pyinstaller和wordcloud和jieba的使用案列
一、pyinstaller庫
1、簡介
pyinstaller庫:將腳本程式轉變為可執行(.exe)格式的第三方庫
注意:需要在.py文件所在目錄進行以下命令,圖標擴展名是.ico
2、格式:
pyinstaller -F 文件.py
pyinstaller -i 圖標名.ico 文件名.py
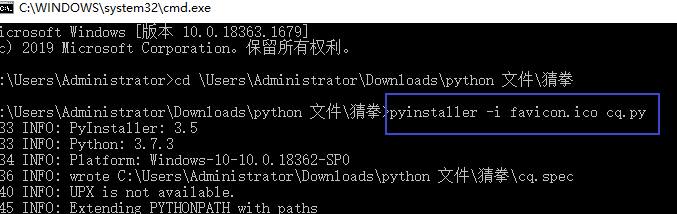
生成後的.exe文件放在dict文件夾里

二、wordcloud庫
1、詞雲介紹
詞雲以詞語為基本單元,根據其在文本中出現的頻率設計不同大小一形成視覺上不同的效果,形成關鍵詞雲層或關鍵詞渲染,從而使讀者一眼就可以讀到文本重點。wordcloud的核心是WordCloud類,所有功能都封裝在這個類中,使用時需要先實例化一個WordCloud類的對象,並調用。
2、需要安裝的模組
pip install wordcloud
pip install imageio
注意:字體文件需要指定路徑,或者和文件放在同一目錄
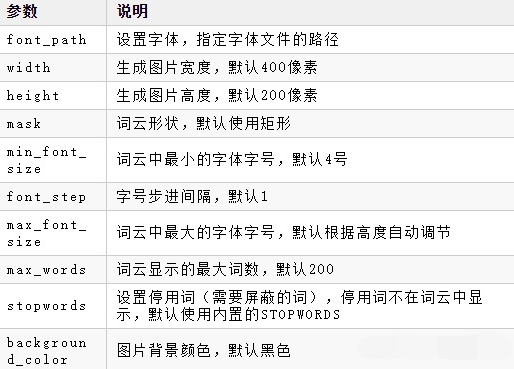
3、wordcloud常用的函數
WordCloud().generate(文本) 將字元串轉化成詞雲
WordCloud().to_file(文件路徑) 將詞雲生成文件
4、案列
點擊查看程式碼
from wordcloud import WordCloud #使用WordCloud類
import imageio
# from scipy.misc import imread 其中imread模組在scipy中已經被棄用,建議使用imageio
mask = imageio.imread('C:/Users/wordcloud/hzw.png')
#圖片轉換成數組形式,一般使用png圖片,windows中路徑要麼用/要麼要\\因為一條\代表轉義字元
with open('C:/Users/wordcloud/hzw.txt','r',encoding='utf-8') as f:
txt = f.read()
wordcloud = WordCloud(width=1017,\
height=1097,\
max_words=400,\
max_font_size=80,\
mask=mask,\
font_path='msyh.ttc',\
).generate(txt) #字元串轉化成詞雲
wordcloud.to_file('C:/Users/wordcloud/xhzw.png') #詞雲生成文件
效果展示:

在生成詞雲時,wordcloud默認會以空格或標點為分割符對目標文本進行分詞處理,對於中文文本,分詞處理需要由用戶來完成,可以結合jieba庫一起使用,一般步驟是先將文本分詞處理,然後以空格拼接,再調用。
用法:
words = jieba.lcut(txt)#進准分詞
newtxt = ‘ ‘.join(words) #空格拼接
結合jieba庫的效果

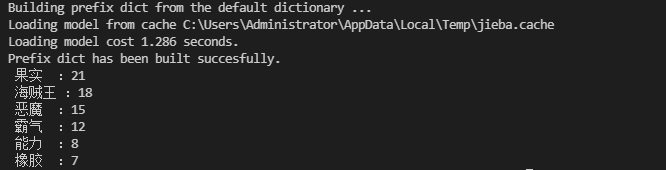
三、jieba庫
1、簡介
通過中文詞庫的方式來識別分詞的
— 利用一個中文詞庫,確定漢字之間的關聯概率
— 通過計算漢字之間的概率,漢字間概率大的組成片語,形成分詞結果
— 除了分詞,用戶還可以添加自定義的片語
2、案列
點擊查看程式碼
from posixpath import commonpath
import jieba
with open('C:/Users/hzw.txt','r',encoding='utf-8') as f:
txt = f.read()
words = jieba.lcut(txt)
counts = {}
bd = [',','。','、',' ']
for word in words:
if word in bd:
continue #如果文本中有標點符號,就跳過
elif len(word)==1: #表示一個字的次遇到就跳過
continue
else:
counts[word]=counts.get(word,0)+1 #將出現過的次記錄次數並寫進字典
items = list(counts.items()) #將字典轉成列表
items.sort(key=lambda x:x[1],reverse=True)
#x可以是任意,[]裡面的數表示對第幾個元素排序,reverse=True表示升序,默認是降序
for i in range(3): #循環三次,只展示排名前三的結果
word,count=items[i] #從元組裡取值
print(f'{word:^5}:{count:<5}') #^居中對齊,保留5個寬度
效果展示