Flink 的運行架構詳細剖析
1. Flink 程式結構
Flink 程式的基本構建塊是流和轉換(請注意,Flink 的 DataSet API 中使用的 DataSet 也是內部流 )。從概念上講,流是(可能永無止境的)數據記錄流,而轉換是將一個或多個流作為一個或多個流的操作。輸入,併產生一個或多個輸出流。

Flink 應用程式結構就是如上圖所示:
Source: 數據源,Flink 在流處理和批處理上的 source 大概有 4 類:基於本地集合的 source、基於文件的 source、基於網路套接字的 source、自定義的 source。自定義的 source 常見的有 Apache kafka、RabbitMQ 等,當然你也可以定義自己的 source。
Transformation:數據轉換的各種操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select等,操作很多,可以將數據轉換計算成你想要的數據。
Sink:接收器,Flink 將轉換計算後的數據發送的地點 ,你可能需要存儲下來,Flink 常見的 Sink 大概有如下幾類:寫入文件、列印出來、寫入 socket 、自定義的 sink 。自定義的 sink 常見的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定義自己的 sink。
2. Flink 並行數據流
Flink 程式在執行的時候,會被映射成一個 Streaming Dataflow,一個 Streaming Dataflow 是由一組 Stream 和 Transformation Operator 組成的。在啟動時從一個或多個 Source Operator 開始,結束於一個或多個 Sink Operator。
Flink 程式本質上是並行的和分散式的,在執行過程中,一個流(stream)包含一個或多個流分區,而每一個 operator 包含一個或多個 operator 子任務。操作子任務間彼此獨立,在不同的執行緒中執行,甚至是在不同的機器或不同的容器上。operator 子任務的數量是這一特定 operator 的並行度。相同程式中的不同 operator 有不同級別的並行度。
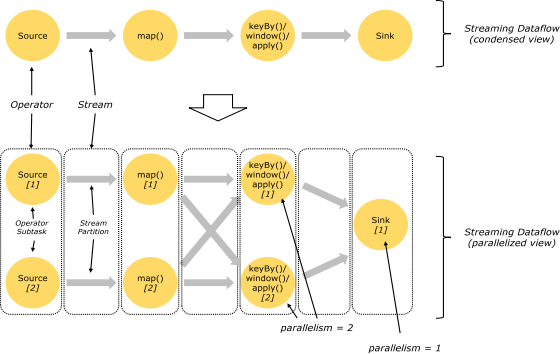
一個 Stream 可以被分成多個 Stream 的分區,也就是 Stream Partition。一個 Operator 也可以被分為多個 Operator Subtask。如上圖中,Source 被分成 Source1 和 Source2,它們分別為 Source 的 Operator Subtask。每一個 Operator Subtask 都是在不同的執行緒當中獨立執行的。一個 Operator 的並行度,就等於 Operator Subtask 的個數。上圖 Source 的並行度為 2。而一個 Stream 的並行度就等於它生成的 Operator 的並行度。
數據在兩個 operator 之間傳遞的時候有兩種模式:
One to One 模式:兩個 operator 用此模式傳遞的時候,會保持數據的分區數和數據的排序;如上圖中的 Source1 到 Map1,它就保留的 Source 的分區特性,以及分區元素處理的有序性。
Redistributing (重新分配)模式:這種模式會改變數據的分區數;每個一個 operator subtask 會根據選擇 transformation 把數據發送到不同的目標 subtasks,比如 keyBy()會通過 hashcode 重新分區,broadcast()和 rebalance()方法會隨機重新分區;
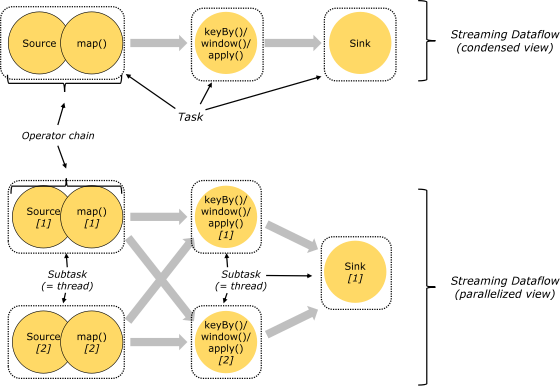
3. Task 和 Operator chain
Flink 的所有操作都稱之為 Operator,客戶端在提交任務的時候會對 Operator 進行優化操作,能進行合併的 Operator 會被合併為一個 Operator,合併後的 Operator 稱為 Operator chain,實際上就是一個執行鏈,每個執行鏈會在 TaskManager 上一個獨立的執行緒中執行。
4. 任務調度與執行
-
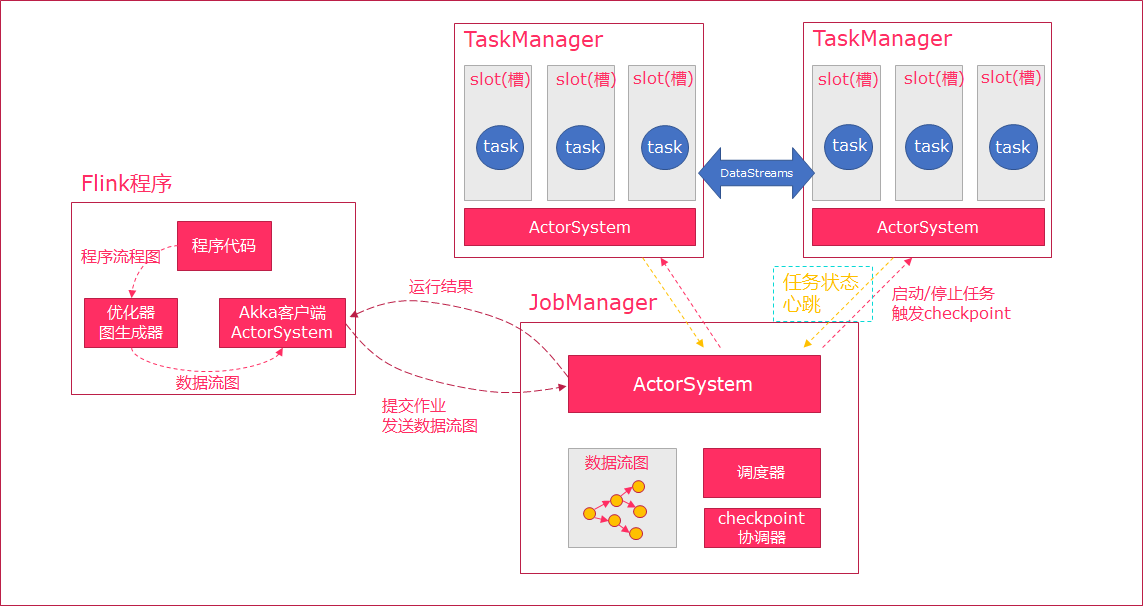
當 Flink 執行 executor 會自動根據程式程式碼生成 DAG 數據流圖;
-
ActorSystem 創建 Actor 將數據流圖發送給 JobManager 中的 Actor;
-
JobManager 會不斷接收 TaskManager 的心跳消息,從而可以獲取到有效的 TaskManager;
-
JobManager 通過調度器在 TaskManager 中調度執行 Task(在 Flink 中,最小的調度單元就是 task,對應就是一個執行緒);
-
在程式運行過程中,task 與 task 之間是可以進行數據傳輸的。
Job Client:
- 主要職責是提交任務, 提交後可以結束進程, 也可以等待結果返回;
- Job Client 不是 Flink 程式執行的內部部分,但它是任務執行的起點;
- Job Client 負責接受用戶的程式程式碼,然後創建數據流,將數據流提交給 Job Manager 以便進一步執行。 執行完成後,Job Client 將結果返回給用戶。
JobManager:
- 主要職責是調度工作並協調任務做檢查點;
- 集群中至少要有一個 master,master 負責調度 task,協調 checkpoints 和容錯;
- 高可用設置的話可以有多個 master,但要保證一個是 leader, 其他是 standby;
- Job Manager 包含 Actor System、Scheduler、CheckPoint 三個重要的組件;
- JobManager 從客戶端接收到任務以後, 首先生成優化過的執行計劃, 再調度到 TaskManager 中執行。
TaskManager:
- 主要職責是從 JobManager 處接收任務, 並部署和啟動任務, 接收上游的數據並處理;
- Task Manager 是在 JVM 中的一個或多個執行緒中執行任務的工作節點;
- TaskManager 在創建之初就設置好了 Slot, 每個 Slot 可以執行一個任務。
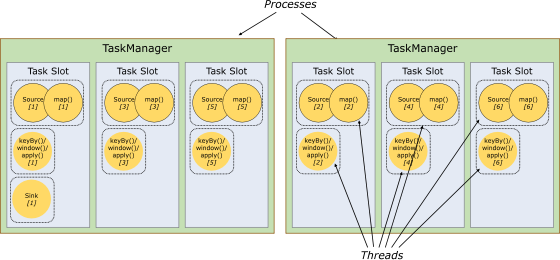
5. 任務槽和槽共享
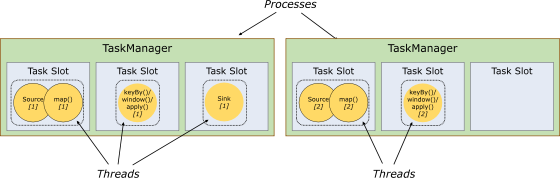
每個 TaskManager 是一個 JVM 的進程, 可以在不同的執行緒中執行一個或多個子任務。
為了控制一個 worker 能接收多少個 task。worker 通過 task slot 來進行控制(一個 worker 至少有一個 task slot)。
1) 任務槽
每個 task slot 表示 TaskManager 擁有資源的一個固定大小的子集。
flink 將進程的記憶體進行了劃分到多個 slot 中。
圖中有 2 個 TaskManager,每個 TaskManager 有 3 個 slot 的,每個 slot 佔有 1/3 的記憶體。
記憶體被劃分到不同的 slot 之後可以獲得如下好處:
-
TaskManager 最多能同時並發執行的任務是可以控制的,那就是 3 個,因為不能超過 slot 的數量。
-
slot 有獨佔的記憶體空間,這樣在一個 TaskManager 中可以運行多個不同的作業,作業之間不受影響。
2) 槽共享
默認情況下,Flink 允許子任務共享插槽,即使它們是不同任務的子任務,只要它們來自同一個作業。結果是一個槽可以保存作業的整個管道。允許插槽共享有兩個主要好處:
-
只需計算 Job 中最高並行度(parallelism)的 task slot,只要這個滿足,其他的 job 也都能滿足。
-
資源分配更加公平,如果有比較空閑的 slot 可以將更多的任務分配給它。圖中若沒有任務槽共享,負載不高的 Source/Map 等 subtask 將會佔據許多資源,而負載較高的窗口 subtask 則會缺乏資源。
-
有了任務槽共享,可以將基本並行度(base parallelism)從 2 提升到 6.提高了分槽資源的利用率。同時它還可以保障 TaskManager 給 subtask 的分配的 slot 方案更加公平。