【每天五分鐘大數據-第一期】 偽分散式+Hadoopstreaming
說在前面
之前一段時間想著把 LeetCode 每個專題完結之後,就開始著手大數據和演算法的內容。
想來想去,還是應該穿插著一起做起來。
畢竟,如果只寫一類的話,如果遇到其他方面,一定會遺漏一些重要的點。
LeetCode 專題復盤,已經進行了一大半了。
大數據計劃
正式開始有更新大數據想法的時候,想著把平常要注意的問題以及重要的知識點寫出來。
可是之後想著咱們讀者大部分是畢業前後的學生,還是從基礎的開始分享。
很多人已經在 hive、HBASE、Spark、Flink 這幾個方面使用的很熟練了,也有的人雖然使用了,但還是感覺對於大數據比較模糊。
後面一步一步都把基礎的、核心的、重要的點給大家分享出來。
另外,這裡的計劃是每天或者每兩天更新一個大數據的小知識點,每天 5 分鐘了解和理解一個小的知識點。
後面會逐步把 HDFS、hive、Hase、Spark、YARN、Kafka、Zookeeper等逐個突破!
跟著這個專題看下去,一定會對大數據有一個本質的理解。

感受大數據
開始想著用什麼內容作為開篇。
從感受開始吧!
既然是學習和感受大數據,那麼,一個環境是必須要的。
下面咱們分三塊內容進行分分享。
1、hadoop偽分散式環境搭建(需要的相關文件已經給大家準備好,文末可取!);
2、使用官方的 WordCount 程式進行感受;
3、自己寫一個 hadoop Streaming 計算 WordCount。
ps:雖然偽分散式和wc老生常談了,但是偽分散式用來測試功能還是不錯的。另外,這兩點作為大數據開篇也是完美的!
搭建一個偽分散式環境
我這邊是在一台伺服器上搭建的,配置是2核2G。
也可以在虛擬機上搭建!
第 ① 步 安裝 jdk
官網下載地址://www.oracle.com/java/technologies/downloads/#java8
這邊選擇jdk8進行下載(文末取)
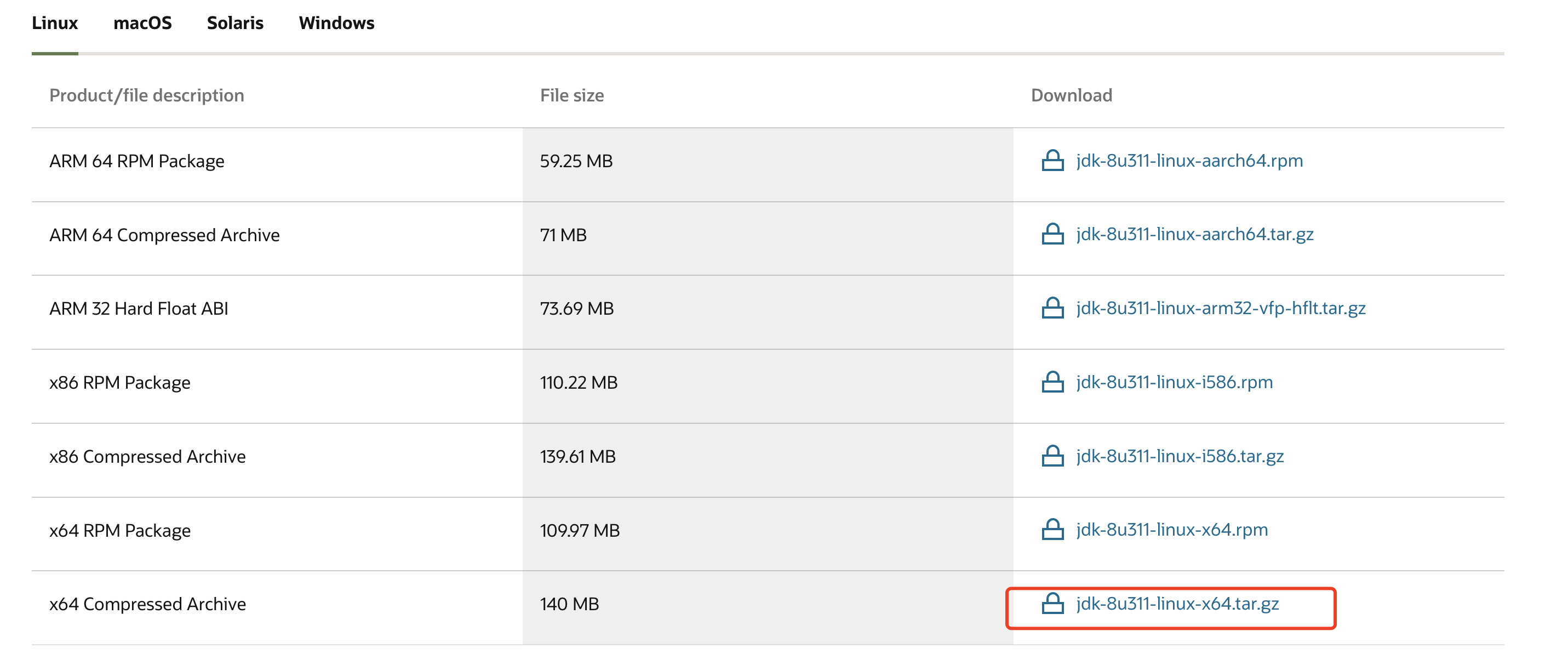
在創建 /usr/local/src/ 下,創建 java 文件,將 jdk 解壓到這裡。
mkdir -p /usr/local/src/java
tar -xvf jdk-8u311-linux-x64.tar -C /usr/local/java/src
第 ② 步 配置環境變數
直接在 /etc/profile 的行末進行配置,也可以根據自己實際情況進行配置。
vim /etc/profile
# 行末添加
export JAVA_HOME=/usr/local/src/java/jdk1.8.0_311/
export PATH=$JAVA_HOME/bin:$PATH
刷新配置:
source /etc/profile
驗證java是否安裝成功:
# java -version
java version "1.8.0_311"
Java(TM) SE Runtime Environment (build 1.8.0_311-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.311-b11, mixed mode)
此時,以上顯示就是安裝成功的!
第 ③ 步 上傳 hadoop 壓縮包(文末取)
這裡選取的是 2.6.1,然後進行解壓到指定目錄
mkdir -p /usr/local/src/hadoop
tar -xvf hadoop-2.6.1.tar.gz -C /usr/local/src/hadoop/
第 ④ 步 修改 hadoop 配置文件
我們需要修改的文件有 5 個,位置都是在 /usr/local/src/hadoop/hadoop-2.6.1/etc/hadoop下
5 個文件分別為:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml.template
yarn-site.xml
4.1 hadoop-env.sh 文件
該文件主要是java環境的配置,使用 vim 打開之後,進行配置。
注意:這裡一定是原始的路徑,而非環境變數名
export JAVA_HOME=/usr/local/src/java/jdk1.8.0_311/
4.2 配置 core-site.xml
用於定義系統級別的參數,如HDFS URI 、Hadoop的臨時目錄等
<configuration>
<!-- 指定hadoop所使用文件系統schema(URI形式),這裡我們使用的HDFS,以及主節點NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop運行時產生文件的存儲目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/hadoop-2.6.1/data</value>
</property>
</configuration>
4.3 配置 hdfs-site.xml
這裡可以定義HDFS中文件副本數量,一般情況配置為 3,但是咱們今天是偽分散式,就一台機器,設置為 1 就好。
<configuration>
<!-- 指定HDFS副本數量,由於此次搭建是偽分散式,所以value指定為1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.4 配置 mapred-site.xml 文件
系統給的是一個模板 mapred-site.xml.template 文件,首先拷貝一份進行配置
cp mapred-site.xml.template mapred-site.xml
然後進行yarn的主節點配置,以及 map 結果傳遞給 reduce 的 shuffle 機制。
<configuration>
<!-- 指定 yarn 的主節點地址(ResourceManager) -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!-- reduce 獲取數據的方式,map 產生的結果傳給 reduce 的機制(shuffle) -->
<property>
<name>yarn.nodemanager.aux.services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.5 配置 yarn-size.xml
配置ResourceManager ,nodeManager的通訊埠,web監控埠等
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>0.0.0.0:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>0.0.0.0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>0.0.0.0:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>0.0.0.0:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
</configuration>
第 ⑤ 步 hadoop添加到環境變數
和 java 環境變數的配置一樣,配置環境變數
vim /etc/profile
# 底部編輯
export HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.6.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH
刷新配置文件
source /etc/profile
第 ⑥ 步 初始化namenode
初始化 hdfs 格式,相當于格式化文件系統。
會往/usr/local/src/hadoop/hadoop-2.6.1/data寫文件
hadoop namenode -format
顯示格式化成功!

第 ⑦ 步 配置本地ssh 免密登錄
如果沒有配置本地 ssh 免密登錄,則在配置中會一直提示讓輸入用戶密碼
yum -y install openssh-server
如果本地ssh正常就不用配置了
之後,
ssh-keygen -t rsa
一直 enter 下去:
[root@iZ2zebkqy02hia7o7gj8paZ sbin]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:oZgJuXGvxnk5pkkfd3r5CT/+uxq9nJMn2xJWk5pa6so root@iZ2zebkqy02hia7o7gj8paZ
The key's randomart image is:
+---[RSA 3072]----+
| |
| . |
| + . . .|
| = = . . o.|
| . + o S o..|
| . o . =o |
| * * . o.=..o |
| o * +.oo=.+=+.|
| o . .Eo+*+OO.|
+----[SHA256]-----+
之後,
cd ~/.ssh/
cp id_rsa.pub authorized_keys
驗證一下:
ssh localhost
如果不用輸入密碼就跳轉登錄了,此時就 ok 了!
第 ⑧ 步 啟動 hadoop 集群
啟動的組件包括 HDFS 以及 yarn。
先啟動 HDFS,再啟動 yarn,均在 /usr/local/src/hadoop/hadoop-2.6.1/sbin下
./start-dfs.sh
./start-yarn.sh
正常的話,很快就啟動了。
啟動之後,使用 jps 看一下進程
35072 NodeManager
34498 DataNode
34644 SecondaryNameNode
34788 ResourceManager
34380 NameNode
82205 Jps
說明是成功的。
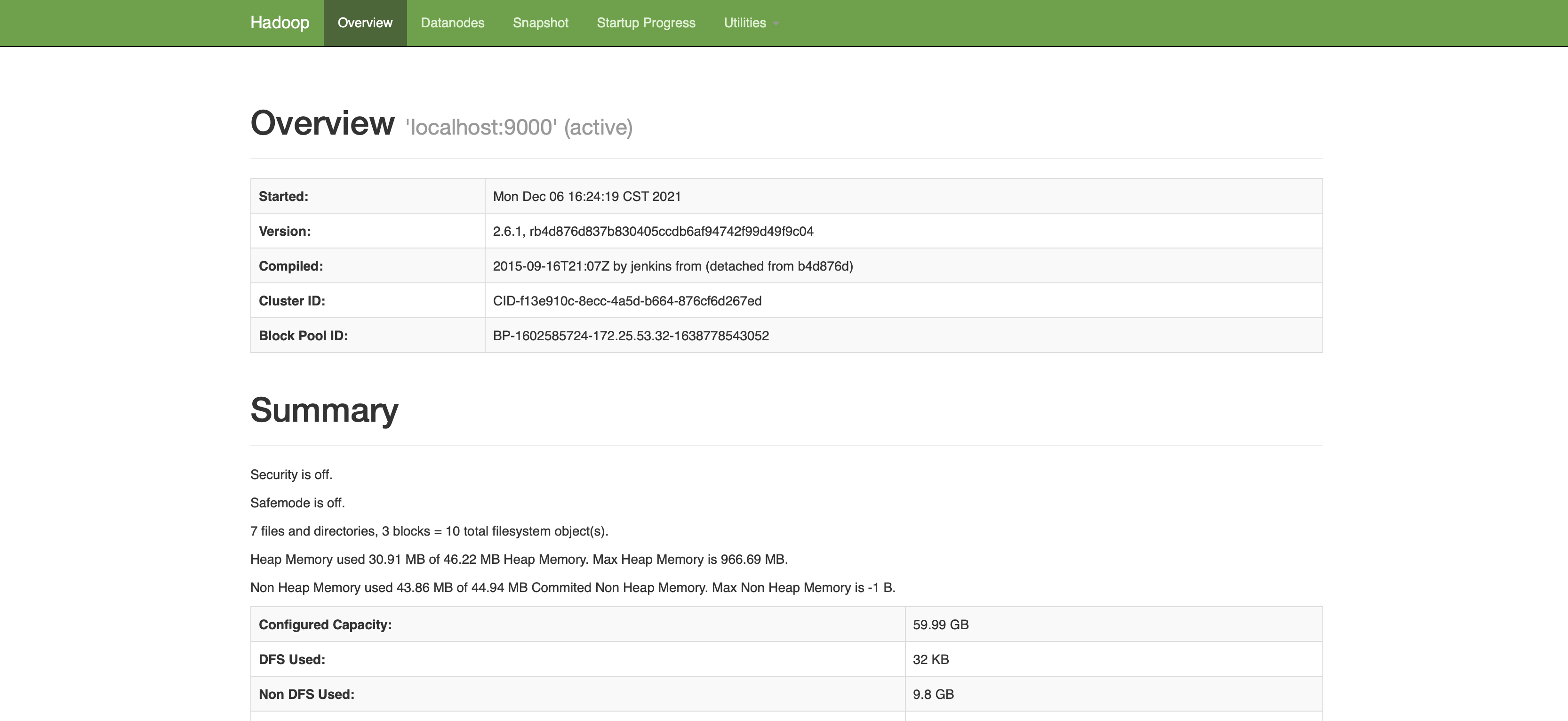
我這邊是在伺服器上配置的,所以想要訪問 hdfs 或者 yarn,需要直接使用 ip 地址就可以訪問了。
HDFS的web介面:ip:50070(ip更換為自己的地址)
yarn的web介面:ip:8088(ip更換為自己的地址)
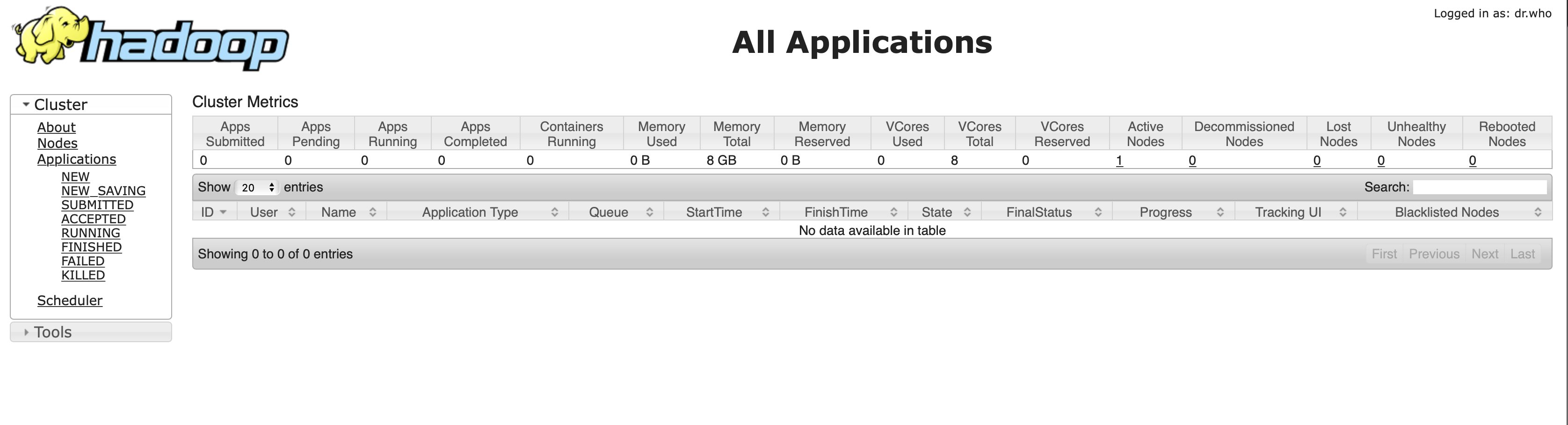
那到現在,一個偽分散式的集群就搭建好了,包括了HDFS、Yarn、MapReduce 等組件。
下面首先使用 hadoop 自帶的一個例子實現 WordCount。
系統 WordCount 演示
首先,咱們看到系統自帶的 WordCount 文件的 jar 包在 /usr/local/src/hadoop/hadoop-2.6.1/share/hadoop/mapreduce 下的 hadoop-mapreduce-examples-2.6.1.jar。
預備需要做的就是創建一個文本文件,然後使用提供的 jar 包進行對文本文件中單詞的計數。
首先,創建兩個文件,分別填入不同的內容。
在 /usr/local/src/hadoop/hadoop-2.6.1/data/ 下創建了 data1.txt 和 data2.txt。
vim data1.txt
vim data2.txt
data1.txt的內容
hadoop flink spark
kafka hive
hbase flink hadoop spark
spark
hbase spark hadoop
data2.txt的內容
hadoop flink spark
kafka hive hbase flink hadoop spark
spark hbase spark hadoop
然後,在 HDFS 創建/input 目錄,並且把上述兩個文件上傳
# 創建 input 目錄
hadoop dfs -mkdir /input
# 上傳文件到 input 目錄下
hadoop dfs -put data* /input/
查看,已經上傳成功
hadoop dfs -ls /input
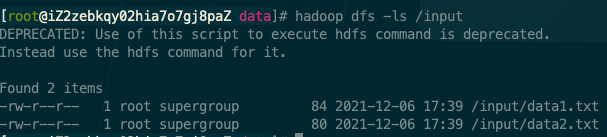
可以在 HDFS 的 web 介面進行查看。

使用自帶的例子進行 WordCount 案例演示
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.1.jar wordcount /input /out

可以看到本地集群的 1 號任務。

最後,查看計算結果
[root@iZ2zebkqy02hia7o7gj8paZ hadoop-2.6.1]# hadoop dfs -ls /out
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Found 2 items
-rw-r--r-- 1 root supergroup 0 2021-12-06 18:28 /out/_SUCCESS
-rw-r--r-- 1 root supergroup 48 2021-12-06 18:28 /out/part-r-00000
[root@iZ2zebkqy02hia7o7gj8paZ hadoop-2.6.1]# hadoop dfs -text /out/part-r-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
flink 4
hadoop 6
hbase 4
hive 2
kafka 2
spark 8
同樣也可以在 web 頁面進行查看。
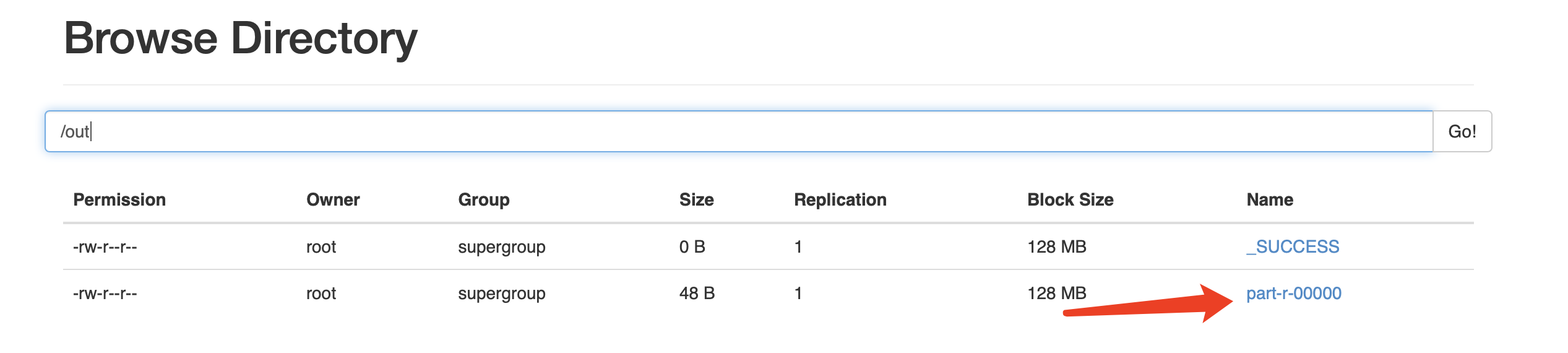
ok!至此,在偽分散式環境計算了第一個 MapReduce 任務。
系統案例感受完了,下面看看自己寫一個 MapReduce 任務。
第一個 MR 程式
通常開發一個 MR(MapReduce)程式,是用 Java 來進行開發的,本身 hadoop 生態也是用 Java實現。
所以,使用 Java 開發 MR 是最好的選擇。
但今天選取 Python 作為 MR 開發語言。
原因有二:其一、很多演算法同學對於 Python 的友好是不言而喻的。其二、MR 程式本身擔任的是離線任務,對實時性要求不高,但是對於開發效率的要求卻不低,Python 開發的MR程式,開箱即用。但用 Java 的話,需要配置一些jar環境,然後打包,上傳。。。
下面就用 Python 作為開發語言進行一個 WordCount 的實現。
官網這麼說:
Hadoop streaming是Hadoop的一個工具, 它幫助用戶創建和運行一類特殊的map/reduce作業, 這些特殊的map/reduce作業是由一些可執行文件或腳本文件充當mapper或者reducer。
例如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input myInputDirs \
-output myOutputDir \
-mapper /bin/cat \
-reducer /bin/wc
是的,看文檔,咱們需要一個輸入文件地址,一個輸出文件地址。
另外,需要一個 mapper 程式以及一個 reducer 程式。
下面就開始搞吧!
首先,咱們需要一個 mapper 程式來進行將文件從標準輸入進行讀取
編寫 mapper.py:
#!/usr/bin/python
import sys
import re
for line in sys.stdin:
words = re.split(" +", line.strip())
for word in words:
print("%s\t%s" % (word, "1"))
其中使用正則 re 是防止單詞之間出現多個空格。
下面編寫 reducer.py:
#!/usr/bin/python
import sys
sum = 0
last_word = None
for line in sys.stdin:
word = line.strip().split("\t")
if len(word) != 2:
continue
word = word[0]
if last_word is None:
last_word = word
if last_word != word:
print('\t'.join([last_word, str(sum)]))
last_word = word
sum = 0
sum += 1
print('\t'.join([last_word, str(sum)]))
下面可以先進性一番測試,通過一個shell命令即可:
cat input_file | python mapper.py | sort -k1 | python reducer.py
最後,就可以編寫文檔中提供的 Hadoop streaming 工具了。
編寫 main.sh 調度 mapper 和 reducer:
#!/bin/bash
HADOOP_HOME="/usr/local/src/hadoop/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_PATH="/input"
OUTPUT_PATH="/out_streaming"
# 清空上次記錄
${HADOOP_HOME} dfs -rmr ${OUTPUT_PATH}
${HADOOP_HOME} jar ${STREAM_JAR_PATH} \
-input ${INPUT_PATH} \
-output ${OUTPUT_PATH} \
-mapper "python mapper.py" \
-reducer "python reducer.py" \
-file ./mapper.py \
-file ./reducer.py
下面當然是執行該文件了:
-x 可以查看執行的詳細資訊
sh -x main.sh
現在看下結果:
[root@iZ2zebkqy02hia7o7gj8paZ script]# hadoop fs -ls /out_streaming
Found 2 items
-rw-r--r-- 1 root supergroup 0 2021-12-07 15:43 /out_streaming/_SUCCESS
-rw-r--r-- 1 root supergroup 48 2021-12-07 15:43 /out_streaming/part-00000
[root@iZ2zebkqy02hia7o7gj8paZ script]# hadoop fs -text /out_streaming/part-00000
flink 4
hadoop 6
hbase 4
hive 2
kafka 2
spark 8
現在顯示的結果和上面使用系統默認wc提供程式的結果是一致的!
以上就是就關於「完虐大數據第一期」的全部分享了。
也本期算是作為一個大數據分享引子,下一期會把三台分散式集群的虛擬機分享出來,有需要的可以持續關注。
如果感覺內容對你有些許的幫助!
期待朋友們的點贊、在看!評論 和 轉發!
下期想看哪方面的,評論區告訴我!
好了~ 咱們下期再見!bye~~