HashMap有幾種遍歷方法?推薦使用哪種?
本文已收錄《面試精選》系列,Gitee 開源地址://gitee.com/mydb/interview
HashMap 的遍歷方法有很多種,不同的 JDK 版本有不同的寫法,其中 JDK 8 就提供了 3 種 HashMap 的遍歷方法,並且一舉打破了之前遍歷方法「很臃腫」的尷尬。
1.JDK 8 之前的遍歷
JDK 8 之前主要使用 EntrySet 和 KeySet 進行遍歷,具體實現程式碼如下。
1.1 EntrySet 遍歷
EntrySet 是早期 HashMap 遍歷的主要方法,其實現程式碼如下:
public static void main(String[] args) {
// 創建並賦值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循環遍歷
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
以上程式的執行結果,如下圖所示:
1.2 KeySet 遍歷
KeySet 的遍歷方式是循環 Key 內容,再通過 map.get(key) 獲取 Value 的值,具體實現如下:
public static void main(String[] args) {
// 創建並賦值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循環遍歷
for (String key : map.keySet()) {
System.out.println(key + ":" + map.get(key));
}
}
以上程式的執行結果,如下圖所示:
KeySet 性能問題
通過以上程式碼,我們可以看出使用 KeySet 遍歷,其性能是不如 EntrySet 的,因為 KeySet 其實循環了兩遍集合,第一遍循環是循環 Key,而獲取 Value 有需要使用 map.get(key),相當於有循環了一遍集合,所以 KeySet 循環不能建議使用,因為循環了兩次,效率比較低。
1.3 EntrySet 迭代器遍歷
EntrySet 和 KeySet 除了以上直接循環外,我們還可以使用它們的迭代器進行循環,如 EntrySet 的迭代器實現程式碼如下:
public static void main(String[] args) {
// 創建並賦值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循環遍歷
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
以上程式的執行結果,如下圖所示:
1.4 KeySet 迭代器遍歷
KeySet 也可以使用迭代器的方式進行遍歷,實現程式碼如下:
public static void main(String[] args) {
// 創建並賦值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循環遍歷
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
String key = iterator.next();
System.out.println(key + ":" + map.get(key));
}
}
以上程式的執行結果,如下圖所示:
雖然 KeySet 循環方式不推薦使用,但還是有必要了解一下的。
1.5 迭代器的作用
既然能直接遍歷,那為什麼還要用迭代器呢?通過以下例子我們就知道了。
不使用迭代器刪除
如果不使用迭代器,假如我們在遍歷 EntrySet 時,在遍歷程式碼中刪除元素,程式碼的實現如下:
public static void main(String[] args) {
// 創建並賦值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循環遍歷
for (Map.Entry<String, String> entry : map.entrySet()) {
if ("Java".equals(entry.getKey())) {
// 刪除此項
map.remove(entry.getKey());
continue;
}
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
以上程式的執行結果,如下圖所示:

可以看到,如果在遍歷的程式碼中動態刪除元素,非迭代器的方式就會報錯。
使用迭代器刪除
接下來,我們使用迭代器循環 EntrySet,並且在循環中動態刪除元素,實現程式碼如下:
public static void main(String[] args) {
// 創建並賦值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循環遍歷
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
if ("Java".equals(entry.getKey())) {
// 刪除此項
iterator.remove();
continue;
}
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
以上程式的執行結果,如下圖所示:

從上述結果可以看出,使用迭代器的優點是可以在循環的時候,動態的刪除集合中的元素。而上面非迭代器的方式則不能在循環的過程中刪除元素(程式會報錯)。
2.JDK 8 之後的遍歷
在 JDK 8 之後 HashMap 的遍歷就變得方便很多了,JDK 8 中包含了以下 3 種遍歷方法:
- 使用 Lambda 遍歷
- 使用 Stream 單執行緒遍歷
- 使用 Stream 多執行緒遍歷
我們分別來看。
2.1 Lambda 遍歷
使用 Lambda 表達式的遍歷方法實現程式碼如下:
public static void main(String[] args) {
// 創建並賦值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循環遍歷
map.forEach((key, value) -> {
System.out.println(key + ":" + value);
});
}
以上程式的執行結果,如下圖所示:

2.2 Stream 單執行緒遍歷
Stream 遍歷是先得到 map 集合的 EntrySet,然後再執行 forEach 循環,實現程式碼如下:
public static void main(String[] args) {
// 創建並賦值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循環遍歷
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
以上程式的執行結果,如下圖所示:
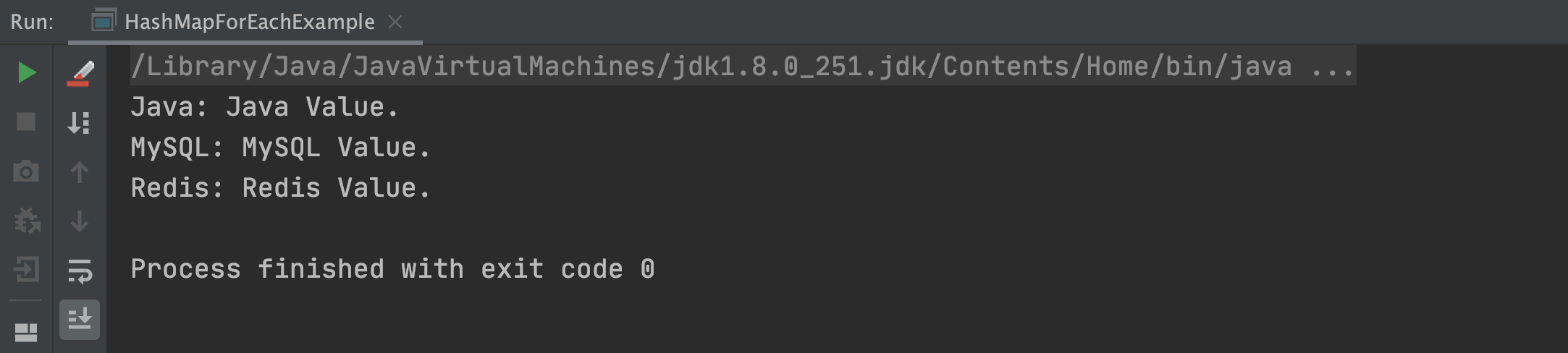
2.3 Stream 多執行緒遍歷
Stream 多執行緒的遍歷方式和上一種遍歷方式類似,只是多執行了一個 parallel 並發執行的方法,此方法會根據當前的硬體配置生成對應的執行緒數,然後再進行遍歷操作,實現程式碼如下:
public static void main(String[] args) {
// 創建並賦值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循環遍歷
map.entrySet().stream().parallel().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
以上程式的執行結果,如下圖所示:
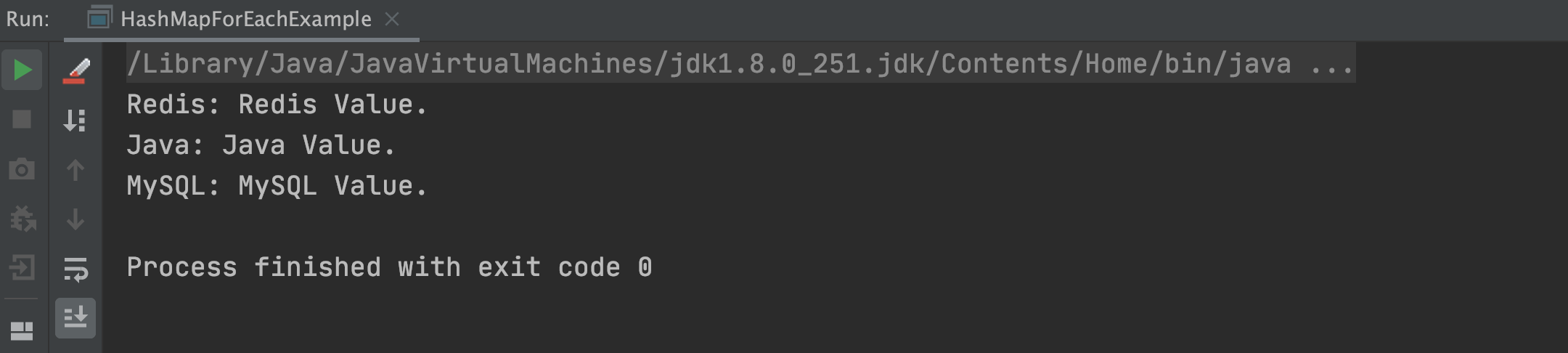
注意上述圖片的執行結果,可以看出當前執行結果和之前的所有遍歷結果都不一樣(列印元素的順序不一樣),因為程式是並發執行的,所以沒有辦法保證元素的執行順序和列印順序,這就是並發編程的特點。
推薦使用哪種遍歷方式?
不同的場景推薦使用的遍歷方式是不同的,例如,如果是 JDK 8 之後的開發環境,推薦使用 Stream 的遍歷方式,因為它足夠簡潔;而如果在遍歷的過程中需要動態的刪除元素,那麼推薦使用迭代器的遍歷方式;如果在遍歷的時候,比較在意程式的執行效率,那麼推薦使用 Stream 多執行緒遍歷的方式,因為它足夠快。所以這個問題的答案是不固定的,我們需要知道每種遍歷方法的優缺點,再根據不同的場景靈活變通。
總結
本文介紹了 7 種 HashMap 的遍歷方式,其中 JDK 8 之前主要使用 EntrySet 和 KeySet 的遍歷方式,而 KeySet 的遍歷方式性能比較低,一般不推薦使用。然而在 JDK 8 之後遍歷方式就有了新的選擇,可以使用比較簡潔的 Lambda 遍歷,也可以使用性能比較高的 Stream 多執行緒遍歷。
是非審之於己,毀譽聽之於人,得失安之於數。
部落客介紹:80 後程式設計師,寫部落格這件事「堅持」了 11 年,愛好:讀書、慢跑、羽毛球。
公眾號:Java面試真題解析


