簡單樹
樹的定義及其概念
什麼是樹?
(圖片源自網路)

差不多了
我們給他加工一下
去掉大量樹葉抽取主幹樹枝
倒立並美化一下
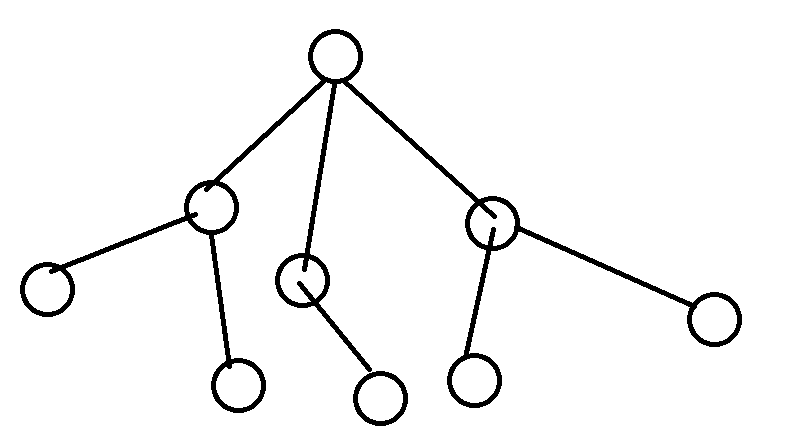
就變成了一棵樹
(美化完還是好醜啊)
我們可以發現原來的「樹根」到了上面,因為我給他倒立了。
然後從樹根可以擴散出主幹,每條主幹又可以擴散出幾條分支,分支又可以擴散出分支……最後不能擴散的分支連接的就是葉子。
如果我們讓樹根是第一層(你喜歡的話第零層也可以),那麼所有和樹根直接相連的點就是第二層。
除了樹根之外所有和第二層相連的點構成第三層。
除了第二層的點之外所有和第三層相連的點構成第四層(我誠實我沒畫出來)
……
所以你就可以發現,除了第\(n-1\)層的點之外所有和第\(n\)層連接的點構成第\(n+1\)層
這就是樹的基本定義(反正又不考這麼簡單的概念自己理解記憶就好了)
樹還有一些專有名詞。
比如說剛剛提到的樹根
你會發現,在樹中任意一個結點(就是那個圈)都可以作為樹根,按照上面的關係確定各個結點對應的層,就可以構成一棵樹。所以說一棵無根樹(是指沒有指定根的樹,不是沒有根的樹)的形態不是固定的
我們現在選定一個結點為根,然後確定每個結點的層數
樹根一般會叫做第一層,有時也會叫做第零層。本文中採用第一種。
我們規定和這個結點直接相連的,層數比這個結點大1的所有結點叫做當前結點的兒子。
那麼對應的當前結點就是這些結點的父親。
比如:
- 樹根是所有第二層的點的父親。
- 第二層的點的父親是樹根。
- 第二層的點是樹根的兒子。
- 樹根的兒子是第二層的所有點。
樹的深度,就是樹的層數。如果樹最深那一層是第\(n\)層,那麼樹的深度就是n(根節點是第1層)。如果根節點是第0層,那麼深度就應該是\(n+1\)
我們又可以發現,對於樹中任意一個點,他的兒子數量不是確定的。可以沒有(葉子結點),可以有一個,可以有兩個,可以有很多個。
然而除了樹根之外,所有結點都有且只有唯一一個確定的父親。根結點沒有父親。
然後一棵樹中每個點肯定都有一條連向父親的邊,除了根結點沒有父親。
所以一棵有\(n\)個點樹裡面有\(n-1\)條「樹枝」,也就是邊
反過來也是成立的,一個有\(n\)個點\(n-1\)條邊的連通圖一定是一棵樹,滿足每個點有且只有一個父親的性質(除了樹根)。
又因為樹根可以任意取,所以做題的時候一般以1號結點作為樹根。(題目有特殊說明就看題目)
樹的父親表示法
如果我們用一個數組\(fa_i\)來表示結點\(i\)的父親
然後為了方便我們令\(\forall 0<i\leq n, fa_i<i\),所以樹根就應該是1號節點,再定義樹根的父親為0號節點(也就是不存在)
為什麼要這樣方便定義?因為我們沒有存儲兒子的資訊,想要找到兒子就只能一個個遍歷,每次都要遍歷n個結點,很不爽。所以我們索性讓兒子的索引號一定排在父親後面,每次從父親開始搜索,搜到\(fa_j=i\)就可以說明結點j是i的兒子。
個人覺得這種方法很不爽
所以我要超綱
樹的孩子兄弟表示法
上面的方法太浪費時間了。
我們可以發現一旦一棵樹的形態確定了下來,那麼父親的兒子就確定了
我們要保存這個節點的兒子,因為題目經常這樣搞
但是每個節點的兒子數量是不一定的,我們如果統一開數組。。。很浪費空間。
我們參考一下鏈表
我們可以發現,父節點可以只保存第一個兒子的資訊,然後讓第一個兒子保存第二個兒子的資訊,第二個保存第三個……
那麼每個節點只需要保存:我的下一個兄弟,我的第一個兒子
空間上變成了兩倍,但是時間上快了很多很多
(質的飛越)
這就是大名鼎鼎的鏈式前向星
struct Edge
{
/*
這裡用邊來表示指向的節點
@param: int v 這條邊指向的節點的編號
int u 指向下一個兒子的邊的編號(可以找到下一個兄弟)
*/
int u,v;
};
// 用來表示節點的第一個兒子,具體大小按需要自定
int head[];
void add(int a,int b)
{
/*
用來增加一條從a連向b的邊,即a是b的父親
@param: int a 父親 int b 兒子
@return: void
*/
static int tot=0; // 表示使用這個函數加的邊的總數,那麼這個tot+1就是新邊的編號了
edge[++tot]=(Edge){head[a],b}; // 新的邊指向b,下一個(上一個?差不多啦反正能找到所有的兄弟就可以了)兄弟的邊的編號
head[a]=tot; // 更新a的第一個兒子為b,也就是指向b的邊,也就是新的邊,就是更新後的tot
}
我們在加邊的時候要注意只能是父親連向兒子,不能兒子逆向連回父親。
光說不做總不好,我們用題來說話
很明顯,城堡是無根樹,我們就令根為1
然後建樹(主要理解這個步驟)
然後樹上dp
設\(f_{i,j}\)表示在\(i\)節點放\((j=1)\)或不放\((j=0)\)時,這棵子樹滿足所有邊都被看見的最小需要的士兵數量。
子樹是什麼……額……對於一棵樹,任意一個節點和他的後代(兒子,兒子的兒子,兒子的兒子的兒子……)所構成的數(也一定是一棵樹)叫做子樹,這個節點叫做子樹的根。跟子集是差不多的概念。但子樹一般默認是非空真子樹。
很明顯,如果\(i\)是葉子節點,那麼子樹\(i\)(以\(i\)為根的子樹)只有\(i\)一個節點,沒有邊,所以
\(f_{i,0}=f_{i,1}=0\),並不需要士兵。這也是遞歸的初始條件。
我們再來想想遞推的結束條件,應該是整棵樹滿足條件所需要的最小士兵數量,也就是根為\(1\)的子樹的\(f\),即
\(\min(f_{1,0},f_{1,1})\),所需要的士兵就是整棵樹滿足條件所需要的最小士兵數,也就是遞推邊界
(不知道你們怎麼理解反正我覺得動態規劃就是遞推)
然後再來想想狀態轉移方程
對於一個節點\(i\),如果是葉子結點,按照上面方式初始化。如果不是葉子結點,那麼我們就分類討論:
- 這個節點放置士兵
那麼他的兒子放不放士兵都隨便,看怎樣便宜怎樣來。 - 這個節點不放置士兵
那麼他的所有兒子都必須放置士兵,代價(花費)就是所以兒子放置士兵,所有以兒子為根的子樹都滿足性質的最小代價和
寫成方程就長這樣:
f_{i,0}=\sum f_{j,1}
f_{i,1}=1+\sum \min(f_{j,0},f_{j,1})
\]
然後我們來討論一下建樹
首先用鏈式前向星存雙向邊,然後用dfs初始化,處理出每個節點的父親。如果這條邊是指向父親的話就跳過或者直接刪除這條邊。否則這條邊就是指向兒子的
然後就。。。不停遞推
#include <bits/stdc++.h>
using namespace std;
struct Edge
{
int u,v;
}edge[3000]; // 有1500個點,1499條邊,建雙向邊就需要開3000數組
int head[1500]; // 儲存每個節點連出去的第一條邊(第一個兒子
int n,fa[1500],a,b,k;
int dp[1500][2];
void add(int a,int b)
{
/*
增加一條單向邊
@param: int a 單向邊的起點
int b 單向邊的終點
@return: void
*/
static int tot=0;
edge[++tot]=(Edge){head[a],b}; head[a]=tot;
}
void init(int k,int f)
{
/*
處理一個結點
@param: int k 當前要處理的結點
int f 這個結點的父親
@return: void
*/
fa[k]=f;
dp[k][0]=0; dp[k][1]=1; // 初始化,葉子結點不會執行下面的循環
for(int j=head[k];j;j=edge[j].u)
{
if(edge[j].v==fa[k]) continue;
init(edge[j].v,k); // 指向的不是父親,先處理這個兒子,然後再維護自己
dp[k][0]+=dp[edge[j].v][1];
dp[k][1]+=std::min(dp[edge[j].v][0],dp[edge[j].v][1]);
}
}
int main()
{
std::cin>>n;
for(int i=1;i<=n;++i)
{
std::cin>>a>>k;
while(k--)
{
std::cin>>b;
add(a,b);
add(b,a); // 建立雙向邊,正著反著都調用一次
}
}
init(1,-1);
std::cout<<std::min(dp[1][0],dp[1][1])<<std::endl;
return 0;
}
這裡init函數是跳過版本的。如果需要調用的情況比較多,可以考慮把指向父親的邊刪掉。
比如這樣,通過鏈表的刪除全部的方法刪除。
void init(int k,int f)
{
/*
處理一個結點
@param: int k 當前要處理的結點
int f 這個結點的父親
@return: void
*/
fa[k]=f;
dp[k][0]=0; dp[k][1]=1; // 初始化,葉子結點不會執行下面的循環
while(edge[head[k]].v==fa[k]) head[k]=edge[head[k]].u;
for(int j=head[k];j;j=edge[j].u) // 從第一條邊開始遍歷所有的邊。便利到最後j是0就表示遍歷完了退出循環。
{
while(edge[edge[j].u].v==fa[k]) edge[j].u=edge[edge[j].u].u;
init(edge[j].v,k); // 指向的不是父親,先處理這個兒子,然後再維護自己
dp[k][0]+=dp[edge[j].v][1];
dp[k][1]+=std::min(dp[edge[j].v][0],dp[edge[j].v][1]);
}
}
但是你會發現用在這道題上面是TLE的
這是因為這道題有0號結點。有些結點的父親就是0,然而如果這條邊是0號邊也就是不存在,這個邊指向的點也是0,就會在while裡面往複
所以我們加一個維護
void init(int k,int f)
{
/*
處理一個結點
@param: int k 當前要處理的結點
int f 這個結點的父親
@return: void
*/
fa[k]=f;
dp[k][0]=0; dp[k][1]=1; // 初始化,葉子結點不會執行下面的循環
while(edge[head[k]].v==fa[k]&&head[k]) head[k]=edge[head[k]].u;
for(int j=head[k];j;j=edge[j].u)
{
while(edge[edge[j].u].v==fa[k]&&edge[j].u) edge[j].u=edge[edge[j].u].u;
init(edge[j].v,k); // 指向的不是父親,先處理這個兒子,然後再維護自己
dp[k][0]+=dp[edge[j].v][1];
dp[k][1]+=std::min(dp[edge[j].v][0],dp[edge[j].v][1]);
}
}
emmmm這裡你聽不懂沒關係……反正是超綱的。
二叉樹
我們再來看看這棵樹
emmm不是這幅
如果我們類似圖的定義來定義一下樹的度
就會有:
結點的度:一個結點的兒子的數量
樹的度:樹中所有結點的度的最大值
所以上面是度為3的樹
那麼二叉樹是什麼呢?
就是一棵度為2的樹
那麼就會有,對於這棵二叉樹中的任意一個結點,他兒子的數量不是0就是1或者2
既然這樣,那我們乾脆就叫任意一個結點的兩個兒子分別為左兒子和右兒子(專業術語)
如果這個結點沒有左兒子,就說左兒子為空
顯然,葉子結點左右兒子都為空
二叉樹會滿足一些性質:
在根節點為第1層的情況下:
- 第\(i\)層最多有\(2^{i-1}\)個結點
- 深度為\(h\)的二叉樹最多有\(2^{h}-1\)個結點
- 若在任意一棵二叉樹中,有\(n_0\)個葉子節點,有\(n_2\)個度為2的節點,則必有\(n_0=n_2+1\)
證明:對於一棵二叉樹,\(n_0,n_2\)的值都是由他的左右兒子決定的。
特殊地,如果這個結點沒有左右兒子,那麼就是葉子結點,\(n_0=1,n_2=0\),滿足條件
當這個結點不是葉子結點的時候:
定義這個結點\(rt\)的子樹分別為\(A,B\),且\(A,B\)如果不為空,則滿足上述性質
當其中一個子樹為空的時候,這裡假設\(B\)為空,有\(rt_0=A_0,rt_2=A_2\),因為\(A\)滿足性質,所以\(rt\)也滿足性質
當兩個子樹都不為空的時候,有\(rt_0=A_0+B_0,rt_2=A_2+B_2+1\)(因為兩個子樹都不為空,\(rt\)也是一個度為2的結點)
\(rt_0=A_0+B_0=A_2+1+B_2+1=A_2+B_2+1+1=rt_2+1\)
所以無論\(rt\)是什麼結點,葉子結點也好,不是葉子結點也好,他都滿足性質。
所以當\(rt\)為根節點的時候,滿足性質,表現為整棵二叉樹滿足性質。 - 具有\(n\)個結點的二叉樹最小深度為\(\lfloor log_2n\rfloor+1\)
滿二叉樹
對於所有非葉子結點度都為2,且葉子結點都在同一層的二叉樹,我們叫做滿二叉樹(在不增加層數的情況下你插入不了結點了,就是滿了)
百度定義:滿二叉樹:如果一棵二叉樹只有度為0的結點和度為2的結點,並且度為0的結點在同一層上,則這棵二叉樹為滿二叉樹。
然後我們可以給滿二叉樹的結點編號
一層一層編下來。
首先
第一層根節點給1
第二層只有兩個節點,一個是1的左兒子,一個是1的右兒子。分別給2和3
第三層有四個結點,分別是2的左右兒子,3的左右兒子。對於2的左兒子按照順序給4,右兒子給5。3的左兒子6,右兒子7
。。。。。。
第\(i\)層有\(2^{i-1}\)個結點,他們的編號分別是\(2^{i-1},2^{i-1}+1\dots 2^{i}-1\)
這個方法叫做順序編號。就是先按照層的順序,再按照層中從左到右的順序給結點進行編號。
然後根據推理(反正我推不出來)觀察,發現,對於編號為\(j\)的非葉子結點,它的左兒子編號為\(2j\),右兒子編號為\(2j+1\)
在C++中可以使用位運算符來加快運算速度
j<<1; // 等價於j*2
j<<1|1; // 等價於j*2+1
完全二叉樹
是一棵殘缺的滿二叉樹,但是滿足順序編號所有的結點在與滿二叉樹中對應的結點編號相同。
我覺得百度講的比我清楚qwq
二叉樹的遍歷
遍歷,就是按照一定順序輸出二叉樹的結點所儲存的資訊而不是編號
首先插播一條超綱知識:
對於所有的樹(所有的圖,樹是一種特殊的圖),我們可以採用以下兩種遍歷方式:
深度優先遍歷
就是一路dfs深搜下去,每搜索到一個結點就輸出資訊並標記已訪問(樹不會重複訪問結點所以不用標記)。搜到葉子結點就返回,否則就dfs他的所有兒子
這種遍歷方法輸出的特點是同一子樹內的結點會在一起被遍歷到(如果你保存到數組裡就是保存在連續的一段)
寫成程式碼長成這樣
void dfs(int k)
{
/*
深度優先遍歷
@param: int k 當前遍歷到的結點編號
@return: void
*/
print(val[k]); // 用專門的輸出函數來輸出這個結點的數據(如果是普通數據可以直接輸出,不必調用函數)
static int tot=0;
dat[++tot]=val[k]; // 保存到數組
for(int j=head[i];j;j=edge[j].u) // 鏈式前向星遍歷兒子
{
// 如果訪問過就跳過,這裡vis是定義在一些神奇的地方(函數外啊,函數內啊隨便。反正我沒定義(逃)。。。)
if(vis[edge[j].v]) continue; // 圖的寫法,樹可以改成if(edge[j].v==fa[k])
dfs(edge[j].v); // 沒有訪問過,就遍歷
}
}
廣度優先遍歷
顧名思義就是用廣度優先搜索演算法遍歷的,也叫做層次遍歷/層序遍歷(隨便叫吧)
用queue的bfs實現的。每次從隊頭拿出一個結點,輸出資訊並標記訪問(樹不會重複訪問所以不用標記),然後把這個結點的所有兒子都放進隊列中。重複執行直到隊列為空。
這種遍歷方法輸出的特點是同一層的結點會在一起被遍歷到(如果保存到數組就是保存在連續的一段。)
void bfs(int rt)
{
/*
廣度優先遍歷
@param: int rt 樹的根
@return: void
*/
queue<int> q;
q.push(rt); // 根節點入隊
static int tot=0;
while(!q.empty())
{
int i=q.front(); q.pop(); // 取出隊頭結點
print(val[i]); // 輸出
dat[++tot]=val[i]; // 保存
for(int j=head[i];j;j=edge[j].v) // 搜索所有兒子
{
if(vis[edge[j].v]) continue; // 訪問過就跳過,圖的寫法,樹可以改成if(edge[j].v==fa[k])
q.push(edge[j].v); // 沒有訪問過就入隊
}
}
}
上面的遍歷在二叉樹中都可以用
現在來講講二叉樹專有的遍歷方式
首先給一棵來自百度百科的二叉樹的圖:
(如果圖片顯示不出來請複製上述網址粘貼到地址欄中查看)
這棵樹的深度優先遍歷可能是FCADBEHGM
廣度優先遍歷可能是FECGHADMB
具體取決於你建樹時的細節操作和輸出遍歷時的操作
(也就是實現方法的不同會導致遍歷結果的不同,但是一定滿足遍曆本身的性質)
但是接下來講的三種遍歷出來的序列是確定的:(因為你確定了左右兒子)
先序遍歷/前序遍歷
是基於深度優先遍歷的遍歷
每次遍歷,先輸出自己,然後輸出左兒子的遍歷序列,再輸出右兒子的遍歷序列
也就是遵循根左右原則
void dfs(int k)
{
/*
輸出先序遍歷
@param: int k 當前遍歷到的結點
@return: void
*/
print(val[k]);
// 定義lson[k],rson[k]分別表示k的左右兒子
if(lson[k]) dfs(lson[k]); // 如果有左兒子才輸出左兒子的先序遍歷
if(rson[k]) dfs(rson[k]); // 如果有右兒子才輸出右兒子的先序遍歷
}
如上圖,先序遍歷是FCADBEHGM
中序遍歷
是基於深度優先遍歷的遍歷
每次遍歷,先輸出左兒子的遍歷序列,再輸出自己,最後輸出右兒子的遍歷序列
也就是遵循左根右原則
void dfs(int k)
{
/*
輸出中序遍歷
@param: int k 當前遍歷到的結點
@return: void
*/
if(lson[k]) dfs(lson[k]);
print(val[k]);
if(rson[k]) dfs(rson[k]);
}
如上圖,中序遍歷是ACBDFHEMG
後序遍歷
是基於深度優先遍歷的遍歷
每次遍歷,先輸出左兒子的遍歷序列,再輸出右兒子的遍歷序列,最後輸出自己
也就是遵循左右根原則
void dfs(int k)
{
/*
輸出後序遍歷
@param: int k 當前遍歷到的結點
@return: void
*/
if(lson[k]) dfs(lson[k]);
if(rson[k]) dfs(rson[k]);
print(val[k]);
}
如上圖,後序遍歷是ABDCHMGEF
先序遍歷,中序遍歷,後序遍歷的應用
我們可以知道,對於確定的二叉樹,它的這三種遍歷的序列都是唯一的。
反過來不成立,對於確定的某個序列,二叉樹的形態不是唯一的。
但是,如果有確定的先序遍歷和中序遍歷或者確定的中序遍歷和後序遍歷,就可以確定一棵二叉樹的形態
但是只有先序遍歷和後序遍歷就不行,這個時候題目就會問你:中序遍歷可能是,你只需要排除掉不可能的剩下的就是可能的了。
(至於為什麼我也不知道)
改自2013騰訊筆試題:(不能複製。。。我手敲好累)
已知二叉樹的先序遍歷為FBACDEGH,中序遍歷為ABDCEFGH,則後序遍歷為
A: ADECBHGF
B: ABDECGHF
C: GHADECBF
D: HGADECBF
E(我自己加的): ABCDEF
首先這道題,有一個很白痴的問題(但是我一開始就跳進去了)
E是可以直接排掉的!!!
所以求可能的中序遍歷的時候這也是一種要排除的選項。
(當時分析了好久)
然後我們看看這個先序遍歷先
FBACDEGH
他告訴了我們什麼
首先這個數有8個結點,非空(廢話)。所以根據根左右原則,可以知道樹根為F,那麼BACDEGH就是左右子樹的遍歷序列。無論是哪個子樹,無論形態長什麼樣,我們都可以知道B肯定是某個子樹的根。
然後我們再看看中序遍歷
ABDCEFGH
根節點F在中間,然後就由左根右知道F左邊的ABDCE組成左子樹的中序遍歷序列,所以左子樹由這5個結點組成(注意不是構成,現在還不知道具體形態),右子樹由GH這2個結點組成
然後左子樹的根是B,那麼ABDCE又可以分成兩段:A,DCE這時我們就知道,B的左兒子是A,右兒子是DCE組成的子樹
那麼這個右兒子是怎樣的呢?
我們看看先序遍歷中DCE的位置,是CDE,也就是C是根節點,那麼DCE又被分成了兩段:D,E所以C的左兒子是D,右兒子是E
那麼ABDCE這棵左子樹的形態我們就確定了
同樣我們可以確定GH這棵右子樹
先序遍歷GH,中序遍歷GH,所以G是根,H是右子樹
綜上,我們用(rt,A,B)表示一個結點\(rt\)的左子樹\(A\),右子樹\(B\)(對我懶得畫圖)
那麼這棵樹就可以表示成
(F,
(B, A, (C, D, E)),
(G, 0, H)
)
所以後序遍歷就是ADECBHGF
所以選A
明白了吧?


