論文解析丨Dynamic Anchor Learning for Arbitrary-Oriented Object
編者按
「
任意方向目標廣泛存在於自然場景、航空照片、遙感影像等領域,因此任意方向目標檢測受到了廣泛關注。當前許多旋轉檢測器使用大量具有不同方向的錨來實現與地面真值盒的空間對齊,然後應用聯合交集(IoU)對正候選和負候選進行取樣以進行訓練。

任意方向目標廣泛存在於自然場景、航空照片、遙感影像等領域,因此任意方向目標檢測受到了廣泛關注。當前許多旋轉檢測器使用大量具有不同方向的錨來實現與地面真值盒的空間對齊,然後應用聯合交集(IoU)對正候選和負候選進行取樣以進行訓練。
然而,我們觀察到,所選擇的正錨並不總能確保回歸後的準確檢測,而一些負樣本可以實現準確定位。這表明通過IoU對錨點進行品質評估是不合適的,這進一步導致分類置信度和定位精度之間的不一致。在本文中,我們提出了一種動態錨學習(DAL)方法,該方法利用新定義的匹配度來綜合評估錨的定位潛力,並執行更高效的標籤分配過程。通過這種方式,檢測器可以動態選擇高品質的錨來實現精確的目標檢測,並且可以消除分類和回歸之間的差異
1. Motivation
基於anchor的演算法在訓練時首先根據將預設的anchor和目標根據IoU大小進行空間匹配,以一定的閾值(如0.5)選出合適數目的anchor作為正樣本用於回歸分配的物體。但是這會導致兩個問題:
進一步加劇的正負樣本不平衡。對於旋轉目標檢測而言,預設旋轉anchor要額外引入角度先驗,使得預設的anchor數目成倍增加。此外,旋轉anchor角度稍微偏離gt會導致IoU急劇下降,所以預設的角度參數很多。(例如旋轉文本檢測RRD設置13個角度,RRPN每個位置54個anchor)。
分類回歸的不一致。當前很多工作討論這個問題,即預測結果的分類得分和定位精度不一致,導致通過NMS階段以及根據分類conf選檢測結果的時候有可能選出定位不準的,而遺漏抑制了定位好的anchor。目前工作的解決方法大致可以分為兩類:網路結構入手和label assignment優化,參見related work這裡不再贅述。
2. Discussion
用旋轉RetinaNet在HRSC2016數據集上實驗可視化檢測結果發現,很如下圖b,多低品質的負樣本居然能夠準確回歸出目標位置,但是由於被分為負樣本,分類置信必然不高,不會被檢測輸出;如圖a,一些高品質正樣本anchor反而可能輸出低品質的定位結果。

為了進一步驗證這種現象是否具有普遍性,統計了訓練過程的所有樣本IoU分布,以及分類回歸分數散點圖,結果如下圖。我們將anchor和gt的IoU稱為輸入IoU,pred box和gt的IoU稱為輸出IoU。從中看出:
74%左右的正樣本anchor回歸的pred box後依然是高品質樣本(IoU>0.5);近一半的高品質樣本回歸自負樣本,這說明負樣本還有很大的利用空間,當前基於輸入IoU的label assignment選正樣本的效率並不高,有待優化。
圖c說明,當前的基於輸入IoU的標籤分配會誘導分類分數和anchor初始定位能力成正相關。而我們期望的結果是pred box的分類回歸能力成正相關。從這裡可以認為基於輸入IoU的標籤分配是導致分類回歸不一致的根源之一。這個很好理解,劃分樣本的時候指定的初始對齊很好的為正樣本,其回歸後就算產生了不好的預測結果,分類置信還是很高,因為分類回歸任務是解耦的;反之很多初始對齊不好的anchor被分成負樣本,即使能預測好,由於分數很低,無法在inference被輸出。
進一步統計了預測結果的分布如d,可以看到在低IoU區間分類器表現還行,能有效區分負樣本,但是高IoU區間如0.7以上,分類器對樣本品質的區分能力有限。

3. Method
3.1 Analysis
首先是baseline用的是附加角度回歸的reitnanet。
直觀來說,輸出IoU能夠直接反映預測框的定位能力,那麼直接用輸出IoU來回饋地選取正樣本不就能實現分類回歸的一致嗎?但是進行實驗發現,網路根本不能收斂。即便是在訓練較好的模型上finetune,模型性能依然會劣化發散。推測是兩種情況導致的:
輸入IoU大,但是輸出IoU小的anchor並不應該被劃分為負樣本,其更大概率還是正樣本的,這部分容易學習的樣本丟失嚴重影響收斂
任何樣本都可能在訓練過程中隨機匹配到一個目標,但不應該因此直接確信為正樣本,這在訓練早期尤為嚴重
例如,一個anchor回歸前IoU為0.4,回歸後IoU是0.9,我們可以認為這是一個潛在高品質樣本;但是如果一個anchor回歸前是0,回歸後0.9,他基本不可能是正樣本,不該參與loss計算。反之亦然。可見這麼簡單的思路沒有人採用,不是沒人想到,而是真的不行。相似的label assignment工作中,即使利用了輸出IoU也是用各種加權或者loss等強約束確保可以收斂,有一個只利用輸出IoU進行feedback的工作,但是我復現的時候有很多問題,實驗部分會介紹。
3.2 Dynamic Anchor Selection
可以理解為輸入IoU是目標的空間對齊(spatial alignment),而輸出IoU是由於定位物體所需重要特徵的捕捉能力決定的,可以理解為特徵對齊(feature alignment)能力。據此定義了匹配度(matching degree)如下:

前兩項比較好理解,通過輸入IoU表徵的空間對齊能力對anchor的定位性能作先驗緩和上面的兩種情況以穩定訓練過程。第三項表徵的是回歸前後的不穩定性作用,對回歸前後的變化進行懲罰。實際上這一項是有效利用輸出IoU的關鍵,後面的實驗會證明這一點。自己私下的實驗中發現,有了 f a fa fa和 u u u兩項(即 α = 0 \alpha=0 α=0)實際上就能實現超越輸入IoU的labelassignment了,但是輸出IoU很不穩定,參數比較難調,而加入空間先驗後穩定了很多,效果也能保持很好的水平。
這個不確定性懲罰項 u u u有很多表徵形式,之前試過各種複雜花哨的表徵和加權變換,雖然相對現有形式有所提升但是提升空間不大。沒必要搞得故弄玄虛的,所以最後還是保留了這種最簡單的方式。
有了新的正樣本選擇標準,直接進行正常的樣本劃分就能選出高品質的正樣本。這裡還能進一步結合一些現有的取樣和分配策略進一步獲得更好的效果(如ATSS等),論文沒有展示這部分實驗可以自己嘗試。學習策略上,在訓練前期為了避免輸出IoU的不穩定影響,採取逐漸加大空間對齊影響係數,直至設定值。實驗證明這個策略不影響最終效果,只是加速收斂。
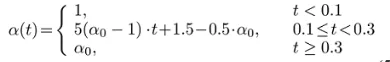
3.3 Matching-Sensitive Loss
得到匹配度矩陣後,我們可以將其加權到訓練loss中,核心思想是增強分類器對高品質樣本的識別效果,從而解決Motivation中提到的分類回歸不一致的問題。具體而言就是將匹配度矩陣進行補償,最大值補償到1,補償值加權到正樣本上去,使之更多地關注高性能樣本的分類和回歸性能。一開始我採用的是直接將md加權到loss,效果很差找問題調了一段時間才解決。補償加權的方法相比直接加權有兩個好處:
避免分類器對匹配度劃定的負樣本進行不合理的關注。比如在md補償的策略下,一個低品質正樣本可能導致很大的補償值從而帶來一堆低品質正樣本;
由於匹配度是介於[0,1],直接加權將導致正樣本被進一步稀釋;
確保分類和回歸任務對補償的anchor的足夠關注,每個樣本至少有一個anchor能學好。例如對於某個gt最大md為0.2,直接加權將導致其loss貢獻很小,本來就難匹配的目標更難學了。
損失函數表示和具體分析如下:


對於分類任務而言,如果正樣本全部置為1,就無法區分高效md不同的樣本了(顯然md=0.1和md=0.9的樣本被分為正樣本的概率不應該一樣)【問:檢測器正常情況下就是這麼做的,咋就沒你這麼多事?不是不能區分。可行的原理是通過不斷的學習,優化下降loss來對「邊緣」程度不同的hard example進行判斷。所以我們看到定位能力和分類分數常常不會差得很遠,這都是反覆的優化的結果。顯然這種策略有效但是很笨,其中顯然還有東西可以做,可以大大提高訓練效率】。所以這裡通過構造帶有定位潛力資訊的md補償矩陣來加權loss進一步關注高品質正樣本的學習情況,使得分類得分更加準確有效,提高NMS的準確性。
對於回歸任務而言,早在cascade RCNN就提出過高精度anchor對loss貢獻相對小而難以優化的問題,還有很多工作從IoU分布、重取樣、歸一化等方法緩解這個問題。這裡我們採用的還是匹配度資訊,方法也是很質樸的對正樣本re-weight;只不過加權關注的不再是空間對齊的anchor,而是對根據md度量的高品質樣本給予更多的關注。
採用匹配度敏感的loss能夠有效增強檢測器的精確定位樣本的區分能力,如下圖所示,左邊是正常訓練檢測器,可以看到定位精度上高性能部分的額區分度很低,但是加了MSL後樣本的定位性能大大提高,同時分類分數也對應提高,越往右上角顏色越深,分類分數和定位性能有較好的關聯性。很多分析由於原論文篇幅有限沒有展開。

4. Experiment
旋轉目標的實驗上採取了四個數據集:三個遙感數據集DOTA,HRSC2016,UCAS-AOD和一個文本檢測數據集ICDAR2015。同時在水平目標數據集上也進行了泛化性實驗,採用的是ICDAR2013,NWPU VHR-10和VOC2007。為了證明我們的方法能夠有效提取高品質的anchor,從而減少旋轉目標檢測中anchor的預設,緩和不平衡問題,我們在特徵圖每個位置僅僅使用了3個水平的anchor,文本檢測由於目標寬高全都很常懸殊,採用5個ratio。
4.1 Ablation
4.1.1 Component-wise evaluation
with input IoU是正常的label assignment方式,相比之下,引入output IoU後性能反而略有下降,特徵對齊的資訊並不能被有效利用。實際上這裡的 α \alpha α設置為0.1,因為輸出IoU實際上非常不穩定,比例一旦增大就會導致訓練不收斂。然而在採用不確定性懲罰後,即使是很簡單的直接作差形式性能也能有很大提高,相比前一個模型直接提升了7%。加入MSL後,mAP進一步得到提高達到88.6。同時,相比AP50的2.7%漲幅,AP75提高了9.9%,可見MSL對高精度定位大有裨益。

4.1.2 Hyper-parameters
匹配度的設置實際上引入了兩個額外的超參數,因此補充了敏感性實驗如下。表中的結果和分析結論基本一致:當不確定性抑制項存在, α \alpha α合理減小會使特徵對齊的影響增大,同時mAP增大,說明能夠輸出IoU能夠有效指導樣本劃分過程。如果 α \alpha α過大將使得空間對齊能力佔主導地位,輸出IoU帶來的不穩定減小,此時不應施加很強的擾動懲罰,即減小 γ \gamma γ的值,如 α \alpha α=0.9時, γ \gamma γ從3減小到5,mAP從70.1提升到83.5。
此外,正如上面所說,其實 s a sa sa也就是正常的IoU完全可以不要,僅靠 f a fa fa和 u u u就能取得更好的結果,但是很敏感anchor設置和 γ \gamma γ取值以及 u u u的形式,比較難調。

這為匹配度公式的參數調試提供一種思路:α \alpha α和 γ \gamma γ應該同時增大或減小。此外觀察不難發現, α \alpha α在0.3-0.5的效果是最好的, γ \gamma γ也大致可以確定。這個結論在其他數據集和其他anchor設置上也驗證過,依然成立,論文篇幅有限這裡沒有予以展示。但是說實話,取值而言會有偏移,雖然不會太多但是還是要調一調,這個有點不快樂。
4.2 Experiment Results
4.2.1 Comparison with other sampling methods
表中列舉的都是自己復現的結果,採用各自論文的思想但是由於原論文都不是做旋轉檢測的,並不完全一致。值得一提的還是HAMbox。很多朋友問我,我說發生了腎莫事,我一看截圖,啊,原來左天,塔門有人復現不出hambox的效果,不收斂或者下降。我這裡直接復現其實也不收斂,最後的85.7結果是在收斂模型上finetune,並且沒有直接用output IoU,而是加了input IoU調製;為了防止大量低品質compensated anchor,設置的每個物體只匹配三個anchor;並且用上類似curriculum learning的方式慢慢加大係數才學收斂的,收斂後效果也害行。比較意外的是atss,沒想到效果這麼好,稍微調一調就86+。

4.2.2 Results on DOTA
RetinaNet在DOTA的結果是唯一一處用的不是我開源的程式碼,而是臨時寫的基於mmdetection的,因為我的程式碼優化不行占顯示記憶體速度慢,順便也在s2anet大佬肩膀上試了試。如果問為腎莫沒在DOTA上做ablation,只能說硬體顯示卡不夠,大意了,跑dota就很費勁了,調了好久,我只能耗子尾汁。

4.2.3 Results on HRSC2016
穩定漲了幾個點,也是這個數據集小容易調。注意啊,很快啊,只放了3anchor就能比肩一些多anchor的的,速度大概24FPS。

4.2.4 Results on UCAS-AOD
這個上面比較意外的是AP75,提升非常大,達到驚人的74,甚至有點不對勁。但是可視化DAL前後的結果,發現也在情理之中。這個數據集比較簡單,尤其是飛機,是個旋轉檢測器都一副要上90封頂的樣子。只是baseline很多定位性能卡在AP75坎的檢測結果全被MSL優化後抬上來了。

4.2.5 Results on ICDAR2015
其實可以看出這個方法並不萬能,在文本檢測器上還是不行,文本檢測的難點不只是匹配。baseline只有77.5的情況下,反覆調參加通用trick也只能到81.5,加了多尺度測試勉強提點到82+,和當前先進的檢測器還是有相當的差距。但是可以移植到一些sota檢測器上去,也會有所提升。(BTW,文本和通用旋轉檢測確實不太一樣,要實現較高F1隻是解決旋轉問題遠遠不夠。例如之前寫了個Cascade-RetinaNet在HRSC2016的baseline加點簡單增強就有85+,但是移植到IC15上印象中裸跑才不到75。)

4.3 Experiments on HBB dataset
其實這個方法是通用的,只是旋轉目標匹配難匹配,所以提升更大更明顯。於是如下,可以看出在三個數據集都有提升漲點穩定。

最後這次的四個reviewer都很認真細緻,提出了很多有幫助的建議,還是比較走運的。


