🏆【Alibaba中間件技術系列】「RocketMQ技術專題」幫你梳理RocketMQ或Kafka的選擇理由以及二者PK
- 2021 年 11 月 12 日
- 筆記
- 【技術專區-Alibaba】
前提背景
大家都知道,市面上有許多開源的MQ,例如,RocketMQ、Kafka、RabbitMQ等等,現在Pulsar也開始發光,今天我們談談筆者最常用的RocketMQ和Kafka,想必大家早就知道二者之間的特點以及區別,但是在實際場景中,二者的選取有可能會范迷惑,那麼今天筆者就帶領大家分析一下二者之間的區別,以及選取標準吧!
架構對比
RocketMQ的架構
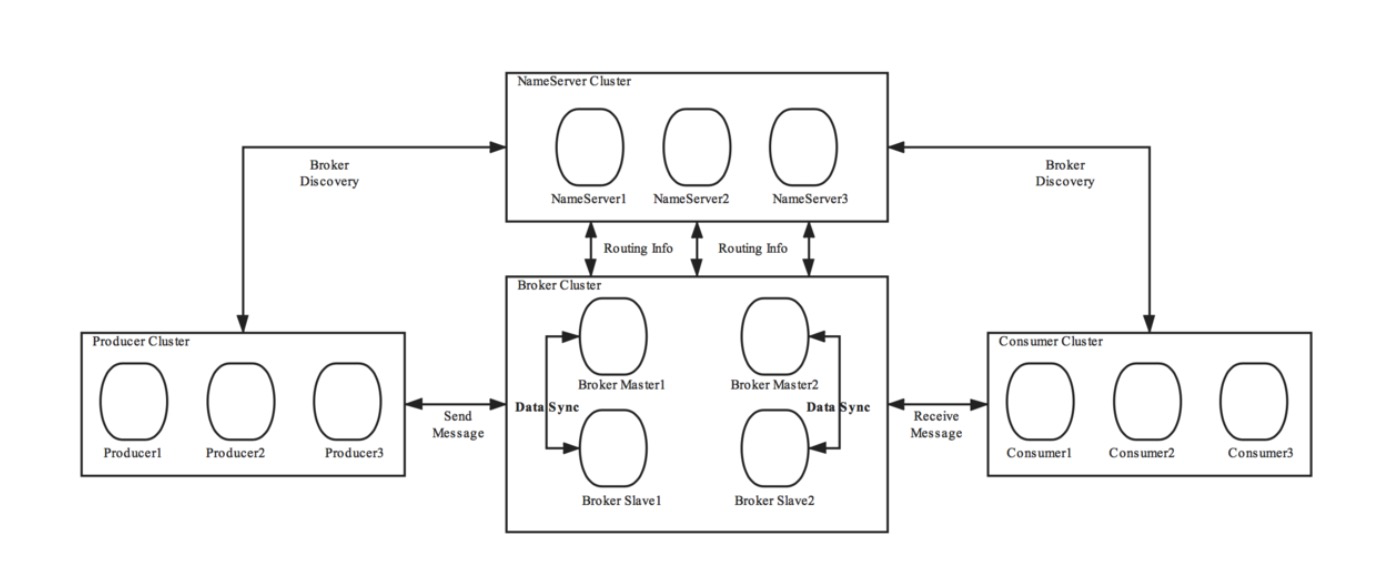
RocketMQ由NameServer、Broker、Consumer、Producer組成,NameServer之間互不通訊,Broker會向所有的nameServer註冊,通過心跳判斷broker是否存活,producer和consumer 通過nameserver就知道broker上有哪些topic。
Kafka的架構
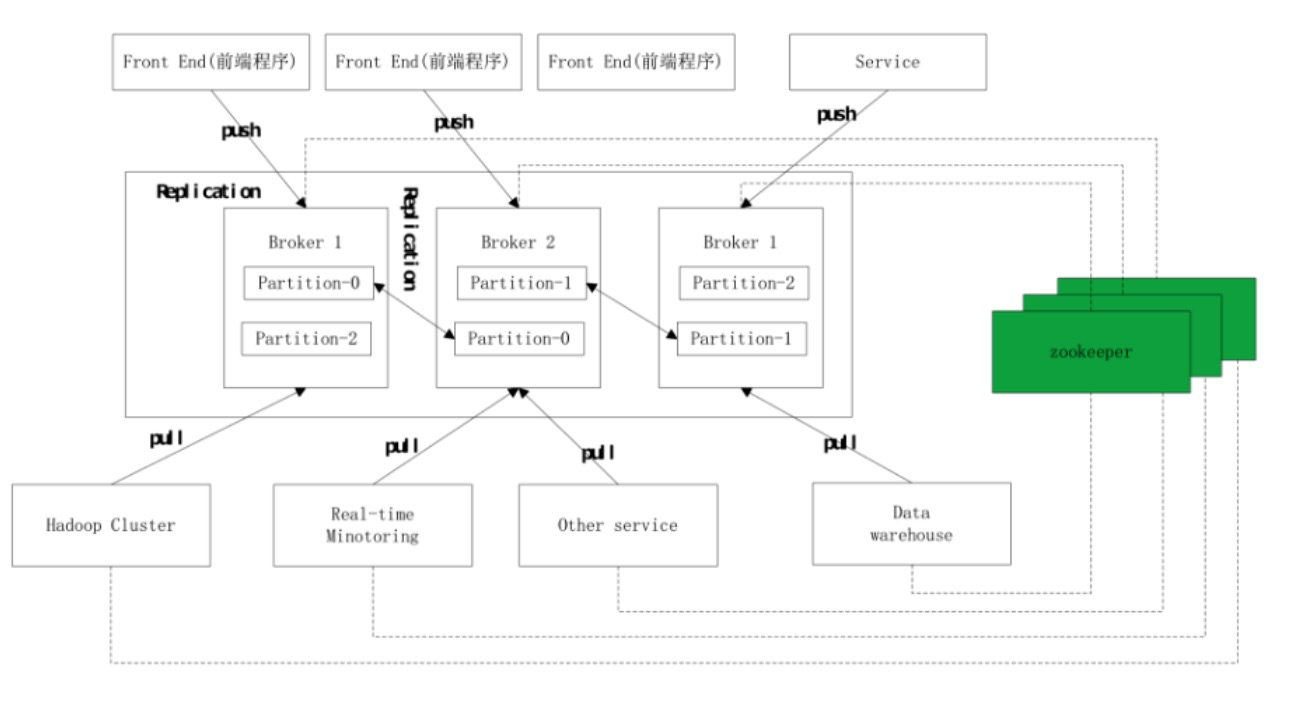
Kafka的元數據資訊都是保存在Zookeeper,新版本部分已經存放到了Kafka內部了,由Broker、Zookeeper、Producer、Consumer組成。
Broker對比
主從架構模型差異:
維度不同
-
Kafka的master/slave是基於partition(分區)維度的,而RocketMQ是基於Broker維度的;
- Kafka的master/slave是可以切換的(主要依靠於Zookeeper的主備切換機制)
- RocketMQ無法實現自動切換,當RocketMQ的Master宕機時,讀能被路由到slave上,但寫會被路由到此topic的其他Broker上。
刷盤機制
RocketMQ支援同步刷盤,也就是每次消息都等刷入磁碟後再返回,保證消息不丟失,但對吞吐量稍有影響。一般在主從結構下,選擇非同步雙寫策略是比較可靠的選擇。
消息查詢
RocketMQ支援消息查詢,除了queue的offset外,還支援自定義key。RocketMQ對offset和key都做了索引,均是獨立的索引文件。
消費失敗重試與延遲消費
RocketMQ針對每個topic都定義了延遲隊列,當消息消費失敗時,會發回給Broker存入延遲隊列中,每個消費者在啟動時默認訂閱延遲隊列,這樣消費失敗的消息在一段時候後又能夠重新消費。
-
延遲時間與延遲級別一一對應,延遲時間是隨失敗次數逐漸增加的,最後一次間隔2小時。
-
當然發送消息是也可以指定延遲級別,這樣就能主動設置延遲消費,在一些特定場景下還是有作用的。
數據讀寫速度
-
Kafka每個partition獨佔一個目錄,每個partition均有各自的數據文件.log,相當於一個topic有多個log文件。
-
RocketMQ是每個topic共享一個數據文件commitlog,
Kafka的topic一般有多個partition,所以Kafka的數據寫入速度比RocketMQ高出一個量級。
但Kafka的分區數超過一定數量的文件同時寫入,會導致原先的順序寫轉為隨機寫,性能急劇下降,所以kafka的分區數量是有限制的。
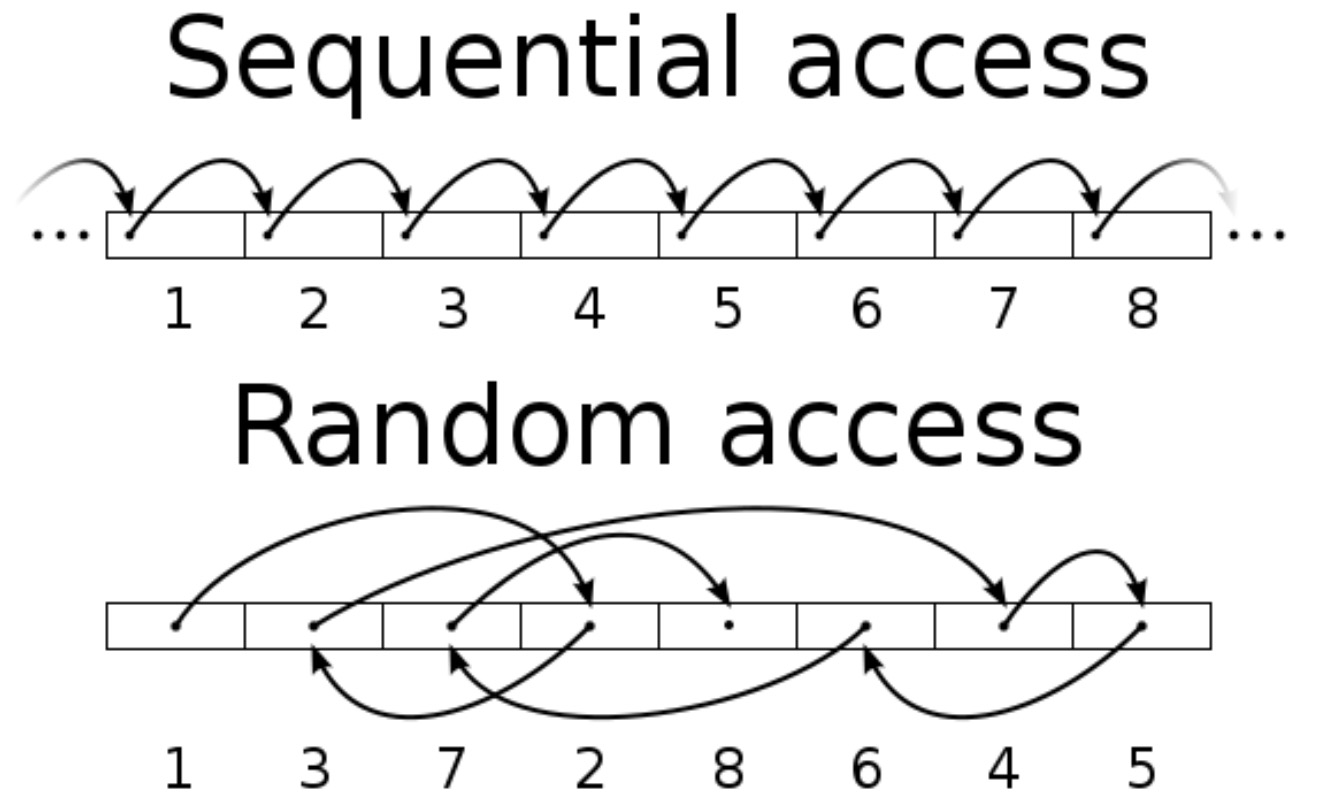
隨機和順序讀寫的對比
-
連續 / 隨機 I/O(在底層硬碟維度)
- 連續 I/O :指的是本次 I/O 給出的初始扇區地址和上一次 I/O 的結束扇區地址是完全連續或者相隔不多的。反之,如果相差很大,則算作一次隨機 I/O。
-
發生隨機I/O可能是因為磁碟碎片導致磁碟空間不連續,或者當前block空間小於文件大小導致的。
連續 I/O 比隨機 I/O 效率高的原因是
- 連續 I/O,磁頭幾乎不用換道,或者換道的時間很短;
- 隨機 I/O,如果這個 I/O 很多的話,會導致磁頭不停地換道,造成效率的極大降低。
隨機和順序速度比較
IOPS和吞吐量:為何隨機是關注IOPS,順序關注吞吐量?
-
隨機在每次IO操作的定址時間和旋轉延時都不能忽略不計,而這兩個時間的存在也就限制了IOPS的大小;
-
順序讀寫可以忽略不計定址時間和旋轉延時,主要花費在數據傳輸的時間上。
IOPS來衡量一個IO系統性能的時候,要說明讀寫的方式以及單次IO的大小,因為讀寫方式會受到旋轉時間和尋道時間影響,而單次IO會受到數據傳輸時間影響。
服務治理
-
Kafka用Zookeeper來做服務發現和治理,broker和consumer都會向其註冊自身資訊,同時訂閱相應的znode,這樣當有broker或者consumer宕機時能立刻感知,做相應的調整;
-
RocketMQ用自定義的nameServer做服務發現和治理,其實時性差點,比如如果broker宕機,producer和consumer不會實時感知到,需要等到下次更新broker集群時(最長30S)才能做相應調整,服務有個不可用的窗口期,但數據不會丟失,且能保證一致性。
- 但是某個consumer宕機,broker會實時回饋給其他consumer,立即觸發負載均衡,這樣能一定程度上保證消息消費的實時性。
Producer差異
發送方式
-
kafka默認使用非同步發送的形式,有一個memory buffer暫存消息,同時會將多個消息整合成一個數據包發送,這樣能提高吞吐量,但對消息的實效有些影響;
-
RocketMQ可選擇使用同步或者非同步發送。
發送響應
Kafka的發送ack支援三種設置:
-
消息存進memory buffer就返回(0);
-
等到leader收到消息返回(1)
-
等到leader和isr的follower都收到消息返回(-1)
上面也介紹了,Kafka都是非同步刷盤
RocketMQ都需要等broker的響應確認,有同步刷盤,非同步刷盤,同步雙寫,非同步雙寫等策略,相比於Kafka多了一個同步刷盤。
Consumer差異
消息過濾
- RocketMQ的queue和kafka的partition對應,但RocketMQ的topic還能更加細分,可對消息加tag,同時訂閱時也可指定特定的tag來對消息做更進一步的過濾。
有序消息
-
RocketMQ支援全局有序和局部有序
-
Kafka也支援有序消息,但是如果某個broker宕機了,就不能在保證有序了。
消費確認
RocketMQ僅支援手動確認,也就是消費完一條消息ack+1,會定期向broker同步消費進度,或者在下一次pull時附帶上offset。
Kafka支援定時確認,拉取到消息自動確認和手動確認,offset存在zookeeper上。
消費並行度
Kafka的消費者默認是單執行緒的,一個Consumer可以訂閱一個或者多個Partition,一個Partition同一時間只能被一個消費者消費,也就是有多少個Partition就最多有多少個執行緒同時消費。
如分區數為10,那麼最多10台機器來並行消費(每台機器只能開啟一個執行緒),或者一台機器消費(10個執行緒並行消費)。即消費並行度和分區數一致。
RocketMQ消費並行度分兩種情況:有序消費模式和並發消費模式,
-
有序模式下,一個消費者也只存在一個執行緒消費,並行度同Kafka完全一致。
-
併發模式下,每次拉取的消息按consumeMessageBatchMaxSize(默認1)拆分後分配給消費者執行緒池,消費者執行緒池min=20,max=64。也就是每個queue的並發度在20-64之間,一個topic有多個queue就相乘。所以rocketmq的並發度比Kafka高出一個量級。
並發消費方式並行度取決於Consumer的執行緒數,如Topic配置10個隊列,10台機器消費,每台機器100個執行緒,那麼並行度為1000。
事務消息
RocketMQ指定一定程度上的事務消息,當前開源版本刪除了事務消息回查功能,事務機制稍微變得沒有這麼可靠了,不過阿里雲的rocketmq支援可靠的事務消息;kafka不支援分散式事務消息。
Topic和Tag的區別?
業務是否相關聯
-
無直接關聯的消息:淘寶交易消息,京東物流消息使用不同的 Topic 進行區分。
-
交易消息,電器類訂單、女裝類訂單、化妝品類訂單的消息可以用Tag進行區分。
消息優先順序是否一致:如同樣是物流消息,盒馬必須小時內送達,天貓超市 24 小時內送達,淘寶物流則相對會慢一些,不同優先順序的消息用不同的 Topic 進行區分。
消息量級是否相當:有些業務消息雖然量小但是實時性要求高,如果跟某些萬億量級的消息使用同一個Topic,則有可能會因為過長的等待時間而「餓死」,此時需要將不同量級的消息進行拆分,使用不同的Topic。
Tag和Topic的選用
針對消息分類,您可以選擇創建多個Topic,或者在同一個Topic下創建多個Tag。
不同的Topic之間的消息沒有必然的聯繫。
Tag則用來區分同一個Topic下相互關聯的消息,例如全集和子集的關係、流程先後的關係。
通過合理的使用 Topic 和 Tag,可以讓業務結構清晰,更可以提高效率。
Tag怎麼實現消息過濾
RocketMQ分散式消息隊列的消息過濾方式有別於其它MQ中間件,是在Consumer端訂閱消息時再做消息過濾的。
RocketMQ這麼做是在於其Producer端寫入消息和Consumer端訂閱消息採用分離存儲的機制來實現的,Consumer端訂閱消息是需要通過ConsumeQueue這個消息消費的邏輯隊列拿到一個索引,然後再從CommitLog裡面讀取真正的消息實體內容,所以說到底也是還繞不開其存儲結構。
ConsumeQueue的存儲結構:可以看到其中有8個位元組存儲的Message Tag的哈希值,基於Tag的消息過濾是基於這個欄位值的。

Tag過濾方式
-
Consumer端在訂閱消息時除了指定Topic還可以指定Tag,如果一個消息有多個Tag,可以用||分隔。
-
Consumer端會將這個訂閱請求構建成一個SubscriptionData,發送一個Pull消息的請求給Broker端。
-
Broker端從RocketMQ的文件存儲層—Store讀取數據之前,會用這些數據先構建一個MessageFilter,然後傳給Store。
-
Store從ConsumeQueue讀取到一條記錄後,會用它記錄的消息tag hash值去做過濾,由於在服務端只是根據hashcode進行判斷。
無法精確對tag原始字元串進行過濾,故在消息消費端拉取到消息後,還需要對消息的原始tag字元串進行比對,如果不同,則丟棄該消息,不進行消息消費。
Message Body過濾方式
向伺服器上傳一段Java程式碼,可以對消息做任意形式的過濾,甚至可以做Message Body的過濾拆分
數據消息的堆積能力
理論上Kafka要比RocketMQ的堆積能力更強,不過RocketMQ單機也可以支援億級的消息堆積能力,我們認為這個堆積能力已經完全可以滿足業務需求。
消息數據回溯
-
Kafka理論上可以按照Offset來回溯消息
-
RocketMQ支援按照時間來回溯消息,精度毫秒,例如從一天之前的某時某分某秒開始重新消費消息,典型業務場景如consumer做訂單分析,但是由於程式邏輯或者依賴的系統發生故障等原因,導致今天消費的消息全部無效,需要重新從昨天零點開始消費,那麼以時間為起點的消息重放功能對於業務非常有幫助。
性能對比
-
Kafka單機寫入TPS約在百萬條/秒,消息大小10個位元組
-
RocketMQ單機寫入TPS單實例約7萬條/秒,單機部署3個Broker,可以跑到最高12萬條/秒,消息大小10個位元組。
數據一致性和實時性
消息投遞實時性
-
Kafka使用短輪詢方式,實時性取決於輪詢間隔時間
-
RocketMQ使用長輪詢,同Push方式實時性一致,消息的投遞延時通常在幾個毫秒。
消費失敗重試
-
Kafka消費失敗不支援重試
-
RocketMQ消費失敗支援定時重試,每次重試間隔時間順延
消息順序
-
Kafka支援消息順序,但是一台Broker宕機後,就會產生消息亂序
-
RocketMQ支援嚴格的消息順序,在順序消息場景下,一台Broker宕機後,發送消息會失敗,但是不會亂序
Mysql Binlog分發需要嚴格的消息順序
(題外話)Kafka沒有的,RocketMQ獨有的tag機制
普通消息、事務消息、定時(延時)消息、順序消息,不同的消息類型使用不同的 Topic,無法通過Tag進行區分。
總結
-
RocketMQ定位於非日誌的可靠消息傳輸(日誌場景也OK),目前RocketMQ在阿里集團被廣泛應用在訂單,交易,充值,流計算,消息推送,日誌流式處理,binglog分發等場景。
-
RocketMQ的同步刷盤在單機可靠性上比Kafka更高,不會因為作業系統Crash,導致數據丟失。
-
同時同步Replication也比Kafka非同步Replication更可靠,數據完全無單點。
-
另外Kafka的Replication以topic為單位,支援主機宕機,備機自動切換,但是這裡有個問題,由於是非同步Replication,那麼切換後會有數據丟失,同時Leader如果重啟後,會與已經存在的Leader產生數據衝突。
-
例如充值類應用,當前時刻調用運營商網關,充值失敗,可能是對方壓力過多,稍後在調用就會成功,如支付寶到銀行扣款也是類似需求。這裡的重試需要可靠的重試,即失敗重試的消息不因為Consumer宕機導致丟失。


