尚矽谷數據倉庫實戰之2數倉分層+維度建模
@
數倉筆記
尚矽谷數據倉庫4.0影片教程
B站直達:2021新版電商數倉V4.0丨大數據數據倉庫項目實戰
百度網盤://pan.baidu.com/s/1FGUb8X0Wx7IWAmKXBRwVFg ,提取碼:yyds
阿里雲盤://www.aliyundrive.com/s/F2FuMVePj92 ,提取碼:335o
第1章 數倉分層
1.1 為什麼要分層

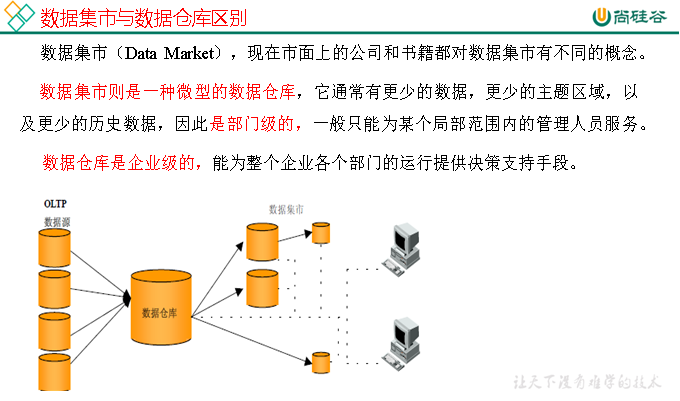
1.2數據集市與數據倉庫概念
1.3 數倉命名規範
1.3.1 表命名
Ø ODS層命名為ods_表名
Ø DIM層命名為dim_表名
Ø DWD層命名為dwd_表名
Ø DWS層命名為dws_表名
Ø DWT層命名為dwt_表名
Ø ADS層命名為ads_表名
Ø 臨時表命名為tmp_表名
1.3.2 腳本命名
Ø 數據源_to_目標_db/log.sh
Ø 用戶行為腳本以log為後綴;業務數據腳本以db為後綴。
1.3.3 表欄位類型
Ø 數量類型為bigint
Ø 金額類型為decimal(16, 2),表示:16位有效數字,其中小數部分2位
Ø 字元串(名字,描述資訊等)類型為string
Ø 主鍵外鍵類型為string
Ø 時間戳類型為bigint
第2章 數倉理論
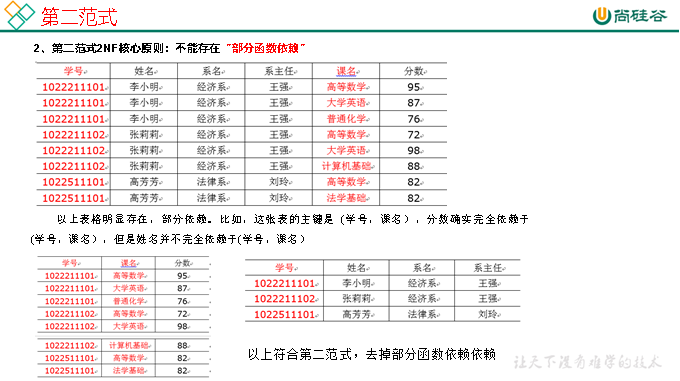
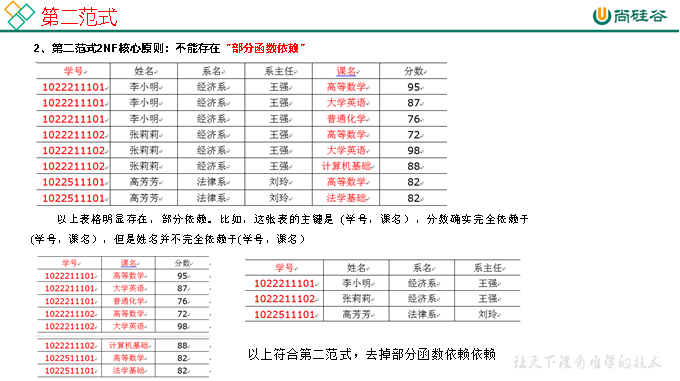
2.1 範式理論
2.1.1 範式概念
1)定義
數據建模必須遵循一定的規則,在關係建模中,這種規則就是範式。
2)目的
採用範式,可以降低數據的冗餘性。
為什麼要降低數據冗餘性?
(1)十幾年前,磁碟很貴,為了減少磁碟存儲。
(2)以前沒有分散式系統,都是單機,只能增加磁碟,磁碟個數也是有限的
(3)一次修改,需要修改多個表,很難保證數據一致性
3)缺點
範式的缺點是獲取數據時,需要通過Join拼接出最後的數據。
4)分類
目前業界範式有:第一範式(1NF)、第二範式(2NF)、第三範式(3NF)、巴斯-科德範式(BCNF)、第四範式(4NF)、第五範式(5NF)。
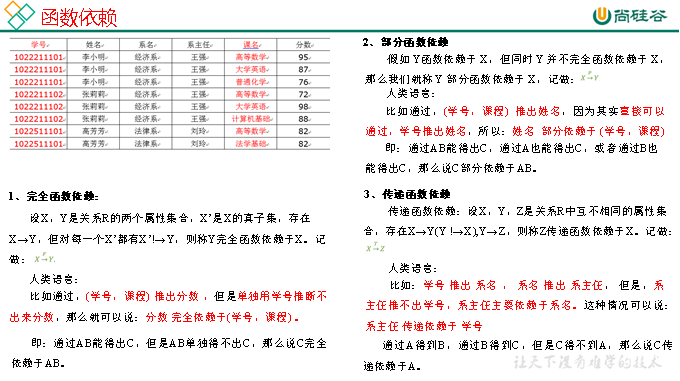
2.1.2 函數依賴
2.1.3 三範式區分

2.2 關係建模與維度建模
關係建模和維度建模是兩種數據倉庫的建模技術。關係建模由Bill Inmon所倡導,維度建模由Ralph Kimball所倡導。
2.2.1 關係建模
關係建模將複雜的數據抽象為兩個概念——實體和關係,並使用規範化的方式表示出來。關係模型如圖所示,從圖中可以看出,較為鬆散、零碎,物理表數量多。
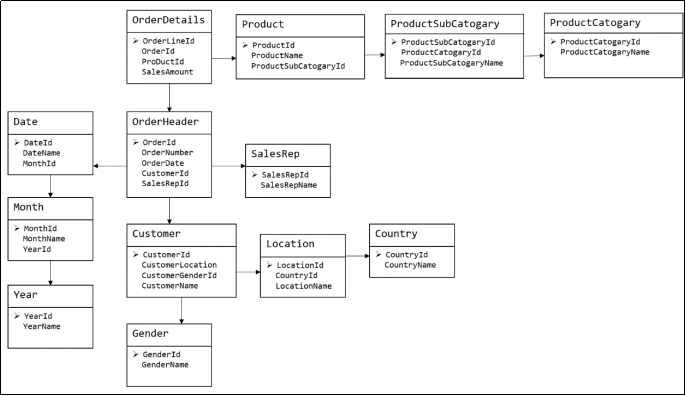
關係模型嚴格遵循第三範式(3NF),數據冗餘程度低,數據的一致性容易得到保證。由於數據分布於眾多的表中,查詢會相對複雜,在大數據的場景下,查詢效率相對較低。
2.2.2 維度建模
維度模型如圖所示,從圖中可以看出,模型相對清晰、簡潔。
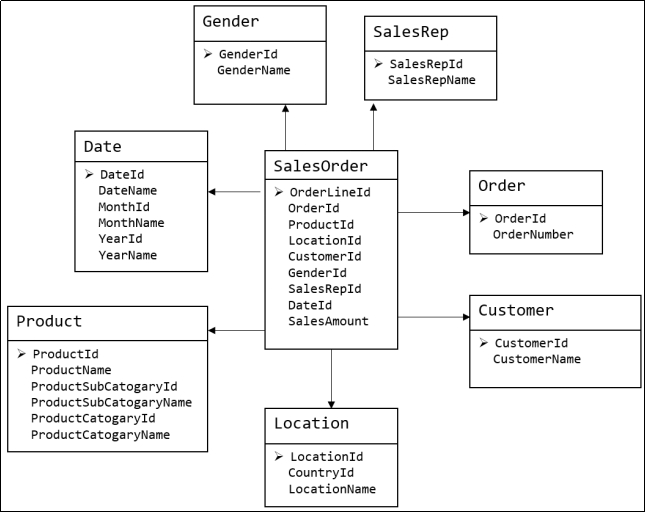
圖 維度模型示意圖
維度模型以數據分析作為出發點,不遵循三範式,故數據存在一定的冗餘。維度模型面向業務,將業務用事實表和維度表呈現出來。表結構簡單,故查詢簡單,查詢效率較高。
2.3 維度表和事實表(重點)
2.3.1 維度表
維度表:一般是對事實的描述資訊。每一張維表對應現實世界中的一個對象或者概念。 例如:用戶、商品、日期、地區等。
維表的特徵:
Ø 維表的範圍很寬(具有多個屬性、列比較多)
Ø 跟事實表相比,行數相對較小:通常< 10萬條
Ø 內容相對固定:編碼表
時間維度表:
| 日期ID | day of week | day of year | 季度 | 節假日 |
|---|---|---|---|---|
| 2020-01-01 | 2 | 1 | 1 | 元旦 |
| 2020-01-02 | 3 | 2 | 1 | 無 |
| 2020-01-03 | 4 | 3 | 1 | 無 |
| 2020-01-04 | 5 | 4 | 1 | 無 |
| 2020-01-05 | 6 | 5 | 1 | 無 |
2.3.2 事實表
事實表中的每行數據代表一個業務事件(下單、支付、退款、評價等)。「事實」這個術語表示的是業務事件的度量值(可統計次數、個數、金額等),例如,2020年5月21日,宋宋老師在京東花了250塊錢買了一瓶海狗人蔘丸。維度表:時間、用戶、商品、商家。事實表:250塊錢、一瓶
每一個事實表的行包括:具有可加性的數值型的度量值、與維表相連接的外鍵,通常具有兩個和兩個以上的外鍵。
事實表的特徵:
Ø 非常的大
Ø 內容相對的窄:列數較少(主要是外鍵id和度量值)
Ø 經常發生變化,每天會新增加很多。
1)事務型事實表
以每個事務或事件為單位,例如一個銷售訂單記錄,一筆支付記錄等,作為事實表裡的一行數據。一旦事務被提交,事實表數據被插入,數據就不再進行更改,其更新方式為增量更新。
2)周期型快照事實表
周期型快照事實表中不會保留所有數據,只保留固定時間間隔的數據,例如每天或者每月的銷售額,或每月的賬戶餘額等。
例如購物車,有加減商品,隨時都有可能變化,但是我們更關心每天結束時這裡面有多少商品,方便我們後期統計分析。
3)累積型快照事實表
累計快照事實表用於跟蹤業務事實的變化。例如,數據倉庫中可能需要累積或者存儲訂單從下訂單開始,到訂單商品被打包、運輸、和簽收的各個業務階段的時間點數據來跟蹤訂單聲明周期的進展情況。當這個業務過程進行時,事實表的記錄也要不斷更新。
| 訂單id | 用戶id | 下單時間 | 打包時間 | 發貨時間 | 簽收時間 | 訂單金額 |
|---|---|---|---|---|---|---|
| 3-8 | 3-8 | 3-9 | 3-10 |
2.4 維度模型分類
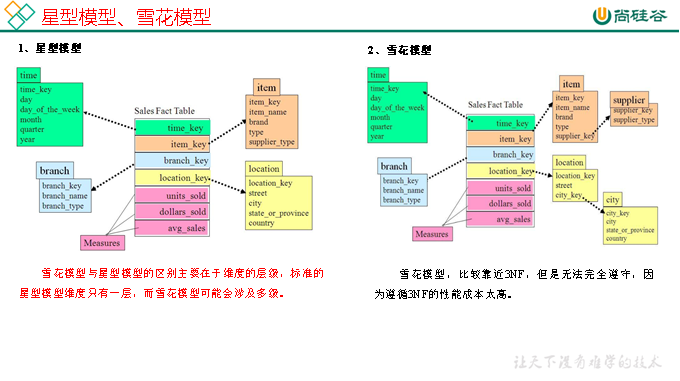
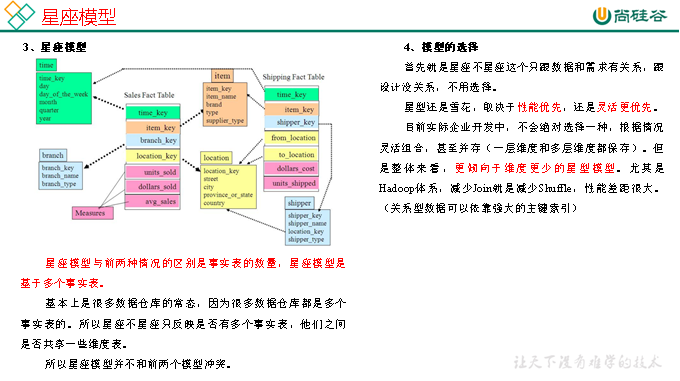
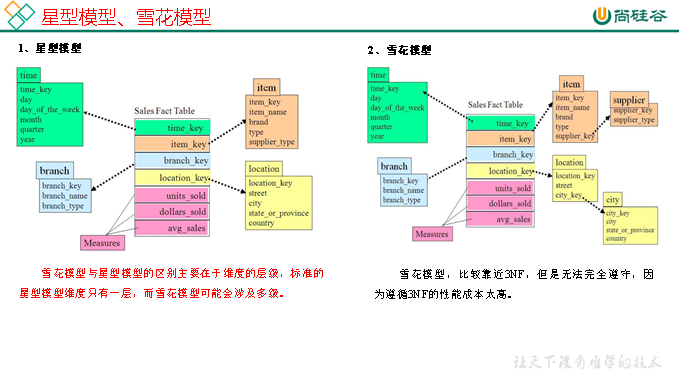
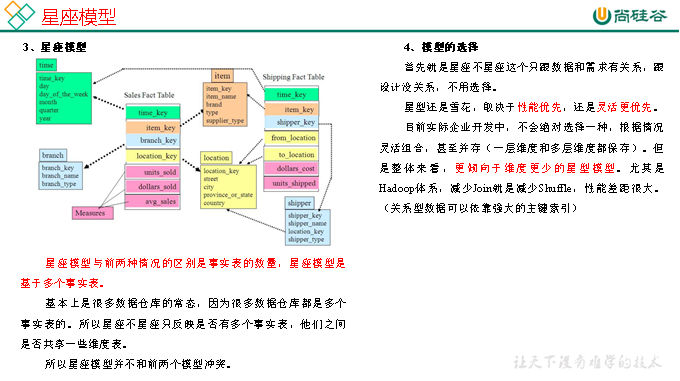
在維度建模的基礎上又分為三種模型:星型模型、雪花模型、星座模型。
2.5 數據倉庫建模(絕對重點)
2.5.1 ODS層
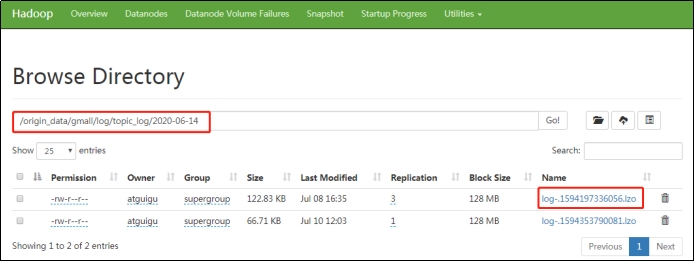
1)HDFS用戶行為數據
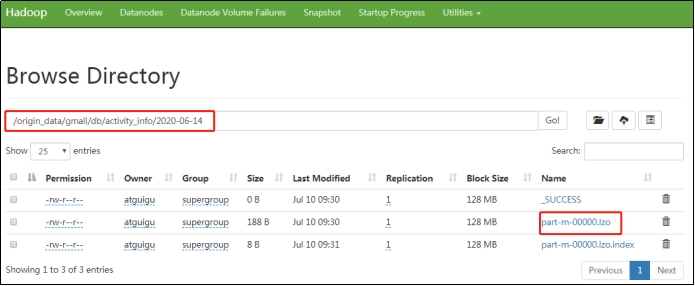
2)HDFS業務數據
3)針對HDFS上的用戶行為數據和業務數據,我們如何規劃處理?
(1)保持數據原貌不做任何修改,起到備份數據的作用。
(2)數據採用壓縮,減少磁碟存儲空間(例如:原始數據100G,可以壓縮到10G左右)
(3)創建分區表,防止後續的全表掃描
2.5.2 DIM層和DWD層
DIM層DWD層需構建維度模型,一般採用星型模型,呈現的狀態一般為星座模型。
維度建模一般按照以下四個步驟:
選擇業務過程→聲明粒度→確認維度→確認事實
(1)選擇業務過程
在業務系統中,挑選我們感興趣的業務線,比如下單業務,支付業務,退款業務,物流業務,一條業務線對應一張事實表。
(2)聲明粒度
數據粒度指數據倉庫的數據中保存數據的細化程度或綜合程度的級別。
聲明粒度意味著精確定義事實表中的一行數據表示什麼,應該儘可能選擇最小粒度,以此來應各種各樣的需求。
典型的粒度聲明如下:
訂單事實表中一行數據表示的是一個訂單中的一個商品項。
支付事實表中一行數據表示的是一個支付記錄。
(3)確定維度
維度的主要作用是描述業務是事實,主要表示的是「誰,何處,何時」等資訊。
確定維度的原則是:後續需求中是否要分析相關維度的指標。例如,需要統計,什麼時間下的訂單多,哪個地區下的訂單多,哪個用戶下的訂單多。需要確定的維度就包括:時間維度、地區維度、用戶維度。
(4)確定事實
此處的「事實」一詞,指的是業務中的度量值(次數、個數、件數、金額,可以進行累加),例如訂單金額、下單次數等。
在DWD層,以業務過程為建模驅動,基於每個具體業務過程的特點,構建最細粒度的明細層事實表。事實表可做適當的寬表化處理。
事實表和維度表的關聯比較靈活,但是為了應對更複雜的業務需求,可以將能關聯上的表盡量關聯上。
業務匯流排矩陣:
| 時間 | 用戶 | 地區 | 商品 | 優惠券 | 活動 | 度量值 | |
|---|---|---|---|---|---|---|---|
| 訂單 | √ | √ | √ | 運費/優惠金額/原始金額/最終金額 | |||
| 訂單詳情 | √ | √ | √ | √ | √ | √ | 件數/優惠金額/原始金額/最終金額 |
| 支付 | √ | √ | √ | 支付金額 | |||
| 加購 | √ | √ | √ | 件數/金額 | |||
| 收藏 | √ | √ | √ | 次數 | |||
| 評價 | √ | √ | √ | 次數 | |||
| 退單 | √ | √ | √ | √ | 件數/金額 | ||
| 退款 | √ | √ | √ | √ | 件數/金額 | ||
| 優惠券領用 | √ | √ | √ | 次數 |
至此,數據倉庫的維度建模已經完畢,DWD層是以業務過程為驅動。
DWS層、DWT層和ADS層都是以需求為驅動,和維度建模已經沒有關係了。
DWS和DWT都是建寬表,按照主題去建表。主題相當於觀察問題的角度。對應著維度表。
2.5.3 DWS層與DWT層
DWS層和DWT層統稱寬表層,這兩層的設計思想大致相同,通過以下案例進行闡述。
1)問題引出:兩個需求,統計每個省份訂單的個數、統計每個省份訂單的總金額
2)處理辦法:都是將省份表和訂單表進行join,group by省份,然後計算。同樣數據被計算了兩次,實際上類似的場景還會更多。
那怎麼設計能避免重複計算呢?
針對上述場景,可以設計一張地區寬表,其主鍵為地區ID,欄位包含為:下單次數、下單金額、支付次數、支付金額等。上述所有指標都統一進行計算,並將結果保存在該寬表中,這樣就能有效避免數據的重複計算。
3)總結:
(1)需要建哪些寬表:以維度為基準。
(2)寬表裡面的欄位:是站在不同維度的角度去看事實表,重點關注事實表聚合後的度量值。
(3)DWS和DWT層的區別:DWS層存放的所有主題對象當天的匯總行為,例如每個地區當天的下單次數,下單金額等,DWT層存放的是所有主題對象的累積行為,例如每個地區最近7天(15天、30天、60天)的下單次數、下單金額等。
2.5.4 ADS層