.Net Core中使用ElasticSearch(一)
- 2021 年 10 月 25 日
- 筆記
- .NET Core, elasticsearch, ES
一、安裝配置
在官網下載Es,注意版本號,不同大版本號之間差異很大。我安裝的是7.14.0版本
1.1 安裝成服務
cmd 進入bin目錄下執行
elasticsearch-service.bat install
1.2 安裝插件
ik分詞器,分詞器的版本和ES版本需要一致
elasticsearch-plugin.bat install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.0/elasticsearch-analysis-ik-7.14.0.zip
1.3 配置帳號密碼
修改config目錄下面的elasticsearch.yml文件,在裡面添加如下內容,並重啟。
xpack.security.enabled: true xpack.license.self_generated.type: basic xpack.security.transport.ssl.enabled: true
執行:
elasticsearch-setup-passwords interactive
然後配置每個賬戶密碼。
通過帳號密碼鏈接: //username:[email protected]:9200
二、基礎概念
2.1 文檔元數據
|
節點 |
說明 |
|
_index |
文檔存儲的地方,必須小寫,不能以下劃線開頭,不能包含逗號 |
|
_type |
文檔代表的對象的類,命名可以是大寫或者小寫,但是不能以下劃線或者句號開頭,不應該包含逗號 |
|
_id |
文檔的唯一標識 |
2.2 索引
一個 索引 類似於傳統關係資料庫中的一個 資料庫 ,是一個存儲關係型文檔的地方。事實上,我們的數據被存儲在分片(shards)中,索引只是一個把一個或多個分片分組在一起的邏輯空間。
2.3 文檔
文檔指最頂層結構或根對象序列化的JSON數據(以唯一Id標識並存儲於ES中),相當於關係數據的行。在版本7.0中已經沒有文檔了,統一為「_doc」。
三、數據的物理存儲
ES為什麼能搜索和存儲海量數據呢?是因為它的水平拓展,它內部分將整個數據進行分片,每個分片存儲部分數據。

如圖:將整個數據分為5片,每一片都有一個副本,5個主分片分別存儲在不同節點。每個節點就是一個ElasticSearch實例。
3.1 數據是怎麼存儲到分片中的?
在創建索引時,主分片的數量和其副本的數量已經確定了,當創建文檔時,Es會根據文檔的Id值選擇一個主分片,可能這個主分片,在另一個節點。文檔被發送到主分片和該主分片所有的副分片中。在新建一個文檔的時候, Elasticsearch 如何知道一個文檔應該存放到哪個分片中呢?首先這肯定不會是隨機的,否則將來要獲取文檔的時候我們就不知道從何處尋找了。實際上,這個過程是根據下面這個公式決定的:
shard = hash(routing) % number_of_primary_shards
routing 是一個可變值,默認是文檔的 _id ,也可以設置成一個自定義的值。這就解釋了為什麼我們要在創建索引的時候就確定好主分片的數量 並且永遠不會改變這個數量:因為如果數量變化了,那麼所有之前路由的值都會無效,文檔也再也找不到了。
新建、索引、刪除操作,必須在主分片上完成後才能被複制到相關副分片。
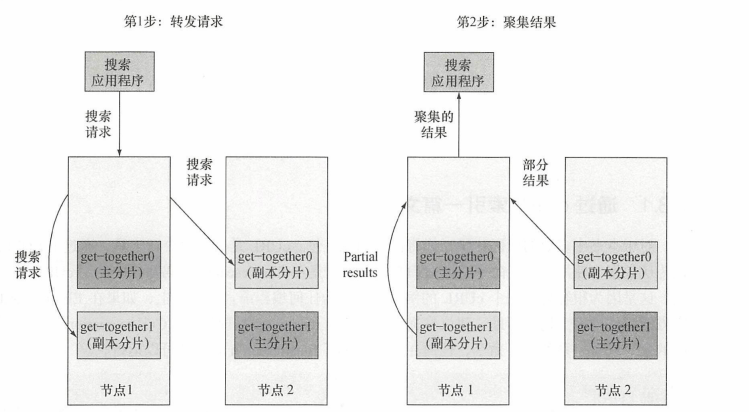
3.2 多個節點查詢的過程
當其中一個節點接收到搜索請求時,會將請求轉發到其他節點,然後將每個節點的結果聚集返回。在默認情況下,搜索請求通過round-robin輪詢機制選中主分片和副分片。
3.3 為什麼ElasticSearch查詢快?
Es為了查詢速度,使用的是倒排索引。假如存儲的一個文檔中Content欄位值為:
1:My nickname is Microheart.
2:Hello Microheart
為了創建倒排索引,我們首先將每個文檔的 content 域拆分成單獨的詞(也就是tokens),創建一個包含所有不重複詞條的排序列表,然後列出每個詞條出現在哪個文檔。
|
my |
1 |
|
nickname |
1 |
|
is |
1 |
|
microheart |
1,2 |
|
hello |
2 |
3.4 相關性
上面的例子,提到了相關性,相關性主要根據下面三個有關:
- 檢索詞頻率:檢索詞在該欄位出現的頻率,出現頻率越高,相關性也越高。 欄位中出現過 5 次要比只出現過 1 次的相關性高。
- 反向文檔頻率:每個檢索詞在索引中出現的頻率,頻率越高,相關性越低。檢索詞出現在多數文檔中會比出現在少數文檔中的權重更低。
- 欄位長度準則:欄位的長度是多少?長度越長,相關性越低。 檢索詞出現在一個短的 title 要比同樣的詞出現在一個長的 content 欄位權重更大。
3.5 映射
域映射:域最重要的屬性是type,就是欄位類型。對於非string的域,只需要設置type
string域映射有兩個重要的屬性 index和 analyzer
Index:控制怎樣索引字元串
- analyzed :首先分析字元串,然後索引它。換句話說,以全文索引這個域。
- not_analyzed:索引這個域,所以它能夠被搜索,但索引的是精確值。不會對它進行分析。
- no:不索引這個域。這個域不會被搜索到。
analyzer:指定分詞器
上面的例子中,為什麼會按照單詞拆詞呢?因為默認不指定分詞器,就是standard分詞器,它會按照英文單詞拆詞。分詞器有:snowball、standard、keyword、ik_smart、ik_max_word。其中ik_smart和ik_max_word是中文的分詞
ES 2.x版本中只有string類型,ES 5.x以後,只有text 和 keyword欄位。
比如一篇部落格,有標題和內容兩個欄位,指定為ik_smart。假如標題為 「.Net Core中使用ElasticSearch」,就會被拆詞為 「net」、「core」、 “中”、「使用」、「elasticsearch」。如果用戶搜索「.net core」,應該對用戶的搜索詞也進行拆詞,拆分為 「net」、「core」,那麼標題就會命中。
/// <summary> /// 標題 /// </summary> [Text(Analyzer = "ik_smart")] public string Title { get; set; } /// <summary> /// 內容 /// </summary> [Text(Analyzer = "ik_smart")] public string Content { get; set; }


