經過4次優化我把python程式碼耗時減少95%
- 2021 年 11 月 12 日
- 筆記
- Python, 互聯網python編程
背景交代
團隊做大學英語四六級考試相關服務。業務中有一個care服務,購買了care服務考試不過可以全額退款,不過有一個前提是要完成care服務的任務,比如堅持背單詞N天,完成指定的試卷。
在這個背景下,當2021年6月的四六級考試完成之後,要統計出兩種用戶數據:
- 完成care服務的用戶
- 沒有完成care的用戶
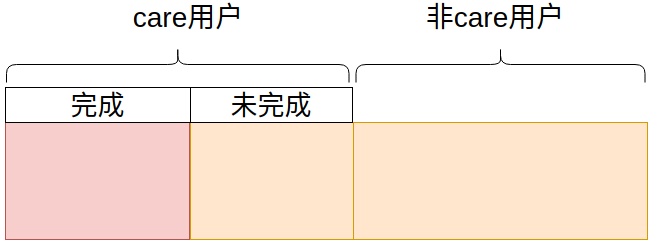
所以簡化的邏輯就是要在所有的用戶中區分出care完成用戶和care未完成用戶。
- 目標1:完成care服務
- 目標2:未完成care服務
所有目標用戶的數量在2.7w左右,care完成用戶在0.4w左右。所以我需要做的是在從資料庫中查詢出的 2.7w 所有用戶,去另一個表區分出care完成用戶和care未完成用戶。
第一版
第一版:純粹使用資料庫查詢。首先查詢出所有目標,然後遍歷所有用戶,在遍歷中使用user id從另一張表中查詢出care完成用戶。
總量在2.7w 左右,所以資料庫就查詢了2.7w次。
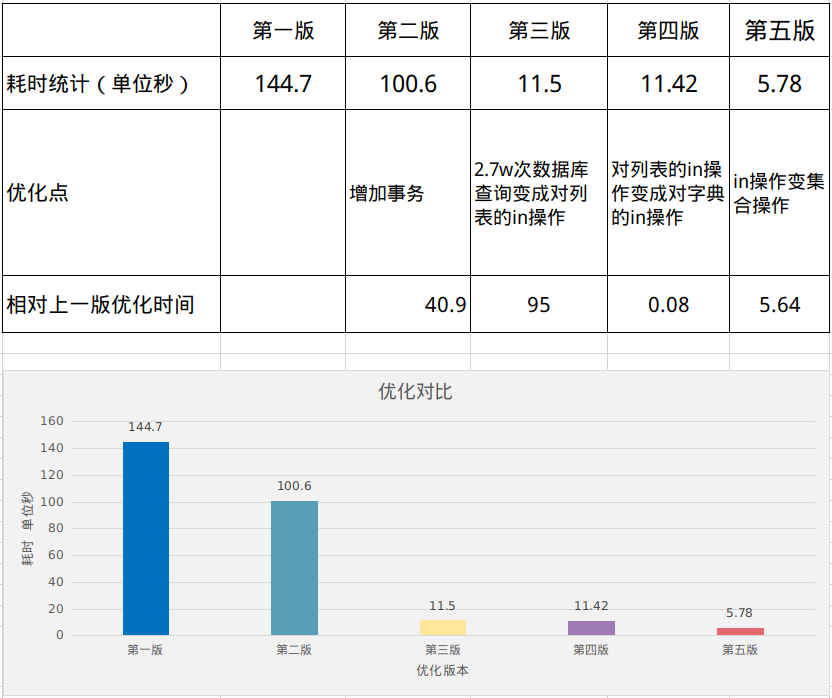
耗時統計:144.7 s
def remind_repurchase():
# 查詢出所有用戶
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
for user in all_users:
# 從另一張表查詢用戶是否完成care
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.user_id == user.user_id,
cm.UserInsurance.plan_id == user.plan_id,
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
# care 完成
if len(user_insurance) == 1:
# 其他邏輯
plan_15_16_can_refund_users.append(user.user_id)
else:
# care未完成用戶
plan_15_16_not_refund_users.append(user.user_id)
主要的耗時操作就在for循環查詢資料庫。這種耗時肯定是不被允許的,需要提高效率。
第二版
優化點:增加事務
第二版優化思路:對於 2.7w 次的資料庫庫查詢肯定會有 2.7w 次建立連接、事務、查詢語句轉SQL等。2.7w次的開銷也是一個極大的數字。理所當然的想到了減少事務的開銷。將所有的資料庫查詢都放在一個事務中完成,就能夠有效減少查詢帶來的耗時。
耗時統計:100.6 s
def remind_repurchase():
# 查詢出所有用戶
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# 增加事務
with pwdb.database.atomic():
for user in all_users:
# 從另一張表查詢用戶是否完成care
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.user_id == user.user_id,
cm.UserInsurance.plan_id == user.plan_id,
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
# care 完成
if len(user_insurance) == 1:
# 其他邏輯
plan_15_16_can_refund_users.append(user.user_id)
else:
# care未完成用戶
plan_15_16_not_refund_users.append(user.user_id)
增加事務之後減少了44s,相當於縮短了時間30%的時間,由此可以看出事務在資料庫中查詢是一個比較耗時的操作。
第三版
優化點:將2.7w次的資料庫查詢轉變成對列表的in操作。
第三版提出改進方案:原來的邏輯是循環 2.7w 次,在資料庫中查詢用戶是否完成care服務。2.7w 次的資料庫查詢是耗時最長的原因,而可以改進的方法是將所有完成care服務的用戶先一次性查詢出來,放到一個列表中。遍歷所有用戶時不去查資料庫,而是直接使用in操作在列表中查詢。這種方法直接將 2.7w 次資料庫遍歷減少到1次,極大縮短了資料庫查詢耗時。
耗時統計:11.5 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# 所有care完成用戶,先將所有用戶查詢出來放在一個列表中
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_list = [user.user_id for user in user_insurance]
for user in all_users:
user_id = user.user_id
# care 完成
if user.user_id in user_insurance_list:
# 查分數
plan_15_16_can_refund_users.append(user_id)
else:
# care未完成用戶 + 非care用戶
plan_15_16_not_refund_users.append(user_id)
這一次優化的效果是非常顯著的,可以看出想要提高程式碼效率要盡量減少資料庫查詢次數。
第四版
優化點:2.7w 次對列表的in操作變成對字典的in操作
在第三版中已經極大的優化了效率,但是仔細琢磨之後發現還是有提升的空間的。在第三版中 2.7w 次for循環,然後用in操作在列表中查詢。眾所周知python中對列表的in操作是遍歷的,時間複雜度為0(n),所以效率不高,而對字典的in操作時間複雜度為常數級別0(1)。所以在第四版優化中先查詢出的數據不保存為列表,而是保存為字典。key就是原來列表中的值,value可自定義。
耗時統計:11.42 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# 所有care完成用戶,先將所有用戶查詢出來放在一個列表中
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_dict = {user.user_id:True for user in user_insurance}
for user in all_users:
user_id = user.user_id
# care 完成
if user.user_id in user_insurance_dict:
# 查分數
plan_15_16_can_refund_users.append(user_id)
else:
# care未完成用戶 + 非care用戶
plan_15_16_not_refund_users.append(user_id)
由於2.7w次的in操作數據量並不是很大,並且列表的in操作在python中優化的效率也很好,所以這裡的對字典的in操作並沒有減少時間消耗。
第五版
優化點:將in操作轉變成集合操作。
在前四版的優化下已經將耗時縮短了 133s,減少了近 92.1% 的耗時,想著這個數據看起來還不錯了。隔天早上在刷牙時腦子裡思緒紛飛就想到這個事情了。這時忽然想到既然我能查詢全部用戶,又將完成care用戶的用戶查詢到一個列表中,這時不就是相當於兩個集合嗎?既然是集合,那麼使用集合之間的交集和差集是不是比循環 2.7w 次要快呢?上班之後馬上動手來驗證這個想法。果然,還能夠減少時間消耗,將第四版中的11.42 直接減少了一半,縮短到5.78,縮短近50%。
耗時統計: 5.78 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
all_users_set = set([user.user_id for user in all_users])
plan_15_16_can_refund_users = []
received_user_count = 0
# 所有care完成用戶
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_set = set([user.user_id for user in user_insurance])
temp_can_refund_users = all_users_set.intersection(user_insurance_set)
總結
最終優化的結果:
第一版耗時: 144.7 s
最後一版耗時: 5.7 s
優化時間:109 s
優化百分比:95.0%
在各個版本中的優化詳細細節如下:
由此可以得出幾個結論,幫助減少程式耗時:
結論一:事務不僅能夠保證數據原子性,合理使用還能有效減少資料庫查詢耗時
結論二:集合操作的效率非常高,要善於使用集合減少循環
結論三:字典的查找效率高於列表,但是萬次級別的操作無法體驗優勢
最後的還有一個結論:程式設計師的靈感似乎在刷牙、上廁所、洗澡、喝水時特別活躍,所以寫不出來程式碼就該去摸摸魚了。


