深度剖析Redis6的持久化機制(大量圖片說明,簡潔易懂)
- 2021 年 10 月 22 日
- 筆記
Redis的強勁性能很大程度上是由於它所有的數據都存儲在記憶體中,當然如果redis重啟或者伺服器故障導致redis重啟,所有存儲在記憶體中的數據就會丟失。但是在某些情況下,我們希望Redis在重啟後能夠保證數據不會丟失。
-
將redis作為nosql資料庫使用。
-
將Redis作為高效快取伺服器,快取被擊穿後對後端資料庫層面的瞬時壓力是特別大的,所有快取同時失效可能會導致雪崩。
這時我們希望Redis能將數據從記憶體中以某種形式同步到硬碟上,使得重啟後可以根據硬碟中的記錄來恢複數據。
Redis支援兩種方式的持久化,一種是RDB方式、另一種是AOF(append-only-file)方式,兩種持久化方式可以單獨使用其中一種,也可以將這兩種方式結合使用。
- RDB:根據指定的規則「定時」將記憶體中的數據存儲在硬碟上,
- AOF:每次執行命令後將命令本身記錄下來。
RDB模式
RDB的持久化方式是通過快照(snapshotting)完成的,它是Redis默認的持久化方式,配置如下。
# save 3600 1
# save 300 100
# save 60 10000
Redis允許用戶自定義快照條件,當符合快照條件時,Redis會自動執行快照操作。快照的條件可以由用戶在配置文件中配置。配置格式如下
save <seconds> <changes>
第一個參數是時間窗口,第二個是鍵的個數,也就是說,在第一個時間參數配置範圍內被更改的鍵的個數大於後面的changes時,即符合快照條件。當觸發條件時,Redis會自動將記憶體中的數據生成一份副本並存儲在磁碟上,
這個過程稱之為「快照」,除了上述規則之外,還有以下幾種方式生成快照。
- 根據配置規則進行自動快照
- 用戶執行SAVE或者GBSAVE命令
- 執行FLUSHALL命令
- 執行複製(replication)時
根據配置規則進行自動快照
- 修改redis.conf文件,表示5秒內,有一個key發生變化,就會生成rdb文件。
save 5 1 # 表示3600s以內至少發生1個key變化(新增、修改、刪除),則重寫rdb文件
save 300 100
save 60 10000
-
修改文件存儲路徑
dir /data/program/redis/bin -
其他參數配置說明
參數 說明 dir rdb文件默認在啟動目錄下(相對路徑) config get dir獲取dbfilename 文件名稱 rdbcompression 開啟壓縮可以節省存儲空間,但是會消耗一些CPU的計算時間,默認開啟 rdbchecksum 使用CRC64演算法來進行數據校驗,但是這樣做會增加大約10%的性能消耗,如果希望獲取到最大的性能提升,可以關閉此功能。
如果需要關閉RDB的持久化機制,可以參考如下配置,開啟save,並注釋其他規則即可
save ""
#save 900 1
#save 300 10
#save 60 10000
用戶執行SAVE或者GBSAVE命令
除了讓Redis自動進行快照以外,當我們對服務進行重啟或者伺服器遷移我們需要人工去干預備份。redis提供了兩條命令來完成這個任務
-
save命令
如圖4-24所示,當執行save命令時,Redis同步做快照操作,在快照執行過程中會阻塞所有來自客戶端的請求。當redis記憶體中的數據較多時,通過該命令將導致Redis較長時間的不響應。所以不建議在生產環境上使用這個命令,而是推薦使用bgsave命令
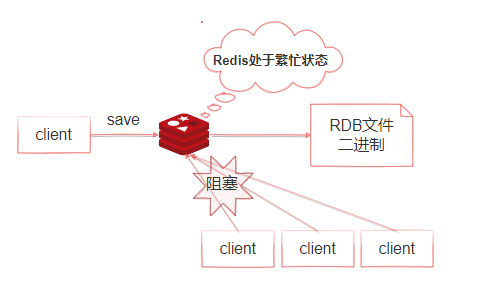
圖4-24 -
bgsave命令
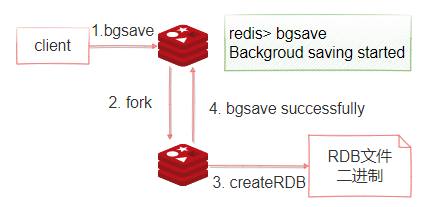
如圖4-25所示,bgsave命令可以在後台非同步地進行快照操作,快照的同時伺服器還可以繼續響應來自客戶端的請求。執行BGSAVE後,Redis會立即返回ok表示開始執行快照操作,在redis-cli終端,通過下面這個命令可以獲取最近一次成功執行快照的時間(以 UNIX 時間戳格式表示)。
LASTSAVE

1:redis使用fork函數複製一份當前進程的副本(子進程)
2:父進程繼續接收並處理客戶端發來的命令,而子進程開始將記憶體中的數據寫入硬碟中的臨時文件
3:當子進程寫入完所有數據後會用該臨時文件替換舊的RDB文件,至此,一次快照操作完成。
注意:redis在進行快照的過程中不會修改RDB文件,只有快照結束後才會將舊的文件替換成新的,也就是說任何時候RDB文件都是完整的。 這就使得我們可以通過定時備份RDB文件來實現redis資料庫的備份, RDB文件是經過壓縮的二進位文件,佔用的空間會小於記憶體中的數據,更加利於傳輸。
bgsave是非同步執行快照的,bgsave寫入的數據就是for進程時redis的數據狀態,一旦完成fork,後續執行的新的客戶端命令對數據產生的變更都不會反應到本次快照
Redis啟動後會讀取RDB快照文件,並將數據從硬碟載入到記憶體。根據數據量大小以及伺服器性能不同,這個載入的時間也不同。
執行FLUSHALL命令
該命令在前面講過,會清除redis在記憶體中的所有數據。執行該命令後,只要redis中配置的快照規則不為空,
也就是save 的規則存在。redis就會執行一次快照操作。不管規則是什麼樣的都會執行。如果沒有定義快照規則,就不會執行快照操作。
執行複製(replication)時
該操作主要是在主從模式下,redis會在複製初始化時進行自動快照。這個會在後面講到;
這裡只需要了解當執行複製操作時,即時沒有定義自動快照規則,並且沒有手動執行過快照操作,它仍然會生成RDB快照文件。
RDB數據恢復演示
- 準備初始數據
redis> set k1 1
redis> set k2 2
redis> set k3 3
redis> set k4 4
redis> set k5 5
-
通過shutdown命令關閉觸發save
redis> shutdown -
備份dump.rdb文件(用來後續恢復)
cp dump.rdb dump.rdb.bak -
接著再啟動redis-server(systemctl restart redis_6379),通過keys命令查看,發現數據還在
keys *
模擬數據丟失
-
執行flushall
redis> flushall -
shutdown(重新生成沒有數據的快照,用來模擬後續的數據恢復)
redis> shutdown -
再次啟動redis, 通過keys 命令查看,此時rdb中沒有任何數據。
-
恢復之前備份的rdb文件(之前保存了數據的rdb快照)
mv dump.rdb.bak dump.rdb -
再次重啟redis,可以看到之前快照保存的數據
keys *
文件的優勢和劣勢
一、優勢
1.RDB是一個非常緊湊(compact)的文件,它保存了redis 在某個時間點上的數據集,這種文件非常適合用於進行備份和災難恢復。
2.生成RDB文件的時候,redis主進程會fork()一個子進程來處理所有保存工作,主進程不需要進行任何磁碟IO操作。
3.RDB 在恢復大數據集時的速度比AOF的恢復速度要快。
二、劣勢
-
1、RDB方式數據沒辦法做到實時持久化/秒級持久化。因為bgsave每次運行都要執行fork操作創建子進程,頻繁執行成本過高
-
2、在一定間隔時間做一次備份,所以如果redis意外down掉的話,就會丟失最後一次快照之後的所有修改(數據有丟失)。
如果數據相對來說比較重要,希望將損失降到最小,則可以使用AOF方式進行持久化。
AOF模式
AOF(Append Only File):Redis 默認不開啟。AOF採用日誌的形式來記錄每個寫操作,並追加到文件中。開啟後,執行更改Redis數據的命令時,就會把命令寫入到AOF文件中。
Redis 重啟時會根據日誌文件的內容把寫指令從前到後執行一次以完成數據的恢復工作。
AOF配置開關
# 開關
appendonly no /yes
# 文件名
appendfilename "appendonly.aof"
通過修改redis.conf重啟redis之後:systemctl restart redis_6379。
再次運行redis的相關操作命令,會發現在指定的dir目錄下生成appendonly.aof文件,通過vim查看該文件內容如下
*2
$6
SELECT
$1
0
*3
$3
set
$4
name
$3
mic
*3
$3
set
$4
name
$3
123
AOF配置相關問題解答
問題1:數據都是實時持久化到磁碟嗎?
雖然每次執行更改Redis資料庫內容的操作時,AOF都會將命令記錄在AOF文件中,但是事實上,由於作業系統的快取機制,數據並沒有真正地寫入硬碟,而是進入了系統的硬碟快取。在默認情況下系統每30秒會執行一次同步操作。以便將硬碟快取中的內容真正地寫入硬碟。
在這30秒的過程中如果系統異常退出則會導致硬碟快取中的數據丟失。一般來說能夠啟用AOF的前提是業務場景不能容忍這樣的數據損失,這個時候就需要Redis在寫入AOF文件後主動要求系統將快取內容同步到硬碟中。在redis.conf中通過如下配置來設置同步機制。
| 參數 | 說明 |
|---|---|
| appendfsync everysec | AOF持久化策略(硬碟快取到磁碟),默認everysec 1 no 表示不執行fsync,由作業系統保證數據同步到磁碟,速度最快,但是不太安全; 2 always 表示每次寫入都執行fsync,以保證數據同步到磁碟,效率很低; 3 everysec表示每秒執行一次fsync,可能會導致丟失這1s數據。通常選擇 everysec ,兼顧安全性和效率。 |
問題2:文件越來越大,怎麼辦?
由於AOF持久化是Redis不斷將寫命令記錄到 AOF 文件中,隨著Redis不斷的運行,AOF 的文件會越來越大,文件越大,佔用伺服器記憶體越大以及 AOF 恢復要求時間越長。
例如set gupao 666,執行1000次,結果都是gupao=666。
為了解決這個問題,Redis新增了重寫機制,當AOF文件的大小超過所設定的閾值時,Redis就會啟動AOF文件的內容壓縮,只保留可以恢複數據的最小指令集。
可以使用命令下面這個命令主動觸發重寫
redis> bgrewriteaof
AOF 文件重寫並不是對原文件進行重新整理,而是直接讀取伺服器現有的鍵值對,然後用一條命令去代替之前記錄這個鍵值對的多條命令,生成一個新的文件後去替換原來的 AOF 文件。
重寫觸發機制如下
| 參數 | 說明 |
|---|---|
| auto-aof-rewrite-percentage | 默認值為100。表示的是當目前的AOF文件大小超過上一次重寫時的AOF文件大小的百分之多少時會再次進行重寫,如果之前沒有重寫過,則以啟動時AOF文件大小為依據 |
| auto-aof-rewrite-min-size | 默認64M。表示限制了允許重寫的最小AOF文件大小,通常在AOF文件很小的情況下即使其中有很多冗餘的命令我們也並不太關心 |
在啟動時,Redis會逐個執行AOF文件中的命令來將硬碟中的數據載入到記憶體中,載入的速度相對於RDB會慢一些
問題:重寫過程中,AOF文件被更改了怎麼辦?
Redis 可以在 AOF 文件體積變得過大時,自動地在後台對 AOF 進行重寫: 重寫後的新 AOF 文件包含了恢復當前數據集所需的最小命令集合。
重寫的流程是這樣,
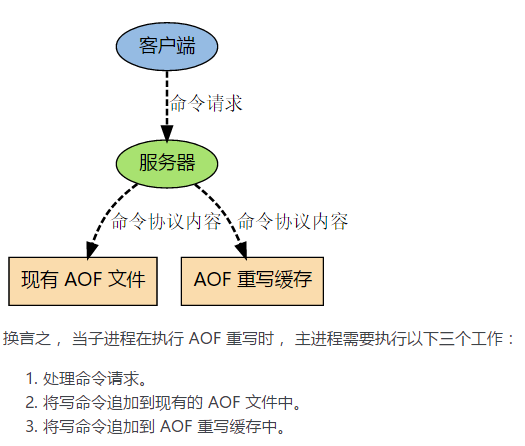
- 主進程會fork一個子進程出來進行AOF重寫,這個重寫過程並不是基於原有的aof文件來做的,而是有點類似於快照的方式,全量遍歷記憶體中的數據,然後逐個序列到aof文件中。
- 在fork子進程這個過程中,服務端仍然可以對外提供服務,那這個時候重寫的aof文件的數據和redis記憶體數據不一致了怎麼辦?不用擔心,這個過程中,主進程的數據更新操作,會快取到aof_rewrite_buf中,也就是單獨開闢一塊快取來存儲重寫期間收到的命令,當子進程重寫完以後再把快取中的數據追加到新的aof文件。
- 當所有的數據全部追加到新的aof文件中後,把新的aof文件重命名正式的文件名字,此後所有的操作都會被寫入新的aof文件。
- 如果在rewrite過程中出現故障,不會影響原來aof文件的正常工作,只有當rewrite完成後才會切換文件。因此這個rewrite過程是比較可靠的。
Redis允許同時開啟AOF和RDB,既保證了數據安全又使得進行備份等操作十分容易。如果同時開啟後,Redis重啟會使用AOF文件來恢複數據,因為AOF方式的持久化可能丟失的數據更少。
AOF的優劣勢
優點:
1、AOF 持久化的方法提供了多種的同步頻率,即使使用默認的同步頻率每秒同步一次,Redis 最多也就丟失 1 秒的數據而已。
缺點:
1、對於具有相同數據的的Redis,AOF 文件通常會比 RDB 文件體積更大(RDB存的是數據快照)。
2、雖然 AOF 提供了多種同步的頻率,默認情況下,每秒同步一次的頻率也具有較高的性能。在高並發的情況下,RDB 比 AOF 具好更好的性能保證。
關注[跟著Mic學架構]公眾號,獲取更多精品原創



