Cilium 1.11 發布,帶來內核級服務網格、拓撲感知路由….
- 2021 年 12 月 15 日
- 筆記
作者:Cilium 母公司 Isovalent 團隊
譯者:范彬,狄衛華,米開朗基楊註:本文已取得作者本人的翻譯授權!
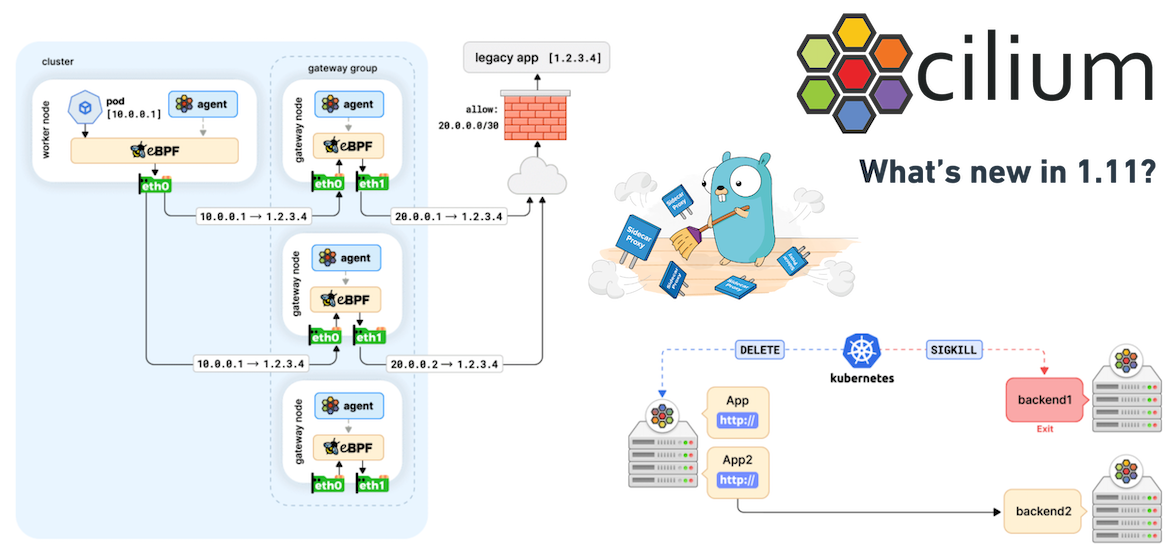
Cilium 項目已逐漸成為萬眾矚目之星,我們很自豪能夠成為該項目的核心人員。幾天前,我們發布了具有諸多新功能的 Cilium 1.11 版本,這是一個令人興奮的版本。諸多新功能中也包括了萬眾期待的 Cilium Service Mesh 的 Beta 版本。在本篇文章中,我們將深入探討其中的部分新功能。
Service Mesh 測試版本(Beta)
在探討 1.11 版本之前,讓我們先了解一下 Cilium 社區宣布的 Service Mesh 的新功能。

- 基於 eBPF 技術的 Service Mesh (Beta)版本: 定義了新的服務網格能力,這包括 L7 流量管理和負載均衡、TLS 終止、金絲雀發布、追蹤等諸多能力。
- 集成了 Kubernetes Ingress (Beta) 功能: 通過將 eBPF 和 Envoy 的強勢聯合,實現了對 Kubernetes Ingress 的支援。
Cilium 網站的一篇文章詳細介紹了Service Mesh Beta 版本,其中也包括了如何參與到該功能的開發。當前,這些 Beta 功能是 Cilium 項目中的一部分,在單獨分支進行開發,可獨立進行測試、回饋和修改,我們期待在 2022 年初 Cilium 1.12 版本發布之前合入到 Cilium 主分支。
Cilium 1.11
Cilium 1.11 版本包括了 Kubernetes 額外功能,及獨立部署的負載均衡器。
- OpenTelemetry 支援:Hubble L3-L7 可觀測性數據支援 OpenTelemetry 跟蹤和度量(Metrics)格式的導出。 (更多詳情)
- Kubernetes APIServer 策略匹配:新的策略實體用於簡單方便地創建進出 Kubernetes API Server 流量的策略模型。 (更多詳情)
- 拓撲感知的路由:增強負載均衡能力,基於拓撲感知將流量路由到最近的端點,或保持在同一個地區(Region)內。 (更多詳情)
- BGP 宣告 Pod CIDR:使用 BGP 在網路中宣告 Pod CIDR 的 IP 路由。(更多詳情)
- 服務後端流量的優雅終止:支援優雅的連接終止,通過負載均衡向終止的 Pod 發送的流量可以正常處理後終止。(更多詳情)
- 主機防火牆穩定版:主機防火牆功能已升級為生產可用的穩定版本。(更多詳情)
- 提高負載均衡器擴展性:Cilium 負載均衡支援超過 64K 的後端端點。(更多詳情)
- 提高負載均衡器設備支援:負載均衡的加速 XDP 快速路徑現在支援 bond 設備(更多詳情) 同時,可更普遍地用於多設備設置。 (更多詳情)。
- Kube-Proxy-replacement 支援 istio:Cilium 的 kube-proxy 替代模式與 Istio sidecar 部署模式兼容。 (更多詳情)
- Egress 出口網關的優化:Egress 網關能力增強,支援其他數據路徑模式。 (更多詳情)
- 託管 IPv4/IPv6 鄰居發現:對 Linux 內核和 Cilium 負載均衡器進行了擴展,刪除了其內部 ARP 庫,將 IPv4 的下一跳發現以及現在的 IPv6 節點委託給內核管理。 (更多詳情)
- 基於路由的設備檢測:外部網路設備基於路由的自動檢測,以提高 Cilium 多設備設置的用戶體驗。 (更多詳情)
- Kubernetes Cgroup 增強:在 cgroup v2 模式下集成了 Cilium 的 kube-proxy-replacement 功能,同時,對 cgroup v1/v2 混合模式下的 Linux 內核進行了增強。 (更多詳情)
- Cilium Endpoint Slices:Cilium 基於 CRD 模式能夠更加高效地與 Kubernetes 的控制平面交互,並且不需要專有 ETCD 實例,節點也可擴展到 1000+。 (更多詳情)
- 集成 Mirantis Kubernetes 引擎:支援 Mirantis Kubernetes 引擎。 (更多詳情)
什麼是 Cilium ?
Cilium 是一個開源軟體,為基於 Kubernetes 的 Linux 容器管理平台上部署的服務,透明地提供服務間的網路和 API 連接及安全。
Cilium 底層是基於 Linux 內核的新技術 eBPF,可以在 Linux 系統中動態注入強大的安全性、可見性和網路控制邏輯。 Cilium 基於 eBPF 提供了多集群路由、替代 kube-proxy 實現負載均衡、透明加密以及網路和服務安全等諸多功能。除了提供傳統的網路安全之外,eBPF 的靈活性還支援應用協議和 DNS 請求/響應安全。同時,Cilium 與 Envoy 緊密集成,提供了基於 Go 的擴展框架。因為 eBPF 運行在 Linux 內核中,所以應用所有 Cilium 功能,無需對應用程式程式碼或容器配置進行任何更改。
請參閱 [Cilium 簡介] 部分,了解 Cilium 更詳細的介紹。
OpenTelemetry 支援
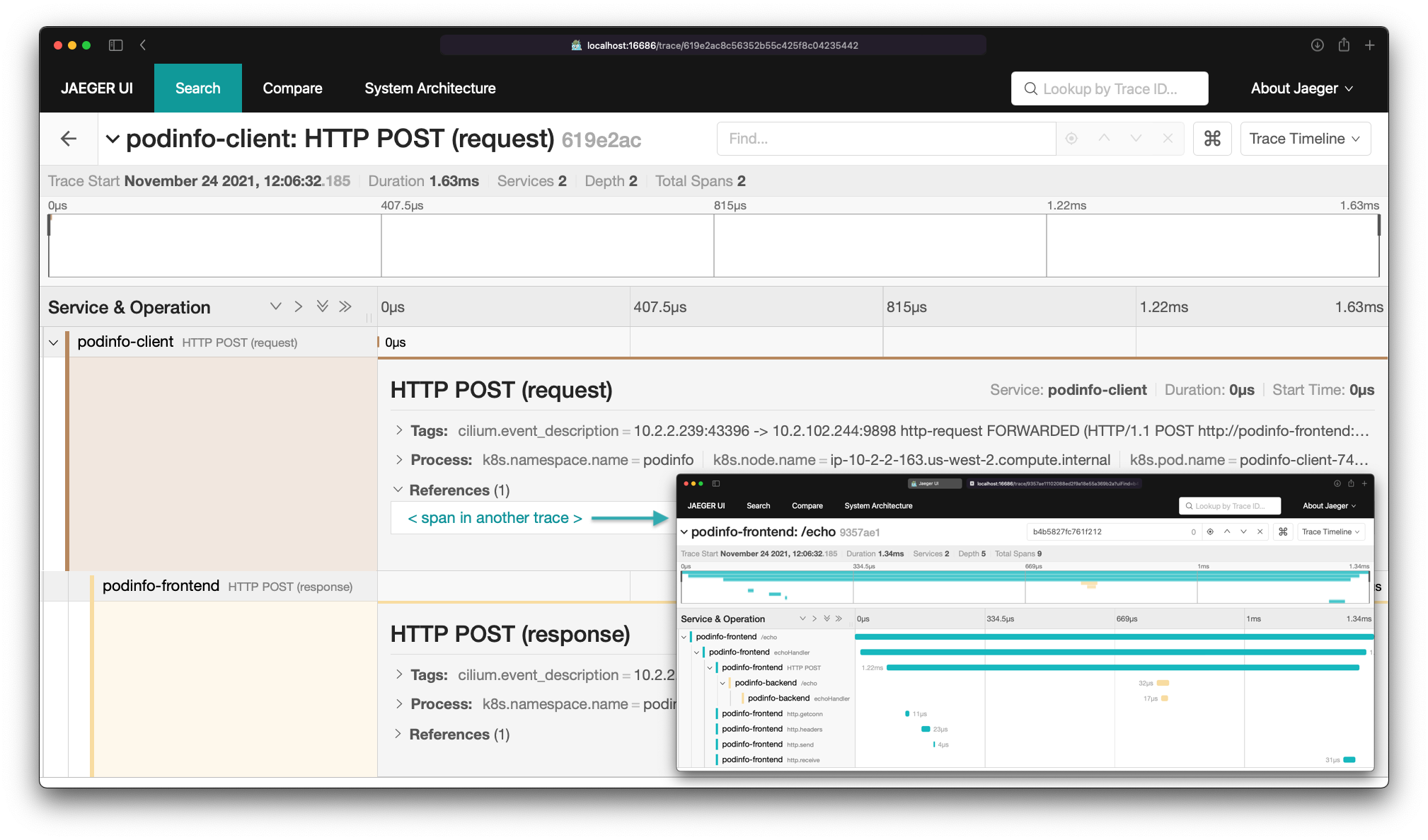
新版本增加了對 OpenTelemetry 的支援。
OpenTelemetry 是一個 CNCF 項目,定義了遙測協議和數據格式,涵蓋了分散式跟蹤、指標和日誌。該項目提供了 SDK 和運行在 Kubernetes 上的收集器。通常,應用程式直接檢測暴露 OpenTelemetry 數據,這種檢測最常使用 OpenTelemetry SDK 在應用程式內實現。OpenTelemetry 收集器用於從集群中的各種應用程式收集數據,並將其發送到一個或多個後端。CNCF 項目 Jaeger 是可用於存儲和呈現跟蹤數據的後端之一。
支援 OpenTelemetry 的 Hubble 適配器是一個附加組件,可以部署到運行 Cilium 的集群上(Cilium 版本最好是 1.11,當然也應該適用於舊版本)。該適配器是一個嵌入了 Hubble 接收器的 OpenTelemetry 收集器,我們推薦使用 OpenTelemetry Operator 進行部署(詳見用戶指南)。Hubble 適配器從 Hubble 讀取流量數據,並將其轉換為跟蹤和日誌數據。
Hubble 適配器添加到支援 OpenTelemetry 的集群中,可對網路事件和應用級別遙測提供有價值的可觀測性。當前版本通過 OpenTelemetry SDK 提供了 HTTP 流量和 spans 的關聯。
感知拓撲的負載均衡
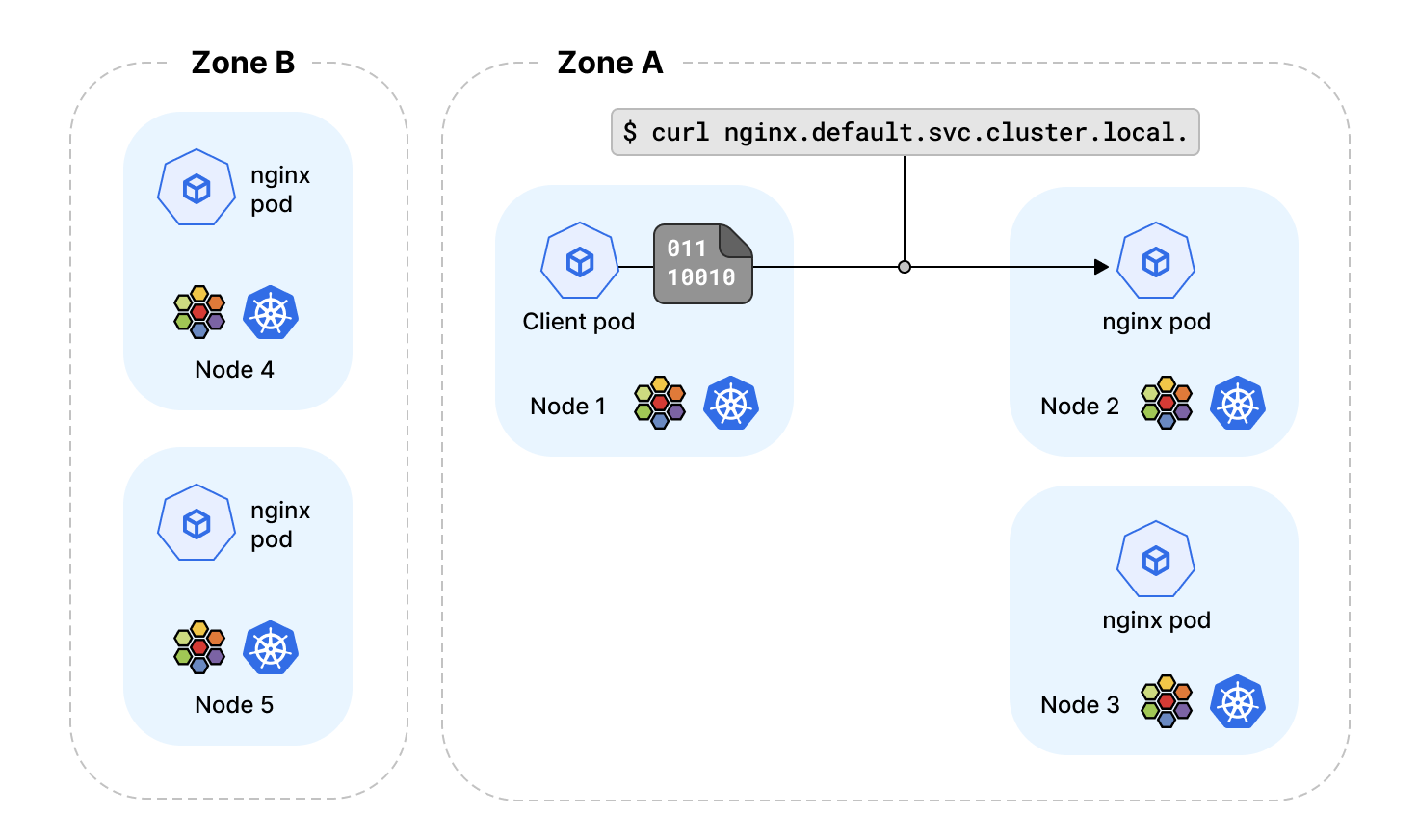
Kubernetes 集群在跨多數據中心或可用區部署是很常見的。這不僅帶來了高可用性好處,而且也帶來了一些操作上的複雜性。
目前為止,Kubernetes 還沒有一個內置的結構,可以基於拓撲級別描述 Kubernetes service 端點的位置。這意味著,Kubernetes 節點基於服務負載均衡決策選擇的 service 端點,可能與請求服務的客戶在不同的可用區。 這種場景下會帶來諸多副作用,可能是雲服務費用增加,通常由於流量跨越多個可用區,雲提供商會額外收取費用,或請求延遲增加。更廣泛地說,我們需要根據拓撲結構定義 service 端點的位置, 例如,服務流量應該在同一節點(node)、同一機架(rack)、同一故障分區(zone)、同一故障地區(region)、同雲提供商的端點之間進行負載均衡。
Kubernetes v1.21 引入了一個稱為拓撲感知路由的功能來解決這個限制。通過將 service.kubernetes.io/topology-aware-hints 註解被設置為 auto ,在 service 的 EndpointSlice 對象中設置端點提示,提示端點運行的分區。分區名從節點的 topology.kubernetes.io/zone 標籤獲取。 如果兩個節點的分區標籤值相同,則被認為處於同一拓撲級別。
該提示會被 Cilium 的 kube-proxy 替代來處理,並會根據 EndpointSlice 控制器設置的提示來過濾路由的端點,讓負載均衡器優先選擇同一分區的端點。
該 Kubernetes 功能目前處於 Alpha 階段,因此需要使用–feature-gate 啟用。更多資訊請參考官方文檔。
Kubernetes APIServer 策略匹配
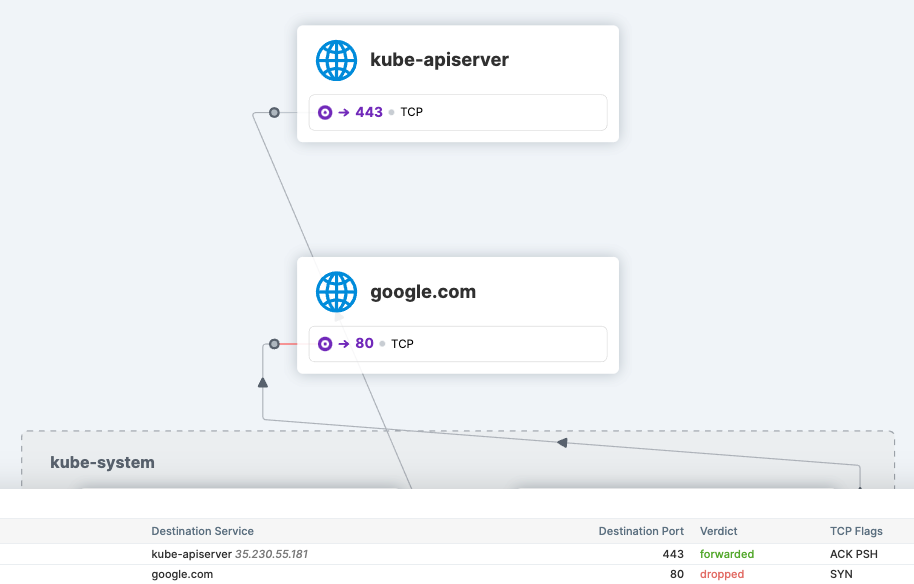
託管 Kubernetes 環境,如 GKE、EKS 和 AKS 上,kube-apiserver 的 IP 地址是不透明的。在以前的 Cilium 版本中,沒有提供正規的方式來編寫 Cilium 網路策略,定義對 kube-apiserver 的訪問控制。這涉及一些實現細節,如:Cilium 安全身份分配,kube-apiserver 是部署在集群內,還是部署在集群外。
為了解決這個問題,Cilium 1.11 增加了新功能,為用戶提供一種方法,允許使用專用策略對象定義進出 apiserver 流量的訪問控制。該功能的底層是實體選擇器,能夠解析預留的 kube-apiserver 標籤含義, 並可自動應用在與 kube-apiserver 關聯的 IP 地址上。
安全團隊將對這個新功能特別感興趣,因為它提供了一個簡單的方法來定義對 pod 的 Cilium 網路策略,允許或禁止訪問 kube-apiserver。下面 CiliumNetworkPolicy 策略片段定義了 kube-system 命名空間內的所有 Cilium 端點允許訪問 kube-apiserver, 除此之外的所有 Cilium 端點禁止訪問 kube-apiserver。
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: allow-to-apiserver
namespace: kube-system
spec:
endpointSelector: {}
egress:
- toEntities:
- kube-apiserver
BGP 宣告 Pod CIDR
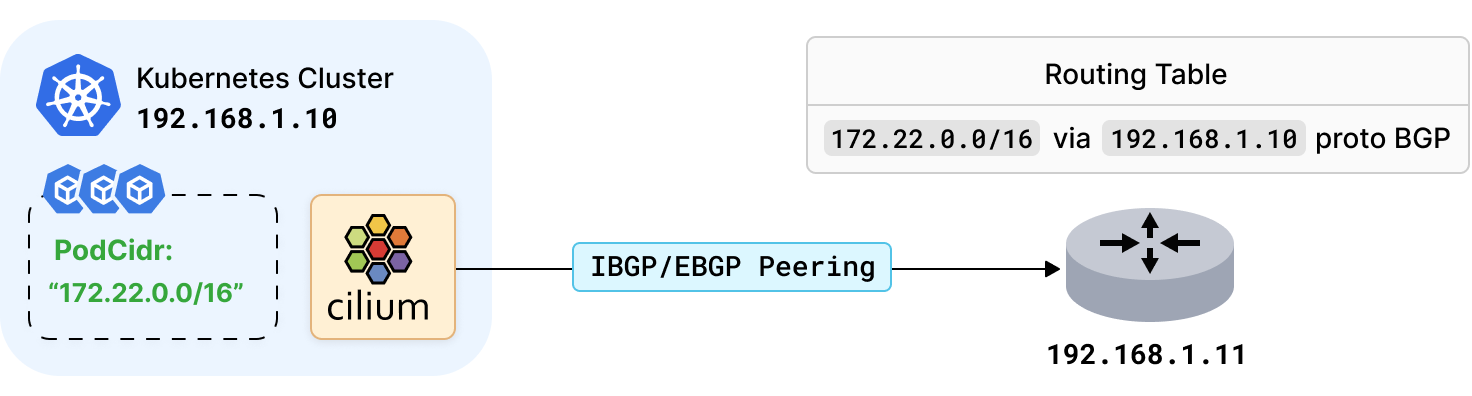
隨著私有 Kubernetes 環境的日益關注,我們希望與現存的數據中心網路基礎設施很好地集成,它們通常是基於 BGP 協議進行路由分發的。 在上一個版本中,Cilium agent 已經開始集成了 BGP 協議, 可以通過 BGP 向 BGP 路由器發布負載均衡器的 service 的 VIP。
現在,Cilium 1.11 版本還引入了通過 BGP 宣告 Kubernetes Pod 子網的能力。Cilium 可與任何下游互聯的 BGP 基礎設施創建一個 BGP 對等體,並通告分配的 Pod IP 地址的子網。這樣下游基礎設施就可以按照合適方式來分發這些路由,以使數據中心能夠通過各種私有/公共下一跳路由到 Pod 子網。
要開始使用此功能,運行 Cilium 的 Kubernetes 節點需要讀取 BGP 的 ConfigMap 設置:
apiVersion: v1
kind: ConfigMap
metadata:
name: bgp-config
namespace: kube-system
data:
config.yaml: |
peers:
- peer-address: 192.168.1.11
peer-asn: 64512
my-asn: 64512
同時,Cilium 應該使用以下參數進行安裝 :
$ cilium install \
--config="bgp-announce-pod-cidr=true"
Cilium 安裝完後,它將會向 BGP 路由器發布 Pod CIDR 範圍,即 192.168.1.11。
下面是最近的 Cilium eCHO episode 完整演示影片。
如果想了解更多,如:如何為 Kubernetes service 配置 LoadBalancer IP 宣告,如何通過 BGP 發布節點的 Pod CIDR 範圍,請參見 docs.cilium.io。
託管 IPv4/IPv6 鄰居發現
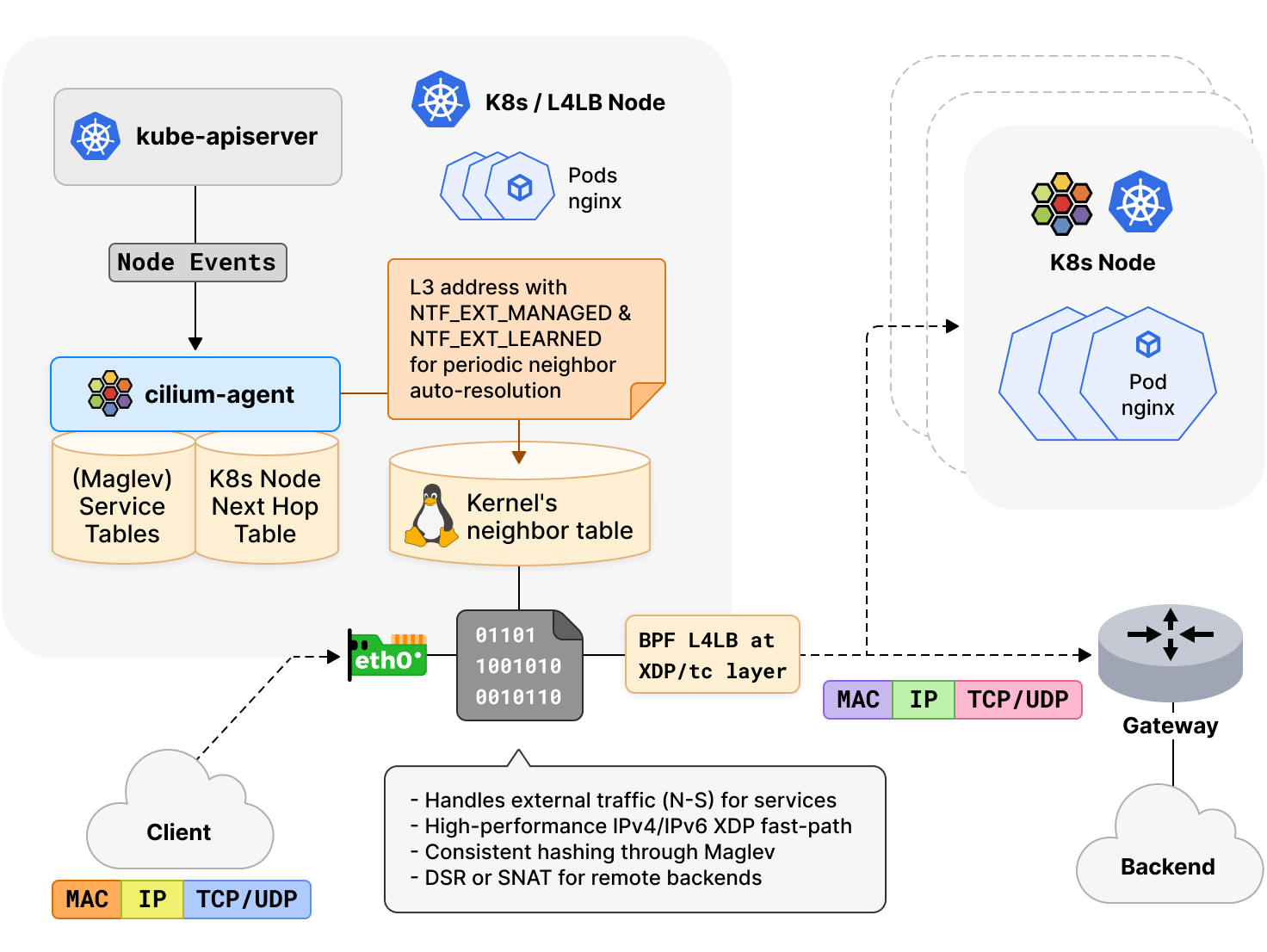
當 Cilium 啟用 eBPF 替代 kube-proxy 時,Cilium 會執行集群節點的鄰居發現,以收集網路中直接鄰居或下一跳的 L2 地址。這是服務負載平衡所必需的,eXpress Data Path (XDP) 快速路徑支援每秒數百萬數據包的可靠高流量速率。在這種模式下,在技術上按需動態解析是不可能的,因為它需要等待相鄰的後端被解析。
在 Cilium 1.10 及更早版本中,cilium agent 本身包含一個 ARP 解析庫,其控制器觸發發現和定期刷新新增集群節點。手動解析的鄰居條目被推送到內核並刷新為 PERMANENT 條目,eBPF 負載均衡器檢索這些條目,將流量定向到後端。cilium agent 的 ARP 解析庫缺乏對 IPv6 鄰居解析支援,並且,PERMANENT 鄰居條目還有許多問題:舉個例子,條目可能變得陳舊,內核拒絕學習地址更新,因為它們本質上是靜態的,在某些情況下導致數據包在節點間被丟棄。此外,將鄰居解析緊密耦合到 cilium agent 也有一個缺點,在 agent 啟停周期時,不會發生地址更新的學習。
在 Cilium 1.11 中,鄰居發現功能已被完全重新設計,Cilium 內部的 ARP 解析庫已從 agent 中完全移除。現在 agent 依賴於 Linux 內核來發現下一跳或同一 L2 域中的主機。Cilium 現在可同時支援 IPv4 和 IPv6 鄰居發現。對於 v5.16 或更新的內核,我們已經將今年 Linux Plumbers 會議期間共同組織的 BPF & Networking Summit 上,提出的「管理」鄰居條目工作提交到上游(part1, part2, part3)。在這種情況下,agent 將新增集群節點的 L3 地址下推,並觸發內核定期自動解析它們對應的 L2 地址。
這些鄰居條目作為「外部學習」和「管理」鄰居屬性,基於 netlink 被推送到內核中。雖然舊屬性確保在壓力下這些鄰居條目不會被內核的垃圾收集器處理,但是 “管理” 鄰居屬性會,在可行的情況下,內核需要自動將這些鄰居屬性保持在 REACHABLE 狀態。這意思是,如果節點的上層堆棧沒有主動向後端節點發送或接收流量,內核可以重新學習,將鄰居屬性保持在 REACHABLE 狀態,然後通過內部內核工作隊列定期觸發顯式鄰居解析。對於沒有 “管理” 鄰居屬性功能的舊內核,如果需要,agent controller 將定期督促內核觸發新的解決方案。因此,Cilium 不再有 PERMANENT 鄰居條目,並且在升級時,agent 將自動將舊條目遷移到動態鄰居條目中,以使內核能夠在其中學習地址更新。
此外,在多路徑路由的情況下,agent 會做負載均衡,它現在可以在路由查找中查看失敗的下一跳。這意味著,不是替代所有的路由,而是通過查看相鄰子系統資訊來避免失敗的路徑。總的來說,對於 Cilium agent 來說,這項修正工作顯著促進了鄰居管理,並且在網路中的節點或下一跳的鄰居地址發生變化時,數據路徑更易變化。
XDP 多設備負載均衡器
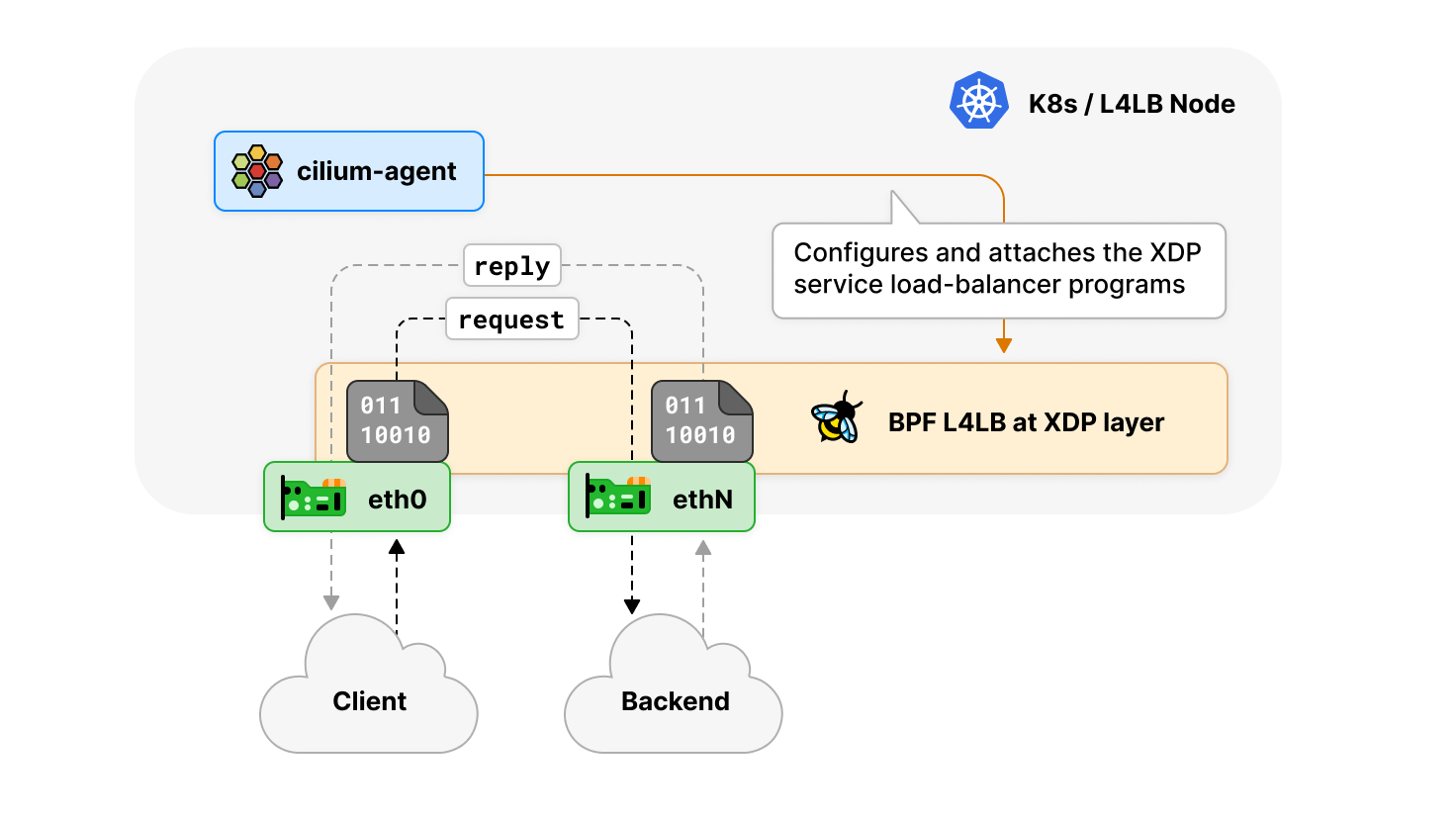
在此版本前,基於 XDP 的負載均衡器加速只能在單個網路設備上啟用,以髮夾方式(hair-pinning)運行,即數據包轉發離開的設備與數據包到達的設備相同。這個最初的限制是在基於 XDP 層的 kube-proxy 替代加速中加入的,原因是在 XDP(XDP_REDIRECT)下對多設備轉發的驅動支援有限,而同設備轉發(XDP_TX)是 Linux 內核中每個驅動的 XDP 都支援的。
這意味著多網路設備的環境下,我們需要使用 tc eBPF 機制,所以必須使用 Cilium 的常規 kube-proxy 替代。這種環境的一個典型例子是有兩個網路設備的主機,其中一個是公網,接受來自外部對 Kubernetes service 的請求,而另一個是私有網路,用於 Kubernetes 節點之間的集群內通訊。
由於在現代 LTS Linux 內核上,絕大多數 40G 和 100G 以上的上游網卡驅動都支援開箱即用的 XDP_REDIRECT,這種限制終於可以解除,因此,這個版本在 Cilium 的 kube-proxy 替代,及 Cilium 的獨立負載均衡器上,實現了 XDP 層的多網路設備的負載均衡,這使得在更複雜的環境中也能保持數據包處理性能。
XDP 透明支援 bond 設備

在很多企業內部或雲環境中,節點通常使用 bond 設備,設置外部流量的雙埠網卡。隨著最近 Cilium 版本的優化,如在 XDP 層的 kube-proxy 替代 或獨立負載均衡器,我們從用戶那裡經常收到的一個問題是 XDP 加速是否可以與 bond 網路設備結合使用。雖然 Linux 內核絕大多數 10/40/100Gbit/s 網路驅動程式支援 XDP,但它缺乏在 bond(和 802.3ad)模式下透明操作 XDP 的能力。
其中的一個選擇是在用戶空間實現 802.3ad,並在 XDP 程式實現 bond 負載均衡,但這對 bond 設備管理是一個相當頗為繁瑣努力,例如:對 netlink 鏈路事件的觀測,另外還需要為編排器的本地和 bond 分別提供單獨的程式。相反,本地內核實現解決了這些問題,提供了更多的靈活性,並且能夠處理 eBPF 程式,而不需要改變或重新編譯它們。內核負責管理 bond 設備組,可以自動傳播 eBPF 程式。對於 v5.15 或更新的內核,我們已經在上游(part1, part2)實現了 XDP 對 bond 設備的支援。
當 XDP 程式連接到 bond 設備時,XDP_TX 的語義等同於 tc eBPF 程式附加到 bond 設備,這意味著從 bond 設備傳輸數據包使用 bond 配置的傳輸方法來選擇從屬設備。故障轉移和鏈路聚合模式均可以在 XDP 操作下使用。對於通過 XDP_TX 將數據包從 bond 設備上回傳,我們實現了輪循、主動備份、802.3ad 以及哈希設備選擇。這種情況對於像 Cilium 這樣的髮夾式負載均衡器來說特別有意義。
基於路由的設備檢測
1.11 版本顯著的提升了設備的自動檢測,可用於 使用 eBPF 替代 kube-proxy、頻寬管理器和主機防火牆。
在早期版本中,Cilium 自動檢測的設備需要有默認路由的設備,和有 Kubernetes NodeIP 的設備。展望未來,現在設備檢測是根據主機命名空間的所有路由表的條目來進行的。也就是說,所有非橋接的、非 bond 的和有全局單播路由的非虛擬的設備,現在都能被檢測到。
通過這項改進,Cilium 現在應該能夠在更複雜的網路設置中自動檢測正確的設備,而無需使用 devices 選項手動指定設備。使用後一個選項時,無法對設備名稱進行一致性的命名規範,例如:無法使用共同前綴正則表達式對設備命名。
服務後端流量的優雅終止
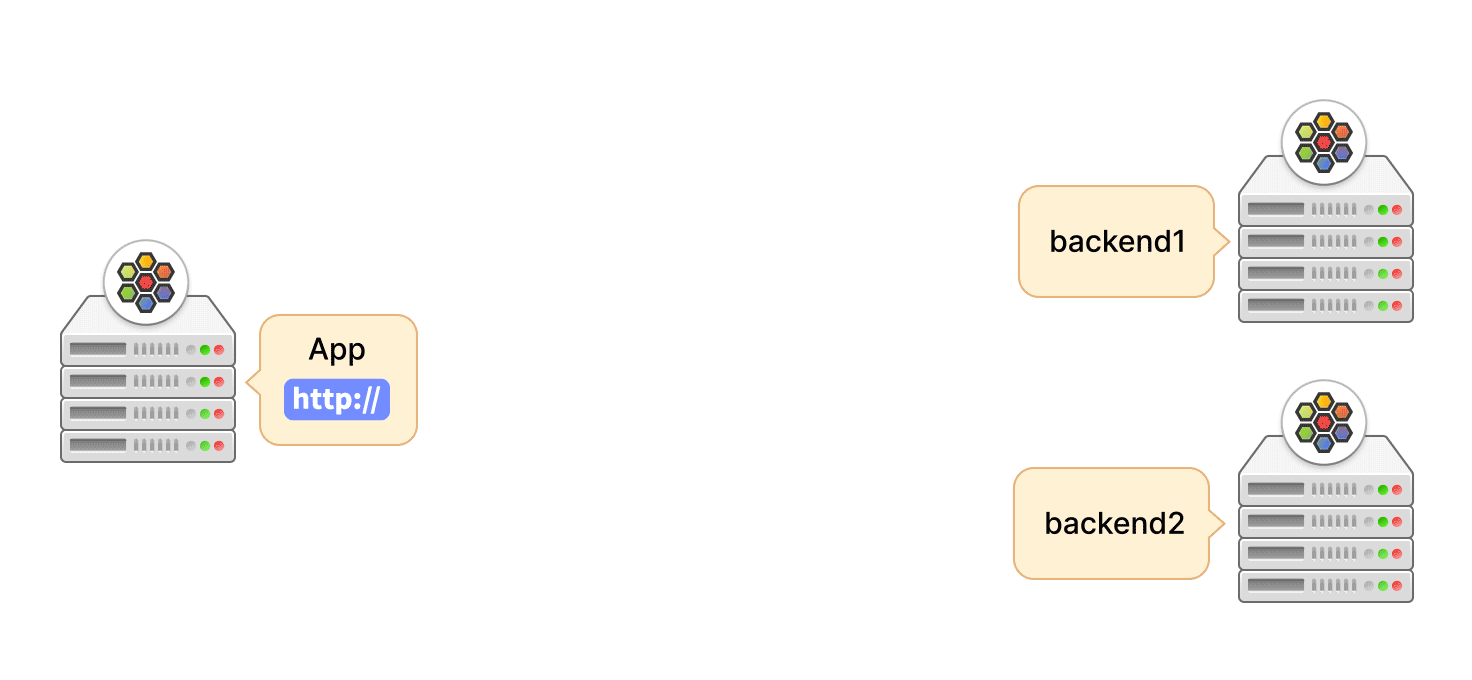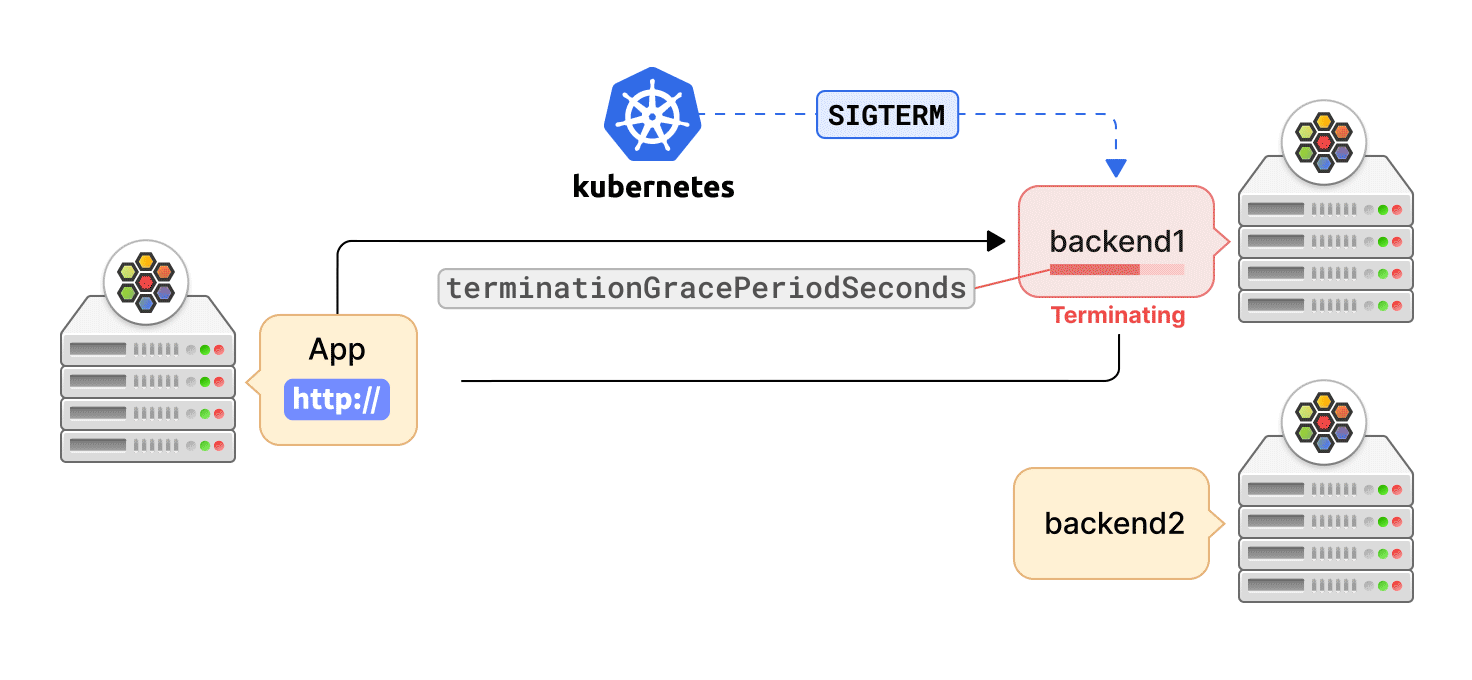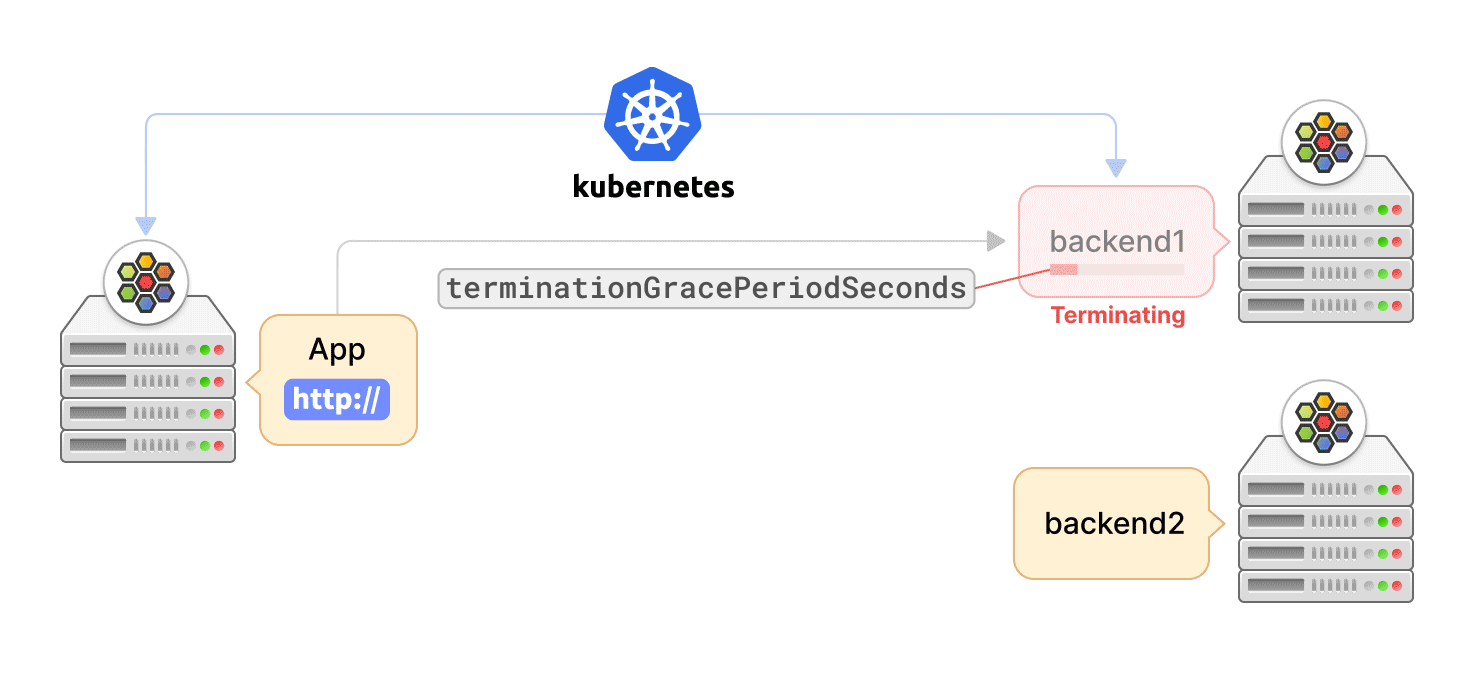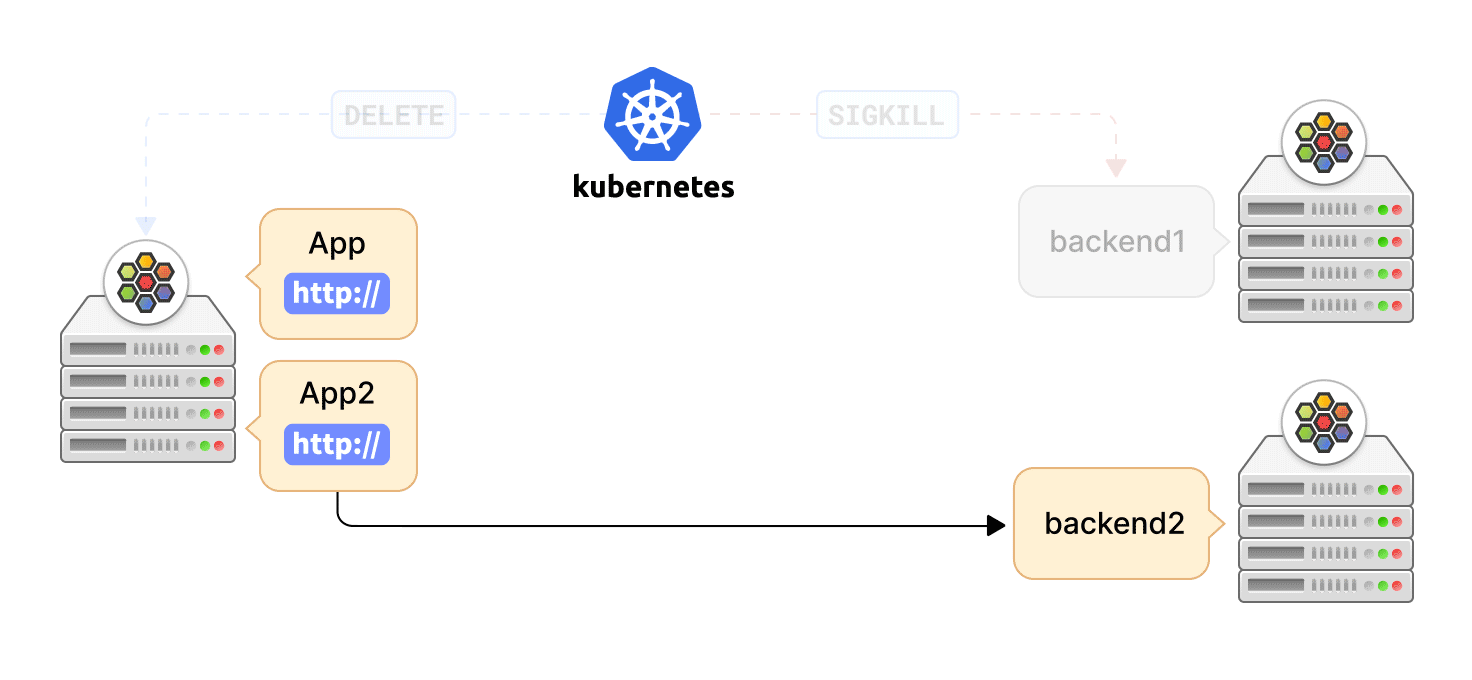
Kubernetes 可以出於多種原因終止 Pod,如滾動更新、縮容或用戶發起的刪除。在這種情況下,重要的是要優雅地終止與 Pod 的活躍連接,讓應用程式有時間完成請求以最大程度地減少中斷。異常連接終止會導致數據丟失,或延遲應用程式的恢復。
Cilium agent 通過 “EndpointSlice” API 監聽 service 端點更新。當一個 service 端點被終止時,Kubernetes 為該端點設置 terminating 狀態。然後,Cilium agent 刪除該端點的數據路徑狀態,這樣端點就不會被選擇用於新的請求,但該端點正在服務的當前連接,可以在用戶定義的寬限期內被終止。
同時,Kubernetes 告知容器運行時向服務的 Pod 容器發送 SIGTERM 訊號,並等待終止寬限期的到來。然後,容器應用程式可以啟動活躍連接的優雅終止,例如,關閉 TCP 套接字。一旦寬限期結束,Kubernetes 最終通過 SIGKILL 訊號對仍在 Pod 容器中運行的進程觸發強制關閉。這時,agent 也會收到端點的刪除事件,然後完全刪除端點的數據路徑狀態。但是,如果應用 Pod 在寬限期結束前退出,Kubernetes 將立即發送刪除事件,而不管寬限期設置。
更多細節請關注 docs.cilium.io 中的指南。
Egress 出口網關的優化
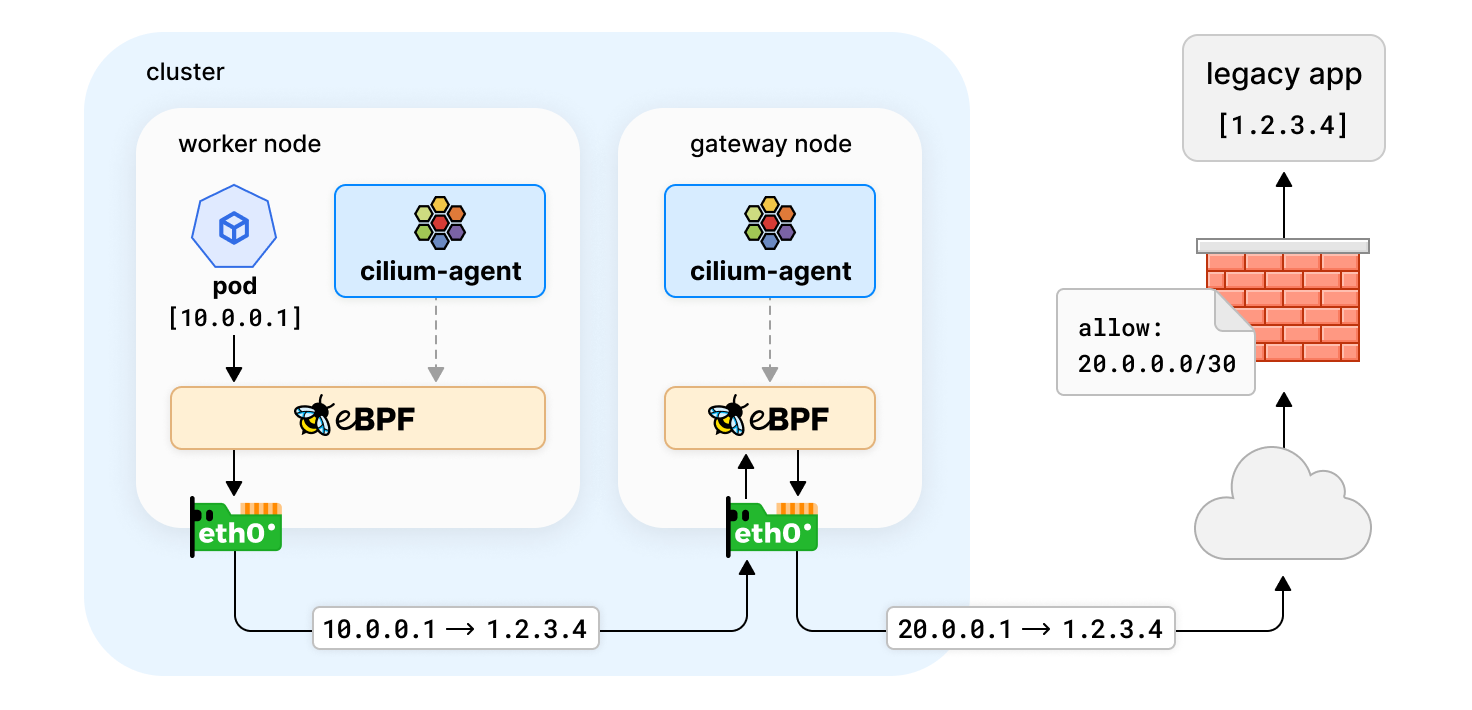
簡單的場景中,Kubernetes 應用只與其他 Kubernetes 應用進行通訊,因此流量可通過網路策略等機制進行控制。但現實世界情況並非總是如此,例如:私有部署的一些應用程式沒有被容器化,Kubernetes 應用程式需要與集群外的服務進行通訊。這些傳統服務通常配置的是靜態 IP,並受到防火牆規則的保護。那麼在此種情況下,應該如何對流量控制和審計呢?
Egress 出口 IP 網關功能在 Cilium 1.10 中被引入,通過 Kubernetes 節點充當網關用於集群出口流量來解決這類問題。用戶使用策略來指定哪些流量應該被轉發到網關節點,以及如何轉發流量。這種情況下,網關節點將使用靜態出口 IP 對流量進行偽裝,因此可以在傳統防火牆建立規則。
apiVersion: cilium.io/v2alpha1
kind: CiliumEgressNATPolicy
metadata:
name: egress-sample
spec:
egress:
- podSelector:
matchLabels:
app: test-app
destinationCIDRs:
- 1.2.3.0/24
egressSourceIP: 20.0.0.1
在上面的示例策略中,帶有 app: test-app 標籤的 Pod 和目標 CIDR 為 1.2.3.0/24 的流量,需要通過 20.0.0.1 網關節點的出口 IP(SNAT)與集群外部通訊。
在 Cilium 1.11 開發周期中,我們投入了大量精力來穩定出口網關功能,使其可投入生產。現在,
出口網關現在可以工作在直接路由,區分內部流量(即 Kubernetes 重疊地址的 CIDR 的出口策略)及在不同策略中使用相同出口 IP下。一些問題,如回復被錯誤描述為出口流量和其他等已經修復,同時測試也得到了改進,以便及早發現潛在的問題。
Kubernetes Cgroup 增強
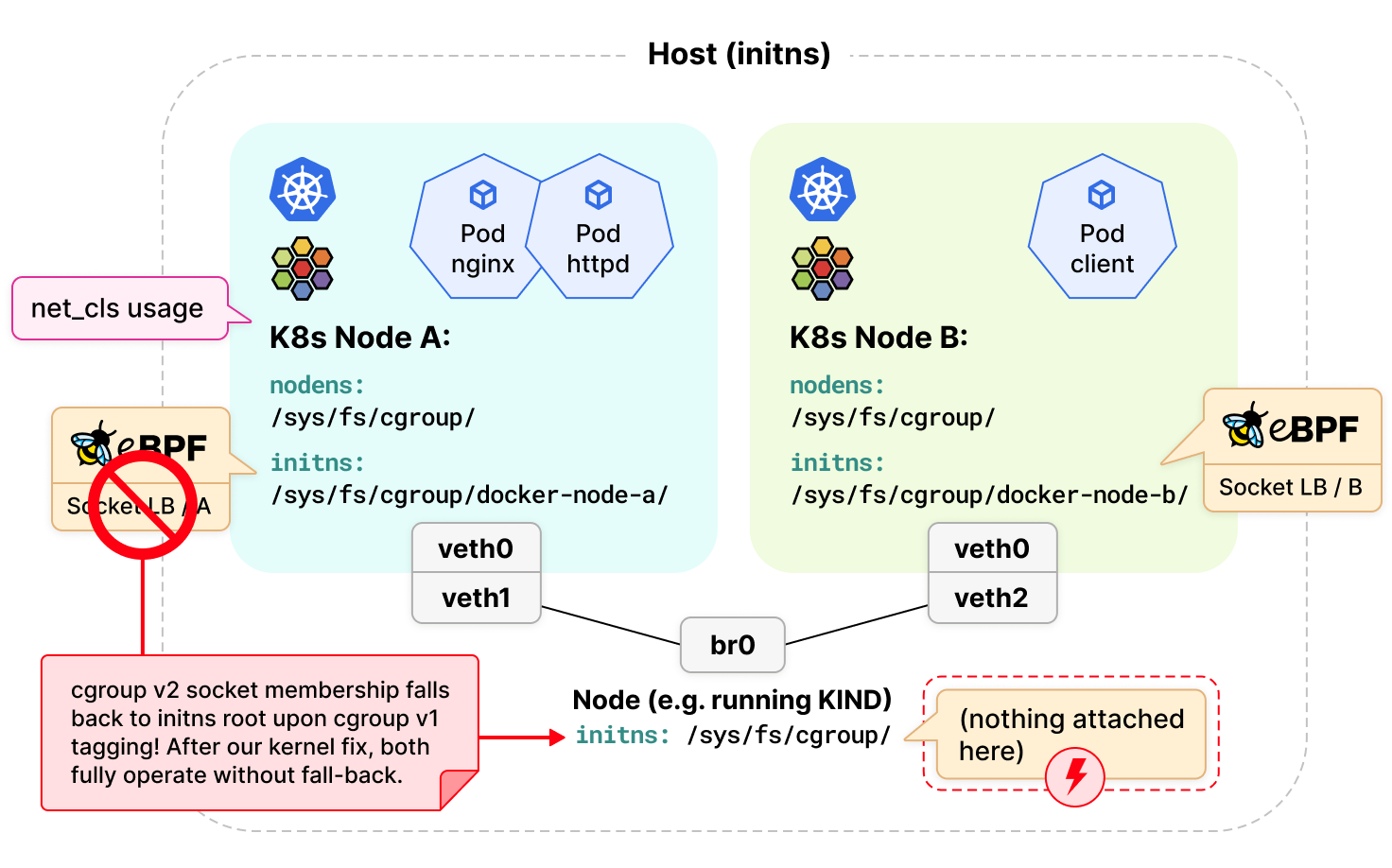
Cilium 使用 eBPF 替代 kube-proxy 作為獨立負載均衡器的優勢之一是能夠將 eBPF 程式附加到 socket hooks 上,例如 connect(2)、bind(2)、sendmsg(2) 以及其他各種相關的系統調用,以便透明地將本地的應用程式連接到後端服務。但是這些程式只能被附加到 cgroup v2。雖然 Kubernetes 正在努力遷移到 cgroup v2,但目前絕大多數用戶的環境都是 cgroup v1 和 v2 混合使用。
Linux 在內核的 socket 對象中標記了 socket 與 cgroup 的關係,並且由於 6 年前的一個設定,cgroup v1 和 v2 的 socket 標籤是互斥的。這就意味著,如果一個 socket 是以 cgroup v2 成員身份創建的,但後來通過具有 cgroup v1 成員身份的 net_prio 或 net_cls 控制器進行了標記,那麼 cgroup v2 就不會執行附加在 Pod 子路徑上的程式,而是回退執行附加到 cgroup v2 層次結構 (hierarchy) 根部的 eBPF 程式。這樣就會導致一個很嚴重的後果,如果連 cgroup v2 根部都沒有附加程式,那麼整個 cgroup v2 層次結構 (hierarchy) 都會被繞過。
現如今,cgroup v1 和 v2 不能並行運行的假設不再成立,具體可參考今年早些時候的 Linux Plumbers 會議演講。只有在極少數情況下,當被標記為 cgroup v2 成員身份的 eBPF 程式附加到 cgroup v2 層次結構的子系統時,Kubernetes 集群中的 cgroup v1 網路控制器才會繞過該 eBPF 程式。為了在數據包處理路徑上的盡量前面(early)的位置解決這個問題,Cilium 團隊最近對 Linux 內核進行了修復,實現了在所有場景下允許兩種 cgroup 版本 (part1, part2) 之間相互安全操作。這個修復不僅使 Cilium 的 cgroup 操作完全健壯可靠,而且也造福了 Kubernetes 中所有其他 eBPF cgroup 用戶。
此外,Kubernetes 和 Docker 等容器運行時最近開始陸續宣布支援 cgroup v2。在 cgroup v2 模式下,Docker 默認會切換到私有 cgroup 命名空間,即每個容器(包括 Cilium)都在自己的私有 cgroup 命名空間中運行。Cilium 通過確保 eBPF 程式附加到正確的 cgroup 層次結構的 socket hooks 上,使 Cilium 基於套接字的負載均衡在 cgroup v2 環境中能正常工作。
增強負載均衡器的可擴展性
主要外部貢獻者:Weilong Cui (Google)
最近的測試表明,對於運行著 Cilium 且 Kubernetes Endpoints 超過 6.4 萬的大型 Kubernetes 環境,Service 負載均衡器會受到限制。有兩個限制因素:
- Cilium 使用 eBPF 替代 kube-proxy 的獨立負載均衡器的本地後端 ID 分配器仍被限制在 16 位 ID 空間內。
- Cilium 用於 IPv4 和 IPv6 的 eBPF datapath 後端映射所使用的密鑰類型被限制在 16 位 ID 空間內。
為了使 Kubernetes 集群能夠擴展到超過 6.4 萬 Endpoints,Cilium 的 ID 分配器以及相關的 datapath 結構已被轉換為使用 32 位 ID 空間。
Cilium Endpoint Slices
主要外部貢獻者:Weilong Cui (Google), Gobinath Krishnamoorthy (Google)
在 1.11 版本中,Cilium 增加了對新操作模式的支援,該模式通過更有效的 Pod 資訊廣播方式大大提高了 Cilium 的擴展能力。
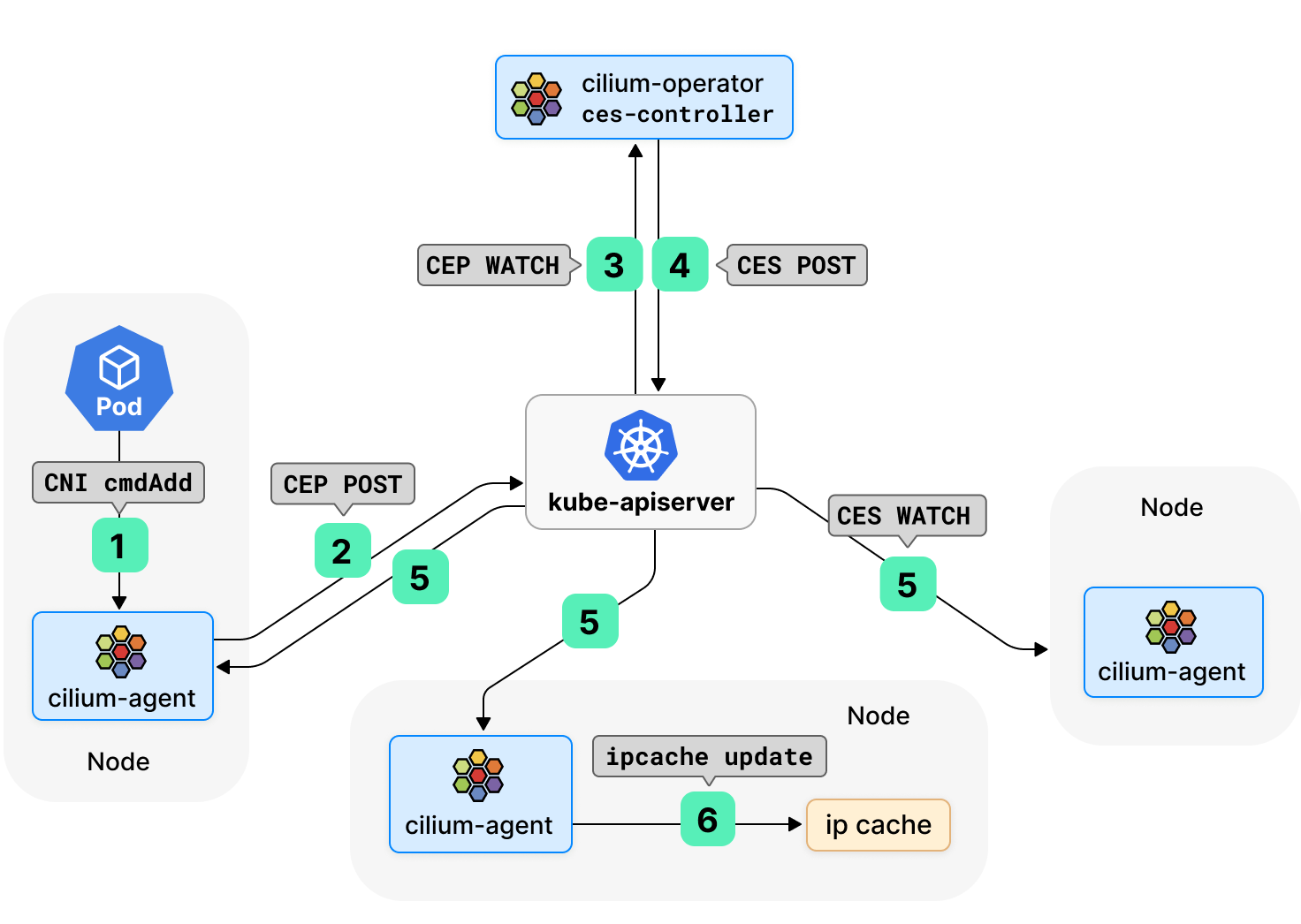
之前,Cilium 通過 watch CiliumEndpoint (CEP) 對象來廣播 Pod 的 IP 地址和安全身份資訊,這種做法在可擴展性方面會帶來一定的挑戰。每個 CEP 對象的創建/更新/刪除都會觸發 watch 事件的組播,其規模與集群中 Cilium-agent 的數量呈線性關係,而每個 Cilium-agent 都可以觸發這樣的扇出動作。如果集群中有 N 個節點,總 watch 事件和流量可能會以 N^2 的速率二次擴展。
Cilium 1.11 引入了一個新的 CRD CiliumEndpointSlice (CES),來自同一命名空間下的 CEPs 切片會被 Operator 組合成 CES 對象。在這種模式下,Cilium-agents 不再 watch CEP,而是 watch CES,大大減少了需要經由 kube-apiserver 廣播的 watch 事件和流量,進而減輕 kube-apiserver 的壓力,增強 Cilium 的可擴展性。
由於 CEP 大大減輕了 kube-apiserver 的壓力,Cilium 現在已經不再依賴專用的 ETCD 實例(KVStore 模式)。對於 Pod 數量劇烈變化的集群,我們仍然建議使用 KVStore,以便將 kube-apiserver 中的處理工作卸載到 ETCD 實例中。
這種模式權衡了「更快地傳播 Endpoint 資訊」和「擴展性更強的控制平面」這兩個方面,并力求雨露均沾。注意,與 CEP 模式相比,在規模較大時,如果 Pod 數量劇烈變化(例如大規模擴縮容),可能會產生較高的 Endpoint 資訊傳播延遲,從而影響到遠程節點。
GKE 最早採用了 CES,我們在 GKE 上進行了一系列「最壞情況」規模測試,發現 Cilium 在 CES 模式下的擴展性要比 CEP 模式強很多。從 1000 節點規模的負載測試來看,啟用 CES 後,watch 事件的峰值從 CEP 的 18k/s 降低到 CES 的 8k/s,watch 流量峰值從 CEP 的 36.6Mbps 降低到 CES 的 18.1Mbps。在控制器節點資源使用方面,它將 CPU 的峰值使用量從 28 核/秒減少到 10.5 核/秒。


詳情請參考 Cilium 官方文檔。
Kube-Proxy-Replacement 支援 Istio
許多用戶在 Kubernetes 中使用 eBPF 自帶的負載均衡器來替代 kube-proxy,享受基於 eBPF 的 datapath 帶來的高效處理方式,避免了 kube-proxy 隨著集群規模線性增長的 iptables 規則鏈條。
eBPF 對 Kubernetes Service 負載均衡的處理在架構上分為兩個部分:
- 處理進入集群的外部服務流量(南北方向)
- 處理來自集群內部的服務流量(東西方向)
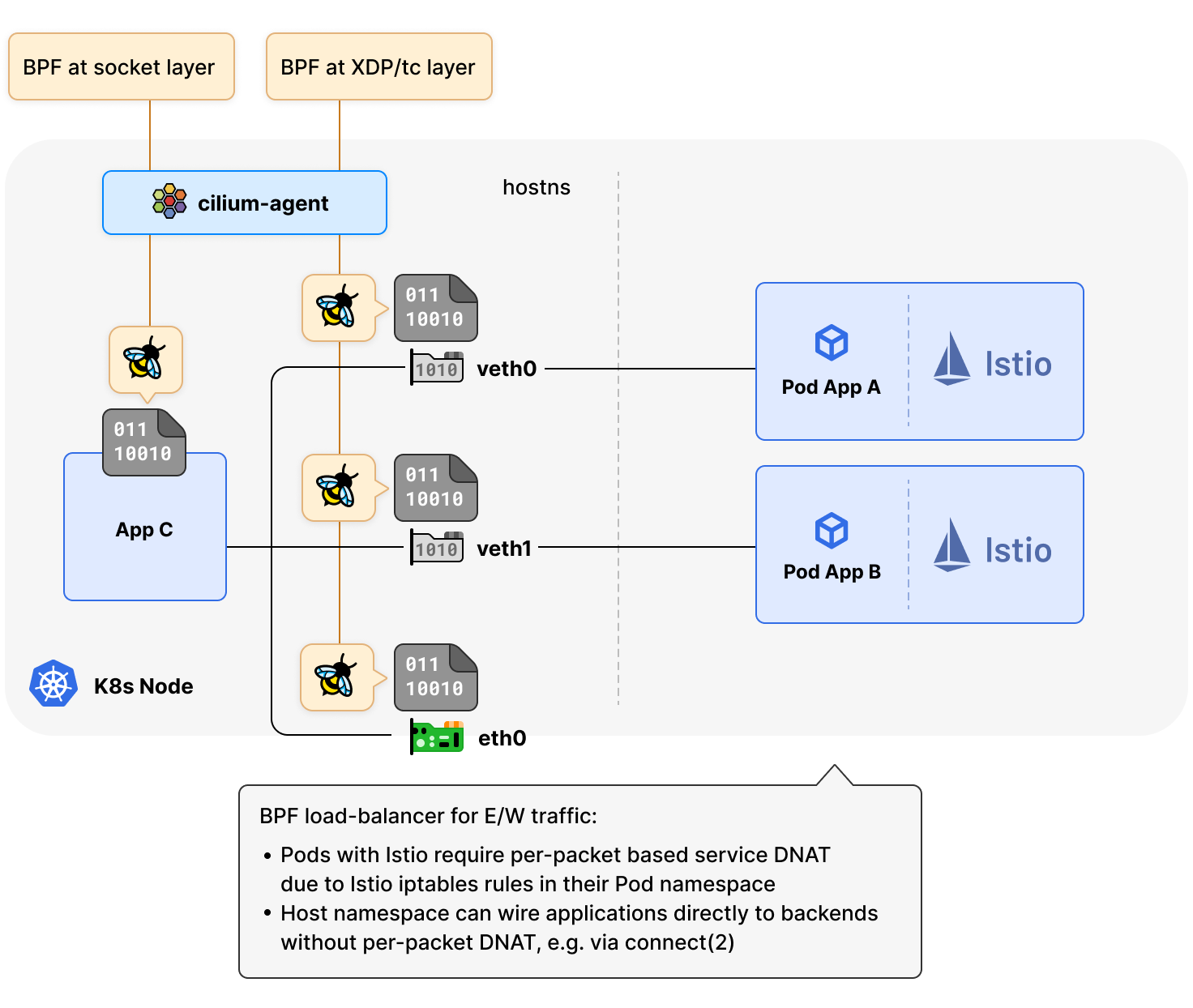
在 eBPF 的加持下,Cilium 在南北方向已經實現了儘可能靠近驅動層(例如通過 XDP)完成對每個數據包的處理;東西流量的處理則儘可能靠近 eBPF 應用層,處理方式是將應用程式的請求(例如 TCP connect(2))從 Service 虛擬 IP 直接「連接」到後端 IP 之一,以避免每個數據包的 NAT 轉換成本。
Cilium 的這種處理方式適用於大多數場景,但還是有一些例外,比如常見的服務網格解決方案(Istio 等)。Istio 依賴 iptables 在 Pod 的網路命名空間中插入額外的重定向規則,以便應用流量在離開 Pod 進入主機命名空間之前首先到達代理 Sidecar(例如 Envoy),然後通過 SO_ORIGINAL_DST 從其內部 socket 直接查詢 Netfilter 連接跟蹤器,以收集原始服務目的地址。
所以在 Istio 等服務網格場景下,Cilium 改進了對 Pod 之間(東西方向)流量的處理方式,改成基於 eBPF 的 DNAT 完成對每個數據包的處理,而主機命名空間內的應用仍然可以使用基於 socket 的負載均衡器,以避免每個數據包的 NAT 轉換成本。
要想開啟這個特性,只需在新版 Cilium agent 的 Helm Chart 中設置 bpf-lb-sock-hostns-only: true 即可。詳細步驟請參考 Cilium 官方文檔。
特性增強與棄用
以下特性得到了進一步增強:
- 主機防火牆 (Host Firewall) 從測試版 (beta) 轉為穩定版 (stable)。主機防火牆通過允許 CiliumClusterwideNetworkPolicies 選擇集群節點來保護主機網路命名空間。自從引入主機防火牆功能以來,我們已經大大增加了測試覆蓋率,並修復了部分錯誤。我們還收到了部分社區用戶的回饋,他們對這個功能很滿意,並準備用於生產環境。
以下特性已經被棄用:
- Consul 之前可以作為 Cilium 的 KVStore 後端,現已被棄用,推薦使用更經得起考驗的 Etcd 和 Kubernetes 作為 KVStore 後端。之前 Cilium 的開發者主要使用 Consul 進行本地端到端測試,但在最近的開發周期中,已經可以直接使用 Kubernetes 作為後端來測試了,Consul 可以退休了。
- IPVLAN 之前用來作為 veth 的替代方案,用於提供跨節點 Pod 網路通訊。在 Cilium 社區的推動下,大大改進了 Linux 內核的性能,目前 veth 已經和 IPVLAN 性能相當。具體可參考這篇文章:eBPF 主機路由。
- 策略追蹤 (Policy Tracing) 在早期 Cilium 版本中被很多 Cilium 用戶使用,可以通過 Pod 中的命令行工具
cilium policy trace來執行。然而隨著時間的推移,它沒有跟上 Cilium 策略引擎的功能進展。Cilium 現在提供了更好的工具來追蹤 Cilium 的策略,例如網路策略編輯器和 Policy Verdicts。


