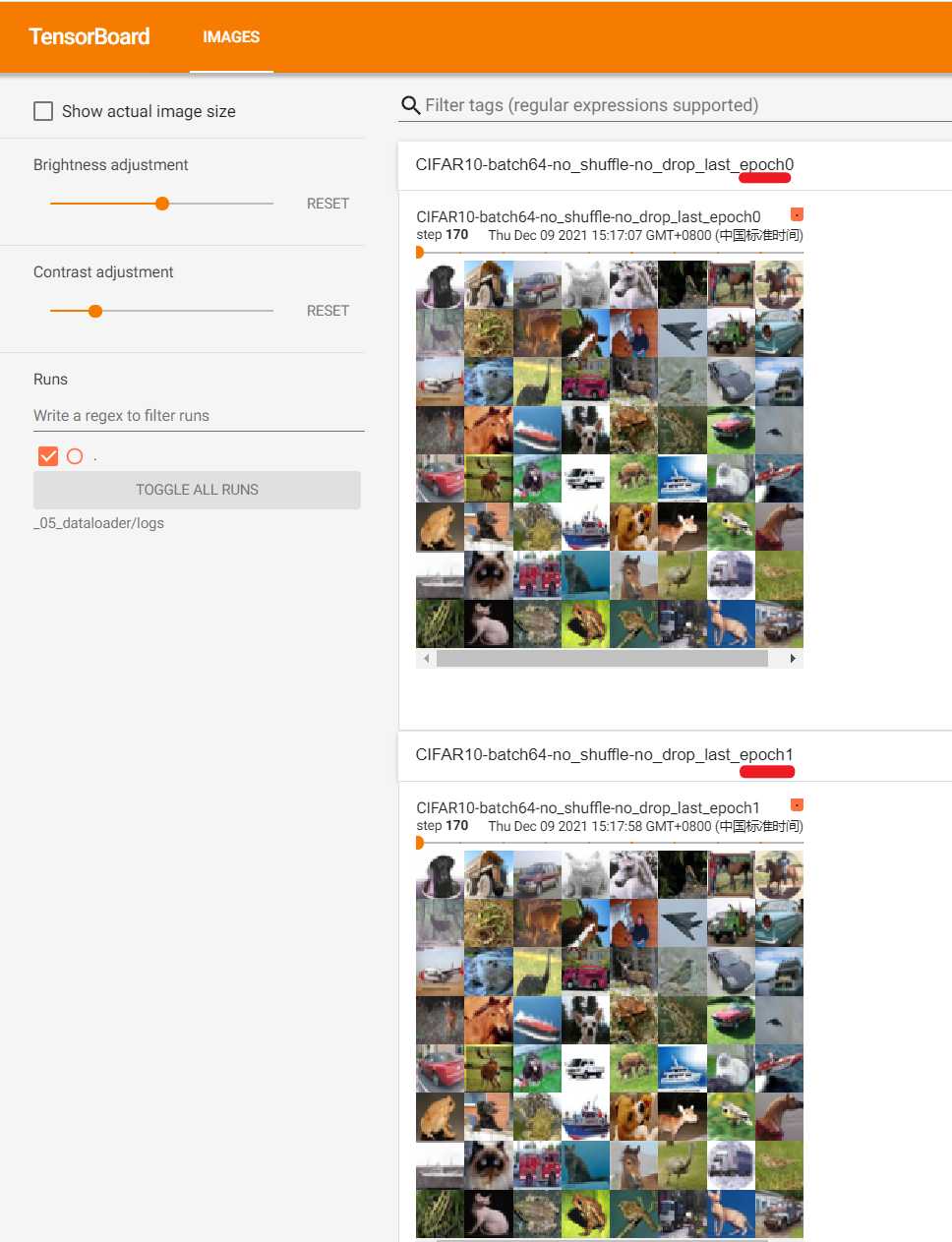
腳本執行成功後,啟動tensorbard可視化服務並在瀏覽器中訪問:
step=170時:(日誌比較大,瀏覽器中可能需要多次刷新才能完全載入)
step=781時:
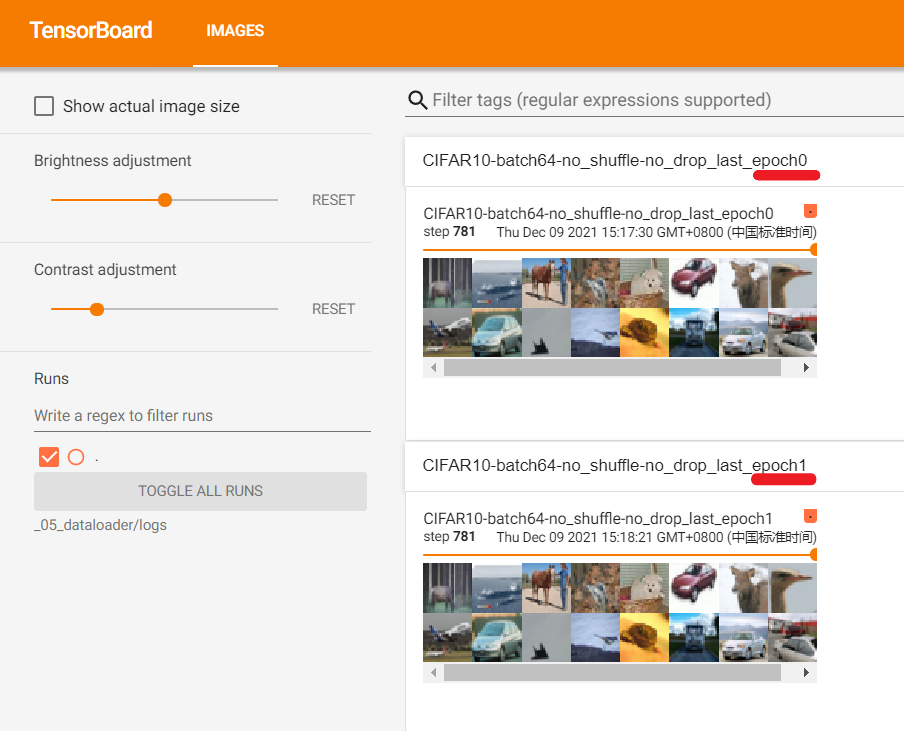
由於我們在創建DataLoader時,參數shuffle=False使得epoch0和epoch1之間相同批次抽取的影像是相同的;參數drop_last=False使得即使最後一個批次影像不足64也沒有被捨棄。
修改腳本使得:shuffle=True,drop_last=True,然後再次執行腳本並啟動tensorbard可視化服務。瀏覽器中訪問結果如下:
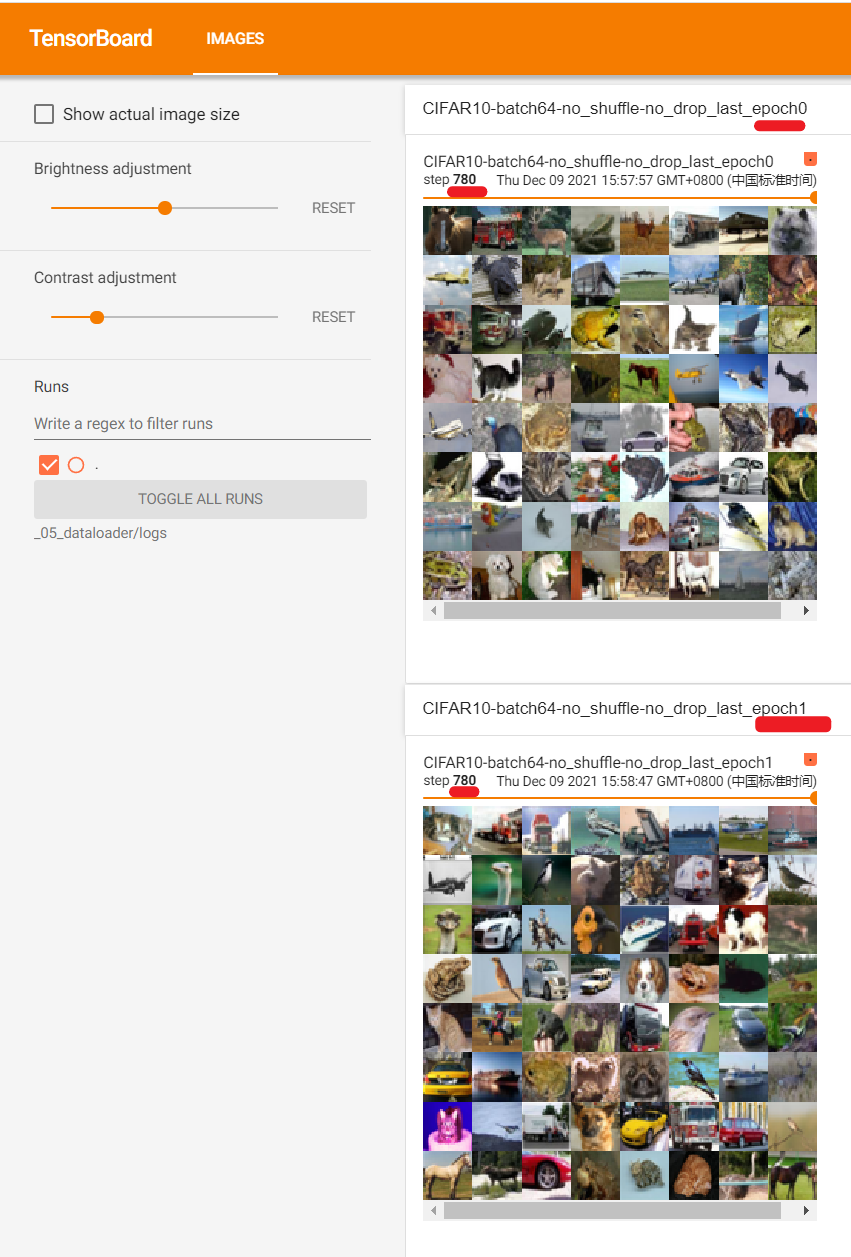
如圖所示,epoch0和epoch1之間相同批次(780)抽取的影像不相同,且第781個批次被捨棄。


