Go語言核心36講(Go語言實戰與應用二十)–學習筆記
- 2021 年 12 月 2 日
- 筆記
- 【016】Go語言核心36講
42 | bufio包中的數據類型 (上)
今天,我們來講另一個與 I/O 操作強相關的程式碼包bufio。bufio是「buffered I/O」的縮寫。顧名思義,這個程式碼包中的程式實體實現的 I/O 操作都內置了緩衝區。
bufio包中的數據類型主要有:
1、Reader;
2、Scanner;
3、Writer和ReadWriter。
與io包中的數據類型類似,這些類型的值也都需要在初始化的時候,包裝一個或多個簡單 I/O 介面類型的值。(這裡的簡單 I/O 介面類型指的就是io包中的那些簡單介面。)
下面,我們將通過一系列問題對bufio.Reader類型和bufio.Writer類型進行討論(以前者為主)。今天我的問題是:bufio.Reader類型值中的緩衝區起著怎樣的作用?
這道題的典型回答是這樣的。
bufio.Reader類型的值(以下簡稱Reader值)內的緩衝區,其實就是一個數據存儲中介,它介於底層讀取器與讀取方法及其調用方之間。所謂的底層讀取器,就是在初始化此類值的時候傳入的io.Reader類型的參數值。
Reader值的讀取方法一般都會先從其所屬值的緩衝區中讀取數據。同時,在必要的時候,它們還會預先從底層讀取器那裡讀出一部分數據,並暫存於緩衝區之中以備後用。
有這樣一個緩衝區的好處是,可以在大多數的時候降低讀取方法的執行時間。雖然,讀取方法有時還要負責填充緩衝區,但從總體來看,讀取方法的平均執行時間一般都會因此有大幅度的縮短。
問題解析
bufio.Reader類型並不是開箱即用的,因為它包含了一些需要顯式初始化的欄位。為了讓你能在後面更好地理解它的讀取方法的內部流程,我先在這裡簡要地解釋一下這些欄位,如下所示。
1、buf:[]byte類型的欄位,即位元組切片,代表緩衝區。雖然它是切片類型的,但是其長度卻會在初始化的時候指定,並在之後保持不變。
2、rd:io.Reader類型的欄位,代表底層讀取器。緩衝區中的數據就是從這裡拷貝來的。
3、r:int類型的欄位,代表對緩衝區進行下一次讀取時的開始索引。我們可以稱它為已讀計數。
4、w:int類型的欄位,代表對緩衝區進行下一次寫入時的開始索引。我們可以稱之為已寫計數。
5、err:error類型的欄位。它的值用於表示在從底層讀取器獲得數據時發生的錯誤。這裡的值在被讀取或忽略之後,該欄位會被置為nil。
6、lastByte:int類型的欄位,用於記錄緩衝區中最後一個被讀取的位元組。讀回退時會用到它的值。
7、lastRuneSize:int類型的欄位,用於記錄緩衝區中最後一個被讀取的 Unicode 字元所佔用的位元組數。讀回退的時候會用到它的值。這個欄位只會在其所屬值的ReadRune方法中才會被賦予有意義的值。在其他情況下,它都會被置為-1。
bufio包為我們提供了兩個用於初始化Reader值的函數,分別叫:
- NewReader;
- NewReaderSize;
它們都會返回一個*bufio.Reader類型的值。
NewReader函數初始化的Reader值會擁有一個默認尺寸的緩衝區。這個默認尺寸是 4096 個位元組,即:4 KB。而NewReaderSize函數則將緩衝區尺寸的決定權拋給了使用方。
由於這裡的緩衝區在一個Reader值的生命周期內其尺寸不可變,所以在有些時候是需要做一些權衡的。NewReaderSize函數就提供了這樣一個途徑。
在bufio.Reader類型擁有的讀取方法中,Peek方法和ReadSlice方法都會調用該類型一個名為fill的包級私有方法。fill方法的作用是填充內部緩衝區。我們在這裡就先重點說說它。
fill方法會先檢查其所屬值的已讀計數。如果這個計數不大於0,那麼有兩種可能。
一種可能是其緩衝區中的位元組都是全新的,也就是說它們都沒有被讀取過,另一種可能是緩衝區剛被壓縮過。
對緩衝區的壓縮包括兩個步驟。第一步,把緩衝區中在[已讀計數, 已寫計數)範圍之內的所有元素值(或者說位元組)都依次拷貝到緩衝區的頭部。
比如,把緩衝區中與已讀計數代表的索引對應位元組拷貝到索引0的位置,並把緊挨在它後邊的位元組拷貝到索引1的位置,以此類推。
這一步之所以不會有任何副作用,是因為它基於兩個事實。
第一事實,已讀計數之前的位元組都已經被讀取過,並且肯定不會再被讀取了,因此把它們覆蓋掉是安全的。
第二個事實,在壓縮緩衝區之後,已寫計數之後的位元組只可能是已被讀取過的位元組,或者是已被拷貝到緩衝區頭部的未讀位元組,又或者是代表未曾被填入數據的零值0x00。所以,後續的新位元組是可以被寫到這些位置上的。
在壓縮緩衝區的第二步中,fill方法會把已寫計數的新值設定為原已寫計數與原已讀計數的差。這個差所代表的索引,就是壓縮後第一次寫入位元組時的開始索引。
另外,該方法還會把已讀計數的值置為0。顯而易見,在壓縮之後,再讀取位元組就肯定要從緩衝區的頭部開始讀了。
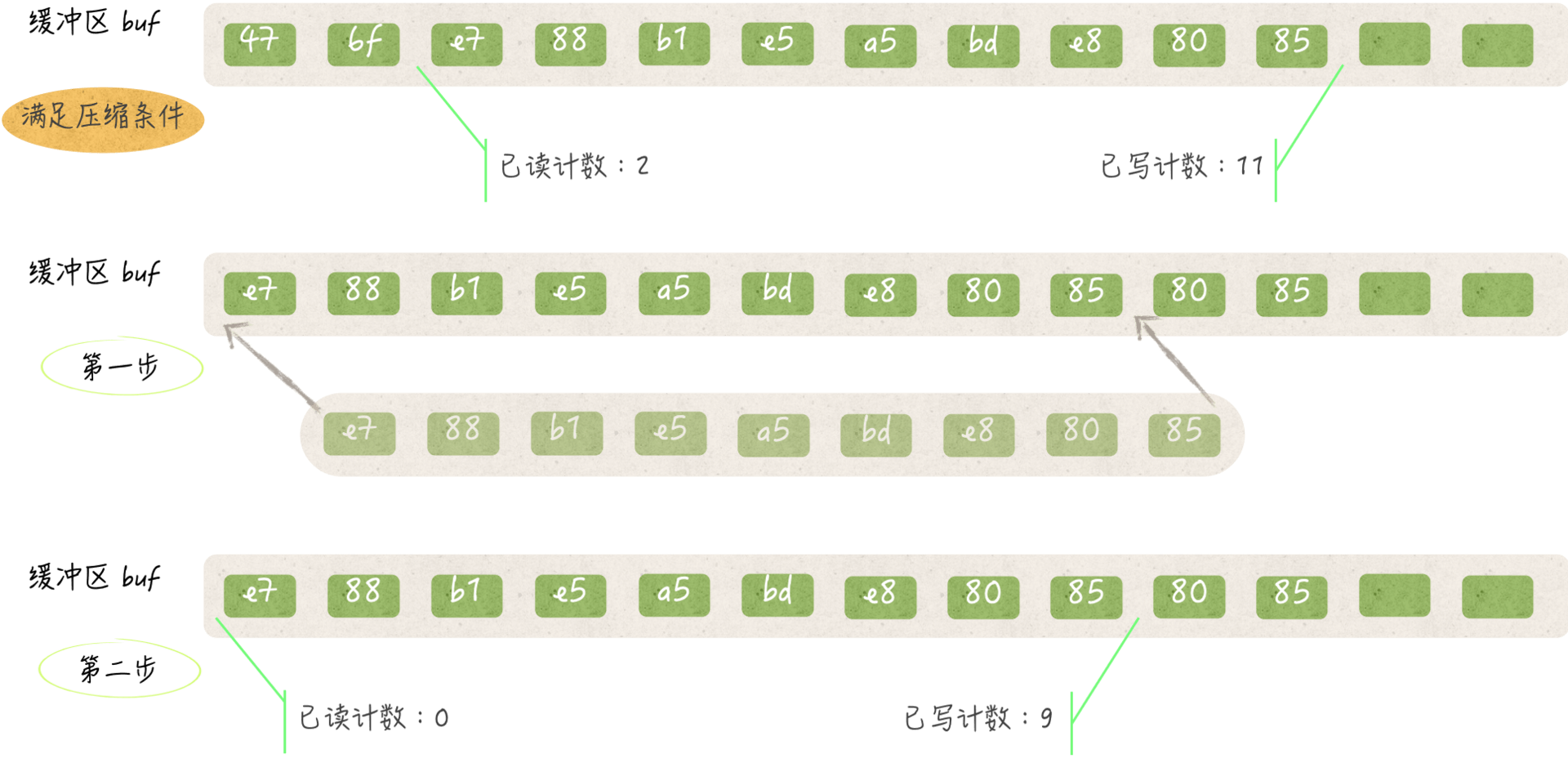

(bufio.Reader 中的緩衝區壓縮)
實際上,fill方法只要在開始時發現其所屬值的已讀計數大於0,就會對緩衝區進行一次壓縮。之後,如果緩衝區中還有可寫的位置,那麼該方法就會對其進行填充。
在填充緩衝區的時候,fill方法會試圖從底層讀取器那裡,讀取足夠多的位元組,並盡量把從已寫計數代表的索引位置到緩衝區末尾之間的空間都填滿。
在這個過程中,fill方法會及時地更新已寫計數,以保證填充的正確性和順序性。另外,它還會判斷從底層讀取器讀取數據的時候,是否有錯誤發生。如果有,那麼它就會把錯誤值賦給其所屬值的err欄位,並終止填充流程。
好了,到這裡,我們暫告一個段落。在本題中,我對bufio.Reader類型的基本結構,以及相關的一些函數和方法進行了概括介紹,並且重點闡述了該類型的fill方法。
後者是我們在後面要說明的一些讀取流程的重要組成部分。你起碼要記住的是:這個fill方法大致都做了些什麼。
知識擴展
問題 1:bufio.Writer類型值中緩衝的數據什麼時候會被寫到它的底層寫入器?
我們先來看一下bufio.Writer類型都有哪些欄位:
1、err:error類型的欄位。它的值用於表示在向底層寫入器寫數據時發生的錯誤。
2、buf:[]byte類型的欄位,代表緩衝區。在初始化之後,它的長度會保持不變。
3、n:int類型的欄位,代表對緩衝區進行下一次寫入時的開始索引。我們可以稱之為已寫計數。
4、wr:io.Writer類型的欄位,代表底層寫入器。
bufio.Writer類型有一個名為Flush的方法,它的主要功能是把相應緩衝區中暫存的所有數據,都寫到底層寫入器中。數據一旦被寫進底層寫入器,該方法就會把它們從緩衝區中刪除掉。
不過,這裡的刪除有時候只是邏輯上的刪除而已。不論是否成功地寫入了所有的暫存數據,Flush方法都會妥當處置,並保證不會出現重寫和漏寫的情況。該類型的欄位n在此會起到很重要的作用。
bufio.Writer類型值(以下簡稱Writer值)擁有的所有數據寫入方法都會在必要的時候調用它的Flush方法。
比如,Write方法有時候會在把數據寫進緩衝區之後,調用Flush方法,以便為後續的新數據騰出空間。WriteString方法的行為與之類似。
又比如,WriteByte方法和WriteRune方法,都會在發現緩衝區中的可寫空間不足以容納新的位元組,或 Unicode 字元的時候,調用Flush方法。
此外,如果Write方法發現需要寫入的位元組太多,同時緩衝區已空,那麼它就會跨過緩衝區,並直接把這些數據寫到底層寫入器中。
而ReadFrom方法,則會在發現底層寫入器的類型是io.ReaderFrom介面的實現之後,直接調用其ReadFrom方法把參數值持有的數據寫進去。
總之,在通常情況下,只要緩衝區中的可寫空間無法容納需要寫入的新數據,Flush方法就一定會被調用。並且,bufio.Writer類型的一些方法有時候還會試圖走捷徑,跨過緩衝區而直接對接數據供需的雙方。
你可以在理解了這些內部機制之後,有的放矢地編寫你的程式碼。不過,在你把所有的數據都寫入Writer值之後,再調用一下它的Flush方法,顯然是最穩妥的。
package main
import (
"bufio"
"fmt"
"strings"
)
func main() {
comment := "Package bufio implements buffered I/O. " +
"It wraps an io.Reader or io.Writer object, " +
"creating another object (Reader or Writer) that " +
"also implements the interface but provides buffering and " +
"some help for textual I/O."
basicReader := strings.NewReader(comment)
fmt.Printf("The size of basic reader: %d\n", basicReader.Size())
fmt.Println()
// 示例1。
fmt.Println("New a buffered reader ...")
reader1 := bufio.NewReader(basicReader)
fmt.Printf("The default size of buffered reader: %d\n", reader1.Size())
// 此時reader1的緩衝區還沒有被填充。
fmt.Printf("The number of unread bytes in the buffer: %d\n", reader1.Buffered())
fmt.Println()
// 示例2。
bytes, err := reader1.Peek(7)
if err != nil {
fmt.Printf("error: %v\n", err)
}
fmt.Printf("Peeked contents(%d): %q\n", len(bytes), bytes)
fmt.Printf("The number of unread bytes in the buffer: %d\n", reader1.Buffered())
fmt.Println()
// 示例3。
buf1 := make([]byte, 7)
n, err := reader1.Read(buf1)
if err != nil {
fmt.Printf("error: %v\n", err)
}
fmt.Printf("Read contents(%d): %q\n", n, buf1)
fmt.Printf("The number of unread bytes in the buffer: %d\n", reader1.Buffered())
fmt.Println()
// 示例4。
fmt.Printf("Reset the basic reader (size: %d) ...\n", len(comment))
basicReader.Reset(comment)
fmt.Printf("Reset the buffered reader (size: %d) ...\n", reader1.Size())
reader1.Reset(basicReader)
peekNum := len(comment) + 1
fmt.Printf("Peek %d bytes ...\n", peekNum)
bytes, err = reader1.Peek(peekNum)
if err != nil {
fmt.Printf("error: %v\n", err)
}
fmt.Printf("The number of peeked bytes: %d\n", len(bytes))
fmt.Println()
// 示例5。
fmt.Printf("Reset the basic reader (size: %d) ...\n", len(comment))
basicReader.Reset(comment)
size := 300
fmt.Printf("New a buffered reader with size %d ...\n", size)
reader2 := bufio.NewReaderSize(basicReader, size)
peekNum = size + 1
fmt.Printf("Peek %d bytes ...\n", peekNum)
bytes, err = reader2.Peek(peekNum)
if err != nil {
fmt.Printf("error: %v\n", err)
}
fmt.Printf("The number of peeked bytes: %d\n", len(bytes))
}
總結
今天我們從「bufio.Reader類型值中的緩衝區起著怎樣的作用」這道問題入手,介紹了一部分 bufio 包中的數據類型,在下一次的分享中,我會沿著這個問題繼續展開。
筆記源碼
//github.com/MingsonZheng/go-core-demo
![]()

本作品採用知識共享署名-非商業性使用-相同方式共享 4.0 國際許可協議進行許可。
歡迎轉載、使用、重新發布,但務必保留文章署名 鄭子銘 (包含鏈接: //www.cnblogs.com/MingsonZheng/ ),不得用於商業目的,基於本文修改後的作品務必以相同的許可發布。





