剖析虛幻渲染體系(12)- 移動端專題Part 2(GPU架構和機制)
- 12.4 移動渲染技術要點
- 12.4.1 Tile-based (Deferred) Rendering
- 12.4.2 Hierarchical Tiling
- 12.4.3 Early-Z
- 12.4.4 Transaction Elimination
- 12.4.5 Forward Pixel Kill
- 12.4.6 Hidden Surface Removal
- 12.4.7 Low Resolution Z pass
- 12.4.8 FlexRender
- 12.4.9 Universal Bandwidth Compression
- 12.4.10 Arm Frame Buffer Compression
- 12.4.11 Index-Driven Vertex Shading
- 12.4.12 Pixel Local Storage
- 12.4.13 Subpass
- 12.4.14 Adaptive Scalable Texture Compression
- 12.4.15 big.LITTLE Core
- 12.4.16 其它技術要點
- 12.5 移動GPU架構和機制
- 團隊招員
- 特別說明
- 參考文獻
12.4 移動渲染技術要點
筆者這段時間研讀了近年來Siggraph、GDC關於移動端的Papers,查閱了Qualcomm、Arm、PowerVR等移動端GPU廠商和部分移動設備廠商的開發指南,在本章總結一下目前移動端常見的專用渲染技術。
具體見後面的參考文獻列表。
12.4.1 Tile-based (Deferred) Rendering
TBR全稱是Tile-based Rendering,譯為基於分塊的渲染。它是目前移動端GPU架構中應用非常廣泛的一種技術,用來加速渲染,減少頻寬和能耗。
TBDR全稱是Tile-based Deferred Rendering,是TBR的一種改進版,意為基於分塊的延遲渲染,最早由PowerVR應用於GPU晶片中。它最顯著的不同點在於通過了Early-Z測試的像素不會立即執行像素著色器,而是先標記該像素屬於哪個圖元。當Tile處理完所有圖元(場景中的所有物體),再繪製Tile上所有做了標記的像素。TBDR做到了硬體層級的遮擋像素剔除,減少OverDraw,減少頻寬和記憶體訪問。
PowerVR的TBDR在開始渲染之前,會捕獲整個場景,這樣被遮擋的像素在被像素著色器之前就可以被識別和剔除。每個Tile都被光柵化並單獨處理,由於渲染的尺寸很小,使得允許所有數據都保存在非常快的Tile記憶體中。
與TB(D)R對應的是用於PC的立即渲染(Immediately Rendering,IMR)模式。IMR、TBR、TBDR架構的對比圖如下:

IMR、TBR、TBDR架構運行示意圖。其中紅色橢圓表示頻寬高,會引發性能瓶頸。
對於IMR模式的GPU,若忽略並行處理邏輯,則執行的偽程式碼如下所示:
for draw in renderPass:
for primitive in draw:
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:
for fragment in primitive:
execute_fragment_shader(fragment)
IMR的GPU硬體架構如下所示:
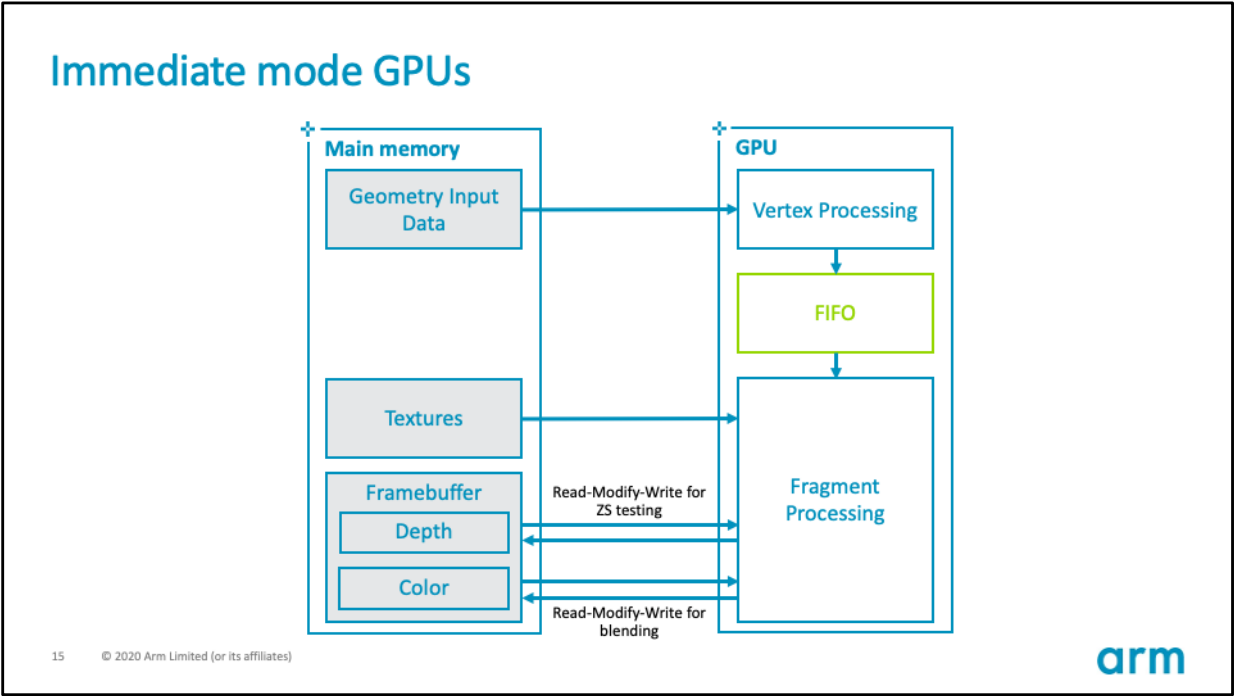
其硬體數據流和記憶體交互圖如下:

IMR模式的GPU的優勢在於,頂點著色器和其它幾何體相關著色器的輸出可以保留在GPU內的晶片上。這些著色器的輸出可以存儲在FIFO緩衝區,直到管道中的下一階段準備使用數據,GPU可以使用很少的外部記憶體頻寬存儲和檢索中間幾何結果。
IMR模式的GPU的劣勢在於,像素著色在螢幕上跳躍,因為三角形按繪製順序處理,數據流中的任何三角形都可能覆蓋螢幕的任何部分(下圖)。意味著活動工作集是整個framebuffer的大小。例如,考慮一個解析度為1440p的設備,使用32位每像素(BPP)的顏色,32位每像素的填充深度/模板,將提供30MB的總工作集,若全部存儲在on chip上,數據量過大,因此必須存儲在DRAM的off chip之外。
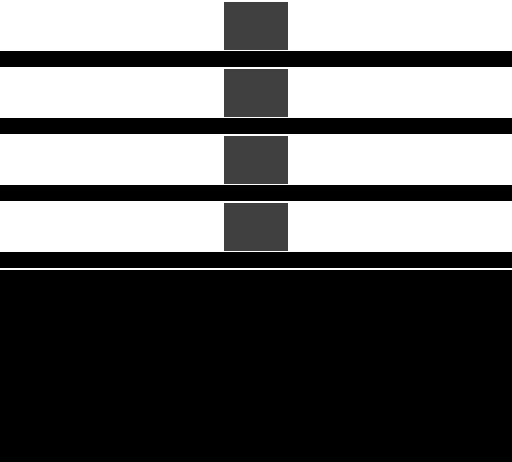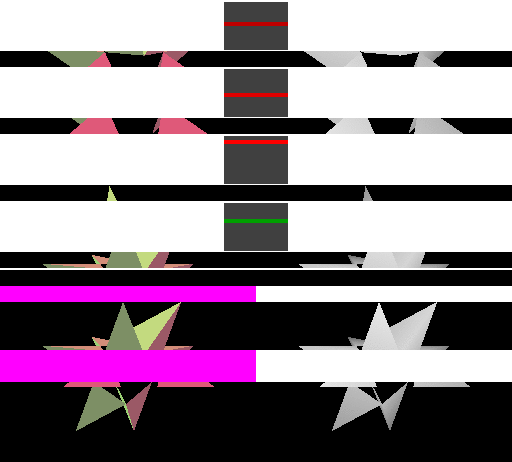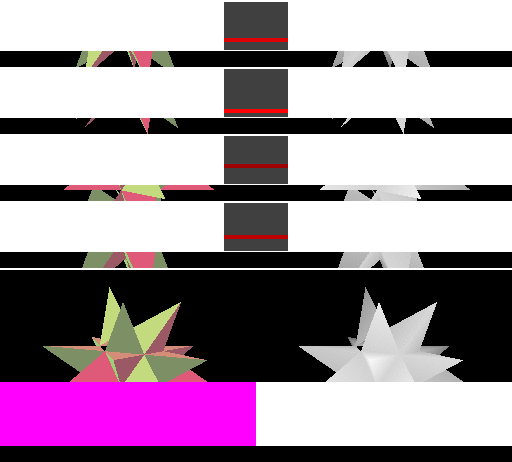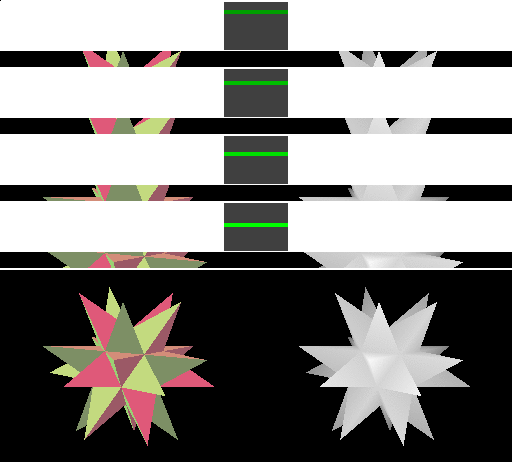
IMR的並行渲染示意圖,隨機訪問遍布全螢幕幕,導致緩衝命中率大大降低。
在處理高解析度畫面時,放置在記憶體上的頻寬負載可能非常高,因為每個像素都有多個讀-修改-寫操作。可以通過將最近訪問的framebuffer部分保持在靠近GPU的位置來減輕高頻寬負載。
TB(D)R的GPU則與IMR GPU不同,它先將螢幕劃分成若干個固定大小的區域,然後再執行著色計算。下面是TBR的執行偽程式碼:
# Pass one
for draw in renderPass:
for primitive in draw:
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:
append_tile_list(primitive)
# Pass two
for tile in renderPass:
for primitive in tile:
for fragment in primitive:
execute_fragment_shader(fragment)
TB(D)R GPU的硬體架構如下所示:

其硬體數據流和記憶體交互圖如下:

TB(D)R的優勢在於,Tile只佔整個framebuffer的一小部分。 因此,可以將整個顏色、深度和模板的工作集存儲在快速的 on-chip RAM上,與GPU著色器核心緊密耦合。GPU用於深度測試和混合透明像素所需的framebuffer數據無需訪問外部記憶體即可獲得,通過減少GPU對通用framebuffer操作所需的外部記憶體訪問數量,可以顯著提高像素密集型內容的能源效率。此外,多數情況存在一個深度和模板緩衝,它們是瞬態的,只需要在著色過程中存在。如果明確告訴GPU驅動程式不需要保存附件(Attachment),那麼驅動程式就不會將它們寫回主存。
以下圖形API可以指示驅動程式丟棄附件:
OpenGL ES 2.0:
glDiscardFramebufferEXTOpenGL ES 3.0:
glInvalidateFramebufferVulkan:恰當的渲染通道storeOp
值得一提的是,由於每個Tile的尺寸通常不會很大,使得GPU計算單元訪問單個Tile內的數據具有良好的鄰域性,能夠提升Cache命中率。
當然,天下沒有免費的午餐,TB(D)R同樣存在一些劣勢。例如,GPU必須將幾何通道的輸出(每個頂點的變化數據和Tile的中間狀態)存儲到主記憶體中,著色通道隨後讀取這些數據。因此,需要在與幾何圖形相關的額外頻寬成本和為framebuffer數據節省的頻寬之間取得平衡。同樣重要的是要考慮到一些渲染操作,比如曲面細分,對於TBR來說是不成比例的高消耗。曲面細分等操作被設計來適應IMR模式架構的優勢,因為幾何數據的爆炸可以在on-chip FIFO緩衝區內緩衝,而不是被寫回主存儲器。
下面以Qualcomm Adreno系列GPU加以說明TB(D)R的架構、運行過程、涉及的渲染技術和優化技巧。

TB(D)R的渲染不同於IMR模式,繪製過程分為分塊(Binning Pass)、渲染(Rendering Pass)、解析(Resolve Pass)3個階段。
分塊(Binning Pass)過程大致如下:
-
設定每個Bin(也被稱為Tile)的固定大小(2的N次方,長寬通常相同,具體尺寸因GPU廠商而異,如16×16、32×32、64×64),根據Frame Buffer尺寸設置可見數據流。

-
轉換圖元坐標。注意此階段處理的是索引和頂點數據,某些GPU(如Adreno)會用特殊的簡化過的shader(而非完整的Vertex Shader)來處理坐標,以減少頻寬和能耗。此階段通常只有頂點的位置有效,其它頂點數據(紋理坐標、法線、切線、頂點顏色)都會被忽略。
-
遍歷所有圖元,標記所有圖元覆蓋到的塊,將可見性數據寫入到被覆蓋的塊數據流中。
-
將可見性數據流寫回系統顯示記憶體中。

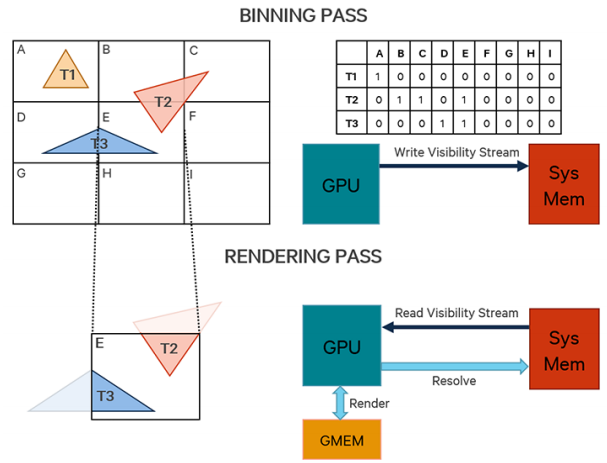
Binning階段的運行示意圖如下:
渲染(Rendering Pass)過程大致如下:
- 初始化渲染Pass。
- 遍歷所有分塊,對每個分塊執行以下操作:
- 利用分塊的可見性數據流,執行繪製調用。
- 光柵化圖元。
- 像素操作(像素著色器、深度模板測試、Alpha測試、混合)。
- 寫入像素數據(顏色、深度、模板等等)到分塊晶片上的緩衝區(又被稱為On-Chip Memory、GMEM、Tiled Memory)。
Rendering階段的運行示意圖如下:
如果GPU上存在多個Tile處理單元,則可以同時處理多個Tile,並且Tile處理單元之間是相互獨立的:
解析(Resolve Pass)階段過程如下:
-
如果開啟了MSAA,在GMEM上的解析顏色、深度等數據(求平均值)。可以減少後續步驟GMEM傳輸到系統顯示記憶體的數據總量。

-
將分塊上的所有像素數據(顏色、深度、模板等)寫入到系統顯示記憶體中。
-
如果不是Frame Buffer的最後一個分塊,繼續執行下一個分塊。
-
如果是Frame Buffer的最後一個分塊,交互緩衝區,執行下一幀的Binning Pass。

解析階段的運行示意圖如下(注意Tile內的像素包含鋸齒,下方大畫面的是解析完MSAA帶抗鋸齒的像素):

其中Binning Pass和Rendering Pass通常是分幀處理的,意味著Rendering Pass會落後Binning Pass一幀,以減少Stall,提升吞吐量,提升渲染效率。
基於TB(D)R GPU架構的優化和技術還有很多,後面會涉及到。
12.4.2 Hierarchical Tiling
Hierarchical Tiling譯為層級分塊,是Arm Midgard系列晶片首次使用的分塊技術,顧名思義,它在分層的基礎上實現分塊。
在這種情況下,使用Hierarchical Tiling允許Midgard使用可變的分塊大小,基於進一步分解分塊的想法(沿著層次結構向下,見下圖),直到分塊的複雜性達到預期的大小(或者達到最小的分塊複雜性)。這種技術使得Midgard只在必要的情況下使用小尺寸分塊,並通過在複雜性較低的場景使用大尺寸分塊來節省資源。
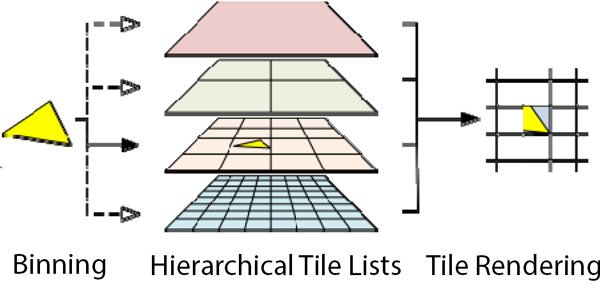
更具體地說,Arm通常將不同層級的分塊(bin)設為以下的大小:
- Hierarchy Level 0設為16×16像素;
- Hierarchy Level 1設為32×32像素;
- Hierarchy Level 2設為64×64像素;
- Hierarchy Level 3設為128×128像素;
- ……

系統的目標是找出每個圖元覆蓋的分塊,更新分塊的結構資訊。
如果是小面積圖元(如上圖灰色三角形),由於影響到的塊比較少,用低層級的塊,以節省讀取頻寬。
如果是大面積圖元(如上圖藍色三角形),由於影響到的塊比較多,用高層級的塊,以節省寫入頻寬。
對於圖元複雜的情況,GPU會採用啟發性策略,以自動決定哪種是最佳的分布。
至於啟發性策略的具體細節是怎樣的,目前還沒找到相關資料或文獻,如果以後找到了(或有同學提供)再補充。
12.4.3 Early-Z
Early-Z是提前深度測試,提供了一種快速遮擋方法,剔除不需要的渲染Pass的對象(螢幕空間的位置不可見的像素)。Adreno GPU可以以4倍的繪製像素填充率剔除被遮擋的像素。
Early-Z通常發生在Rendering Pass階段的光柵化之後像素著色之前。(下圖)

Early-Z技術可以將很多無效的像素提前剔除,避免它們進入消耗嚴重的像素著色器。Early-Z剔除的最小單位不是1像素,而是像素塊(pixel quad)。下面是其中的一個運行案例。
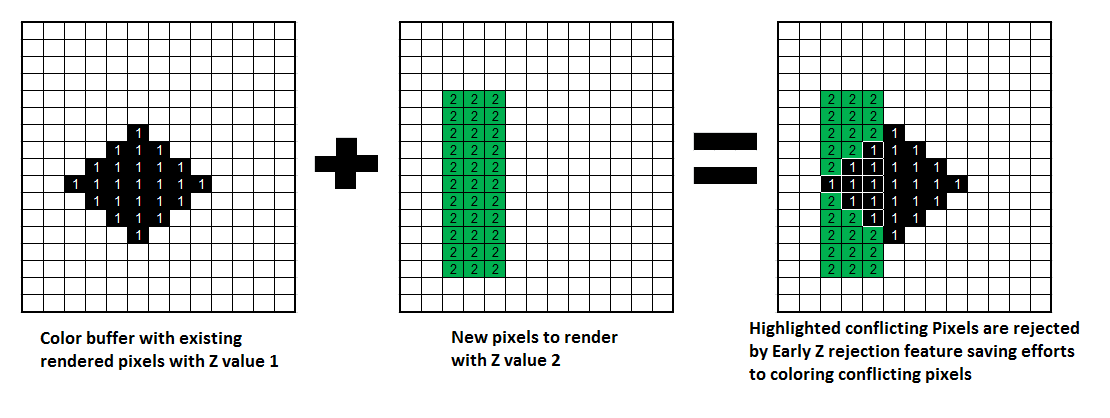
Early-Z運行示意圖。左邊是已經渲染的存儲於深度緩衝的值,全部為1;中間是準備渲染的所有深度值為2的區域;右邊利用Early-Z技術剔除了比深度緩衝較大的像素。
為了最大化發揮Early-Z技術,渲染引擎(如UE)會在渲染初期利用專門的Pass(如UE的PrePass),渲染出所有不透明物體的深度,發揮TBR架構的Early-Z技術。對支援TBDR架構的GPU,則無需此步。
但是,以下情況會導致Early-Z失效:
- 開啟Alpha Test:由於Alpha Test需要在像素著色器後面的Alpha Test階段比較,所以無法在像素著色器之前就決定該像素是否被剔除。
- 開啟Alpha Blend:啟用了Alpha混合的像素很多需要與frame buffer做混合,無法執行深度測試,也就無法利用Early-Z技術。
- 開啟Tex Kill:即在shader程式碼中有像素摒棄指令(DX的discard,OpenGL的clip)。
- 關閉深度測試:Early-Z是建立在深度測試開啟的條件下,如果關閉了深度測試,也就無法啟用Early-Z技術。
- 開啟Alpha To Coverage:Alpha To Coverage會開啟多取樣,會影響周邊像素,而Early-Z階段無法得知周邊像素是否被裁剪,故無法提前剔除。
- 以及其它任何導致需要混合後面顏色的操作。
12.4.4 Transaction Elimination
Transaction Elimination (TE)是Mali GPU架構的一個關鍵頻寬節約功能,可以顯著節省晶片系統(SoC)上的能源。
當執行TE時,GPU將當前幀緩衝區與之前渲染的幀進行比較,只對修改過的特定部分進行部分更新,從而大大減少了每幀向外部記憶體傳輸的數據量。以Tile為粒度進行比較,使用循環冗餘檢查(Cyclic Redundancy Check,CRC)簽名來確定Tile是否已被修改(具有相同CRC簽名的Tile被認定是相同的,從而忽略該Tile的數據的傳輸)。
循環冗餘檢查(Cyclic Redundancy Check,CRC)是一種根據網路數據包、電腦文件、記憶體數據流等數據產生簡短固定位數校驗碼的一種散列函數,主要用來檢測或校驗數據傳輸或者保存後可能出現的錯誤。這裡被Mali GPU用來檢測本幀的Tile數據和之前的Frame Buffer數據是否相同。

TE技術運行概要。當前幀會每個分塊計算一個CRC鍵值,以便下一幀比較每個分塊是否有數據變更,對於無變更的分塊取消數據傳輸。圖中右下角的綠色分塊和上一幀匹配,不需要傳輸數據到Frame Buffer。對於互動遊戲而言,平均可以減少20%以上的頻寬。
執行TE技術對最終影像品質沒有影響,可用於GPU支援的所有幀快取格式的所有應用程式,而無需考慮幀快取精度要求。另外,需要注意的是,TE發生在Tile寫入數據到系統記憶體(Frame Buffer)期間(下圖左下方)。
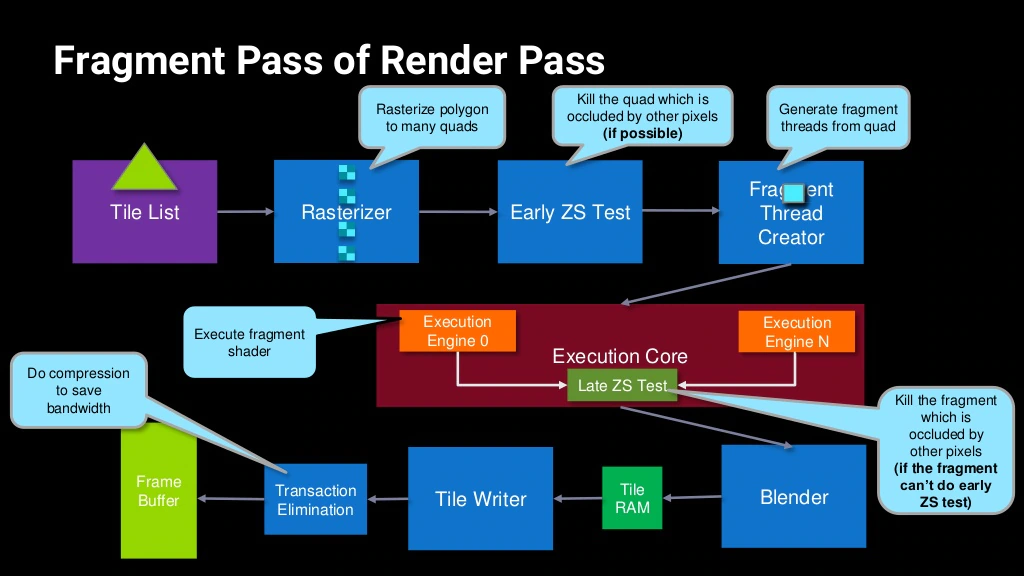
12.4.5 Forward Pixel Kill
Forward Pixel Kill (FPK)是Mali-T62X和T678及之後的晶片內置的一種減少OverDraw的技術。
在支援FPK的GPU中,像素著色的執行緒即便啟動,也不會不可逆轉地完成。正在進行的計算可以在任何時候終止,如果渲染管線發現後面的執行緒將把不透明的數據寫入相同的像素位置。因為每個執行緒都需要有限的時間來完成,所以有一個時間窗口,可以利用它來殺死已經在管道中的像素。實際上,利用管道的深度來模擬對未來的預見效應。
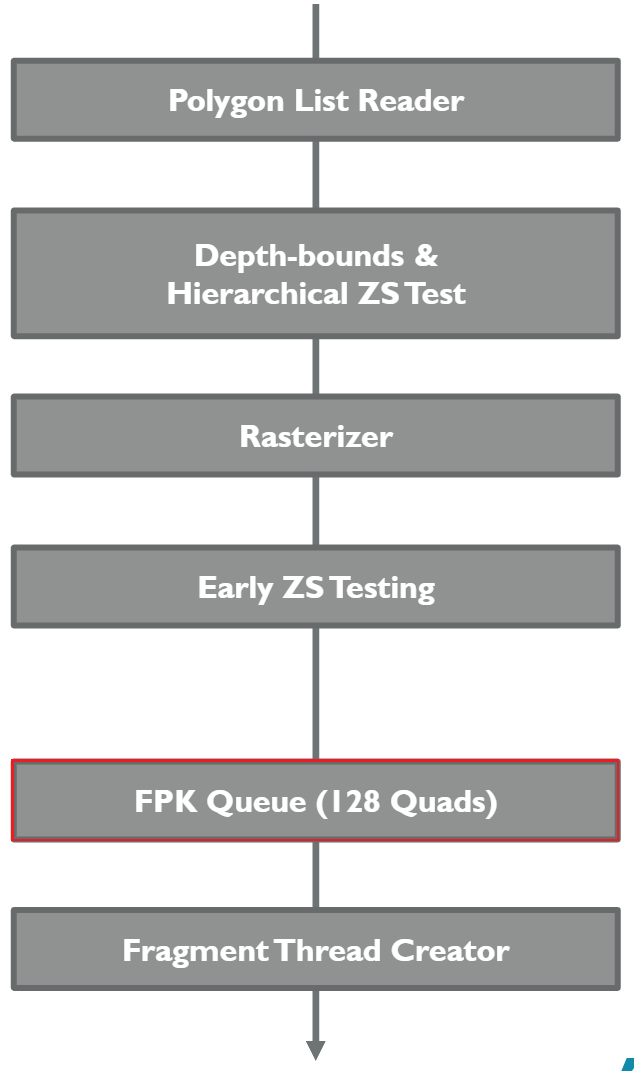
支援FPK的GPU晶片內都存在FIFO(先進先出)緩衝區(介於Early Z測試和像素著色器之間,見下圖),用來存儲通過了Eearly-Z測試即將進入像素著色計算的Quad。
舉個具體的例子說明FPK的運行機制,以下圖為例:
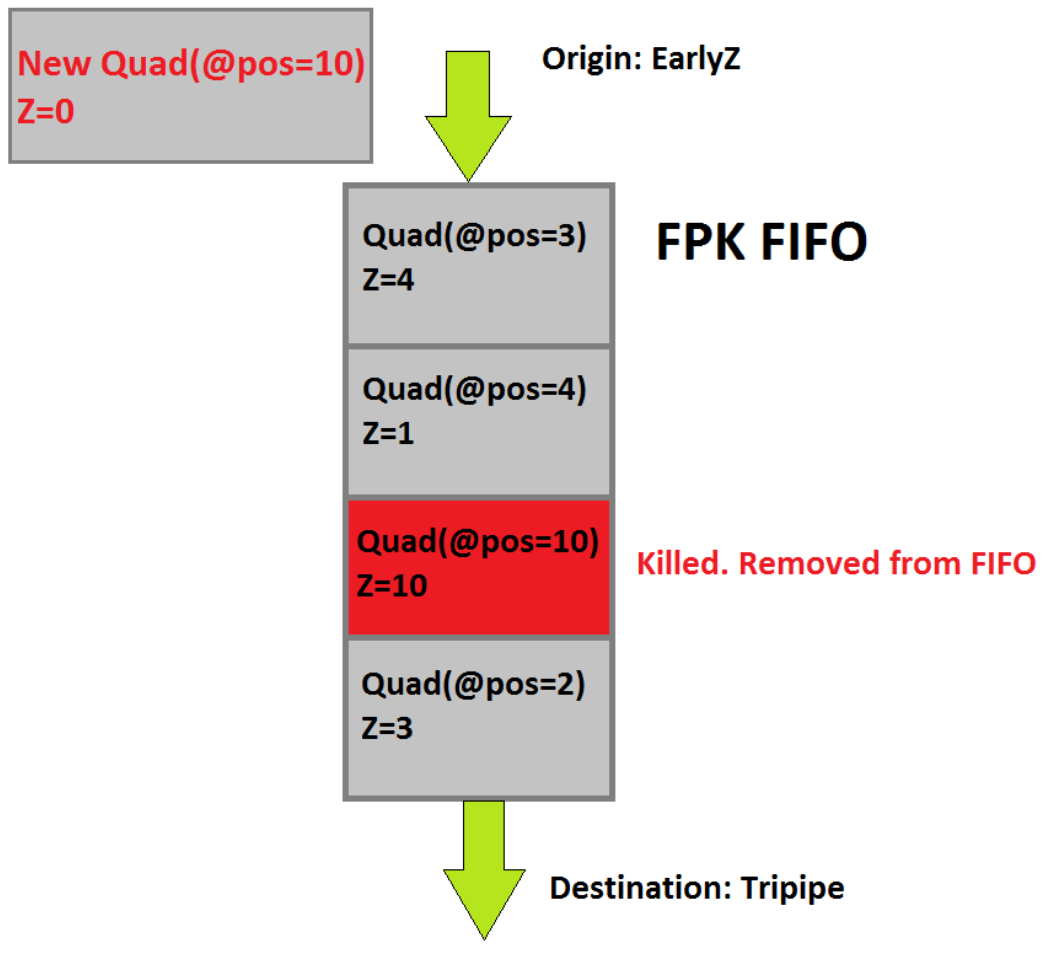
上述圖中新的Quad(位置是10,深度是0)通過了EarlyZ測試,即將進入FPK FIFO緩衝區,結果發現FIFO中已經存在位置為10位置為10,新進來的Quad便會替換掉FIFO隊列的Quad(因為新的深度更靠近螢幕)。換而言之,FPK FIFO中的Quad會被新進的位置相同深度更小(近)的Quad替換掉。
關於FPK需要補充幾點說明:
- FPK剔除粒度是Quad(2×2像素塊)。
- FPK只對不透明物體有效。
- FPK必須開啟深度測試才能起作用。
12.4.6 Hidden Surface Removal
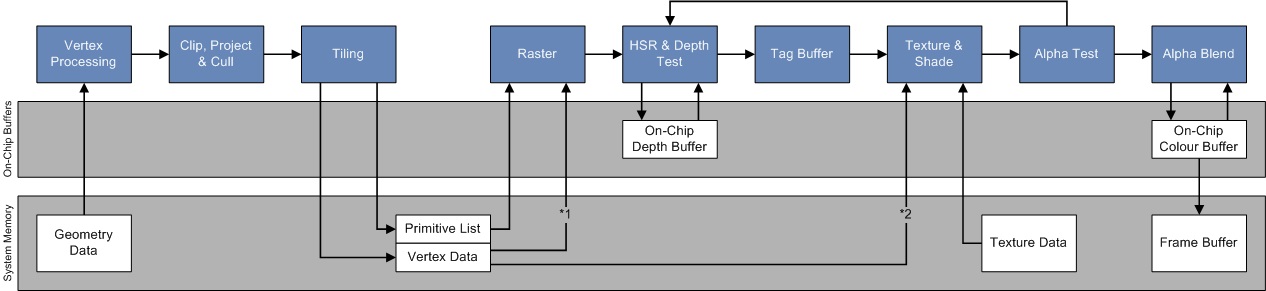
Hidden Surface Removal(HSR)譯為隱藏表面消除,是PowerVR晶片的專用技術,通過HSR技術,可以實現零OverDraw,而與繪製順序無關。
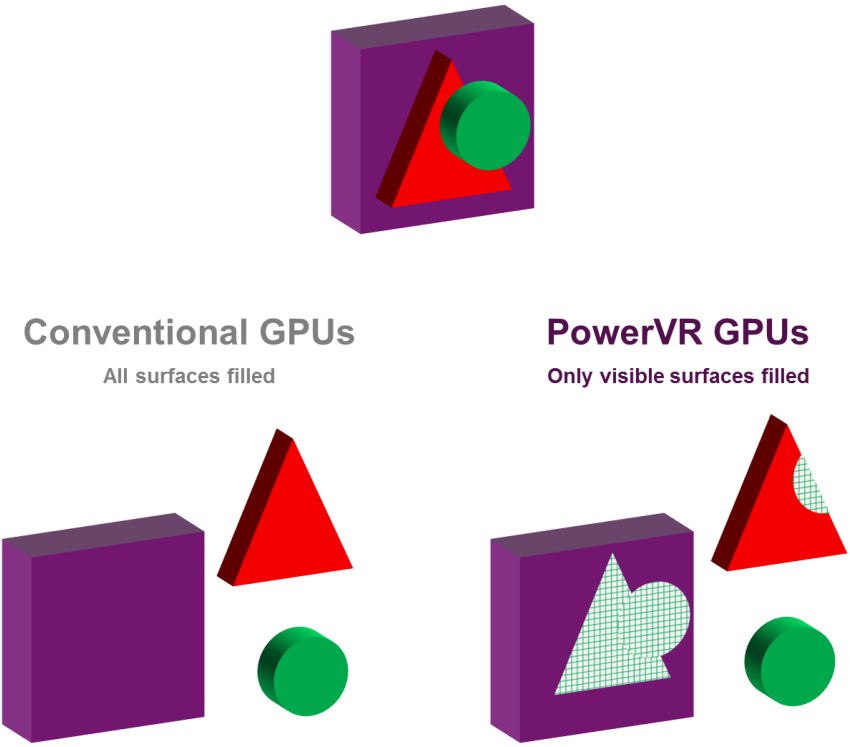
左下是傳統GPU,不會對被遮擋的像素執行剔除,而右下展示了PowerVR利用HSR可以做到像素級剔除。
在包含Early-Z測試的架構中,應用程式可以通過從前面到後面提交draw調用來避免一些OverDraw。按照這個順序提交可以建立深度緩衝區,因此遠離相機的被遮擋的像素可以儘早被剔除。然而,這給應用程式帶來了額外的負擔,因為每次相機或場景中的對象移動時,繪製都必須進行排序。它也不能刪除所有的OverDraw,因為逐繪製排序是非常粗糙的。例如,它不能解決由對象交叉引起的OverDraw。 它還可以防止應用程式對繪製調用進行排序,以將圖形API狀態更改保持在最小值。
使用PowerVR的TBDR,無論物體的提交順序如何(不排序),HSR將完全避免OverDraw。HSR階段處於光柵化之後像素著色之前:
12.4.7 Low Resolution Z pass
Low Resolution Z pass簡稱LRZ,是Adreno A5X及以上的晶片在TBR執行Early-Z剔除時的優化技術。
在Binning Pass階段,GPU會構造一個低解析度的Z緩衝區,以LRZ-Tile(注意不是Bin Tile)為粒度來剔除被遮擋的區域,以提高Binning階段的性能。在測試全解析度Z緩衝區之前,這個LRZ還可以在Rendering Pass中被用來有效地剔除像素。
這個特性的優點是減少記憶體訪問和頻寬,減少渲染圖元,不需要應用程式從前到後繪製,提高幀率。
但是,以下幾種情況會使LRZ技術失效:
- 在像素著色器中寫入深度值。
- 使用了圖形API(Vulkan)的次級命令緩衝區(secondary command buffer)。
- 需要IMR直接渲染的任何條件。
12.4.8 FlexRender
FlexRender是Adreno晶片的獨有技術,是混合了TBR(Binning)和IMR(Direct Rendering)兩種模式的渲染技術,通過在兩種模式之間動態切換來最大化性能。

FlexRender運行示意圖。Direct Rendering模式下,GPU繞過GMEM直接和系統記憶體交互;Binning模式下,GPU通過GMEM和系統記憶體交互。
驅動程式和GPU分析給定渲染目標的渲染參數並自動選擇模式,比如渲染目標尺寸很小,會主動切換成IMR模式,以減少渲染消耗(TBR存在基礎消耗),如果是執行遮擋剔除,也會切換成IMR模式(哪怕之前處於TBR模式)。
通常情況下,IMR模式要比TBR模式消耗的能量多:
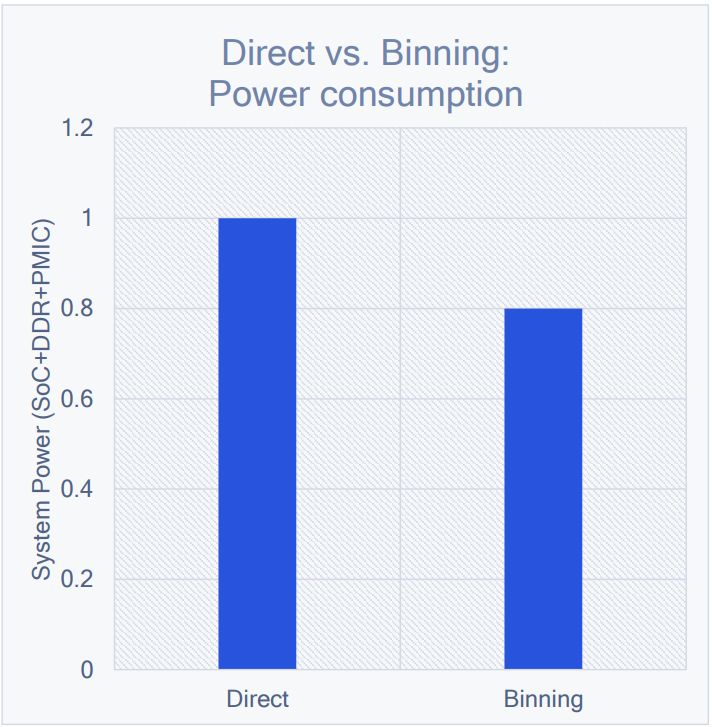
GFXBench Manhattan 3.0監控下的Snapdragon SoC在Direct和Binning模式的能耗對比,後者會省20%左右。
12.4.9 Universal Bandwidth Compression
Universal Bandwidth Compression (UBWC) 是Adreno A5x及之後的晶片加入的通用頻寬壓縮技術,是一種獨特的預測帶壓縮方案,通過最小化數據頻寬,可提高系統記憶體的有效吞吐量,實現顯著的節能。
除了GPU晶片,UBWC技術在應用於Snapdraggon CPU的多個組件上,如顯示、影片、相機等。壓縮支援YUV和RGB格式,減少記憶體瓶頸。
UBWC雖然應用於高通的晶片上,但Google Developer Contributes Universal Bandwidth Compression To Freedreno Driver顯示該技術實際上是由Freedreno開源驅動器提供。UBWC具體用了何種壓縮演算法,此文並未提及。
12.4.10 Arm Frame Buffer Compression
Arm Frame Buffer Compression (AFBC)專用於Arm設計的GPU中,解決了在移動設備的熱限制下創建越來越複雜的設計的難度。最重要的應用是影片後處理,在許多使用情況下,GPU需要讀取影片並在2D或3D場景中使用影片流作為紋理時應用特效。在這種情況下,AFBC可以降低整個系統級頻寬和傳輸空間協調影像數據的電力成本高達50%。
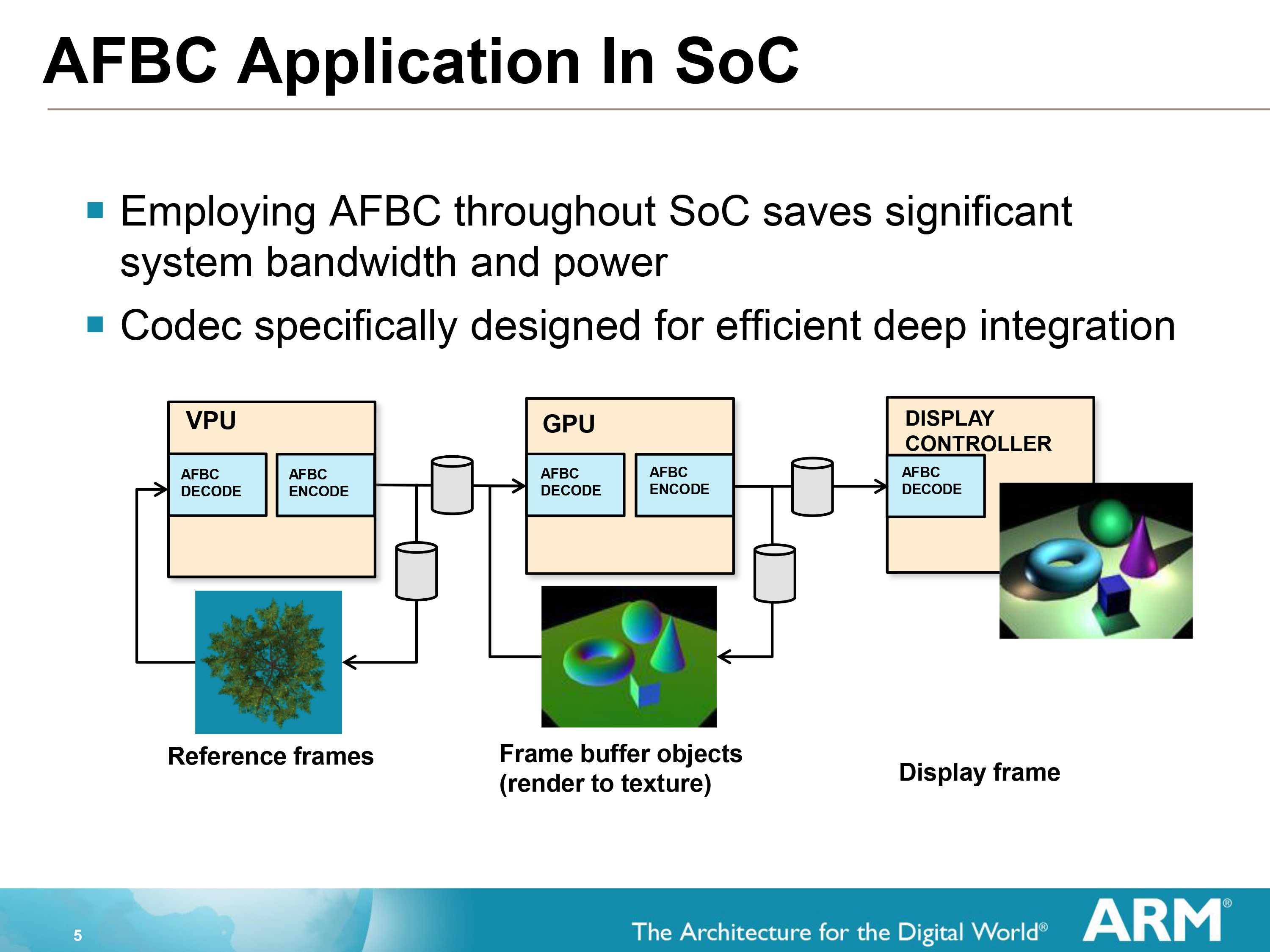
AFBC運行示意圖。
作為一種無損的壓縮協議和格式,AFBC最小化在SoC的IP塊之間的數據傳輸量。具體低說,AFBC有如下特點:
- 無損壓縮格式。壓縮格式保留原始影像精度,壓縮率和其它無損的壓縮標準相媲美。
- 被Mali GPU完全支援。
- 減少能量消耗。主要受益於頻寬的減少。
- SoC設計的區域效率高。AFBC可以在設計中以零面積成本添加。
- 有界的最壞情況壓縮比。最壞情況(隨機訪問)的效率下降成4×4級別。
- 支援YUV和RGB格式。YUV壓縮比一般為50%。
12.4.11 Index-Driven Vertex Shading
Index-Driven Vertex Shading(IDVS)是Mali GPU內的一種頂點處理優化技術,發生在每個Render Pass的頂點處理階段。
IDVS的主要特點在於將傳統的頂點著色器拆分為兩個階段:
- 第一階段是位置著色(Position Shading),發生在各類頂點Culling之前,此階段只轉換頂點位置,而不執行頂點的其它操作。
- 第二階段是可變著色(Varying Shading),發生在各類頂點Culling之後,只處理通過各類Culling的頂點,執行頂點的位置轉換之外的其它操作。
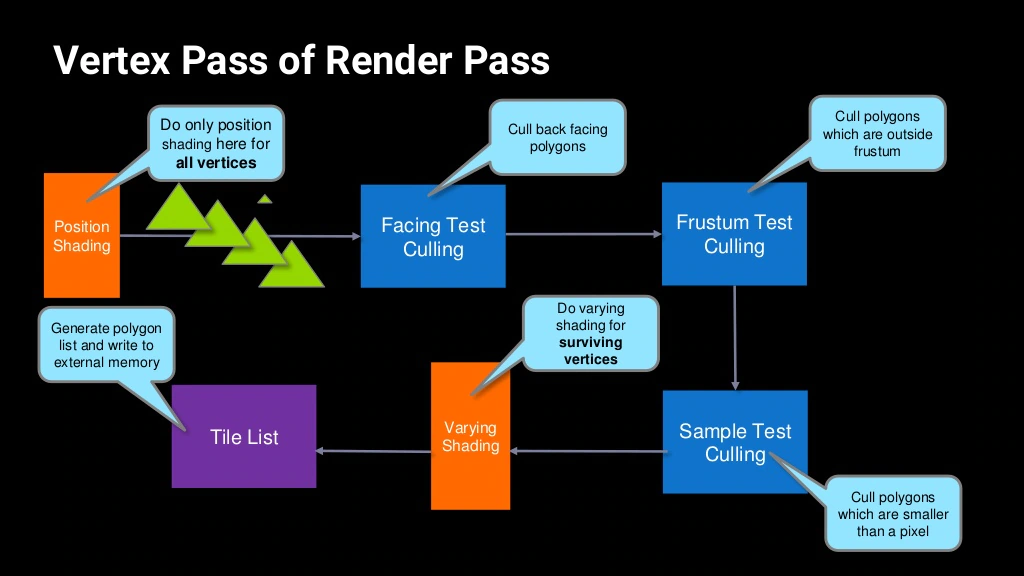
IDVS將頂點著色器拆分為位置著色(Position Shading)和可變著色(Varying Shading)兩個階段。
IDVS技術的優勢在於:
-
Varying Shading大多數情況消耗的性能要比Position Shading大,通過各類頂點Culling階段剔除掉無效的頂點,從而避免進入消耗大的Varying Shading。
-
通過匹配IDVS技術的頂點屬性布局,可以減少數據讀取量,提升Cache命中率,提升性能,降低功耗。匹配IDVS技術的頂點屬性布局如下:
-
將頂點的位置單獨成一個數據流,數據流布局如下:
xyz | xyz | xyz | ... -
將頂點除位置之外的屬性按照SoA(Structure of Array)布局,例如:
color,uv,normal | color,uv,normal | color,uv,normal | ...
-

IDVS頂點數據流優化及交互示意圖。
12.4.12 Pixel Local Storage
Pixel Local Storage(PLS)是OpenGL ES的一種數據存取方式,用PLS聲明的數據將保存在GPU的Tile buffer上(下圖)。

PLS啟用時,渲染管線可以高效地執行顏色操作、混合等。GLSL聲明PLS數據關鍵字有三種,說明如下表:
| 關鍵字 | 作用 |
|---|---|
| __pixel_localEXT | 可讀可寫數據。 |
| __pixel_local_inEXT | 只讀數據。 |
| __pixel_local_outEXT | 只寫數據。 |
PLS的應用以延遲渲染為例,則偽程式碼如下所示:
// ------GBuffer生成------
__pixel_local_outEXT FragData // 只寫數據
{
layout(rgba8) highp vec4 Color;
layout(rg16f) highp vec2 NormalXY;
layout(rg16f) highp vec2 NormalZ_LightingB;
layout(rg16f) highp vec2 LightingRG;
}gbuf;
void main()
{
gbuf.Color = CalcDiffuseColor();
vec3 Normal = CalcNormal();
gbuf.NormalXY = Normal.xy;
gbuf.NormalZ_LightingB.x = Normal.Z;
}
// ------光照累積------
__pixel_localEXT FragData // 可讀寫數據
{
layout(rgba8) highp vec4 Color;
layout(rg16f) highp vec2 NormalXY;
layout(rg16f) highp vec2 NormalZ_LightingB;
layout(rg16f) highp vec2 LightingRG;
}gbuf;
void main()
{
vec3 Lighting = CalcLighting(gbuf.NormalXY, gbuf.NormalZ_LightingB.x);
gbuf.LightingRG += Lighting.xy;
gbuf.NormalZ_LightingB.y += Lighting.z;
}
// ------最終著色------
__pixel_local_inEXT FragData // 只讀數據
{
layout(rgba8) highp vec4 Color;
layout(rg16f) highp vec2 NormalXY;
layout(rg16f) highp vec2 NormalZ_LightingB;
layout(rg16f) highp vec2 LightingRG;
}gbuf;
out highp vec4 FragColor;
void main()
{
FragColor = resolve(gbuf.Color, gbuf.LightingRG, gbuf.NormalZ_LightingB.y);
}
利用PLS執行延遲渲染的運行示意圖如下(注意右上方小方塊的紅色代表渲染幾何數據階段,綠色代表渲染光照階段):

除了OpenGL ES,Metal、Vulkan、D3D等圖形API也提供了相應的介面、關鍵字或標記支援GPU Tile上的數據操作。
以上程式碼顯示,延遲著色所需的GBuffer數據一直處於PLS之中,最好解析後返回最終顏色,而不需要將GBuffer寫回系統記憶體(下圖)。
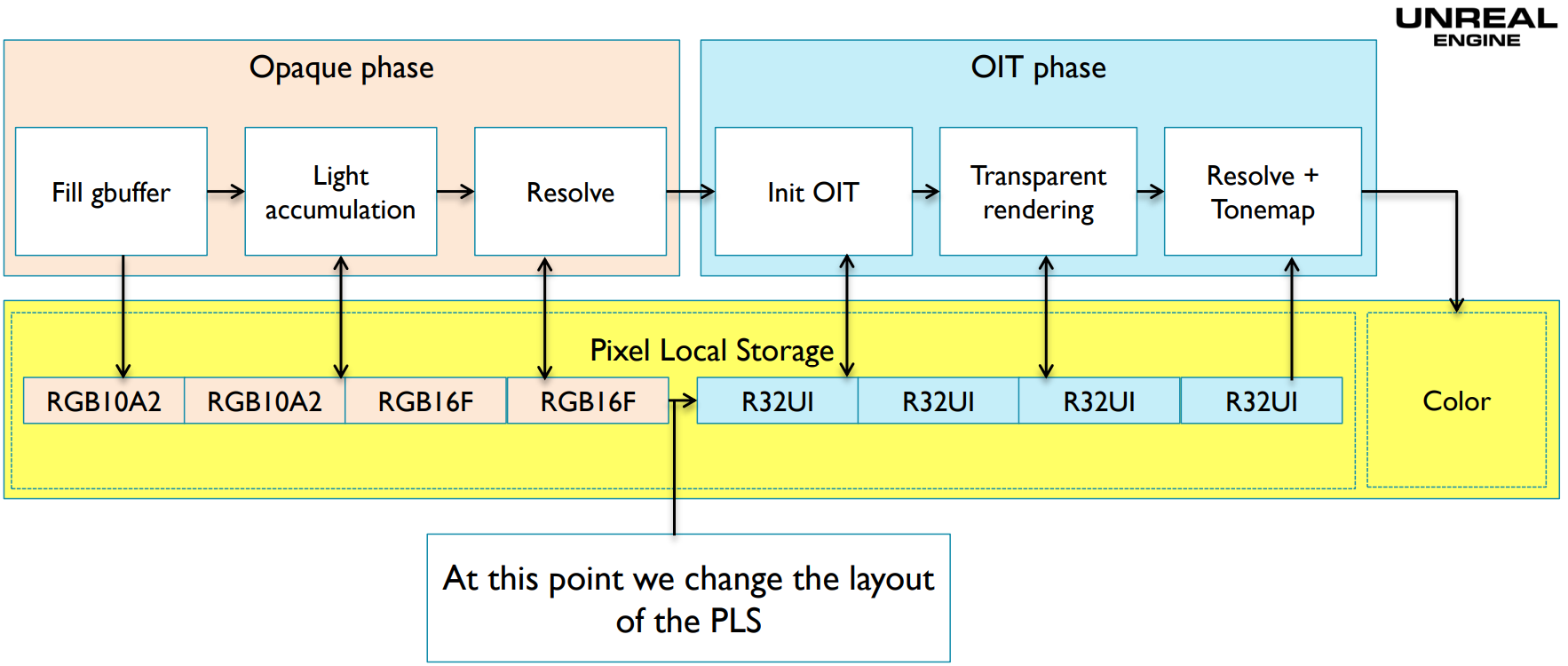
PLS能夠提升22%左右的性能:
UE4還利用PLS實現了高效的粒子軟混合:

左:粒子一般混合模式;右:粒子軟混合模式。
Vulkan也有類似的機制,被稱為Subpass,見後面章節。
12.4.13 Subpass
Subpass(子通道)是順應TB(D)R硬體架構的產物,適用於Vulkan、DX12、Metal等現代圖形API,底層原理類似於Pixel Local Storage。
使用Subpass需滿足以下幾點特殊的要求:
- 所有subpass必須在同一個Render Pass中。
- 不需要取樣周邊鄰域像素。(否則會跨Tile訪問數據,無法保持所有數據訪問在同一個Tile內)
- GPU支援TB(D)R的硬體架構。
- Vulkan、DX12、Metal等現代圖形API。
每個RenderPass和Subpass都可以為每個Attachment指定loadOp和storeOp,以便精確控制它們的存取行為:


subpass的loadOp標記有3種:
- LOAD_OP_LOAD:從全局記憶體載入Attachment到Tile。
- LOAD_OP_CLEAR:清理Tile緩衝區的數據。
- LOAD_OP_DONT_CARE:不對Tile緩衝區的數據做任何操作,通常用於Tile內的數據會被全部重新,效率高於LOAD_OP_CLEAR。
以上3個標記執行的效率:LOAD_OP_DONT_CARE > LOAD_OP_CLEAR > LOAD_OP_LOAD。Vulkan使用示例程式碼:
VkAttachmentDescription colorAttachment = {};
colorAttachment.format = VK_FORMAT_B8G8R8A8_SRGB;
colorAttachment.samples = VK_SAMPLE_COUNT_1_BIT;
// 標明loadOp為DONT_CARE.
colorAttachment.loadOp = VK_ATTACHMENT_LOAD_OP_DONT_CARE;
subpass的storeOp標記有2種:
- STORE_OP_STORE:將Tile內的數據存儲到全局記憶體。
- STORE_OP_DONT_CARE:不對Tile緩衝區的數據做任何存儲操作。
以上兩個標記的執行效率:STORE_OP_DONT_CARE > STORE_OP_STORE。Vulkan使用示例程式碼:
VkAttachmentDescription colorAttachment = {};
colorAttachment.format = VK_FORMAT_B8G8R8A8_SRGB;
colorAttachment.samples = VK_SAMPLE_COUNT_1_BIT;
// 標明loadOp為DONT_CARE.
colorAttachment.loadOp = VK_ATTACHMENT_LOAD_OP_DONT_CARE;
// 標明storeOp為DONT_CARE.
colorAttachment.storeOp = VK_ATTACHMENT_STORE_OP_DONT_CARE;
不像OpenGL ES在Shader中有顯式的關鍵字(__pixel_localEXT、__pixel_local_inEXT、__pixel_local_outEXT)來聲明Tile內變數,Vulkan為了讓Attachment存儲到Tile內,必須使用標記TRANSIENT_ATTACHMENT和LAZILY_ALLOCATED:
VkImageCreateInfo imageInfo{VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO};
imageInfo.flags = flags;
imageInfo.imageType = type;
imageInfo.format = format;
imageInfo.extent = extent;
imageInfo.samples = sampleCount;
// Image使用TRANSIENT_ATTACHMENT的標記.
imageInfo.usage = VK_IMAGE_USAGE_TRANSIENT_ATTACHMENT_BIT;
VmaAllocation memory;
VmaAllocationCreateInfo memoryInfo{};
memoryInfo.usage = memoryUsage;
// Image所在的記憶體使用LAZILY_ALLOCATED的標記.
memoryInfo.preferredFlags = VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT;
// 創建Image.
auto result = vmaCreateImage(device.get_memory_allocator(), &imageInfo, memoryInfo, &handle, &memory, nullptr);
使用subpass的loadOp和storeOp進行優化之後,Vulkan的官方測試示例顯示可以減少36%的全局記憶體讀取、62%的全局記憶體寫入、7%的片元執行周期:

另外,使用正確的storeOp和loadOp可以高效地在Tile內解析MSAA數據,具體說明如下:
-
帶MSAA的Image(或attachment)必須是瞬態的(transient),通過以下標記可在Render Pass結束時獲得解析MSAA後的數據:
- loadOp = LOAD_OP_CLEAR;
- storeOp = STORE_OP_DONT_CARE;
- 使用LAZILY_ALLOCATED的記憶體標記;
- 在subpass使用pResolveAttachments標記。
-
對於深度模板的Attachment,也可以獲得類似的效果:
- 使用VK_KHR_depth_stencil_resolve標記;
- Vulkan 1.2及以上的API才支援。
通過以上方式可以高效地在Tile內解析掉MSAA數據,而不會傳輸MSAA數據到全局記憶體。此外,需要避免使用vkCmdResolveImage介面解析MSAA:
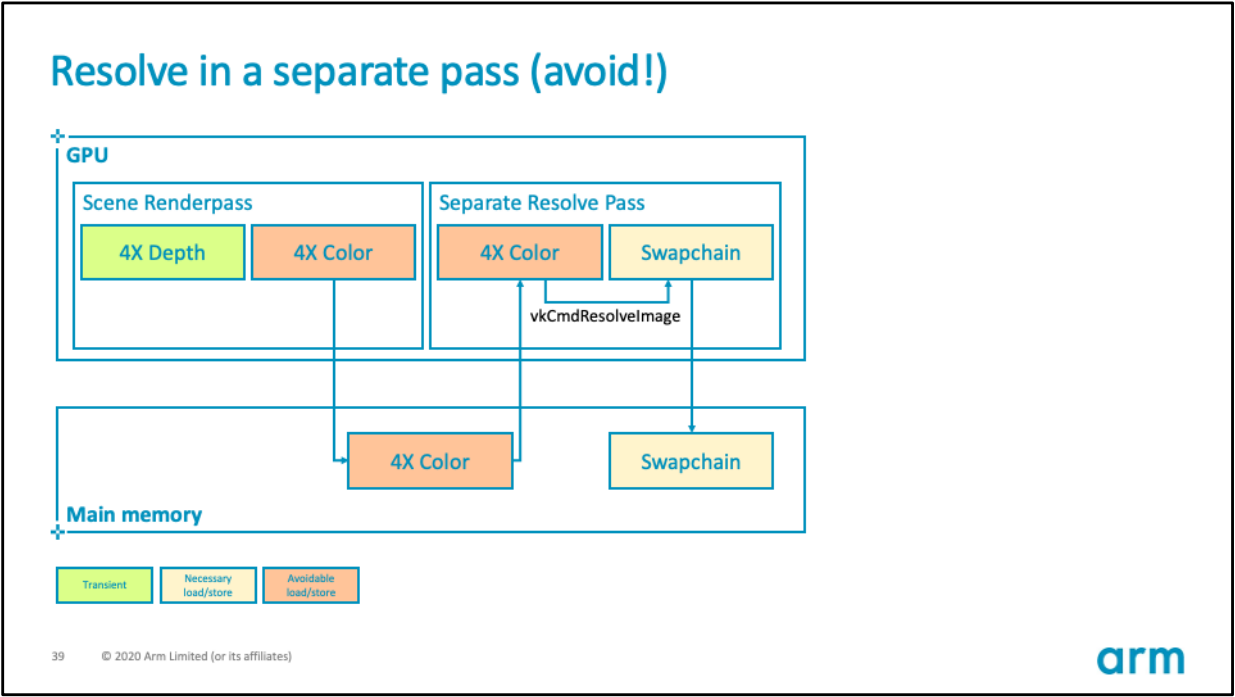

上:使用vkCmdResolveImage解析MSAA的錯誤示範;下:使用Tile內解析MSAA的正確示範。
使用subpass的loadOp和storeOp對MSAA解析進行優化之後,Vulkan的官方測試示例顯示可以減少261%的全局記憶體讀取、440%的全局記憶體寫入!!
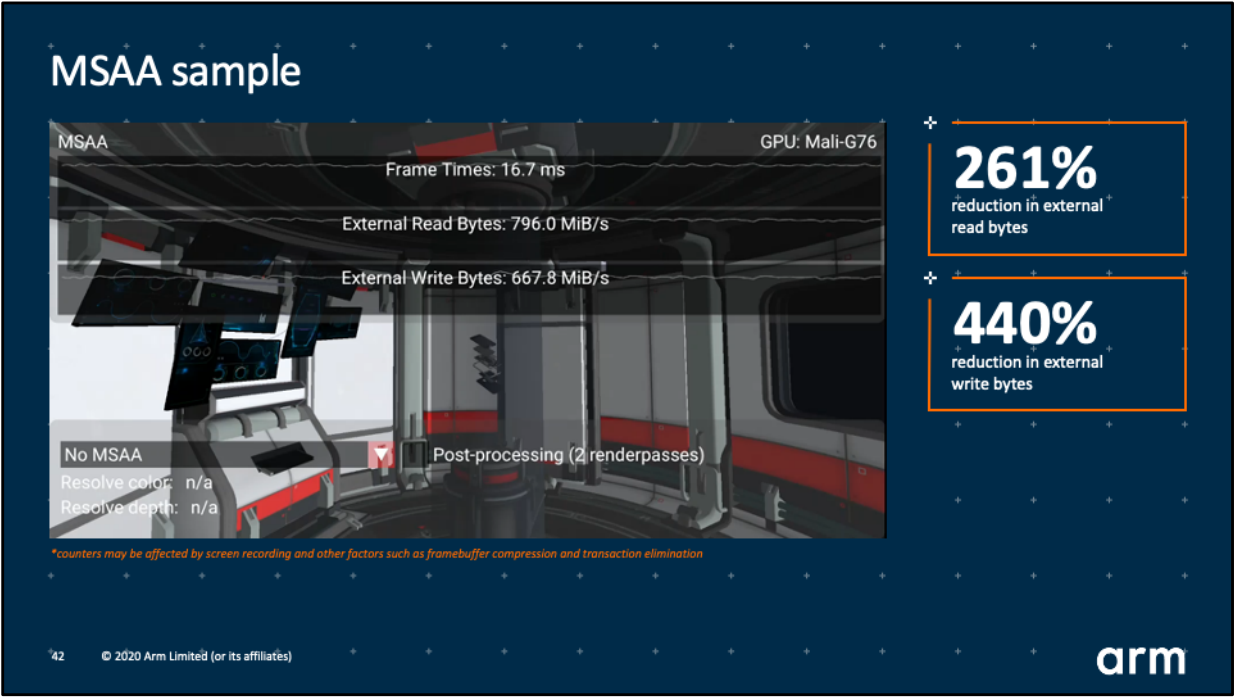
優化效果可見一斑!!還等什麼,儘管拿起subpass的有利武器對應用程式進行優化吧!!
更多說明參見Vulkan官方組織KhronosGroup的github:Appropriate use of render pass attachments。
有關UE對Subpass的封裝可參見:10.4.4.2 Subpass渲染。
12.4.14 Adaptive Scalable Texture Compression
Adaptive Scalable Texture Compression (ASTC)是Arm和AMD共同研發的一種紋理壓縮格式,不同於ETC和ETC2的固定塊尺寸(4×4),ASTC支援可變塊大小的壓縮,從而獲得靈活的更大壓縮率的紋理數據,降低GPU的頻寬和能耗。
ASTC雖然尚未成為OpenGL的標準格式,只是以擴展的形式存在,但目前已經廣泛地被主流GPU支援,可謂不是標準的的標準擴展。但在Vulkan中,ASTC已經是標準的特性了。具體地說,ASTC支援以下特性:
-
格式靈活。ASTC可以壓縮1到4個通道之間的數據,包括一個非相關通道,如RGB+A(相關RGB,非相關alpha)。並且塊大小可變,如4×4、5×4、6×5、10X5等。
Adreno A5X及以上的GPU晶片支援ASTC以下不同塊大小的格式(包含二維和三維):
-
ASTC_4X4
ASTC_5X4
-
ASTC_5X5
-
ASTC_6X5
-
ASTC_6X6
-
ASTC_8X5
-
ASTC_8X6
-
ASTC_8X8
-
ASTC_10X5
-
ASTC_10X6
-
ASTC_10X8
-
ASTC_10X10
-
ASTC_12X10
-
ASTC_12X12
-
ASTC_3X3X3
-
ASTC_4X3X3
-
ASTC_4X4X3
-
ASTC_4X4X4
-
ASTC_5X4X4
-
ASTC_5X5X4
-
ASTC_5X5X5
-
ASTC_6X5X5
-
ASTC_6X6X5
-
ASTC_6X6X6
-
-
靈活的比特率。ASTC在壓縮影像時提供了廣泛的比特率選擇,在0.89位和8位每texel (bpt)之間。比特率的選擇與顏色格式的選擇無關。而傳統的ETC等格式只能是整數的比特率。
-
高級格式支援。ASTC可以壓縮影像在低動態範圍(LDR)、LDR sRGB、高動態範圍(HDR)顏色空間,還可以壓縮3D體積紋理。
-
改善影像品質。儘管具有高度的格式靈活性,但在同等比特率下,ASTC在影像品質上的表現優於幾乎所有傳統的紋理壓縮格式(ETC2、PVRCT和BC等)。
-
格式矩陣全覆蓋。在ASTC尚未出現之前,傳統的紋理壓縮格式支援的顏色格式和比特率的組合相對較少,如下圖所示:
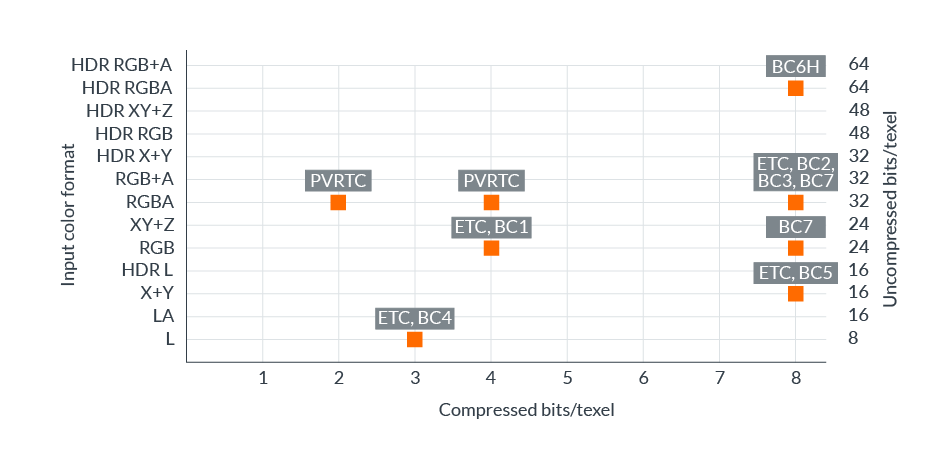
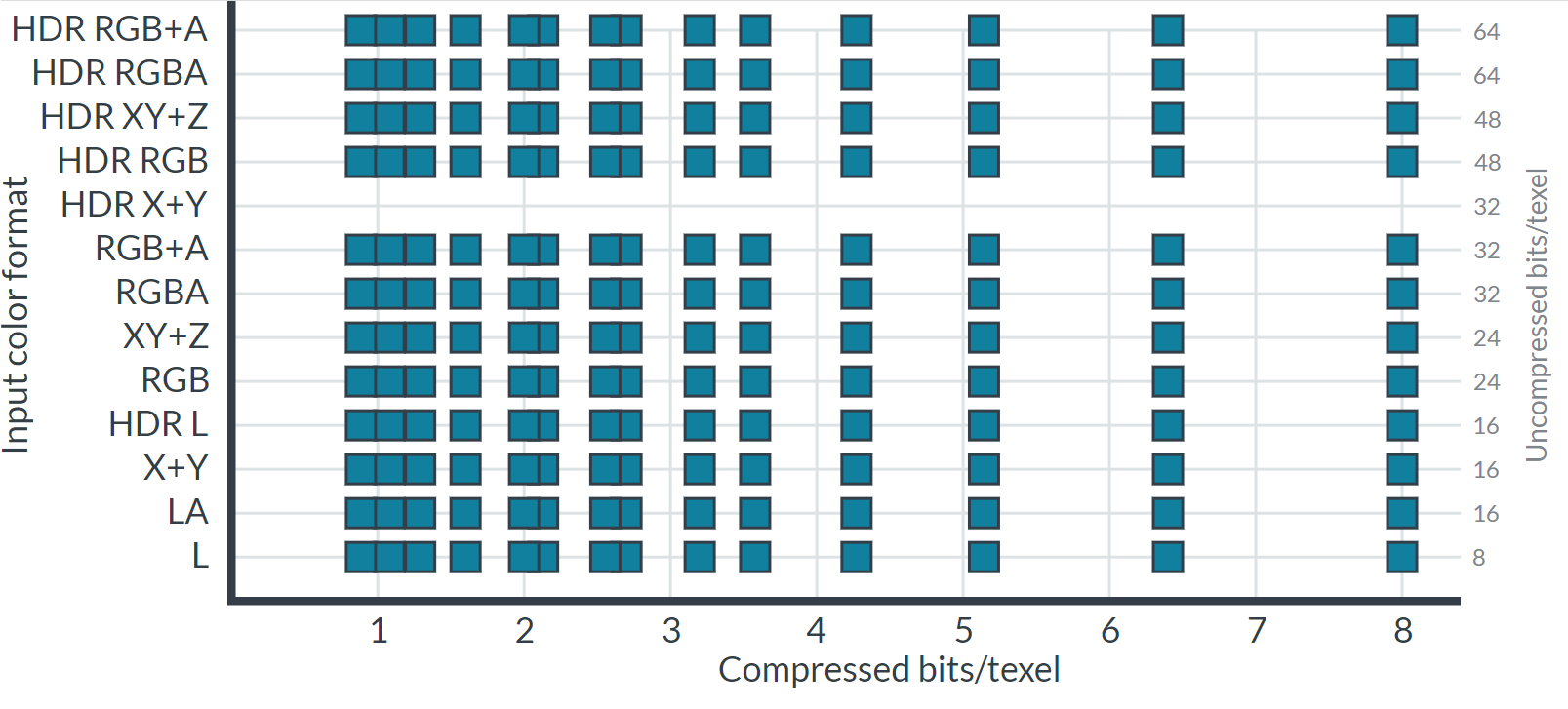
以上格式還受圖形API或作業系統限制,因此任何單一平台的壓縮選擇都非常有限。ASTC的出現解決了上述問題,幾乎實現了所需格式矩陣的完整覆蓋,為內容創建者提供了廣泛的比特率選擇。下圖顯示了可用的格式和比特率:


ASCT是如何達成上述目標的呢?答案就在於ASTC用了一種特殊的壓縮演算法和數據結構。ASTC的演算法技術要點和闡述如下:
-
塊壓縮
實時圖形的壓縮格式需要能夠快速有效地將隨機樣本轉換為紋理,因此對壓縮技術必須做到以下幾點:
- 僅給定一個取樣坐標,計算記憶體中數據的地址。
- 能夠在不解壓太多周圍數據的前提下解壓隨機取樣。
所有當代實時壓縮格式(包括ASTC)使用的標準解決方案,是將影像分割成固定大小的像素塊,然後每個塊被壓縮成固定數量的輸出位。這保證Shader以任意順序快速訪問texels,並具有良好的解壓成本。
ASTC中的2D Block footprints範圍從4×4 texels到12×12 texels,它們都被壓縮成128位輸出塊。通過將128位除以佔用空間中的像素數,便能得到格式比特率,這些比特率範圍從8 bpt(\(128 / (4\cdot4)\))到0.89 bpt(\(128 / (12\cdot12)\))。下面是不同比特率的畫質對比圖:

-
顏色端點(Color endpoint)
塊的顏色數據被編碼為兩個顏色端點之間的梯度。每個texel沿著梯度選擇一個位置,然後在解壓期間插值。ASTC支援16色端點編碼方案,稱為端點模式( endpoint mode)。端點模式的選項允許改變以下內容:
-
顏色通道的數量。 例如:亮度、亮度+alpha、rgb或rgba。
-
編碼方法。 例如:直接、基數+偏移、基數+比例或量化級別。
-
數據範圍。 例如:低動態範圍或高動態範圍。
允許逐塊選擇不同的端點模式和端點顏色BISE量化級別。
-
-
顏色分區(Color partition)
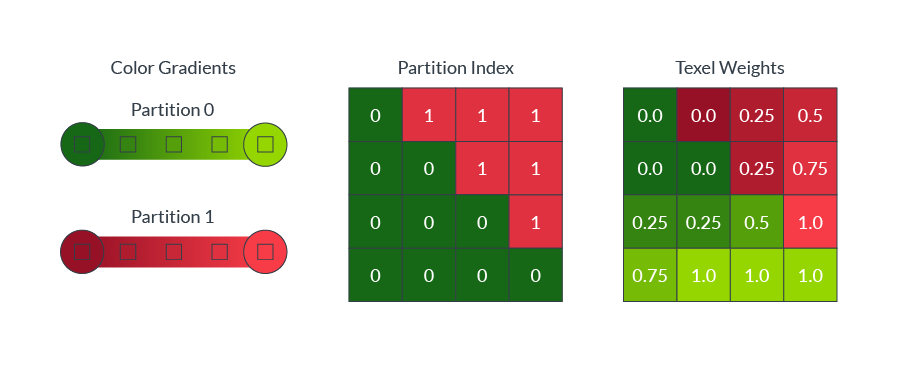
塊內的顏色通常是複雜的,單色漸變通常不能準確地捕捉塊內的所有顏色。例如,躺在綠色草地上的紅球,需要進行兩種顏色的劃分,如下圖所示:
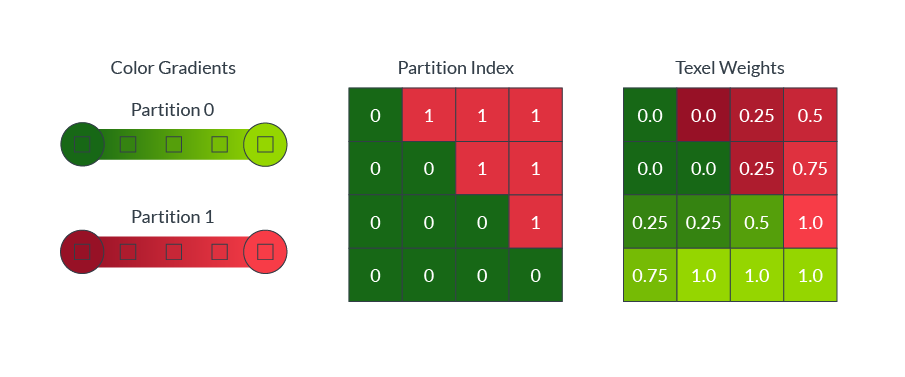
ASTC允許單個塊最多引用四個顏色梯度,稱為分區。為了解壓,每個texel被分配到一個單獨的分區。
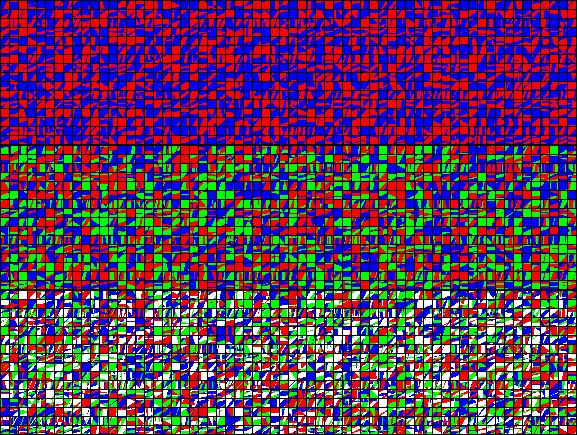
直接存儲每個texel的分區分配將需要大量的解壓縮硬體來存儲所有塊大小。 相反,ASTC使用分區索引作為seed值,以演算法生成一系列模式。壓縮過程為每個塊選擇最佳匹配的模式,然後塊只需要存儲最佳匹配模式的索引。下圖顯示了8 × 8塊大小的2個(影像頂部)、3個(影像中間)和4個(影像底部)分區生成的模式:
可以在每個塊的基礎上選擇分區的數量和分區索引,並且可以在每個分區上選擇不同的顏色端點模式。
-
顏色編碼
ASTC使用漸變來指定每個texel的顏色值。每個壓縮塊存儲漸變的端點顏色,以及每個像素的插值權重。在解壓過程中,每個像素的顏色值是根據每個像素的權重在兩個端點顏色之間插值生成的。下圖顯示了各種texel權重的插值:
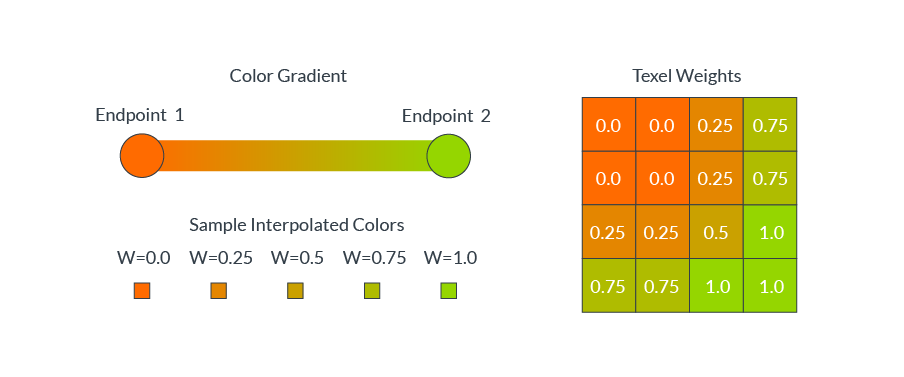
方塊通常包含複雜的顏色分布,例如一個紅色的球放在綠色的草地上。在這些情況下,單一的顏色梯度不能準確地代表所有不同的texel顏色值。 ASTC允許一個塊定義多達四個不同的顏色梯度,稱為分區(partition),並可以將每個texel分配到一個單獨的分區。下圖顯示了分區索引是如何為每個texel指定顏色漸變的(兩個分區,一個用於紅球像素,一個用於綠草像素):
-
存儲字元表(Storing alphabet)
儘管每個像素的顏色和權重值理論上是浮點值,但可以直接存儲實際值的位太少了。為了減小存儲大小,必須在壓縮期間對這些值進行量化。例如,如果對0.0到1.0範圍內的每個texel有一個浮點權重,可以選擇量化到5個值:0.0、0.25、0.5、0.75和1.0,再使用整數0-4來表示存儲中的這五個量化值。
一般情況下,如果選擇量化N層,需要能夠有效地存儲包含N個符號的字元表中的字元。一個N個符號表包含每個字元的log2(N)位資訊。如果有一個由5個可能的符號組成的字元表,那麼每個字元包含大約2.32位的資訊,但是簡單的二進位存儲需要四捨五入到3位,這浪費了22.3%的存儲容量。下圖表顯示了使用簡單的二進位編碼存儲任意N個符號字元表所浪費的位空間百分比:
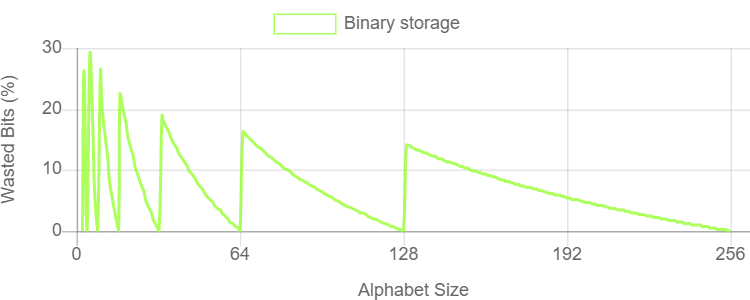
上述圖表顯示,對於大多數字元大小,使用整數位每個字元浪費大量的存儲容量。對於壓縮格式來說,效率是至關重要的,因此這是ASTC需要解決的問題。
一種解決方案是將量化級別四捨五入到2的下一次方,這樣就不用浪費額外的比特了。然而,這種解決方案迫使編碼器消耗了本可以在其它地方使用獲得更大收益的比特位,因此此方案降低了影像品質,並非最優解決方案。
-
五元和三元數(Quint and trit)
一個更有效的解決方案是將三個五元字元組合在一起,而不是將一個五元字元組合成三個位。五個字母中的三個字元有\(5^3=125\)個組合,包含6.97位資訊。我們可以以7位的形式存儲這三個quint字元,而存儲浪費僅為0.5%。
我們也可以用類似的方法構造一個三符號的字母表,稱為三個一組,並將五個一組的三個一組字元組合起來。每個字元組有\(3^5=243\)個組合,包含7.92位資訊。我們可以以8位的形式存儲這5個trit字元,而存儲浪費僅為1%。
-
有界整數序列編碼(Bounded Integer Sequence Encoding)
ASTC使用的有界整數序列編碼(Bounded Integer Sequence Encoding,BISE)允許使用最多256個符號的任意字元存儲字元序列。每一個字元大小都是用最節省空間的位、元和五元進行編碼的。
- 包含最多\(2^n-1\)個符號的字母表可以使用每個字元n位進行編碼。
- 包含最多\(3\cdot(2^n – 1)\)個符號的字母表可以使用每個字元用n位(m)和一個trit (t)進行編碼,並使用方程\((t \cdot 2^n) + m\)重建。
- 包含最多\(5\cdot(2^n – 1)\)個符號的字母表可以使用每個字元用n位(m)和一個quint (q)進行編碼,並使用方程\((q \cdot 2^n) + m\)重建。
當序列中的字元數不是3或5的倍數時,必須避免在序列末尾浪費存儲空間,因此在編碼上添加了另一個約束。如果序列中要編碼的最後幾個值為零,則已編碼位串的最後幾個位也必須為零。理想情況下,非零位的數目很容易計算,並且不依賴於先前編碼值的大小。這在壓縮期間很難妥當處理,但也是可能解決的。意味著不需要在位序列結束後存儲任何填充,因為我們可以安全地假設它們是零位。
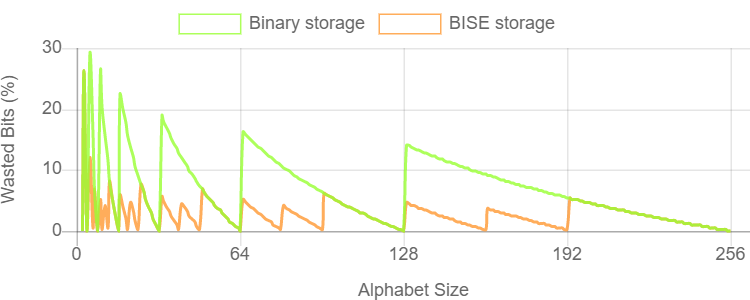
有了這個約束,通過對bit、trit和quint的智慧打包,BISE使用固定位數對N個符號字母表中的S個字元串進行編碼:
- S最大值為\(2^N – 1\) ,使用 \(N \cdot S\)位。
- S最大值為\(3\cdot2^N – 1\) ,使用 \(N\cdot S + \text{ceil}(8S / 5)\)位。
- S最大值為\(5\cdot2^N – 1\) ,使用 \(N\cdot S + \text{ceil}(7S / 3)\)位。
壓縮器選擇為所存儲的字母大小產生最小存儲空間的選項。一些使用二進位,一些使用bit和trit,還有一些使用bit和quint。下圖顯示了BISE存儲相對於二進位存儲的效率增益:







此外,在壓縮過程中,會為每個塊選擇最佳編碼,在計算texel權重值時,除了上述的BISE,還有雙平面權重(Dual-plane weights)演算法。
ASTC免費自由使用,容易集成,被眾多主流系統和硬體支援。支援ASTC需要以下OpenGL擴展:
GL_AMD_compressed_ATC_texture
GL_ANDROID_extension_pack_es31a
相比傳統的紋理壓縮格式(ETC、BC、PVRTC等),使用ASTC的壓縮效果非常明顯,畫質更貼近原圖,壓縮率更高:


左:原始法線貼圖;中:壓縮成ETC的效果;右:壓縮成ASTC的效果。
由此帶來的直觀收益就是佔用更少的記憶體、頻寬,每幀大約能減少24.4%的頻寬:

關於ASTC的更多詳情可參看Adaptive Scalable Texture Compression。
12.4.15 big.LITTLE Core
移動端CPU(注意不是GPU,如Qualcomm Keyo CPU)存在big.LITTLE的組合架構,最早由Arm提出。此架構同時存在big core和little core,big core為了高性能而優化,little core為了能量消耗而優化。
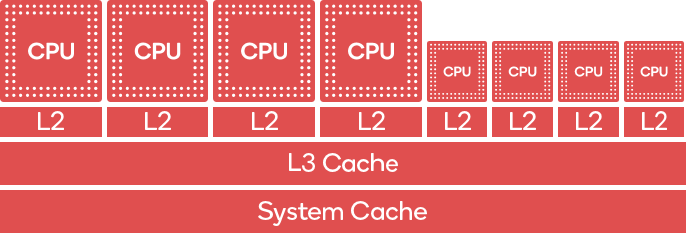
Qualcomm Keyo CPU的big.LITTLE架構。左邊4個是big core,執行性能高但耗電量較大,右邊4個是little core,執行性能較低但較省電。
big.LITTLE架構的特點如下:
- 通過將兩個非常不同的處理器組合在一個SoC中,以應對智慧設備在性能方面需求的變化。
- big.LITTLE軟體自動處理任務分配到適當的CPU核。作業系統直接感知系統中的高性能和高效率核心,並可以根據性能需求將每個任務動態分配到合適的核心。
理解以及如何使用這種架構的特性對於優化性能和功率效率至關重要,優化得好,將獲得更長的遊戲時間和遊戲的散熱。
為了提升big.LITTLE的效率,盡量優先使用little core。假設幀預期時間為16ms (60FPS),開發者可以使用工具(如Snapdragon Profiler)來識別任務,將其移至LITTLE core。例如,一款帶有布料模擬的遊戲,在big core上執行需要3毫秒,而在little core執行可能需要10毫秒。只要這個執行時間是可以接受的(本例的幀預算是16ms),應該被移到little core中,減少對big core的利用,提高電力效率。
移動端SoC製造廠商(如Qualcomm、Arm)通常提供了相關SDK和API給開發者指定任務在哪種類型的CPU核上運行,具體可參看:Controlling Task Execution。
12.4.16 其它技術要點
除了以上小節涉及的技術要點,實際上移動端晶片或圖形API還存在很多其它技術,比如SIMD、SIMT、Unified shader architecture(統一著色器架構,見下圖)、Scalar architecture(標量著色器架構)、Tripipe(下下圖)等等。更多技術細節可以閱讀筆者的另一篇關於GPU的文章:深入GPU硬體架構及運行機制。
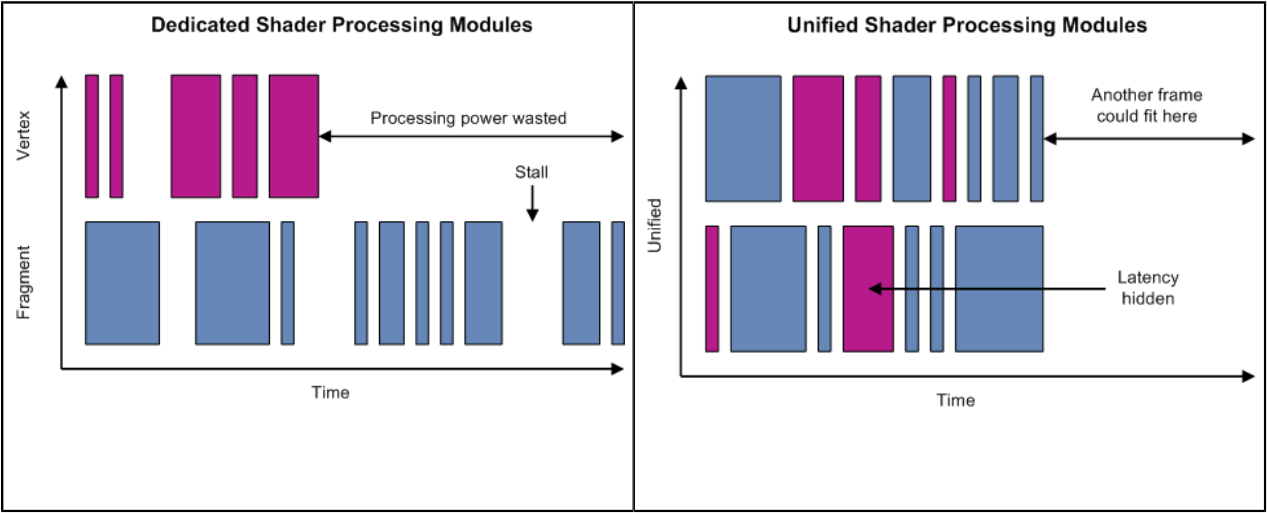
左:分離式著色器處理單元,右:同意著色器處理單元。可見後者的處理器基本處於滿負荷運行,從而減少等待和空載,提升整體運算能力。

Mali GPU中的Tripipe結構示意圖,包含3個運算單元、1個存取單元和1個紋理單元,擁有128bit頻寬,2倍FP64、4倍FP32、8倍FP16的操運算效率。
另外,OpenGL ES還有不少擴展可以提升性能,比如針對紋理子區域讀寫操作:
KHR_partial_update
EXT_buffer_age
此擴展允許調用者利用Backbuffer的時間指定多個方框繪製幀內容。此技術類似於TE,但不會寫數據到Tile緩衝區。
12.5 移動GPU架構和機制
本章將闡述移動端GPU的硬體架構和運行機制。
12.5.1 移動GPU概述
移動端GPU由於隨身性,需要考慮PPA三個指標,因此設計一款高性能的GPU異常困難,具有高度的挑戰性。目前主要有Qualcomm、Arm、Imagination Tech等GPU製作廠商,他們的代表作分別是Adreno、Mali、PowerVR。移動端的GPU通常集成在SoC之中,和CPU、記憶體等器件形成有機的硬體架構體系。
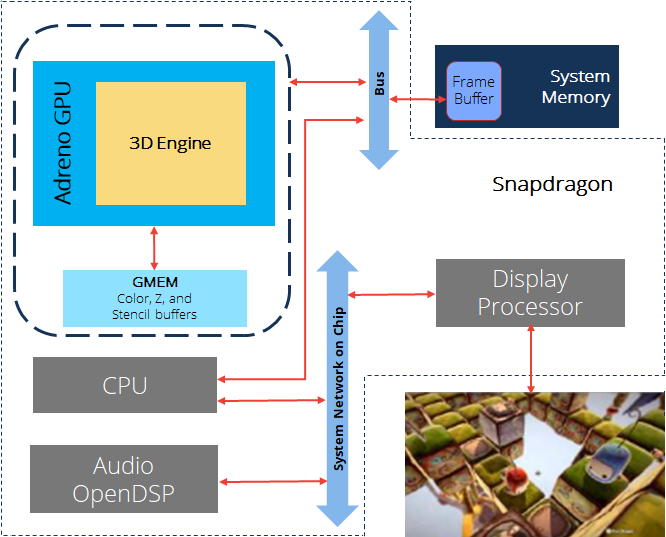
Snapdragon框架圖。包含了了CPU、Adreno GPU、記憶體等元件,通過Bus、Network等進行數據交互。
隨著時間推移,移動端硬體隨之發展,越來越多新的圖形API和渲染特性也被遷移到移動端,具體表現在:
-
主流GPU支援DX12、Vulkan1.2、OpenGL ES 3.2等圖形API,支援VRS、Mesh Shading、Ray Tracing、WaveMath等新的渲染特性。
-
GPU吞吐量和計算能力大幅提升,包含ALU、Texture、Memory等方面:
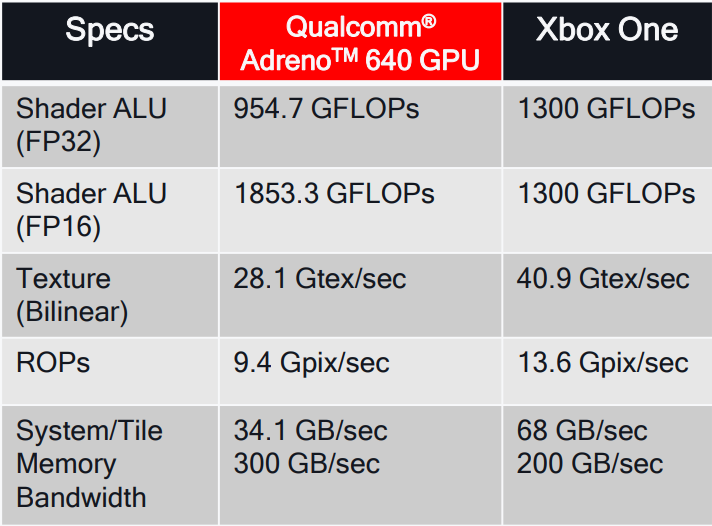
Qualcomm Adreno 640 GPU的性能一覽,右側是Xbox One的性能數據。
-
記憶體頻寬增加,能耗比提升。
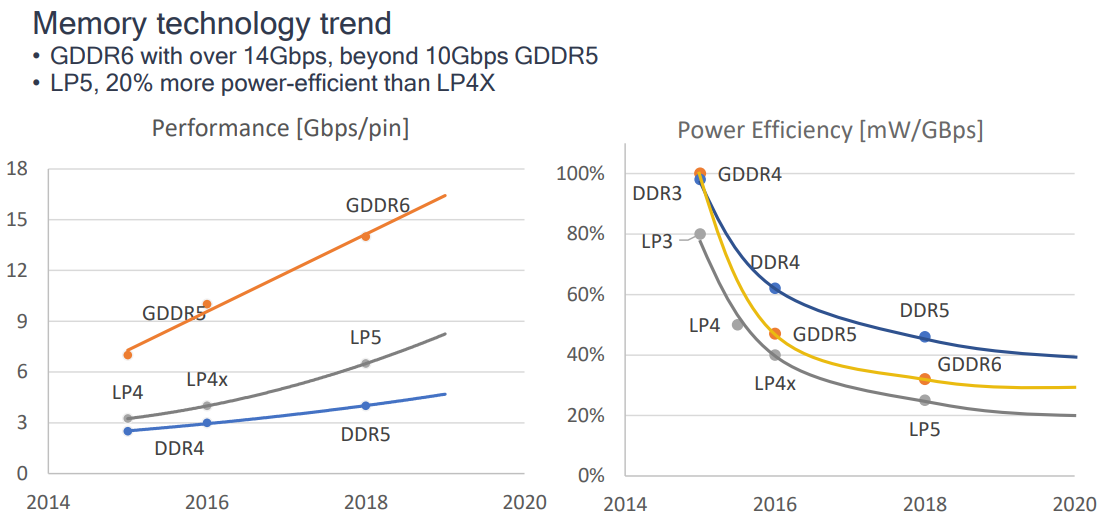
-
電量節省特性大量湧現。
- Render Target Compression, FP16 math ops, ASTC, Vulkan Subpasses。
- UBWC、AFBC、IDVS、PLS等。
-
移動端Soc被廣泛地應用於VR應用,並帶來了諸多專用優化技術。
-
Compute Shader能力的完善和提升,對OpenCL庫的支援趨於完善。
-
並行數量越來越多,吞吐量提升。
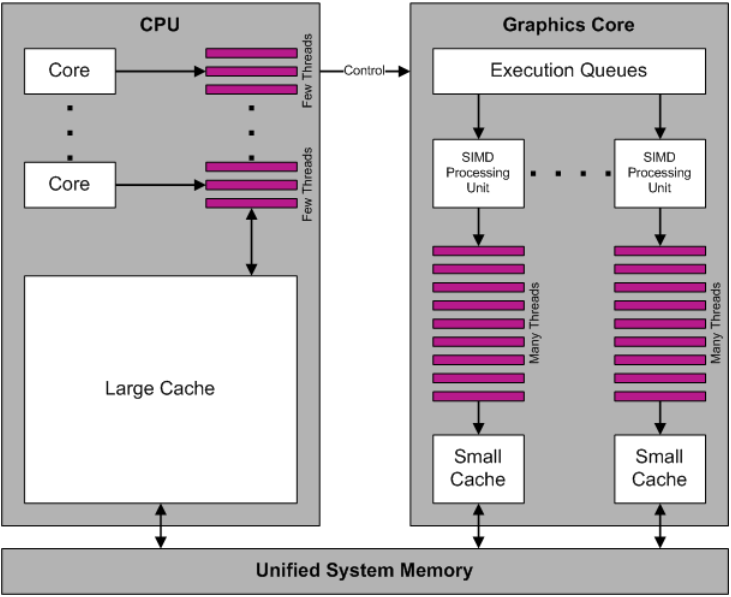
CPU和GPU運行示意圖,可知GPU快取小但擁有數量眾多的執行緒。



移動端GPU架構內的相關概念和名詞解析如下:
| 概念 | 全稱 | 解析 |
|---|---|---|
| AMBA | Advanced Microcontroller Bus Architecture | 高級微控制器匯流排架構 |
| AXI | AMBA Advanced eXtensible Interface | AMBA高級可擴展介面 |
| APB | AMBA Advanced Peripherial Bus | AMBA高級外圍匯流排 |
| ACE | AMBA AXI Coherency Extensions | AMBA AXI一致性擴展 |
| GPU | Graphics Processing Unit | 圖形處理單元 |
| VPU | Video Processing Unit | 影片處理單元 |
| DPU | Display Processing Unit | 顯示處理單元 |
| ISA | Instruction Set Architecture | 指令集架構 |
| SIMD | Single Instruction Multiple Data | 單指令多數據 |
| ISP | Image Synthesis Processor | 合成影像處理器 |
| TSP | Texture and Shading Processor | 紋理和著色處理器 |
12.5.2 移動GPU運行機制
由於每個GPU廠商、每個系列、每代產品的運行機制都可能存在不同,本節就以Mali GPU為例,闡述移動端的GPU運行機制。首先說明一下Arm Mali T880 GPU硬體架構的參數,如下:
-
16個Shader Core(SC)。
-
Tile尺寸為16×16(內部4×4~32×32)。
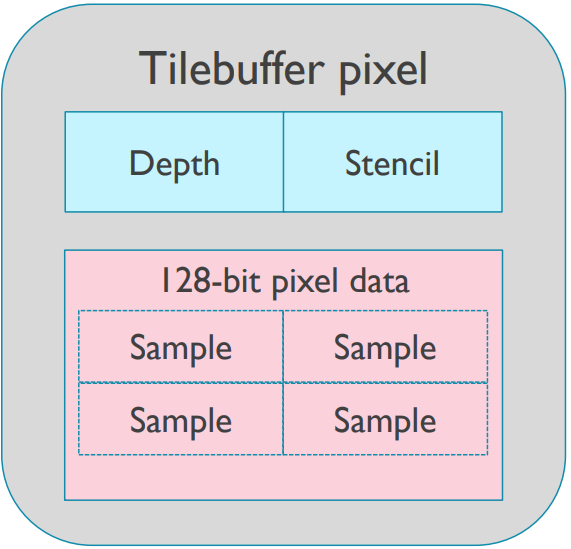
- 可存儲深度模板緩衝,128位像素數據。
- 每像素擁有16位元組,原始位訪問(Raw bit access)。
-
支援GLES3.2,Vulkan 1.0,CL 1.2,DX 11.2。
-
4x、8x、16x的MSAA。

Arm Mali T880 GPU硬體架構示意圖及其功能描述。
對於Mali GPU,驅動程式通過Job Manager(作業管理器)提交繪製任務,由Job Manager向GPU的繪製硬體創建並提交任務,它們通過內部連接元件交互。

應用程式、驅動程式、GPU、DPU等各個層級的交互簡化後的示意圖如下:
應用程式、驅動程式、GPU等交互示意圖。其中eglSwapBuffers表示幀結束,App會屬性繪製命令給驅動程式,驅動程式會編排任務給GPU,GPU繪製完成之後提交結果給DPU。注意它們各個層級之間存在著延時。
首先考察應用層和驅動層的交互。應用程式在調用圖形API(如OpenGL ES)時,驅動程式會創建對應的資源架構圖:
GPU內部存在以下幾種Job(作業)類型:
| 作業名稱 | 縮寫 | 描述 |
|---|---|---|
| Vertex Job | V | 執行一組頂點的頂點著色器。 |
| Tiler Job | T | Tiling Unit(分塊單元,固定功能)分拆轉換後的圖元到覆蓋的分塊。 |
| Fragment Job | F | 運行在所有Tile的單一渲染目標的工作。 |
| Job Chain | – | 作業鏈。 |
以下是GPU作業鏈的其中一種情形:

作業鏈示意圖。其中作業之間存在依賴關係(箭頭所示),只有前序任務完成了,才行執行下一個作業。
CPU、GPU的交互示意圖如下,其中CPU通過APB提交任務給GPU,GPU內的Job Manager通過AXI存取共享記憶體,而CPU也可以通過AXI存取共享記憶體。
GPU內的Job Manager創建和分配任務示意圖如下:

Job Mananger運行示意圖。圖中分配了3個頂點作業、1個分塊作業和2個著色作業。其中分塊作業依賴於頂點作業。
對於Shader Core而言,Mali的結構是Tripipe,是統一著色器架構,可以執行VS或PS:
更進一步地,頂點作業運行示意圖如下。頂點執行緒不會寫入tile緩衝區,但會直接訪問主記憶體,頂點任務包含了4n個頂點。
片元作業示意圖如下:
Fragment Work分為Front-End、Tripipe、Back-End三個階段。成功經過光柵化、Early-Z、FPK的像素會由Fragment Thread Creator創建執行緒(以Quad為單位,即2×2個執行緒),進入Tripipe著色,然後進入Late-Z、混合,最後寫入Tile記憶體。
但是,不是所有移動端GPU的運行機制都跟Mali的一模一樣,比如PowerVR的就會諸多不同點:
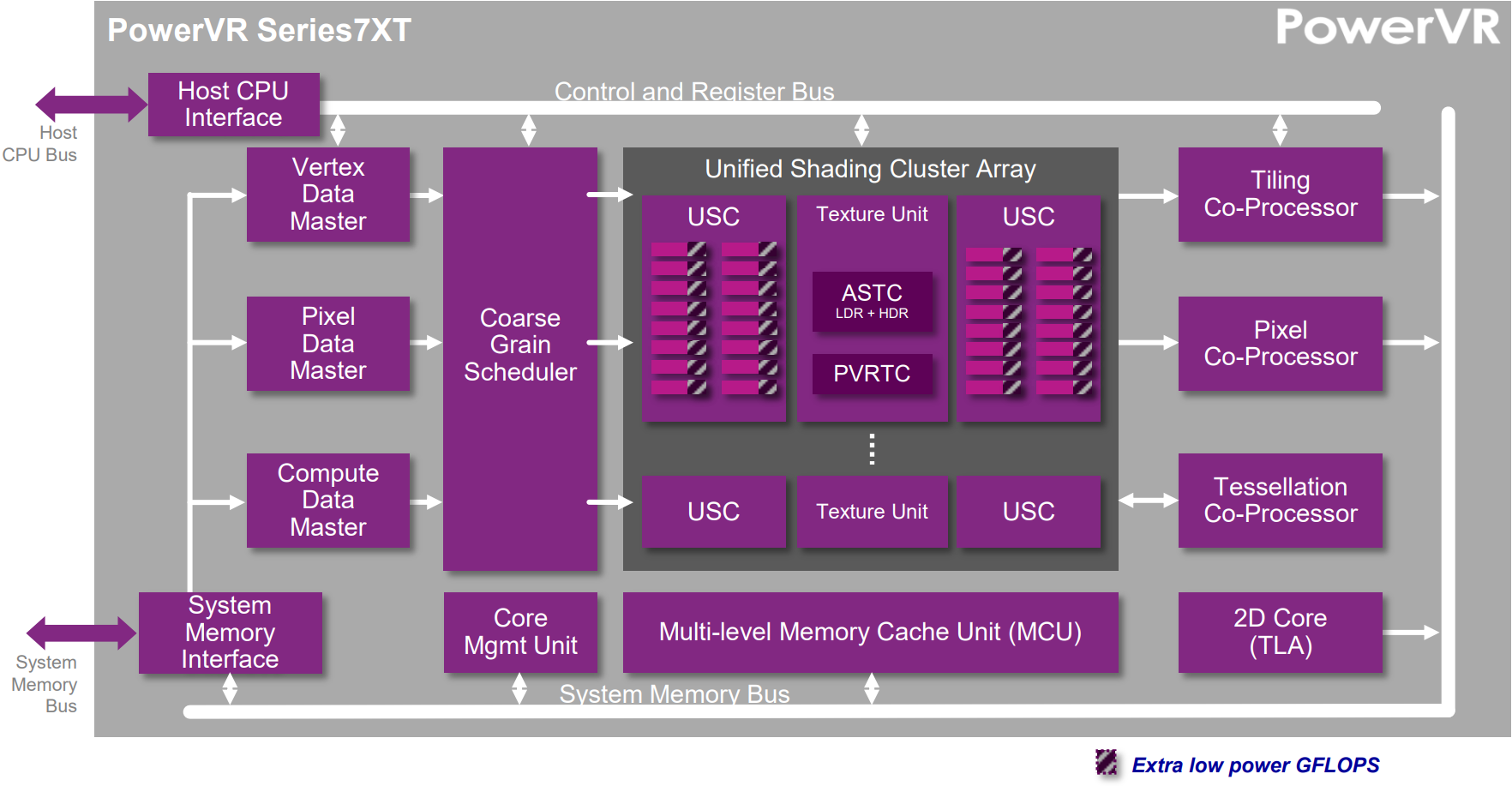
PowerVR Series 7XT架構示意圖。
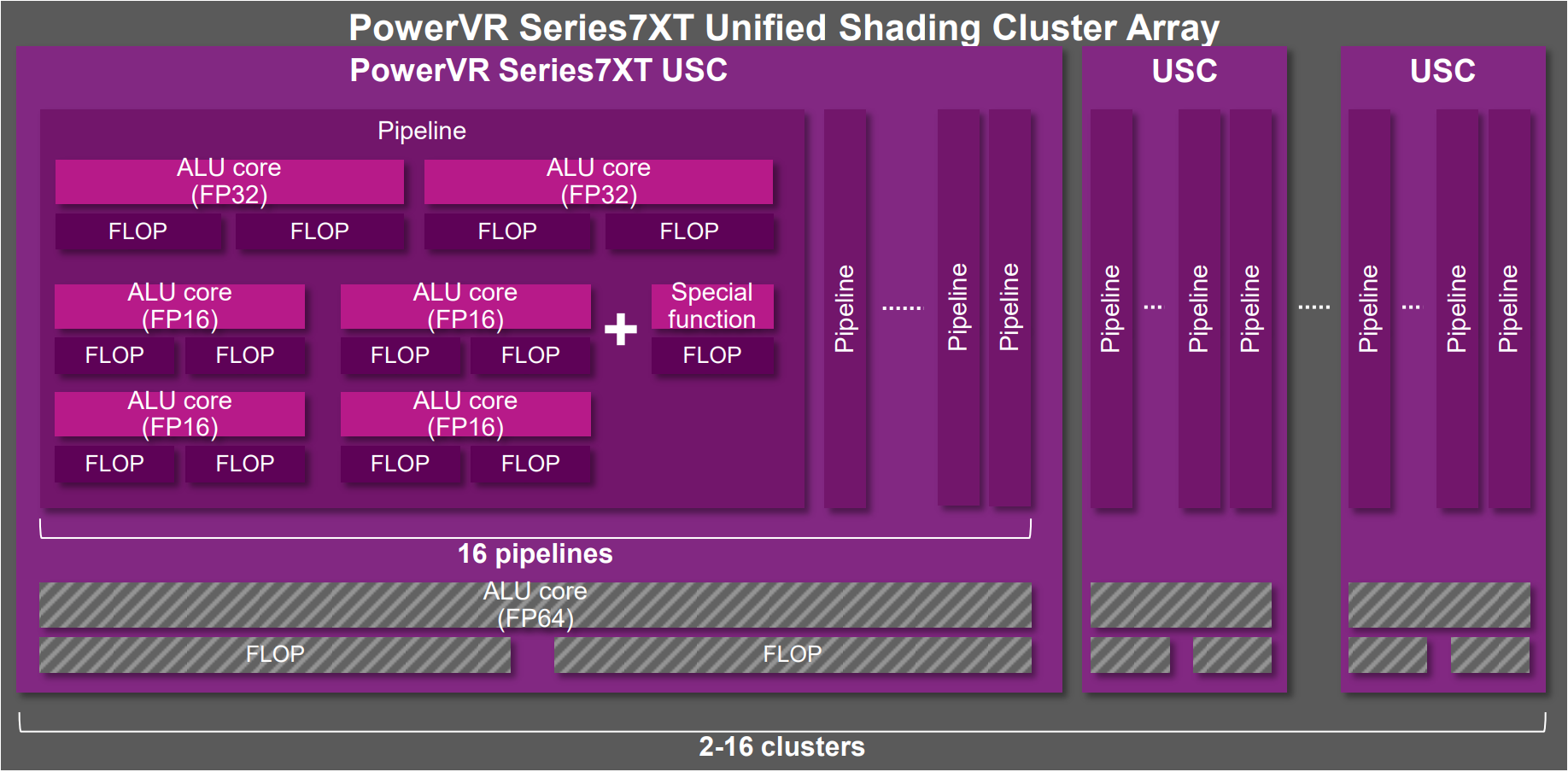
PowerVR Series 7XT統一著色器簇組架構圖。
更多PowerVR的介紹可參見:
- PowerVR Series5 Architecture Guide for Developers
- PowerVR Graphics – Latest Developments and Future Plans
12.5.3 並行、卡頓和延時
隨著摩爾定律的放緩,現代移動端的SoC朝著多核高並行的方向發展,應用程式能否利用多核性能提升並行效率,很大程式上決定了它的品質和用戶體驗。
和並行效率相反,卡頓和延時是實時應用(如遊戲)的天敵。卡頓意味著幀率低,應用程式運行不夠流暢;延時則意味著操作不能及時響應,降低產品的用戶體驗,甚至會導致用戶嚴重流失。
無論是在PC端還是移動端,渲染管線需要處理的場景越來越複雜,加上多執行緒等特性,因此或多或少存在著等待、卡頓(Stall)等現象,由此導致了延時(Latency)。這種現象在TB(D)R盛行的移動端渲染管線中尤為明顯。
造成卡頓和延時的原因有客觀和主觀。客觀的原因指多執行緒的協同等待、同步,驅動程式的優化,GPU內部執行機制的良性優化等。而主觀方面是指那些沒有使用符合特定渲染機制的介面、標記、狀態或資源,這類是可以避免和優化的。
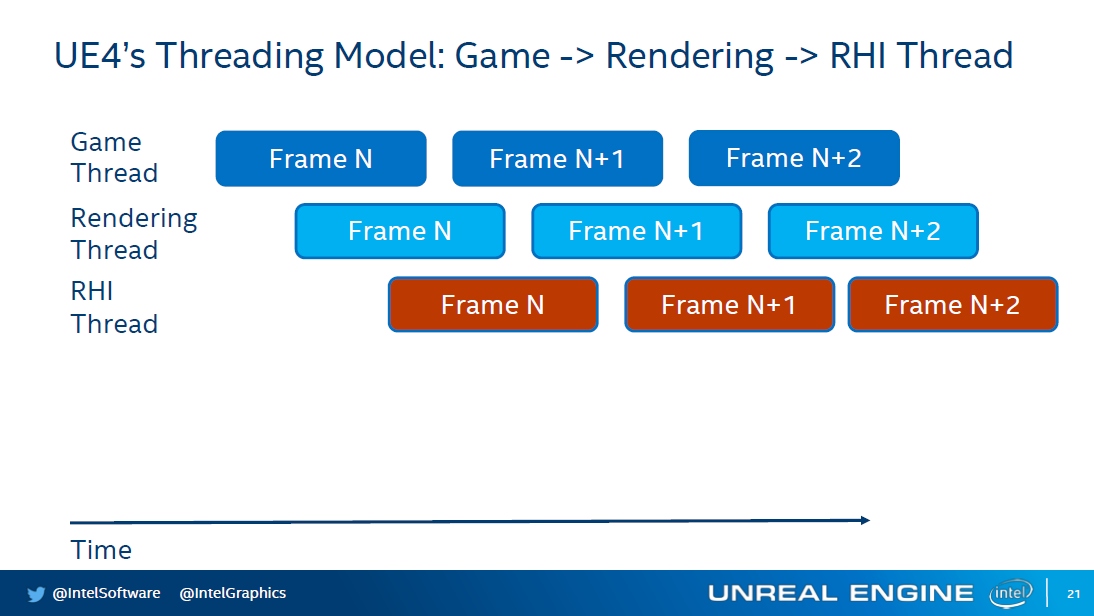
UE存在遊戲執行緒、渲染執行緒、RHI執行緒,後面的執行緒通常會比前面的執行緒延時一些,它們之間還存在同步和等待,防止前面的執行緒領先太多時間。

應用程式、驅動程式、GPU、顯示器之間的延時示意圖,下層會比上層落後一段時間。
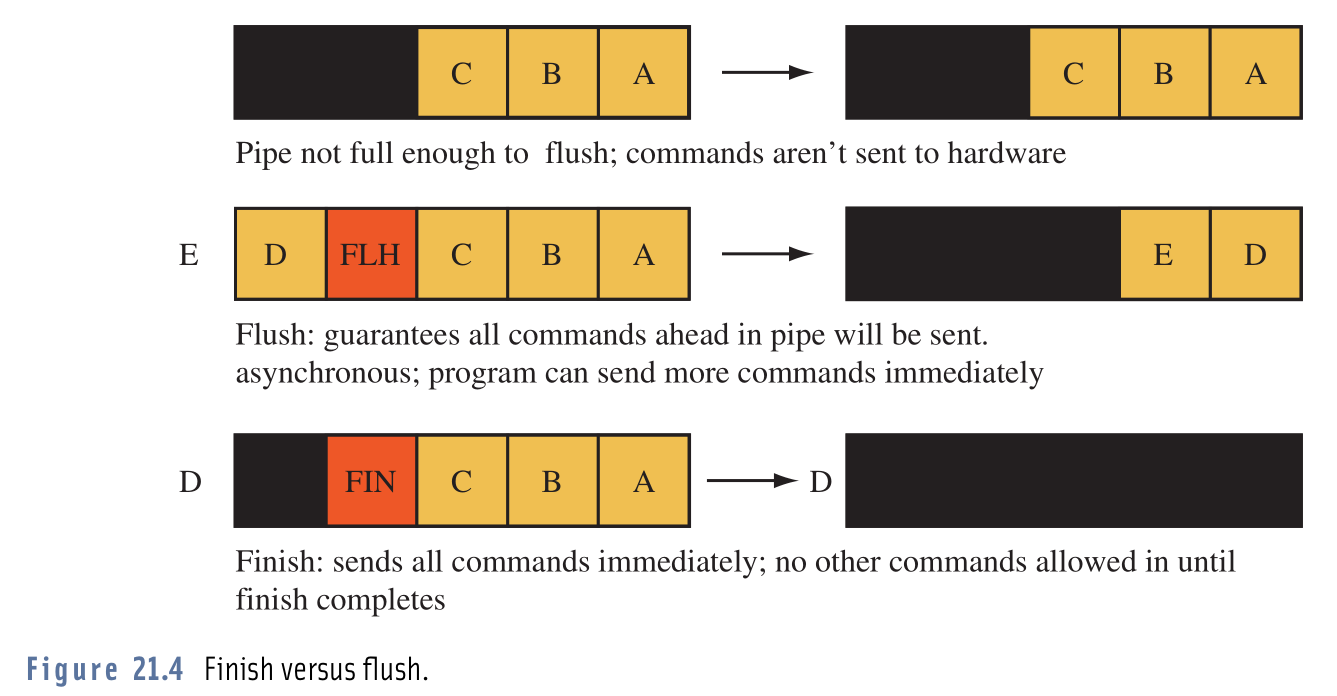
OpenGL的glFinish和glFlush執行示意圖。其中glFlush調用之後,不一定會立即刷新渲染指令到GPU,只有當驅動器的渲染命令緩衝區滿了才會,因此也可能導致延時。
移動端GPU的TB(D)R較普通的做法是將Binning Pass和Rendering Pass放在不同的幀處理,以提升並行效率,但也會導致延時:
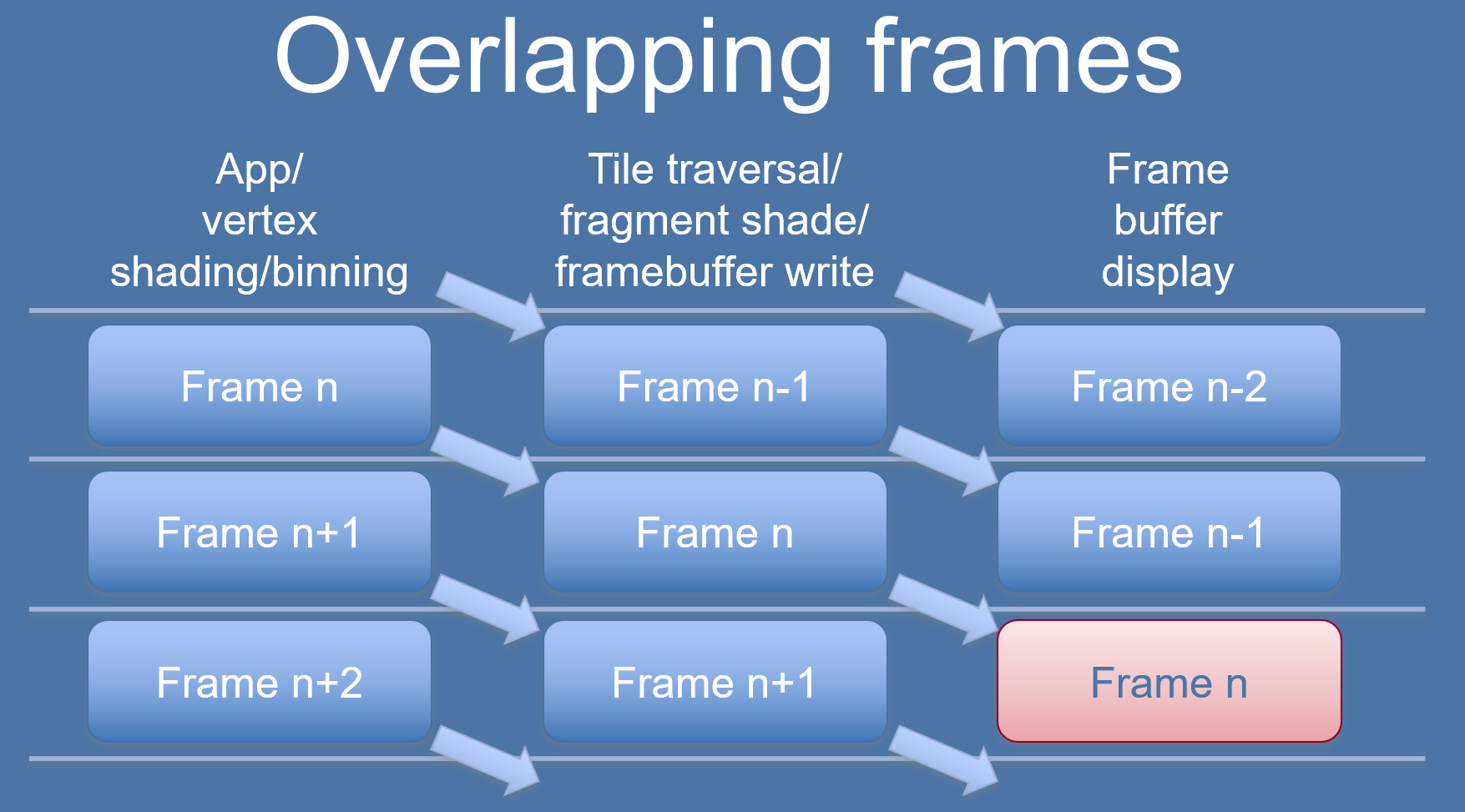
TBR架構中的Binning、Rendering錯幀處理示意圖。
以上是完美錯幀處理的情況,如果有以下情形之一,則會打亂TBR的執行節奏,導致更嚴重的Stall和延時:
-
Binning依賴上一幀的數據或資源。
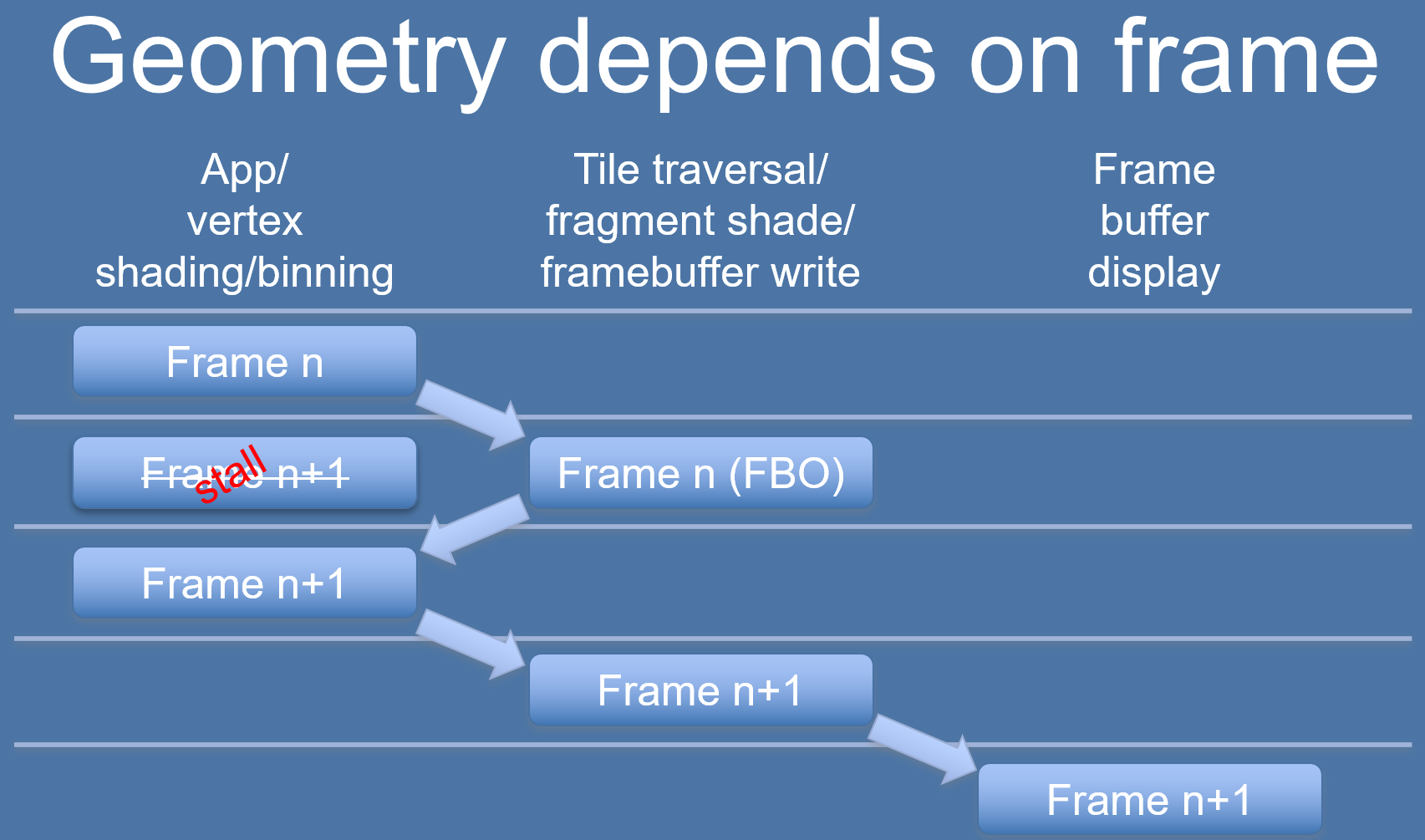
n+1幀的binning需要依賴n幀的Rendering渲染結果,所以不能和n幀的Rendering Pass並行處理,只能延時到下一幀。
這種情況可以通過延時使用解決,比如N幀的binning使用N-1幀的Rendering結果。下圖是實時環境立體圖的優化案例:
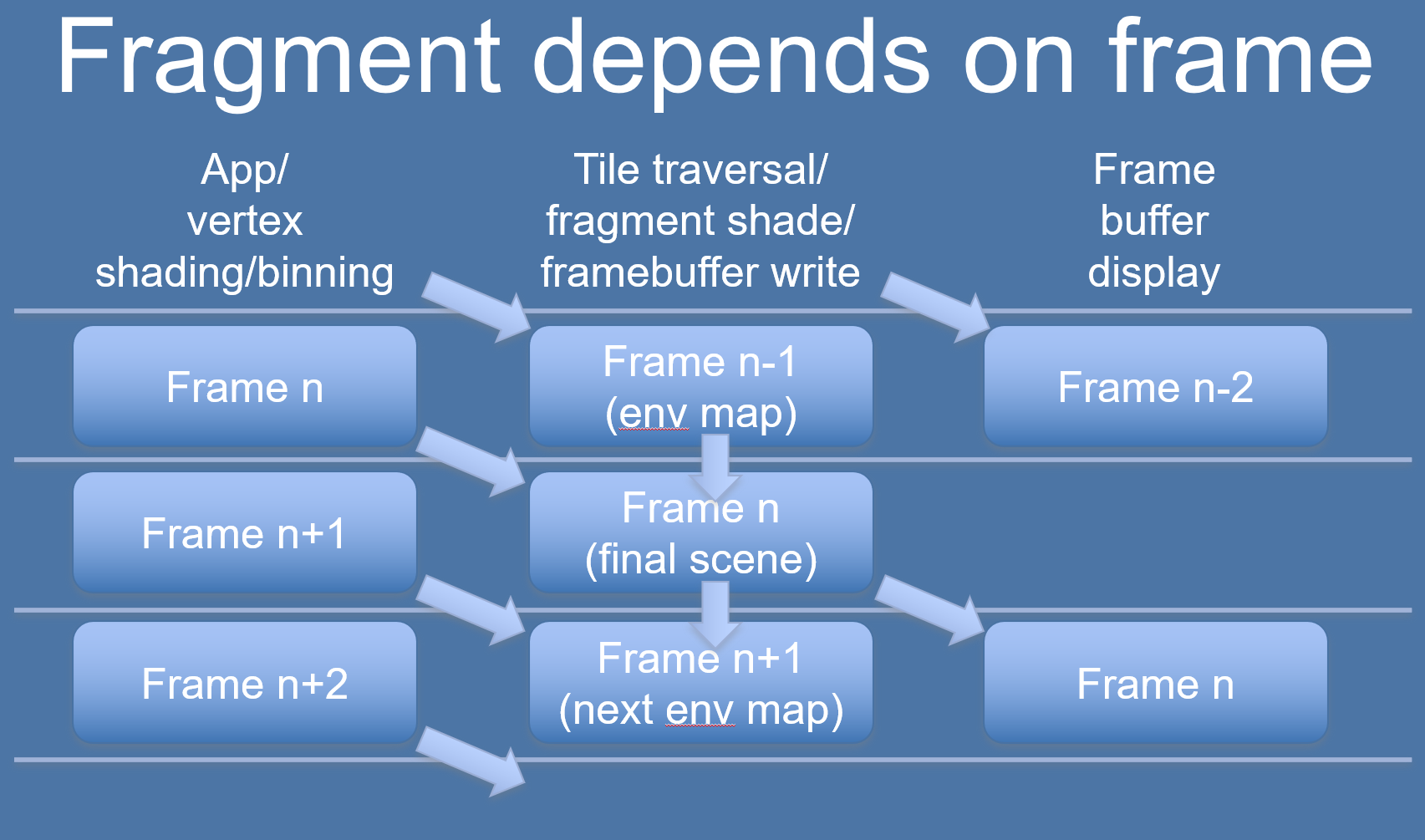
-
在提交之後、渲染使用之前,要修改數據。例如:
- 像素著色器計算並寫入數據到一個幀緩衝對象,使用結果生成位移。
- 從CPU寫入紋理,使用它進行渲染,然後再次更新紋理,然後渲染下一幀;像素著色器在紋理更新完成之前不會執行。


Vulkan等現代圖形API存在Subpass機制,Subpass可以並行處理(Overlap),也可以指定數據依賴:
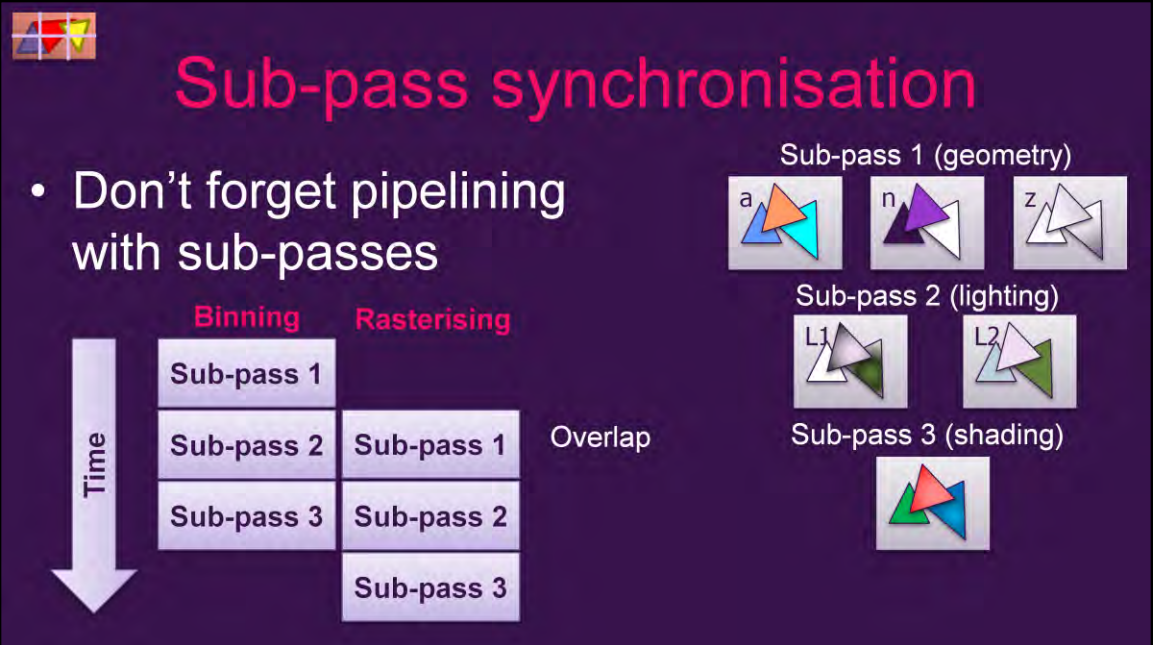

上:subpass的overlap機制i;下:subpass內部和之間的數據依賴。
使用Vulkan、Metal、DX12等現代圖形API可以精確指定渲染管線屏障(Barrier)的等待階段,例如下圖使用了默認的PipelineBarrier,會導致Vertex、Fragment處理存在較多的空閑或等待,浪費GPU時間周期:

通過修改屏障需要等待的源階段和目標階段,可以緩解這類Stall,提升著色器單元的利用率:

Pipeline Barrier的具體優化示例如下:
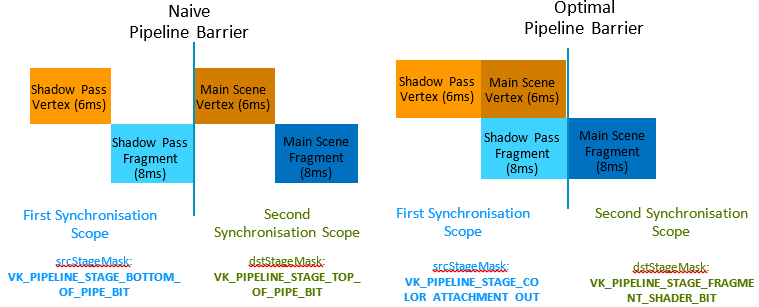
利用Vulkan的Pipeline Barrier優化各個Pass之間的等待階段,可以減少Stall和延時。圖中從28ms下降到22ms。
PowerVR的TBDR架構,會在本幀所有圖元處理完Binning數據,才開始渲染階段,這也許會導致更嚴重的延時。
除了以上所述的情況會導致延時,還有GPU內部的一些執行情況也會,比如GPU指令組之間存在依賴關係:
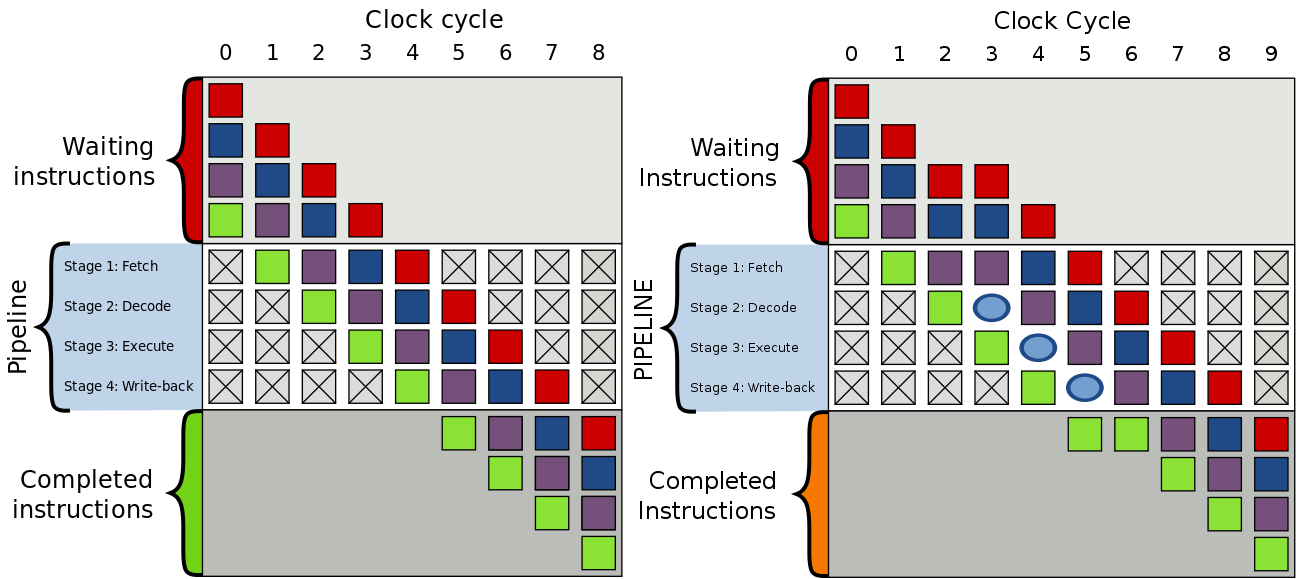
左:GPU指令組正常執行,沒有等待的情況;右:GPU指令組被加入了氣泡(bubble),導致了延時。
氣泡(bubble)的產生是為了解決GPU指令組之間的數據依賴:
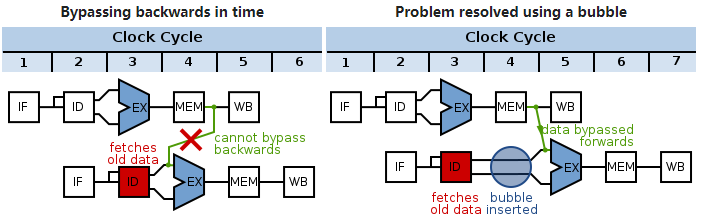
左:下組指令依賴上組數據的寫入,如果不處理就會獲得舊的數據;右:在下組指令插入氣泡,延遲一個時鐘周期以保證獲取最新的數據。
Shader中的if和for等動態分支循環語句會降低GPU計算單元利用率,拉長它們運行指令的時間:

訪問記憶體的指令也會使GPU計算單元產生Stall,延長計算時間:
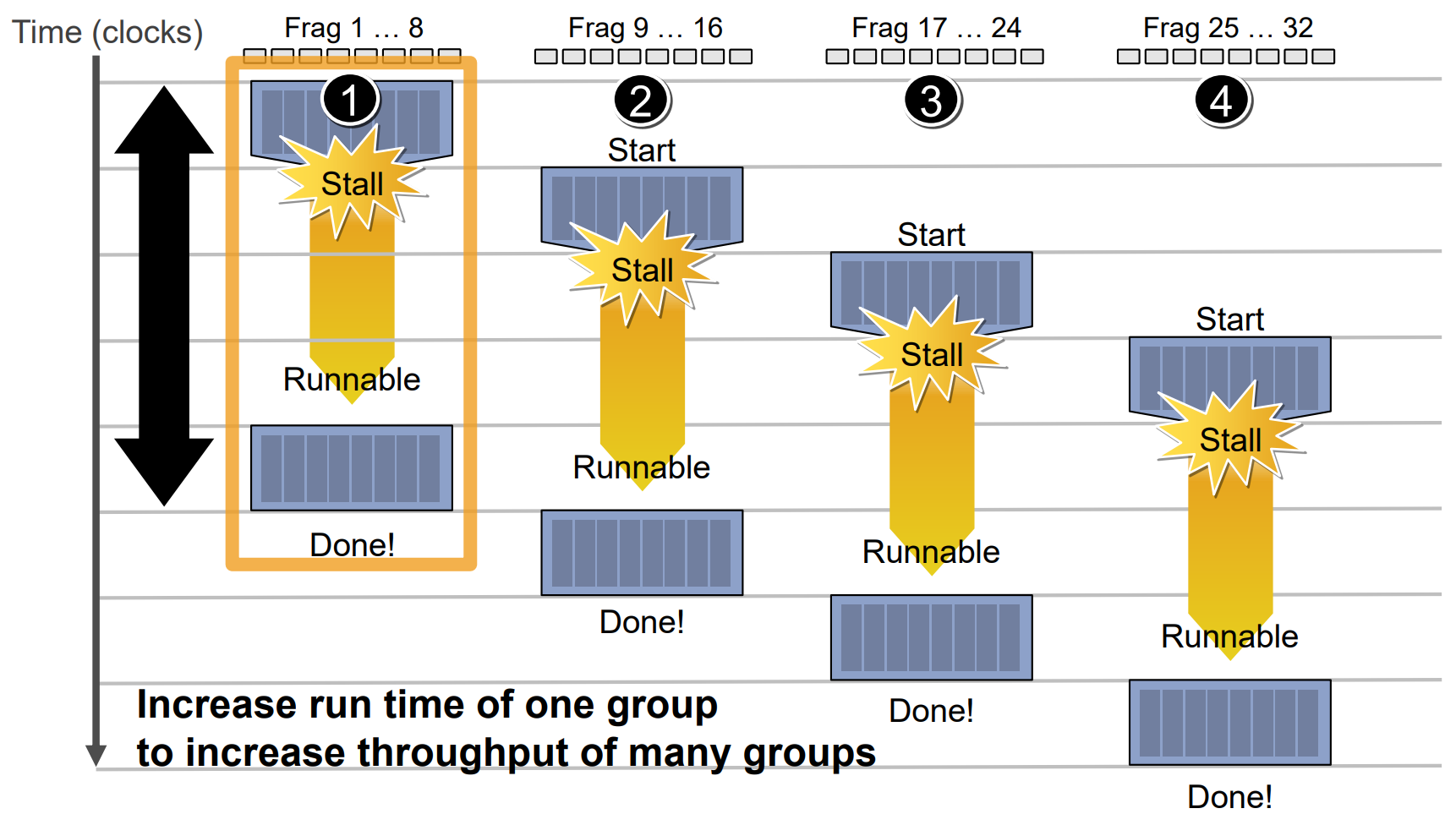
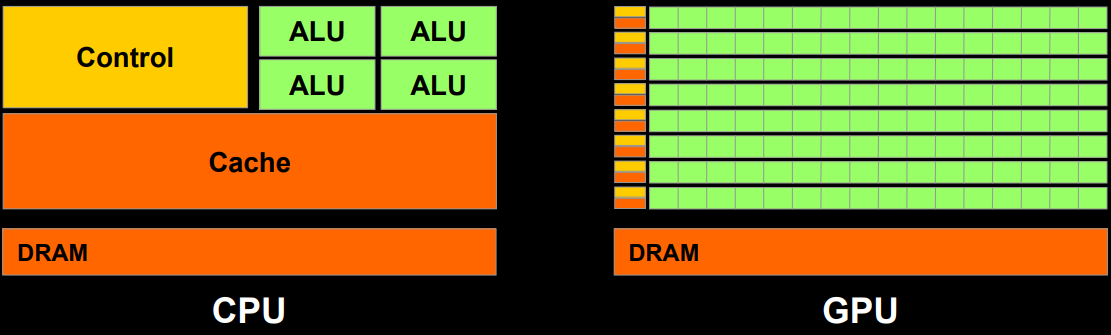
不同於CPU的低延時低吞吐率,GPU天生為了高並行和高吞吐率而設計,但與此同時快取容量小,Cache命中率低,延時較高:
因此,如果GPU數據結構設計得不好,會極大降低Cache命中率,從而增加計算單元的卡頓和延時。GPU的執行緒編排器(Thread Schdule)通常會考慮數據關聯性,保持同個執行緒組的執行緒在同一個快取行:
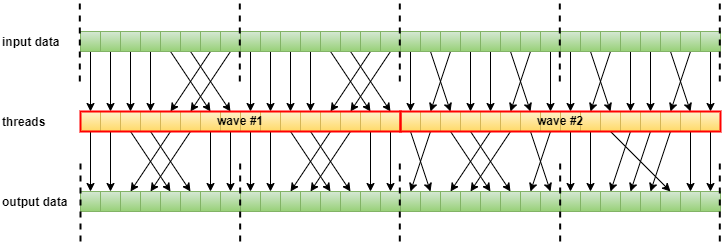
尺寸為16的Wave運行示意圖。其中虛線表示執行緒組之間不能跨界存取數據,以提高執行緒組內部訪問數據的快取命中率。
除上述情況之外,如果系統或應用程式使用了雙緩衝、三緩衝、垂直同步等機制,也會引入一定的延時。
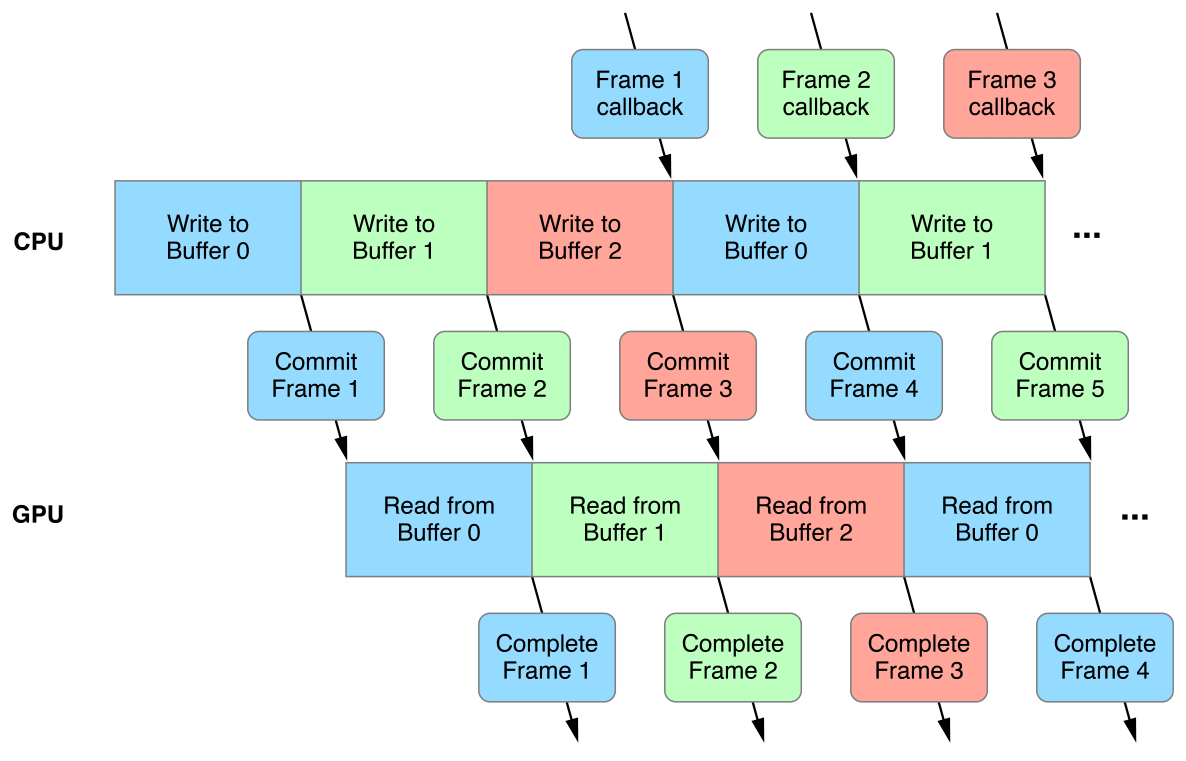
三緩衝執行機制示意圖。
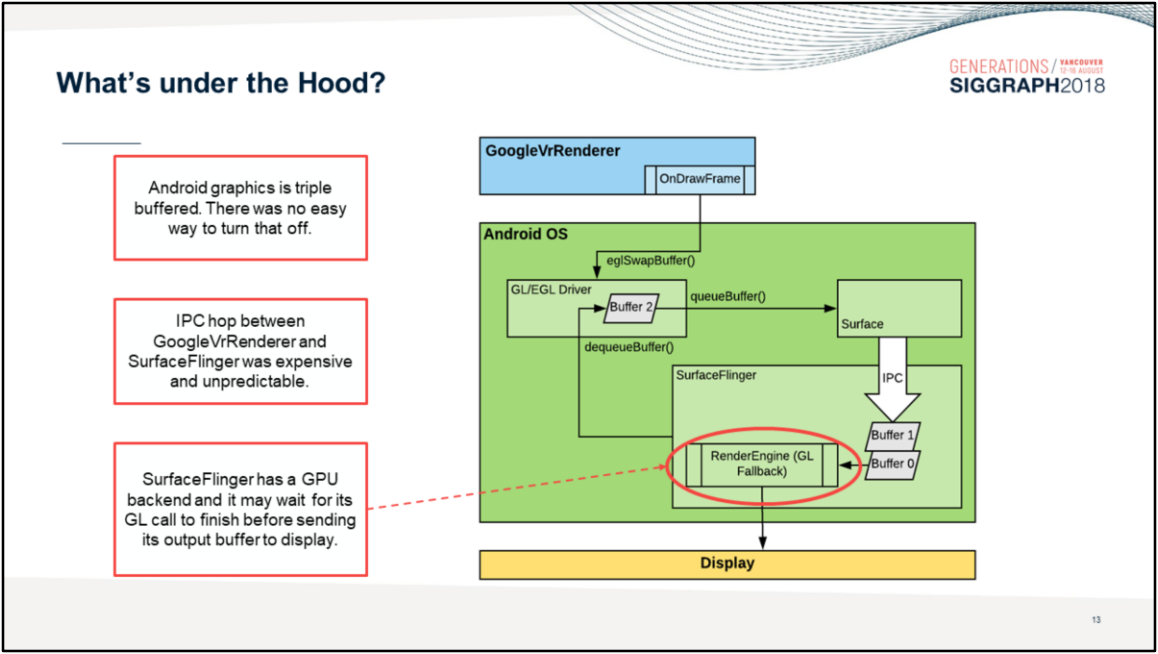
Android系統渲染模組使用了多層級封裝和三緩衝機制,使得畫面總是延遲3幀:
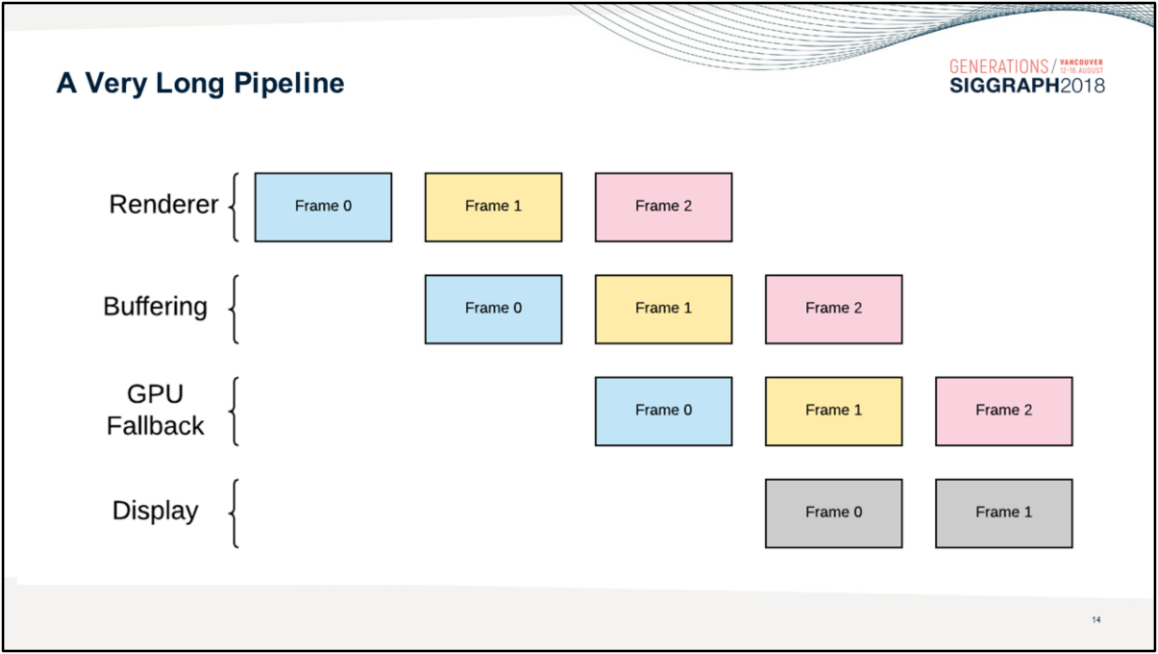
相反,善用Async Compute、Copy Engine、Graphic Pipeline等部位的並行機制,利用RDG的自動處理資源分配和依賴,利用子資源(subresource)和別名資源(aliasied resource)的特性,合併屏障等操作,可以減少Pass之間、Pass內部的等待和延時,提升並行效率。

Async Compute、Copy Engine、Graphic Pipeline的並行運行案例。

別名資源運行機制示意圖,其中資源A和D分別在不同時間段佔用了同一塊記憶體區域。在使用RDG時,別名資源可以節省超過50%的已使用資源分配空間,即便它們會給渲染系統添加額外的資源管理複雜性。
總之,從CPU的App層的邏輯更新、渲染指令生成、圖形API的調用和提交,橫跨驅動層、系統層、GPU內部,到最終的顯示器呈現,都可能存在各種各樣的依賴、等待、卡頓和延時等問題。這就要求我們統攬全局,甄別整條渲染管線的瓶頸,對症下藥,才能使我們的程式高效、流暢、即時地運行。
UE4官方文檔針對延時給了一些建議和優化措施,詳見Low Latency Frame Syncing。
- 未完待續
團隊招員
部落客所在的團隊正在用UE4開發一種全新的沉浸式體驗的產品,急需各路賢士加入,共謀宏圖大業。目前急招以下職位:
- UE邏輯開發。
- UE引擎程式。
- UE圖形渲染。
- TA(技術向、美術向)。
要求:
- 紮實的技術基礎。
- 高度的技術熱情。
- 良好的自驅力。
- 良好的溝通協作能力。
- 有UE使用經驗或移動端開發經驗更佳。
有意向或想了解更多的請添加部落客微信:81079389(註明部落格園求職),或者發簡歷到部落客郵箱:81079389#qq.com(#換成@)。
靜待各路英雄豪傑相會。
特別說明
- 感謝所有參考文獻的作者,部分圖片來自參考文獻和網路,侵刪。
- 本系列文章為筆者原創,只發表在部落格園上,歡迎分享本文鏈接,但未經同意,不允許轉載!
- 系列文章,未完待續,完整目錄請戳內容綱目。
- 系列文章,未完待續,完整目錄請戳內容綱目。
- 系列文章,未完待續,完整目錄請戳內容綱目。
參考文獻
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Mobile Rendering
- Qualcomm® Adreno™ GPU
- PowerVR Developer Documentation
- Arm Mali GPU Best Practices Developer Guide
- Arm Mali GPU Graphics and Gaming Development
- Moving Mobile Graphics
- GDC Vault
- Siggraph Conference Content
- GameDev Best Practices
- Accelerating Mobile XR
- Frequently Asked Questions
- Google Developer Contributes Universal Bandwidth Compression To Freedreno Driver
- Using pipeline barriers efficiently
- Optimized pixel-projected reflections for planar reflectors
- UE4畫面表現移動端較PC端差異及最小化差異的分享
- Deferred Shading in Unity URP
- 移動遊戲性能優化通用技法
- 深入GPU硬體架構及運行機制
- Adaptive Performance in Call of Duty Mobile
- Jet Set Vulkan : Reflecting on the move to Vulkan
- Vulkan Best Practices – Memory limits with Vulkan on Mali GPUs
- A Year in a Fortnite
- The Challenges of Porting Traha to Vulkan
- L2M – Binding and Format Optimization
- Adreno Best Practices
- 移動設備GPU架構知識匯總
- Mali GPU Architectures
- Cyclic Redundancy Check
- Arm Guide for Unreal Engine
- Arm Virtual Reality
- Best Practices for VR on Unreal Engine
- Optimizing Assets for Mobile VR
- Arm® Guide for Unreal Engine 4 Optimizing Mobile Gaming Graphics
- Adaptive Scalable Texture Compression
- Tile-Based Rendering
- Understanding Render Passes
- Lighting for Mobile Platforms
- Frame Pacing for Mobile Devices
- ARM Mali GPU. Midgard Architecture
- ARM』s Mali Midgard Architecture Explored
- [Unite Seoul 2019] Mali GPU Architecture and Mobile Studio
- Killing Pixels – A New Optimization for Shading on ARM Mali GPUs
- Qualcomm’s Quad-Core Snapdragon S4 (APQ8064/Adreno 320) Performance Preview
- Low Resolution Z Buffer support on Turnip
- Render Graph與現代圖形API
- Hidden Surface Removal Efficiency
- Unreal Engine 4: Mobile Graphics on ARM CPU and GPU Architecture
- Low Latency Frame Syncing
- Qualcomm® Snapdragon™ Mobile Platform OpenCL General Programming and Optimization
- Qualcomm Announces Snapdragon 865 and 765(G): 5G For All in 2020, All The Details
- Introduction to PowerVR for Developers
- PowerVR Series5 Architecture Guide for Developers
- PowerVR Graphics – Latest Developments and Future Plans
- PowerVR virtualization: a critical feature for automotive GPUs
- PowerVR Performance Recommendations
- PowerVR Low Level GLSL Optimisation
- Mobile GPU approaches to power efficiency
- Processing Architecture for Power Efficiency and Performance
- opengl: glFlush() vs. glFinish()
- Cramming Software onto Mobile GPUs
- Vulkan on Mobile Done Right
- Triple Buffering
- Asynchronous Shaders
- Why Talking About Render Graphs
- NVIDIA Variable Rate Shading
- Introduction to compute shaders
- Introduction to GPU Architecture
- An Introduction to Modern GPU Architecture
- Understanding GPU caches
- Transitioning from OpenGL to Vulkan
- Next Generation OpenGL Becomes Vulkan: Additional Details Released
- Bringing Fortnite to Mobile with Vulkan and OpenGL ES
- Appropriate use of render pass attachments
- Preparing Android for XR


