前端開發需要了解的瀏覽器通識
瀏覽器通識
一、瀏覽器架構
1、單進程瀏覽器時代
2007年之前,市面上瀏覽器都是單進程的,在同一個進程里會存在網路、插件、JavaScript運行環境、渲染引擎和頁面等。
缺點
- 不穩定:一個節點崩潰,整個瀏覽器崩潰
- 不流暢:運行在同一個執行緒,需要重上到下一次完成
- 不安全:通過瀏覽器的漏洞來獲取系統許可權,可以對你的電腦做一些惡意的事情
2、多進程瀏覽器時代
新的Chrome瀏覽器包括:
- 1個瀏覽器(Browser)主進程:介面顯示、用戶交互、子進程管理,同時提供存儲等功能
- 1個 GPU 進程:UI介面都選擇採用GPU來繪製
- 1個網路(NetWork)進程:網路資源載入
- 多個渲染進程:將 HTML、CSS 和 JavaScript 轉換為用戶可以與之交互的網頁
- 多個插件進程:負責插件的運行
瀏覽器是多進程的優點 - 一個頁面崩潰不會影響到整個瀏覽器
- 多進程可以充分利用現代 CPU 多核的優勢。
- 方便使用沙盒模型隔離插件等進程,提高瀏覽器的穩定性。
3、Chrome 打開一個頁面需要啟動多少進程?分別有哪些進程?
- 打開 1 個頁面至少需要 1 個網路進程、1 個瀏覽器進程、1 個 GPU 進程以及 1 個渲染進程,共 4 個;
- 最新的 Chrome 瀏覽器包括:1 個瀏覽器(Browser)主進程、1 個 GPU 進程、1 個網路(NetWork)進程、多個渲染進程和多個插件進程。
二、javascript單執行緒
1、為什麼採用單執行緒
主要用途是與用戶互動,以及操作DOM。如果JavaScript是多執行緒的,會帶來很多複雜的問題。
Web Worker:為 JavaScript 創造多執行緒環境,允許主執行緒創建 Worker 執行緒,將一些任務分配給後者運行。但是子執行緒完全受主執行緒控制,且不得操作DOM
2、瀏覽器內核中執行緒之間的關係
- GUI渲染執行緒和JS引擎執行緒互斥
- JS阻塞頁面載入:js如果執行時間過長就會阻塞頁面
3、進程和執行緒又是什麼呢
進程:是 CPU 資源分配的最小單位(是能擁有資源和獨立運行的最小單位)。
執行緒:是 CPU 調度的最小單位(是建立在進程基礎上的一次程式運行單位)。
4、任務隊列
JS 是單執行緒的,同步執行任務會造成瀏覽器的阻塞,所以我們將 JS 分成一個又一個的任務,通過不停的循環來執行事件隊列中的任務。
- 單執行緒就意味著,所有任務都要排隊執行,前一個任務結束,才會執行後一個任務。
- 如果當前執行緒空閑,並且隊列為空,那每次加入隊列的函數將立即執行。
三、渲染機制
1. 瀏覽器如何渲染網頁
瀏覽器渲染一共有五步
- 處理 HTML 並構建 DOM 樹。
- 處理 CSS構建 CSSOM 樹。
- 將 DOM 與 CSSOM 合併成一個渲染樹。
- 根據渲染樹來布局,計算每個節點的位置。
- 調用 GPU 繪製,合成圖層,顯示在螢幕上
第四步和第五步是最耗時的部分,這兩步合起來,就是我們通常所說的渲染
- 在構建 CSSOM 樹時,會阻塞渲染,直至 CSSOM樹構建完成
- 當 HTML 解析到 script 標籤時,會暫停構建 DOM,完成後才會從暫停的地方重新開始
四、快取機制
1、常見 http 快取的類型
- 私有/瀏覽器/本地快取
- 代理快取
2、快取的好處
- 減少了冗餘的數據傳輸,減少網費
- 減少伺服器端的壓力
W3. eb 快取能夠減少延遲與網路阻塞,進而減少顯示某個資源所用的時間 - 加快客戶端載入網頁的速度
3、瀏覽器快取總結
瀏覽器快取分為強快取和協商快取。
強快取
對一個網站而言,CSS、JavaScript、圖片等靜態資源更新的頻率都比較低,而這些文件又幾乎是每次HTTP請求都需要的,如果將這些文件快取在瀏覽器中,可以極好的改善性能。
通過設置http頭中的cache-control和expires的屬性,可設定瀏覽器快取,將靜態內容設為永不過期,或者很長時間後才過期。
1、Cache-Control
Cache-Control屬性是在伺服器端配置的,不同的伺服器有不同的配置,apache、nginx、IIS、tomcat等配置都不盡相同。
以Apache為例,在http.conf中做如下配置:
<filesMatch 」.(jpg|jpeg|png|gif|ico)$」>
Header set Cache Control max-age=16768000,public
</filesMatch>
<filesMatch 」.(css|js)$」>
Header set Cache Control max-age=2628000,public
</filesMatch>
問題:瀏覽器快取的資源,若又想更新資源,如何實現?
解決:通過修改該資源的名稱來實現。修改了資源名稱,瀏覽器會當做不同的資源。
Cache-Control相關屬性
no-cache:不使用本地快取。
no-store:直接禁止遊覽器快取數據,
public:可以被所有的用戶快取,
private:只能被終端用戶的瀏覽器快取,
max-age:從當前請求開始,
must-revalidate,當快取過期時,
2、Expires
Expires屬性也是在服務端配置的,具體的配置也根據伺服器而定。
問題:可能存在客戶端時間跟服務端時間不一致的問題。
解決:建議Expires結合Cache-Control一起使用。
Cache-Control: public
Expires: Wed, Jan 10 2018 00:27:04 GMT
過程
- 第一次瀏覽器發送請求給伺服器時,此時瀏覽器還沒有本地快取副本,伺服器返回資源給瀏覽器,響應碼是200 OK,瀏覽器收到資源後,把資源和對應的響應頭一起快取下來
- 第二次瀏覽器準備發送請求給伺服器時候,瀏覽器會先檢查上一次服務端返回的響應頭資訊中的Cache-Control,它的值是一個相對值,單位為秒,表示資源在客戶端快取的最大有效期,過期時間為第一次請求的時間減去Cache-Control的值,過期時間跟當前的請求時間比較,如果本地快取資源沒過期,那麼命中快取,不再請求伺服器
- 如果沒有命中,瀏覽器就會把請求發送給伺服器,進入快取協商階段。
協商快取
覽器在第一次訪問頁面時向伺服器請求資源,並快取起來,下次再訪問時會判斷在快取中是否已有該資源且有沒有更新過,如果已有該資源且未更新過,則直接從瀏覽器快取中讀取。
原理:
通過HTTP 請求頭中的 If-Modified-Since(If-No-Match) 和響應頭中的Last-Modified(ETag)來實現
HTTP請求把 If-Modified-Since(If-No-Match)傳給伺服器
伺服器將其與Last-Modified(ETag)對比,若相同,則文件沒有被改動過,則返回304,直接瀏覽器快取中讀取資源即可。
快取位置
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
Service Worker
離線快取: 這個應用場景比如PWA,它借鑒了Web Worker思路,由於它脫離了瀏覽器的窗體,因此無法直接訪問DOM。它能完成的功能比如:離線快取、消息推送和網路代理,其中離線快取就是Service Worker Cache。
Memory Cache
記憶體快取:從效率上講它是最快的,從存活時間來講又是最短的,當渲染進程結束後,記憶體快取也就不存在了。
Disk Cache
存儲在磁碟中的快取:從存取效率上講是比記憶體快取慢的,優勢在於存儲容量和存儲時長。
Push Cache
推送快取:這算是瀏覽器中最後一道防線吧,它是HTTP/2的內容
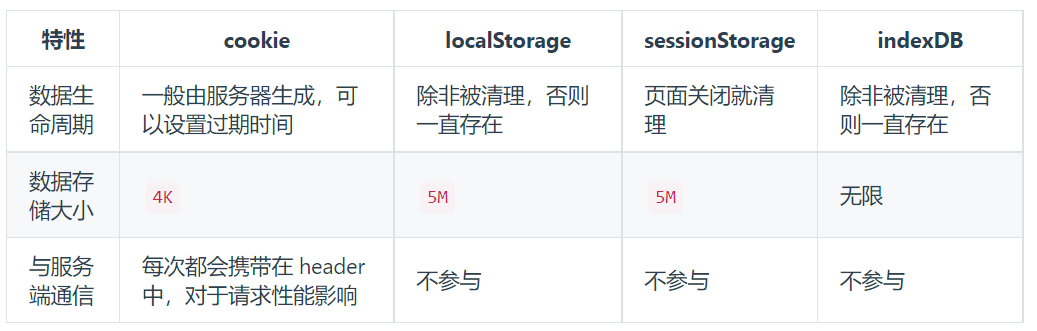
六、瀏覽器存儲
- 短暫性存儲:我們只需要將數據存在記憶體中,只在運行時可用
- 持久性存儲:可以分為 瀏覽器端 與 伺服器端
- 瀏覽器:
- cookie: 通常用於存儲用戶身份,登錄狀態等
- localStorage / sessionStorage: 長久儲存/窗口關閉刪除, 體積限制為 4~5M
- indexDB:瀏覽器提供的本地資料庫
- 伺服器:
- 分散式快取 redis
- 資料庫
- 瀏覽器:
存儲大小:
cookie數據大小不能超過4k
sessionStorage和localStorage雖然也有存儲大小的限制,但比cookie大得多,可以達到5M或更大
有效期時間:
localStorage 存儲持久數據,瀏覽器關閉後數據不丟失除非主動刪除數據
sessionStorage 數據在當前瀏覽器窗口關閉後自動刪除
cookie 設置的cookie過期時間之前一直有效,即使窗口或瀏覽器關閉
七、跨域處理方案
八、安全
九、PWA漸進式web應用–離線存儲
十、DOM節點操作
JavaScript之BOM和DOM及其兼容操作詳細總結
(1)創建新節點
createDocumentFragment() //創建一個DOM片段
createElement() //創建一個具體的元素
createTextNode() //創建一個文本節點
(2)添加、移除、替換、插入
appendChild(node)
removeChild(node)
replaceChild(new,old)
insertBefore(new,old)
(3)查找
getElementById();
getElementsByName();
getElementsByTagName();
getElementsByClassName();
querySelector();
querySelectorAll();
(4)屬性操作
getAttribute(key);
setAttribute(key, value);
hasAttribute(key);
removeAttribute(key);
十一、頁面載入過程
-
當我們打開網址的時候,瀏覽器會從伺服器中獲取到 HTML 內容
-
瀏覽器獲取到 HTML 內容後,就開始從上到下解析 HTML 的元素
-
<head>元素內容會先被解析,此時瀏覽器還沒開始渲染頁面 -
當瀏覽器解析到這裡時(步驟 3),會暫停解析並下載 JavaScript 腳本
-
當 JavaScript 腳本下載完成後,瀏覽器的控制權轉交給 JavaScript 引擎。當腳本執行完成後,控制權會交回給渲染引擎,渲染引擎繼續往下解析 HTML 頁面
-
此時
<body>元素內容開始被解析,瀏覽器開始渲染頁面]
js延遲載入的方式有哪些
- 將 js 腳本放在文檔的底部,來使 js 腳本儘可能的在最後來載入執行
- 給 js 腳本添加 defer 屬性,這個屬性會讓腳本的載入與文檔的解析同步解析,然後在文檔解析完成後再執行這個腳本文件,這樣的話就能使頁面的渲染不被阻塞。多個設置了 defer 屬性的腳本按規範來說最後是順序執行的,但是在一些瀏覽器中可能不是這樣
- 給 js 腳本添加 async屬性,這個屬性會使腳本非同步載入,不會阻塞頁面的解析過程,但是當腳本載入完成後立即執行 js腳本,這個時候如果文檔沒有解析完成的話同樣會阻塞。多個 async 屬性的腳本的執行順序是不可預測的,一般不會按照程式碼的順序依次執行
- 動態創建 DOM 標籤的方式,我們可以對文檔的載入事件進行監聽,當文檔載入完成後再動態的創建 script 標籤來引入 js 腳本

十二、輸入url到展示過程
基礎版本
- 瀏覽器根據請求的URL交給DNS域名解析,找到真實IP,向伺服器發起請求;
- 伺服器交給後台處理完成後返回數據,瀏覽器接收文件(HTML、JS、CSS、圖象等);
- 瀏覽器對載入到的資源(HTML、JS、CSS等)進行語法解析,建立相應的內部數據結構(如HTML的DOM);
- 載入解析到的資源文件,渲染頁面,完成。
-
從瀏覽器接收url到開啟網路請求執行緒(這一部分可以展開瀏覽器的機制以及進程與執行緒之間的關係)
-
開啟網路執行緒到發出一個完整的HTTP請求(這一部分涉及到dns查詢,TCP/IP請求,五層網際網路協議棧等知識)
-
從伺服器接收到請求到對應後台接收到請求(這一部分可能涉及到負載均衡,安全攔截以及後台內部的處理等等)
-
後台和前台的HTTP交互(這一部分包括HTTP頭部、響應碼、報文結構、cookie等知識,可以提下靜態資源的cookie優化,以及編碼解碼,如gzip壓縮等)
-
單獨拎出來的快取問題,HTTP的快取(這部分包括http快取頭部,ETag,catch-control等)
-
瀏覽器接收到HTTP數據包後的解析流程(解析html-詞法分析然後解析成dom樹、解析css生成css規則樹、合併成render樹,然後layout、painting渲染、複合圖層的合成、GPU繪製、外鏈資源的處理、loaded和DOMContentLoaded等)
-
CSS的可視化格式模型(元素的渲染規則,如包含塊,控制框,BFC,IFC等概念)
-
JS引擎解析過程(JS的解釋階段,預處理階段,執行階段生成執行上下文,VO,作用域鏈、回收機制等等)
-
其它(可以拓展不同的知識模組,如跨域,web安全,hybrid模式等等內容)


