Spark-On-Yarn
- 2021 年 11 月 9 日
- 筆記
原理

兩種模式
client-了解
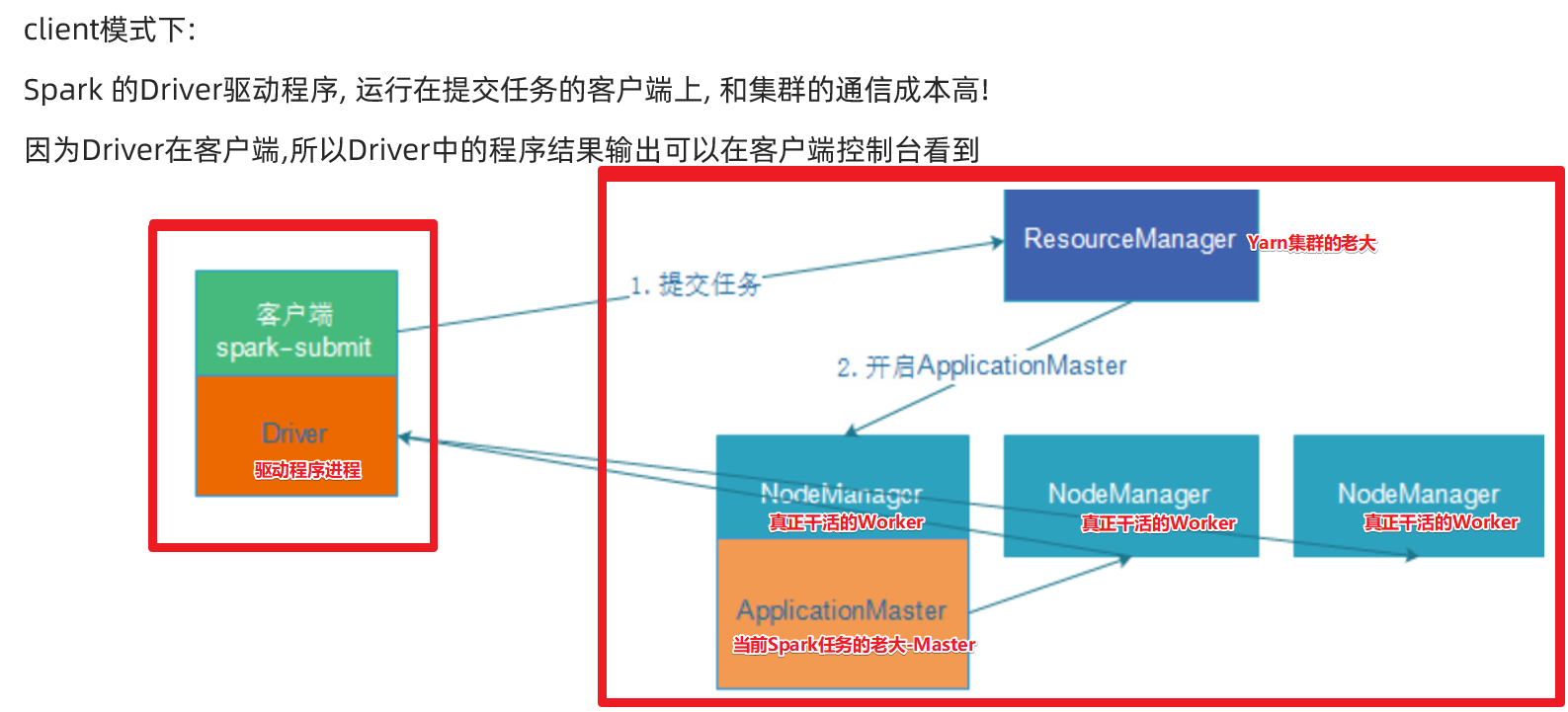
cluster模式-開發使用
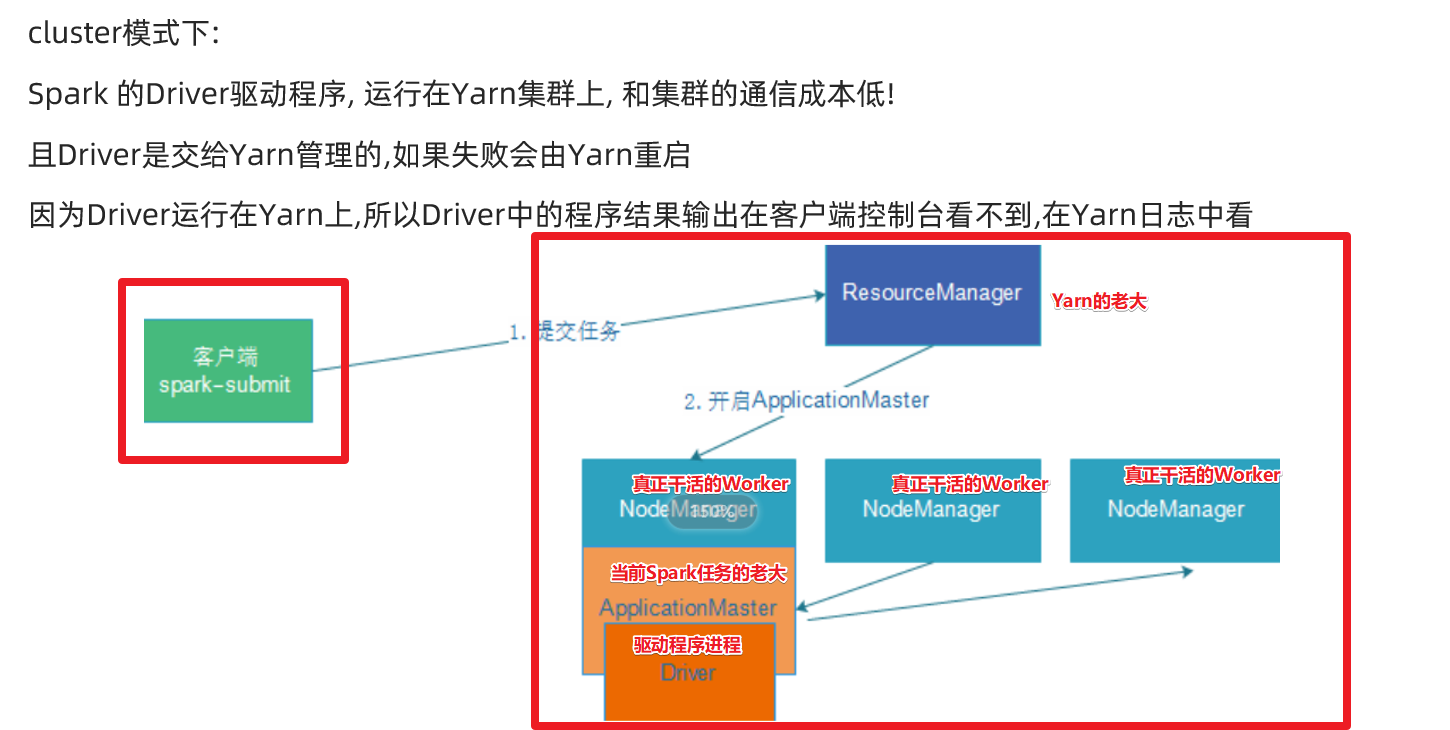
操作
1.需要Yarn集群
2.歷史伺服器
3.提交任務的的客戶端工具-spark-submit命令
4.待提交的spark任務/程式的位元組碼–可以使用示常式序
spark-shell和spark-submit
- 兩個命令的區別
spark-shell:spark應用互動式窗口,啟動後可以直接編寫spark程式碼,即時運行,一般在學習測試時使用
spark-submit:用來將spark任務/程式的jar包提交到spark集群(一般都是提交到Yarn集群)
Spark程式開發
導入依賴
<dependencies>
<dependency>
<groupid>org.apache.spark</groupid>
<artifactid>spark-core_2.11</artifactid>
<version>2.4.5</version>
</dependency>
<dependency>
<groupid>org.scala-lang</groupid>
<artifactid>scala-library</artifactid>
<version>2.11.12</version>
</dependency>
<dependency>
<groupid>org.scala-lang</groupid>
<artifactid>scala-compiler</artifactid>
<version>2.11.12</version>
</dependency>
<dependency>
<groupid>org.scala-lang</groupid>
<artifactid>scala-reflect</artifactid>
<version>2.11.12</version>
</dependency>
<dependency>
<groupid>mysql</groupid>
<artifactid>mysql-connector-java</artifactid>
<version>5.1.49</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupid>org.apache.maven.plugins</groupid>
<artifactid>maven-compiler-plugin</artifactid>
<version>3.1</version>
<configuration>
<source>1.8
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupid>org.scala-tools</groupid>
<artifactid>maven-scala-plugin</artifactid>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
案例
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo02WordCount {
def main(args: Array[String]): Unit = {
/**
* 1、去除setMaster("local")
* 2、修改文件的輸入輸出路徑(因為提交到集群默認是從HDFS獲取數據,需要改成HDFS中的路徑)
* 3、在HDFS中創建目錄
* hdfs dfs -mkdir -p /spark/data/words/
* 4、將數據上傳至HDFS
* hdfs dfs -put words.txt /spark/data/words/
* 5、將程式打成jar包
* 6、將jar包上傳至虛擬機,然後通過spark-submit提交任務
* spark-submit --class Demo02WordCount --master yarn-client spark-1.0.jar
* spark-submit --class cDemo02WordCount --master yarn-cluster spark-1.0.jar
*/
val conf: SparkConf = new SparkConf
conf.setAppName("Demo02WordCount")
//conf.setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("/spark/data/words/words.txt")
// 2、將每一行的單詞切分出來
// flatMap: 在Spark中稱為 運算元
// 運算元一般情況下都會返回另外一個新的RDD
val flatRDD: RDD[String] = fileRDD.flatMap(_.split(","))
//按照單詞分組
val groupRDD: RDD[(String, Iterable[String])] = flatRDD.groupBy(word => word)
val words: RDD[String] = groupRDD.map(kv => {
val key = kv._1
val size = kv._2.size
key + "," +size
})
// 使用HDFS的JAVA API判斷輸出路徑是否已經存在,存在即刪除
val hdfsConf: Configuration = new Configuration()
hdfsConf.set("fs.defaultFS", "hdfs://master:9000")
val fs: FileSystem = FileSystem.get(hdfsConf)
// 判斷輸出路徑是否存在
if (fs.exists(new Path("/spark/data/words/wordCount"))) {
fs.delete(new Path("/spark/data/words/wordCount"), true)
}
// 5、將結果進行保存
words.saveAsTextFile("/spark/data/words/wordCount")
sc.stop()
}
}


