【程式碼更新】單細胞分析實錄(21): 非負矩陣分解(NMF)的R程式碼實現,只需兩步,啥圖都有
1. 起因
之前的程式碼(單細胞分析實錄(17): 非負矩陣分解(NMF)程式碼演示)沒有涉及到python語法,只有4個python命令行,就跟Linux下面的ls grep一樣的。然鵝,有幾個小夥伴不會命令行,所以我決定再改寫一下,把命令行都放到R下面運行。
2. 嘗試
2.1 一開始,我的想法是教大家在R裡面調用python,需要提前下載好anaconda和一些python包
然而想了想在Windows上安裝python包可能對大家不是很友好,有些包很難裝,我之前也弄了很久。考慮到這次更新是針對桌面版Rstudio用戶,故沒有採用。
2.2 最終,我採用的方案是,使用Rstudio Server,也就是網頁版Rstudio
這樣做有幾個好處:
- 直接和雲伺服器連接,伺服器下載python包和R包都很容易(雲伺服器剛買,下血本)
- 我提前配置好運行環境,用戶只需上傳數據,分析數據,下載數據即可。
程式碼方面也更加簡化:
- 我盡量減少了人工處理的時間,主要分析程式碼只有兩行
如果你之前在我這兒拿過程式碼,可以直接找我要更新的程式碼。此外,如果因為之前的程式碼涉及命令行,你操作起來有困難,可以找我開Rstudio Server的賬戶 (高端玩家就別了,伺服器配置比較低,就夠幾個人用的那種)。
3. 注意
- 我會提前安裝可能用到的R包,所以不用重複安裝,直接library就可以
- 請大家及時下載結果文件,以免丟失;也請大家在做完分析後,刪除表達數據,伺服器存儲空間不是很大
- 每個帳號只保留半個月時間,若想再次使用,可以聯繫我再開一個帳號
- 有任何問題可以微信或者郵箱問我
接下來簡單介紹一下,使用方法
登錄
打開我給你的鏈接,輸入用戶名和密碼即可登錄
之後就可以看見Rstudio的介面了

然後確保你的家目錄下面有圖中框出來的幾個文件,並點擊進入count_data文件夾
上傳數據
點擊upload上傳數據

運行程式碼
主要是3.R中的step1和step2兩個函數

library(reticulate)
use_condaenv(condaenv = "cnmf_env", required = T,conda = "/home/hsy/miniconda3/bin/conda")
py_config() #如果顯示cnmf_env環境裡面的python就OK
source("1.R")
step1(dir_input = "count_data",dir_output = "res1",k=3:5,iteration = 50) #這裡為了演示方便,取值都比較小
source("2.R")
step2(dir_input = "res1",dir_output = "res2",dir_count = "count_data",usage_filter = 0.03,top_gene = 30,cor_min = 0,cor_max = 0.6)
查看結果
step2之後,會在res2文件夾中生成結果文件
sampleID_program.usage.norm.txt和sampleID_program.Zscore.txt
是NMF分解表達矩陣得到的兩個矩陣
program_topngene.txt
這是所有program的前幾十個基因,一般會放到文件附表
program_pearson_cor.complete.heatmap.pdf
program之間的相關性熱圖
cor_heatmap_data.txt
用來畫上圖的數據
program_topngene_enrichment.xlsx
program_topngene_enrichment_order.csv
這兩個都是對program前幾十個基因的富集分析結果,這兩個文件可以用來輔助我們理解program,其中第二個文件和相關性熱圖的順序一致,看起來更方便
sampleID_program_gene.heatmap.pdf
用來驗證在這個樣本中,program找得對不對,其實就是看program的表達,一般看program的前幾十個基因
sampleID_data_heatmap.txt
用來畫上面那個熱圖的數據
program之間的相關性熱圖

某個樣本中program的表達

下載結果
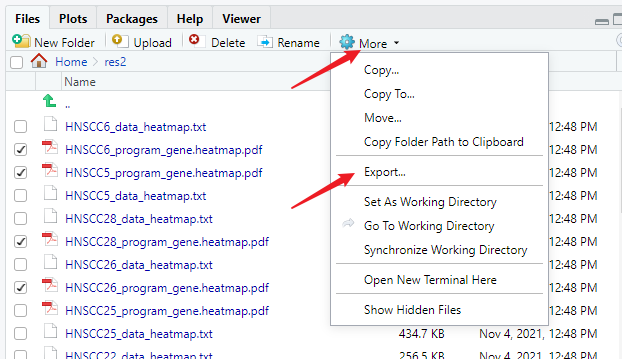
選中你想導出的文件,點擊more,再點擊Export就可以了
至此,公眾號僅有的兩篇付費教程都已更新完畢~
因水平有限,有錯誤的地方,歡迎批評指正!


