一文帶你理解TDengine中的快取技術
- 2021 年 11 月 10 日
- 筆記
- tdengine, TDengine技術部落格, 時序資料庫, 物聯網大數據平台
作者 | 王明明,濤思數據軟體工程師

小 T 導讀:在電腦系統中,快取是一種常用的技術,既有硬體快取,比如我們經常聽到的 CPU L2 高速快取,也有軟體快取,比如很多系統里把 Redis 當做資料庫的快取。本文為根據 TDengine 線上 Meetup 第四期王明明的分享《TDengine 快取技術解析》(影片)整理而成。
TDengine 是一款高性能的物聯網大數據平台。為了高效處理時序數據,TDengine 中大量用到了快取技術,自己實現了哈希表、快取池等技術。今天我會為大家講解 TDengine 中用到的這些快取技術。
首先我會介紹一下什麼是快取,常用的快取技術,最後重點分享 TDengine 中的相關技術,最好講一下改進和優化的方向。下面我們正式開始。
什麼是快取?
凡是位於速度相差較大的兩種硬體之間,用於協調兩者數據傳輸速度差異的結構,均可稱之為快取。
-
快取最早是用來協調 CPU 和主記憶體之間的速度差異,進化出了目前的 L1/L2/L3 三層 CPU 內部的高速快取;
-
在記憶體和硬碟之間也有 Cache,每次寫磁碟時並沒有立即刷到磁碟上,而是寫入到磁碟快取中,由作業系統負責 flush 到磁碟;
-
此外,硬碟與網路之間也有某種意義上的 Cache,比如 CDN 快取,代理伺服器的快取等等。
快取工作的原則主要是引用的局部性,包括空間局部性和時間局部性。
-
空間局部性是指 CPU 在某一時刻需要某個數據,那麼很可能下一步就需要其附近的數據,例如載入讀磁碟數據的時候,雖然只需要一部分數據,但是每次都載入一個塊,那麼當需要附近數據的時候就可以直接從記憶體獲取,避免再讀取磁碟。
-
時間局部性是指當某個數據被訪問過一次之後,過不了多久時間就會被再一次訪問。例如我們手機後台運行程式,會把最近打開的應用快取在後台,很可能一會兒還會訪問相同的應用,這種情況下直接將其從後台調到前台即可。
在使用快取時要根據系統的架構、性能的要求以及要解決的問題選擇合適的快取位置,比如記憶體快取、 磁碟快取、分散式快取等。
使用快取有很多優點:
-
提高性能,將相應數據存儲起來以避免數據的重複創建、處理和傳輸,可有效提高性能。
-
提高穩定性,同一個應用中,對同一數據、邏輯功能的多次請求是經常發生的。當請求量很大時,如果每次請求都進行處理,消耗的資源是很大的浪費,也同時造成系統的不穩定。
-
提高可用性,有時,提供數據資訊的服務可能會意外停止,如果使用了快取技術,可以在一定時間內仍正常提供對最終用戶的支援,提高了系統的可用性。
快取是有狀態的,包括時間狀態和空間狀態。
-
時間狀態:應用程式使用的永久數據; 只在進程周期內有效;和特定的用戶會話有關; 處理某個消息的時間內有效。
-
空間狀態:應用程式/進程/執行緒/單機/分散式/用戶/角色。
使用快取時需要考慮的問題:
-
安全性:執行緒安全/許可權安全
-
序列化
-
快取數據優化
-
提前載入/動態載入
-
過期策略:FIFO/LRU/LFU
-
管理:效率監控,大小限制
快取一致性問題:
-
當使用分散式的快取時,需要考慮多個快取的一致性問題,防止由於不一致出現問題。
-
處理一致性問題時需要根據實際的應用場景兼顧 CAP 原則。根據問題的場景不同,一致性要求也不同,可以強一致性或者弱一致性(最終一致性)。
a. 比如銀行轉賬場景需要強一致性,數據沒統一之前,不允許用戶進行操作,防止金額出錯。
b. 大多數互聯網產品為了保證可用性和分區容錯性,通常採用弱一致性,比如不同地區的用戶看到的同一個排行榜可能有非常短暫的不同,但數據同步成功後,排行榜就相同了,這個延遲通常在幾十 ms,對於用戶來說是可以接受的。
常用的快取技術
-
使用硬體快取 (CPU Cache)
-
使用本地記憶體快取(雙緩衝/環形緩衝/緩衝池)
-
使用記憶體映射文件 (mmap)
-
使用資料庫快取 (Redis/MySQL)
TDengine 中的快取方案
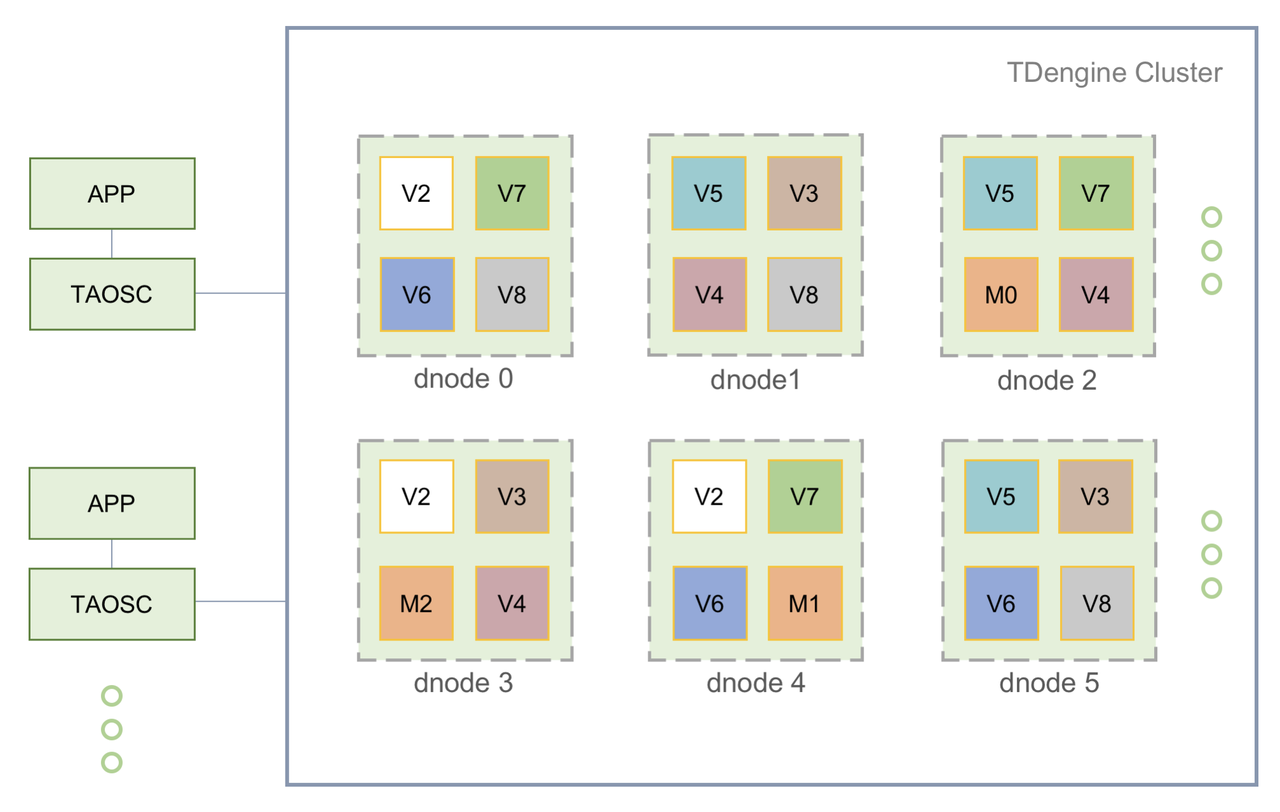
首先我們來複習一下 TDengine 的整體架構。
-
數據節點(dnode):服務進程,可以包括多個 vnode 和 mnode,查詢數據時需要 dnode 的網路位置來獲取數據。
-
虛擬節點(vnode):存儲、查詢的基本單位。多個 vnode 組成一個虛擬節點組(VGroup),分布在不同的機器上,起到備份的效果。同時 vnode 也便於水平擴展。
-
管理節點(mnode):存儲資料庫的元數據,起到管理集群的功能。
再來看一下 TDengine 的數據模型。
-
一個採集點一張表(時間戳作為主鍵,順序存儲)
-
一張表的數據在文件中以塊的形式連續存放
-
文件中的數據塊大小可配
-
採用 Block Range Index(BRIN)索引塊數據
TDengine 中都有哪些數據需要快取呢?
具體可以分為如下幾類:
-
元數據 (table meta/stable vgroup)
-
連接數據 (rpc/http session)
-
查詢快取 (qinfo handle/ show info)
-
最新數據 (last 和 last_row)
-
時序數據 (buffer pool/ multilevel storage)
接下來我們就具體看一下 TDengine 中的快取方案。
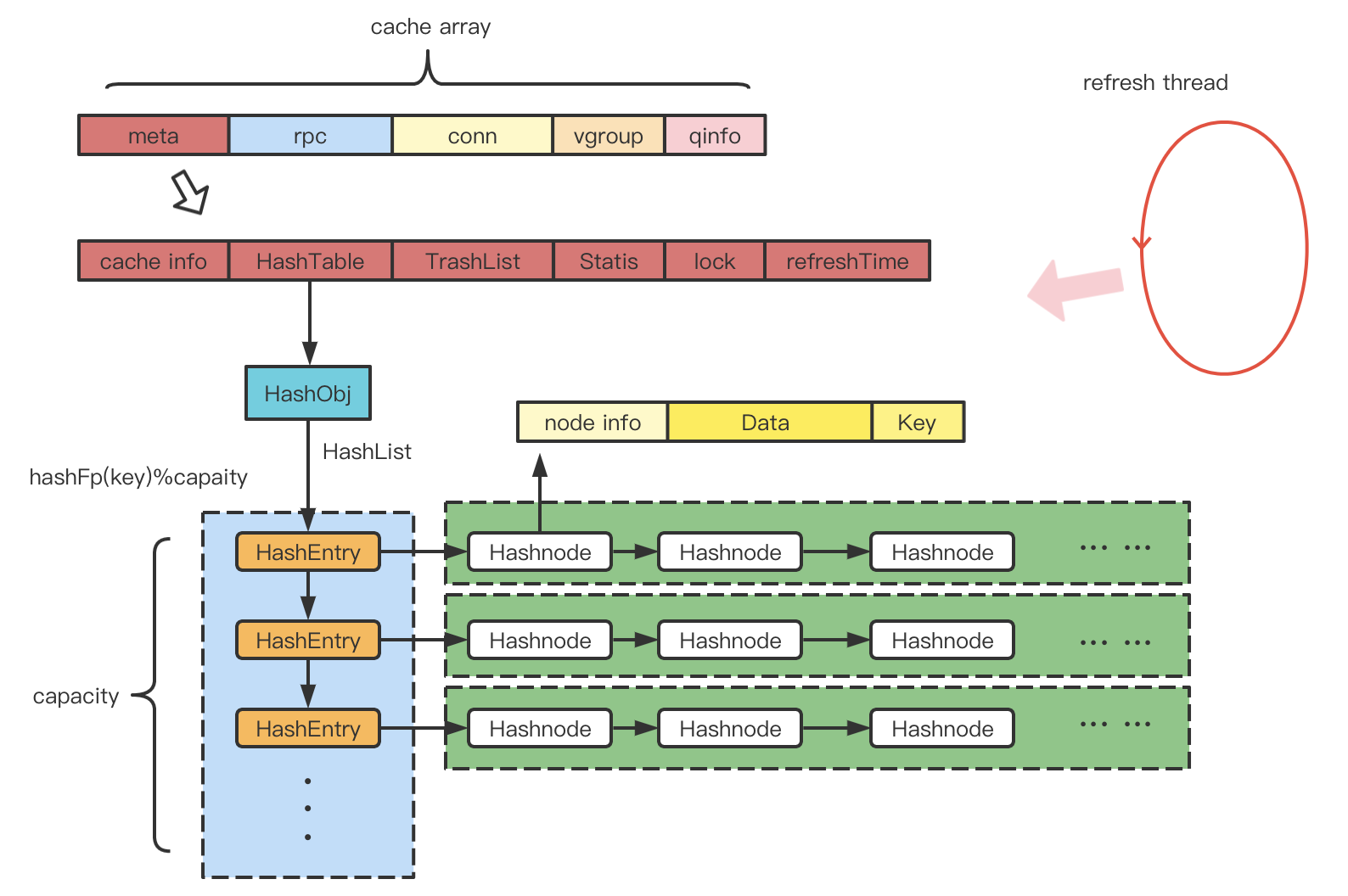
首先是通用的哈希快取 (meta data/ rpcObj/ qinfo)。
-
哈希快取,通過一個列表來管理,每個元素是一個快取結構,裡面包括快取資訊、 哈希表 、垃圾回收鏈表、統計資訊、更新頻率、鎖等資訊。此外,有一個刷新執行緒定時檢測快取列表中過期的數據,將其刪除。
-
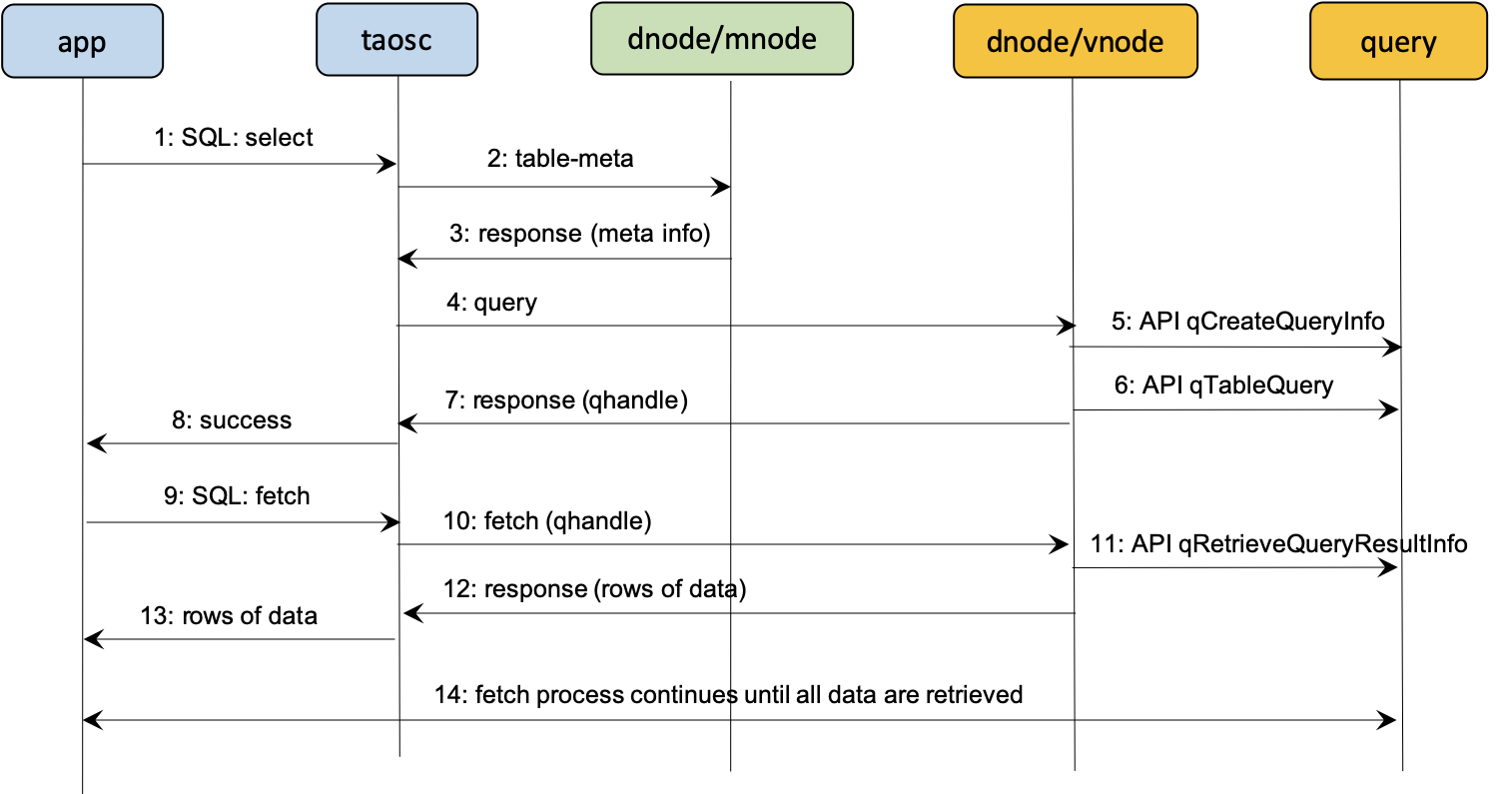
查詢計劃 id (query handle),query handle 是資料庫查詢時,server 先生產一個執行計劃,返回給 client,然後 client 拿著這個計劃 id,分多次去 server 取數據,直到數據查詢完。這個快取是消息時間範圍,整個進程內有效的,不需要更新,使用完即釋放。
-
元數據快取(meta data), meta data 數據主要記錄數據表的 scheme,所在的節點地址。通過客戶端快取 meta data 可以避免頻繁的向 mnode 取數據。但是 meta 數據需要考慮更新一致性問題。通過版本號來控制。
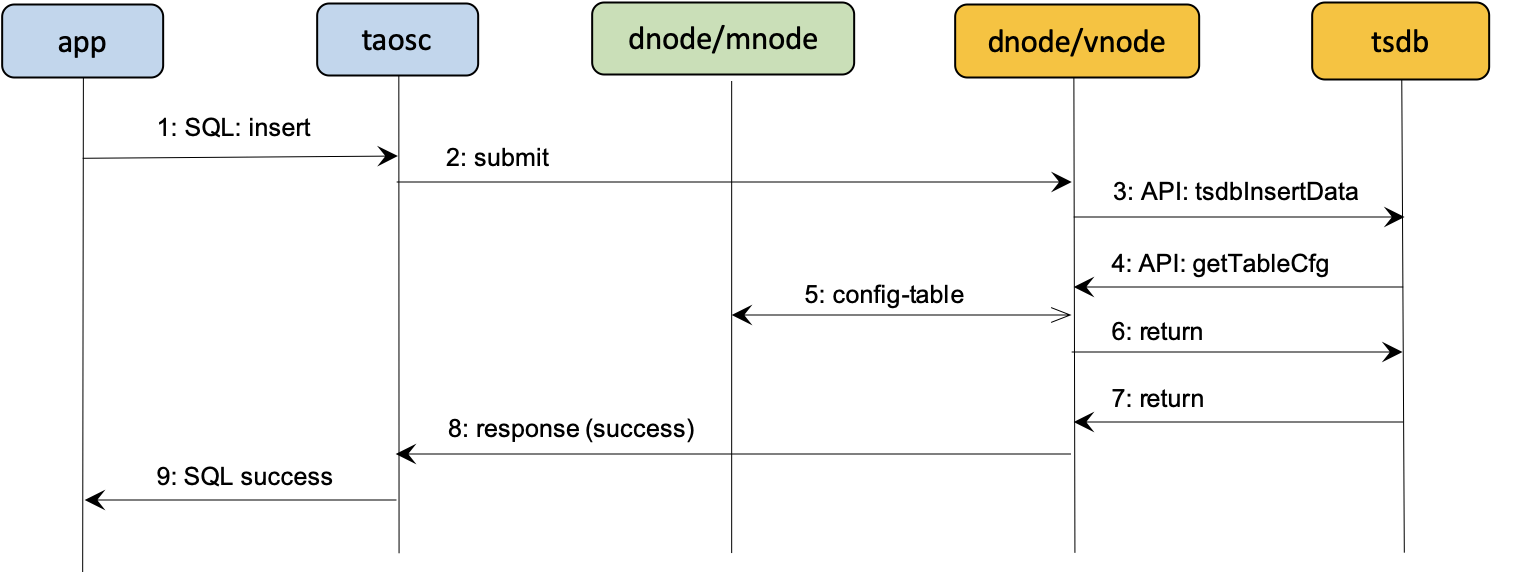
其次是 TSDB 記憶體塊快取 (double buffer/buffer pool)。
-
TDengine 提供雙快取/快取池來優化數據寫入查詢的性能。預分配 16M*6 的 buffer pool,使用超過 1/3 容量落地,落地時 mem 轉化為 imei(不可變更),負責寫入磁碟。
-
直接將最近到達的數據保存在快取中,可以更加快速地響應用戶針對最近數據的查詢分析,整體上提供更快的資料庫查詢響應能力。
-
TDengine 重啟以後系統的快取將被清空,之前快取的數據均會被批量寫入磁碟,之前快取的數據不會重新載入到快取中。
-
數據查詢時首先通過 time range 定位數據所在的位置,因為 MEM 和 IMEM 中都記錄有最新、最舊數據的時間戳。然後如果在 MEM 中,通過跳錶來快速查詢數據位置。在磁碟中,通過磁碟塊文件索引查找數據,最後做結果融合返回。
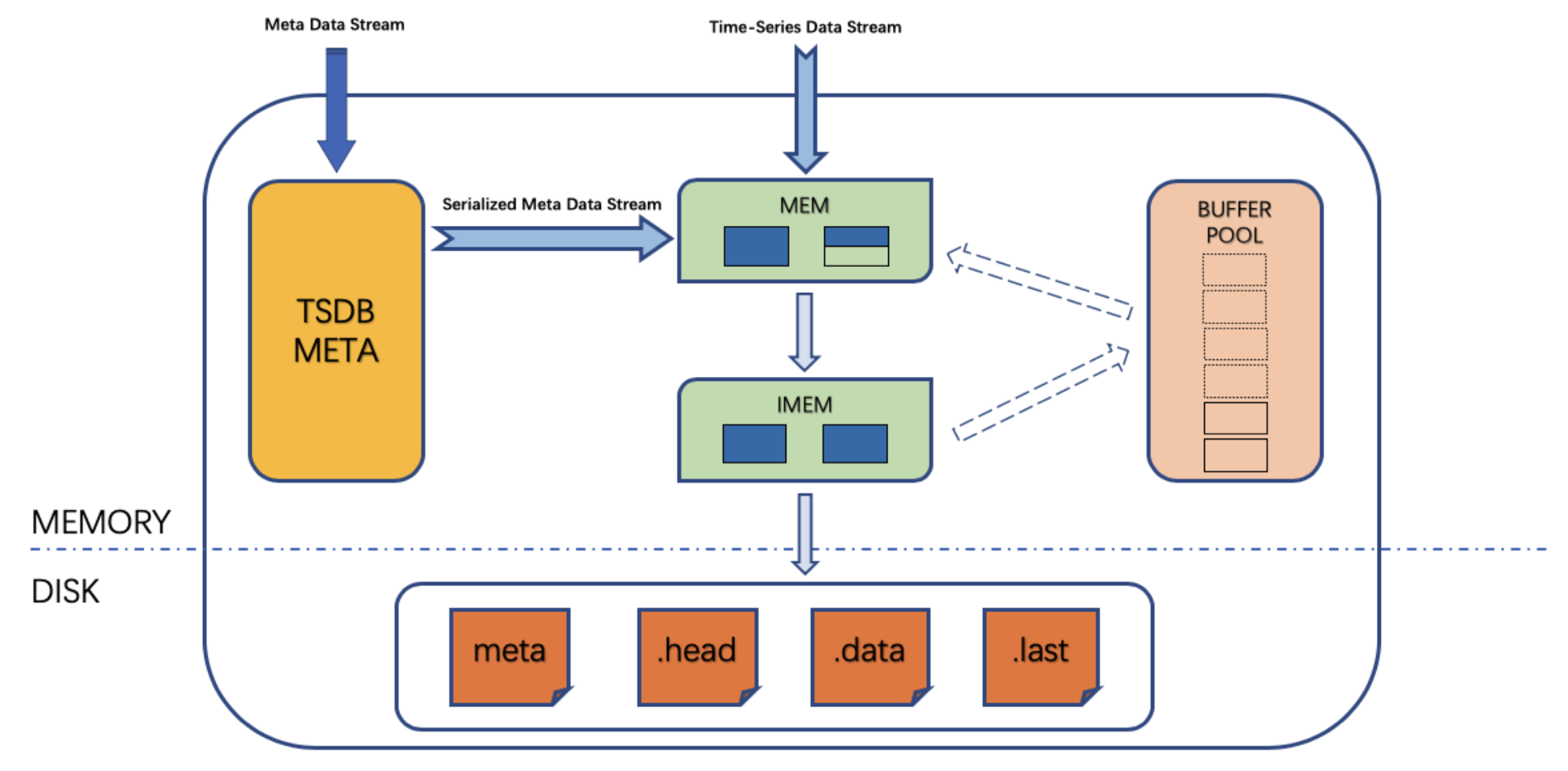
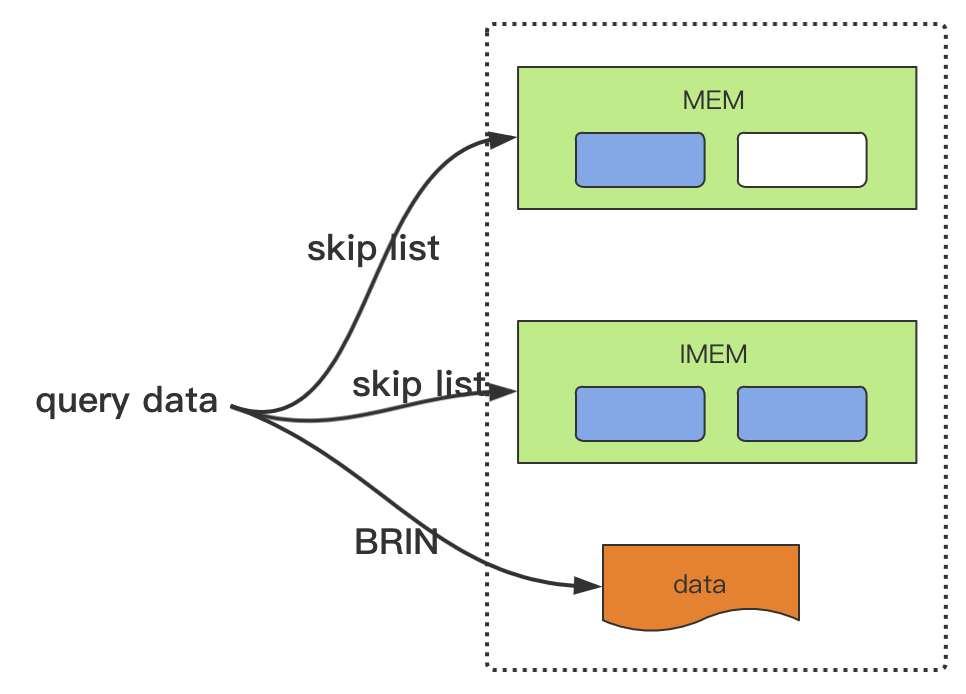
再來看 last 和 last_row 快取 (local storage)。
-
時序資料庫總是有對最新一行數據或者某列最新一條數據查詢的需求,因此設計了 last 和 last_row 快取來快速響應用戶需求。防止每次都去磁碟查詢數據。
-
每個表開闢快取區快取該數據,服務啟動時會全量載入,插入時會更新,此外在配置更新的時候,也會更新快取數據。比如,默認是關閉的。用戶使用命令開啟快取功能時,就會載入數據,同理關閉開關時,會釋放之前的快取區。
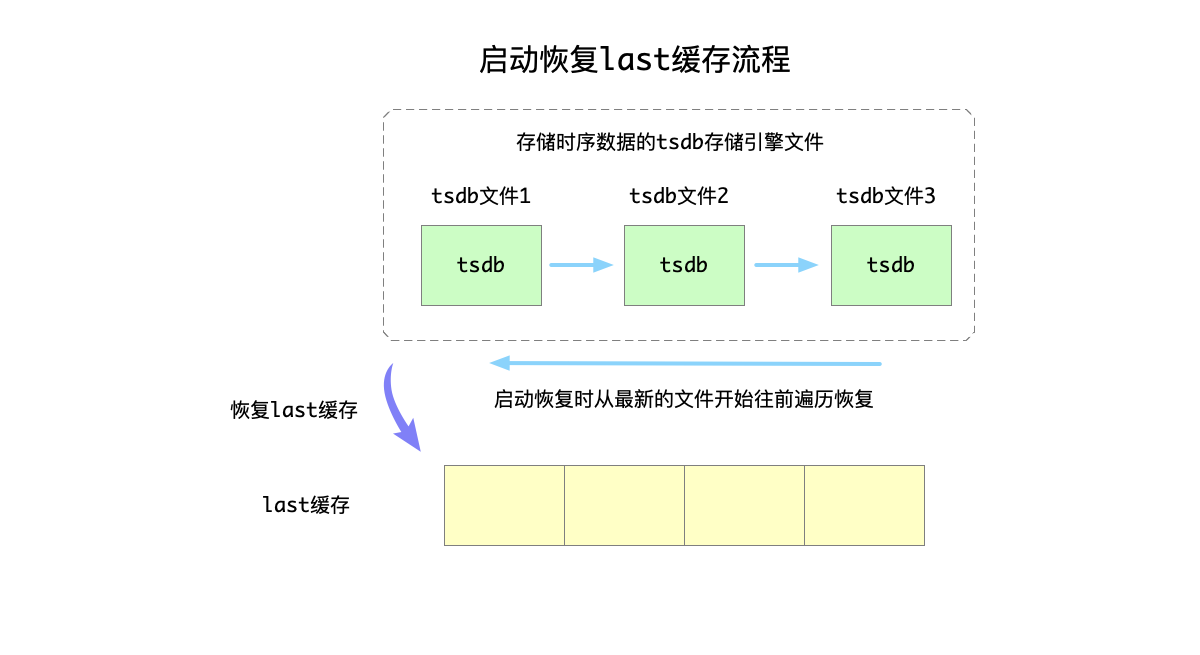
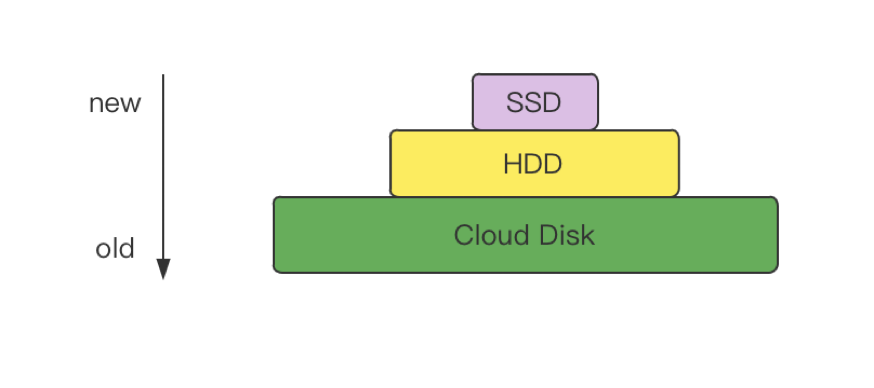
最後我們再來看一下多級存儲 (ssd/hdd/cloud)。
由於物聯網的數據量是巨大的,為了很好的平衡性能和成本,TDengine 還採用了分級存儲的思想,不同熱度數據存儲在不同的地方。分級存儲的這一思想也體現在電腦的體系結構里(暫存器、L1/L2 Cache、記憶體、硬碟)。
快取對性能提升舉例
-
測試環境: 12 核 i7 3.2GHz 64GB 4T HDD
-
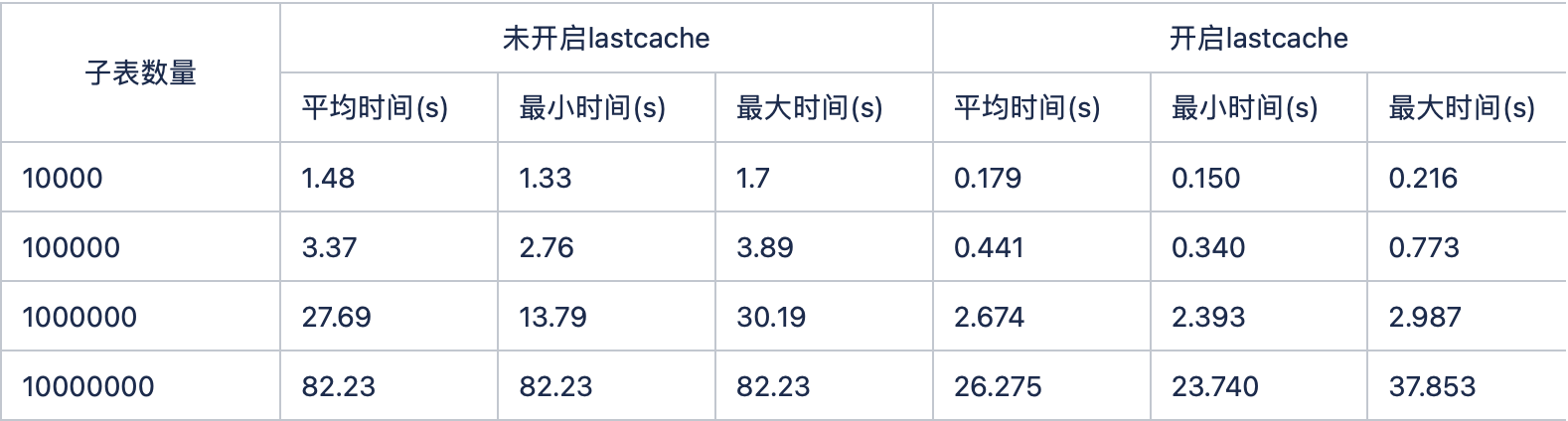
last_row 快取性能對比 (select last_row(*) from stable 查詢語句 1000 次,統計查詢時間)
-
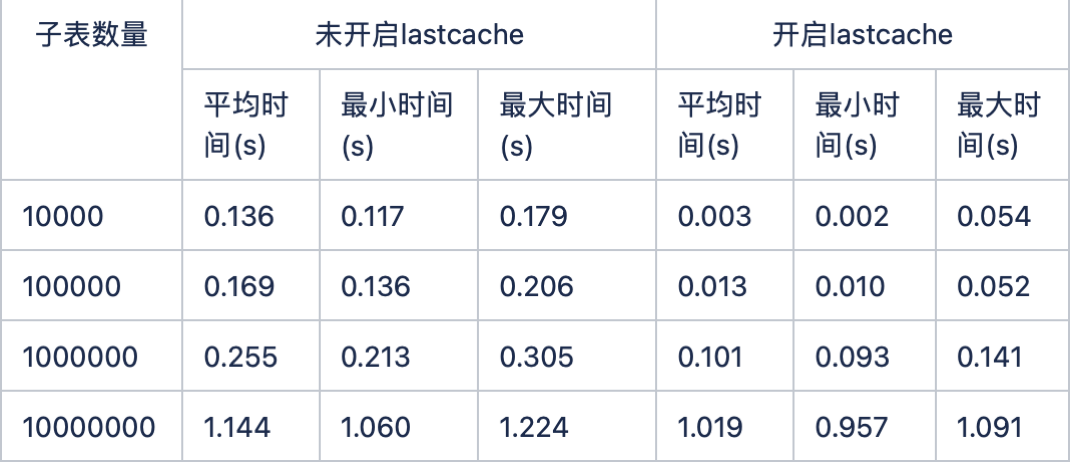
last 快取性能對比 (select last(*) from stable 和 select last_row(*) from stable 查詢語句 1000 次,統計查詢時間)
-
開啟快取性能比不開啟快取提升將近 1 個數量級。快取對系統性能提升還是很大的,所以,在使用 TDengine 時,可以根據自己的需求,打開或關閉開關
問題及改進優化方向
先來看問題,主要是兩點:
-
mnode 的 meta 數據全量載入,表數量很大時,記憶體佔用大,啟動慢;
-
last 和 last_row 快取啟動全量載入。
最後我們再來看一下優化方向:
-
全量載入改為動態載入;
-
預分配快取大小,通過 LRU 等策略來更新數據;
-
qhandle 通過對象池管理,避免頻繁 calloc。
如果想了解更具體的實現細節,可以在GitHub上查看相關源程式碼,也期待大家加入進來,一起改進TDengine!
關於作者
王明明,北京郵電大學畢業,主修方向為電子資訊、模式識別和影像處理。畢業後入職騰訊,先後在 TEG 魔王工作室卡牌遊戲開發、騰訊地圖手圖後台開發、騰訊看點知識圖譜後台開發。對網路編程、RPC 框架原理、Redis 快取等技術有深入的研究。


