不止是上雲,更是上岸
作者
常耀國,騰訊SRE專家,現就職於PCG-大數據平台部,負責千萬級QPS業務的上雲、監控和自動化工作。
背景
BeaconLogServer 是燈塔 SDK 上報數據的入口,接收眾多業務的數據上報,包括微視、 QQ 、騰訊影片、 QQ 瀏覽器、應用寶等多個業務,呈現並發大、請求大、流量突增等問題,目前 BeaconLogServer 的 QPS 達到千萬級別以上,為了應對這些問題,平時需要耗費大量的人力去維護服務的容量水位,如何利用上雲實現 0 人力運維是本文著重分析的。
混合雲彈性伸縮
彈性伸縮整體效果
首先談一下自動擴縮容,下圖是 BeaconLogServer 混合雲彈性伸縮設計的方案圖
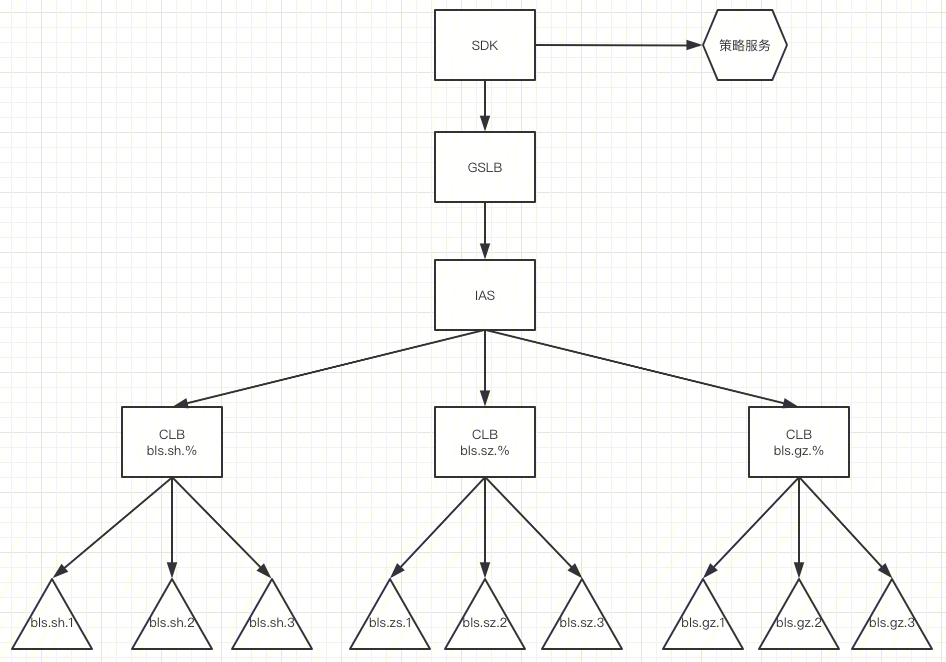
彈性伸縮方案
資源管理
先從資源管理講起,目前 BeaconLogServer 節點個數是8000多個,需要的資源很大,單獨依靠平台的公共資源,在一些節假日流量突增的時候,可能無法實現快速的擴容,因此,經過調研123平台(PAAS 平台)和算力平台(資源平台),我們採用了混合雲的方式,來解決這個問題。
分析 BLS 業務場景,流量突增存在下面兩種情況:
-
日常業務負載小幅度升高,時間持續較短
-
春節業務負載大幅度升高,並持續一段時間
針對上述的業務場景,我們採用三種資源類型來應對不同場景,具體如下表所述:
| 類型 | 場景 | set |
|---|---|---|
| 公共資源池 | 日常業務 | bls.sh.1 |
| 算力平台 | 小高峰 | bls.sh.2 |
| 專用資源池 | 春節 | bls.sh.3 |
日常業務我們使用公共資源池+算力資源,當業務的負載小幅度上升的話,使用算力資源快速擴容,保障服務的容量水位不超過安全閾值。面對春節負載大幅度升高,這時需要構建專有資源池來應對春節的流量升高。
彈性擴縮容
上文闡述了資源的管理,那麼針對不同的資源,何時開始擴容,何時開始縮容?
BeaconLogServer 日常的流量分布是 123 平台公共資源:算力平台=7:3。目前設置的自動擴容的閾值時60%,當 CPU 使用率大於60%,平台自動擴容。彈性擴縮容依賴的是 123 平台的調度功能,具體的指標設置如下:
| 類型 | CPU自動縮容閾值 | CPU自動擴容閾值 | 最小副本數 | 最大副本數 |
|---|---|---|---|---|
| 123平台公共資源池 | 20 | 60 | 300 | 1000 |
| 算力平台 | 40 | 50 | 300 | 1000 |
| 123平台專有資源池 | 20 | 60 | 300 | 1000 |
可以看到算力平台自動縮容閾值較大,自動擴容閾值較小,主要考慮算力平台是應對流量突增的情況,而且算力平台資源經常替換,因此優先考慮先擴容或縮容算力平台的資源。最小副本數是保障業務所需的最低資源需求,如果少於這個值,平台會自動補充。最大副本數設置1000,是因為 IAS 平台(網關平台)一個城市支援的最大 RS 節點數是1000。
問題及解決
方案推進的過程中,我們也遇到了很多問題,挑選幾個問題和大家分享一下。
1)首先從接入層來講,之前接入層業務使用的是 TGW , TGW 有一個限制,就是RS的節點不能超過200個,目前 BeaconLogServer 的節點是8000多個,繼續使用 TGW 需要申請很多個域名,遷移耗時多且不便於維護。我們調研接入層 IAS , IAS 四層每個城市支援的節點個數是1000個,基本可以滿足我們的需求,基於此,我們設計如下的解決方案如下:
總體上採用「業務+地域」模式分離流量。當集群中一個城市的 RS 節點超過500個就需要考慮拆分業務,例如公共集群的節點超出閾值,可以把當前業務量大的影片業務拆分出來,作為一個單獨的集群;如果是一個獨立集群的業務節點超出閾值,先考慮增加城市,把流量拆分到新的城市。如果無法新增城市,此時考慮新增一個 IAS 集群,然後在 GLSB 上按照區域把流量分配到不同的集群。
2)同一個城市不同的資源池設置不同的 set,那麼IAS如何接入同一個城市不同 set 呢?
北極星本來有[通配組功能],但是 IAS 不支援 set 通配符功能實際上,我們推動 IAS 實現了通配組匹配,例如使用 bls.sh.% 可以匹配 bls.sh.1 , bls.sh.2 , bls.sh.3 。注意, IAS 通配符和北極星的不一樣,北極星使用的是**, IAS 在上線的時候發現有用戶使用做單獨匹配,所以使用%來表示通配符。
3)資源管理這塊遇到的難點是 IAS 四層無法使用算力資源的節點,後面在經過溝通,打通了 IAS 到算力資源的。這裡的解決方案是使用 SNAT 能力。
此方案的注意事項
-
只能綁定 IP 地址,無法拉取實例,實例銷毀也不會自動解綁,需要通過控制台或 API 主動解綁(已跨帳號,拉取不到實例)
-
如果是大規模上量:過哪些網關、哪些容量需要評估、風險控制,需要評估
單機故障自動化處理
單機故障處理效果
單機故障自動化處理,目標是實現0人力維護,如下圖是我們自動化處理的截圖。
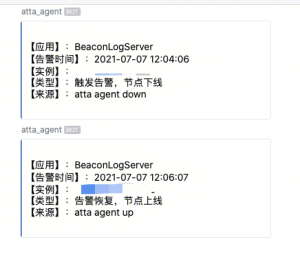
單機故障處理方案
單機故障主要從系統層面和業務層面兩個維度考慮,詳情如下:
| 維度 | 告警項 |
|---|---|
| 系統層面 | CPU |
| 系統層面 | 記憶體 |
| 系統層面 | 網路 |
| 系統層面 | 磁碟 |
| 業務層面 | ATTA Agent不可用 |
| 業務層面 | 隊列過長 |
| 業務層面 | 發送atta數據成功率 |
針對單機故障,我們採用的是開源的 Prometheus +公司的 Polaris(註冊中心) 的方式解決。Prometheus 主要是用來採集數據和發送告警,然後通過程式碼把節點從 Polaris 摘除。
至於告警發生和告警恢復的處理,當告警發生的時候,首先會判斷告警的節點個數,如果低於三個以下,我們直接在 Polaris 摘除節點,如果大於3個,可能是普遍的問題,這時候我們會發送告警,需要人工的介入。當告警恢復的時候,我們直接在平台重啟節點,節點會重新註冊 Polaris 。
ATTA Agent 異常處理
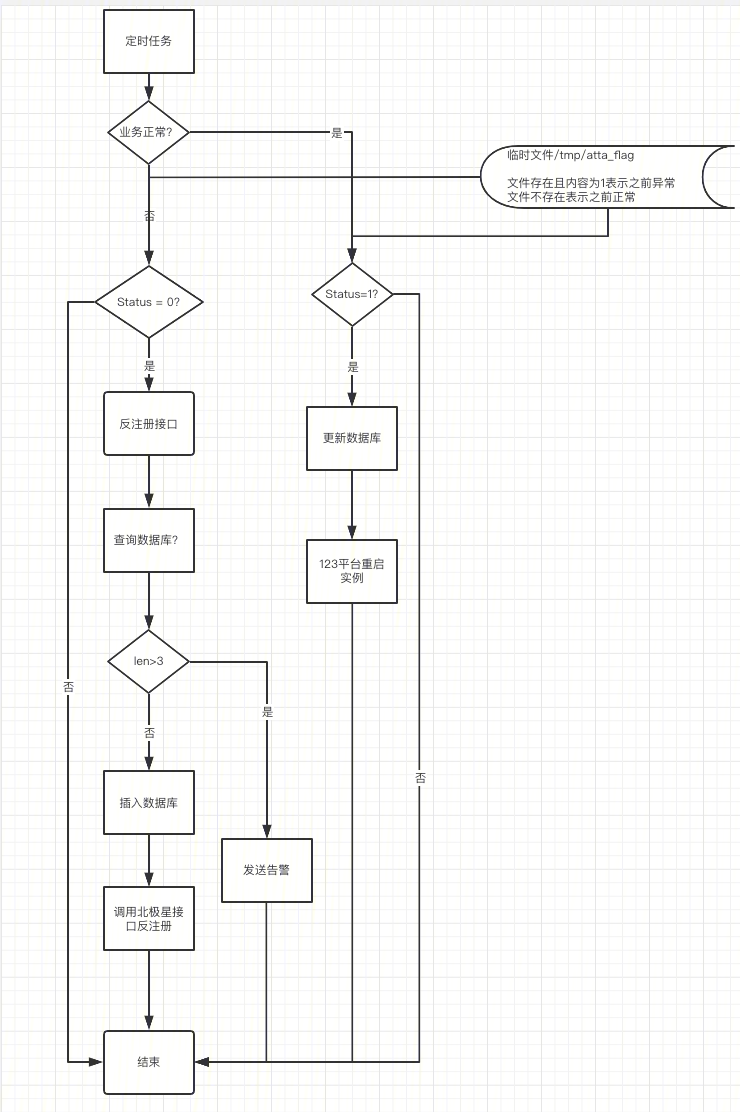
如圖所示,處理流程是兩條線,告警觸發和告警恢復,當業務異常的時候,首先判斷當前異常節點的數量,保證不會大範圍的摘掉節點。然後在北極星摘除節點。當業務恢復的時候,直接重啟節點。
問題及解決
主要的難點是 Prometheus Agent 的健康檢查和 BeaconLogServer 節點的動態變化,對於第一個問題,目前主要是由平台方負責維護。對於第二個問題,我們利用了定時腳本從 Polaris 拉取節點和 Prometheus 熱載入的能力實現的。
總結
此次上雲有效的解決了自動擴縮容和單機故障這兩塊的問題,減少了手動操作,降低了人為操作錯誤風險,提升系統的穩定性。通過此次上雲,也總結了幾點:
-
遷移方案:上雲之前做好遷移方案的調研,特別是依賴系統的支援的功能,降低遷移過程因系統不支援的系統性風險 。
-
遷移過程:做好指標監控,遷移流量之後,及時觀測指標,出現問題及時回滾。
關於我們
更多關於雲原生的案例和知識,可關注同名【騰訊雲原生】公眾號~
福利:
①公眾號後台回復【手冊】,可獲得《騰訊雲原生路線圖手冊》&《騰訊雲原生最佳實踐》~
②公眾號後台回復【系列】,可獲得《15個系列100+篇超實用雲原生原創乾貨合集》,包含Kubernetes 降本增效、K8s 性能優化實踐、最佳實踐等系列。
③公眾號後台回復【白皮書】,可獲得《騰訊雲容器安全白皮書》&《降本之源-雲原生成本管理白皮書v1.0》
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多乾貨!!



