論文翻譯:Fullsubnet: A Full-Band And Sub-Band Fusion Model For Real-Time Single-Channel Speech Enhancement
論文作者:Xiang Hao, Xiangdong Su, Radu Horaud, and Xiaofei Li
翻譯作者:凌逆戰
論文地址:Fullsubnet:實時單通道語音增強的全頻帶和子頻帶融合模型
程式碼://github.com/haoxiangsnr/FullSubNet
摘要
本文提出了一種用於單通道實時語音增強的全頻帶和子頻帶融合模型FullSubNet。全頻帶和子頻帶是指分別輸入全頻帶和子頻帶雜訊頻譜特徵,輸出全頻帶和子頻帶語音目標的模型。子帶模型獨立處理每個頻率。它的輸入由一個頻率和幾個上下文頻率組成。輸出是對相應頻率的乾淨語音目標的預測。這兩種模型有不同的特點。全頻帶模型可以捕獲全局 上下文譜和長距離交叉頻帶依賴。但缺乏訊號平穩性建模和關注局部譜模式的能力。子帶模型正好相反。在我們提出的FullSubNet中,我們將一個純全頻帶模型和一個純子頻帶模型依次連接起來,並利用實際的聯合訓練將這兩種模型的優點結合起來。我們在DNS挑戰(INTERSPEECH 2020)數據集上進行了實驗,對所提出的方法進行了評價。實驗結果表明,全頻帶資訊和子頻帶資訊是互補的,FullSubNet可以有效地集成它們。此外,FullSubNet的性能也超過了DNS Challenge (INTERSPEECH 2020)中排名第一的方法。
關鍵詞:全頻帶,子頻帶融合,子頻帶,語音增強
1 引言
近年來,基於深度學習的單通道語音增強方法極大地提高了語音增強系統的語音品質和可懂度。這些方法通常在有監督的環境中進行訓練,可分為時域方法和頻域方法。時域方法[1-3]使用神經網路直接將帶噪語音映射純凈語音波形。頻域方法[4-7]通常使用雜訊頻譜特徵(例如復頻譜、幅度頻譜)作為神經模型的輸入。學習目標是乾淨語音的頻譜特徵或某個掩碼(例如,理想二進位掩碼(Ideal Binary Mask, IBM)[8]、理想比率掩碼(Ideal Ratio Mask, IRM)[9]、復理想比率掩碼(complex Ideal Ratio Mask, cIRM)[10])。一般來說,由於時域訊號的維度較高並且缺乏明顯的幾何結構,頻域方法仍然佔據絕大多數語音增強方法的主導地位。在本文中,我們重點研究了頻域實時單通道語音增強。
在我們之前的工作[11]中,提出了一種基於子帶的單通道語音增強方法。與傳統的基於全頻帶的方法不同,該方法以子頻帶方式執行:模型的輸入由一個頻率和多個上下文頻率組成。輸出是對應頻率的乾淨語音目標的預測。所有頻率都是獨立處理的。該方法的設計依據如下:
- 它學習訊號的頻率平穩性來區分語音和平穩雜訊。眾所周知,語音是非平穩的,而許多類型的雜訊是相對平穩的。隨頻率變化的STFT幅值的時間演化反映了平穩性,這是傳統雜訊功率估計器[12, 13]和語音增強方法[14, 15]的基礎。
- 它著重於當前和上下文頻率中呈現的局部頻譜。局部譜模式已被證明是區分語音和其他訊號的有用資訊。該方法在INTERSPEECH 2020中提交給DNS挑戰[16],並在16份實時音頻提交中排名第四。
子帶模型滿足了DNS挑戰的實時性要求,性能也非常有競爭力。然而,由於它不能對全局頻譜進行建模,也不能利用長距離跨頻帶依賴性。特別是對於信噪比極低的子帶,子帶模型很難恢復乾淨的語音,而藉助於全頻帶相關性可以恢復乾淨語音。另一方面,全頻帶模型[4,5]的訓練是學習高維輸入和輸出之間的回歸,缺乏專門用於子頻帶資訊(如訊號平穩性)的機制。
針對上述問題,本文提出了一種全頻帶與子頻帶融合模型FullSubNet。通過大量的前期實驗,將FullSubNet設計成全頻帶模型和子頻帶模型的串聯。簡而言之,全頻帶模型的輸出是子頻帶模型的輸入。通過有效的聯合訓練,對兩種模型進行了聯合優化。FullSubNet可以捕獲全局(全頻帶)上下文,同時保留對訊號平穩性進行建模和關注局部頻譜模式的能力。像子帶模型一樣,FullSubNet仍然滿足實時需求,並且可以在合理的延遲內利用未來的資訊。我們在DNS挑戰(INTERSPEECH 2020)數據集上評估FullSubNet。實驗結果表明,FullSubNet顯著優於子帶模型[17]和參數量較大的純全帶模型,說明子帶資訊和全帶資訊是互補的。所提出的融合模型可以有效地集成它們。此外,我們還比較了在DNS挑戰中排名靠前的方法的性能,結果表明,我們的客觀性能指標優於它們。
2 方法
我們用短時傅立葉變換(STFT)域表示語音訊號:
$$公式1:X(t, f)=S(t, f)+N(t, f)$$
其中$X(t, f)$,$S(t, f)$,$N(t, f)$分別代表帶噪語音、純凈語音 和干擾雜訊 的 複數值。$t=1, …, T$為時間幀,$f=0, …, F-1$為頻點。
本文只研究去噪任務,目標是抑制雜訊$N(t, f)$,並恢復語音訊號S(t, f)。我們提出了一個全頻帶和子頻帶融合模型來完成這一任務,包括一個純全頻帶模型$$和G_{full}一個純子頻帶模型$G_{sub}$。基本工作流程如圖1所示。接下來,我們將詳細介紹每個部分。

圖1所示。提出的的FullSubNet圖。矩形中的第二行描述了當前階段數據的維數,例如,1 (F)表示一個F維向量。F (2N + 1)表示F獨立(2N + 1)維向量
2.1 輸入
先前的工作 [4, 5, 11, 17] 已經證明幅度譜特徵可以提供關於全頻段全局頻譜、子帶局部頻譜和訊號平穩性的關鍵線索。 因此,我們使用帶噪語音的全頻帶幅度譜特徵:
$$公式2:\mathbf{X}(t)=[|X(t, 0)|, \cdots,|X(t, f)|, \cdots,|X(t, F-1)|]^{T} \in \mathbb{R}^{F}$$
我們將其序列化為:
$$公式3:\tilde{\mathbf{X}}=(\mathbf{X}(1), \cdots, \mathbf{X}(t), \cdots, \mathbf{X}(T))$$
作為全頻帶模型$G_{full}$的輸入。 然後,$G_{full}$可以捕獲全局上下文資訊並輸出一個大小與$\tilde{X}$相同的譜embedding,有望為後面的子帶模型$G_{sub}$提供補充資訊。
子帶模型$G_{sub}$根據帶噪語音中子帶訊號的語音平穩性和編碼後的局部譜 和 全帶模型的輸出 預測頻率方向的純凈語音目標。取時頻點$|X(t, f)|$及其相鄰的$2*N$個時頻點作為子帶單元。$N$是每測考慮的相鄰頻率數。對於邊界頻率,當$f-N<0$或$f+N>F-1$,使用圓形傅里葉頻率。我們將子帶單元和全帶模型的輸出連接起來,表示為$G_{full}(|X(t, f)|)$,作為子帶模型$G_{sub}$的輸入
$$公式4:\begin{aligned}
\mathrm{x}(t, f)=&[|X(t, f-N)|, \cdots,|X(t, f-1)|,|X(t, f)|\\
&|X(t, f+1)|, \cdots,|X(t, f+N)| \\
&\left.G_{\text {full }}(|X(t, f)|)\right]^{T} \in \mathbb{R}^{2 N+2}
\end{aligned}$$
對於頻率$f$, $G_{sub}$的輸入序列為
$$公式5:\widetilde{\mathrm{x}}(f)=(\mathrm{x}(1, f), \cdots, \mathrm{x}(t, f), \cdots, \mathrm{x}(T, f))$$
在該序列中,訊號隨時間軸的時間變換反映了訊號的平穩性,這是一個區分語音和相關的平穩雜訊的有效線索。雜訊子帶譜(由2N + 1頻率組成)及其時間動態提供了局部頻譜模式,可通過專門的子帶模型學習得到。雖然訊號平穩性線索和局部模式實際上也存在於全頻帶模型$G_{full}$的輸入中,但是,它們沒有被全頻帶模型$G_{full}$專門的學習到。因此,子帶模型$G_{sub}$仍然學習與全帶模型$G_{full}$相關的一些額外且不同的資訊。同時,全頻帶模型$G_{full}$的輸出提供了子頻帶模型$G_{sub}$未看到的一些補充資訊。
由於全頻帶頻譜特徵$X(f)$包含$F$個頻率,我們最終為$G_{sub}$生成$F$個獨立的輸入序列,每個序列的維數為$2N+2$。
2.2 學習目標
毫無疑問,相位的精確估計可以提供更多的聽覺感知品質改善,特別是在低信噪比(SNR)條件下。然而,相位被包裹在$-\pi~\pi$中,並且具有混亂的數據分布,這使得不容易估計。與之前的工作[11,17]一樣,我們採用複數理想比率掩模(cIRM)作為模型的學習目標,而不是直接估計相位。按照[10],我們在訓練中使用雙曲正切來壓縮cIRM,在推理中使用逆函數來解壓縮掩碼(K=10,C=0.1)。對於一個時頻點,我們將cIRM表示為$y(t,f)\in R^2$。子帶模型將頻率$f$作為輸入序列$\tilde{x}(f)$,然後預測cIRM序列
$$公式6:\widetilde{\mathbf{y}}(f)=(\mathbf{y}(1, f), \cdots, \mathbf{y}(t, f), \cdots, \mathbf{y}(T, f))$$
2.3 模型框架
圖1顯示了FullSubNet的架構。FullSuNet中的全頻帶和子頻帶模型具有相同的模型結構,包括兩個堆疊的單向LSTM層和一個線性(完全連接)層。全頻帶模型的LSTM每層包含512個隱藏單元,並使用ReLU作為輸出層的激活函數。全頻帶模型在每個時間步長輸出一個$F$維向量,每個頻率對應一個元素。然後將子帶單元與該矢量頻率逐次連接,形成F個獨立的輸入樣本(如式4所示)。根據我們之前的實驗,子帶模型不需要像全帶模型那樣大,因此LSTM每層使用384個隱藏單元。根據[10]的設置,子帶模型的輸出層不使用激活函數。值得注意的是,所有的頻率共享一個唯一的子頻帶網路(及其參數)。在訓練過程中,考慮到LSTM記憶容量有限,採用等長序列生成輸入-目標序列對。
為了使模型更易於優化,必須對輸入序列進行規範化,以使輸入振幅相等。對於全頻帶模型,我們根據經驗計算全頻帶序列$\tilde{X}$上的幅度譜特徵的平均值,並將輸入序列歸一化為$\frac{\bar{x}}{\mu_{full}}$。子帶模型獨立處理頻率。對於頻率$f$,我們計算輸入序列$\tilde{x}(f)$上的平均值$\mu_{sub}(f)$,並將輸入序列歸一化為$\frac{\bar{x}(f)}{\mu_{sub}(f)}$。
在實時推理階段,我們通常使用累積歸一化方法[18,19],即每次使用所有可用幀計算用于歸一化的平均值。然而,在實際的實時語音增強系統中,語音訊號最初通常是無聲的,這意味著語音訊號的起始部分大部分是無效的。在這項工作中,為了更好地展示 FullSubNet 網的性能而不考慮規範化問題,我們直接使用在整個測試剪輯上計算的$\mu_{full}$和$\mu_{sub}(f)$來在推理過程中進行歸一化。
與 [17] 中提到的方法相同,我們提出的方法支援輸出延遲,這使模型能夠在合理的小延遲內探索未來資訊。 如圖1所示,為了推斷$y(t-\tau )$,未來的時間步長,也就是說$x(t-\tau+1),…,x(t)$作為在輸入序列(就像圖1所示)。
3 實驗設置
3.1 數據集
我們在DNS Challenge (INTERSPEECH 2020)數據集上評估了FullSubNet[16]。clean speech set包括2150名說話人的500多小時片段。雜訊數據集包含150個類別超過180個小時的片段。為了充分利用數據集,我們在模型訓練過程中通過動態混合來模擬語音-雜訊混合。具體地說,在每個訓練階段開始之前,75%的乾淨語音與
(1)多通道脈衝響應資料庫[20]中隨機選擇的室內脈衝響應(RIR)混合,混響時間(T60)為0.16秒、0.36秒和0.61秒。
(2) 混響挑戰數據集[21],具有三個混響時間0.3秒、0.6秒和0.7秒。
然後,通過將乾淨語音(其中75%為混響)和隨機信噪比在-5到20 dB之間的雜訊混合,動態生成語音-雜訊混合。經過十個epoch訓練後,該模型顯示的總數據超過5000小時。DNS挑戰提供了一個公開可用的測試數據集,包括兩類合成剪輯,即無混響和有混響。每個類別有150個雜訊片段,信噪比分布在0 ~ 20 dB之間。我們使用這個測試數據集進行評估。
3.2 實現
訊號被轉換到STFT域使用漢寧窗,窗長為512(32 ms)和256幀移。我們使用PyTorch來實現FullSubNet。Adam優化器的使用學習率為0.001。訓練序列長度設置為T = 192幀(約3秒)。根據DNS Challenge (INTERSPEECH 2020)的實時性要求,我們設置$\tau$ = 2,利用兩個未來幀來增強當前幀,並使用16*2 = 32ms的前瞻性。如[17],我們在FullSubNet中為子帶模型的輸入頻率的每一側設置了15個相鄰頻率。
3.3 基準線
為了驗證全頻帶和子頻帶融合方法的有效性,我們使用與FullSubNet相同的實驗設置和學習目標(cIRM)與以下兩種模型進行了比較。
- 子帶模型[17]:子帶模型在DNS-Challenge中取得了非常有競爭力的性能(實時跟蹤的第四名)。為了公平地比較性能,就像訓練FullSubNet一樣,我們在訓練期間使用動態混合。
- 全頻帶模型:我們構建一個純全頻帶模型,它包含三個LSTM層,每層有512個隱藏單元。全頻帶模型的架構,即LSTM層的堆棧,實際上被廣泛應用於語音增強,如[6,26]。該模型比所提出的融合模型略大,因此比較是足夠公平的。
除了這兩種模型,我們還比較了在DNS挑戰(INTERSPEECH 2020)中排名第一的方法,包括NSNet[22]、DTLN[23]、convc – tasnet[24]、DCCRN[19]和PoCoNet[25]。
4 結果
4.1 與基準線比較
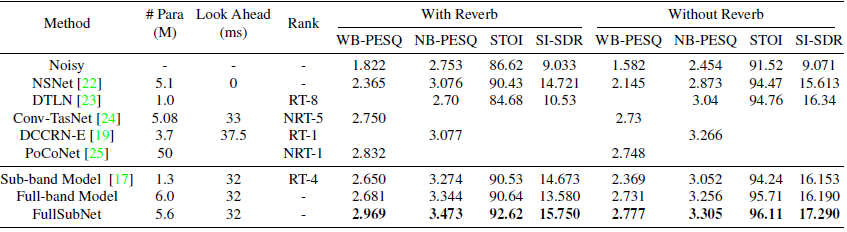
在表 1 的最後三行,我們比較了子帶模型、全帶模型和 FullSubNet 的性能。 #表中的Para和Look Ahead分別代表模型的參數量和使用的未來資訊的長度。 With Reverb 是指測試數據集中的帶噪語音不僅有雜訊,而且有一定程度的混響,這大大增加了語音增強的難度。沒有混響意味著測試數據集中的帶噪語音只有噪音。為了公平比較,這三個模型使用相同的訓練目標 (cIRM)、實驗設置和使用的未來資訊的長度。
從表中我們可以發現,大部分全頻段模型的評估分數都優於子頻段模型,因為全頻段模型使用更大的網路來利用寬頻資訊。有趣的是,相對於全頻段模型,子頻段模型對於 With Reverb 數據似乎更有效,因為全頻段模型對於 With Reverb 的優勢小於無 Reverb 的優勢。這表明子帶模型通過關注窄帶頻譜的時間演化,有效地模擬了混響效應。這可能是由於混響效應的跨頻帶相關性實際上遠低於訊號頻譜的跨頻帶相關性。
關於FullSubNet:(1)雖然子帶模型的性能已經非常有競爭力,但是在集成了全帶模型(由兩個LSTM層和一個線性層堆疊而成)之後,模型性能得到了極大的提升。這種改進表明全局頻譜模式和長距離跨帶依賴性對於語音增強至關重要。 (2)FullSubNet的性能也明顯超過了全頻段模型。我們必須首先指出,這種改進並非來自使用更多參數。事實上,FullSubNet(兩層全帶LSTM加兩層子帶LSTM)的參數甚至比全帶模型(三層全帶LSTM)還要少。 FullSubNet 在集成子帶模型後,繼承了子帶模型的獨特能力,即利用訊號平穩性和局部頻譜模式,以及對混響效果進行建模的能力。 FullSubNet 相對於全波段模型的明顯優勢表明,子波段模型所利用的資訊確實沒有被全波段模型學習到,這是對全波段模型的補充。總的來說,這些結果證明所提出的融合模型成功地整合了全頻帶和子頻帶技術的優點。
4.2 與最先進的方法進行比較
在表1中,除了說明FullSubNet可以有效地整合兩種互補的模型外,我們還將其與DNS Challenge (INTERSPEECH 2020)中排名第一的方法進行了性能比較。表格中的「Rank」列表示是否支援實時處理和挑戰排名。例如,RT-8表示實時(RT)軌道的第8位。NRT-1是指非實時(NRT)軌道的第一個位置。
在表1中,NSNet是DNS挑戰的官方基準線方法,它使用一個緊湊的RNN以單幀輸入、單幀輸出的方式增強雜訊短時間語音頻譜。我們使用asteroid工具包中提供的DNS挑戰配方來實現和訓練NSNet。使用[17]中提到的方法生成訓練數據。在表中,無論哪種指標,我們提出的方法在所有指標上都大大超過了NSNet。
在DNS挑戰的主觀聽力測試中,DTLN、convtasnet、DCCRN、PoCoNet排名第一。為了保證比較的公平性,我們直接引用他們的原始論文成績。表格中空白的位置表示在原論文中沒有報告相應的分數。DTLN[23]具有實時處理能力。它將STFT操作和學習的分析和合成基礎結合成一個不到100萬個參數的堆疊網路。[24]提出了一個低延遲的Conv-TasNet。 Conv-TasNet [18]是一種應用廣泛的時域音頻分離網路,具有較大的計算複雜度。因此,低延遲的Conv-TasNet 無法滿足實時性要求。DCCRN[19]模擬了卷積遞歸網路內部的複數運算。它贏得了實時賽道的第一名。PoCoNet[25]是一種採用頻率-位置嵌入的卷積神經網路。此外,採用半監督方法對帶噪數據集進行預增強,以增加會話訓練數據。它贏得了非實時賽道的第一名。這些方法涵蓋了大量基於深度學習的高級語音增強技術,在一定程度上代表了當前的先進水平。這些方法的原始論文提供了在本工作中使用的同一測試集上的評價結果,但並沒有提供本工作中使用的所有指標。可以看出,在這個有限的數據集上,所提出的融合模型取得了比所有這些模型都要好得多的客觀得分。PoCoNet的性能與我們的很接近,但它是非實時模型,具有更大的網路(約50m參數)。FullSubNet提供了一種新的全頻帶/子頻帶融合模型,這可能不會與這些最先進的模型中所採用的先進技術相衝突。因此,值得期待的是,適當地結合它們,可以進一步提高語音增強能力。
在計算複雜度方面,在基於Intel Xeon E5-2680 v4的虛擬四核CPU (2.4 GHz)上測試,提出的模型(PyTorch實現)的1幀STFT (32 ms)處理時間為10.32 ms,明顯滿足實時性要求。稍後,我們將開放源程式碼和預訓練模型,並在https: //github.com/haoxiangsnr/FullSubNet上顯示一些增強的音頻剪輯。
表1。DNS挑戰測試數據集上的WB-PESQ [MOS]、NB-PESQ [MOS]、STOI[%]和SI-SDR [dB]的性能
5 總結
在本文中,我們提出了一個全頻帶和子頻帶融合模型,稱為FullSubNet,用於實時單通道語音增強。該模型融合了全頻帶模型和子頻帶模型的優點,既能捕獲全局(全頻帶)光譜資訊,又能捕獲長距離跨頻帶依賴關係,同時保留了訊號平穩性建模和局部光譜模式識別的能力。在DNS挑戰(INTERSPEECH 2020)測試數據集上,我們證明了子頻帶資訊和全頻帶資訊是互補的,FullSubNet可以有效地集成它們。在DNS挑戰中,我們還與一些排名前列的方法進行了性能比較,結果表明FullSubNet優於這些方法。
6 參考文獻
[1] Dario Rethage, Jordi Pons, and Xavier Serra, A wavenet for speech denoising, in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5069 5073.
[2] A. Pandey and D. Wang, Tcnn: Temporal convolutional neural network for real-time speech enhancement in the time domain, in ICASSP 2019 – 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 6875 6879.
[3] Xiang Hao, Xiangdong Su, Zhiyu Wang, Hui Zhang, and Batushiren, UNetGAN: A Robust Speech Enhancement Approach in Time Domain for Extremely Low Signal-to-Noise Ratio Condition, in Proc. Interspeech 2019, 2019, pp. 1786 1790.
[4] Y. Xu, J. Du, L. Dai, and C. Lee, A regression approach to speech enhancement based on deep neural networks, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 1, pp. 7 19, 2015.
[5] D. Wang and J. Chen, Supervised speech separation based on deep learning: An overview, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 10, pp. 1702 1726, 2018.
[6] Jitong Chen and DeLiangWang, Long short-term memory for speaker generalization in supervised speech separation, The Journal of the Acoustical Society of America, vol. 141, no. 6, pp. 4705 4714, 2017.
[7] H. Erdogan, J. R. Hershey, S. Watanabe, and J. Le Roux, Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks, in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 708 712.
[8] DeLiang Wang, On Ideal Binary Mask As the Computational Goal of Auditory Scene Analysis, in Speech Separation by Humans and Machines, Pierre Divenyi, Ed., pp. 181 197.Kluwer Academic Publishers, Boston, 2005.
[9] Lei Sun, Jun Du, Li-Rong Dai, and Chin-Hui Lee, Multipletarget deep learning for lstm-rnn based speech enhancement, in 2017 Hands-free Speech Communications and Microphone Arrays (HSCMA). IEEE, 2017, pp. 136 140.
[10] D. S. Williamson, Y. Wang, and D. Wang, Complex ratio masking for monaural speech separation, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 3, pp. 483 492, 2016.
[11] Xiaofei Li and Radu Horaud, Narrow-band Deep Filtering for Multichannel Speech Enhancement, arXiv preprint arXiv:1911.10791, 2019.
[12] Timo Gerkmann and Richard C Hendriks, Unbiased mmsebased noise power estimation with low complexity and low tracking delay, IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 4, pp. 1383 1393, 2011.
[13] Xiaofei Li, Laurent Girin, Sharon Gannot, and Radu Horaud, Non-stationary noise power spectral density estimation based on regional statistics, in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016, pp. 181 185.
[14] Yariv Ephraim and David Malah, Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator, IEEE Transactions on acoustics, speech, and signal processing, vol. 32, no. 6, pp. 1109 1121, 1984.
[15] Israel Cohen and Baruch Berdugo, Speech enhancement for non-stationary noise environments, Signal processing, vol. 81, no. 11, pp. 2403 2418, 2001.
[16] Chandan KA Reddy, Ebrahim Beyrami, Harishchandra Dubey, Vishak Gopal, Roger Cheng, Ross Cutler, Sergiy Matusevych, Robert Aichner, Ashkan Aazami, Sebastian Braun, et al., The interspeech 2020 deep noise suppression challenge: Datasets, subjective speech quality and testing framework, arXiv preprint arXiv:2001.08662, 2020.
[17] Xiaofei Li and Radu Horaud, Online monaural speech enhancement using delayed subband lstm, arXiv preprint arXiv:2005.05037, 2020.
[18] Y. Luo and N. Mesgarani, Conv-tasnet: Surpassing ideal time frequency magnitude masking for speech separation, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256 1266, 2019.
[19] Yanxin Hu, Yun Liu, Shubo Lv, Mengtao Xing, Shimin Zhang, Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie, Dccrn: Deep complex convolution recurrent network for phase-aware speech enhancement, arXiv preprint arXiv:2008.00264, 2020.
[20] Elior Hadad, Florian Heese, Peter Vary, and Sharon Gannot, Multichannel audio database in various acoustic environments, in 2014 14th International Workshop on Acoustic Signal Enhancement (IWAENC). IEEE, 2014, pp. 313 317.
[21] Keisuke Kinoshita, Marc Delcroix, Sharon Gannot, Emanu el AP Habets, Reinhold Haeb-Umbach, Walter Kellermann, Volker Leutnant, Roland Maas, Tomohiro Nakatani, Bhiksha Raj, et al., A summary of the reverb challenge: state-of-the-art and remaining challenges in reverberant speech processing research, EURASIP Journal on Advances in Signal Processing, vol. 2016, no. 1, pp. 7, 2016.
[22] Y. Xia, S. Braun, C. K. A. Reddy, H. Dubey, R. Cutler, and I. Tashev, Weighted speech distortion losses for neuralnetwork- based real-time speech enhancement, in ICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 871 875.
[23] Nils L Westhausen and Bernd T Meyer, Dual-signal transformation lstm network for real-time noise suppression, arXiv preprint arXiv:2005.07551, 2020.
[24] Yuichiro Koyama, Tyler Vuong, Stefan Uhlich, and Bhiksha Raj, Exploring the Best Loss Function for DNN-Based Lowlatency Speech Enhancement with Temporal Convolutional Networks, arXiv:2005.11611 [cs, eess], Aug. 2020, arXiv: 2005.11611.
[25] Umut Isik, Ritwik Giri, Neerad Phansalkar, Jean-Marc Valin, Karim Helwani, and Arvindh Krishnaswamy, Poconet: Better speech enhancement with frequency-positional embeddings, semi-supervised conversational data, and biased loss, arXiv preprint arXiv:2008.04470, 2020.
[26] Felix Weninger, Hakan Erdogan, Shinji Watanabe, Emmanuel Vincent, Jonathan Le Roux, John R Hershey, and Bj orn Schuller, Speech enhancement with lstm recurrent neural networks and its application to noise-robust asr, in International Conference on Latent Variable Analysis and Signal Separation. Springer, 2015, pp. 91 99.

