Spark記錄(一):Spark全景概述
一、Spark是什麼
Spark是一個開源的大數據處理引擎。
二、Spark的主要組件如下圖所示:
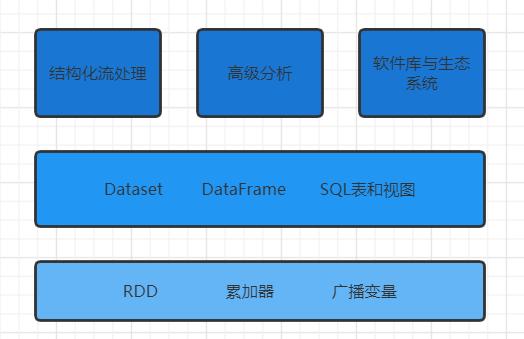
三、Spark運行時架構
Spark共有三種運行模式:本地模式、集群模式、客戶端模式。
生產環境基本都是用集群模式。集群模式需要用到集群管理器,三個核心的集群管理器為:Spark自帶的獨立集群管理器、Yarn、Mesos。
集群模式運行時,單個Spark任務的架構圖為:
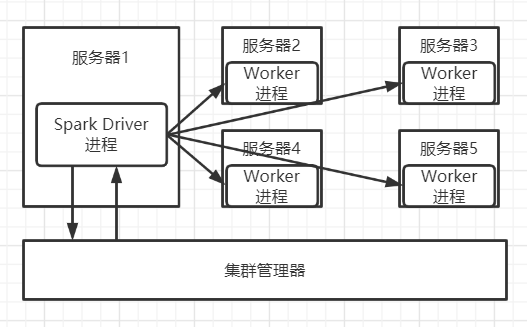
其中集群管理器負責分配/回收伺服器資源和監控整個Spark任務是否完成。
四、IDEA環境準備
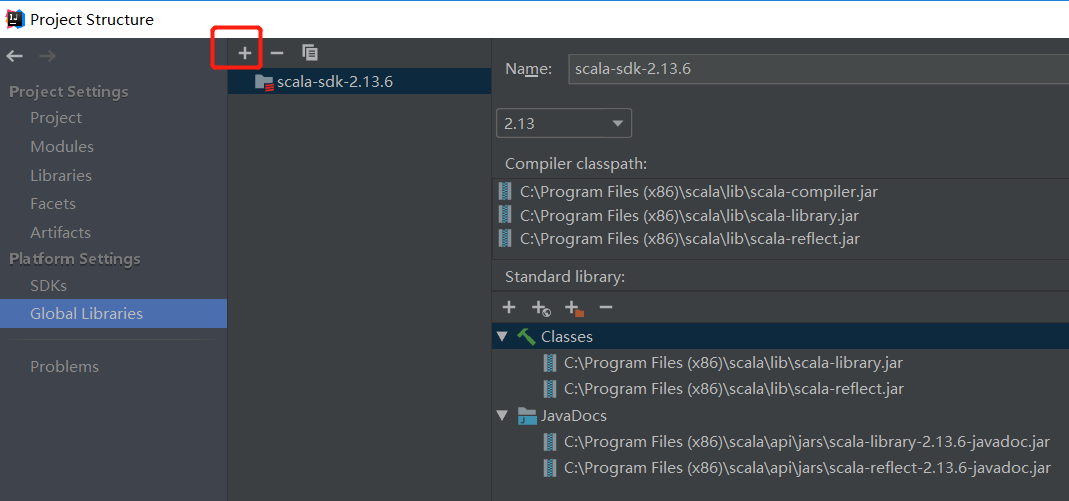
1、準備Scala的SDK
若用Scala開發的話,需做此步。下載Scala的msi文件本地安裝之後,在IDEA中如下圖所示的加號位處導入Scala的SDK目錄,導入之後會如下圖所示:
2、在Plugins中安裝名叫Scala的插件
自行安裝即可
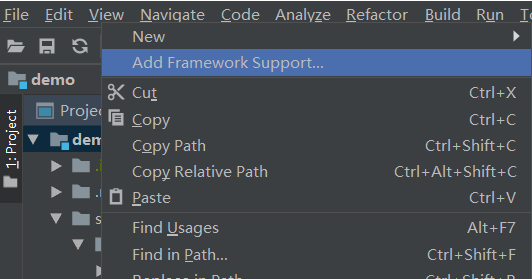
3、配置項目支援Scala
選中項目最高級目錄後右鍵,選擇【Add Framework Support】,然後在裡面勾選Scala選項
如此之後,便可以在包裡面右鍵new Scala類了:
4、導入maven依賴
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
版本用的是:
<spark.version>3.2.0</spark.version>
<scala.version>2.13</scala.version>
5、編寫個簡單的腳本運行
def main(args: Array[String]): Unit = { val ss = SparkSession.builder().appName("localhost").master("local[*]").getOrCreate() val df1 = ss.range(2, 100, 2).toDF() val df2 = ss.range(2, 100, 4).toDF() val df11 = df1.repartition(5) val df21 = df2.repartition(6) val df12 = df11.selectExpr("id * 5 as id") val df3 = df2.join(df12, "id") val df4 = df3.selectExpr("sum(id)") df4.collect().foreach(println(_)) df4.explain() }
運行結果:

Intersting Number!
explain列印出來的邏輯計劃,有時間再詳細解讀。
另附:
1、下載歷史Hadoop版本的地址:
//archive.apache.org/dist/hadoop/core/
2、下載winutils.exe、hadoop.dll文件的地址:
//blog.csdn.net/ytp552200ytp/article/details/107223357

