OPPO 圖資料庫平台建設及業務落地
- 2021 年 11 月 15 日
- 筆記

本文首發於 OPPO 數智技術公眾號,WeChat ID: OPPO_tech
1、什麼是圖資料庫
圖資料庫(Graph database)是以圖這種數據結構存儲和查詢的資料庫。與其他資料庫不同,關係在圖資料庫中占首要地位。這意味著應用程式不必使用外鍵或帶外處理(如 MapReduce)來推斷數據連接。與關係資料庫或其他 NoSQL 資料庫相比,圖資料庫的數據模型也更加簡單,更具表現力。
圖資料庫在社交網路、知識圖譜、金融風控、個性化推薦、網路安全等領域應用廣泛。
2、圖資料庫調研
2.1、調研背景
隨著知識圖譜等業務數據的不斷增長,現有圖資料庫 JanusGraph 應對已經比較吃力,導入時間已經無法滿足業務的要求。因此尋找性能更好的開源屬性圖資料庫已經成為了當前迫切要做的事情。
新圖資料庫應滿足以下要求:
- 能夠支援 10 億節點 100 億邊 170 億屬性的大規模圖譜
- 全量導入時間不超過 10h
- 二度查詢平均響應時間不超過 50ms,QPS 能夠達到 5000+
- 開源且支援分散式的屬性圖資料庫
2.2、調研過程
第一步,搜集常見的開源分散式屬性圖資料庫,如下表:
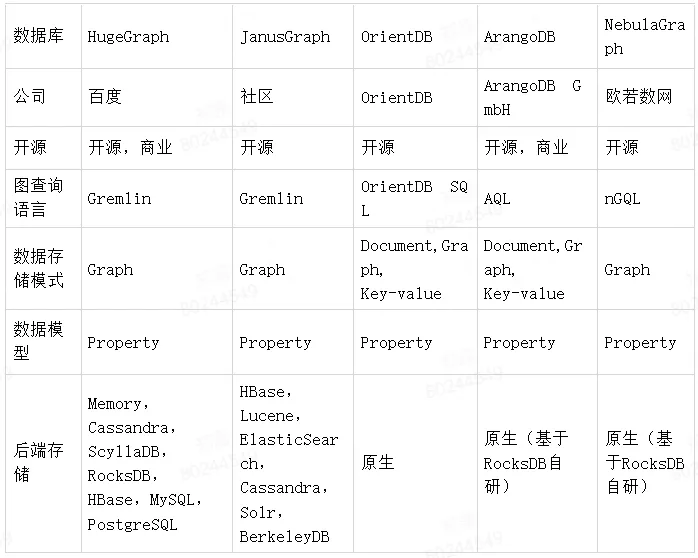
第二步,基於美團、LightGraph、TigerGraph、GalaxyBase 等圖資料庫測試報告,分析可得幾個圖資料庫性能如下:
- 導入:Nebula Graph > HugeGraph > JanusGraph > ArangoDB > OrientDB
- 查詢:Nebula Graph > HugeGraph > JanusGraph > ArangoDB > OrientDB
Nebula Graph不論是在導入還是在查詢性能上都表現優異。
第三步,為了驗證 Nebula Graph 的性能,對 Nebula Graph 和 JanusGraph 進行了一次性能對比測試,測試結果如下:
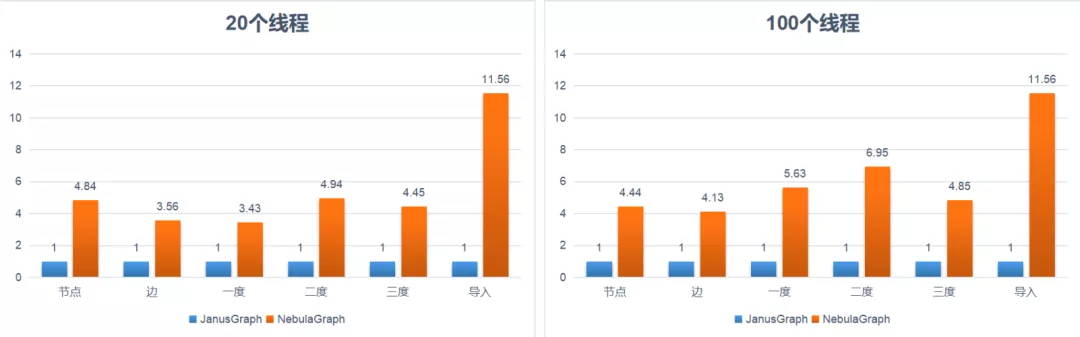
上圖中,將 JanusGraph 性能看作 1,Nebula Graph 導入性能要比 JanusGraph 快一個數量級,查詢性能是 JanusGraph 的 4-7 倍。而且隨著並發量的增大,性能差距會進一步拉大,而且 JanusGraph 在從 20 個執行緒開始,三度鄰居查詢會有 error。而 Nebula Graph 沒有任何 error。
Nebula Graph 全量導入 10 億節點 100 億邊只需要 10h,滿足要求,目前正在調研 SST 導入,可以大幅提升導入速度。
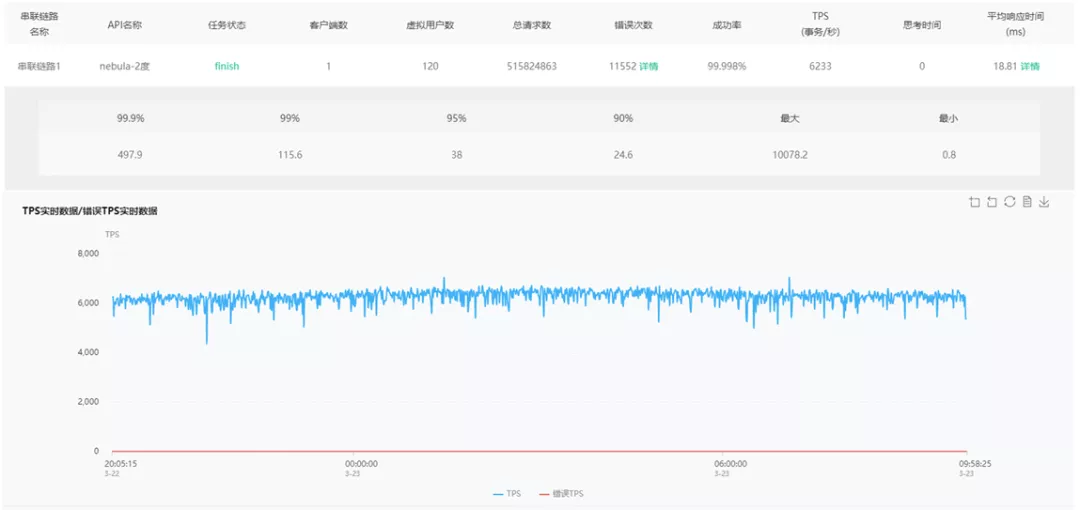
對 Nebula Graph 使用 120 個執行緒進行二度鄰居查詢壓測,最終 QPS 在 6000+,相比單機有一些提升。成功率接近 5 個 9,而且響應時間比較穩定,平均 18.81ms,p95 38ms,p99 也才115.6ms,符合需求。
2.3、調研結論
Nebula Graph 導入性能、響應時間、以及穩定性均符合需求,支援數據切分,分散式版本免費開源,使用的企業也多,中文文檔,文檔全面,社區活躍,是開源圖資料庫的理想選擇。
3、Nebula Graph 簡介
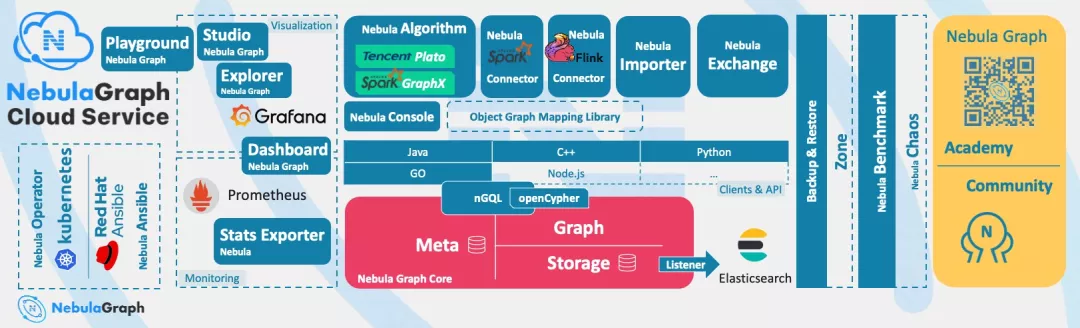
圖片來源於 Nebula Graph 文檔站
Nebula Graph 是一款開源的、分散式的、易擴展的原生圖資料庫,能夠承載數千億個點和數萬億條邊的超大規模數據集,並且提供毫秒級查詢。
Nebula Graph 基於圖資料庫的特性使用 C++ 編寫,採用 shared-nothing 架構,支援在不停止資料庫服務的情況下擴縮容,而且提供了非常多原生工具,例如 Nebula Graph Studio、Nebula Console、Nebula Exchange 等,可以大大降低使用圖資料庫的門檻。
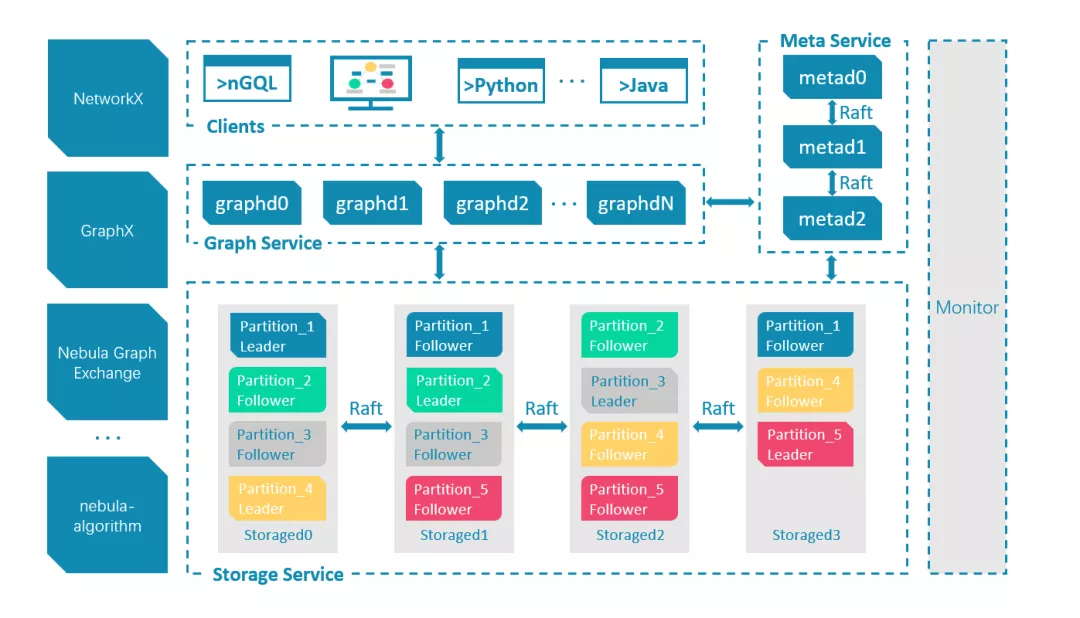
圖片來源於 Nebula Graph 文檔站
Nebula Graph 由三種服務構成:Graph 服務、Meta 服務和 Storage 服務,是一種存儲與計算分離的架構。
Meta 服務負責數據管理,例如 Schema 操作、集群管理和用戶許可權管理等。服務是由 nebula-metad 進程提供的,生產環境中,建議在 Nebula Graph 集群中部署3個 nebula-metad 進程。請將這些進程部署在不同的機器上以保證高可用。所有 nebula-metad 進程構成了基於 Raft 協議的集群,其中一個進程是 leader,其他進程都是 follower。
Graph 服務主要負責處理查詢請求,包括解析查詢語句、校驗語句、生成執行計劃以及按照執行計劃執行四個大步驟,服務是由 nebula-graphd 進程提供的,可以部署多個。
Storage 服務負責存儲數據,服務是由 nebula-storaged 進程提供的,所有nebula-storaged 進程構成了基於 Raft 協議的集群,數據在 nebula-storaged 中分區存儲,每個分區都有一個 leader,其它副本集構成該分區的 follower。
4、圖資料庫平台建設
之前在使用 JanusGraph 的時候,遇到過導入緩慢、查詢慢、高並發 OOM(JanusGraph 執行緒池採用無界隊列導致)、FULL GC(業務 Gremlin 語句中包含 Value 導致元空間不斷膨脹導致)等問題,這些在切到 Nebula Graph 後基本得到了解決。
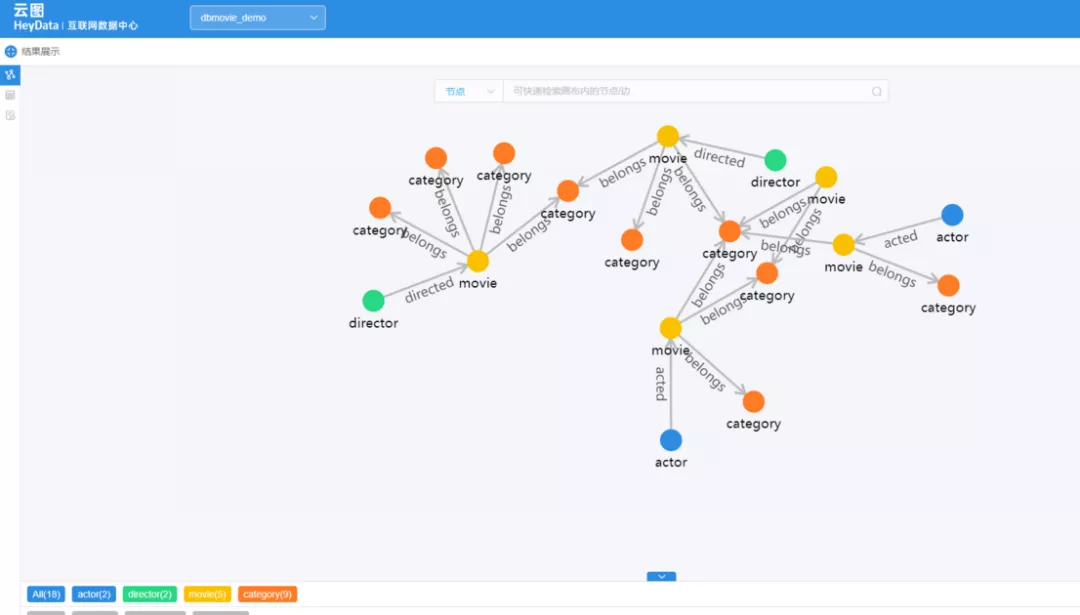
JanusGraph 並沒有好用的管理介面,如上圖所示,我們開發了一套包含多圖管理、Schema 管理、圖可視化、圖導入、許可權管理的管理介面。
而 Nebula Graph Studio 提供多圖管理、Schema 管理、圖可視化、圖導入等功能,省去了很多開發工作,降低了使用門檻。

整個圖資料庫平台的結構如上圖所示,基於 Nebula Graph 和 Nebula Graph 官方工具,著重開發了 全量導入、增量導入、圖導出、備份/還原、查詢工程(圖檢索)等功能。
官方導入工具需要提供導入配置文件,為了更便於業務使用,我們設計了一個 schema 配置表格,業務只需填好表格,導入的時候會自動創圖,創建圖的 schema,自動生成導入配置文件,自動導入數據,自動平衡數據,平衡leader, 創建索引,執行 compact 任務。當前還是批量寫入的導入方式,後續會調研 SST 導入,導入性能可進一步提升。
官方提供的導入工具採用的是非同步客戶端,導入時極難控制導入速率,設置過大,容易導致圖資料庫請求積壓,影響集群的穩定運行。設置過小,速度無法達到最優,導入過慢。我們修改了官方導入工具源碼,將非同步客戶端改成了同步客戶端,可以兼顧性能和穩定性。
官方沒有提供導出工具,我們基於官方的 nebula-spark 開發了一個導出工具,除了能夠導出數據,還能夠導出 Schema 配置以及索引配置,便於業務做數據遷移。
為了支援數據回滾,我們開發了指定圖譜的數據快速備份和還原的功能,不過該功能無法備份圖譜元數據,全量導入會刪除並重建圖譜,由於元數據發生變化,之前的備份就沒有用了。後續會嘗試全量導入只清理數據不刪圖的方式來避免這個問題。
知識圖譜業務的邊類型非常多,經常一次查詢需要查詢幾十上百種邊,每種類型的邊其實只需要返回 Top 10(根據rank排序)個結果就好。這種情況通過 nGQL 很不好實現,只能查詢這些邊的所有數據,或者所有邊合在一起的 Top N 個數據,前者有性能問題,後者經常只能返回部分類型邊的數據,無法滿足需求。針對這種情況,我們對邊進行了分類,對於數量較少的那些邊類型,一條語句查詢所有數據。對於數量多的邊類型,使用多執行緒並行查詢每條邊的Top 10,這樣就能進行一定的規避。
為了保證服務的高可用,我們實現了雙機房部署。為了不讓上層業務感知機房切換,在圖資料庫上層做了查詢工程(圖檢索),業務直接調用查詢工程的服務,查詢工程會根據集群狀態選擇合適的圖資料庫集群查詢。另外,為了向上層業務屏蔽底層圖資料庫變更和版本升級,查詢工程會管理所有業務的查詢語句。遇到圖資料庫因為版本升級出現查詢語句不兼容的時候,只需要在查詢工程中將圖查詢語言進行調整就好,避免波及上層業務。同時,查詢工程也對查詢結果進行了快取,可以極大的提高圖查詢的吞吐量。
當然我們還遇到一些問題,如rank因大小端問題導致排序失效、查詢結果只返回邊類型id等,因為篇幅原因,在此不一一列舉,這些問題通過 Nebula Graph 社區幫助,已經得到了規避或解決。
*注意:以上提到的 Nebula Graph 問題僅針對 V1.2.0 版本,很多問題後續版本已經修復。
5、業務落地
5.1、知識圖譜及智慧問答
在使用圖譜之前,小布助手只支援基於文檔的問答 DBQA,DBQA 利用的是非結構化的文本,適合回答 Why、How 等解釋性、論述性問題,而對於事實性問題回答準確率和覆蓋率不高。
在使用圖譜後,小布助手支援基於知識庫的問答 KBQA,在 What、When 等事實性問題的準確率和覆蓋率大幅度提升。例如:xxx的老婆是?xxx奧特曼的體重是多少?北京的面積是多少?
除了事實性問答,小布助手還可以利用圖譜的推理能力實現一些複雜問答:例如:xxx和xxx是什麼關係?OPPO發布的第一款手機是什麼?xxx和xxx共同參演的電影有哪些?出生在xx的雙子座明星有哪些?
由於知識圖譜存在規模龐大的半結構化數據,而且數據之間存在很多的關聯關係,使用關係型資料庫是無法滿足存儲和查詢要求的,而圖資料庫恰恰能夠解決大規模圖譜存儲和多跳查詢的挑戰。
5.2、內容標籤

在一些推薦場景中,需要理解影片、音頻或文本的內容,給其打上和內容相關的標籤。例如在短影片推薦中,理解影片的內容有利於對用戶進行精準推薦。
對於影視類影片,將演員、影視節目、扮演角色構造成一個影視娛樂圖譜,當有新的影視類短影片發布時,可以通過影片中人臉識別出演員、標題或字幕中識別出影視角色,利用圖譜快速推理出對應的影視作品,給影片打上內容標籤,從而提升推薦效果。
5.3、數據血源
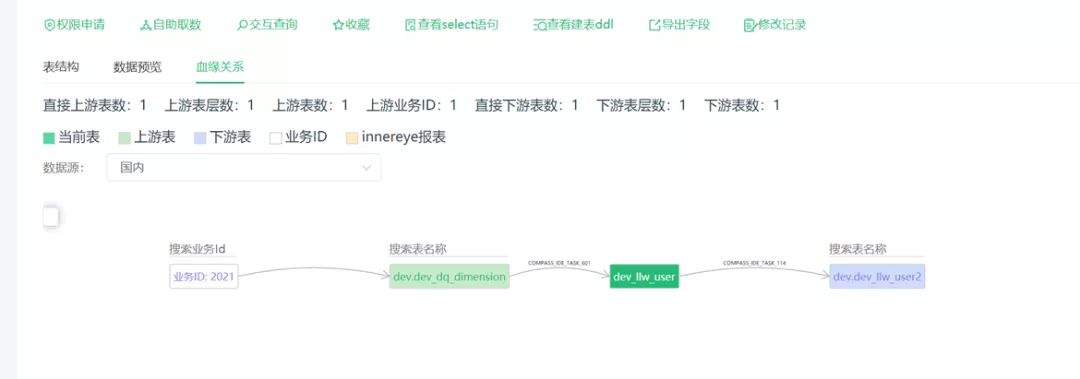
在數倉中,經常需要運行各種 ETL Job,數據表和任務非常多,如何直觀的觀察數據表上下游與任務之間的關係變成一個亟需解決的問題。
使用關係型資料庫處理多層級的關聯查詢非常麻煩,不僅開發工作量大,而且查詢性能極慢。而使用圖資料庫,不僅大大減少了開發工作量,而且能夠快速的查出表的上下游關係,便於直觀觀察數據的血緣關係。
5.4、服務架構拓撲

在服務資源管理中,業務資源會分為多個層級,每個層級下面有對應的伺服器、服務和管理人員,如果使用關係資料庫來處理,當需要展示多級資源的時候,查詢會很麻煩,性能會很差。這個時候,可以將資源、管理人員、伺服器、業務層級之間的關係放到圖資料庫中,展示的時候,一條查詢語句就能搞定,查詢速度還很快。
6、總結
通過知識圖譜等業務實踐落地,完成了從 JanusGraph 向 Nebula Graph 的轉變,導入性能提升了一個數量級,查詢性能以及並發能力都有 3-6 倍的提升。而且,Nebula Graph 比 JanusGraph 更穩定。在實踐的過程中,也遇到過很多問題,得到了 Nebula Graph 社區非常多的幫助,十分感謝社區的支援!
圖資料庫在最近這幾年發展很快,Neo4j 今年上半年融資3.25 億美金,刷新了資料庫的融資記錄。Gartner 發布的報告指出:「到 2023 年,圖技術將促進全球 30% 企業的快速決策場景化。圖技術應用的年增長率超過 100%。」隨著 5G 和物聯網的普及,圖資料庫將成為處理關係的基礎設施。
7、參考文檔
- 1.數據結構:什麼是圖://blog.csdn.net/dudu3332/article/details/104682280
- 2.Nebula Graph 架構總覽://docs.nebula-graph.com.cn/2.0.1/1.introduction/3.nebula-graph-architecture/1.architecture-overview/
- 3.越來越火的圖資料庫究竟是什麼?//www.cnblogs.com/mantoudev/p/10414495.html
- 4.圖的應用場景://help.aliyun.com/document_detail/134191.html
- 5.最全的知識圖譜技術綜述://www.sohu.com/a/196889767_151779
- 6.KBQA 從入門到放棄://www.sohu.com/a/163278588_500659
- 7.graphdb-benchmarks://github.com/socialsensor/graphdb-benchmarks
- 8.主流開源分散式圖資料庫 Benchmark://discuss.nebula-graph.com.cn/t/topic/1377
- 9.圖資料庫 LightGraph 測試報告://zhuanlan.zhihu.com/p/79426763
- 10.TigerGraph 官方測試://www.tigergraph.com.cn/developers/graph-benchmark/comparison/
- 11.GalaxyBase 官方測試://blog.csdn.net/qq_41604676/article/details/117331328
作者簡介
Qirong, OPPO 高級後端工程師, 主要從事圖資料庫、圖計算及相關領域的工作。
本文中如有任何錯誤或疏漏,歡迎去 GitHub://github.com/vesoft-inc/nebula issue 區向我們提 issue 或者前往官方論壇://discuss.nebula-graph.com.cn/ 的 建議回饋 分類下提建議 👏;交流圖資料庫技術?加入 Nebula 交流群請先填寫下你的 Nebula 名片,Nebula 小助手會拉你進群~~


