Apache Kyuubi 在 T3 出行的深度實踐
- 支撐了80%的離線作業,日作業量在1W+
- 大多數場景比 Hive 性能提升了3-6倍
- 多租戶、並發的場景更加高效穩定
T3出行是一家基於車聯網驅動的智慧出行平台,擁有海量且豐富的數據源。因為車聯網數據的多樣性,T3出行構建了以 Apache Hudi 為基礎的企業級數據湖,提供強有力的業務支撐。而對於負責數據價值挖掘的終端用戶而言,平台的技術門檻是另一種挑戰。如果能將平台的能力統合,並不斷地優化和迭代,讓用戶能夠通過 JDBC 和 SQL 這種最普遍最通用的技術來使用,數據生產力將可以得到進一步的提升。
T3出行選擇了基於網易數帆主導開源的 Apache Kyuubi(以下簡稱Kyuubi)來搭建這樣的能力。在2021 中國開源年會(COSCon’21)上,T3出行高級大數據工程師李心愷詳細解讀了選擇 Kyuubi 的原因,以及基於 Kyuubi 的深度實踐和實現的價值。
引入 Kyuubi 前的技術架構
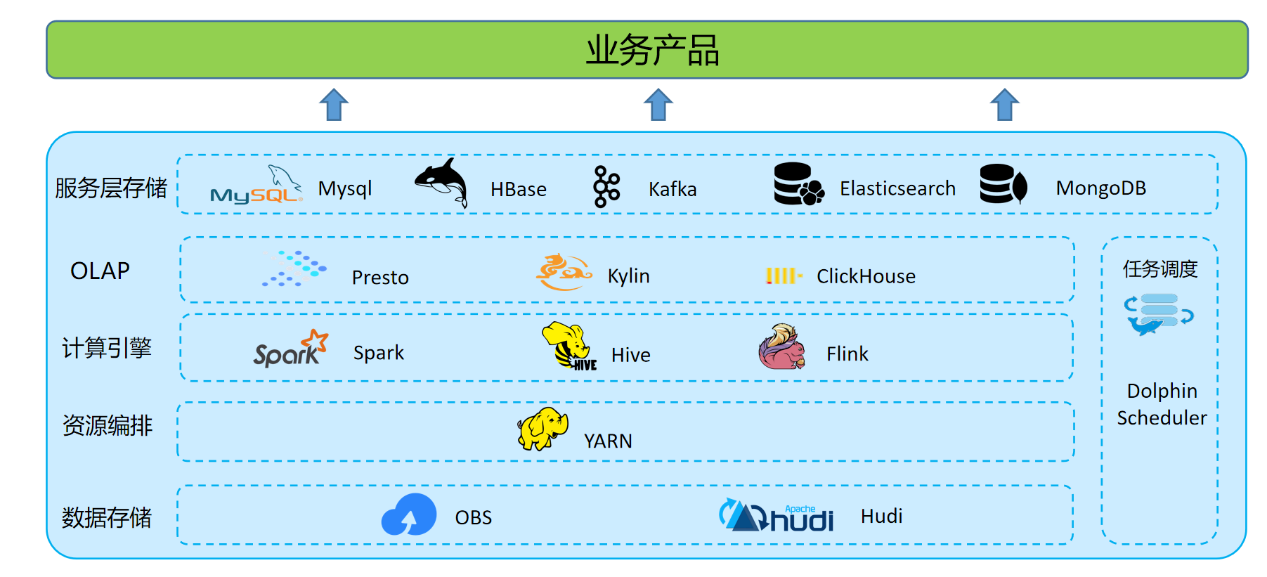
T3出行整個數據湖體系,由數據存儲與計算、數據查詢與分析和應用服務層組成。其中數據計算分為離線和實時。
數據存儲
OBS 對象存儲,格式化數據存儲格式以 Hudi 格式為主。
數據計算
離線數據處理:利用 Hive on Spark 批處理能力,在 Apache Dolphin Scheduler 上定時調度,承擔所有的離線數倉的 ETL 和數據模型加工的工作。
實時數據處理:建設了以 Apache Flink 引擎為基礎的開發平台,開發部署實時作業。
數據查詢與分析
OLAP 層主要為面向管理和運營人員的報表,對接報表平台,查詢要求低時延響應,需求多變快速響應。面向數據分析師的即席查詢,更是要求 OLAP 引擎能支援複雜 SQL 處理、從海量數據中快速甄選數據的能力。
應用服務層
數據應用層主要對接各個業務系統。離線 ETL 後的數據寫入不同業務不同資料庫中,面向下游提供服務。
現有架構痛點
跨存儲
數據分布在 Hudi、ClickHouse、MongoDB 等不同存儲,需要寫程式碼關聯分析增加數據處理門檻和成本。
SQL不統一
Hive 不支援通過 upsert、update、delete 等語法操作 Hudi 表,同時 MongoDB、ClickHouse 等語法又各不相同,開發轉換成本較高。
資源管控乏力
Hive on Spark、Spark ThriftServer 沒有較好的資源隔離方案,無法根據租戶許可權做並發控制。
選型 Apache Kyuubi
Apache Kyuubi 是一個 Thrift JDBC/ODBC 服務,對接了 Spark 引擎,支援多租戶和分散式的特性,可以滿足企業內諸如 ETL、BI 報表等多種大數據場景的應用。Kyuubi 可以為企業級數據湖探索提供標準化的介面,賦予用戶調動整個數據湖生態的數據的能力,使得用戶能夠像處理普通數據一樣處理大數據。項目已於2021年 6 月 21 號正式進入 Apache 孵化器。於T3出行而言,Kyuubi 的角色是一個面向 Serverless SQL on Lakehouse 的服務。
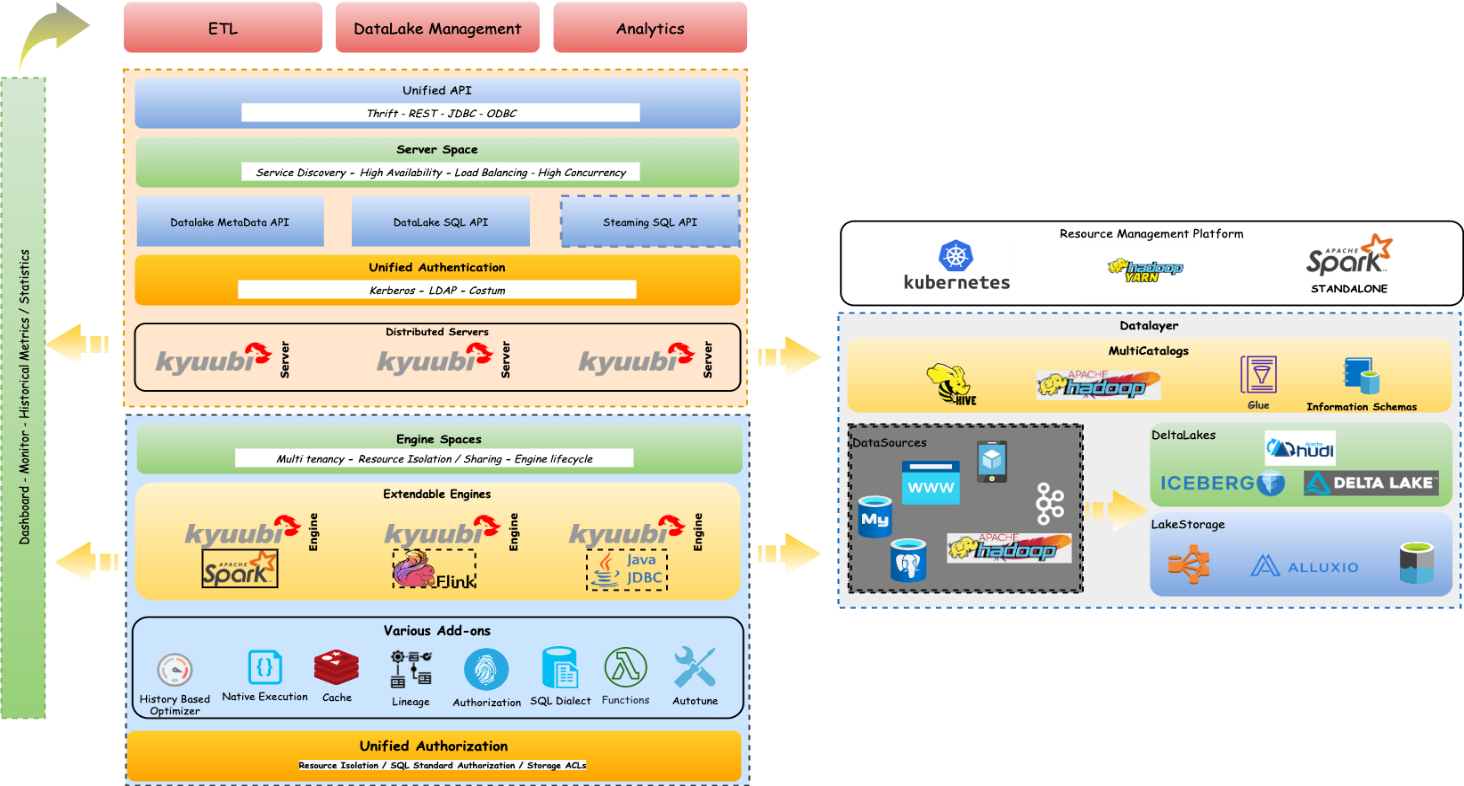 Apache Kyuubi 架構
Apache Kyuubi 架構
HiveServer 是一個廣泛應用的大數據組件。因傳統的 MR 引擎處理效率已經較為落後,Hive 引擎替換為了 Spark,但是為了和原本的 MR 及 TEZ 引擎共存,Hive 保留了自己的優化器,這使得Hive Parse 性能在大多數場景下都落後於 Spark Parse。
STS(Spark Thrift Server)支援HiveServer 的介面和協議,允許用戶直接使用 Hive 介面提交 SQL 作業。但是 STS 不支援多租戶,同時所有 Spark SQL 查詢都走唯一一個 Spark Thrift 節點上的同一個 Spark Driver,並發過高,並且任何故障都會導致這個唯一的 Spark Thrift 節點上的所有作業失敗,從而需要重啟 Spark Thrift Server,存在單點問題。
對比 Apache Kyuubi 和 Hive、STS,我們發現,Kyuubi 在租戶控制,任務資源隔離,引擎升級對接,性能等方面擁有諸多優勢。詳情見下圖。
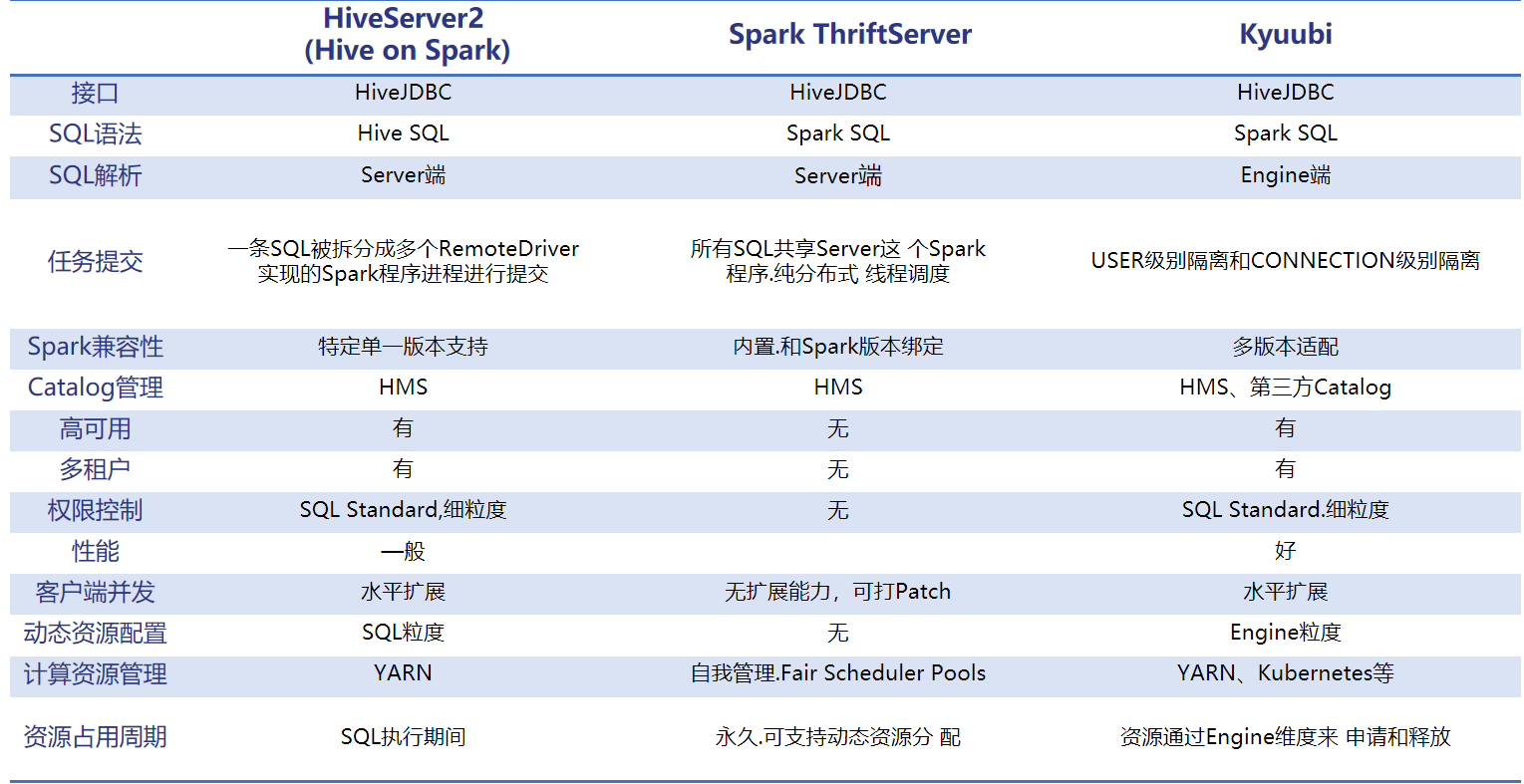
Apache Kyuubi 優勢
Apache Kyuubi在T3出行場景
AD-HOC場景
Hue 整合 Kyuubi,替代 Hive 為分析師和大數據開發提供服務。
我們在 hue_safety_valve.ini 配置文件中,增加如下配置:
[notebook]
[[interpreters]]
[[[cuntom]]]
name=Kyuubi
interface=hiveserver2
[spark]
sql_server_host=Kyuubi Server IP
sql_server_port=Kyuubi Port然後重啟 Hue 即可。
ETL場景
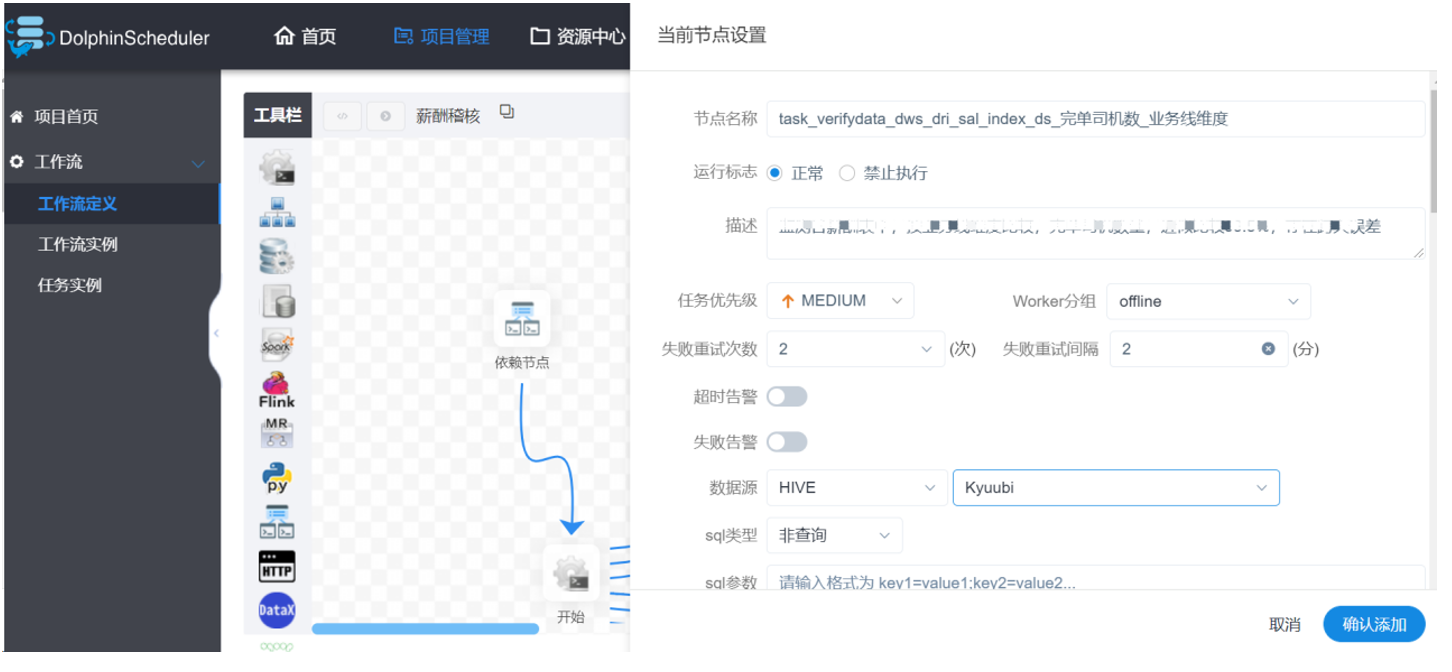
DS 配置 Kyuubi 數據源,進行離線 ETL 作業。因為 Kyuubi Server 的介面、協議都和 HiveServer2 完全一致,所以 DS 只需要數據源中 Hive 數據源類型配置為 Kyuubi 多數據源,就可以直接提交 SQL 任務。
目前,Kyuubi 在T3出行支撐了80%的離線作業,日作業量在1W+。
聯邦查詢場景
公司內部使用多種數據存儲系統,這些不同的系統解決了對應的使用場景。除了傳統的 RDBMS (比如 MySQL) 之外,我們還使用 Apache Kafka 來獲取流和事件數據,還有 HBase、MongoDB,以及數據湖對象存儲和 Hudi 格式的數據源。
我們知道,要將不同存儲來源的數據進行關聯,我們需要對數據進行提取,並放到同一種存儲介質中,比如 HDFS,然後進行關聯操作。這種數據割裂,會給我們的數據關聯分析帶來很大的麻煩,如果我們能夠使用一種統一的查詢引擎分別查詢不同數據源的數據,然後直接進行關聯操作,這將帶來巨大的效率提升。
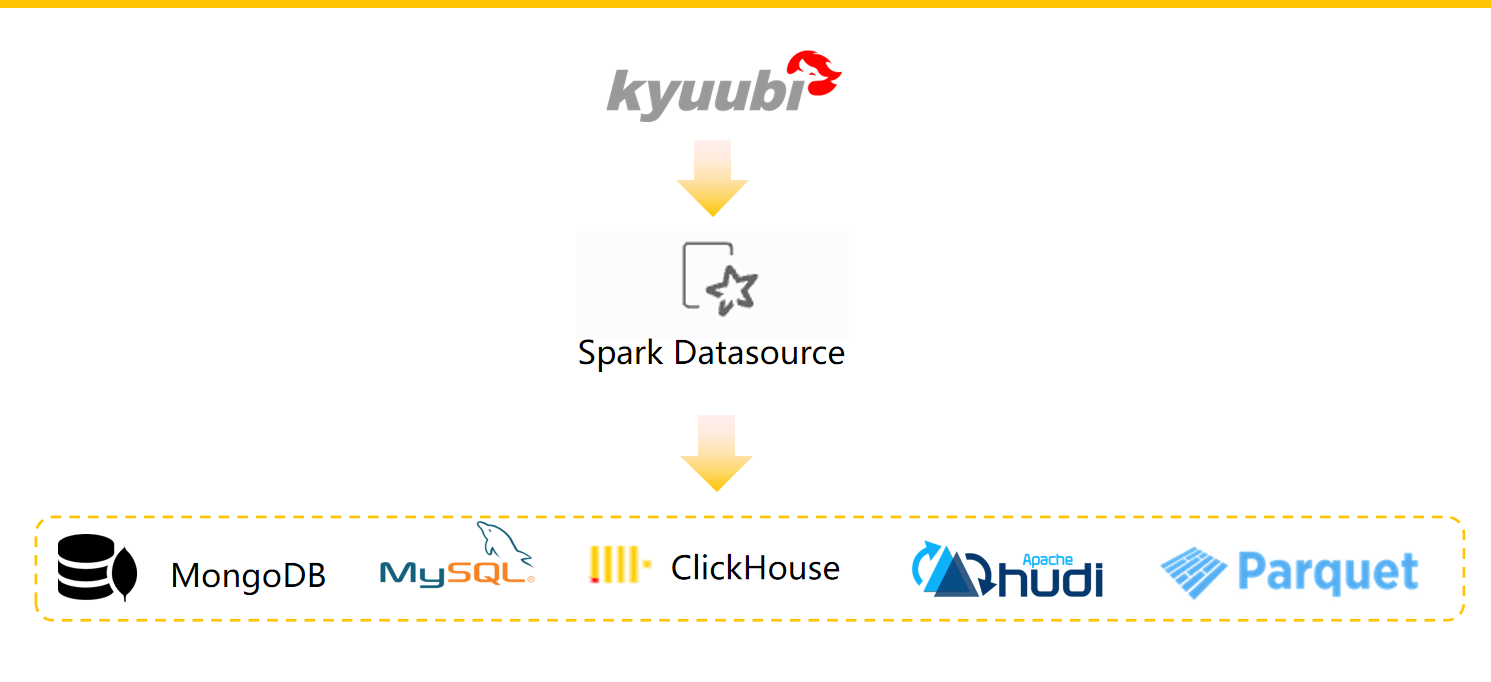
所以,我們利用 Spark DatasourceV2 實現了統一語法的跨存儲聯邦查詢。其提供高效,統一的 SQL 訪問。這樣做的優勢如下:
- 單個 SQL 方言和 API
- 統一安全控制和審計跟蹤
- 統一控制
- 能夠組合來自多個來源的數據
- 數據獨立性
基於 Spark DatasourceV2 ,對於讀取程式,我們只需定義一個 DefaultSource 的類,實現 ReadSupport 相關介面,就可以對接外部數據源,同時 SupportsPushDownFilters、SupportsPushDownRequiredColumns、SupportsReportPartitioning 等相關的優化,實現了運算元下推功能。由此我們可以將查詢規則下推到 JDBC 等數據源,在不同數據源層面上進行一些過濾,再將計算結果返回給 Spark,這樣可以減少數據的量,從而提高查詢效率。
現有方案是通過建立外部表,利用 HiveMeta Server 管理外部數據源的元資訊, 對錶進行統一多許可權管理。
例如:MongoDB 表映射
CREATE EXTERNALTABLE mongo_test
USING com.mongodb.spark.sql
OPTIONS (
spark.mongodb.input.uri "mongodb://用戶名:密碼@IP:PORT/庫名?authSource=admin",
spark.mongodb.input.database "庫名",
spark.mongodb.input.collection "表名",
spark.mongodb.input.readPreference.name "secondaryPreferred",
spark.mongodb.input.batchSize "20000"
);後續升級 Spark3.X ,引入了 namespace 的概念後,DatasouceV2 可實現插件形式的Multiple Catalog 模式,這將大大提高聯邦查詢的靈活度。
Kyuubi 性能測試

我們基於 TPC-DS 生成了 500GB 數據量進行了測試。選用部分事實表和維度表,分別在 Hive 和 Kyuubi 上進行性能壓測。主要關注場景有:
- 單用戶和多用戶場景
- 聚合函數性能對比
- Join 性能對比
- 單 stage 和多 stage 性能對比
壓測結果對比,Kyuubi 基於 Spark 引擎大多數場景比 Hive 性能提升了3-6倍,同時多租戶、並發的場景更加高效穩定。
T3出行對 Kyuubi 的改進與優化
我們對 Kyuubi 的改進和優化主要包括如下幾個方面:
- Kyuubi Web:啟動一個獨立多 web 服務,監控管理 Kyuubi Server。
- Kyuubi EventBus:定義了一個全局的事件匯流排。
- Kyuubi Router:路由模組,可以將專有語法的 SQL 請求轉發到不同的原生 JDBC 服務上。
- Kyuubi Spark Engine:修改原生 Spark Engine。
- Kyuubi Lineage:數據血緣解析服務,將執行成功多 SQL 解析存入圖資料庫,提供 API 調用。
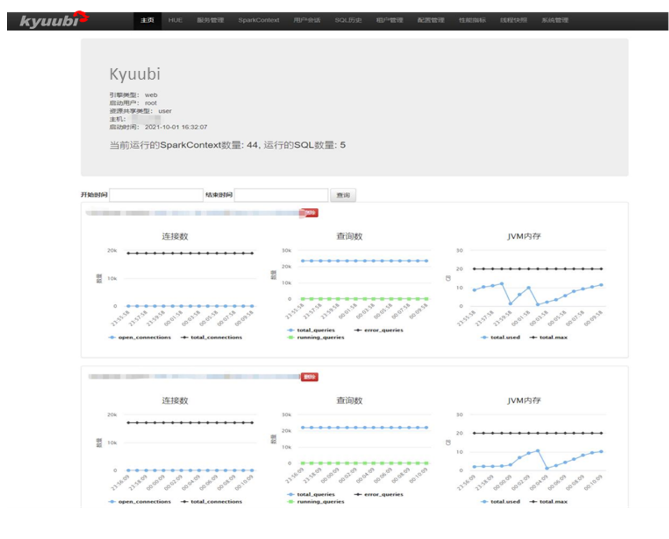
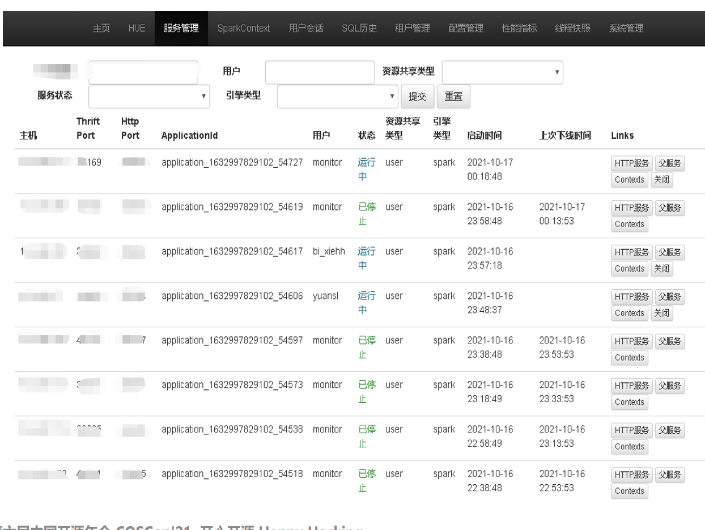
Kyuubi Web 服務功能
- 當前運行的 SparkContext 和 SQL 數量
- 各個 Kyuubi Server 實例狀態
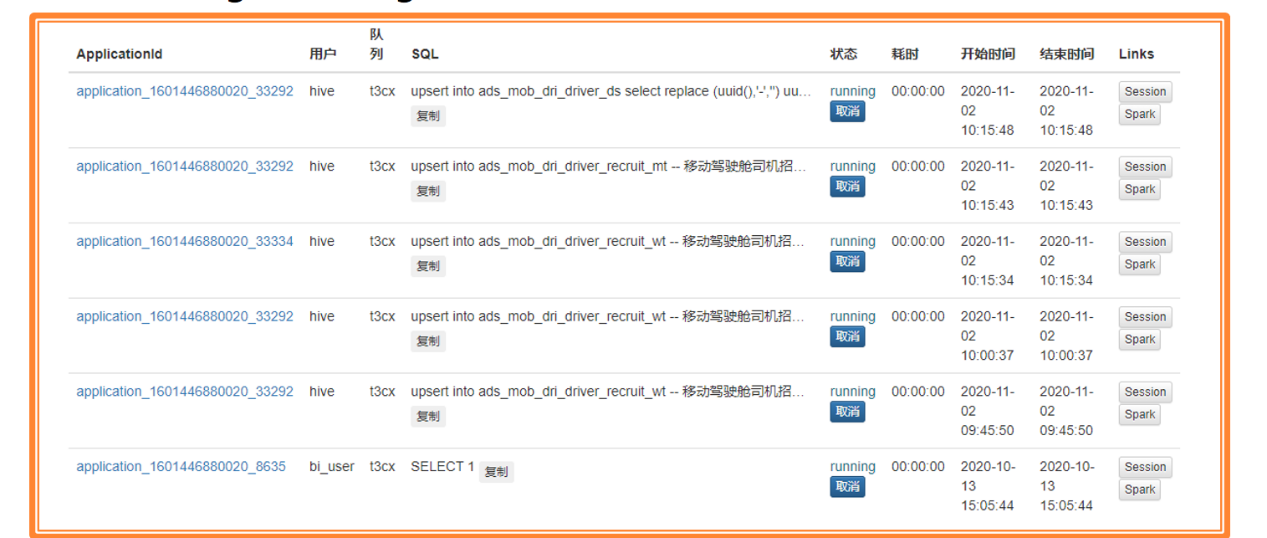
- Top 20: 1天內最耗時的 SQL
- 用戶提交 SQL 排名(1天內)
- 展示各用戶 SQL 運行的情況和具體語句
- SQL 狀態分為:closed,cancelled,waiting和running。其中waiting和running 的 SQL 可取消
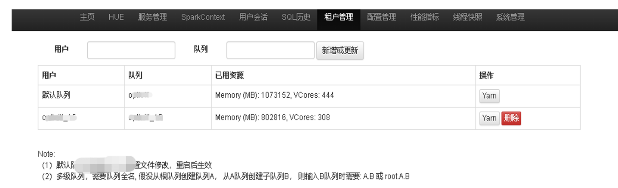
- 根據管理租戶引擎對應隊列和資源配置、並發量
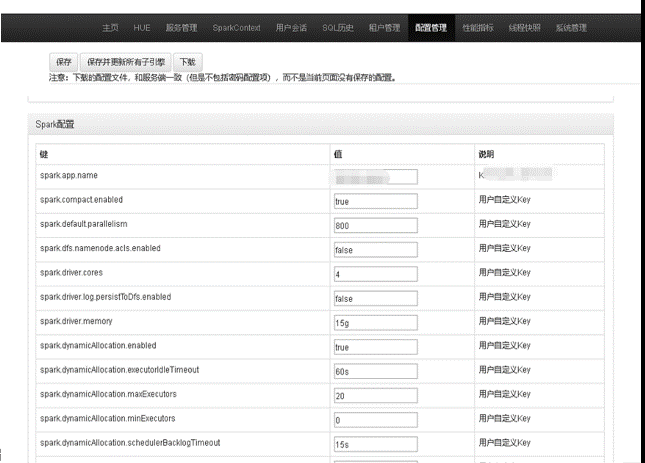
- 可以在線查看、修改 Kyuubi Server、Engine 相關配置
Kyuubi EventBus
Server 端引入了 RESTful Service。
在Server應用進程中,事件匯流排監聽了包括應用停止時間、JDBC 會話關閉、JDBC 操作取消等事件。引入事件匯流排的目的,是為了在單個應用中和不同的子服務間進行通訊。否則不同的子服務對象需要包含對方的實例依賴,服務對象的模型會非常複雜。

Kyuubi Router
增加了 Kyuubi JDBC Route 模組,JDBC 連接會先打向此服務。
該服務根據既定策略轉發到不同服務。下圖為具體策略。
Kyuubi Spark Engine
- 將 Kyuubi-Spark-Sql-Engine 的 Spark 3.X 版本改成了 Spark 2.4.5,適配集群版本,後續集群升級會跟上社區版本融合
- 增加了Hudi datasource 模組,使用 Spark datasource 計劃查詢 Hudi,提高對 Hudi 的查詢效率
- 集成 Hudi 社區的 update、delete 語法,新增了 upsert 語法和 Hudi 建表語句

Kyuubi Lineage
基於 ANTLR 的 SQL 血緣解析功能。現有提供了兩個模式,一個是定時調度,解析一定時間範圍內的執行成功的 SQL 語句,將解析結果存儲到 HugeGraph 圖庫中,用於數據治理系統等調用。另一個模式為提供 API 調用,查詢時用戶直接調用,SQL 複雜時可以直觀理清自己的 SQL 邏輯,方便修改和優化自己的 SQL。
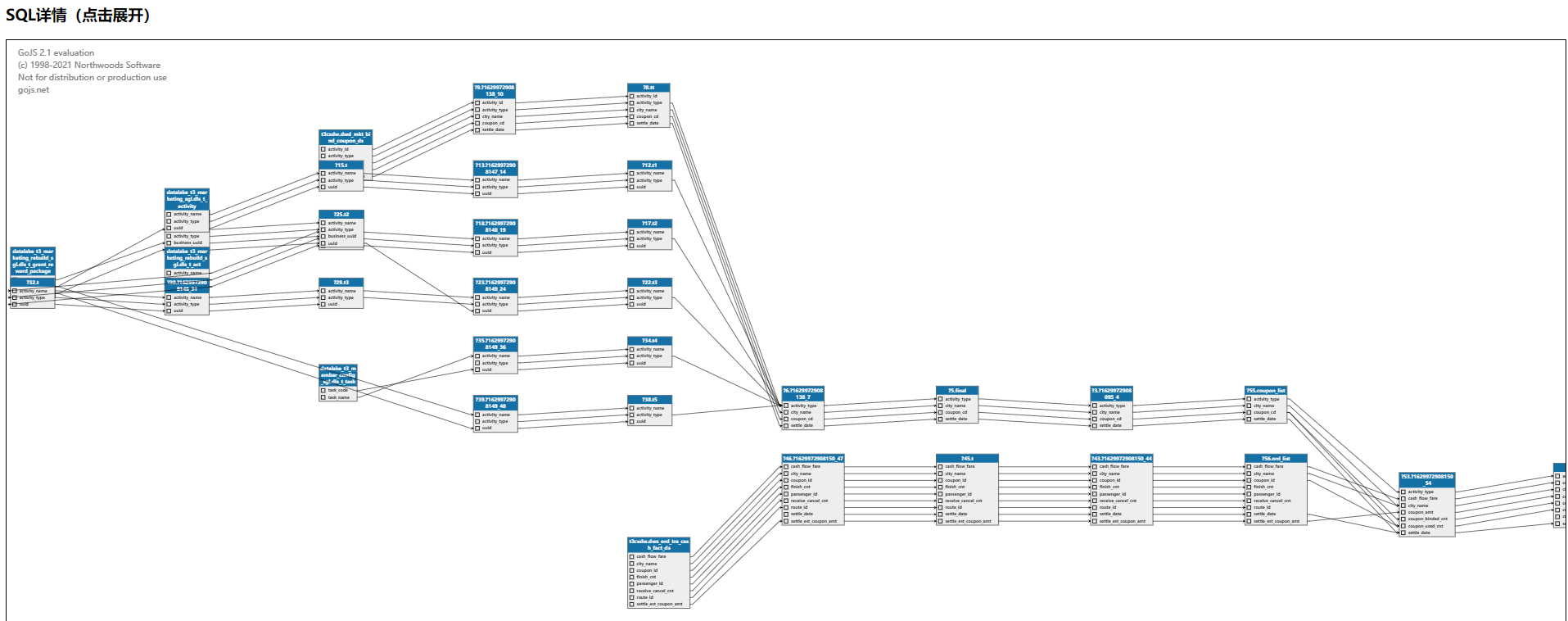
基於 Kyuubi 的解決方案

總結

T3出行大數據平台基於 Apache Kyuubi 0.8,實現了數據服務統一化,大大簡化了離線數據處理鏈路,同時也能保障查詢時延要求,之後我們將用來提升更多業務場景的數據服務和查詢能力。最後,感謝 Apache Kyuubi 社區的相關支援。後續計劃升級到社區的新版本跟社區保持同步,同時基於T3出行場景做的一些功能點,也會陸續回饋給社區,共同發展。也期望 Apache kyuubi 作為 Serverless SQL on Lakehouse 引領者越來越好!
作者:李心愷,T3出行高級大數據工程師
Kyuubi 主頁:
//kyuubi.apache.org/
Kyuubi 源碼:
//github.com/apache/incubator-kyuubi


