分庫分表利器之Sharding Sphere(深度好文,看過的人都說好)
- 2021 年 10 月 24 日
- 筆記
Sharding-Sphere
Sharding-JDBC 最早是噹噹網內部使用的一款分庫分表框架,到2017年的時候才開始對外開源,這幾年在大量社區貢獻者的不斷迭代下,功能也逐漸完善,現已更名為 ShardingSphere,2020年4⽉16⽇正式成為 Apache 軟體基⾦會的頂級項⽬。
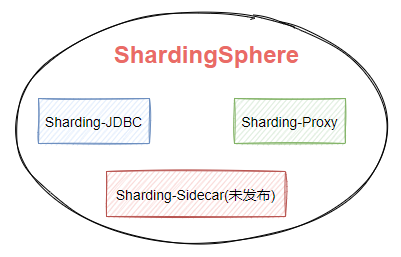
隨著版本的不斷更迭 ShardingSphere 的核心功能也變得多元化起來。如圖7-1,ShardingSphere生態包含三款開源分散式資料庫中間件解決方案,Sharding-JDBC、Sharding-Proxy、Sharding-Sidecar。
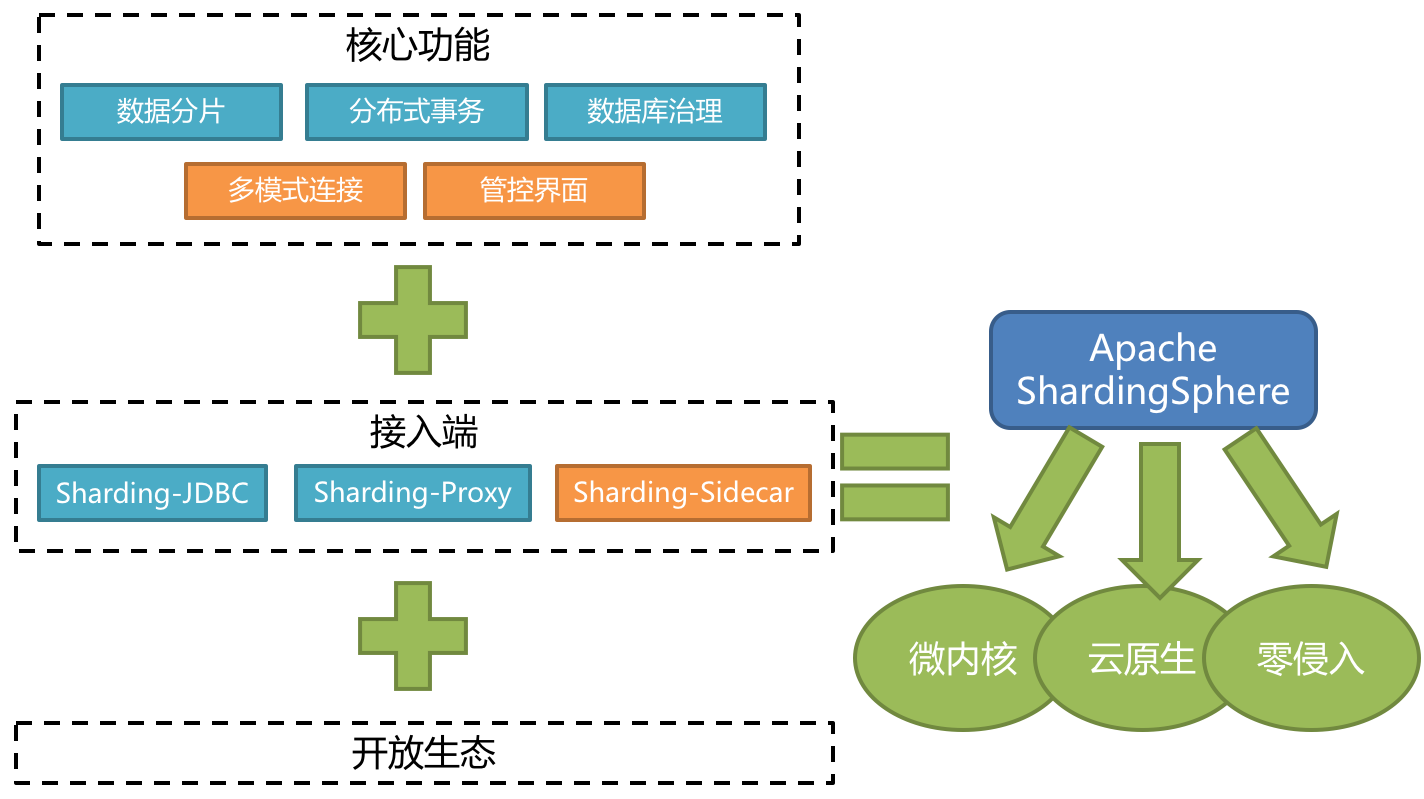
Apache ShardingSphere 5.x 版本開始致力於提供可插拔架構,項目的功能組件能夠靈活的以可插拔的方式進行擴展。 目前,數據分片、讀寫分離、數據加密、影子庫壓測等功能,以及對 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 與協議的支援,均通過插件的方式織入項目。 開發者能夠像使用積木一樣訂製屬於自己的獨特系統。Apache ShardingSphere 目前已提供數十個 SPI 作為系統的擴展點,而且仍在不斷增加中。
如圖7-2,是Sharding-Sphere的整體架構。
Sharding-JDBC
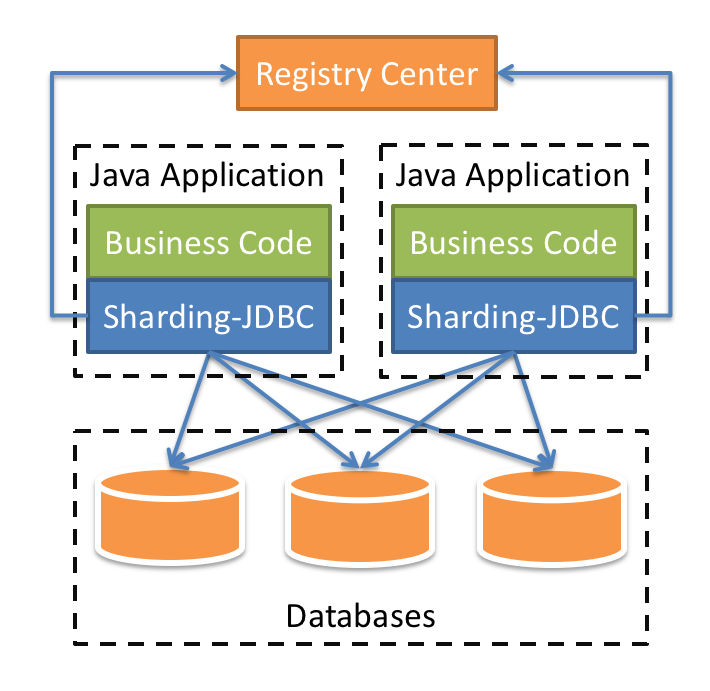
Sharding-JDBC是比較常用的一個組件,它定位的是一個增強版的JDBC驅動,簡單來說就是在應用端來完成資料庫分庫分表相關的路由和分片操作,也是我們本階段重點去分析的組件。
我們在項目內引入Sharding-JDBC的依賴,我們的業務程式碼在操作資料庫的時候,就會通過Sharding-JDBC的程式碼連接到資料庫。也就是分庫分表的一些核心動作,比如SQL解析,路由,執行,結果處理,都是由它來完成的,它工作在客戶端。
Sharding-Proxy
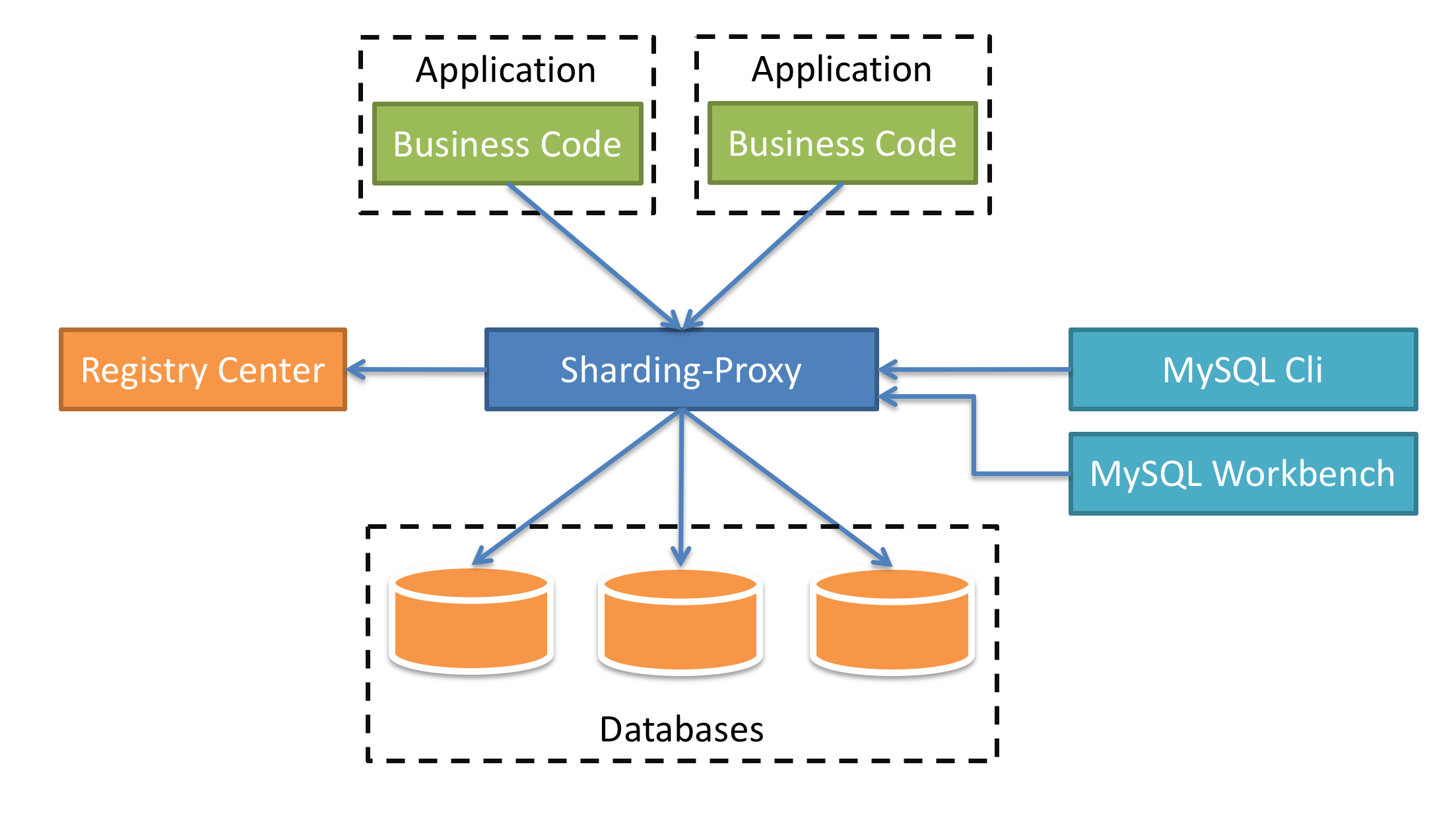
Sharding-Proxy有點類似於Mycat,它是提供了資料庫層面的代理,什麼意思呢?簡單來說,以前我們的應用是直連資料庫,引入了Sharding-Proxy之後,我們的應用是直連Sharding-Proxy,然後Sharding-Proxy通過處理之後再轉發到mysql中。
這種方式的好處在於,用戶不需要感知到分庫分表的存在,相當於正常訪問mysql。目前Sharding-Proxy支援Mysql和PostgreSQL兩種資料庫協議,如圖7-4所示。
Sharding-Sidecar(TODO)
看到Sidecar,大家應該就能想到服務網格架構,它主要定位於 Kubernetes 的雲原生資料庫代理,以 Sidecar 的形式代理所有對資料庫的訪問。目前Sharding-Sidecar還處於開發階段未發布。
Sharding-JDBC
Sharding-JDBC是對原有JDBC驅動的增強,在分庫分表的場景中,為應用提供了如圖7-5所示的功能。

Sharding-JDBC的整體架構
如圖7-6所示,Java應用程式通過Sharding-JDBC驅動訪問資料庫,而在Sharding-JDBC中,它會根據相關配置完成分庫分表路由、分散式事務等功能,所以我們可以認為它是對JDBC驅動的增強。
Registry Center表示註冊中心,用來實現集中化分片配置規則管理、動態配置、以及數據源等資訊。

Sharding-JDBC的基本使用
為了讓大家更好的理解Shading-JDBC,我們通過一個案例來簡單認識一下Sharding-JDBC。『
//shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-jdbc-quick-start/
為了更直觀的理解Sharding-JDBC,下面通過一個原生的案例進行演示。
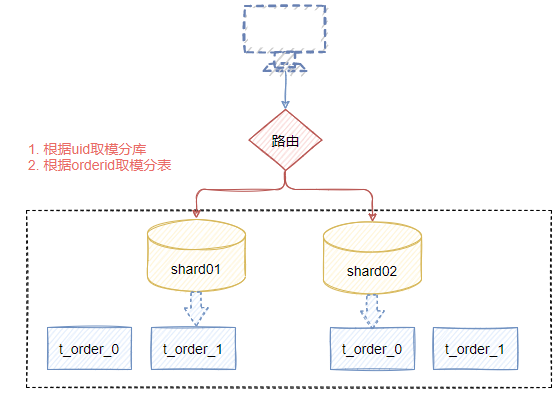
圖7-8表示整體項目結構。

引入Maven依賴
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.0.0-alpha</version>
</dependency>
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
Order
定義Order表的實體對象。
@Data
public class Order implements Serializable {
private static final long serialVersionUID = 661434701950670670L;
private long orderId;
private int userId;
private long addressId;
private String status;
}
OrderReporitoryImpl
定義資料庫操作層
public interface OrderRepository {
void createTableIfNotExists() throws SQLException;
Long insert(final Order order) throws SQLException;
}
public class OrderRepositoryImpl implements OrderRepository {
private final DataSource dataSource;
public OrderRepositoryImpl(final DataSource dataSource) {
this.dataSource = dataSource;
}
@Override
public void createTableIfNotExists() throws SQLException {
String sql = "CREATE TABLE IF NOT EXISTS t_order (order_id BIGINT NOT NULL AUTO_INCREMENT, user_id INT NOT NULL, address_id BIGINT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id))";
try (Connection connection = dataSource.getConnection();
Statement statement = connection.createStatement()) {
statement.executeUpdate(sql);
}
}
@Override
public Long insert(final Order order) throws SQLException {
String sql = "INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)";
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS)) {
preparedStatement.setInt(1, order.getUserId());
preparedStatement.setLong(2, order.getAddressId());
preparedStatement.setString(3, order.getStatus());
preparedStatement.executeUpdate();
try (ResultSet resultSet = preparedStatement.getGeneratedKeys()) {
if (resultSet.next()) {
order.setOrderId(resultSet.getLong(1));
}
}
}
return order.getOrderId();
}
}
OrderServiceImpl
定義資料庫訪問層
public interface ExampleService {
/**
* 初始化表結構
*
* @throws SQLException SQL exception
*/
void initEnvironment() throws SQLException;
/**
* 執行成功
*
* @throws SQLException SQL exception
*/
void processSuccess() throws SQLException;
}
public class OrderServiceImpl implements ExampleService {
private final OrderRepository orderRepository;
Random random=new Random();
public OrderServiceImpl(final DataSource dataSource) {
orderRepository=new OrderRepositoryImpl(dataSource);
}
@Override
public void initEnvironment() throws SQLException {
orderRepository.createTableIfNotExists();
}
@Override
public void processSuccess() throws SQLException {
System.out.println("-------------- Process Success Begin ---------------");
List<Long> orderIds = insertData();
System.out.println("-------------- Process Success Finish --------------");
}
private List<Long> insertData() throws SQLException {
System.out.println("---------------------------- Insert Data ----------------------------");
List<Long> result = new ArrayList<>(10);
for (int i = 1; i <= 10; i++) {
Order order = insertOrder(i);
result.add(order.getOrderId());
}
return result;
}
private Order insertOrder(final int i) throws SQLException {
Order order = new Order();
order.setUserId(random.nextInt(10000));
order.setAddressId(i);
order.setStatus("INSERT_TEST");
orderRepository.insert(order);
return order;
}
}
DataSourceUtil
public class DataSourceUtil {
private static final String HOST = "192.168.221.128";
private static final int PORT = 3306;
private static final String USER_NAME = "root";
private static final String PASSWORD = "123456";
public static DataSource createDataSource(final String dataSourceName) {
HikariDataSource result = new HikariDataSource();
result.setDriverClassName("com.mysql.jdbc.Driver");
result.setJdbcUrl(String.format("jdbc:mysql://%s:%s/%s?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8", HOST, PORT, dataSourceName));
result.setUsername(USER_NAME);
result.setPassword(PASSWORD);
return result;
}
}
Sharding-JDBC分片規則配置
public class ShardingDatabasesAndTableConfiguration {
//創建兩個數據源
private static Map<String,DataSource> createDataSourceMap(){
Map<String, DataSource> dataSourceMap=new HashMap<>();
dataSourceMap.put("ds0",DataSourceUtil.createDataSource("shard01"));
dataSourceMap.put("ds1",DataSourceUtil.createDataSource("shard02"));
return dataSourceMap;
}
private static ShardingRuleConfiguration createShardingRuleConfiguration(){
ShardingRuleConfiguration configuration=new ShardingRuleConfiguration();
configuration.getTables().add(getOrderTableRuleConfiguration());
// configuration.getBindingTableGroups().add("t_order,t_order_item");
//
//
/**
* 設置資料庫的分片規則
* inline表示行表達式分片演算法,它使用groovy的表達式,支援單分片鍵,比如 t_user_$->{uid%8} 表示t_user表根據u_id%8分成8張表
*/
configuration.setDefaultDatabaseShardingStrategy(
new StandardShardingStrategyConfiguration("user_id","inline"));
/**
* 設置表的分片規則
*/
configuration.setDefaultTableShardingStrategy(new StandardShardingStrategyConfiguration("order_id","order_inline"));
Properties props=new Properties();
props.setProperty("algorithm-expression","ds${user_id%2}"); //表示根據user_id取模得到目標表
/**
* 定義具體的分片規則演算法,用於提供分庫分表的演算法規則
*/
configuration.getShardingAlgorithms().put("inline",new ShardingSphereAlgorithmConfiguration("INLINE",props));
Properties properties=new Properties();
properties.setProperty("algorithm-expression","t_order_${order_id%2}");
configuration.getShardingAlgorithms().put("order_inline",new ShardingSphereAlgorithmConfiguration("INLINE",properties));
configuration.getKeyGenerators().put("snowflake",new ShardingSphereAlgorithmConfiguration("SNOWFLAKE",getProperties()));
return configuration;
}
private static Properties getProperties(){
Properties properties=new Properties();
properties.setProperty("worker-id","123");
return properties;
}
//創建訂單表的分片規則
private static ShardingTableRuleConfiguration getOrderTableRuleConfiguration(){
ShardingTableRuleConfiguration tableRule=new ShardingTableRuleConfiguration("t_order","ds${0..1}.t_order_${0..1}");
tableRule.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("order_id","snowflake"));
return tableRule;
}
public static DataSource getDataSource() throws SQLException {
return ShardingSphereDataSourceFactory.createDataSource(createDataSourceMap(), Collections.singleton(createShardingRuleConfiguration()),new Properties());
}
}
Main方法測試
public class ExampleMain {
public static void main(String[] args) throws SQLException {
DataSource dataSource=ShardingDatabasesAndTableConfiguration.getDataSource();
ExampleService exampleService=new OrderServiceImpl(dataSource);
exampleService.initEnvironment();
exampleService.processSuccess();
}
}
Sharding-JDBC使用總結
從上述的案例來看,Sharding-JDBC相當於通過配置化的方式幫我們提供了分片規則的配置,但是基於原生的使用方式,配置起來比較複雜,我們可以直接集成到Spring-Boot中,使用起來會比較簡潔。
Spring Boot集成Sharding-JDBC分片實戰
下面給大家演示一下在springboot應用中集成mybatis的情況下,如何實現分庫分表的配置。
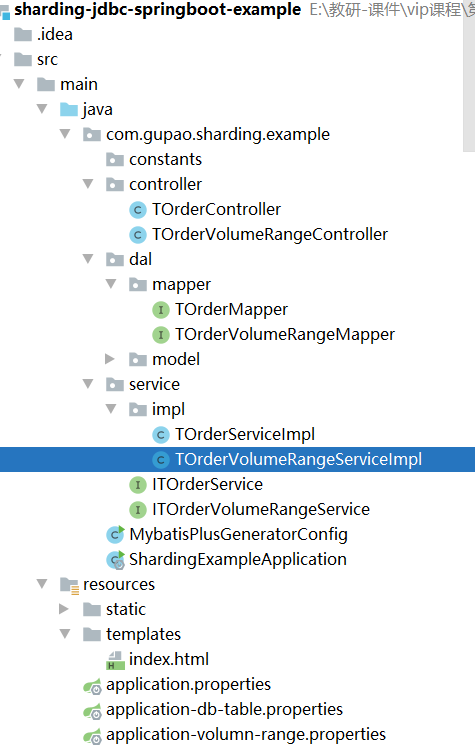
項目程式碼參考: sharding-jdbc-spring-boot-example,項目結構如圖7-8所示。
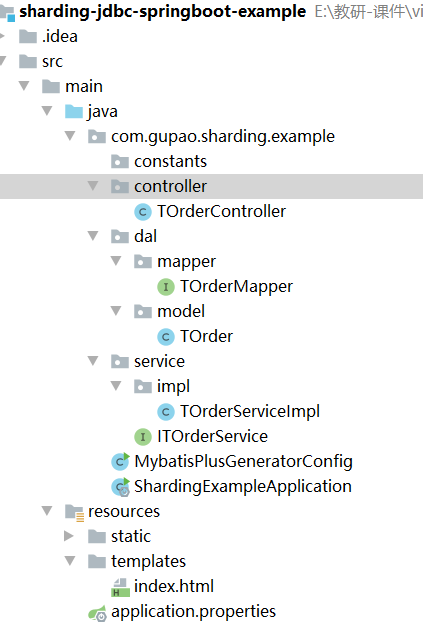
其中,MybatisPlusGeneratorConfig,用來生成t_order表的dal、service、controller程式碼,由於程式碼是基於mybatis-plus生成,這裡就不做過多描述了
引入pom依賴
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.3</version> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-generator</artifactId> <version>3.4.1</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId> <version>5.0.0-alpha</version> </dependency> <dependency> <groupId>com.zaxxer</groupId> <artifactId>HikariCP</artifactId> <version>3.4.2</version> </dependency></dependencies>
application.properties配置
#配置數據源名稱spring.shardingsphere.datasource.names=ds-0,ds-1spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driver# 分別配置多個數據源的詳細資訊spring.shardingsphere.datasource.ds-0.username=rootspring.shardingsphere.datasource.ds-0.password=123456spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://192.168.221.128:3306/shard01?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8spring.shardingsphere.datasource.ds-1.username=rootspring.shardingsphere.datasource.ds-1.password=123456spring.shardingsphere.datasource.ds-1.jdbc-url=jdbc:mysql://192.168.221.128:3306/shard02?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8# 配置資料庫的分庫策略,其中database-inline會在後面聲明spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=user_idspring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline# 配置t_order表的分表策略,其中t-order-inline會在後面聲明# 行表達式標識符可以使用 ${...} 或 $->{...},但前者與 Spring 本身的屬性文件佔位符衝突,因此在 Spring 環境中使用行表達式標識符建議使用 $->{...}spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order_$->{0..1}spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_idspring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=t-order-inline# 配置order_id採用雪花演算法生成全局id策略spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=order_idspring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=snowflake# 配置具體的分庫分表規則spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds-$->{user_id % 2}spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.props.algorithm-expression=t_order_$->{order_id % 2}spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-item-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-item-inline.props.algorithm-expression=t_order_item_$->{order_id % 2}# 配置雪花演算法spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKEspring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123
增加邏輯程式碼
TOrderMapper
@Update("CREATE TABLE IF NOT EXISTS t_order (order_id BIGINT AUTO_INCREMENT, user_id INT NOT NULL, address_id BIGINT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id))")void createTableIfNotExists();
TOrderServiceImpl
@Servicepublic class TOrderServiceImpl extends ServiceImpl<TOrderMapper, TOrder> implements ITOrderService { @Autowired TOrderMapper orderMapper; Random random=new Random(); @Override public void initEnvironment() throws SQLException { orderMapper.createTableIfNotExists(); } @Override public void processSuccess() throws SQLException { System.out.println("-------------- Process Success Begin ---------------"); List<Long> orderIds = insertData(); System.out.println("-------------- Process Success Finish --------------"); } private List<Long> insertData() throws SQLException { System.out.println("---------------------------- Insert Data ----------------------------"); List<Long> result = new ArrayList<>(10); for (int i = 1; i <= 10; i++) { TOrder order = new TOrder(); order.setUserId(random.nextInt(10000)); order.setAddressId(i); order.setStatus("INSERT_TEST"); orderMapper.insert(order); result.add(order.getOrderId()); } return result; }}
TOrderController
提供測試介面。
@RestController@RequestMapping("/t-order")public class TOrderController { @Autowired ITOrderService orderService; @GetMapping public void init() throws SQLException { orderService.initEnvironment(); orderService.processSuccess(); }}
Sharding-JDBC的相關概念說明
前面我們通過兩種方式演示了Sharding-JDBC的分庫分表功能的用法,其實,從這個層面來說,Sharding-JDBC相當於增強了JDBC驅動的功能,使得開發者只需要通過配置就可以輕鬆完成分庫分表功能的實現。
在Sharding-JDBC中,有一些表的概念,需要給大家普及一下,邏輯表、真實表、分片鍵、數據節點、動態表、廣播表、綁定表。
邏輯表
邏輯表可以理解為資料庫中的視圖,是一張虛擬表。可以映射到一張物理表,也可以由多張物理表組成,這些物理表可以來自於不同的數據源。對於mysql, Hbase和ES,要組成一張邏輯表,只需要他們有相同含義的key即可。這個key在mysql中是主鍵,Hbase中是生成rowkey用的值,是ES中的key。
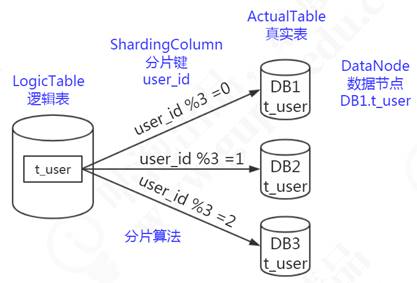
在前面的分庫分表規則配置中,就有用到t_order這個邏輯表的定義,當我們針對t_order表操作時,會根據分片規則映射到實際的物理表進行相關事務操作,如圖7-9所示,邏輯表會在SQL解析和路由時被替換成真實的表名。
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order_$->{0..1}
廣播表
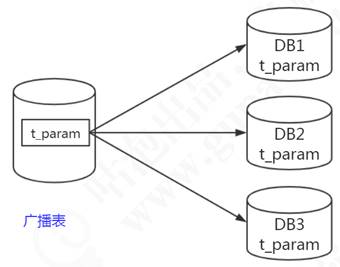
廣播表也叫全局表,也就是它會存在於多個庫中冗餘,避免跨庫查詢問題。
比如省份、字典等一些基礎數據,為了避免分庫分表後關聯表查詢這些基礎數據存在跨庫問題,所以可以把這些數據同步給每一個資料庫節點,這個就叫廣播表,如圖7-10所示。
在Sharding-JDBC中,配置方式如下
# 廣播表, 其主節點是ds0spring.shardingsphere.sharding.broadcast-tables=t_configspring.shardingsphere.sharding.tables.t_config.actual-data-nodes=ds$->{0}.t_config
綁定表
我們有些表的數據是存在邏輯的主外鍵關係的,比如訂單表order_info,存的是匯總的商品數,商品金額;訂單明細表order_detail,是每個商品的價格,個數等等。或者叫做從屬關係,父表和子表的關係。他們之間會經常有關聯查詢的操作,如果父表的數據和子表的數據分別存儲在不同的資料庫,跨庫關聯查詢也比較麻煩。所以我們能不能把父表和數據和從屬於父表的數據落到一個節點上呢?
比如order_id=1001的數據在node1,它所有的明細數據也放到node1;order_id=1002的數據在node2,它所有的明細數據都放到node2,這樣在關聯查詢的時候依然是在一個資料庫,如圖7-11所示
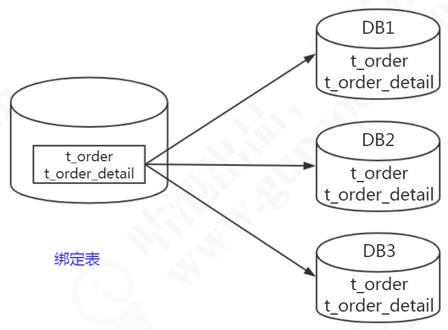
# 綁定表規則,多組綁定規則使用數組形式配置spring.shardingsphere.rules.sharding.binding-tables=t_order,t_order_item
如果存在多個綁定表規則,可以用數組的方式聲明
spring.shardingsphere.rules.sharding.binding-tables[0]= # 綁定表規則列表spring.shardingsphere.rules.sharding.binding-tables[1]= # 綁定表規則列表spring.shardingsphere.rules.sharding.binding-tables[x]= # 綁定表規則列表
Sharding-JDBC中的分片策略
Sharding-JDBC內置了很多常用的分片策略,這些演算法主要針對兩個維度
- 數據源分片
- 數據表分片
Sharding-JDBC的分片策略包含了分片鍵和分片演算法;
- 分片鍵,用於分片的資料庫欄位,是將資料庫(表)水平拆分的關鍵欄位。例:將訂單表中的訂單主鍵的尾數取模分片,則訂單主鍵為分片欄位。 SQL中如果無分片欄位,將執行全路由,性能較差。 除了對單分片欄位的支援,ShardingSphere也支援根據多個欄位進行分片。
- 分片演算法,就是用來實現分片的計算規則。
Sharding-JDBC提供內置了多種分片演算法,包含四種類型分別是
- 自動分片演算法
- 標準分片演算法
- 複合分片演算法
- Hinit分片演算法
自動分片演算法
自動分片演算法,就是根據我們配置的演算法表達式完成數據的自動分發功能,在Sharding-JDBC中提供了五種自動分片演算法
- 取模分片演算法
- 哈希取模分片演算法
- 基於分片容量的範圍分片演算法
- 基於分片邊界的範圍分片演算法
- 自動時間段分片演算法
取模分片演算法
最基礎的取模演算法,它會根據分片欄位的值和sharding-count進行取模運算,得到一個結果。
ModShardingAlgorithm
# database-mod是自定義字元串名字spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-mod# MOD表示取模演算法類型spring.shardingsphere.rules.sharding.sharding-algorithms.database-mod.type=MOD# 表示分片數量spring.shardingsphere.rules.sharding.sharding-algorithms.database-mod.props.sharding-count=2
哈希取模分片演算法
和取模演算法相同,唯一的區別是針對分片鍵得到哈希值之後再取模
HashModShardingAlgorithm
# database-mod是自定義字元串名字spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-hash-modspring.shardingsphere.rules.sharding.sharding-algorithms.database-hash-mod.type=HASH_MODspring.shardingsphere.rules.sharding.sharding-algorithms.database-hash-mod.props.sharding-count=2
分片容量範圍
分片容量範圍,簡單理解就是按照某個欄位的數值範圍進行分片,比如存在下面這樣一個需求,怎麼配置呢?
(0~199)保存到表0[200~399]保存到表1[400~599)保存到表2
參考7.2.3章節中的方式,構建一個t_order_colume_range表,使用mybatis-plus生成相關程式碼,如圖7-12所示
添加如下配置,通過spring.profiles.active=volumn-range來激活不同的配置資訊。
server.port=8080spring.mvc.view.prefix=classpath:/templates/spring.mvc.view.suffix=.htmlspring.shardingsphere.datasource.names=ds-0spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds-0.username=rootspring.shardingsphere.datasource.ds-0.password=123456spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://192.168.221.128:3306/shard01?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8spring.shardingsphere.rules.sharding.tables.t_order_volume_range.actual-data-nodes=ds-0.t_order_volume_range_$->{0..2}spring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-column=user_idspring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-algorithm-name=t-order-volume-rangespring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.column=order_idspring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.key-generator-name=snowflakespring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.type=VOLUME_RANGE#最小的範圍,0-200spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.range-lower=200#最大的範圍,600 ,如果超過600,會報錯spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.range-upper=600# 表示每張表的容量為200spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.sharding-volume=200spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKEspring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123
基於分片邊界的範圍分片演算法
前面講的分片容量範圍分片,是一個均衡的分片方法,如果存在不均衡的場景,比如下面這種情況
(0~1000)保存到表0[1000~20000]保存到表1[20000~300000)保存到表2[300000~無窮大)保存到表3
我們就可以用到基於分片邊界的範圍分片演算法來完成,配置方法如下
BoundaryBasedRangeShardingAlgorithm
# BOUNDARY_RANGE 表示分片演算法類型spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-boundary-range.type=BOUNDARY_RANGE# 分片的範圍邊界,多個範圍邊界以逗號分隔spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-boundary-range.props.sharding-ranges=1000,20000,300000
自動時間段分片演算法
IntervalShardingAlgorithm
根據時間段進行分片,如果想實現如下功能
(1970-01-01 23:59:59 ~ 2020-01-01 23:59:59) 表0[2020-01-01 23:59:59 ~ 2021-01-01 23:59:59) 表1[2021-01-01 23:59:59 ~ 2021-02-01 23:59:59) 表2[2022-01-01 23:59:59 ~ 2024-01-01 23:59:59) 表3
配置方法如下,表示從2010-01-01到2021-01-01這個時間區間內的數據,按照每一年劃分一個表
spring.shardingsphere.rules.sharding.tables.t_order_volume_range.actual-data-nodes=ds-0.t_order_volume_range_$->{0..2}spring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-column=create_datespring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-algorithm-name=t-order-auto-intervalspring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.column=order_idspring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.key-generator-name=snowflakespring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.type=AUTO_INTERVAL# 分片的起始時間範圍,時間戳格式:yyyy-MM-dd HH:mm:ssspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.props.datetime-lower=2010-01-01 23:59:59# 分片的結束時間範圍,時間戳格式:yyyy-MM-dd HH:mm:ssspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.props.datetime-upper=2021-01-01 23:59:59# 單一分片所能承載的最大時間,單位:秒,下面的數字表示1年spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.props.sharding-seconds='31536000'
需要注意,如果是基於時間段來分片,那麼在查詢的時候不能使用函數查詢,否則會導致全路由。
select * from t_order where to_date(create,'yyyy-mm-dd')=''
標準分片演算法
標準分片策略(StandardShardingStrategy),它只支援對單個分片健(欄位)為依據的分庫分表,Sharding-JDBC提供了兩種演算法實現
行表達式分片演算法
類型:INLINE
使用 Groovy 的表達式,提供對 SQL 語句中的 = 和 IN 的分片操作支援,只支援單分片鍵。 對於簡單的分片演算法,可以通過簡單的配置使用,從而避免繁瑣的 Java 程式碼開發,如: t_user_$->{u_id % 8} 表示 t_user 表根據 u_id 模 8,而分成 8 張表,表名稱為 t_user_0 到 t_user_7
配置方法如下。
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds-$->{user_id % 2}spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.props.algorithm-expression=t_order_$->{order_id % 2}
時間範圍分片演算法
和前面自動分片演算法的自動時間段分片演算法類似。
類型:INTERVAL
可配置屬性:
| 屬性名稱 | 數據類型 | 說明 | 默認值 |
|---|---|---|---|
| datetime-pattern | String | 分片鍵的時間戳格式,必須遵循 Java DateTimeFormatter 的格式。例如:yyyy-MM-dd HH:mm:ss | – |
| datetime-lower | String | 時間分片下界值,格式與 datetime-pattern 定義的時間戳格式一致 |
– |
| datetime-upper (?) | String | 時間分片上界值,格式與 datetime-pattern 定義的時間戳格式一致 |
當前時間 |
| sharding-suffix-pattern | String | 分片數據源或真實表的後綴格式,必須遵循 Java DateTimeFormatter 的格式,必須和 datetime-interval-unit 保持一致。例如:yyyyMM |
– |
| datetime-interval-amount (?) | int | 分片鍵時間間隔,超過該時間間隔將進入下一分片 | 1 |
| datetime-interval-unit (?) | String | 分片鍵時間間隔單位,必須遵循 Java ChronoUnit 的枚舉值。例如:MONTHS |
複合分片演算法
使用場景:SQL 語句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是複合分片策略支援對多個分片健操作。
Sharding-JDBC內置了一種複合分片演算法的實現。
類型: COMPLEX_INLINE,實現類:ComplexInlineShardingAlgorithm
| 屬性名稱 | 數據類型 | 說明 | 默認值 |
|---|---|---|---|
| sharding-columns (?) | String | 分片列名稱,多個列用逗號分隔。如不配置無法則不能校驗 | – |
| algorithm-expression | String | 分片演算法的行表達式 | – |
| allow-range-query-with-inline-sharding (?) | boolean | 是否允許範圍查詢。注意:範圍查詢會無視分片策略,進行全路由 |
目前版本還未發布(在github倉庫中已經提供了實現),如果要實現符合分片演算法,需要自己手動實現。
自定義分片演算法
除了默認提供了分片演算法之外,我們可以根據實際需求自定義分片演算法,Sharding-JDBC同樣提供了幾種類型的擴展實現
- 標準分片演算法
- 複合分片演算法
- Hinit分片策略
- 不分片策略
分片策略的介面定義如下,它有四個子類,分別對應上面四種分片策略,我們可以通過繼承不同的分片策略完成自定義分片策略的擴展。
public interface ShardingStrategy { Collection<String> getShardingColumns(); ShardingAlgorithm getShardingAlgorithm(); Collection<String> doSharding(Collection<String> var1, Collection<ShardingConditionValue> var2, ConfigurationProperties var3);}

自定義標準分片演算法
public class StandardModTableShardAlgorithm implements StandardShardingAlgorithm<Long> { private Properties props=new Properties(); /** * 用於處理=和IN的分片。 * @param collection 表示目標分片的集合 * @param preciseShardingValue 邏輯表相關資訊 * @return */ @Override public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) { for(String name:collection){ //根據order_id的值進行取模,得到一個目標值 if(name.endsWith(String.valueOf(preciseShardingValue.getValue()%4))){ return name; } } throw new UnsupportedOperationException(); } /** * 用於處理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND將按照全庫路由處理 * @param collection * @param rangeShardingValue * @return */ @Override public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) { Collection<String> result=new LinkedHashSet<>(collection.size()); for(Long i=rangeShardingValue.getValueRange().lowerEndpoint();i<=rangeShardingValue.getValueRange().upperEndpoint();i++){ for(String name:collection){ if(name.endsWith(String.valueOf(i%4))){ result.add(name); } } } return result; } /** * 初始化對象的時候調用的方法 */ @Override public void init() { } /** * 對應分片演算法(sharding-algorithms)的類型 * @return */ @Override public String getType() { return "STANDARD_MOD"; } @Override public Properties getProps() { return this.props; } /** * 獲取分片相關屬性 * @param properties */ @Override public void setProps(Properties properties) { this.props=properties; }}
通過SPI機制進行擴展
-
在resource目錄下創建META-INF/service/org.apache.shardingsphere.sharding.spi.ShardingAlgorithm文件
-
把自定義標準分片演算法的全路徑寫如到上述文件中
com.gupao.sharding.example.StandardModTableShardAlgorithm
增加application-custom-standard.properties文件
spring.shardingsphere.rules.sharding.tables.t_order_standard.actual-data-nodes=ds-0.t_order_standard_$->{0..3}spring.shardingsphere.rules.sharding.tables.t_order_standard.table-strategy.standard.sharding-column=order_idspring.shardingsphere.rules.sharding.tables.t_order_standard.table-strategy.standard.sharding-algorithm-name=standard-modspring.shardingsphere.rules.sharding.tables.t_order_standard.key-generate-strategy.column=order_idspring.shardingsphere.rules.sharding.tables.t_order_standard.key-generate-strategy.key-generator-name=snowflakespring.shardingsphere.rules.sharding.sharding-algorithms.standard-mod.type=STANDARD_MODspring.shardingsphere.rules.sharding.sharding-algorithms.standard-mod.props.algorithm-class-name=com.gupao.sharding.example.StandardModTableShardAlgorithm
其中,STANDARD_MOD是我們自定義的取模分片演算法的類型。
表以及程式碼生成
把t_order表複製一張t_order_standard,通過mybatis-plus生成業務程式碼。
程式碼工程詳見: sharding-jdbc-springboot-example
關於Java中的SPI機制
SPI 的全名為 Service Provider Interface,它的核心思想是中間件中定義標準,然後使用者可以在這個標準上實現自定義擴展,舉個比較常見的例子,就是JDBC驅動。 Java官方只提供了JDBC驅動的介面
java.sql.Driver
然後各大資料庫廠商,如Mysql、Oracle都會基於這個介面定義不同資料庫的連接實現,然後使用java語言的開發者不需要關心不同資料庫的具體配置,只需要集成相關的依賴包以及配置相關驅動,Java程式就能自動匹配到相關的實現完成資料庫連接。
這種思想在很多地方都有使用,比如Spring中的SpringFactoriesLoader、Dubbo中的SPI思想、Sentinel中的SPI思想等等。很多中間件中使用的SPI都不是Java原生的SPI,而是基於這種思想優化過後的,後續我們會再講到。
下面來看一下SPI如何使用
SPI的使用規則
SPI的使用如圖7-14所示,必須遵循以下約定。
1、在工程的META-INF/services/目錄下,以介面的全限定名作為文件名,文件內容為實現介面的服務類;
2、使用ServiceLoader動態載入META-INF/services下的實現類;
3、介面的實現類需含無參構造函數;(因為類默認包含無參構造函數,如果我們沒有重載構造函數所以此處可忽略)
\07 ShardingSphere分庫分表應用實戰\07 ShardingSphere分庫分表應用實戰.assets\20180329110040213)
SPI的使用實戰
首先創建一個普通的maven項目,目錄結構如下。

Parser
public interface Parser { //解析文件方法 String parse(File file) throws Exception; //文件類型 String getType();}
定義如下兩個實現類
public class JsonParser implements Parser { @Override public String parse(File file) throws Exception { return "我是Json格式解析"; } @Override public String getType() { return ParserConstant.JSON_PARSER; }}
public class XmlParser implements Parser { @Override public String parse(File file) throws Exception { return "我是XML格式解析"; } @Override public String getType() { return ParserConstant.XML_PARSER; }}
ParserConstant
public class ParserConstant { public final static String XML_PARSER="xml"; public final static String JSON_PARSER="json";}
ParserManager
定義一個解析管理器
public class ParserManager { private final static ConcurrentHashMap<String,Parser> registeredParsers = new ConcurrentHashMap<>(); static{ loadInitialParser(); //載入擴展實現 initDefaultStrategy(); //載入默認實現 } private static void loadInitialParser(){ ServiceLoader<Parser> parserServiceLoader=ServiceLoader.load(Parser.class); Iterator<Parser> iterator=parserServiceLoader.iterator(); while(iterator.hasNext()){ Parser parser=iterator.next(); registeredParsers.put(parser.getType(),parser); } } private static void initDefaultStrategy(){ Parser jsonParser=new JsonParser(); Parser xmlParser=new XmlParser(); registeredParsers.put(jsonParser.getType(),jsonParser); registeredParsers.put(xmlParser.getType(),xmlParser); } public static Parser getParser(String key){ return registeredParsers.get(key); }}
把上述項目打包 maven install到本地。
其他項目依賴Parser
上述項目打包之後安裝到本地,在其他項目中,依賴上述項目
演示項目是: sharding-jdbc-springboot-example
- 依賴pom
<dependency> <groupId>org.example</groupId> <artifactId>file-parse-processor</artifactId> <version>1.0-SNAPSHOT</version></dependency>
- 定義擴展實現
public class TxtParser implements Parser { @Override public String parse(File file) throws Exception { return "txt文件解析結果"; } @Override public String getType() { return "txt"; }}
-
配置SPI擴展點
-
在resource目錄下創建 META-INF/services/org.example.Parser
-
把自定義實現類寫的全路徑寫入該文件中
com.gupao.sharding.example.TxtParser -
-
定義controller進行測試
@RestControllerpublic class SPIController { @GetMapping("/spi") public String parser(){ try { return ParserManager.getParser("txt").parse(new File("")); } catch (Exception e) { return "異常"; } }}
通過url訪問測試,可以發現ParserManager可以調用到我們自己擴展實現的解析器。
分散式序列演算法
Sharding-JDBC中默認提供了兩種分散式序列演算法
- UUID
- 雪花演算法
這兩種在前面都說過,就不在重複說明。
分散式序列演算法是為了保證水平分表之後,保證全局唯一性,關於雪花演算法的定義如下。
類型:SNOWFLAKE
可配置屬性:
| 屬性名稱 | 數據類型 | 說明 | 默認值 |
|---|---|---|---|
| worker-id (?) | long | 工作機器唯一標識 | 0 |
| max-vibration-offset (?) | int | 最大抖動上限值,範圍[0, 4096)。註:若使用此演算法生成值作分片值,建議配置此屬性。此演算法在不同毫秒內所生成的 key 取模 2^n (2^n一般為分庫或分表數) 之後結果總為 0 或 1。為防止上述分片問題,建議將此屬性值配置為 (2^n)-1 | 1 |
| max-tolerate-time-difference-milliseconds (?) | long | 最大容忍時鐘回退時間,單位:毫秒 |
關注[跟著Mic學架構]公眾號,獲取更多精品原創


